IM分布式架构系列(15)切换设备后消息怎么补 | 多端同步机制
原创
IM分布式架构系列(15)切换设备后消息怎么补 | 多端同步机制
原创
拉丁解牛说技术
发布于 2026-06-14 15:33:15
发布于 2026-06-14 15:33:15
为什么互联网信息,没有记忆?
回想2026年初至今半年,年初xx、xx的大行情,经历一天一地,现在还有几个人能记得住?
CCTV AI视频流金谷恩仇录,说的波斯猫和白头鹰的矛盾,持续影响国际贸易业务,几家欢喜几家愁?
刷了一年信息,真正留在脑子里的可能就那么几句话、几个道理,以及认真看过的几篇文章,并对自己的生活、工作产生影响的东西。留下来的从来不是信息本身,是被你"用过、想过、跟自己接上线"的那一点——你的认知。
一、多端同步这件事
二、多端同步的三套机制
三、大厂的设计
四、如何优化提升
一、多端同步这件事
在IM实践过程中,消息的多端同步是非常实用的功能。To C/B 业务基本都是标配功能。但是当测试给你反馈:手机上聊得好好的群,切到电脑端打开,最后五条没了;过一会儿手机又把这五条标成未读——明明手机已经读过。 甚至用户换了手机后,发现:换了新手机登录后会话列表是全的,但点进某个群发现最近的对话空了一截,得滚屏往上拉才补回来。
这些现象暴露的问题都是一个:多端同步没对齐。
这个多端同步背后的用户述求,其实就是:"在手机发的、在电脑要立刻看到""换了新设备历史能接上""一个端读过另一个端别再红点",不过要做好这件事,在架构上也需要下一些功夫。
在的IM里,多端同步还需要支持"互踢",一个账号只能一个端在线,并且让两个端看到一致的消息和一致的状态。今天我们讲讲:一条消息怎么同时到所有端、换端后新端怎么补齐、已读和会话状态怎么跨端同步。
1.1 多端同步的 IM 链路
多端同步的本质,是把"一个用户"从"一个收件人"拆成"一组并存的收件端",让发往这个用户的消息和状态变更在每个端上都独立、可靠、不重不漏地落地。它处在消息路由完成之后、投递到每个具体连接之前那一层。
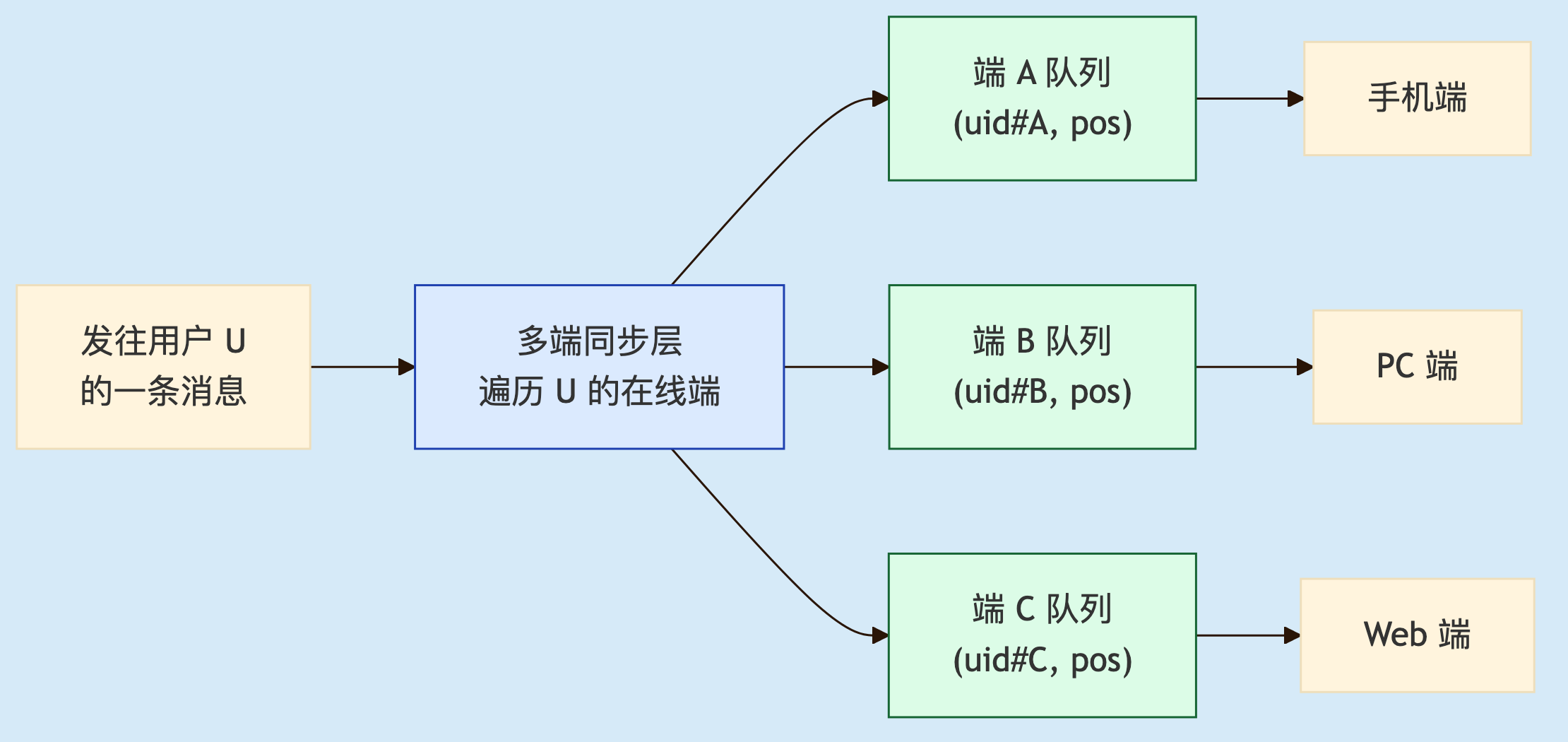
