从OWL到OWL2和SHACL,从本体模型和AI大模型,构建本体建模和大模型推理的分离

从OWL到OWL2和SHACL,从本体模型和AI大模型,构建本体建模和大模型推理的分离

人月聊IT
发布于 2026-06-01 16:35:23
发布于 2026-06-01 16:35:23
大家好,我是人月聊IT。
这篇文章记录的是我自己一段绕了弯路的思考。我最初是带着一个相当笃定的判断出发的——"传统本体根本承载不了真正的业务规则"。后来我发现这个判断不全对,又一次次推翻、修正自己,最终落到一个和出发点很不一样的地方:本体只负责把对象、关系和规则定义清楚,真正的推理交给大模型自己去做。 我把这个反复的过程原原本本写下来,既是给自己一个交代,也是想说明:这个结论不是拍脑袋来的,而是被一步步逼出来的。
本体论(Ontology)源自哲学,在计算机科学中被引入为"共享概念模型的明确形式化规范",目标是为某一领域提供可被机器处理的公共词汇表,以支持知识共享、复用与推理。在语义网技术栈中,RDF 提供三元组数据模型,OWL 在其上扩展逻辑构造器,二者共同支撑了过去二十年的本体建模实践。
然而,一个长期被默认、却很少被言明的前提是:**传统本体的"推理"由一台确定性的推理机来完成**——描述逻辑(DL)推理器做分类与一致性检查,规则引擎做条件触发。整套形式化体系(类、公理、约束)本质上是为这台机器优化的。
进入大模型时代,这个前提发生了根本变化。当本体的消费者从 DL 推理机变成大语言模型(LLM)时,评价一套本体好坏的标准、它应当承载什么、以及它应当长什么样,都要重新回答。本文的核心主张是:
AI 时代的业务语义本体,职责应收敛为"清晰地定义对象、关系、行为与规则";真正的推理——规则的选取、组装与套用——交还给大模型自身的推理能力,而不再依赖 DL 或外部规则引擎。
一、本体如何处理复杂复合规则?
我最早做业务语义建模时,用的是 OWL 和 RDF 这套语义网的东西。RDF 用主谓宾三元组描述事实,OWL 在它上面加了一层逻辑——类的层次、属性的定义域值域、传递性对称性、类的交并补,还能交给推理机做分类和一致性检查。在做学术性的、偏分类的知识库时,它确实很优雅。
可一旦面对真实的工业业务,我就觉得处处别扭,主要是四个地方:
第一,它是静态的,只会描述"是什么",不会描述"做什么"。 OWL 的类只有属性,没有方法、没有行为。比如"订单"应该有个"取消"操作,但在 OWL 里我只能声明订单有个状态属性,取消的逻辑只能甩给外部代码。更别说"库存低于阈值就自动生成采购单"这种"当条件满足就触发动作"的需求,OWL 和 RDF 压根没有事件和触发机制。
第二,复杂的、跨多个对象的组合规则很难写。 我当时最头疼的一个例子是供应链的多级物料清单:成品 A 包含零件 B,B 又包含零件 C,如果 A 产自中国、C 是危险品,那 A 就要施加特殊运输条件。这要跨 A、B、C 多个对象,还要把"产地"和"危险品标志"两个不同属性组合起来判断。OWL 里我可以用传递属性推出"A 包含 C",但"产地 + 危险品组合触发新分类"这种基于多个事实的复合条件,一条公理写不出来。用 SWRL 倒是能凑,可推理的可判定性又可能丢掉,而且很多推理机对 SWRL 支持有限。
