不只是向量存储:Milvus 2.6 的 3 层 AI Agent 能力体系
原创
不只是向量存储:Milvus 2.6 的 3 层 AI Agent 能力体系
原创
术哥
发布于 2026-06-14 22:19:53
发布于 2026-06-14 22:19:53
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 139 篇,Milvus 最佳实战「2026」系列第 12 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
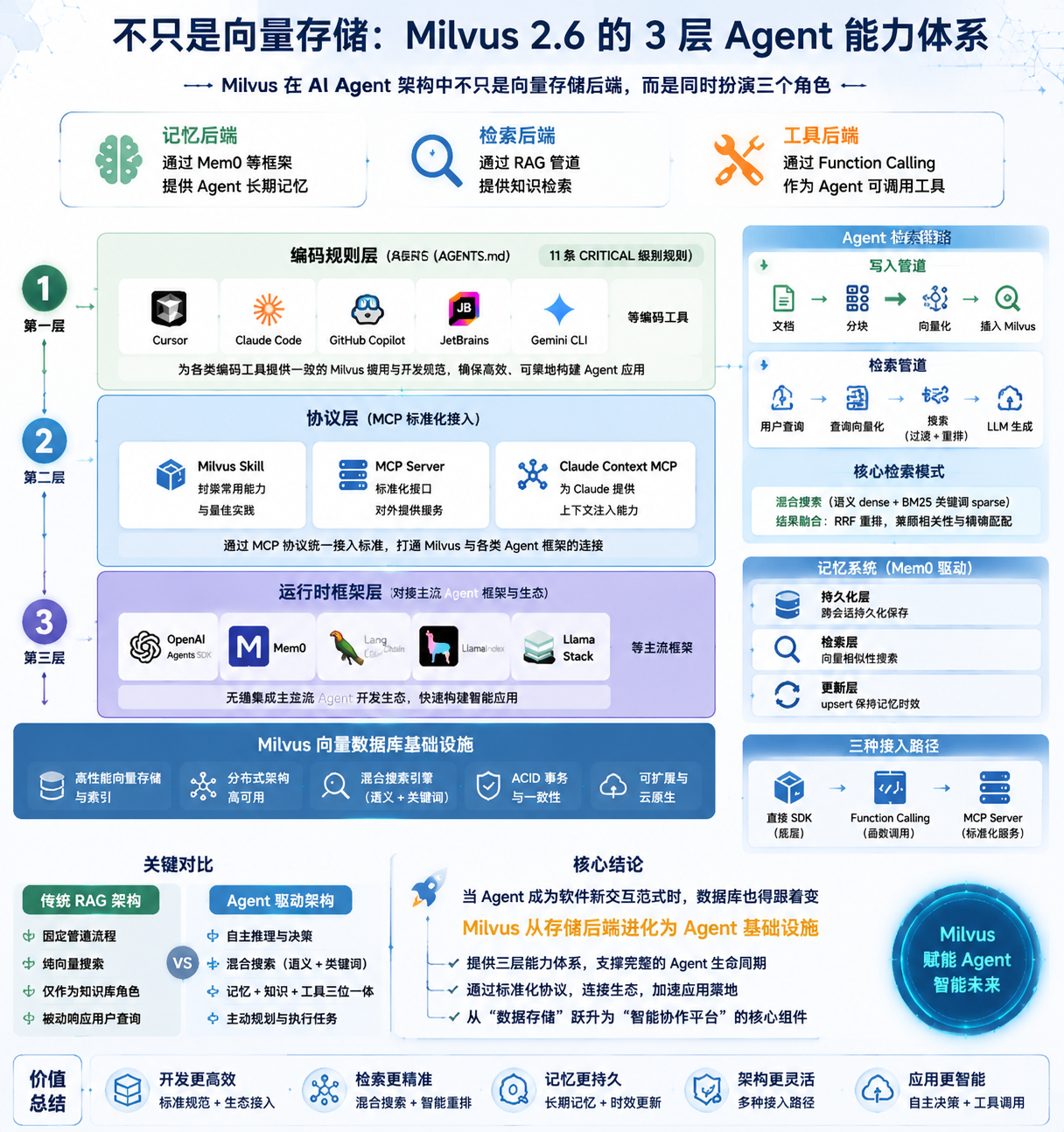
Milvus for AI Agents 架构概览
图 1:Milvus 2.6 Agent 能力体系全景
你在构建 AI Agent 的时候,大概率会遇到三个头疼的问题:Agent 聊着聊着就忘了之前的对话;检索知识只能做线性 RAG 管道,Agent 没法自主决定搜什么;不同 Agent 框架接入向量数据库的方式各不相同,集成代码写了一遍又一遍。
这些问题的根源指向同一个事实:大多数向量数据库仍然把自己定位为存储后端,而不是 Agent 架构的一部分。
翻了一遍 Milvus 2.6.x 的官方文档(截至 2026 年 6 月),发现它做的事情和传统向量数据库不太一样。Milvus 围绕 AI Agent 搭了一套完整的能力体系,涵盖编码 Agent 规则、协议层集成和运行时框架对接。这篇文章就来拆解这套体系的设计逻辑。
说明:本文内容基于 Milvus 2.6.x 官方文档(milvus.io/docs)和本地仓库源码分析整理而成,所有机制描述均可在官方文档或源码中找到依据。文中的架构分析和设计观点仅供参考,实际使用请以官方最新文档为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 从向量数据库到 Agent 基础设施
先说清楚一个核心问题:Milvus 在 Agent 架构中到底是什么角色?
官方文档 milvus_for_agents.md 给出的定位很明确——Milvus 提供的是 agent-friendly interfaces,让 AI 编码助手和自主 Agent 系统能以编程方式与向量数据库交互。不管是 RAG 管道、语义搜索还是 Agent 记忆系统,Milvus 都提供了多种接入方式。
关键在于,Milvus 在 Agent 架构中不是简单的存储后端,而是同时扮演三个角色:
角色 | 职责 | 实现方式 |
|---|---|---|
Memory Backend | 提供 Agent 长期记忆 | 通过 Mem0 等记忆框架 |
Retrieval Backend | 提供知识检索 | 通过 RAG 管道 |
