解密 AI 大模型训练背后的 RoCE 智算网络架构
原创
解密 AI 大模型训练背后的 RoCE 智算网络架构
原创
星融元Asterfusion
修改于 2026-06-09 10:31:26
修改于 2026-06-09 10:31:26
大模型时代:为什么GPU训练离不开高效的AI智算网络?
从“连接服务器”到“决定算力效率”的角色转变
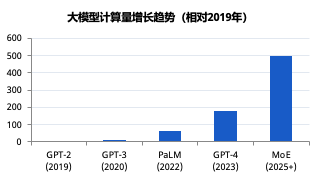
在大模型时代,AI智算网络(AI Computing Network)的角色发生了颠覆性的变化。过去在传统数据中心,网络的核心功能仅仅是将服务器连接起来。然而,在百亿、千亿甚至万亿参数大模型涌现的今天,网络已经直接决定了GPU的利用率和模型的训练效率。
在AI集群中,GPU服务器是最昂贵的硬件资源,但在实际训练中,由于数据同步频繁,GPU往往不是在等待计算,而是在等待网络传输。统计数据显示,网络通信虽然仅占AI集群部署成本的8%~10%,但它却决定了高达90%的GPU训练效率 。一旦网络发生拥塞,昂贵的GPU就会陷入空转状态,造成惊人的集群算力浪费。
AI训练的核心挑战:高带宽、低时延与抗干扰
AI大模型训练本质上属于网络密集型负载,GPU之间需要进行高频的信息同步,最典型的通信模式是All-Reduce/All-Gather(所有GPU互相交换并统一同步计算结果)。这是一个典型的“木桶模型”:只要有一条链路变慢或一个GPU延迟,整个集群都必须停下来等待。因此,AI智算网络面临着三大核心挑战:
- 高带宽:随着万卡、十万卡集群的普及,网络需要承载海量数据吞吐。
- 低时延:减少报文在网络中的抖动与等待时间。
- 抗干扰(无损):训练流量的熵值极低,规律性强,一旦发生拥塞丢包,重传开销将严重拖慢训练节奏。
解构智算中心:解密四大网络平面与流量模型
四大网络平面的协同与隔离
为了避免不同类型的业务流量相互干扰,一个标准的AI智算数据中心通常会划分为四个独立的网络平面:
网络平面 | 核心职责 | 特性要求 |
|---|---|---|
计算网 | 负责GPU之间高性能的同步通信,是集群最核心的网络。 | 必须无损、低时延。 |
存储后端网 | 负责从存储服务器加载数据集,为训练提供源源不断的数据“材料”。 | 必须无损、高吞吐、能处理Incast流量。 |
前端业务网 | 负责用户访问、API调用或推理服务的租用。 | 允许有损,强调Overlay多租户与灵活管理。 |
带外管理网 | 提供设备管理与故障时的Backup(备用)管理手段。 | 基础管理要求,不参与业务流量。 |
其中,计算网和存储网作为算力底座,必须满足无损网络的要求,并通过物理隔离避免受到普通业务流量的冲击 。
传统数据中心流量 vs AI智算网络流量
传统数据中心网络主要处理南北向流量(用户到服务器),数据包较小且呈现随机性。此时,网络设计允许2:1甚至更高的超配收敛比。
相反,AI智算网络则是典型的东西向流量(服务器之间)。它表现为持续时间长、吞吐量巨大的“大象流”(Elephant Flow)。在这种流量模型下,传统网络常用的五元组哈希(Hash)和ECMP(等价多路径路由)极易导致链路负载不均和哈希极化。因此,智算网络采用1:1的无收敛设计。
拓扑设计:如何打造“无阻塞”与“轨道化”的网络架构?