第三,关系是静态的、全局成立的,可现实里关系是看场景的。 比如"设备归属生产线"这条关系,在巡检场景下它一直成立,但在故障预测场景下,只有设备处于"在线"状态它才有意义。OWL 里两个对象用对象属性一连,就默认它永远成立、不分上下文。我想表达"关系的语义粒度随业务视角变化",OWL 给不了我这个机制。
第四,超过两个参与者的关系建模特别笨。 "张三在某年某月向李四买了一台设备",这一句话里有买家、卖家、时间、商品四个角色。OWL 的对象属性本质是二元的,我只能造一个"购买事件"的中间类,再用一堆属性分别连过去——这就是所谓的具体化(reification)。能做,但啰嗦,而且丢掉了关系的直觉,查询和推理都更累。
除了这四点,还有一个更底层的矛盾让我很在意:OWL 默认开放世界假设(OWA)——没被证明为真的,也不能判定为假。可我的业务系统基本都跑在封闭世界假设(CWA)下——没声明为真的就当假。这个认知差异会推出一堆反直觉的结果,也是我觉得 OWL 难直接当业务规则引擎用的重要原因。
所以我当时的结论很干脆:OWL 不行,得另起炉灶。 我去看了 Palantir Foundry 的工业本体,觉得它的"行为类型"很对路——能定义带前置条件、后置条件、副作用的操作;又借了领域驱动设计(DDD)和事件驱动架构(EDA)的事件、命令那套思想,想用"静态本体 + 领域事件 + 命令 + 规则引擎"把动态行为补回来。那会儿我甚至想把复杂的跨对象逻辑塞进"领域服务或聚合根方法"里。
二、OWL 2 和 SHACL
把思路理顺、准备动笔时,我才意识到一件有点尴尬的事:我批的其实是十几年前的老 OWL。
我用来举例的 OWL Lite / DL / Full 三分,是 2004 年 OWL 1 的划分。现行标准是 2009 年的 OWL 2,它有 EL、QL、RL 三个 profile,其中 OWL 2 RL 本来就是面向规则式实现设计的。更关键的是 2017 年成为 W3C 标准的 SHACL——它提供的恰恰是封闭世界的约束校验,能做跨对象约束,配上 SHACL-SPARQL 还能做跨属性的算术和时间比较。
我对着自己列的四条"OWL 做不到"一条条比:封闭世界矛盾,SHACL 解决了一大半;跨属性比较,SHACL-SPARQL 能做;跨对象约束,也能写。也就是说——表达力根本不是问题。 我那个"OWL 装不下规则"的出发点,被新标准推翻了。