一条发给用户 U 的消息,被同步层复制成"每端一份",写入各端独立的队列,各端按自己的进度消费。
这里的核心在于:用户自己发出的消息,也要扩散回自己的其他端。你在手机发了一句话,PC 端同一会话也得立刻显示——否则切到 PC 会觉得消息"丢了"。
1.2 它和"补离线消息"不是同一个问题
日常我们很容易把多端漫游和离线消息补偿混为一谈,两者都在"补消息",但解决的是不同的事:
- 离线消息补偿,负责"单个端从离线到上线、把堆积消息补回来",核心是存储模型(怎么存、切片、过期回收);
- 多端漫游,处理的是"同一用户的多个端之间怎么保持一致",核心是扩散与位点(一份消息扩散成几份、每端读到哪了、状态怎么传到兄弟端)。
一个是时间维度的补偿,一个是设备维度的一致。
二、多端同步的三套机制
多端漫游实际是三套互相独立又彼此依赖的机制:
- 消息漫游(一条消息怎么到所有端);
- 状态漫游(已读 / 置顶 / 隐藏怎么在端间同步);
- 新端登录漫游(换设备后怎么补齐)。
2.1 多端漫游核心目标设计
做到多端一致,从产品体验和技术架构上至少要达到几个目标:
- 端间一致:同一会话在每个端看到的消息集合和顺序最终一致。某端读过的,其他端不该再亮红点(允许短暂延迟,但要收敛)。
- 进度隔离:某端拉慢了、掉线了,不拖累其他端;每端按自己节奏消费,互不阻塞。
- 不重不漏:一条消息在每个端上恰好出现一次;重连、崩溃重启不能让某端漏一条或重一条。
- 状态可传播:已读位点、会话的置顶 / 隐藏 / 免打扰这类变更要能从操作端传到其他端。
- 换端可对齐:新设备登录后能把"这个端从未拿过的消息和状态"补齐,而非从零拉全量。
2.2 机制一:消息扩散到端与每端独立队列
多端同步,要跨的第一道坎是"一条消息怎么变成每个端都能收到"。最朴素的想法是用户 U 一条消息流、所有端都从这条流读,但多个端共享一个读游标时,手机读到第 100 条把游标推到 100、PC 端再来就从 101 开始,前 100 条永远拿不到——共享一条流 + 一个游标,等于多端互相吞消息。主流做法:
方案 | 结构 | 优势 | 代价 |
|---|---|---|---|