1:1收敛比与无阻塞设计
在设计计算网络时,“无阻塞”是第一原则 。这意味着Leaf层设备的上行带宽与下行带宽必须严格对等(1:1)。网络拓扑不能因为设计本身的缺陷,而在网络内部引入任何潜在的拥塞节点。
轨道化(Rail-Only)与轨道优化(Rail-Optimized)架构
为了最大化跨节点通信效率,业界引入了大模型训练策略(LLM并行动作),通过数据并行、张量并行和流水线并行,让大部分通信集中在节点内(利用高速NVLink通道)或同轨道内。 因此,形成了两种主流的组网架构:
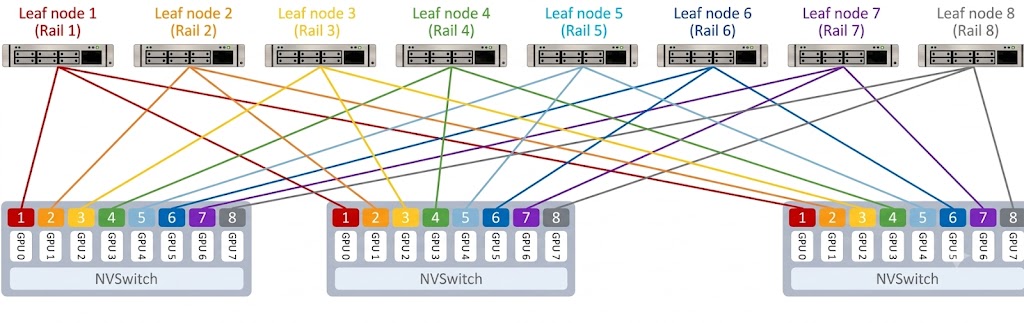
1、轨道化架构(Rail-Only)
将相同编号的网卡连接到相同的Leaf交换机上。例如,所有GPU服务器的1号网卡均连至Leaf1,2号网卡连至Leaf2。同号网卡通信只需在单台Leaf交换机内实现“单跳直达”,物理上完全隔离跨轨流量。这种单层组网没有Spine层,硬件与光模块成本相对较低,能最大程度减少拥塞扩散,非常适合32卡到1024卡的中小规模集群。
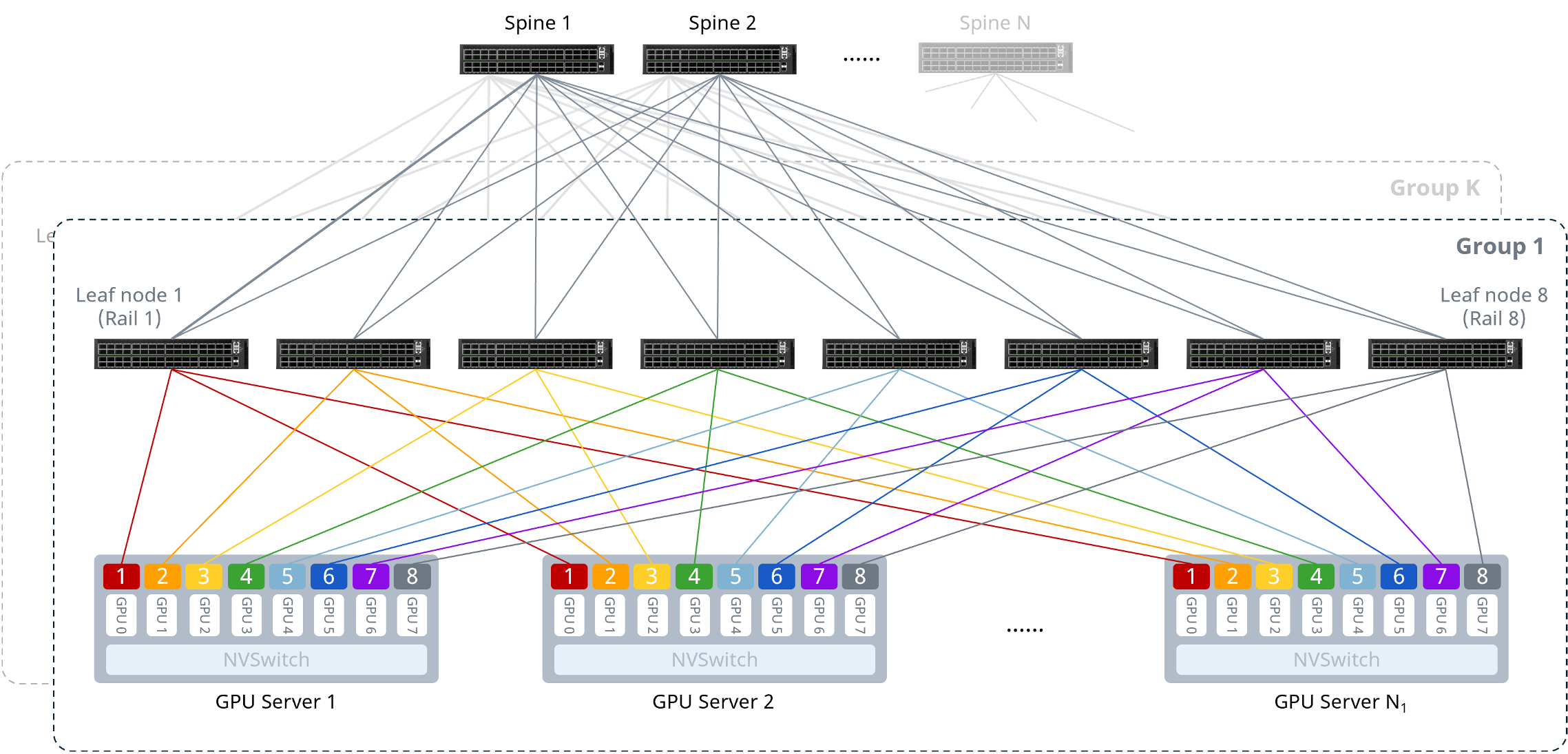
2、轨道优化架构(Rail-Optimized):
为了支持万卡以上的超大规模集群,通过引入Spine层,将多台Leaf交换机和服务器组合成一个“Group”单元,并进行水平堆叠扩展。流量默认优先走本轨道,在需要跨轨通信时允许通过Leaf-Spine-Leaf进行多跳转发。虽然这带来了微小的时延不确定性,但其在扩展性、资源利用率和整体规模之间取得了较好的平衡,是当前构建超大规模集群时更倾向采用的横向扩展方案。
