基于现有业务,在腾讯云 EdgeOne Makers 上部署一个「电商售后客服智能体」
原创
基于现有业务,在腾讯云 EdgeOne Makers 上部署一个「电商售后客服智能体」
原创
鲈鲈鲈鲈鲈鱼
修改于 2026-06-22 22:17:42
修改于 2026-06-22 22:17:42
本文以一个已经具备基础交易能力的电商站点 Maison Perle 为示例,带你体验如何基于现有业务,在 EdgeOne Makers 上改造并部署一个「电商售后客服智能体」。通过这个案例,你将完整体验 Makers 如何帮助开发者基于一个已有业务项目,快速补齐提升体验所需的智能体能力。
假设你正在运营一个精品电商网站,用户已经可以浏览商品、加入购物车、登录账号并完成下单。随着业务逐步跑起来,售后问题也会随之增加:订单什么时候发货?现在物流到哪了?签收后还能不能退?如果想换货,应该怎么操作?这些问题如果全部依赖人工客服处理,不仅重复度高,也很难保证回复口径始终一致。更理想的方式,是让智能体直接接入现有业务数据:用户问订单,就查询订单表;用户问退货政策,就读取店铺规则;用户咨询某个商品,就检索商品信息;用户想申请退款或换货,就进入对应的售后流程。这样一来,智能体就不只是一个聊天窗口,而是一个围绕真实业务运转的售后服务入口。
接下来,我们就以这个场景为起点,体验如何基于一个已有电商站点,在 EdgeOne Makers 上改造并部署一个「电商售后客服智能体」。整个过程会从现有的商品、购物车、账号和订单数据出发,把订单查询、发货规则、退换货说明和商品咨询这些高频售后问题,沉淀成一个可对话、可访问、可部署、可持续迭代的 Agent 服务,并借助 EdgeOne Makers Agent 快速上线。
更重要的是,这个过程不要求你推翻原有技术栈,也不会把你锁定在某一种框架、语言或模型里。你可以继续保留现有业务架构,在不影响原有代码和核心流程的前提下,把 Agent 作为一个新的服务入口接入进来。Makers 默认提供了 Agent 运行、上下文记忆、工具调用等上线所需的基础能力,开发者真正需要关注的,是如何把自己的订单数据、售后规则和业务流程接入进来,让智能体更好地承接和打通真实业务。
Step 1 · 借助模板起步
在 Makers Agent 的模板库里,我们提前准备了针对不同类型、不同场景的预设模板。所有模板都已经准备好了基础对话记忆、工具调用结构、接入业务数据的示例方式,以及部署所需要的运行配置。开发者可以从一个接近业务场景的模板出发,根据自己的业务逻辑来改造 Agent。
这里我们就选择售后客服助手模板来改造,它能够识别意图、路由,并按需检索知识,这样可以省去从零搭建 Agent 基础链路的时间。开发者不需要先把这些通用能力重新实现一遍,而是可以把精力放在更贴近业务的部分。
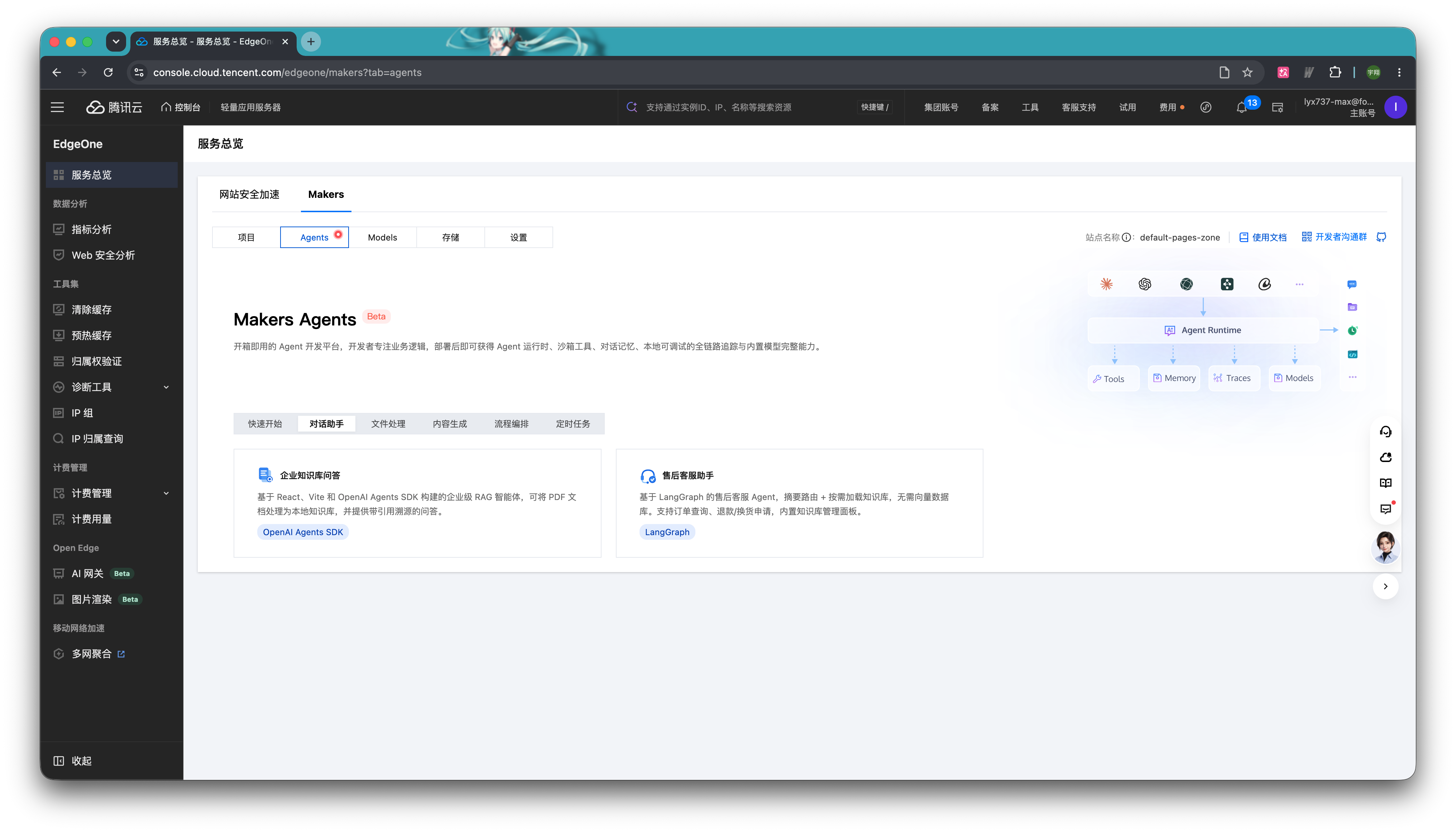
体验模板
你可以先在Makers 里体验一下默认模板实现的能力。售后客服模板实现了一个状态机驱动的客服 Agent,能够识别用户意图、路由到专用处理器,并按需检索知识。无需向量数据库——FAQ 与产品知识通过摘要相似度匹配,仅在需要时加载完整内容。
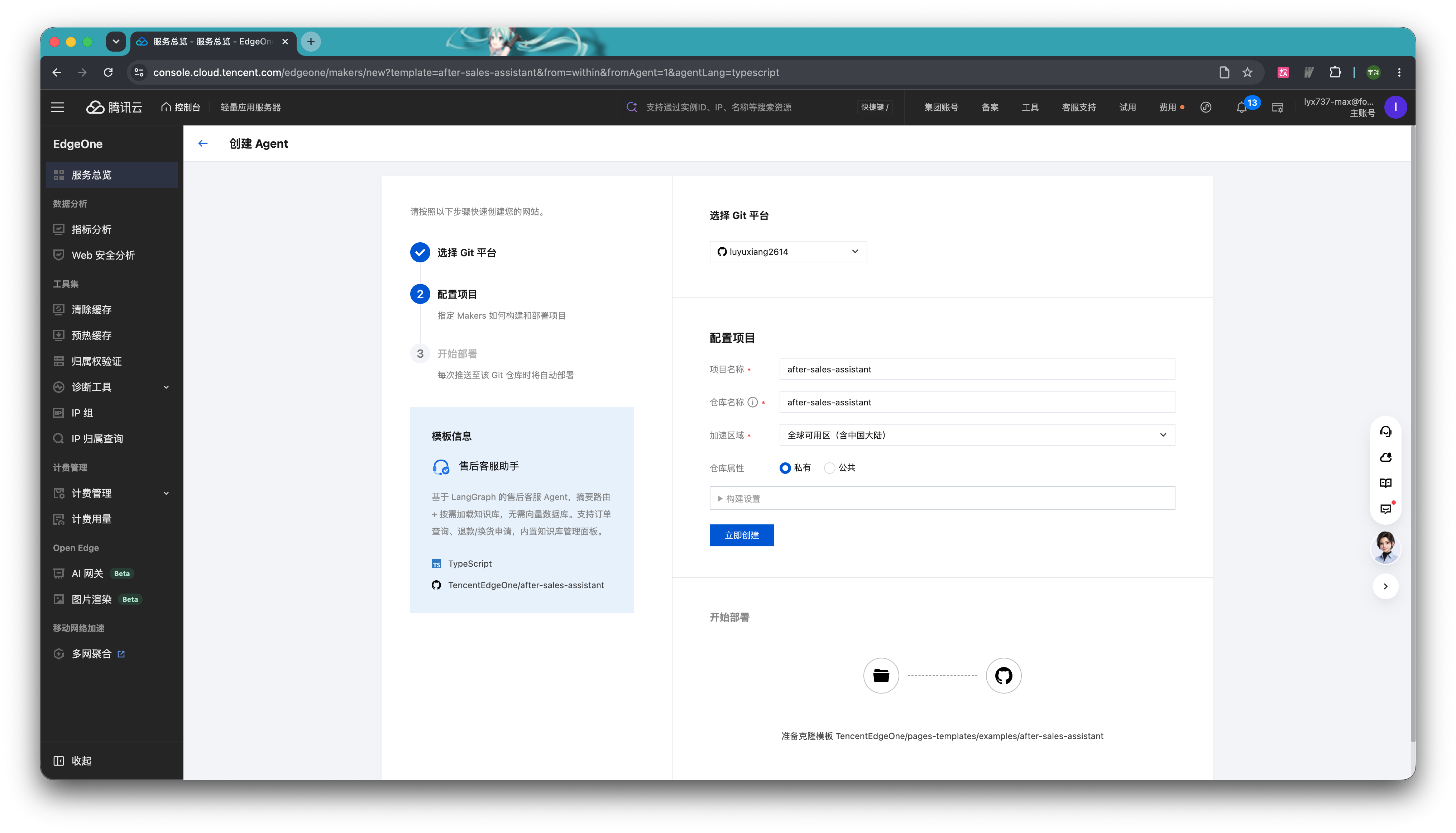
点击开始部署,Makers 会自动创建并填入运行所需的基础环境变量。部署成功后即可点击预览来体验模板。
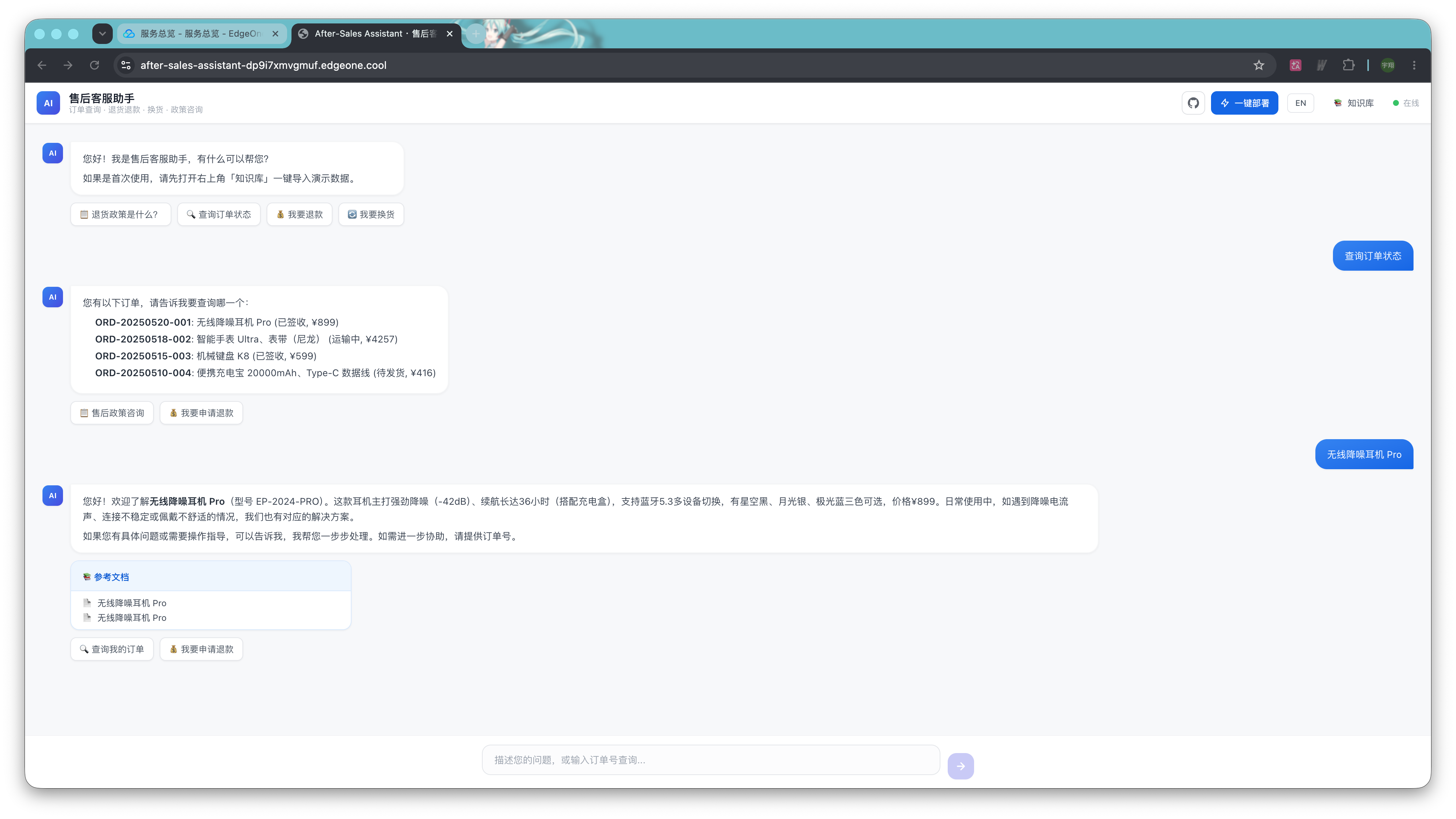
如果你决定从这个模板起步,那么可以点击下面链接获取模板。
GitHub - TencentEdgeOne/after-sales-assistant· GitHub
当然,如果你前面已经部署体验过模板,那么此时模板代码已经克隆在你自己的仓库里了。
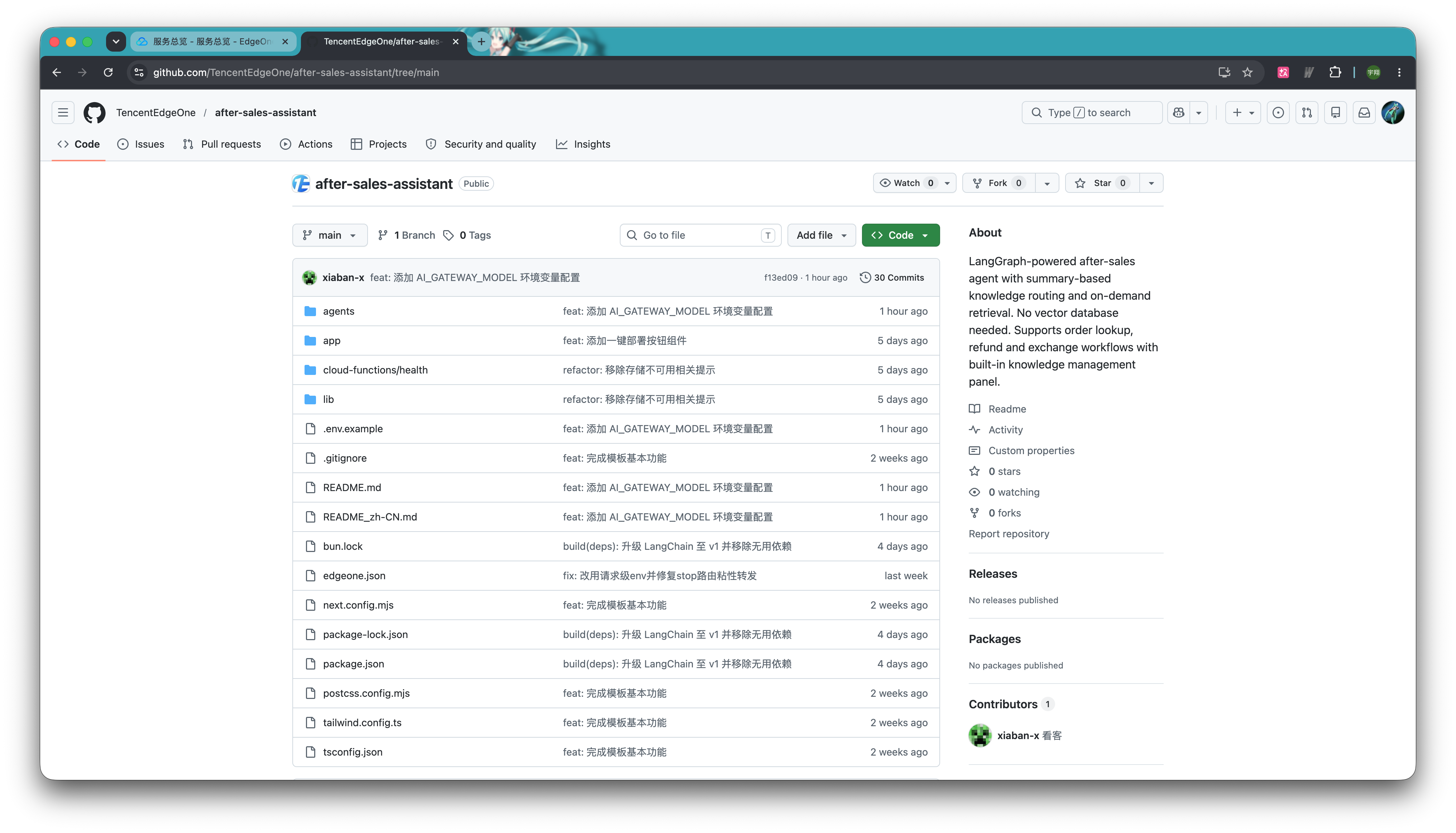
Step 2 · 快速迁移
在 EdgeOne Makers Agent 中,Agent 可以和原来的 Web 项目在同一个项目空间和控制台里上线和管理,不需要在多个平台之间来回同步配置。也因此,下载完模板后,开发者只需要将 after-sales-assistant-main 这个模板中的 agents 和 cloud-functions 这两个文件夹移动至原有业务代码的根目录,即可实现项目合并。
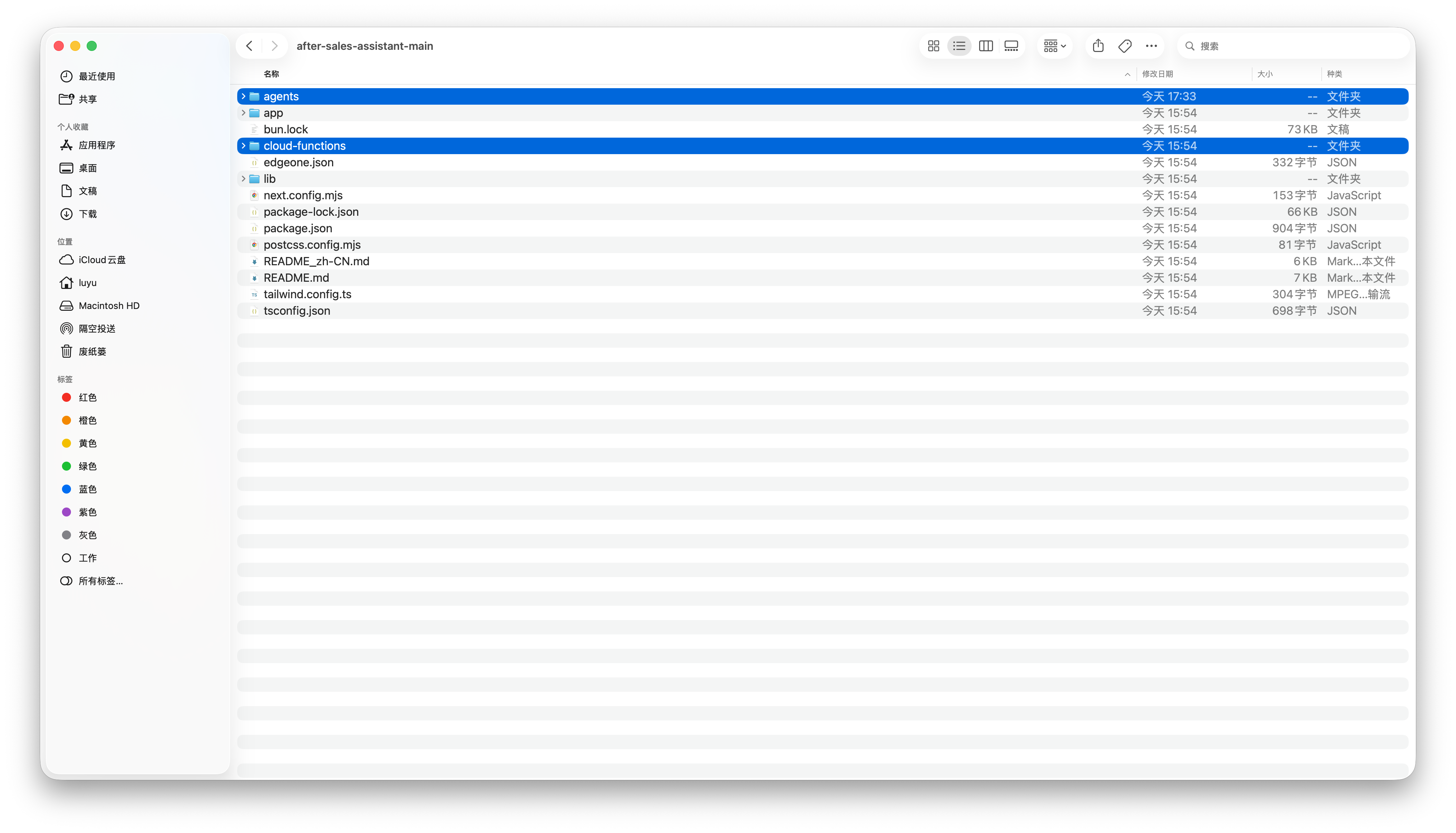
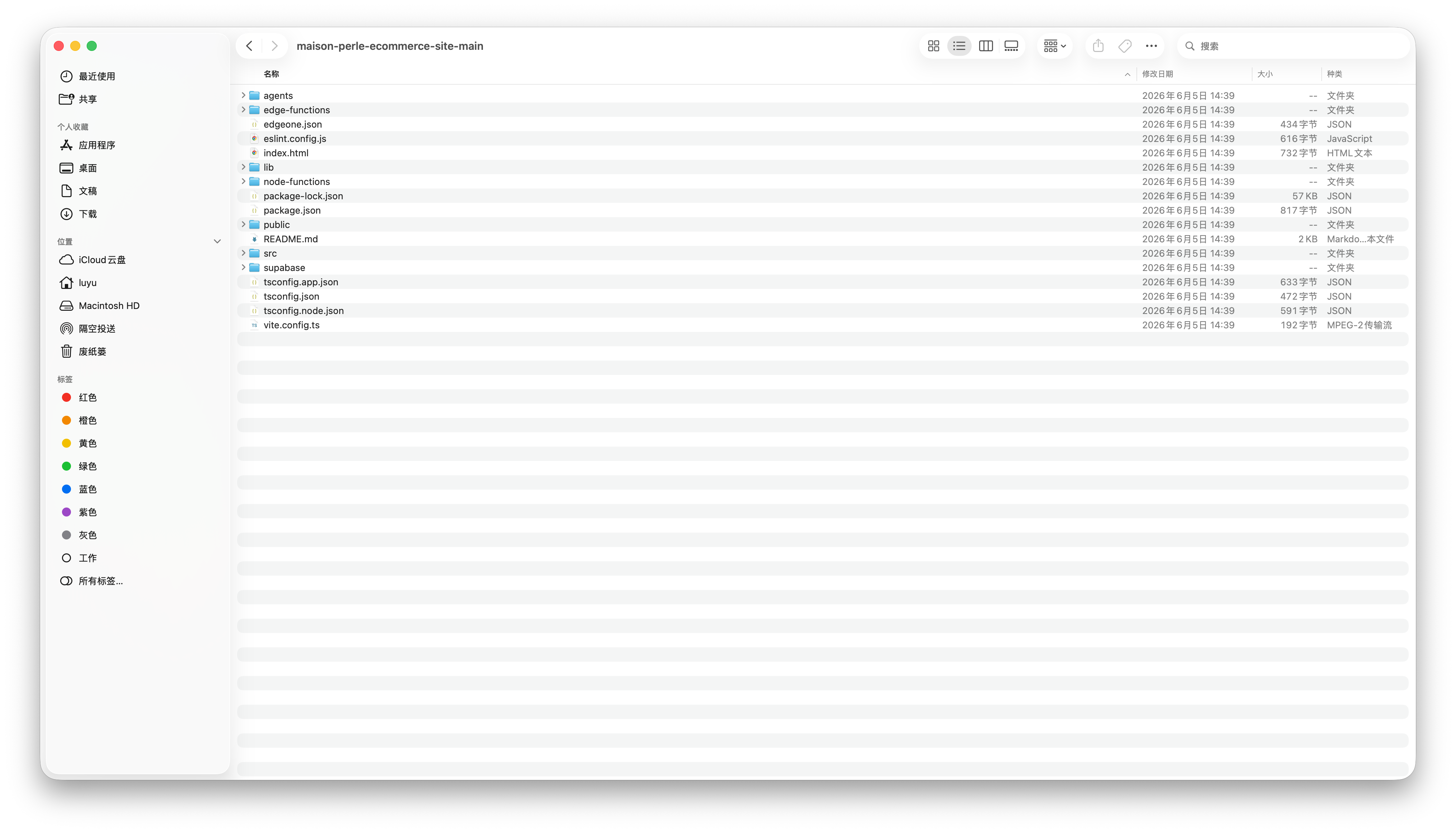
合并完以后,我们还需要对代码做一些微调。这里推荐大家把整个业务的代码导入 Workbuddy 这类的 AI IDE,并加载我们提供的 Prompt 和 Skill,引导 AI 对新接入的 Agent 进行一次面向业务场景的适配,让模板中的客服 Agent 能够更好地匹配当前电商网站的实际数据结构和业务流程。具体来说,AI 会先读取现有项目中的数据结构、商品字段、订单字段和业务接口,再根据这些信息调整 Agent 内部的业务逻辑,使订单查询、商品咨询、售后规则和退换货流程能够与当前项目准确对齐。
具体 Prompt 和 Skill如下:
skill:https://github.com/TencentEdgeOne/edgeone-pages-skills/tree/xiaban/agent
You are migrating an EdgeOne Makers agent template (agents/ and cloud-functions/ already copied into project) from EdgeOne KV to Supabase. Do everything yourself — the user is not a developer and will not provide probe data or make decisions.
What you must do autonomously
1. Gather probe data yourself from the codebase
grep for supabase.auth usage in src/
grep for .from( to find which Supabase tables the main app uses
Read .env for SUPABASE_URL, SUPABASE_SERVICE_ROLE_KEY
curl the Supabase REST API to get the real table list and sample rows:
curl -s "$SUPABASE_URL/rest/v1/" -H "apikey: $SUPABASE_SERVICE_ROLE_KEY" -H "Authorization: Bearer $SUPABASE_SERVICE_ROLE_KEY"
curl -s "$SUPABASE_URL/rest/v1/<table>?select=*&limit=1" -H "apikey: $SUPABASE_SERVICE_ROLE_KEY" -H "Authorization: Bearer $SUPABASE_SERVICE_ROLE_KEY"
Read all agent files (agents/_shared.ts, agents/_graph/, agents/chat/index.ts) to understand current KV-based implementation
Read existing frontend chat component (AIConcierge.tsx or similar)
2. Decide architecture yourself based on findings
If main app uses Supabase Auth → JWT pass-through, else service-role bypass
Call pattern: native fetch + PostgREST (zero deps, best for EdgeOne agent runtime)
3. Dependency setup first — before writing any code
MUST install agent runtime dependencies at project root BEFORE writing agent code:
bash
npm install --save-dev @langchain/langgraph @langchain/core
These are NOT bundled into the frontend build — they are ESBuild resolution stubs.
The actual runtime implementations are provided by the EdgeOne agent node (.edgeone/agent-node/).
But the local agent bundler (esbuild) will fail with “Could not resolve” if they are missing from node_modules.
Installing as devDependencies satisfies the resolver without bloating the production bundle.
Add agents.framework + externalNodeModules to edgeone.json:
json
{
“agents”: { “framework”: “langgraph” },
“externalNodeModules”: [“@langchain/langgraph”, “@langchain/core”]
}
4. Six refactor steps
Delete KV residue from template
Create agents/_supabase.ts with PostgREST fetch + row mappers
Create agents/_model.ts for AI Gateway LLM calls
Rewire agents/_shared.ts (OrderStatus enum, data access wrappers)
Rewire agents/_graph/ (nodes, state, edges, builder) with generateResponse LLM node
Rewire agents/chat/index.ts (JWT pass-through, SSE conventions)
Add agents/_i18n.ts status labels
5. Frontend — create NEW AgentSupport.tsx (NEVER modify existing AIConcierge)
Bottom-left, Headset icon (AIConcierge stays bottom-right untouched)
SSE parsing, conversation_id in localStorage, makers-conversation-id header
Forwards Authorization: Bearer if signed in
6. Deployment readiness — push environment variables (MUST DO)
The agent requires these environment variables on the EdgeOne Makers platform. After the first deployment, immediately push them via CLI — do NOT tell the user to go to the console:
bash
edgeone makers env set SUPABASE_SERVICE_ROLE_KEY “<value-from-.env>”
edgeone makers env set AI_GATEWAY_BASE_URL “<value-from-.env>”
edgeone makers env set AI_GATEWAY_API_KEY “<value-from-.env>”
edgeone makers env set AI_MODEL “<value-from-.env>”
Verify with edgeone makers env ls
If env vars were set after the initial deploy, redeploy so the agent runtime picks them up.
Do NOT tell the user “go to Settings → Environment Variables in the console” — use the CLI.