共享流 + 每端游标 | 用户一条流,每端各记自己的 lastPos | 消息只存一份,省存储 | 流不能删——任一端没追平,整条流都要留;慢端拖住回收,甚至永不在线就无法回收; |
扩散到端 + 每端独立队列 | 给每个端各建一条队列 uid#端,各自独立 pos | 进度完全隔离,某端 ACK 只删自己队列 | 一条消息要写 N 份(N = 端数) |
我们更倾向第2种——扩散到端:同步层遍历 U 的在线端列表(端数通常 2~4 个),给每个端构建一份副本写入该端独立的队列,队列维度是 uid#端(如 uid#mobile、uid#pc、uid#web)。
on_message_to_user(uid, msg):
devices = list_devices(uid) // 该用户当前注册的端: [mobile, pc, web]
for dev in devices:
pos = next_pos(uid, dev)// 该端独立的单调递增序号
queue.append(key=f"{uid}#{dev}", pos, msg)//每端一条独立队列,各写各的 这个方案的好处是进度彻底隔离:手机端 ACK 了只删 uid#mobile 队列的条目,其余队列原封不动等自己的端来取——一致来自消息源(同一条 msg 扩散),隔离来自队列(每端各一条)。缺点和代价是写被放大: N个端就写 N 份,千人群消息再叠加这个 N, 消息扇出量是"群成员数 × 人均端数"。
2.3 为什么每端要独立位点
每端独立位点把这些拆开:每端一个单调递增 pos,存在轻量 KV 里,key 形如 sync:{uid}:{端}。各端拉取时报自己的 minPos / maxPos,服务端只返回该端 pos 之后的增量,响应带 nextPage 翻页。各端 ACK 各自推进,互不干扰。
比如用户消息pos已经是1281,以下不同端过来同步:
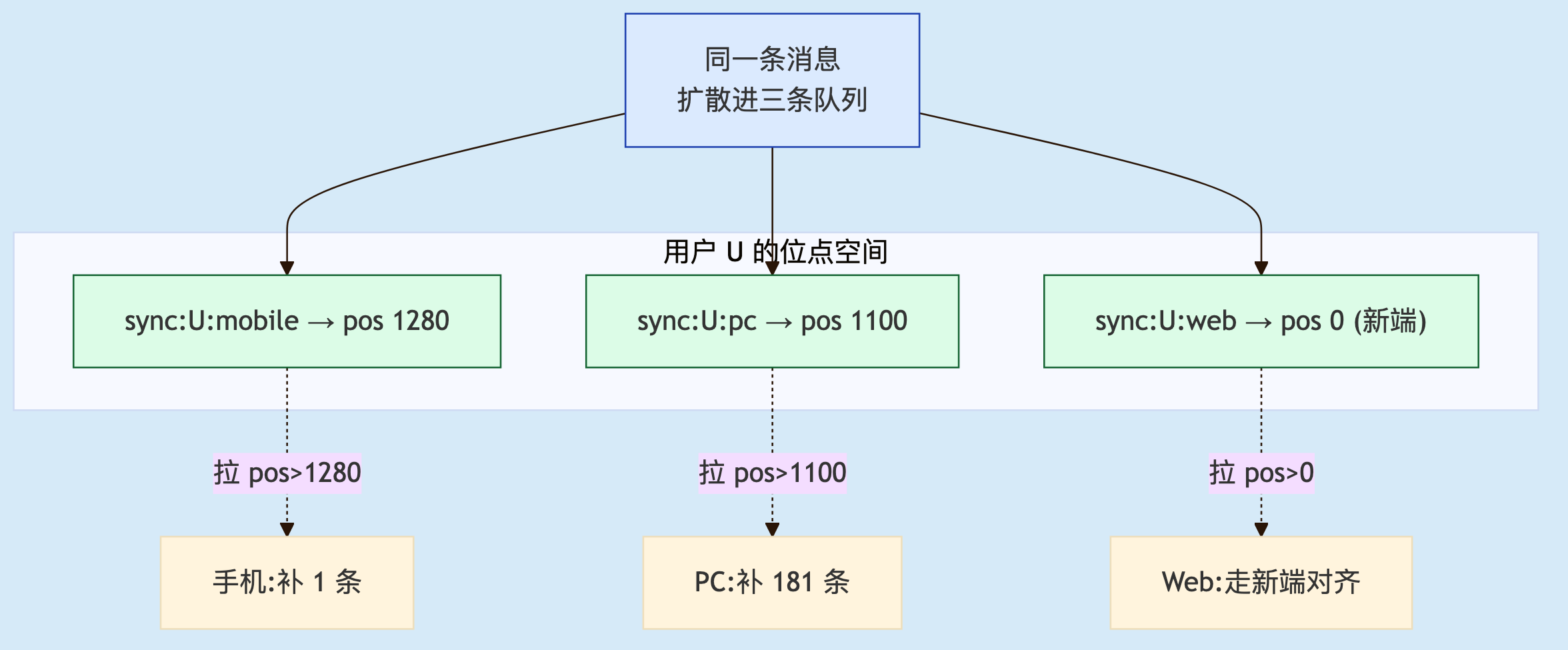
图 2. 每端独立位点。同一条消息进三条队列后,三个端基于各自 pos 拉到的增量量完全不同——手机补 1 条、PC 补 181 条、新 Web 端走新端对齐。
2.4 机制二:已读与会话状态的多端同步