智算网络核心技术深度剖析
无损传输的基石:PFC与ECN的协同逻辑
由于RoCEv2 (RDMA over Converged Ethernet) 基于无连接的UDP协议,无法像TCP那样自我控制拥塞。因此,无损智算网络必须依赖端到端的拥塞控制机制:PFC(基于优先级的流控)和ECN(显式拥塞通知)。
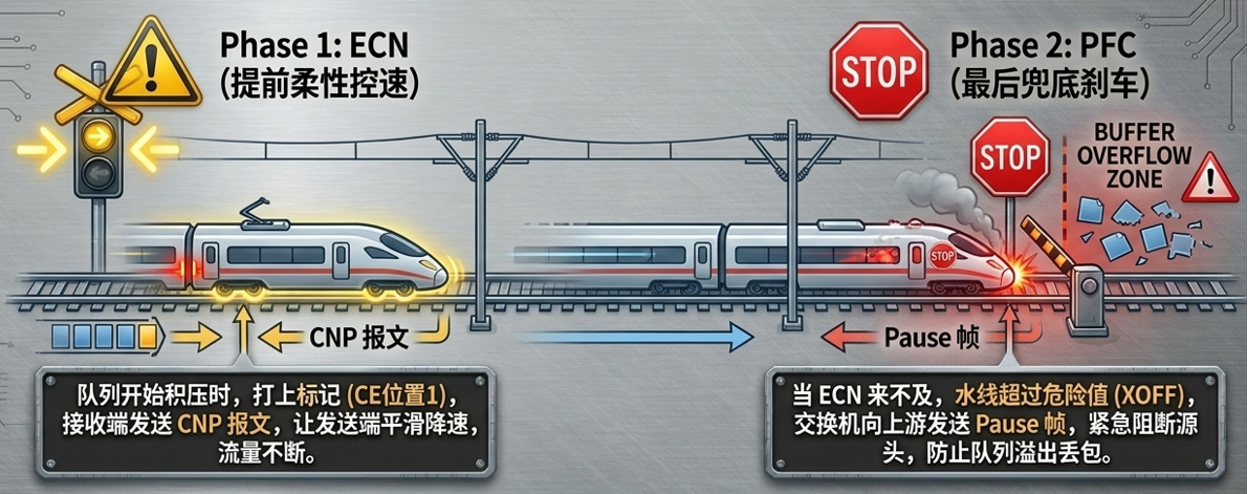
在实际运行(如DCTQCN算法协同)中,两者的触发逻辑有着严格的先后顺序:
- ECN(柔性控速,拥塞避免):当交换机队列达到初期阈值时,标记报文并通知发送端平缓减速,从源头上化解拥塞。
- PFC(刚性刹车,最后兜底):若拥塞持续加剧,ECN无法控制时,交换机向反向触发PFC,直接阻断上游流量以防止队列溢出丢包。
传统网络中PFC与ECN的参数调优极其复杂。目前,行业内的一些优化方案支持在交换机上通过简化的命令,针对不同RoCE场景自动调优参数,从而大幅提升智算网络的工程易用性。
突破哈希极化:自适应路由(ARS)与负载均衡
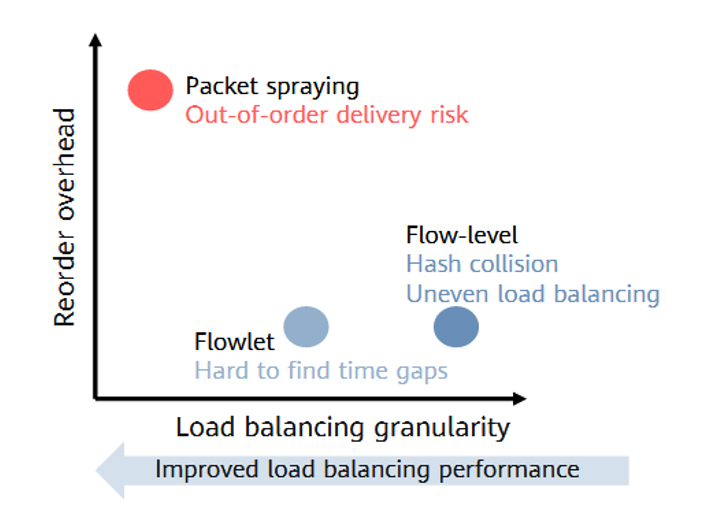
针对大象流引起的链路不均问题,负载均衡技术的粒度决定了网络的高效性:
