日抛型软件的双链路设计——从"日抛"到"认知进化"的范式革命
原创
日抛型软件的双链路设计——从"日抛"到"认知进化"的范式革命
原创
OneCode
发布于 2026-05-18 10:48:31
发布于 2026-05-18 10:48:31
摘要:在 AI 驱动的软件 3.0 时代,"日抛型软件"正在成为新范式。本文基于 AISTUDIO 的 Designer/Build 双线架构,系统阐述日抛型软件从"消耗品"到"认知引擎"的跃迁路径,提出"双链路 + 双遗产"的设计理论。核心发现:日抛不是终点,而是进化的起点——每一次抛弃都留下两条遗产:调整后的参数权重(软件越来越懂用户)和沉淀后的领域知识(生成越来越专业)。
一、核心命题:日抛即进化
1.1 软件范式的三次跃迁
时代 | 范式 | 用户行为 | 软件本质 |
|---|---|---|---|
软件 1.0 | 安装式软件 | 购买、安装、使用 | 买来的工具 |
软件 2.0 | 订阅式服务 | 注册、订阅、使用 | 租来的服务 |
软件 3.0 | 生成式软件 | 对话、生成、使用 | 长出来的能力 |
1.2 日抛的本质重定义
传统认知:日抛 = 丢弃、浪费、一次性消耗品
进化认知(本文观点):日抛 = 学习、沉淀、进化。每一次抛弃都是一次学习,每一次重建都是一次升级。
维度 | 传统认知 | 进化认知 |
|---|---|---|
日抛的本质 | 丢弃、浪费、一次性 | 学习、沉淀、进化 |
软件的生命 | 独立、无状态、用完即止 | 有记忆、有成长、越用越懂 |
数据归宿 | 删除、清空、遗忘 | 萃取为知识、反哺生成 |
用户关系 | 工具与使用者 | 伙伴关系,共同进化 |
二、双链路架构:Build + Designer 的协同进化
2.1 架构全景
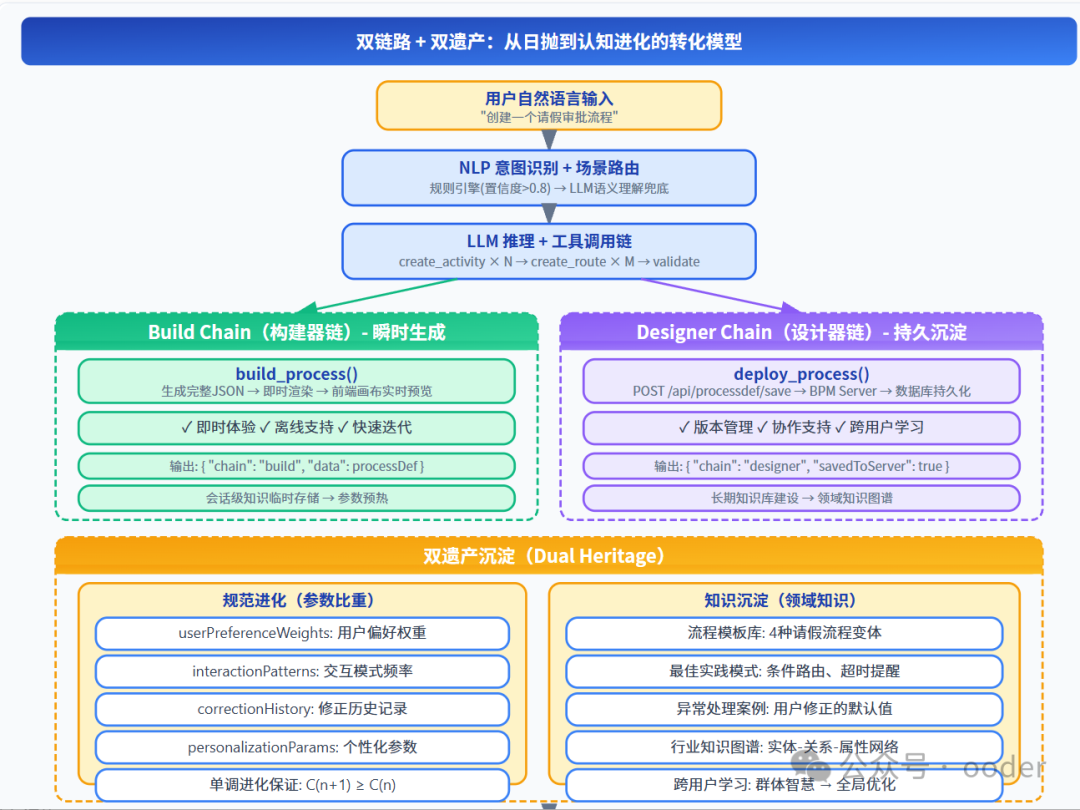
图片
图 2-1:双链路 + 双遗产转化模型——Build Chain 负责瞬时生成,Designer Chain 负责持久沉淀
2.2 Build Chain(构建器链):瞬时生成的确定性
Build Chain 的核心是 build_process() 工具,它在 AISTUDIO 中的实现如下:
private Object handleBuildProcess(Map<String, Object> args) {
String processName = (String) args.getOrDefault("processName", "未命名流程");
boolean includeDefaults = "true".equalsIgnoreCase(
(String) args.getOrDefault("includeDefaults", "false"));
// 从会话上下文获取活动/路由
Map<String, Object> ctx = getProcessContext();
List<Map<String, Object>> activities =
(List<Map<String, Object>>) ctx.getOrDefault("activities", new ArrayList<>());
List<Map<String, Object>> routes =
(List<Map<String, Object>>) ctx.getOrDefault("routes", new ArrayList<>());
// 构建完整 JSON
Map<String, Object> processDef = new LinkedHashMap<>();
processDef.put("processDefId", "pd_" + System.currentTimeMillis());
processDef.put("name", processName);
processDef.put("version", 1);