Tool Backend | 作为 Agent 可调用工具 | 通过 Function Calling |
换句话说,Milvus 的设计目标不只是把查询延迟压到多少毫秒、召回率提到多少。它要解决的是:Agent 能不能自主调用、记忆能不能持久保存、检索够不够灵活。
2. 三层能力架构
Milvus 的 Agent 能力不是散装的 API 文档,而是一个分层清晰的三层体系。从官方文档的文件结构来看,这三层从上到下分别是:编码规则层、协议层、运行时框架层。
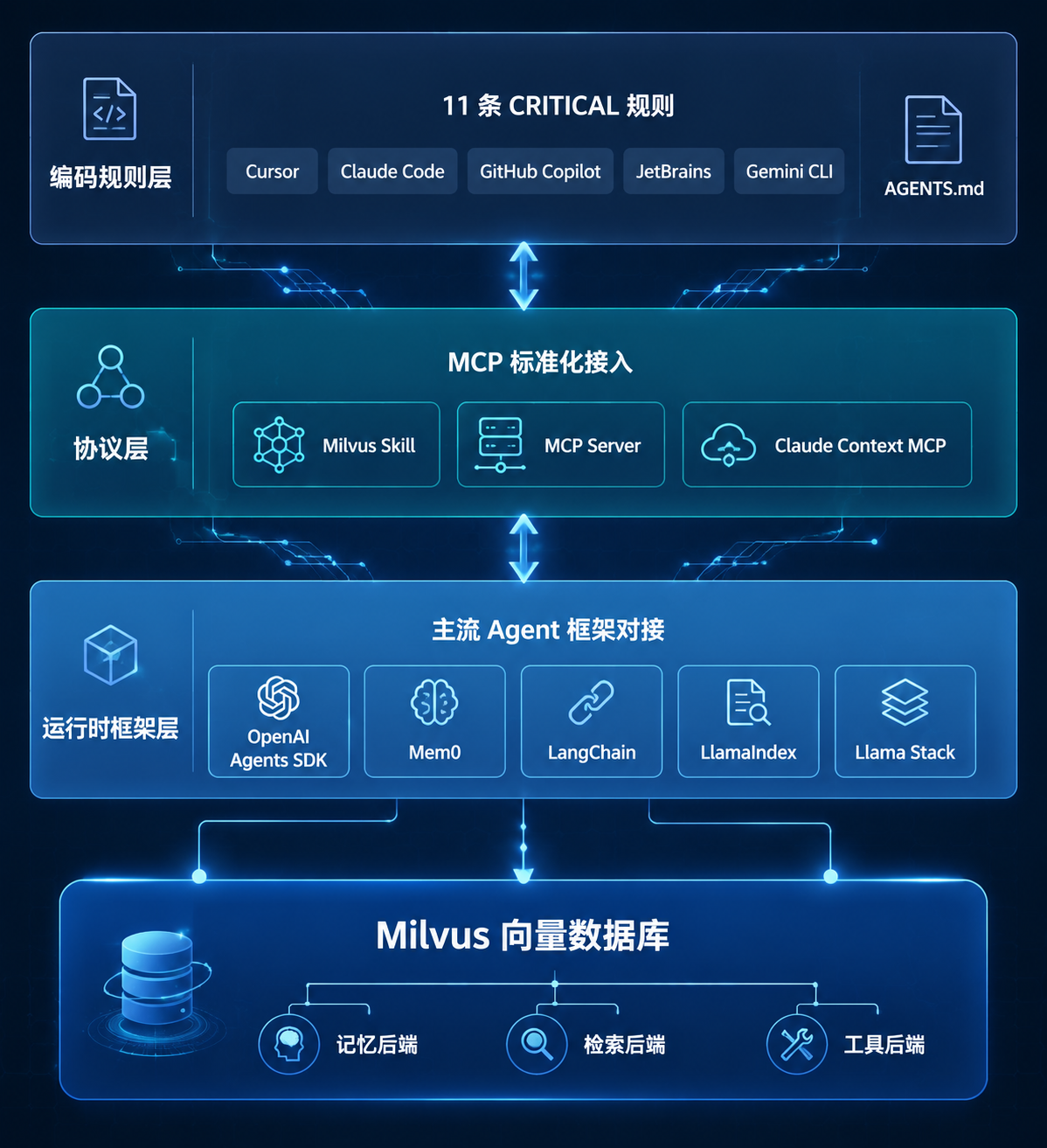
三层架构图
图 2:Milvus Agent 三层能力架构
编码规则层:11 条 CRITICAL 约束
第一层面向 AI 编码助手。Milvus 发布了一套结构化的提示词系统(AGENTS.md),专门给 Cursor、Claude Code、GitHub Copilot 这类编码 Agent 用。
核心是一份包含 11 条关键规则的文档。摘几条 CRITICAL 级别的看看:
规则 | 内容 | 级别 |
|---|---|---|
必须使用 MilvusClient | 禁止 ORM API | CRITICAL |
使用 DataType 枚举 | 禁止字符串类型 | CRITICAL |
Schema 约束 | v2.6+ 可添加 nullable 字段,但不能修改或删除已有字段 | CRITICAL |
索引优先于加载 | 加载优先于搜索 | CRITICAL |
单向量约束 | 每个 AnnSearchRequest 只接受一个向量 | CRITICAL |
说实话,第一次看到这个设计的时候确实有点意外。把 API 使用规则编码成提示词,让 AI 编码助手生成代码时就避开常见错误——这种思路在向量数据库领域相当少见。
规则的覆盖面也考虑了多环境适配。同一种约束会适配到不同工具的提示词位置:
环境 | 提示词位置 |
|---|---|
Cursor |
|
GitHub Copilot |
|
Claude Code |
|
JetBrains IDEs |
|
Gemini CLI |
|
这不是简单的文档搬运,而是把数据库的 API 约束深度嵌入了编码 Agent 的工作流。
协议层:MCP 标准化接入
第二层是协议层。Milvus 提供了三个与 MCP(Model Context Protocol)相关的组件:
- Milvus Skill(GitHub: zilliztech/milvus-skill):Claude Code 的 Agent Skill,教 LLM 使用 PyMilvus 做向量数据库操作
- MCP Server(GitHub: zilliztech/mcp-server-milvus):模型上下文协议服务器,让任何 MCP 兼容的 Agent 直接与 Milvus 交互