消息扩散解决了"内容一致",还有一类东西要同步:状态——已读位点、置顶、隐藏、免打扰。用户期望它们也跨端一致:手机读了一个群,PC 端红点该灭;手机置顶某会话,PC 端也该排到顶。
已读多端同步:同一用户在自己不同端之间的已读位点对齐,不是群里 A 看没看到 B 那种群成员维度回执(那是另一套机制)。这里的焦点是"怎么把已读位点在端之间传播",要解决的是: U 在手机把会话 C 读到 50,怎么让 PC 端也知道。
推荐做法是把状态变更也当成要扩散到端的事件:用户在某端操作(已读、置顶、隐藏),操作端上报,由一个桥接服务异步同步到该用户的其他端:
on_state_change(uid, from_dev, change):// change: {type: READ, conv: C, readPos: 50}
apply_to_store(uid, change) // 先落库:该用户对会话 C 的已读推进到 50
for dev in list_devices(uid):
if dev != from_dev: // 关键:只发给"其他端",不回发操作端
sync_to_device(uid, dev, change, syncFlag=FROM_SYNC)已读位点还有个"只升不降"约束:多端并发上报不同位点(手机 50、PC 30)时服务端取 max,别让晚到的 30 把 50 覆盖回去。
2.5 状态同步的循环放大与方向标记
状态多端同步有个隐蔽的坑:循环放大。没有方向标记时——手机把"会话 C 已读到 50"同步给 PC,PC 收到后当成一次本端已读变更又触发同步,发回手机和 Web,手机收到再触发……一次操作在端之间无限回弹,轻则状态抖动,重则把同步通道打爆。
解法是给同步指令打方向标记。机制二伪代码里那个 syncFlag=FROM_SYNC 就是干这个的:其他端同步来的变更只在本端落地、不再二次外扩;只有用户在本端真实操作的变更才触发外扩。
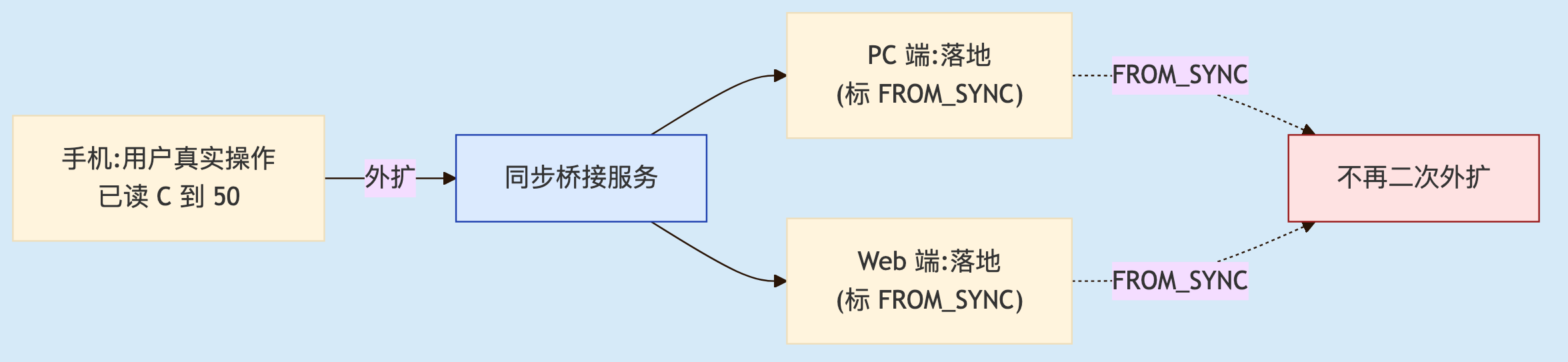
用方向标记切断循环同步。只有用户真实操作触发外扩,带 FROM_SYNC 的同步落地后到此为止;少了它,一次已读会在端间无限回弹