Makers platform rules (never break these)
❌ process.env.X → ✅ context.env.X
❌ headers.get(‘x’) → ✅ headers[‘x’] (plain object)
❌ await req.json() in chat handler → ✅ context.request.body (pre-parsed)
❌ No heartbeat → ✅ “: ping\n\n” every 5 seconds
❌ No [DONE] at stream end → ✅ “data: [DONE]\n\n”
❌ Error crashing stream → ✅ swallow AbortError, emit error_message for others
❌ Service-role key in frontend → ✅ backend only
❌ Modifying existing frontend → ✅ new AgentSupport.tsx
❌ Hardcoded agent replies → ✅ LLM via AI Gateway for natural responses
Agent architecture
Graph flow: START → intentClassifier(regex) → authCheck → [dataNode] → generateResponse(LLM) → ENDClassify intent with simple regex (no LLM needed — saves latency)
Data nodes fetch Supabase, store results in state.fetchedData
generateResponse calls LLM via AI Gateway (context.env.AI_GATEWAY_BASE_URL + /v1/chat/completions, context.env.AI_GATEWAY_API_KEY, model from context.env.AI_MODEL)
System prompt contains FAQ knowledge text + structured fetchedData
Only ONE LLM call per turn
Field mapping
_cents columns → divide by 100
items jsonb → map to OrderItem shape
Missing tracking_number/carrier/updated_at → gracefully default
timestamptz fields → already ISO strings, use as-is
Output
Work silently. When done, show:File tree of what was created/modified