- Claude Context MCP(GitHub: zilliztech/claude-context):专为 Claude Code 设计的 MCP 服务器,提供上下文感知的 Milvus 文档访问
MCP 的意义在于:Agent 不需要学习 Milvus 的 SDK 细节,通过标准协议就能直接查询、插入和管理向量数据。这对多 Agent 系统的接入成本降低不少。
运行时框架层
第三层是运行时框架集成。Milvus 与主流 Agent 框架有官方集成文档:
框架 | 集成方式 |
|---|---|
OpenAI Agents SDK | 通过 Function Calling 封装为 Agent 工具 |
Mem0 | 将 Milvus 作为记忆向量存储后端 |
LangChain | RAG 管道集成 |
LlamaIndex | 混合搜索与异步集成 |
Llama Stack | 元数据过滤与 Agent 协调 |
三层叠在一起,不管你用哪种 Agent 框架、哪种编码工具,Milvus 都给了对应的接入路径。
3. Agent 检索的完整链路
搞清楚架构分层之后,来看实际的数据是怎么流动的。这部分是理解 Milvus 在 Agent loop 中角色的关键。

检索数据流图
图 3:Agent 检索数据流路径
数据流路径
Milvus 官方文档 rag_pipeline.md 定义了两条核心管道:
写入管道(Ingestion Pipeline):
文档 → 分块 → 向量化 → 插入 Milvus检索管道(Retrieval Pipeline):
用户查询 → 查询向量化 → 搜索 Milvus(含过滤和重排)→ LLM 生成在 Agent 场景下,这条检索管道不是固定执行的。Agent 通过 reasoning 自主决定是否检索、检索什么、用什么参数检索。这是 Agent 驱动模式和传统 RAG 的本质区别。
操作顺序约束
写入和检索管道有严格的操作顺序约束。官方文档明确了 7 步强制顺序:
- 向量化文档,生成向量
- 创建 collection(含 schema 定义)
- 插入数据
- 创建索引
- 加载 collection
- 执行搜索
- 传递给 LLM
有两个约束需要特别注意:索引必须在加载之前创建,加载必须在搜索之前完成。
v2.6.x 做了一个优化:create_collection() 支持同时传入 schema 和 index_params,自动处理索引创建和加载。这在 Agent 自动化场景下减少了出错的可能性。
混合搜索:Agent 检索的核心模式
Milvus 在 Agent 场景下推荐的检索模式是 Hybrid RAG——结合语义搜索(dense vectors)和关键词搜索(BM25 sparse vectors)。官方文档给出了完整代码:
# Dense 向量请求(语义搜索)
dense_req = AnnSearchRequest(
data=[query_embedding],