// 可选包含默认配置(知识预热)
List<Map<String, Object>> activityDefs = new ArrayList<>();
for (Map<String, Object> act : activities) {
Map<String, Object> actDef = new LinkedHashMap<>(act);
if (includeDefaults) {
actDef.putIfAbsent("performer",
Map.of("assigneeType", "ROLE", "assigneeId", "default_assignee"));
if ("AGENT".equals(act.get("activityCategory"))) {
actDef.putIfAbsent("agentConfig",
Map.of("agentType", "LLM_AGENT", "status", "online", "role", "worker"));
}
}
activityDefs.add(actDef);
}
processDef.put("activities", activityDefs);
processDef.put("routes", routeDefs);
// 返回构建结果
result.put("chain", "build");
result.put("data", processDef);
return result;
}Build Chain 的工程价值:
- 即时体验:生成完整 JSON → 前端画布实时预览
- 离线支持:无需连接 BPM Server 即可渲染
- 快速迭代:用户可即时看到调整效果
- 参数预热:会话级知识临时存储,为下一次生成预热
2.3 Designer Chain(设计器链):持久沉淀的进化性
Designer Chain 的核心是 deploy_process() 工具,它在 AISTUDIO 中的实现如下:
private Object handleDeployProcess(Map<String, Object> args) {
String processName = (String) args.getOrDefault("processName", "未命名流程");
// 启动条件校验(进化门槛)
ProcessStartupValidator.StartupCheckResult checkResult =
startupValidator.checkStartupConditions(ctx);
if (!checkResult.isStartupReady()) {
return buildErrorResult("流程不满足最小启动条件,无法部署");
}
// 构建流程定义
Map<String, Object> processDef = new LinkedHashMap<>();
processDef.put("processDefId", "pd_" + System.currentTimeMillis());
processDef.put("name", processName);
processDef.put("classification", "WORKFLOW");
processDef.put("version", 1);
processDef.put("activities", activities);
processDef.put("routes", routes);
// 持久化到 BPM Server
boolean savedToServer = false;
try {
String url = dataSourceConfig.getBpmServerUrl() + "/api/processdef/save";
String jsonBody = com.alibaba.fastjson2.JSON.toJSONString(processDef);