顺带我也校正了自己对 Palantir 的理解。我原先把它的构件记成"对象、属性、关系、行为类型",可查了官方文档才发现,它的核心构件准确说是:对象类型(object type)、属性(property)、链接类型(link type)、动作类型(action type),外加一个我之前完全漏掉的——函数(function)。而 Palantir 自己说得很清楚:动作类型用来编排决策流程,函数才是用来承载"任意复杂业务逻辑"的地方。换句话说,工业界早就在用"代码 + 函数"来装复杂逻辑了,这不是什么新发明。我还顺手把另一个想当然改掉了:跨多个对象的逻辑,按 DDD 的本意根本不该塞进聚合根(聚合之间不能互相伸手),那是领域服务该干的事。
这一轮下来,我有点泄气:如果 OWL 2 和 SHACL 都能表达,那我折腾半天到底图什么?
三、能表达,不等于适合给大模型用
但那个让我不舒服的感觉一直没消。我逼着自己想:既然表达力没问题,那我到底在不满什么?
想清楚之后我有点豁然开朗——问题根本不在"能不能表达",而在"这套定义最终是给谁看、给谁用的"。
OWL 也好、SHACL 也好,它们的语法是为推理机和校验器优化的:DL 公理、Turtle 里的 shape graph,都是给机器执行的形式化产物。可我真正想做的,是把本体喂给大语言模型,让它来理解和使用。这是两个完全不同的消费者。一堆密密麻麻的 OWL 公理,对一个"把上下文读进去、靠语义理解来推理"的概率模型来说,既不好读,也不是它擅长的形态。再加上形式化本体编写门槛高、要专门的知识工程师、演进还慢——这些在"给推理机用"的年代是值得的代价,但在"给大模型用"的场景下就成了纯负担。
还有一点是我后来才想透的:"完备"这个词,在两个语境下含义不一样。 推理机要的完备是逻辑上可判定、闭合;而大模型要的"完备",其实是语义清晰、覆盖充分、消歧到位——是另一回事。我一直拿前者的尺子去量后者,难怪怎么量都别扭。
后来我发现,这个判断和学界正在发生的一个转向是吻合的:知识工程的重心,正从"用大模型去做本体工程",转向"为大模型服务的本体";在这个新阶段,大家更看重事实覆盖、可扩展、好维护,而不再死磕逻辑上的语义完备性。这给了我信心——我那个模糊的不满,方向是对的。
至此,我的出发点彻底变了:我要批的不是 OWL 的能力,而是"形式化本体作为大模型的语义载体"这件事本身的错位。
四、于是我的主张成形了:本体定义,大模型推理
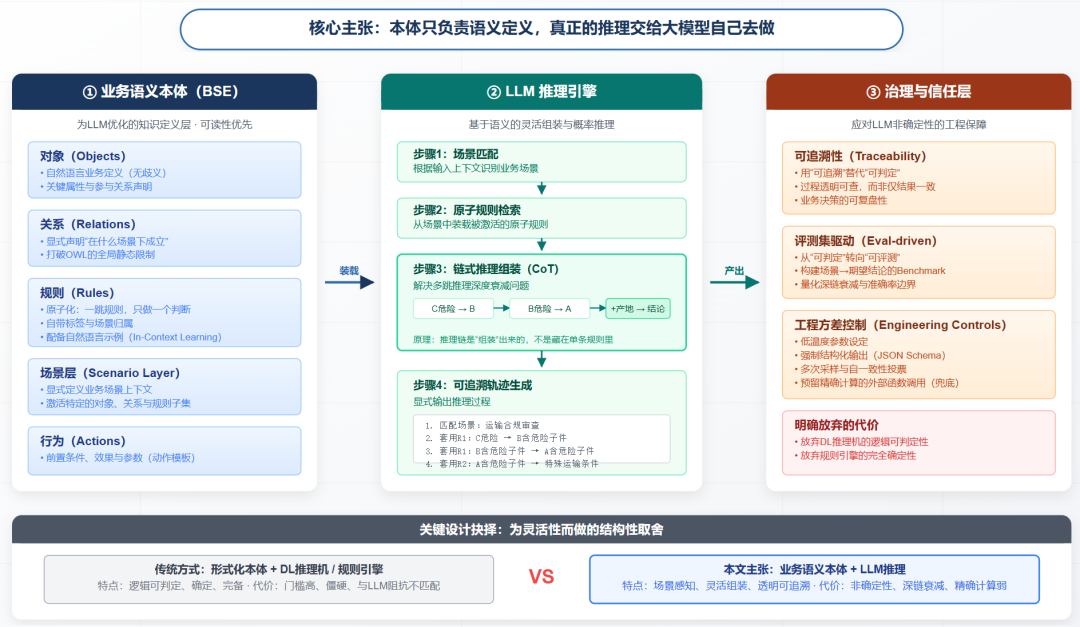
把这层窗户纸捅破之后,方法的轮廓一下子清楚了。核心就一句话——分工:
- 本体只管"定义":用清晰、无歧义、带业务语义的方式,说清楚有哪些对象、它们在什么场景下有什么关系、能发生哪些行为、规则是什么。
- 大模型负责"推理":面对一个具体情境时,由它去匹配场景、挑出相关的对象/关系/规则、把它们灵活组装成推理链、套用、给出结论。
而且我想明确一件事,这是我主动做的、也是我最坚持的取舍:我不要 DL 推理机,也不要规则引擎,我要用的就是大模型自己的推理能力。 我很清楚这意味着放弃确定性——同样的输入,大模型可能给出不完全一样的过程甚至结果。有人会觉得这是致命伤。但我想要的恰恰是那种"按场景灵活组装规则"的能力,这是任何确定性引擎都给不了的;为了这个能力,我愿意接受非确定性,再用别的办法把它的风险压住。