- 逐流(ECMP):无乱序,但面对AI大象流极易发生哈希极化与链路拥塞。
- 逐包(Packet Spray/包喷洒):链路利用率最高,但会引入严重的报文乱序,极端依赖网卡侧的硬件重组能力,且目前需要复杂的端到端效果验证。
- 逐子流(Flowlet 自适应路由): 它基于感知端口带宽利用率和队列深度的动态路由技术,感知端口带宽利用率和队列深度,动态将流量切分成小段并分配到空闲链路上。它在保持近乎逐包高均衡率的同时,通过合理配置静默时间(Age Time)有效避免乱序。
从理论到落地:典型规模部署参考与工程实践
1、400G/800G网络设备选型速查
在构建高吞吐AI集群时,网络设备的密度与端口速率是核心。以下为基于行业主流机型的部署速查指南 :
- 超高带宽旗舰机型:支持64个800G端口或128个400G端口,是目前高吞吐智算网络的核心机型。
- 高密度汇聚机型:适合作为单层架构的Leaf或中小规模集群的骨干节点。
2、万卡级(8K GPU)集群部署示例与关键配置
以使用高密度800G核心交换机与配备8张网卡的服务器对接,构建8192卡GPU的两层Clos架构为例:
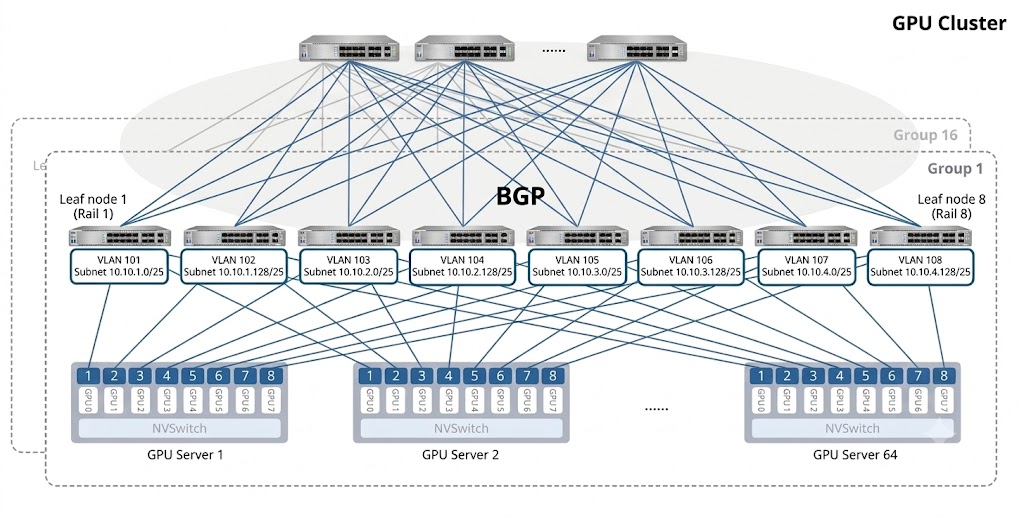
每台服务器拥有8张网卡,一个Group内包含8台Leaf交换机。采用1:1无阻塞设计,单台Leaf向上连接一定数量端口至Spine,向下连接相应端口至服务器。单个Group可接入多台服务器。通过横向水平堆叠多个Group,即可构建大规模的算力集群。