2.6 机制三:新端登录的增量对齐
前两套机制服务的是"已经在场的端"。还有一类场景:新设备第一次登录,或老设备卸载重装后重新登录——这个端的队列和位点要么不存在、要么从 0 开始,不能让它把几年的全量历史拉一遍。对齐分四步:注册连接、拉增量消息(只补保留窗口内、超窗口走历史漫游)、拉会话列表先铺界面、对齐已读位点:
on_new_device_login(uid, dev):
register_device(uid, dev) // 1. 进端列表,以后扩散带上它
init_pos = lookup_or_init(f"sync:{uid}:{dev}") // 起点位点,不是 0
msgs = pull_incremental(uid, dev, init_pos) // 2. 增量消息(保留窗口内)
convs = pull_conversation_list(uid) // 3. 会话列表(秒级,先铺界面)
read_marks = pull_read_positions(uid) // 4. 各会话已读位点,对齐红点
return assemble(msgs, convs, read_marks)要点是新端对齐补的是"这个端缺的进度",不是用户的全量数据——会话列表先到、界面立刻可用,增量消息和已读位点随后补,体验上是"会话秒开、内容渐进补全"。
2.7 多端漫游的端到端全景
三套机制串起来,一个用户(发送端 + 接收端 + 新登录端)的完整链路:
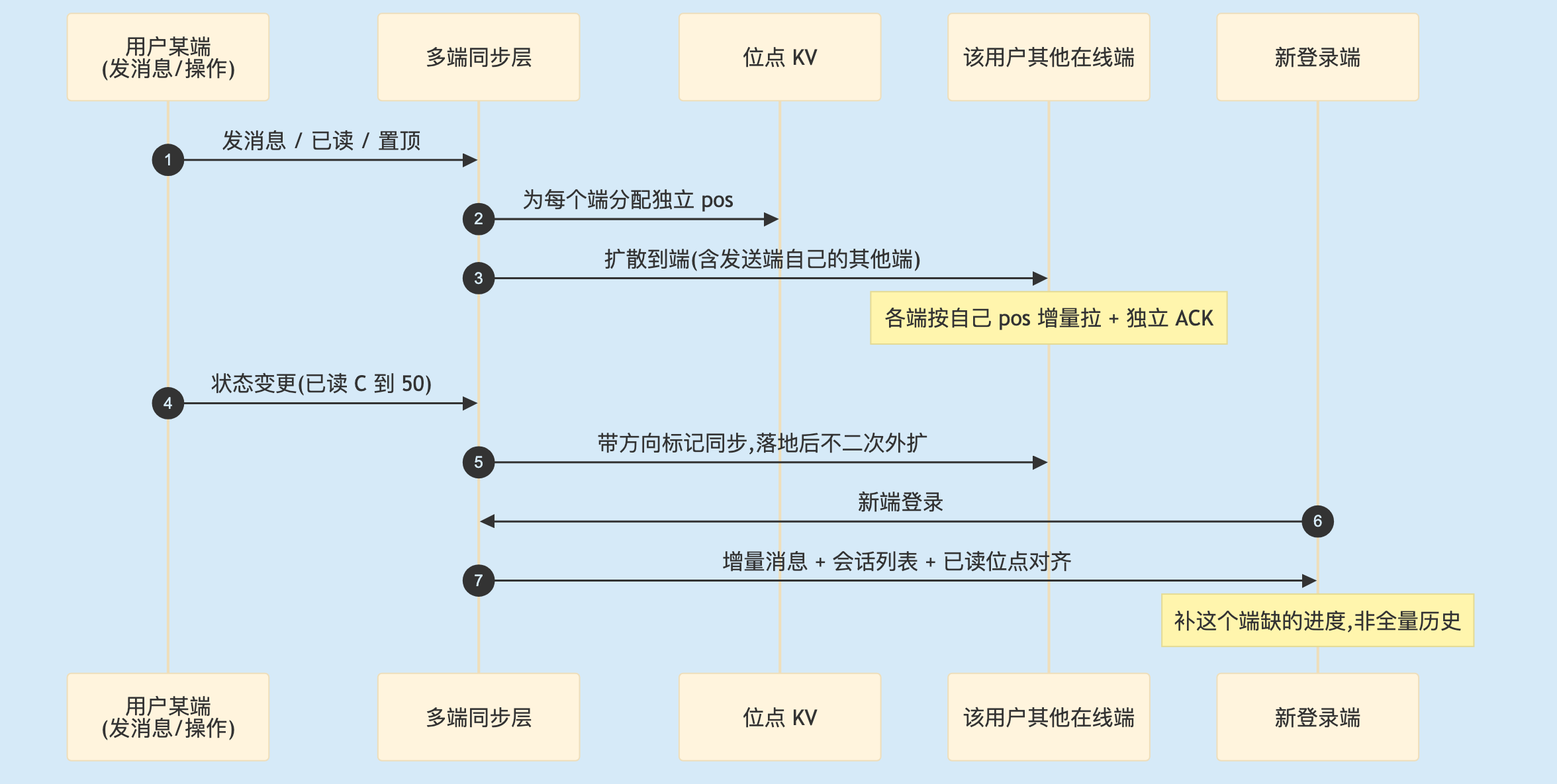
多端漫游端到端全景。消息扩散(每端独立队列与位点)、状态同步(带方向标记防循环)、新端对齐(补缺不补全)三套机制咬合。
三、大厂如何设计
多端增量同步这件事,公开分享里讲得最透、又最聚焦"同一用户多终端怎么对齐"的,是某信的序列号生成器 seqsvr——它不是离线消息系统,而是支撑多终端数据增量同步的底座。
3.1 某信用一个 seqsvr 扛住多终端增量同步
某信在立项之初就定了一个思路:用数据版本号实现终端与后台的增量同步。每一份需和客户端同步的数据(聊天消息、朋友圈通知、好友更新等)都被赋予一个唯一且递增的序列号 sequence,当作这份数据的版本号。