这个选择带来两个我必须认下的后果:
一是评判标准从"可判定"变成了"可评测"。 既然不再有逻辑保证,那"本体好不好"就不能靠逻辑一致性来证明了,只能靠经验——靠一套"场景 → 期望结论"的评测集,看大模型在我关心的那些场景上表现稳不稳。所以从一开始,我就把这套评测集当成一等公民,而不是事后补丁。没有它,"完整业务语义"就是句空话。
二是用"可追溯"替代"可判定"。 结论不确定,那我就要求大模型把推理过程显式吐出来:它匹配了哪个场景、激活了哪几条规则、按什么顺序套、每步的中间结论是什么。这样哪怕结果有波动,整个过程也是看得见、查得到、能复盘的。对真实业务来说,"我能看清它为什么这么判",往往比"它每次都一模一样"更实在。这也是我这套东西相对于"把规则一股脑塞进 prompt 让大模型自由发挥"的关键区别——结构化的规则定义 + 显式的套用轨迹。
五、本体该怎么改造才能让大模型推得动
光有主张不够。我得正视大模型推理的几个真实弱点,并且让本体的结构主动替它减负。这不是回避缺点,而是顺着它的脾气来设计。
它的第一个弱点是多跳推理会随深度衰减。 一两跳很稳,链一长一宽就开始丢条件。我前面那个 A→B→C 的危险品例子就是典型的深链。我的对策是把规则写得原子、局部:一条规则只管一跳、只做一个最小判断;复合的效果,由大模型把多条原子规则一条条串起来产生。也就是说——推理链是"组装"出来的,不是藏在单条规则里的。
它的第二个弱点是精确和大规模的计算。 "交易双方国家不同"这种小比较它能做;但"对上千个 SKU 逐个核对库存够不够"这种精确批量判定,它容易算错或偷懒。在坚持"推理归大模型"的前提下,我能做的是把规则写得便于它拆成可逐条核对的小步骤,并在场景层限制每次只面对一小批数据。至于要不要破例为单点精确计算保留一次外部调用——这一步会偏离"纯大模型"的初衷,我把它留作一个待权衡的开放问题,放到后面。
它的第三个弱点是同一情境多次结果不一致。 这是概率推理的天性。工程上我用低温度、强制结构化输出、必要时多次采样投票来压方差。接受不确定,但不放任它。
至于本体里每一类元素到底要"装"什么,我的原则是:每个元素都要带上让大模型不用猜的信息。
- 对象:除了属性,必须有一句自然语言定义,还要说清它参与哪些关系。大模型是靠语义推理的,"定义写清楚"比"形式正确"重要得多。
- 关系:除了类型和方向,关键是带上**"在什么场景下成立"**。说到这儿我有个挺得意的领悟——我当初那个"场景化关系"的直觉其实没错,只是放错了地方:在给推理机的本体里,"此关系仅当设备在线时有效"非常难表达;可在给大模型的本体里,这就是一句它能直接读懂、并据以取舍的大白话。同一个想法,换了消费者,从累赘变成了优势。
- 行为:声明前置条件、效果、参数,自然语言和结构化都写。它是大模型要套用的动作模板。
- 规则:写成显式的"条件 → 结果",并且满足三条——原子(只管一跳)、带标签(属于哪个场景、引用了哪些对象和关系)、自带一个解好的示例。大模型套规则的可靠性,主要就靠这三样撑起来。