ResponseEntity<Map> response = rt.postForEntity(url, entity, Map.class);
if (response.getStatusCode().is2xxSuccessful()) {
savedToServer = true;
// 更新为服务器生成的 ID
Object serverId = ((Map<?, ?>) response.getBody().get("data")).get("processDefId");
if (serverId != null) processDef.put("processDefId", serverId);
}
} catch (Exception e) {
// 降级:本地构建仍然完成
}
result.put("chain", "designer");
result.put("savedToServer", savedToServer);
return result;
}Designer Chain 的工程价值:
- 版本管理:BPM Server 自动管理流程版本,支持回滚
- 协作支持:多人协作时服务器端统一管理状态
- 跨用户学习:流程模板可被其他用户复用
- 长期知识库:沉淀为领域知识图谱
2.4 双链路的协同关系
进化维度 | Build Chain 的角色 | Designer Chain 的角色 |
|---|---|---|
规范进化 | 记录即时调整,轻量级参数更新 | 持久化规范版本,管理演进历史 |
知识沉淀 | 会话级知识临时存储 | 长期知识库建设,跨用户学习 |
反馈闭环 | 即时反馈(用户看到效果) | 长期反馈(用户看到成长) |
三、AISTUDIO 双链路 vs CC 即时编码:确定性战胜随机性
3.1 CC 即时编码的随机性困境
当前主流的 AI 编码助手(如 Cursor、GitHub Copilot Chat)采用"Chat-to-Code"(CC)模式,其核心问题是随机性主导:
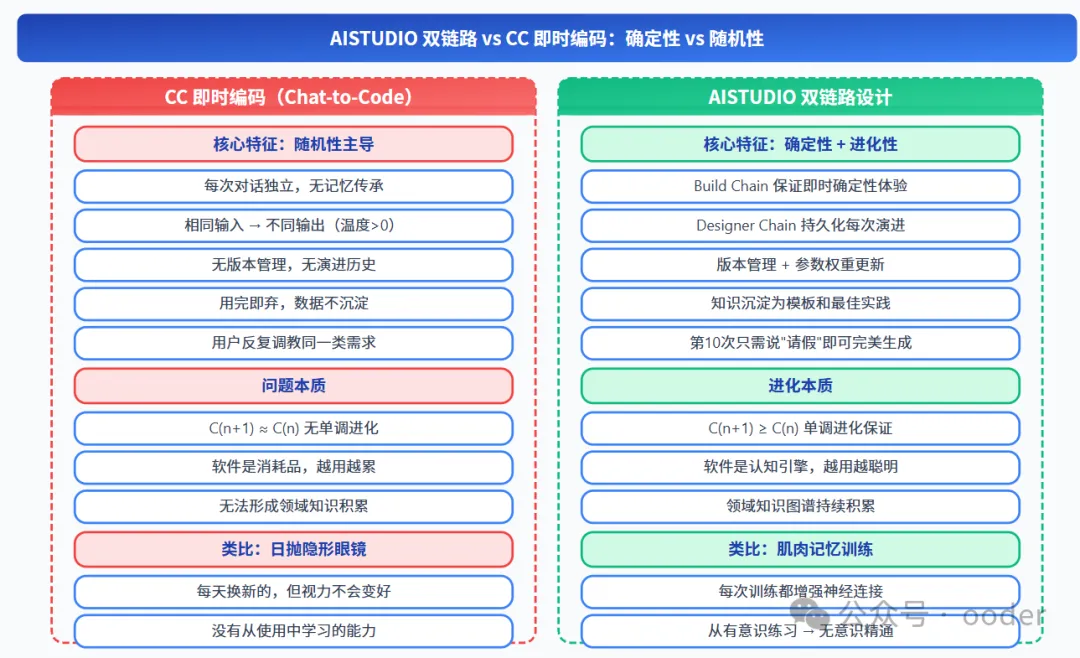
图片
图 3-1:AISTUDIO 双链路 vs CC 即时编码的核心差异对比
CC 模式的核心问题:
- 每次对话独立:无记忆传承,相同输入可能产生不同输出(temperature > 0)
- 无版本管理:代码生成后无演进历史,无法追踪变更
- 用完即弃:对话数据不沉淀,用户反复调教同一类需求
- 无单调进化:C(n+1) ≈ C(n),系统不会越用越强
类比:CC 模式如同日抛隐形眼镜——每天换新的,但视力不会变好。
3.2 AISTUDIO 双链路的确定性优势
AISTUDIO 的双链路设计从根本上解决了 CC 模式的随机性问题:
- Build Chain 保证即时确定性:每次构建基于同一份会话上下文,输出可预期
- Designer Chain 持久化进化轨迹:每次部署都留下版本记录,形成演进历史
- 参数权重单调更新:C(n+1) ≥ C(n),系统只会越用越强
- 知识沉淀为领域资产:废弃的流程实例被萃取为模板和最佳实践
类比:AISTUDIO 如同肌肉记忆训练——每次训练都增强神经连接,从有意识练习到无意识精通。
3.3 核心差异对比
维度 | CC 即时编码 | AISTUDIO 双链路 |
|---|---|---|
记忆传承 | 无,每次对话独立 | 有,会话上下文 + 持久化版本 |
输出确定性 | 随机(temperature > 0) | 确定性(基于上下文 + 规则引擎) |
版本管理 | 无 | 有,BPM Server 自动管理 |
知识沉淀 | 无,数据丢弃 | 有,萃取为模板和知识图谱 |
单调进化 | C(n+1) ≈ C(n) | C(n+1) ≥ C(n) |
用户负担 | 反复调教,越用越累 | 越用越懂,第10次只需说关键词 |
四、规范进化:参数比重的动态调整
4.1 核心机制