Five test prompts the user can try, with expected behavior需要说明的是,这段提示词主要适用于数据库使用 Supabase 的电商网站场景。如果你的项目使用其他数据库、已有订单系统,或业务形态与本文示例不同,可以参考根据实际的数据来源、鉴权方式和业务流程对提示词进行调整。当然,如果你熟悉项目代码,也可以直接手动修改。对于一些特殊业务规则、复杂接口调用或强定制流程,人工微调往往会更加高效。
到这,我们所希望的功能就基本实现了。Agent可以帮助用户查订单、推荐商品、解释政策乃至辅助操作......成为了提升网站转化的新入口。接下来要做的,就是让这个 Agent 能稳稳地跑在线上,开始承接真实业务。
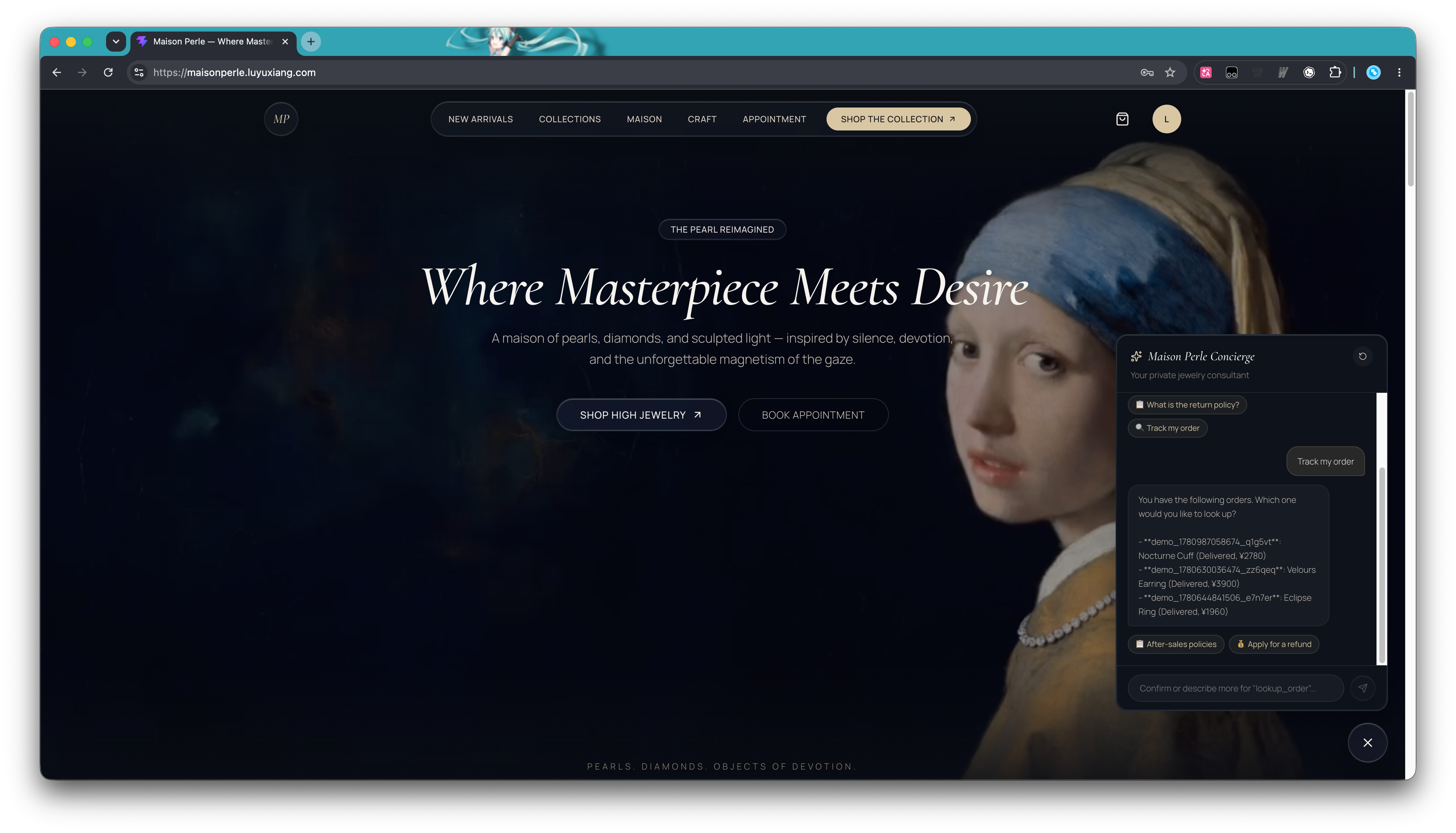
Step 3 · 部署上线
1. 准备环境变量
如果你已经部署过默认模板,那么 Makers 已经帮你生成好了运行所需要的基础变量。你也可以参考下面的步骤来获取。
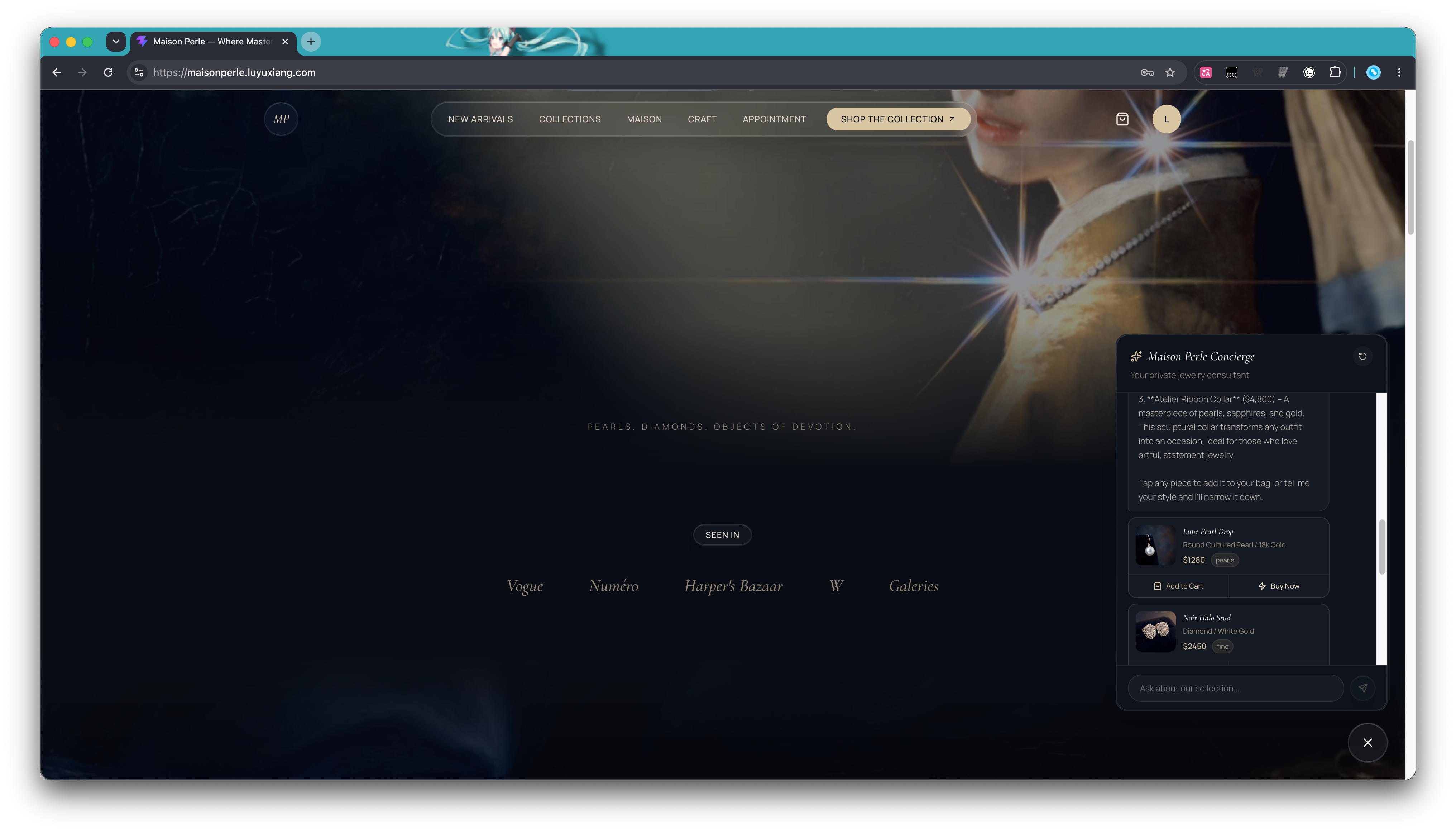
首先是调用平台自带模型网关的 API Key。回到 EdgeOne Makers 平台,选择「Models」,点击左侧的「API Key」选项卡,然后点击「创建 API Key」按钮。
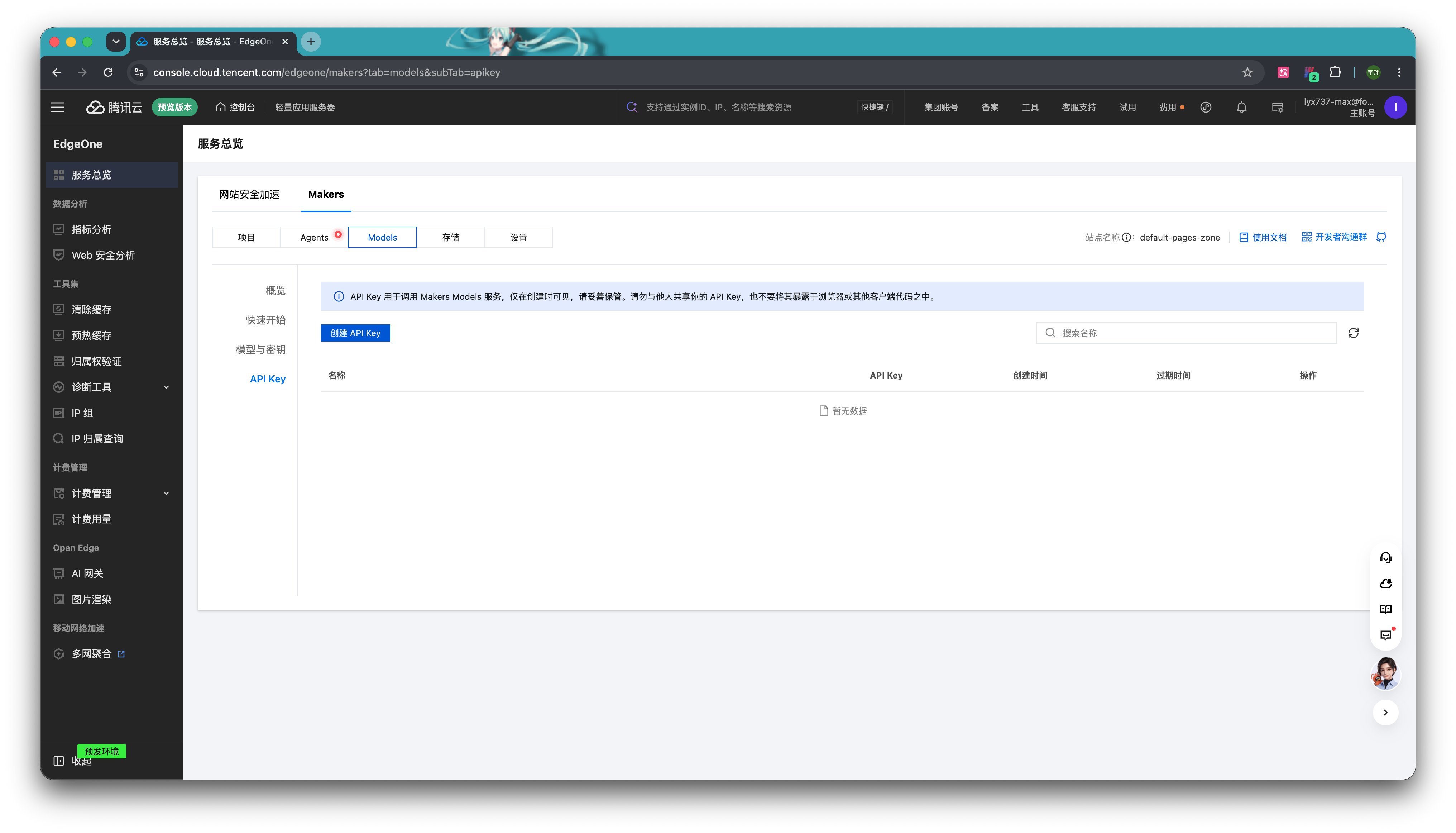
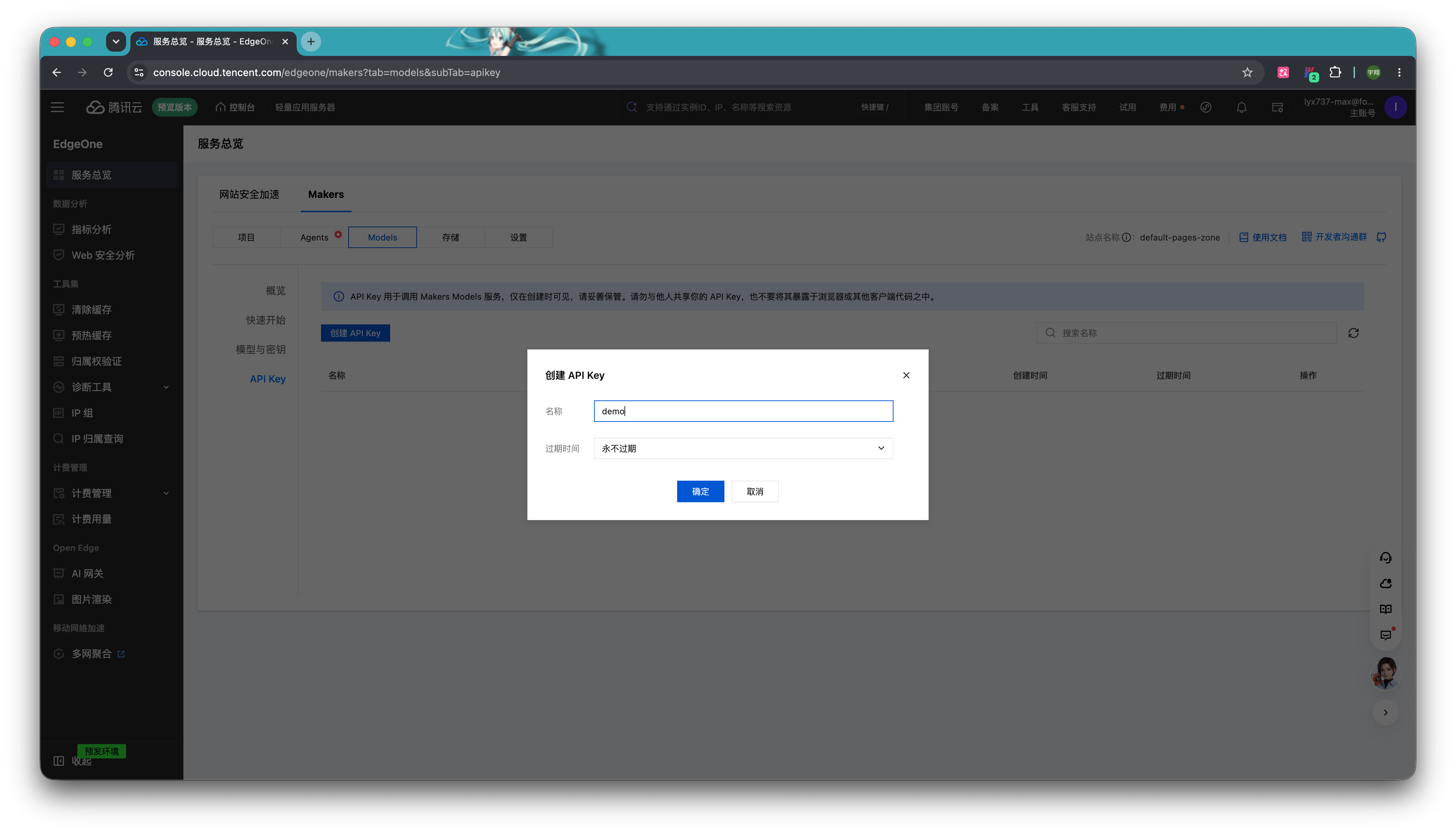
自定一个名称,并设置过期时间,如果你的 Agent 准备长期在线,可以选择默认的永不过期。
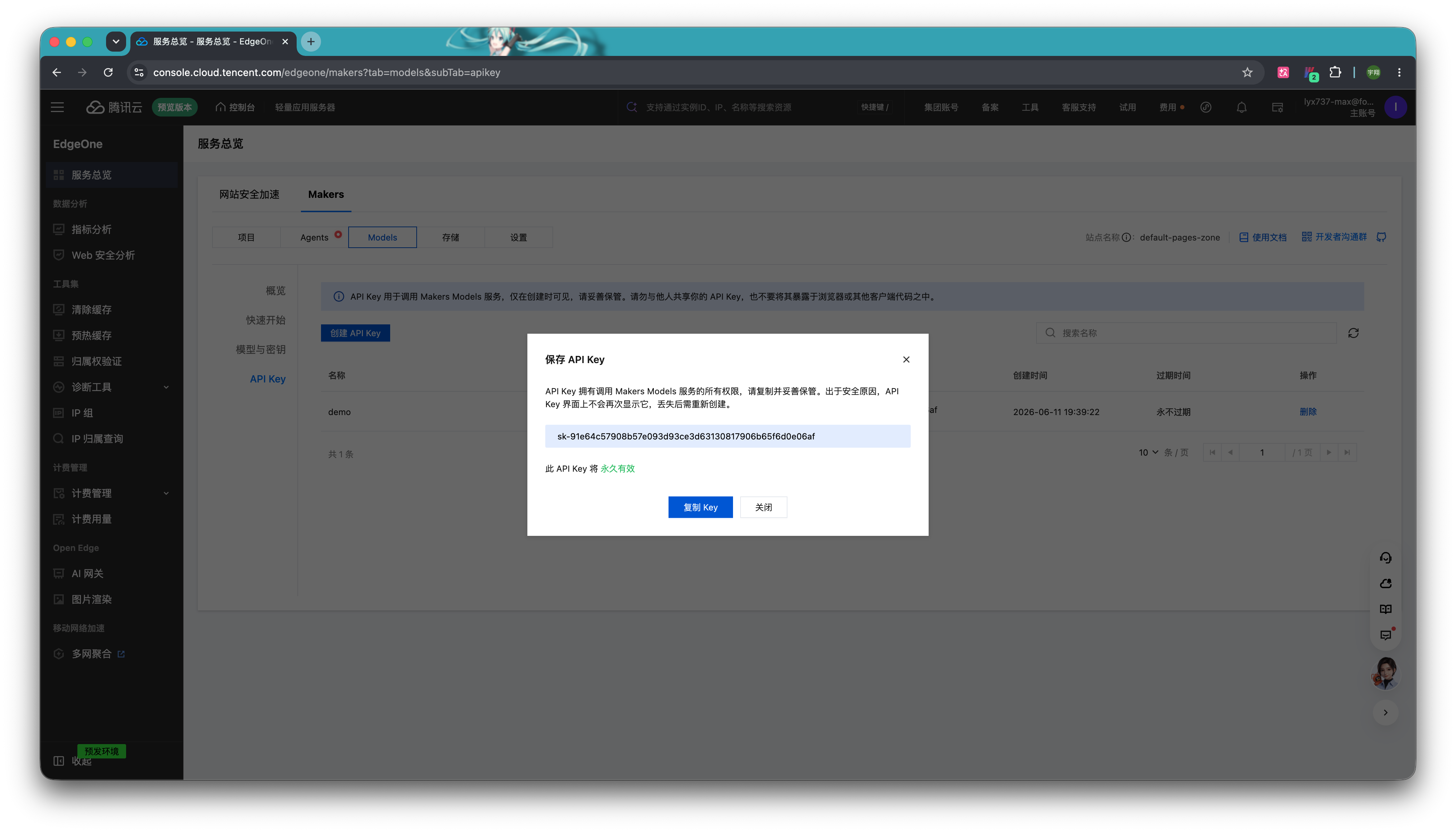
创建完成后,你会获得一串"sk-xxx......xxx"的 Key,对应的就是 AI_GATEWAY_API_KEY 这个环境变量。请复制并妥善保管。出于安全原因,API Key 界面上不会再次显示,丢失后需重新创建。
然后点击左侧的「快速开始」选项卡。
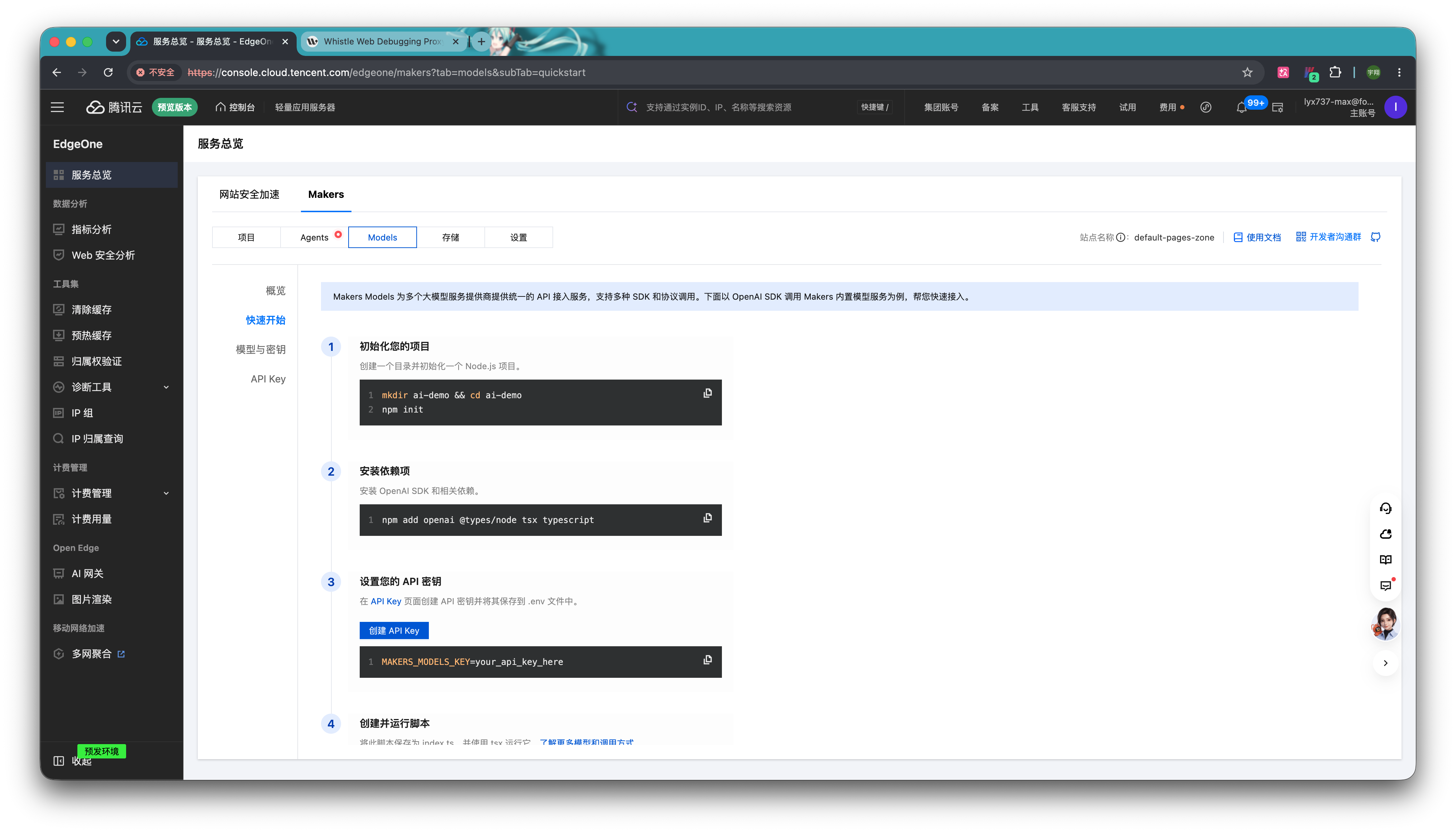
下滑,在第四步 创建并运行脚本的第 5 行有一个 baseURL,引号里的值就是 AI 网关的地址,对应的就是 AI_GATEWAY_BASE_URL 这个环境变量,我们复制下来。
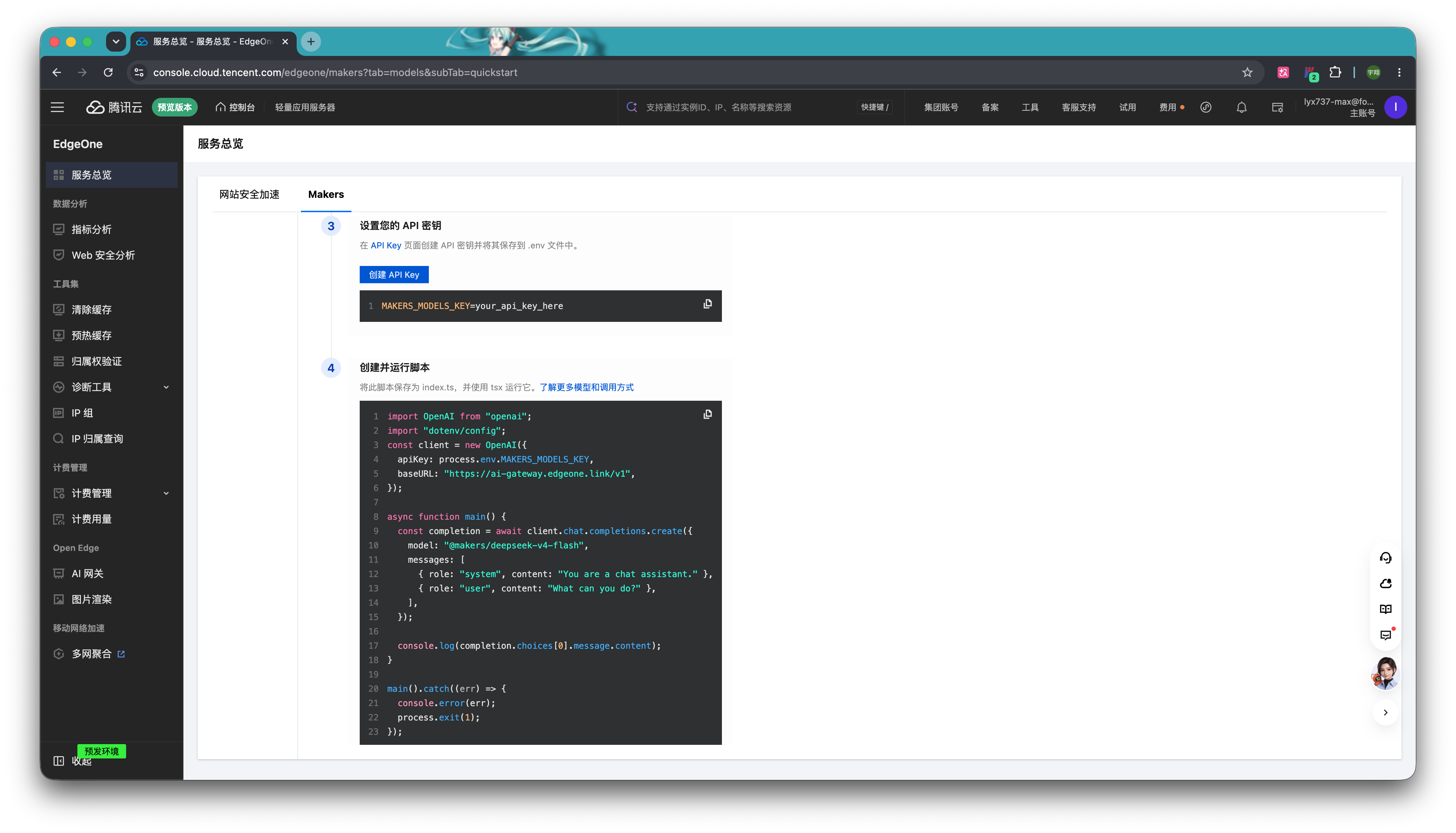
(可选)模板默认提供的模型是 deepseek-v4-flash。如果你想更换其他模型的话,可以在「模型与密钥」选项卡里,查看 AI_GATEWAY_MODEL 这个变量对应的模型 ID。例如,如果你想使用腾讯混元3.0模型,则变量名则为 @makers/hy3-preview。除了平台内置模型,你也可以接入第三方模型,只需要点击列表右侧的添加,并填入该模型的 API Key 即可获取对应的模型 ID 变量值。
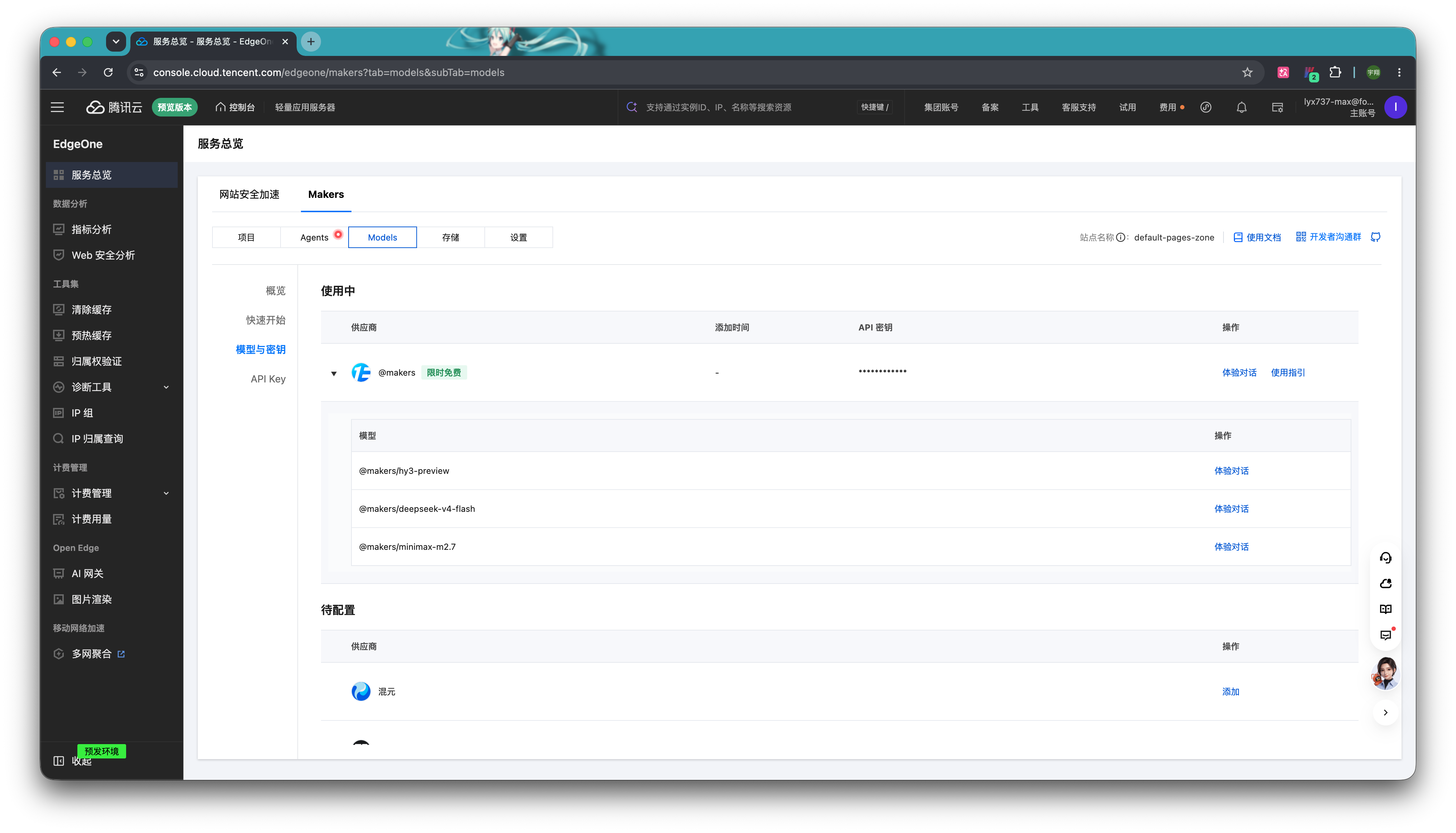
现在,部署所需的基础环境变量就已经准备好了。
2. 代码上传
下一步,是把在本地的修改代码上传托管到 Makers 平台上,这里有两种方式可以选:
2.1 代码仓库上传
如果你已经有了代码仓库,比如 Github,最省事的方式就是先上传到原来网站代码的仓库中:
cd maison-perle-ecommerce-site
git add .