- 场景层:这是我觉得最有价值、传统本体里压根没有的一层。我显式地定义"场景",并声明每个场景下哪些对象、关系、规则是被激活的。大模型拿到一个具体情境,先匹配到场景,再从这层取出被激活的那一小片去推理。所谓"灵活组装",根本不是让大模型凭空发挥,而是我在场景层里预先布好的可组合性。 模块化、能按场景检索、带激活条件——这三条决定了它是"灵活组装"还是"乱抓一气"。
六、供应链危险品运输的一个片段
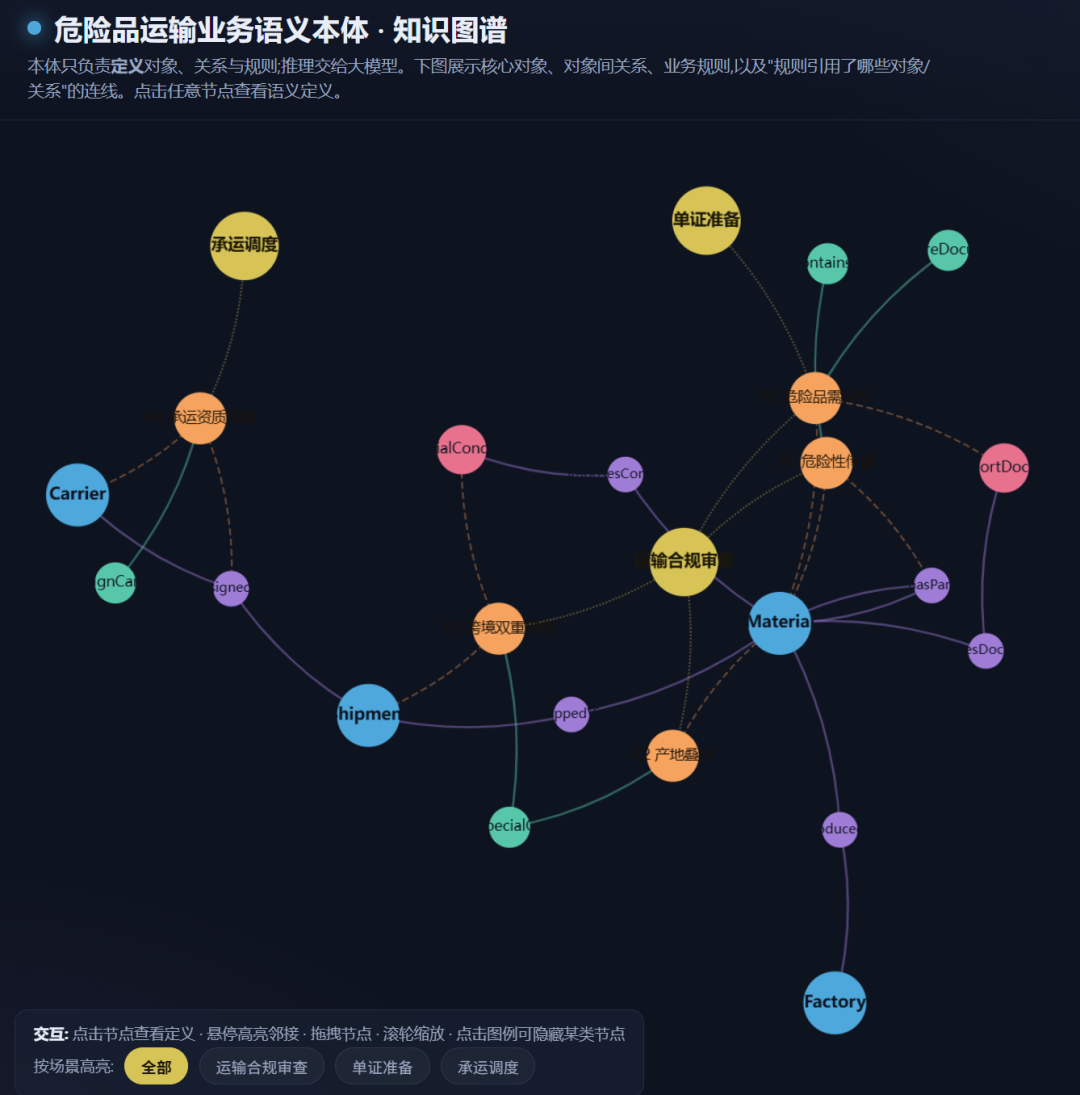
光说不练没意思,我用那个危险品的例子,写一份面向大模型阅读的本体片段。注意它故意没用 Turtle 或 OWL,而是用一种可读的结构化形式,每个元素都带着大白话定义。
objects:
Material:
定义:"可被生产、组装或运输的物料,可包含子物料。"
属性:[id,name,origin_country,is_hazardous]
参与关系:[hasPart,producedIn]
Factory:
定义:"生产物料的工厂实体。"
属性:[id,name,country]
relations:
hasPart:
定义:"物料A在其物料清单中直接包含物料B。"
方向:Material->Material
场景条件:"始终成立(结构性关系)。"
producedIn:
定义:"物料由某工厂生产。"
方向:Material->Factory
场景条件:"始终成立。"
rules:
R1_危险性传递:
场景标签:[运输合规审查]
条件:"物料X通过hasPart直接包含物料Y,且Y被视为危险(is_hazardous为真,或Y已被标记为'含危险子件')。"
结果:"标记X为'含危险子件'。"
引用:[hasPart,Material.is_hazardous]
示例:"成品A直接包含零件C,C为危险品 → A被标记为'含危险子件'。"
R2_产地叠加触发:
场景标签:[运输合规审查]
条件:"物料X被标记为'含危险子件',且X.origin_country为'中国'。"
结果:"对X施加'特殊运输条件:危险品出境申报'。"
引用:[Material.origin_country]
示例:"A含危险子件且产地为中国 → A需危险品出境申报。"
scenarios:
运输合规审查:
定义:"在物料出库运输前,判断其是否需要特殊运输条件。"
激活对象:[Material,Factory]
激活关系:[hasPart,producedIn]
激活规则:[R1_危险性传递,R2_产地叠加触发]
注意我把规则拆成了两条原子规则:R1 只管"危险性沿一跳传递",R2 只管"产地叠加"。当层级是 A→B→C 时,大模型靠反复套用 R1(C 危险 → B 含危险子件 → A 含危险子件),再套 R2,得出最终结论。多跳的效果是组装出来的,没有硬编码在任何一条规则里。
我期望大模型吐出的推理轨迹,大致是这样的:
场景匹配: 运输合规审查