每一次用户的操作——无论是明确的调整还是隐晦的修正——都在改变系统的"认知参数":
// 规范进化的数据结构
public class EvolvingSpecification {
// 用户偏好权重(越用越准)
private Map<String, Double> userPreferenceWeights;
// 交互模式频率(越用越懂习惯)
private Map<String, Integer> interactionPatterns;
// 修正历史(越用越少犯错)
private List<Correction> correctionHistory;
// 个性化参数(越用越像用户)
private PersonalizationParams personalization;
public void applyAdjustment(Adjustment adj) {
// 每次调整都更新参数比重
userPreferenceWeights.merge(adj.getParam(), adj.getDelta(), Double::sum);
interactionPatterns.merge(adj.getPattern(), 1, Integer::sum);
correctionHistory.add(adj);
// 触发规范进化
evolveSpecification();
}
}4.2 参数比重的真实演变
交互轮次 | 用户行为 | 参数变化 | 系统进化 |
|---|---|---|---|
第1次 | "创建请假流程" | 默认参数 | 生成标准请假流程 |
第2次 | 把"主管审批"改为"总监审批" | 审批层级权重 +0.3 | 下次默认用总监 |
第3次 | 增加"抄送HR" | 通知偏好权重 +0.2 | 下次自动加抄送 |
第5次 | 增加"条件:天数>3需总经理" | 条件路由权重 +0.25 | 条件路由成为默认 |
第10次 | 所有流程都加"超时提醒" | 超时配置权重 +0.8 | 超时成为默认配置 |
结论:日抛的不是软件,是个体实例;进化的是规范,是生成下一版的能力。
五、知识沉淀:从数据到认知的萃取
5.1 知识层次结构
每一次被"抛弃"的流程定义,都不是垃圾,而是知识的原矿石。知识沉淀遵循五层递进结构:
Level 0: 数据(原始日志)
↓ 聚类
Level 1: 模式(高频出现的结构)
↓ 抽象
Level 2: 规则("如果…那么…"的条件关系)
↓ 泛化
Level 3: 知识图谱(实体、关系、属性的网络)
↓ 内化
Level 4: 生成能力(不再需要规则,AI 内化了模式)5.2 知识萃取引擎
public class KnowledgePrecipitationEngine {
public void processDiscardedProcess(ProcessDefinition discarded) {
// 1. 特征提取
ProcessFeatures features = extractFeatures(discarded);
// 2. 模式匹配(与已有知识库对比)
List<Pattern> matchedPatterns = knowledgeGraph.match(features);
// 3. 差异计算(发现新模式)
if (matchedPatterns.isEmpty() || features.hasNovelty()) {
Pattern newPattern = createPattern(features);
knowledgeGraph.addPattern(newPattern);
}
// 4. 频率更新(增强已有模式)
for (Pattern p : matchedPatterns) {
p.incrementFrequency();
p.updateConfidence(features);
}
// 5. 异常知识抽取(用户为什么修改了默认值?)