git commit -m "feat: update maison perle ecommerce site"
git push如果你的网站之前就已经托管在 Makers 平台上切使用代码仓库导入部署,那么当上传完成后,平台就会自动触发新版本构建,你可以直接跳转至环境变量的部分。
如果你的网站是第一次部署在 Makers 平台上,那么等上传完以后,需要回到 Makers 的控制台,选择「项目」标签,点击「导入 Git 仓库」。
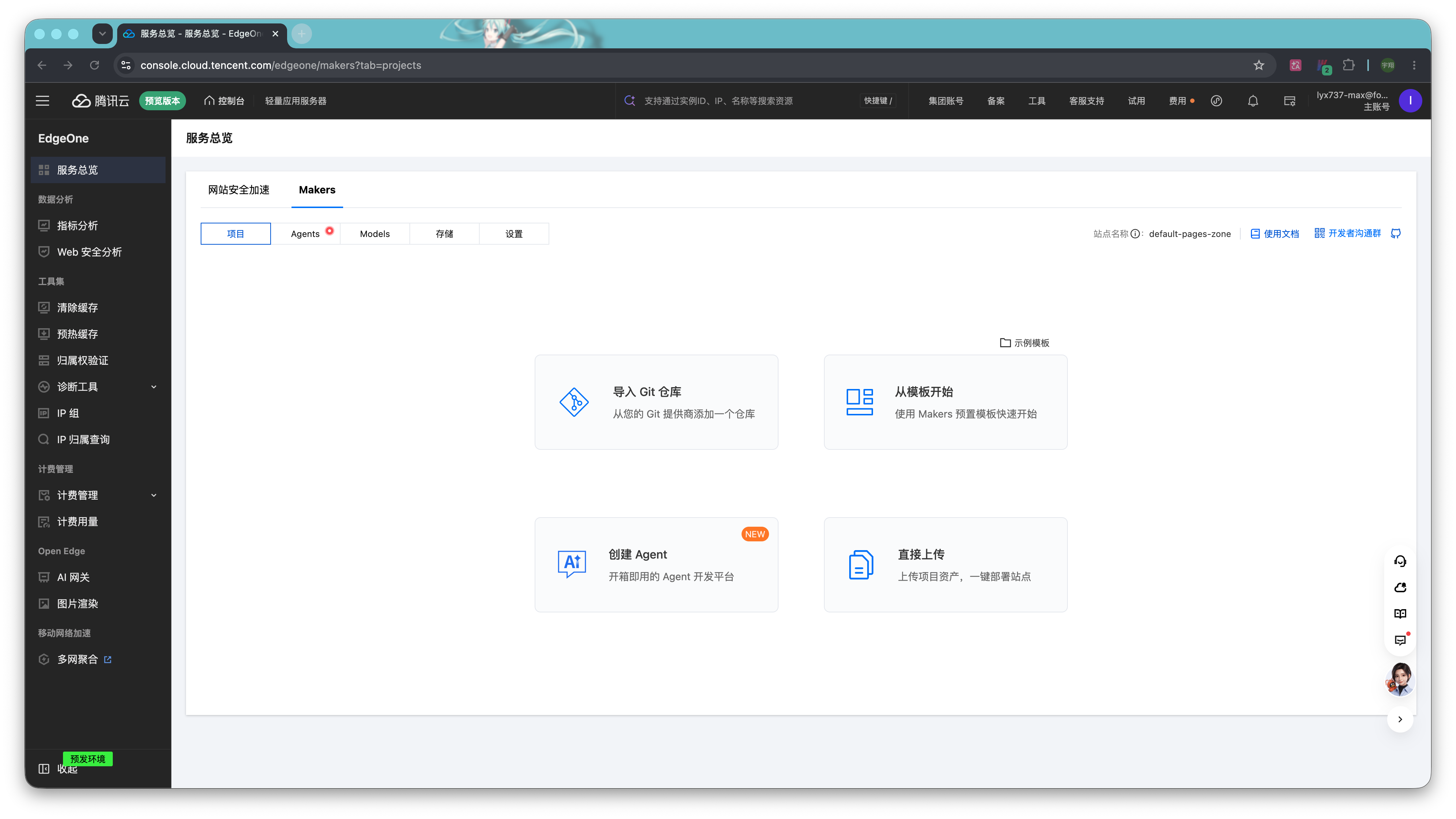
第一次使用需要绑定对应的仓库平台。我们以 Github 为例,点击「Github」。
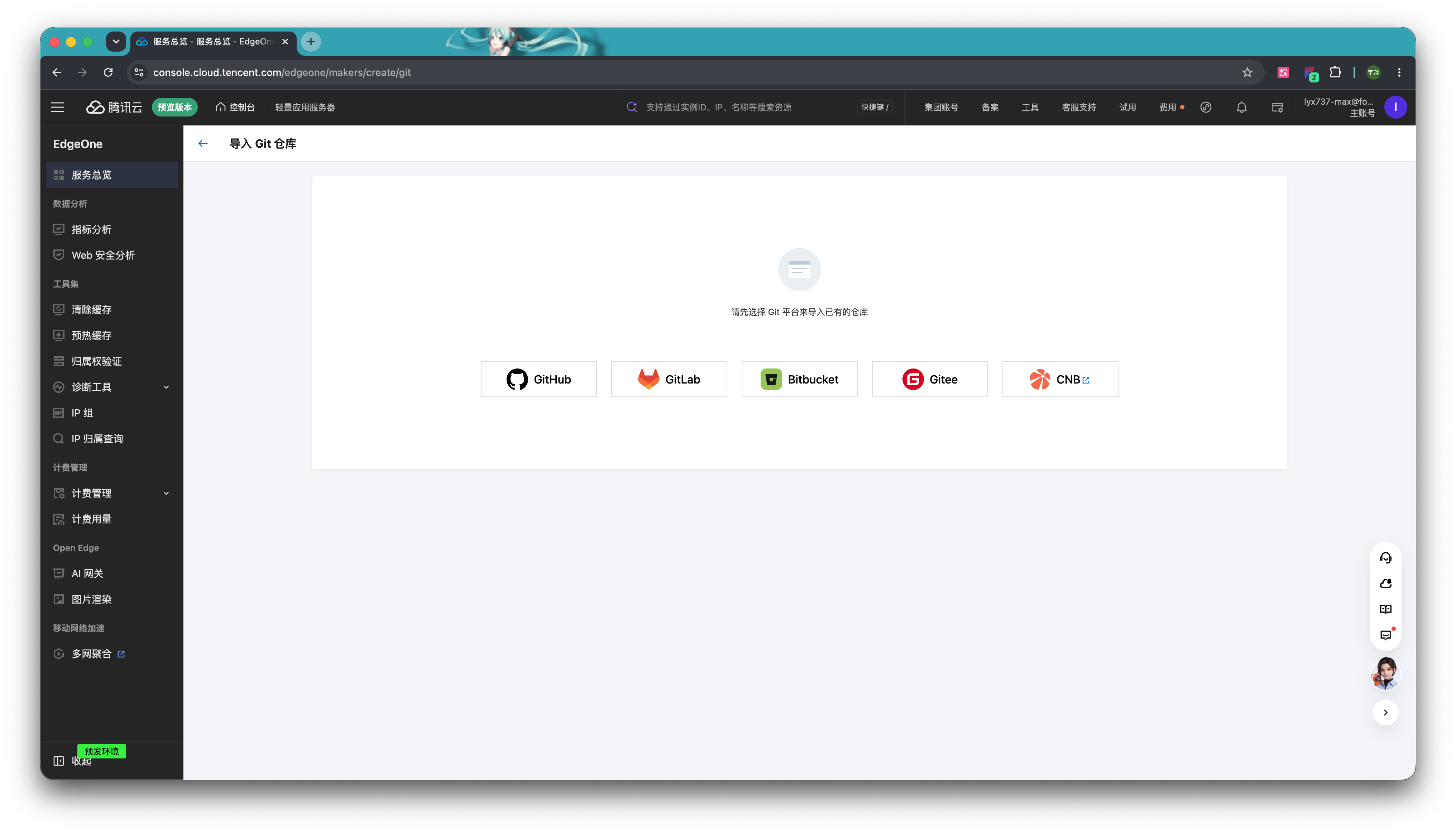
这里会弹出一个弹窗,登录 Github 账号,安装 EO Pages,默认会授权访问所有仓库,你也可以修改为只允许访问指定仓库。然后点击「Install」。
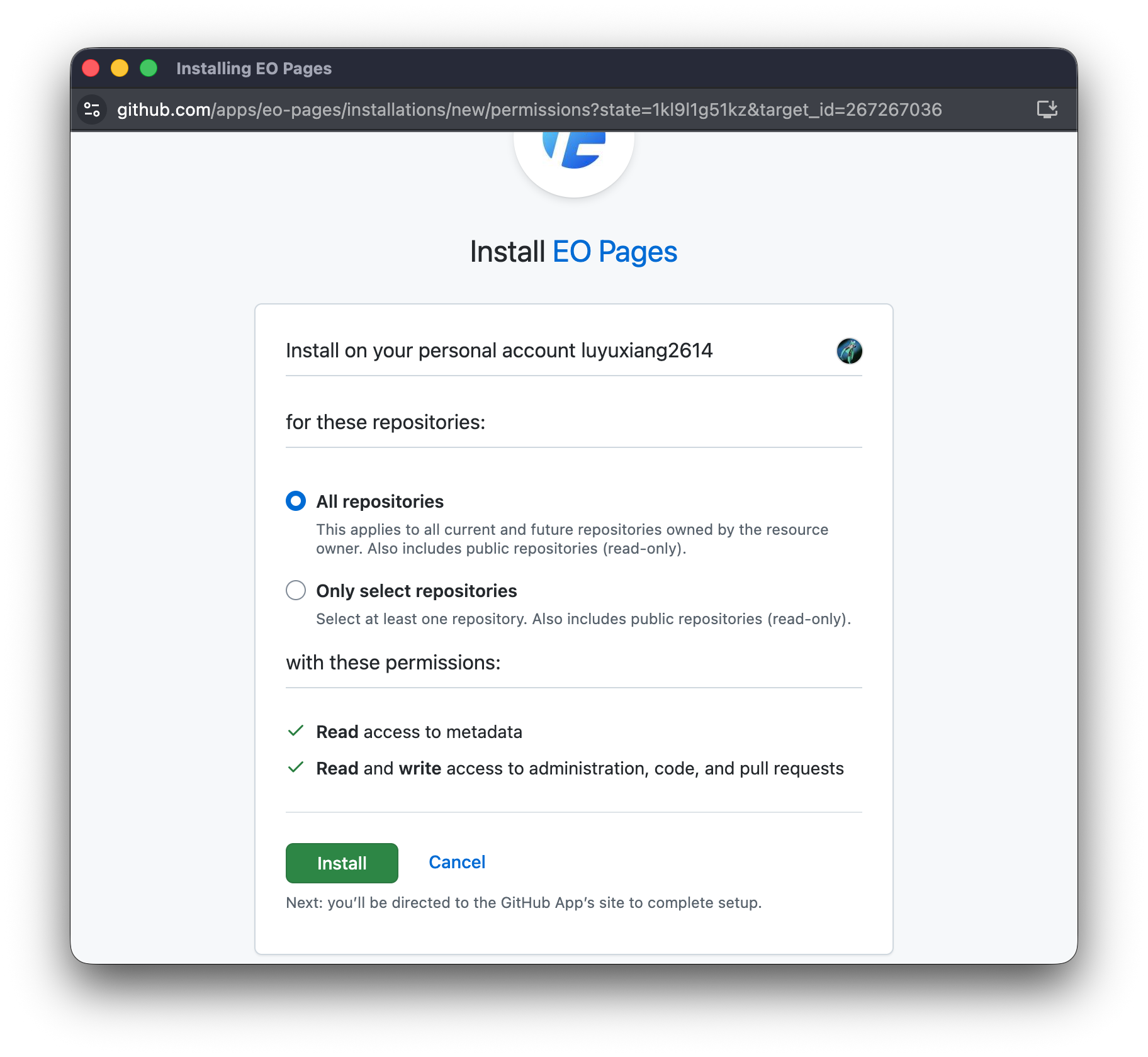
这样,就授权完成了。可以在仓库列表中选择刚才上传好的仓库。
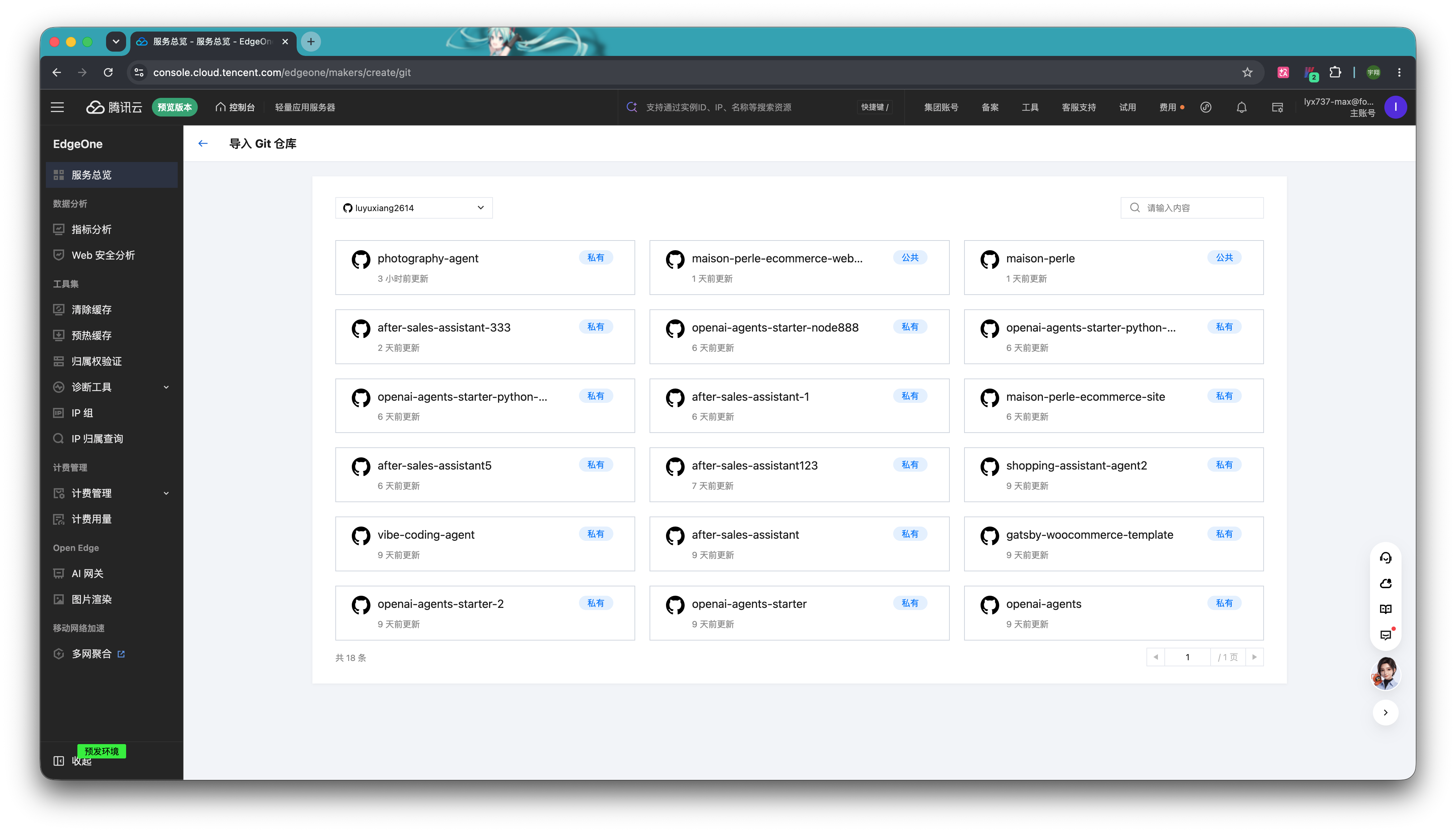
默认选择的是仓库的 main 分支,如果打算托管特定的分支也可以手动搜索修改。
然后根据自身需求选择加速区域。需要注意的是,如果加速区域保包含中国大陆,则腾讯云账号必须完成实名认证,且仅支持完成 ICP 备案的自定义域名绑定。如果您没有提供中国大陆区域访问的需求,可以选择全球可用区(不含中国大陆)。