已知事实: A hasPart B; B hasPart C; C.is_hazardous=true; A.origin_country=中国
套用 R1: C 危险 → 标记 B 为"含危险子件"
套用 R1: B 含危险子件 → 标记 A 为"含危险子件"
套用 R2: A 含危险子件 且 A 产地=中国 → A 需危险品出境申报
结论: A 需施加"特殊运输条件:危险品出境申报"
这份片段里没有一条 OWL 公理,也没有任何规则引擎;它只是把语义说清楚,推理整个由大模型完成,而且过程透明、可查。这就是我想要的样子。
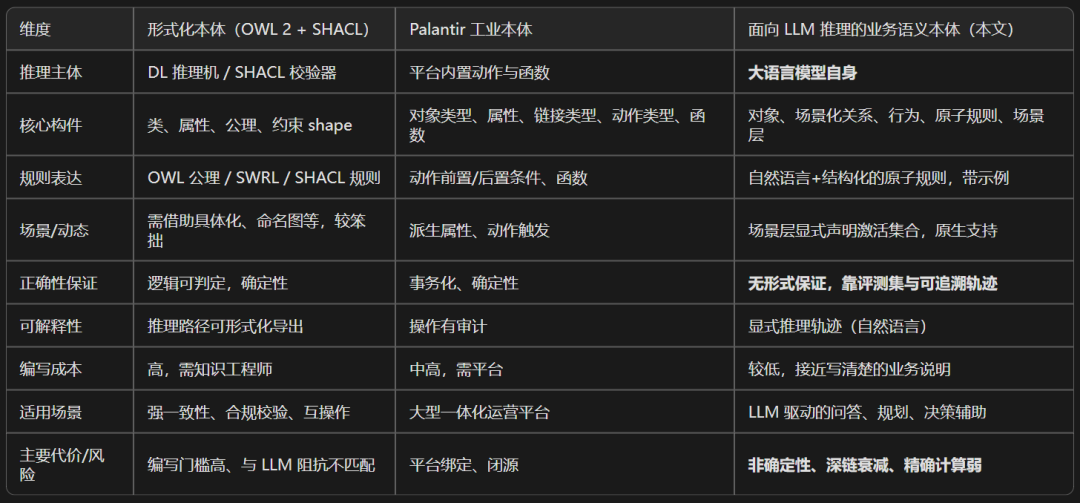
顺便和我绕过的两条老路放在一起对照一下:
维度 | 形式化本体(OWL 2 + SHACL) | Palantir 工业本体 | 我主张的:面向大模型推理的本体 |
|---|---|---|---|
谁来推理 | DL 推理机 / SHACL 校验器 | 平台内置动作与函数 | 大模型自身 |
核心构件 | 类、公理、约束 shape | 对象/属性/链接类型/动作类型/函数 | 对象、场景化关系、行为、原子规则、场景层 |
规则形态 | 公理 / SWRL / SHACL 规则 | 动作条件、函数代码 | 自然语言+结构化的原子规则,带示例 |
正确性 | 逻辑可判定、确定 | 事务化、确定 | 无形式保证,靠评测集 + 可追溯轨迹 |
编写成本 | 高,要知识工程师 | 中高,绑平台 | 较低,接近写清楚的业务说明 |
主要代价 | 门槛高、与大模型阻抗不匹配 | 平台绑定、闭源 | 非确定性、深链衰减、精确计算弱 |
我很清楚最后一列的代价是真实的,所以我才把"评测"和"可追溯"看得那么重——那是我换来灵活性之后,唯一能抓住的两根绳子。
七、待进一步解决的新问题
把主张立住之后,我没有轻松,反而看见了一批新的、之前那套形式化方法里不存在的问题。它们都是"演进到大模型推理"这个选择自己带出来的,老老实实列在这里,因为它们还没被验证,是我接下来真正要去做实验、去试错的地方:
- 深链衰减的边界到底在哪。 原子规则 + 组装,在多深的层级、多宽的规则集下还稳?这个衰减曲线得用分层级、分规模的评测集真刀真枪测出来,不能靠感觉。
- 精确和大规模约束怎么办。 纯大模型做批量精算,会不会成为准确率的瓶颈?要不要、以及在多大程度上破例引入一次外部计算来兜底——这一破例就偏离了"纯大模型"的初衷,是我现在最纠结、还没想清楚的地方。
- 场景层会不会自己变成新的复杂度。 场景从几个涨到成百上千时,"先匹配场景再激活子集"还可靠吗?会不会到某个规模,连"匹配场景"这一步本身都得引入检索(类似 GraphRAG 那种做法)?我原本是想用场景层降复杂度的,结果它可能在大规模下带来新的复杂度。
- 上下文塞不下怎么办。 大本体不可能整个丢进上下文,得按场景做检索式装载。可检索粒度多大合适、检索错了会不会直接把推理带偏,都还没底。