工程落地三大关键配置
- BGP Unnumbered(去IP化邻居建立):在千条链路的超大规模集群中,人工规划和配置IP极易出错。通过启用BGP Unnumbered技术,设备直接利用IPv6 Link-Local地址在物理接口上建立BGP邻居并宣告路由,省去了繁琐的人工IP规划与排错动作。
- 哈希种子(Hash Seed)差异化配置:由于Leaf层和Spine层可能使用相同型号的交换芯片,为了防止流量在第二层转发时发生二次哈希极化,必须在Spine层配置不同的哈希种子(Seed),从而改变哈希算法的随机扰动,使流量重新均匀散列。
- 无损网络级联部署: 依托自动化策略平台统一下发端到端的拥塞控制参数,并结合自适应路由机制,确保大象流在多跳路由中不乱序、不丢包。
构建面向未来的AI算力底座
在大模型技术快速发展的当下,AI智算网络已成为释放GPU算力的关键。无论是侧重于高性价比和低延迟的单层轨道化架构 (Rail-Only),还是侧重于超大规模扩展性的轨道优化架构 (Rail-Optimized),构建一个具备无损传输和智能负载均衡能力的网络,都是支撑万卡级AI集群稳定高效运行的技术基石。通过合理规划网络平面,应用前沿的工程化技术,充分发挥庞大算力集群的潜能。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号