点击环境变量,在这里填入我们上面提到的几个变量名和变量值。
AI_GATEWAY_BASE_URL=https://ai-gateway.edgeone.link/v1
AI_GATEWAY_API_KEY=sk-xxx......xxx
AI_GATEWAY_MODEL=@makers/hy3-preview
SUPABASE_URL=https://xxx.supabase.co
SUPABASE_SERVICE_ROLE_KEY=xxx......xxx如果你的 Agent 运行需要额外的环境变量,可以在这里一并填入。
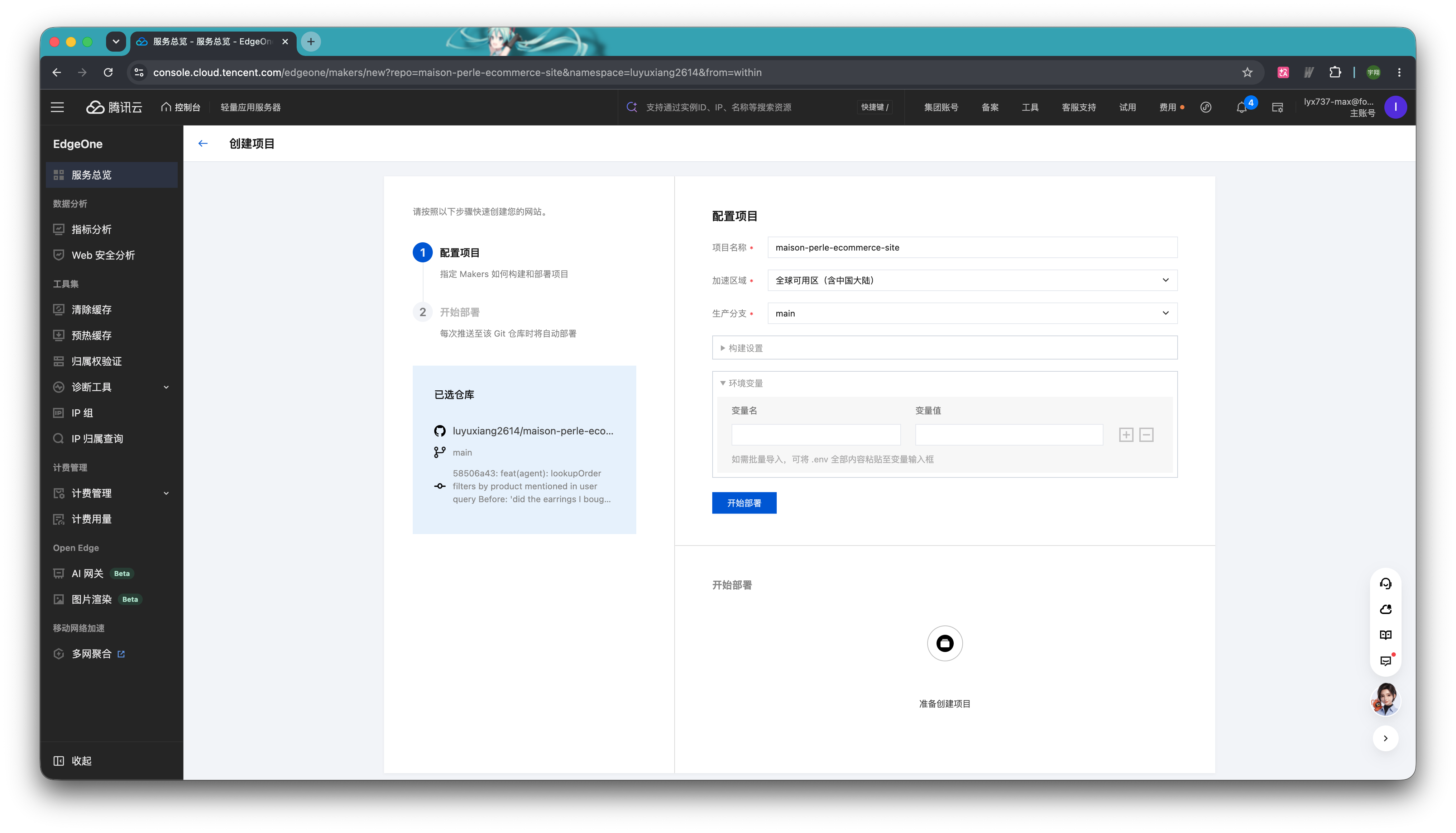
填写完成后点击「开始部署」,接下来等待部署完成即可。
部署成功后,就可以点击右上角「预览」按钮,获取临时预览链接。
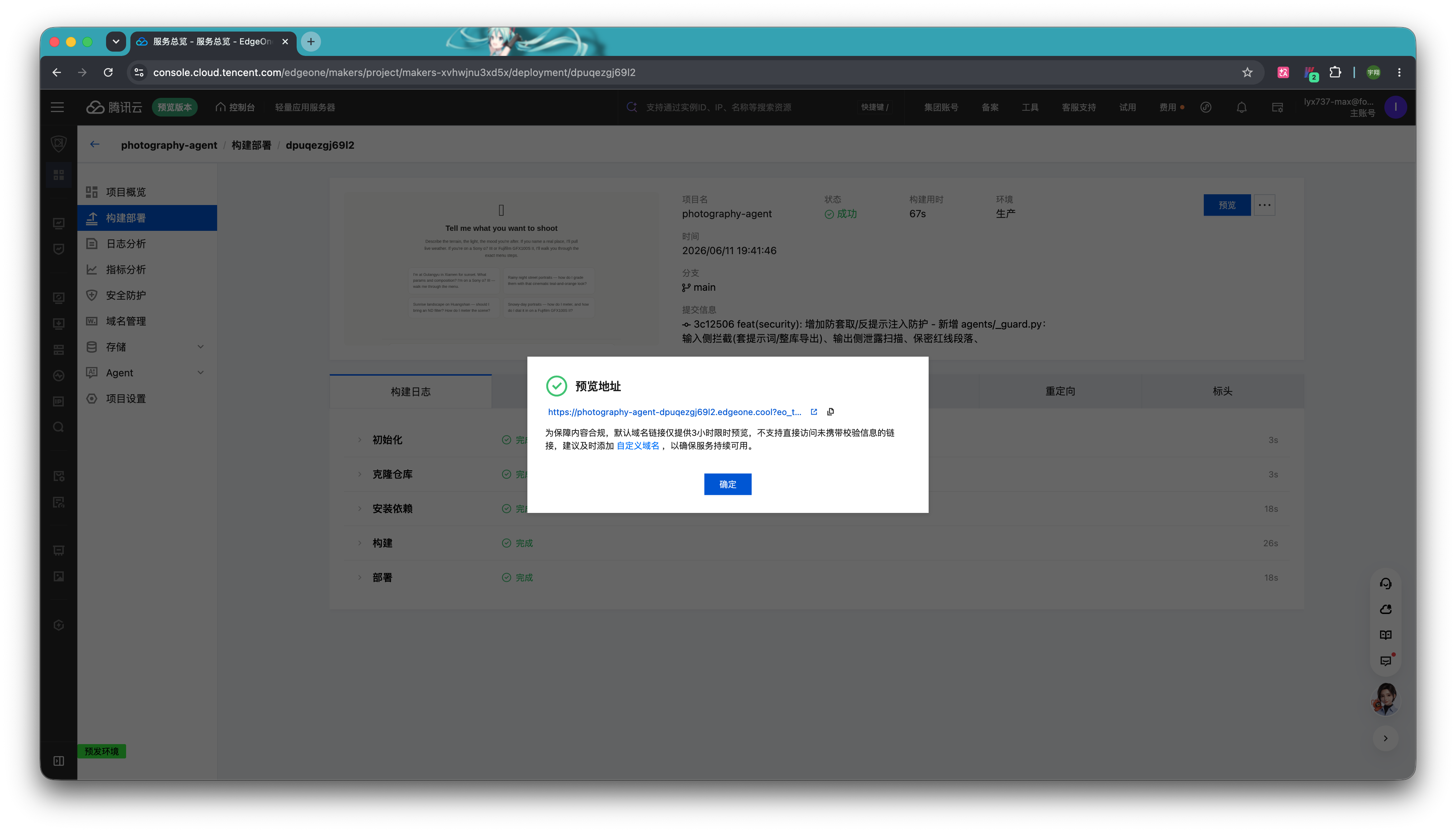
2.2 Workbuddy上传
如果你是在 Workbuddy 上开发,那么可以安装我们提供的 Skill:
npx skills add TencentEdgeOne/edgeone-makers-tools这个 Skill 会先检查你有没有装 EdgeOne CLI,没有的话自动帮你配置。接着,它会问你两个问题:你用的是腾讯云国内站账号还是国际站账号,以及你打算怎么登录。
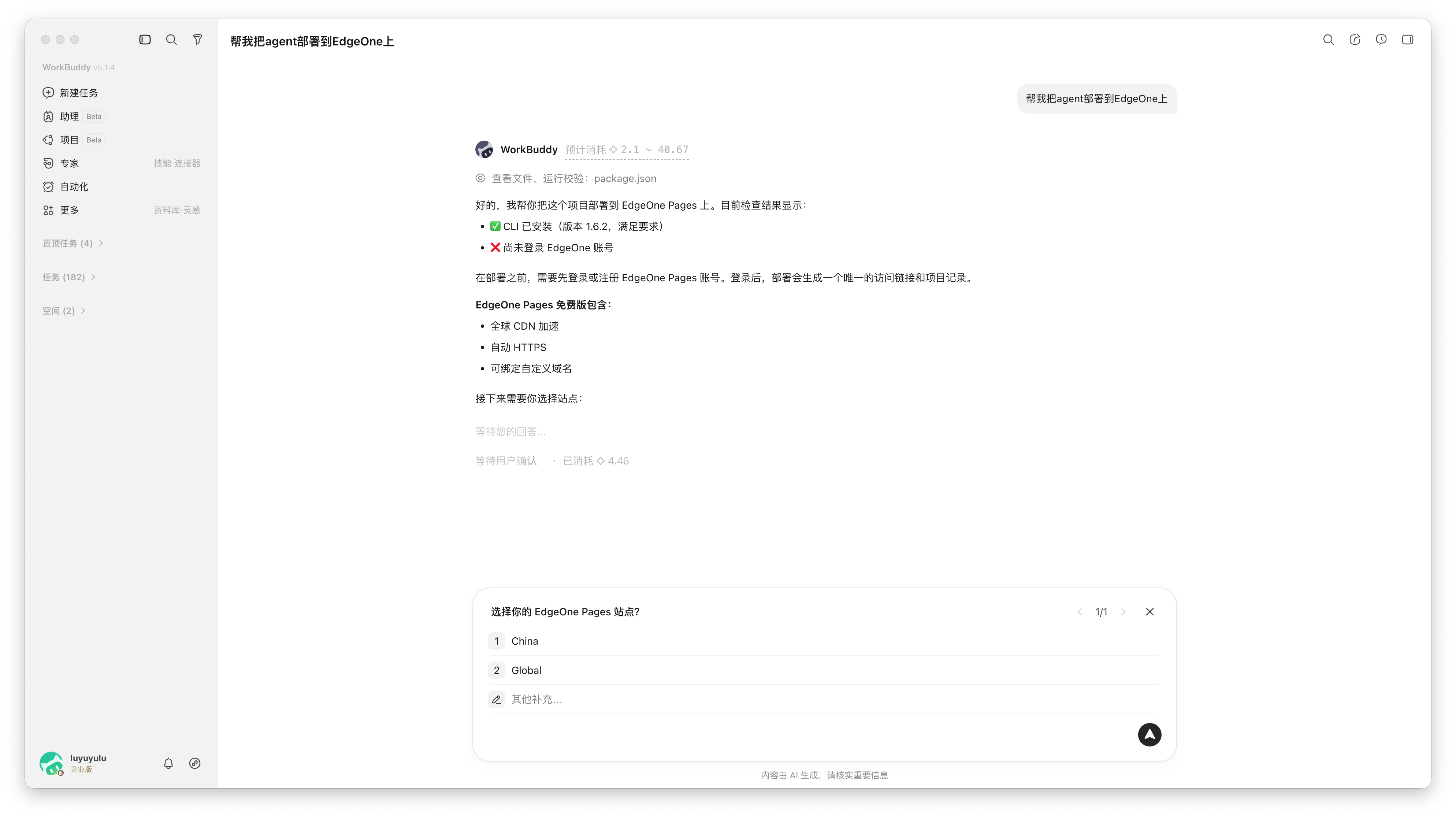