- 方差到底能压到什么水平。 低温度、结构化输出、自一致性投票,在业务关键场景下能把不一致压到可接受的程度吗?这个得量化,不能只说"会好一些"。
- "完整"怎么变成可测量的东西。 我嘴上说的"覆盖充分、消歧到位",得落成一套可测的判据,还得建一个能复现的 benchmark,否则"完整业务语义"永远是个无法证伪的口号。
- 本体和现实会不会越走越远。 自然语言定义写着舒服,但它会随业务演进而漂移。怎么保证本体里的描述始终和真实业务对得上,是个工程治理问题,不是技术一招能解决的。
- 我的真实增量到底比别人多在哪。 GraphRAG、ontology-grounded 的抽取、神经符号的企业知识图谱,都已经在"本体 + 大模型"这条线上了。我得拿实证去和它们比,老实说清楚我这套的边界和真正多出来的那点东西,否则容易是重复造轮子。
八、写在最后
回头看,我这一圈绕得值得。我的出发点"OWL 装不下规则"其实是错的——OWL 2 和 SHACL 早就把表达力补上了;但我那股不满又是对的,只是我一开始没说对原因:症结不在能不能表达,而在这套形式化定义压根不是为大模型这个新消费者准备的。
所以我最终的主张,既不是抛弃 OWL,也不是再造一个更强的逻辑系统,而是承认它的边界、更承认它在大模型时代的载体错位,然后为大模型重做一套"够用、好读、可按场景组装"的业务语义定义,把推理这件事,干脆利落地交还给大模型自己。
我也很清楚,这目前还只是个主张。它能不能立住,不取决于它逻辑上多漂亮,而取决于上面那八个问题里,我能用评测和真实落地回答掉几个。这是我接下来要做的事。
参考与延伸
- W3C: RDF 1.1(2014)、OWL 2 Web Ontology Language(2009)、*Shapes Constraint Language (SHACL)*(2017)——形式化本体与约束的标准。
- Palantir Foundry Ontology 官方文档:对象类型、属性、链接类型、动作类型、函数等核心构件。
- Eric Evans, Domain-Driven Design(2003)——领域事件、领域服务、聚合等概念来源。
- "LLM-empowered Knowledge Graph Construction: A Survey"(arXiv:2510.20345)——论及从"用 LLM 做本体工程"到"为 LLM 服务的本体与知识图谱"的重心转移。
- Microsoft GraphRAG(2024,开源)——基于图结构的检索增强生成,可作场景化检索装载的参考。
- "Grounding LLM Reasoning with Knowledge Graphs"(arXiv:2502.13247)——将思维链等推理策略与知识图谱检索结合的工作。
说明:本文为作者的思考记录与方法主张,参考文献用于定位相关技术脉络,不代表这些来源对本文结论背书。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号