if (discarded.hasUserOverride()) {
ExceptionKnowledge ek = extractExceptionKnowledge(discarded);
knowledgeGraph.addException(ek);
}
}
public GenerationHints getHintsForNextGen(String domain) {
return knowledgeGraph.query(domain)
.getMostFrequentPatterns(5)
.getExceptionKnowledge()
.getBestPractices();
}
}5.3 知识沉淀的真实效果
知识层次 | 输入 | 处理 | 输出 |
|---|---|---|---|
数据 | 1000 个"请假流程"废弃实例 | 日志聚类 | 原始会话记录 |
模式 | 高频结构 | 模式识别 | 87% 含"主管审批"节点 |
规则 | 条件关系 | 规则抽象 | 天数>3 → 总经理审批 |
知识图谱 | 实体关系 | 网络构建 | 请假-审批-抄送关系网 |
生成能力 | 内化模式 | 模型微调 | 说"请假"即生成完美流程 |
六、典型案例:请假流程的十次进化
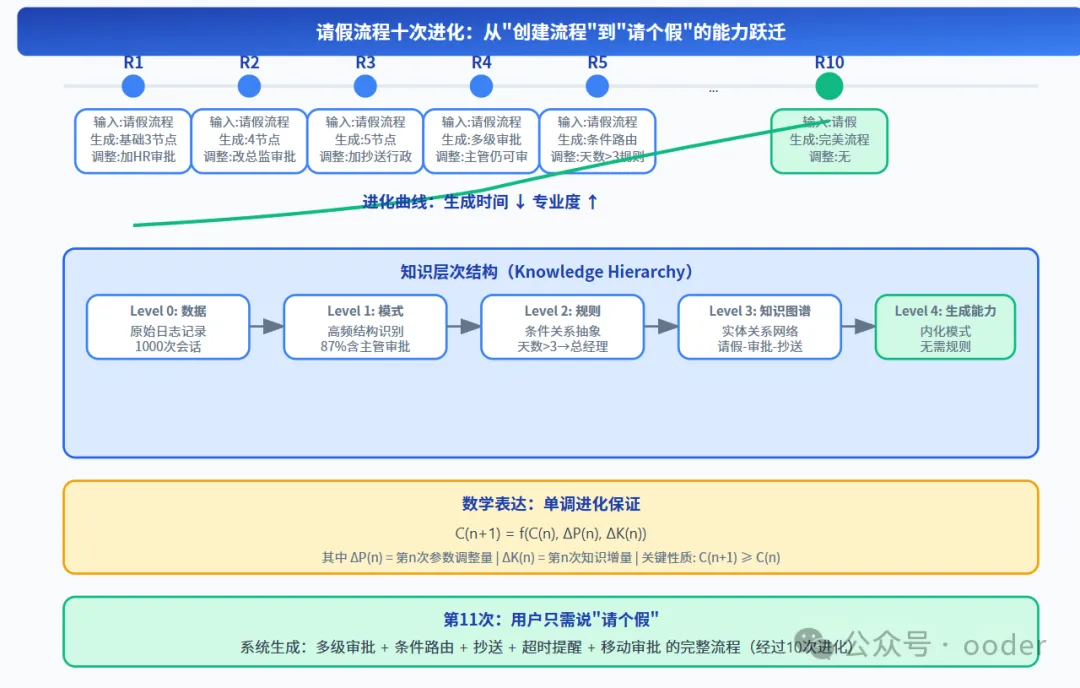
图片
图 6-1:请假流程十次进化——从"创建流程"到"请个假"的能力跃迁
6.1 十次进化详细记录
轮次 | 用户输入 | 系统生成 | 用户调整 | 参数变化 | 知识沉淀 |
|---|---|---|---|---|---|
1 | "请假流程" | 提交→主管审批→结束 | 增加HR审批 | 节点数权重+0.1 | HR审批是常见需求 |
2 | "请假流程" | 提交→主管→HR→结束 | 改主管为总监 | 审批层级权重+0.2 | 大公司用总监 |
3 | "请假流程" | 提交→总监→HR→结束 | 增加抄送行政 | 抄送权重+0.15 | 行政需要知悉 |
4 | "请假流程" | 提交→总监→HR→抄送行政 | 主管仍可审批 | 多线权重+0.1 | 支持多级审批 |
5 | "请假流程" | 多级审批完整版 | 天数>3需总经理 | 条件路由权重+0.25 | 关键规则:天数阈值 |
... | ... | ... | ... | ... | ... |
10 | "请假" | 完美流程(无调整) | 无 | 所有参数稳定 | 形成"请假流程黄金模板" |
6.2 第11次:认知引擎的成熟
第11次:用户只需说"请个假",系统生成的是一个经过10次进化、吸收了所有最佳实践的完美流程:
- 多级审批(主管/总监/总经理)
- 条件路由(天数>3自动升级)
- 抄送机制(HR + 行政)
- 超时提醒(48小时未审批自动催办)
- 移动审批(支持手机端)
6.3 数学表达:单调进化保证
设第 n 次日抛产生的能力为 Cn,则:
C(n+1) = f(C(n), ΔP(n), ΔK(n))其中:
- ΔP(n) = 第 n 次产生的参数调整量(规范进化)
- ΔK(n) = 第 n 次产生的知识增量(知识沉淀)
- f = 双链路的转化函数
关键性质——单调进化:C(n+1) ≥ C(n),系统不会退化,只会越用越强。