anns_field="dense_vector",
param={"metric_type": "COSINE"},
limit=top_k * 2,
)
# BM25 稀疏向量请求(关键词搜索)
sparse_req = AnnSearchRequest(
data=["machine learning applications"], # 直接传文本查询
anns_field="sparse_vector",
param={"metric_type": "BM25"},
limit=top_k * 2,
)
# 使用 RRF 排序器合并两路结果
results = client.hybrid_search(
collection_name=COLLECTION_NAME,
reqs=[dense_req, sparse_req],
ranker=RRFRanker(),
limit=top_k,
output_fields=["text", "source"],
)BM25 全文搜索是 Milvus 2.5+ 引入的内置能力。它基于 sparse-BM25 算法,统一了向量搜索和关键词搜索的 API,不需要手动生成关键词搜索的 embedding。但有一个前提条件:BM25 Function 和 analyzer 必须在 collection 创建时定义。
搜索模式的选择也不是任意的。官方文档 search_patterns.md 给出了决策表:
场景 | 搜索类型 | 调用方式 |
|---|---|---|
单向量找相似项 | 基础 ANN 搜索 |
|
密集加稀疏组合 | 混合搜索 |
|
元数据过滤 | 过滤搜索 | 搜索时加 |
文本关键词匹配 | 全文搜索 | 需 BM25 预定义 |
精确短语匹配 | 短语匹配 |
|
主键检索 | 主键搜索 |
|
注意,搜索迭代器只支持基础 ANN 搜索,不支持混合搜索。这种约束在选型时需要提前考虑到。
4. Agent 记忆系统怎么落地
Agent 的长期记忆是很多人关心的部分。Milvus 在这块的落地方案是通过 Mem0 框架。

记忆架构图
图 4:Agent 记忆架构(Mem0 + Milvus)
Mem0 是 AI 应用的智能记忆层,使用 Milvus 作为向量存储后端。它提供了 6 个核心操作:
add():存储非结构化文本,关联用户 ID 和元数据search():基于语义搜索检索相关记忆update():更新已有记忆get_all():获取用户所有记忆delete():删除记忆history:追踪记忆变更历史
配置很简洁,几行就能跑起来:
config = {
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "quickstart_mem0_with_milvus",
"embedding_model_dims": "1536",