多终端同步就建立在这个版本号上:客户端同步时带上本端已同步到的最大版本号,后台拿它和服务端的最大版本号一比、算出增量返回——既可靠(不漏)又省冗余(只传增量)。换端、重连、崩溃重启逻辑都一样:报上这个端的最大版本号,我给你补差。
支撑这套同步的 seqsvr,按某信公开的算法原理篇有两个基本性质:sequence 是递增的 64 位整型,且每个用户都有独立的 64 位 sequence 空间——版本号按用户切开,用户 A 的 sequence 怎么涨都不影响 B 的。公开给的运行数据是:每天万亿级调用,平时申请耗时 1ms、99.9% 小于 3ms,部署在数百台 4 核服务器上。这是某信之前公开的数据,现在规模应该已发生变化。
那某信为什么不用全局一条 sequence?某信给的理由很直接:全局唯一的 sequence 会有严重的申请互斥问题,难以做出高性能高可靠的架构。每用户独立的 64 位空间已够业务用,还绕开了全局互斥。
3.2 每用户独立 sequence 空间的取舍
维度 | 详情 |
|---|---|
优势 | 用一个版本号统一驱动消息、状态、好友等所有需同步数据,客户端只需报最大版本号即可拉增量,协议极简; 每用户独立空间绕开全局互斥,单点申请轻量(1ms);天然支持多终端、断点续传、崩溃重启,逻辑统一 |
代价 | seqsvr 是一个必须高可用保活的独立重型系统(每天万亿级调用、数百台机器); 每用户独立 sequence 空间需要预分配中间层 + 持久化容灾配套,自建门槛高; 版本号一旦回退就会导致数据错乱、消息消失,对存储可靠性要求极苛刻。 |
我们要看到的是,某信这套是被"数亿活跃用户、每天万亿级调用"逼出来的。中等规模 toB IM 不需要独立 seqsvr 这种重器——一个 Redis 号段或轻量 KV 维护每端位点,量级匹配时反而更省。但"用单调递增版本号驱动多终端增量同步"这个核心思路倒是值得学习。
四、如何优化提升
4.1 扩散到端与单流多位点如何选择