通常情况下,Workbuddy 会在浏览器中弹出腾讯云登录页,完成授权即可。如果你在特殊环境或者浏览器没法弹出,则会切换到 Token 登录模式,可以自行在 Makers 控制台的设置中生成 API Token,粘贴回来即完成授权。
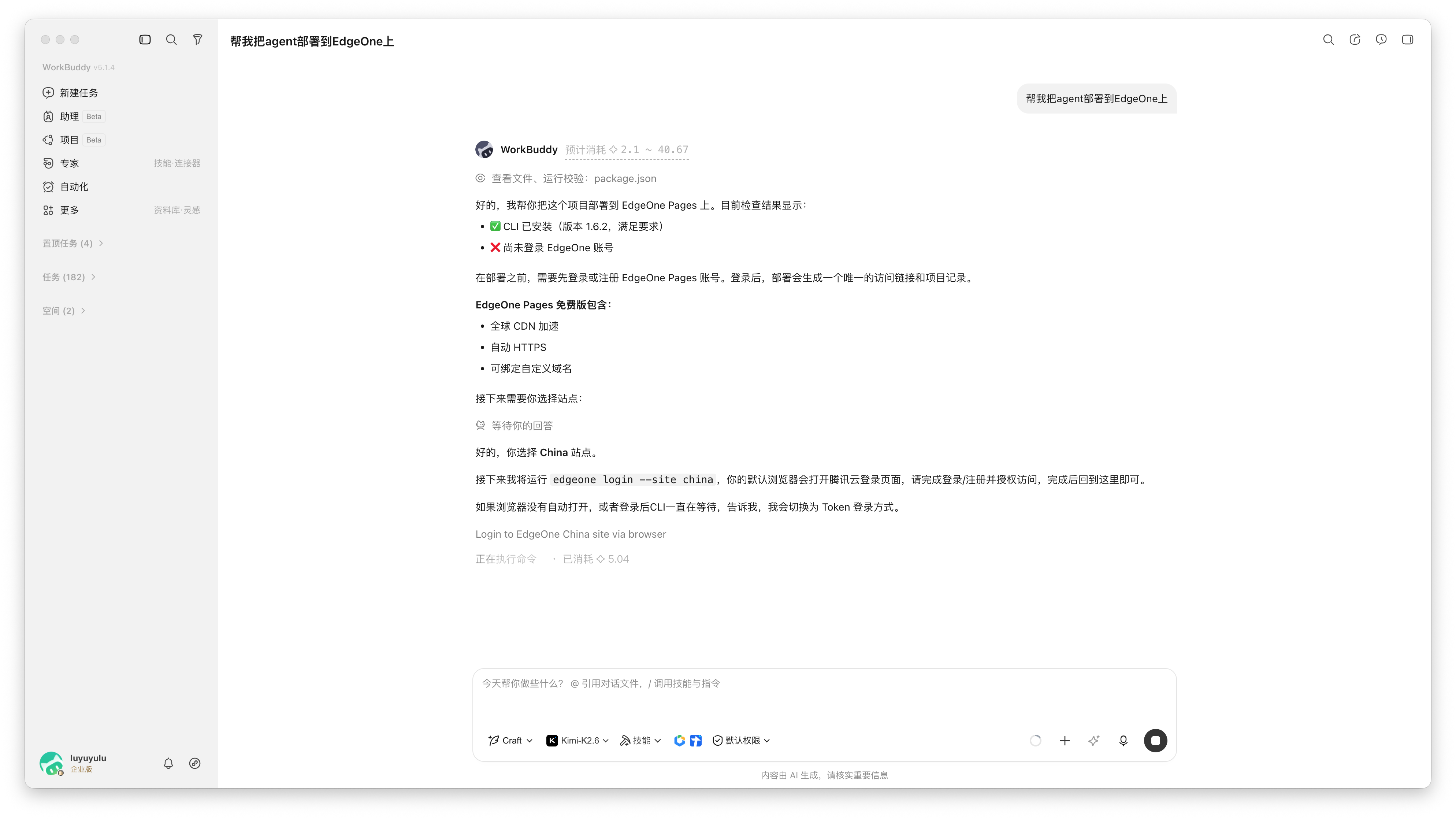
登录完成后,需要手动在项目设置页里上传环境变量,并再重新部署一次。
部署成功后,就可以点击项目右上角「预览」按钮,获取临时预览链接。
3. 自定义域名
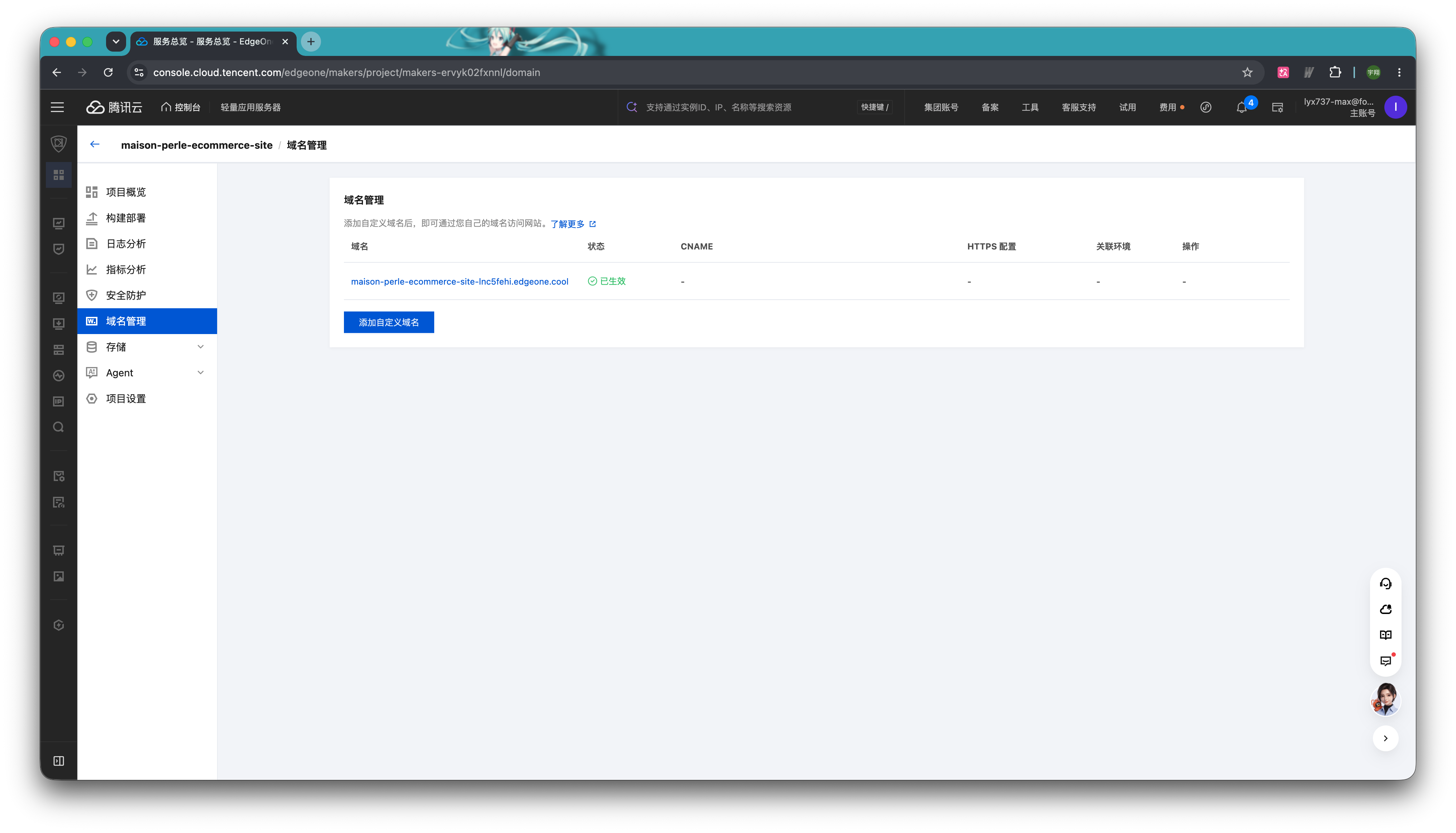
为保障内容合规,默认域名链接仅提供3小时限时预览,这个时候可以先对 Agent 做快速的正常运行测试。如果有对外提供访问或者长期使用的打算,建议及时添加自定义域名以确保服务持续可用。
点击「自定义域名」,或者直接点击左边的「域名管理」选项卡,就能来到域名管理页面。在这里能看到 EdgeOne 提供的默认临时域名。
点击「添加自定义域名」按钮,可以绑定你自己拥有的域名。
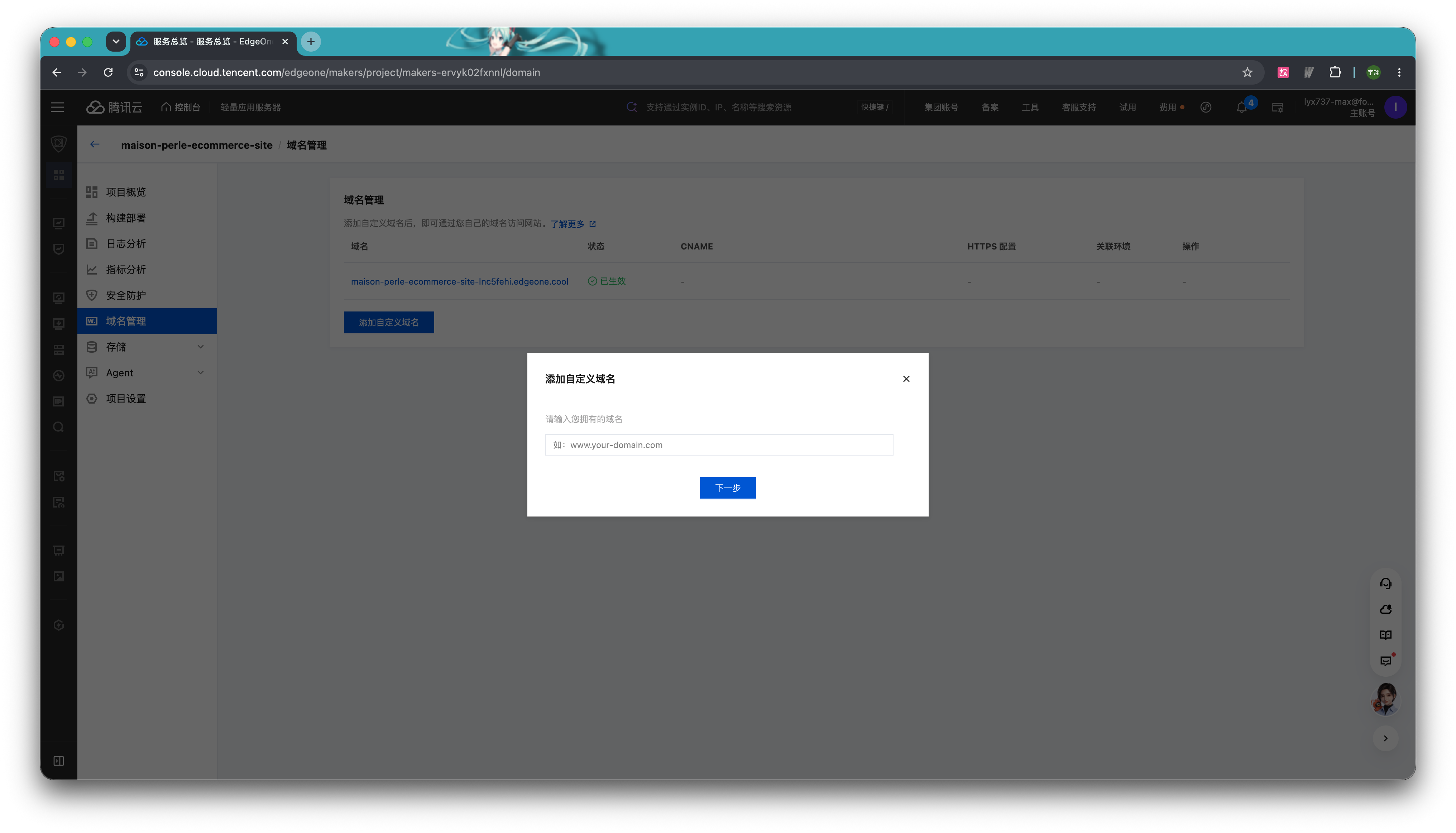
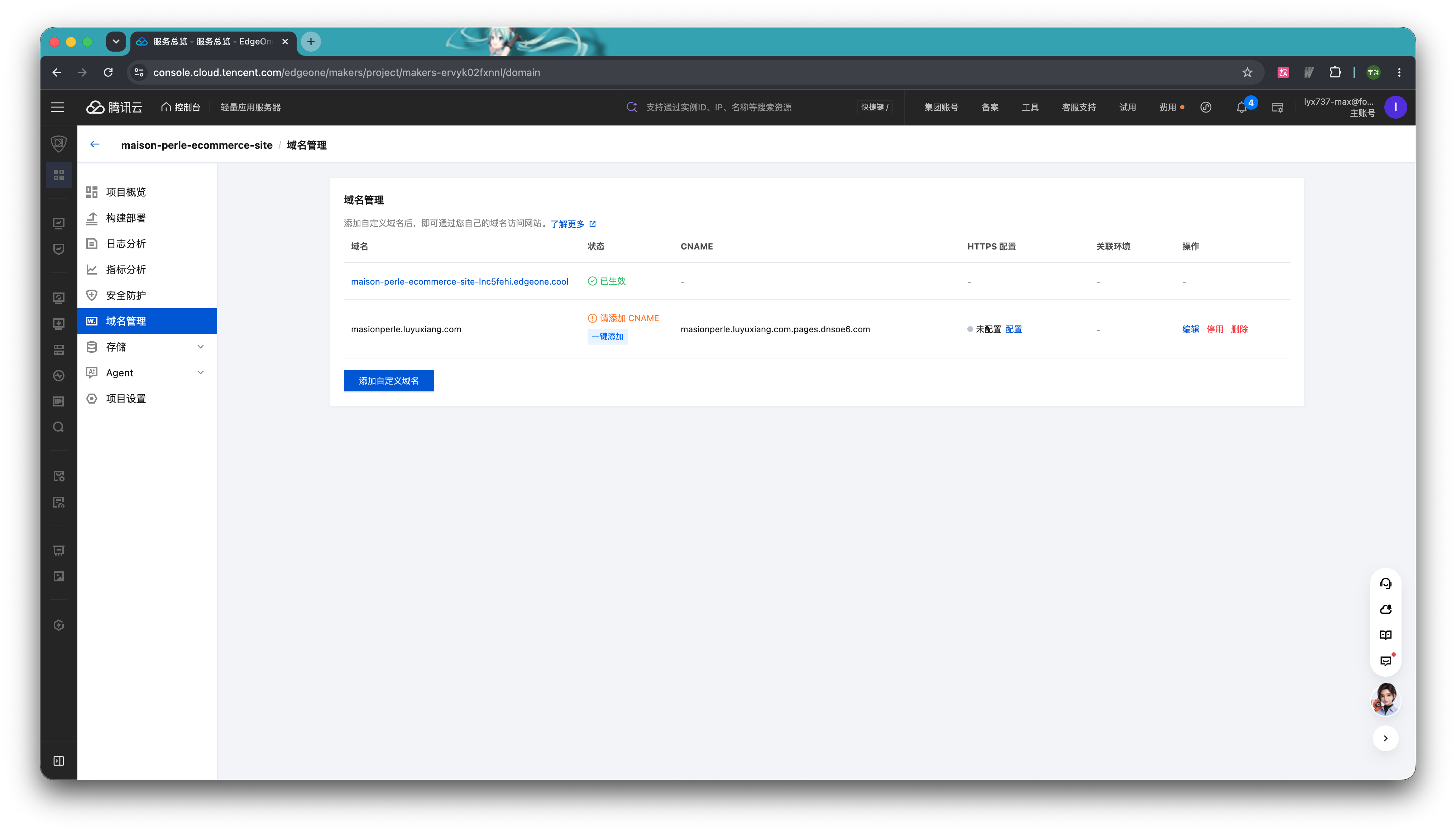
添加完域名后,需要手动调整域名的 CNAME 解析和配置 HTTPS。
如果你的域名注册在腾讯云的话,可以一键添加 CNAME 解析,等待一分钟即可生效。或者去你所使用的域名控制台手动修改解析。