"url": "./milvus.db", # 本地或云端
},
},
}
m = Memory.from_config(config)在 Agent 记忆架构中,Milvus 承担了三层职责:
持久化层:跨会话保存用户偏好、对话历史和知识。Agent 重启后不会丢失上下文。
检索层:通过向量相似性搜索找到与当前对话相关的历史上下文。不是把所有历史都塞进 prompt,而是按需检索。
更新层:通过 upsert 操作保持记忆的时效性。过时信息被覆盖,不会累积成垃圾数据。
这里需要说清楚一个边界:Milvus 本身不提供记忆管理逻辑(如记忆衰减、优先级排序),这些是 Mem0 框架的职责。Milvus 只负责存储和检索。
5. 工具化封装与调用链路
Agent 要能自主调用 Milvus,搜索能力就得封装成 function tool。官方文档 openai_agents_milvus.md 展示了完整的 Function Calling 集成方式。
核心代码就是把 Milvus BM25 搜索封装成一个标准工具函数:
@function_tool
async def search_milvus_text(ctx, collection_name, query_text, limit):
"""Search for text documents in a Milvus collection using full text search."""
client = MilvusClient()
search_params = {"metric_type": "BM25", "params": {"drop_ratio_search": 0.2}}
results = client.search(
collection_name=collection_name,
data=[query_text],
anns_field="sparse",
limit=limit,
search_params=search_params,
output_fields=["text"],
)
return json.dumps({"results": results, "query": query_text})封装好之后,完整的 Agent 调用链路是这样的:
用户提问 → Agent 推理 → Function Call(Milvus 搜索)
→ 向量/BM25 检索 → 结构化结果返回 → Agent → LLM 生成 → 响应这条链路的关键在于:Agent 通过 reasoning 自主决定是否调用 Milvus 搜索,而不是每次提问都走检索流程。这就是 Agent 驱动模式和固定 RAG 管道的区别。
从集成方式来看,Agent 有三种接入路径:
- 直接 SDK:Agent 代码中直接调用 PyMilvus(适合自定义 Agent)
- Function Calling:通过