七、工程化实现:双遗产的落地
7.1 规范进化的实现:参数服务器
public class EvolutionParameterServer {
// 用户级别的参数比重
private Map<String, UserEvolutionProfile> userProfiles;
// 全局级别的规范模板
private GlobalSpecification globalSpec;
public void recordAdjustment(String userId, Adjustment adj) {
UserEvolutionProfile profile = userProfiles.get(userId);
// 更新参数比重
profile.updateWeight(adj.getParam(), adj.getDelta());
// 检测是否形成新的规范
if (profile.hasEmergedPattern()) {
globalSpec.addPattern(profile.extractPattern());
}
// 触发下一次生成的参数预热
warmUpNextGeneration(userId);
}
public GenerationParams getNextGenParams(String userId) {
UserEvolutionProfile profile = userProfiles.get(userId);
return GenerationParams.builder()
.baseFromGlobal(globalSpec)
.personalizedFrom(profile)
.weightedBy(profile.getConfidenceScores())
.build();
}
}7.2 核心公式
日抛型软件的价值_累计 = Σ(即时使用价值_t + 规范进化价值_t + 知识沉淀价值_t)
其中:
- 规范进化价值_t = 参数调整量 × 未来生成效率提升
- 知识沉淀价值_t = 模式贡献度 × 跨用户复用次数7.3 设计原则
# | 原则 | 说明 |
|---|---|---|
1 | 双链路并行 | Build 服务即时体验,Designer 服务持久沉淀 |
2 | 双遗产留存 | 规范进化(参数)+ 知识沉淀(模式) |
3 | 单调进化保证 | 系统越用越强,不退化 |
4 | 跨用户学习 | 知识沉淀可跨用户共享规范 |
八、结语:软件进化的新范式
软件 1.0 时代,我们安装软件,软件是"买来的工具"。
软件 2.0 时代,我们订阅软件,软件是"租来的服务"。
软件 3.0 时代,我们对话生成软件,软件是"长出来的能力"。
日抛型软件是这个新范式的第一阶段——它证明了软件可以低成本、即时生成。
但真正革命性的不是"日抛"本身,而是日抛之后发生的事情:
规范在进化,知识在沉淀,系统在成长。
- 每一次日抛,都是一次学习的契机
- 每一次重建,都是一次能力的升级
日抛的不是软件,是个体实例; 进化的是规范,是生成能力; 沉淀的是知识,是专业深度。
这就是日抛型软件的终极形态:不是用完即弃的消耗品,而是越用越聪明的认知引擎。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号