判断标准我倾向看两个量:人均端数和消息写放大能不能扛。人均端数稳定在 2~4 个、单聊为主的 toB 场景,扩散到端的写放大可控、进度隔离很值,优先选它;
但是如果遇到万人群——群消息本身就扩散到每个成员,再乘人均端数会到难看的量级,这时单流多位点(消息只存一份、每端各记游标)更省。折中是混合: 单聊小群走扩散到端、超大群走单流多位点。
4.2 僵尸端的队列膨胀治理
扩散到端模型有个天敌:僵尸端。用户在某台公用电脑登录过一次再没回来,这个端的队列没人消费、位点永不推进、消息越堆越多,既占存储又拖累"是否所有端都已分发"的判定。
应对策略,我们有两个:活跃度淘汰——给每端记最后活跃时间,超过 N 天没拉过的从端列表摘掉、队列 TTL 回收;端数上限兜底——同一用户保留的端按 LRU 淘汰最老的,否则频繁在网吧 / 临时设备登录的用户会让队列数量失控。少任何一条,僵尸端都会慢慢把存储和判定逻辑拖垮。
4.3 状态同步的冲突与最终一致
状态多端同步在并发下会撞冲突——两端几乎同时操作同一会话,同步指令乱序到达结果可能不一致。对单调类状态(已读位点)用"只升不降"消解:服务端永远取 max、晚到的小值丢弃,天然幂等。对布尔 / 翻转类状态(置顶、隐藏、免打扰),得给每次变更带版本或时间戳后写覆盖,并约定时钟以服务端为准。要接受的现实是这类状态做的是最终一致——允许端间短暂不一致,只要能秒级收敛就能接受。如果想做强一致(每次操作所有端阻塞确认),这个代价过高,一般不推荐。
4.4 漫游冷启动的拉取性能
新端登录是体验最脆弱的一环——用户刚换新手机,第一印象全押在这一下。冷启动最怕"一次拉太多":会话几百个、每个都要补增量,串行拉能卡好几秒。
这里有两个立竿见影的优化。会话列表与消息拉取解耦:会话列表是一次按 uid 的索引查询,毫秒级返回先把界面铺出来,增量消息按会话懒加载、点进哪个补哪个。按会话并行 + 每会话上限:批量补时并行查、每会话设条数上限,配 nextPage 让用户主动上拉。核心判断:冷启动要的是"会话秒开"而非"内容一次到位"——把全量补齐切成渐进补全,用户感知到的延迟,能提升整整1个数量级。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号