@function_tool封装(适合 OpenAI Agents SDK 等框架) - MCP Server:通过标准协议接入(适合任意 MCP 兼容 Agent)
三种方式的灵活度不同。直接 SDK 灵活但代码量大,MCP Server 接入成本低但受限于协议定义的接口范围。
你在项目中用的是哪种 Agent 接入方式?欢迎在评论区聊聊。
6. 传统 RAG vs Agent 驱动模式
前面拆了架构、检索链路和记忆系统,现在把它们放在一起对比。传统 RAG 和 Agent 驱动的检索模式有 5 个本质变化:
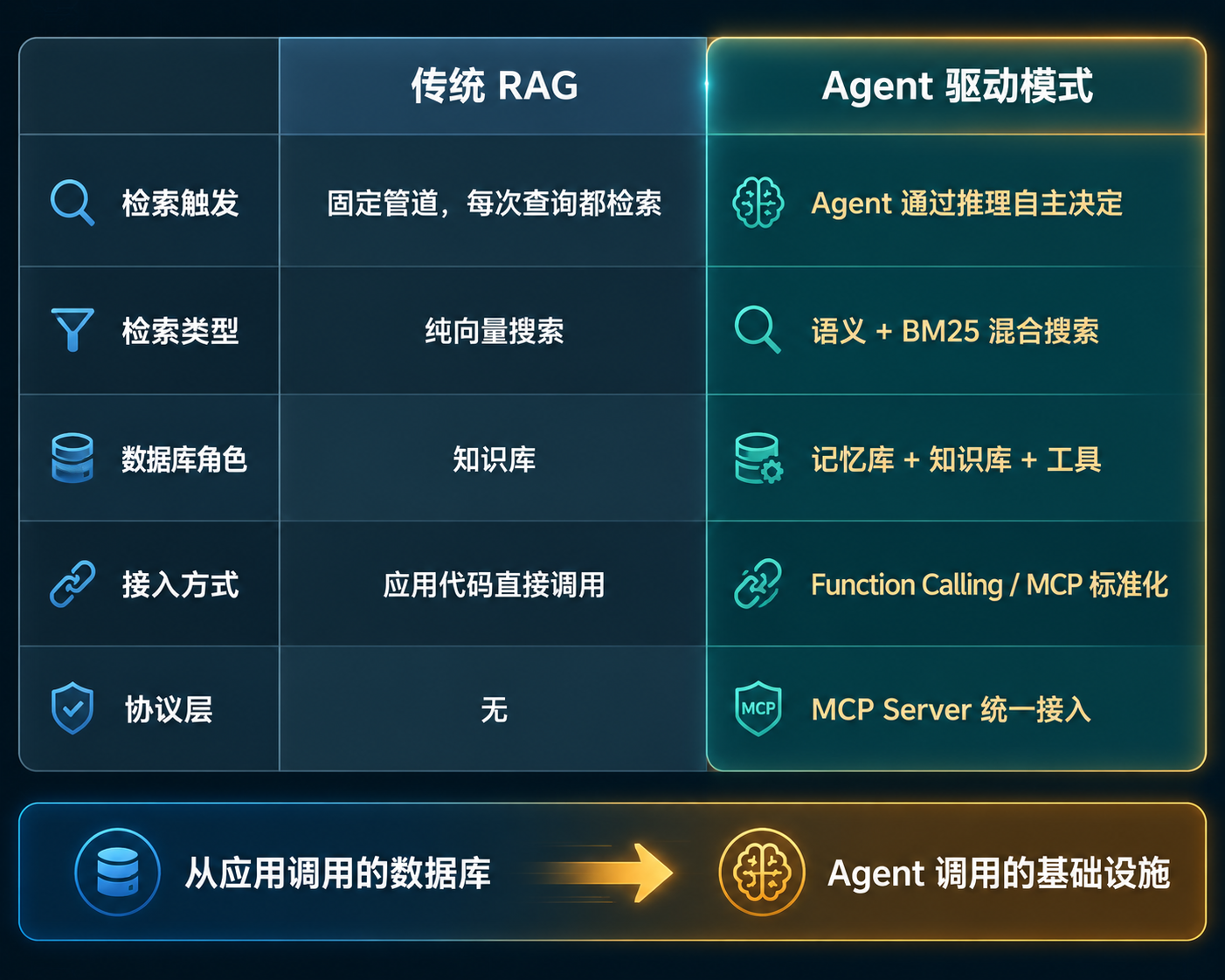
RAG vs Agent 对比图
图 5:传统 RAG 与 Agent 驱动模式对比
维度 | 传统 RAG | Agent 驱动模式 |
|---|---|---|
检索触发 | 固定管道,每次查询都检索 | Agent 通过 reasoning 自主决定 |
检索类型 | 纯向量搜索 | dense + BM25 混合搜索 |
数据库角色 | 知识库 | 记忆库 + 知识库 + 工具 |
接入方式 | 应用代码直接调用 | Function Calling / MCP 标准化 |
协议层 | 无 | MCP Server 统一接入 |
5 个维度对比下来,一个趋势很明显:Milvus 的定位从应用调用的数据库变成了Agent 调用的基础设施。
举个具体的例子:在传统 RAG 中,用户问一个问题,系统固定执行 embed → search → generate 三步。Agent 模式下,Agent 可能先推理判断这个问题需不需要检索知识库,如果需要就调用 Milvus 工具,如果不需要就直接回答。检索不再是流程的必经节点,而是 Agent 工具箱里的一个选项。
这也是为什么 Milvus 要做编码规则层——当 Agent 自主编码调用 Milvus 时,11 条 CRITICAL 规则能防止它犯低级错误(比如先加载再建索引,或者用字符串代替 DataType 枚举)。
7. 系统设计视角与边界
Agent 友好性设计的四个维度
从系统设计角度,Milvus 的 Agent 友好性体现在几个方面:
统一接口:MilvusClient 统一所有操作,废弃了旧的 ORM API(connections.connect()、Collection()、utility.list_collections())。Agent 生成的代码只需要学一套 API。
约束编码:11 条 CRITICAL 规则编码到提示词中,从源头防止 Agent 生成错误代码。
多协议支持:SDK + REST API + MCP,覆盖从直接编码到标准协议的不同接入需求。
弹性部署:从 Milvus Lite(进程内零配置)到 Zilliz Cloud(Serverless 托管),匹配 Agent 从原型到生产的全链路需求。
部署选型上,官方的建议也比较务实:
阶段 | 部署方式 | 适用场景 |
|---|---|---|
原型开发 | Milvus Lite | 零配置进程内运行 |
开发 | Milvus Standalone | 单节点 Docker |
生产 | Zilliz Cloud(Serverless) | 托管,Agent 无需管理基础设施 |
自托管生产 | Milvus Distributed | 多节点 K8s |
官方的建议是:对于 Agent 工作负载,生产环境推荐用 Zilliz Cloud。理由也直接——Agent 通常不管理基础设施,Serverless 部署能消除运维开销。
当前未覆盖的边界
下面这些内容在当前 v2.6.x 官方资料和源码中没有找到明确的实现依据,需要说清楚:
- Milvus 自身不提供 Agent 编排能力。它是被 Agent 调用的存储和检索后端,不是 Agent 本身
- 多 Agent 协作协议需要依赖外部框架(如 CrewAI、AutoGen),Milvus 不内置
- Agent 工作流编排的可视化需要依赖 LangSmith、LangFuse 等外部可观测性工具
- Milvus 不提供 embedding 和 reranking 模型推理服务,只负责存储和检索向量
这些边界不是缺陷,而是职责划分。Milvus 专注做向量存储和检索,把编排、推理、可视化交给上层框架。
总结
回到开头的问题:Milvus 在 AI Agent 架构中到底是什么?
答案不是单纯的向量数据库。它是 Agent 的记忆后端、检索后端和工具后端。编码规则层教 AI 正确使用 API、协议层通过 MCP 标准化接入、运行时框架层对接主流 Agent 框架——三层体系把 Milvus 从存储后端推到了 Agent 基础设施的位置。
说到底,这套设计思路的核心只有一句话:当 Agent 成为软件的新交互范式时,数据库也得跟着变。Milvus 2.6.x 的 Agent 能力体系,就是对这个变化的回应。
如果你的项目正在搭建 AI Agent,正在选型向量数据库,Milvus 的这套三层体系值得花时间研究。建议收藏本文,选型时翻出来对照看看。
相关资源
Milvus 官方文档:https://milvus.io/docs
Milvus GitHub:https://github.com/milvus-io/milvus
MCP Server for Milvus:https://github.com/zilliztech/mcp-server-milvus
Mem0 + Milvus 快速开始:https://milvus.io/docs/quickstart_mem0_with_milvus.md
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号