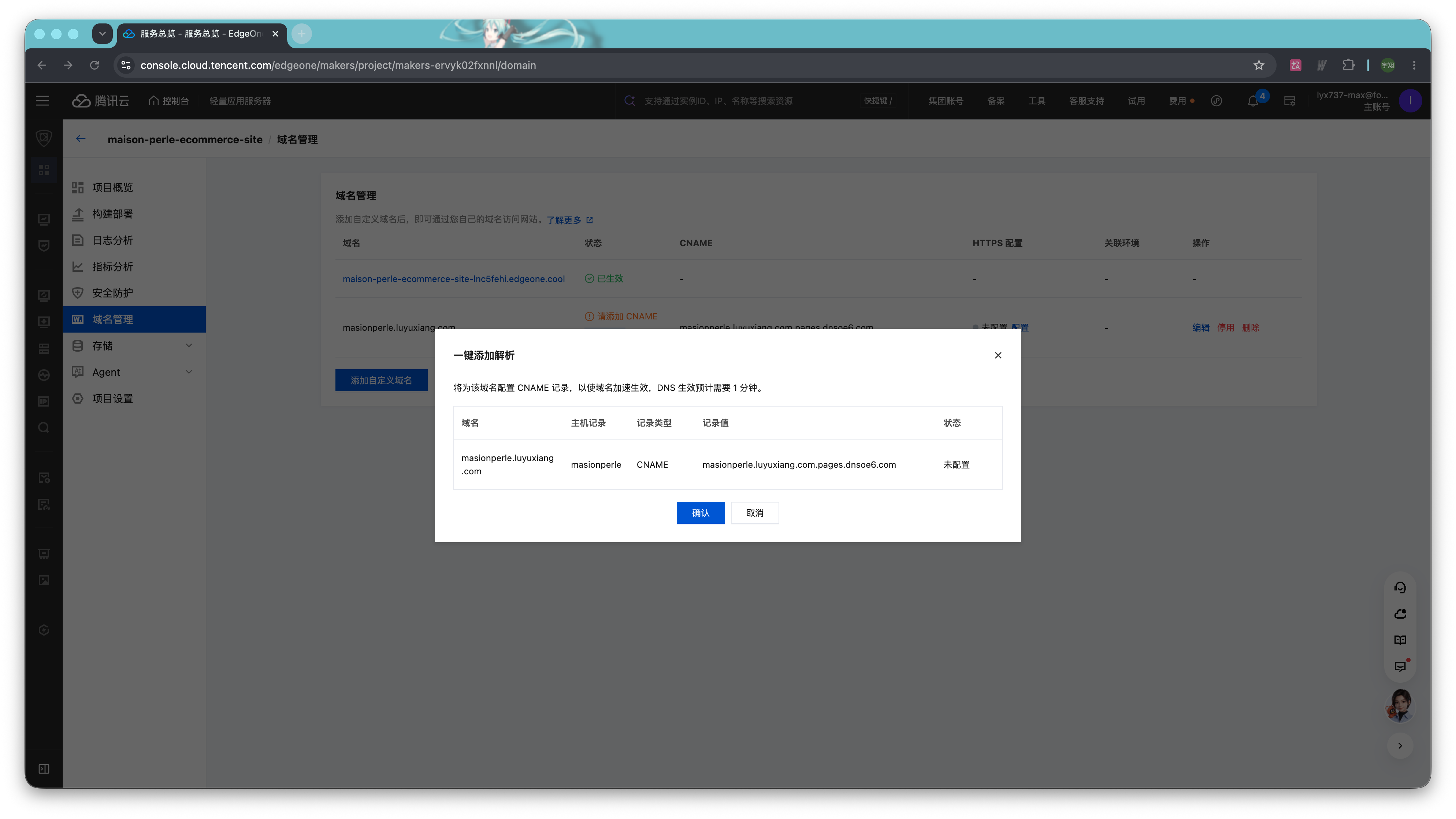
HTTPS 配置则需要进一步操作。点击 HTTPS 配置列的「配置」按钮,再点击「边缘 HTTPS 证书」方框里的「配置」。
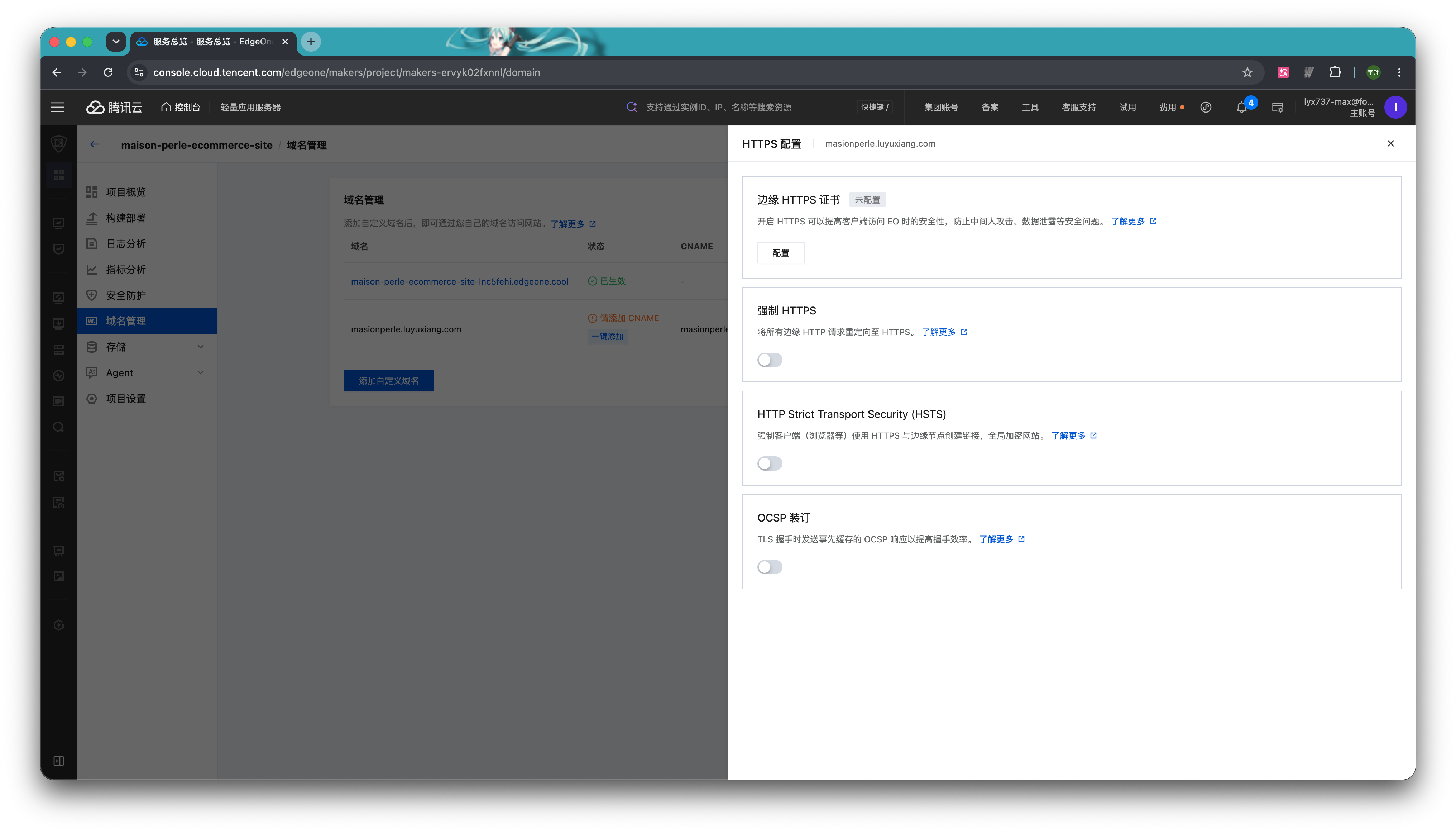
EdgeOne 提供了两种配置方式。第一种是针对没有证书但想实现 HTTPS 访问的用户。选择「申请免费证书」,EdgeOne 提供可自动申请、自动续签、自动部署的免费证书。
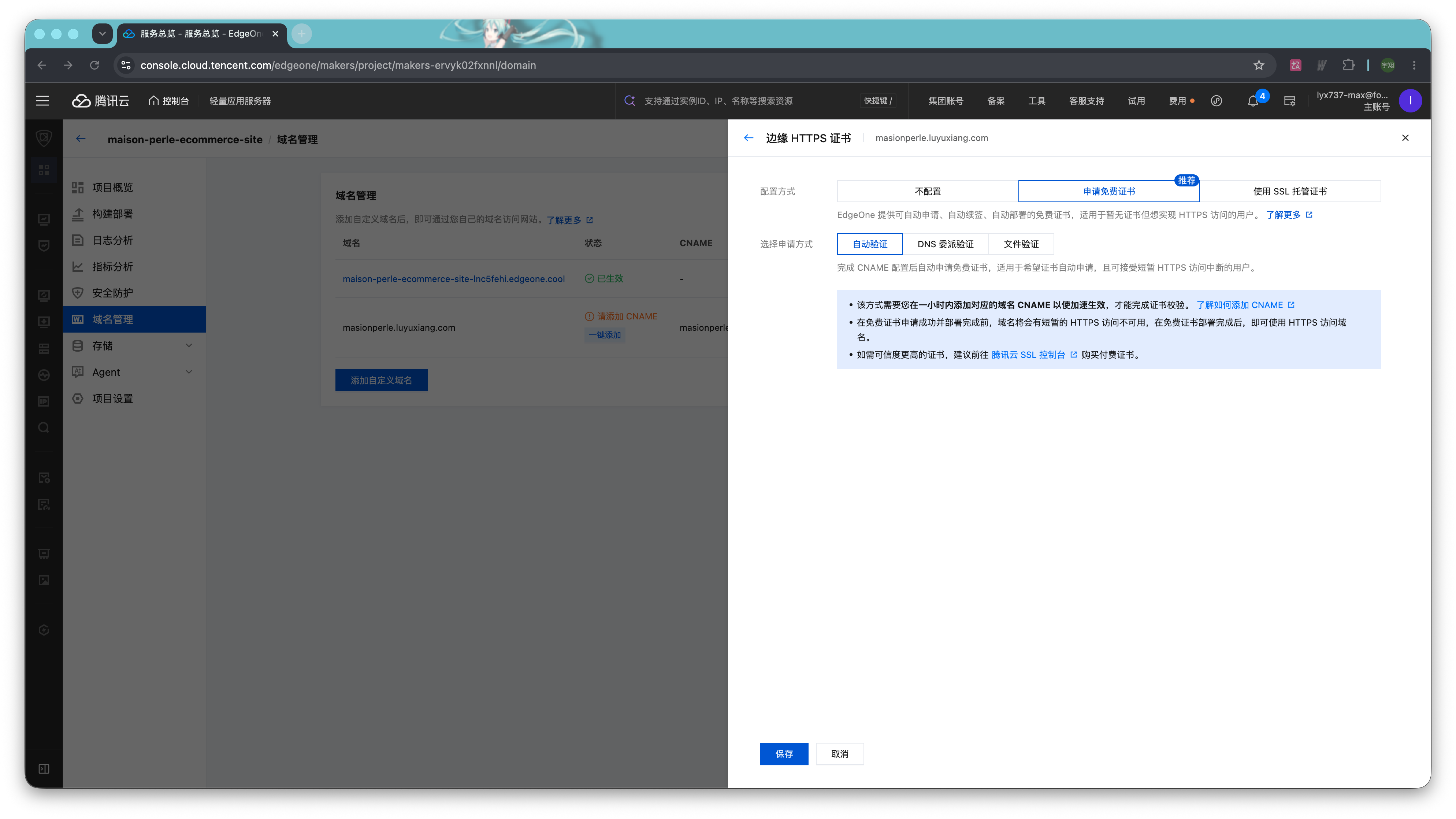
第二种则适用于已有 SSL 证书的用户。选择「申请 SSL 托管证书」可以将托管在腾讯云内的 SSL 的证书部署至 EdgeOne。
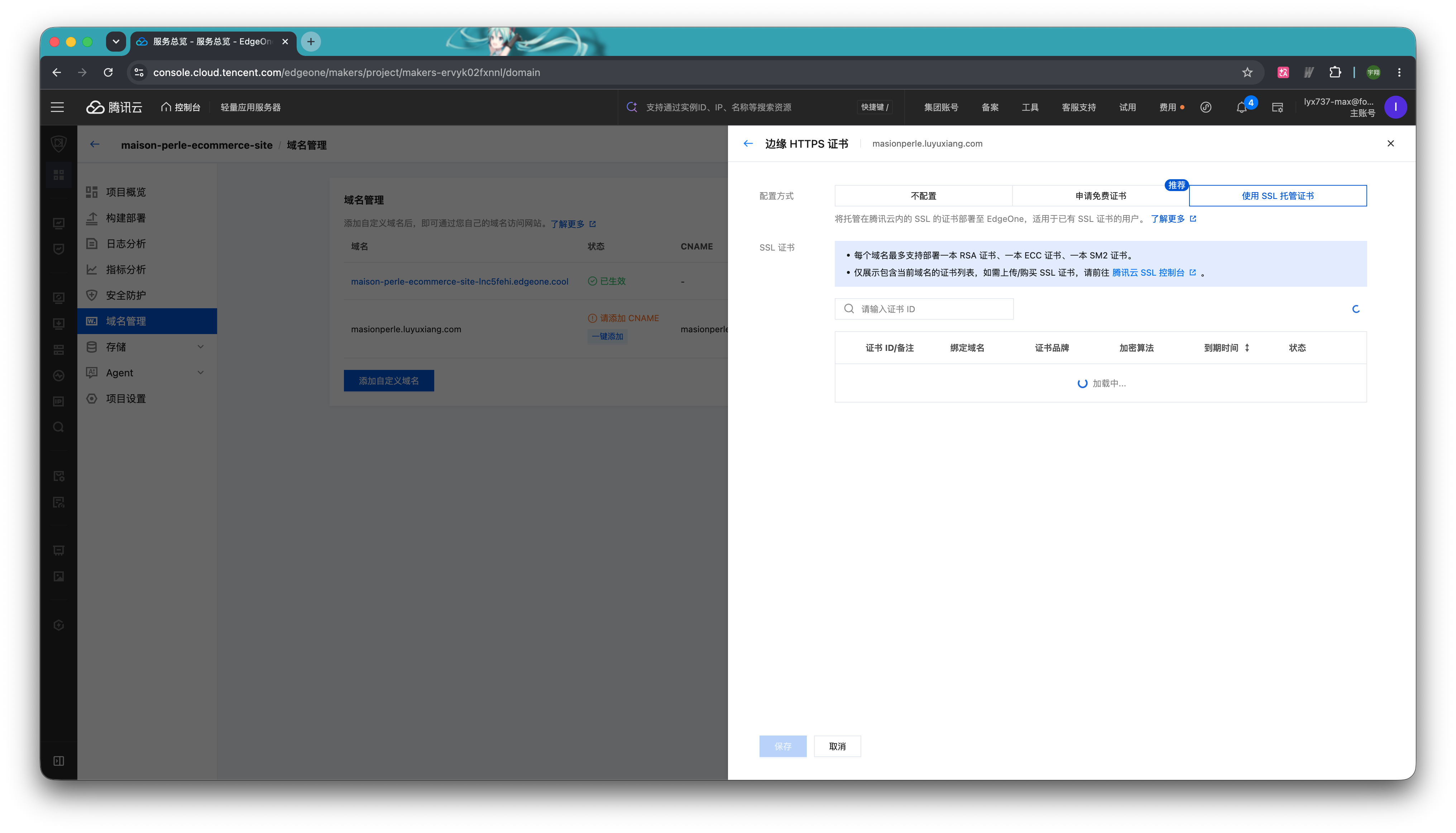
完成这两项配置后,就可以通过你的自定义域名访问了。
4. 观测能力
Agent 部署上线以后,另一个很重要的问题是:它到底有没有按预期运行?
普通 Web 应用出问题时,我们通常还能看接口日志、错误堆栈、请求耗时。但 Agent 应用的执行链路更长:用户发起一次对话后,模型可能会先理解问题,再调用工具,工具返回结果后模型再继续组织回答。如果中间某一步表现异常,只看最终回复很难判断问题出在哪里。
Makers 提供的观测能力,解决的就是这个问题。它会自动记录 Agent 的运行过程,不需要开发者从零搭一套日志系统。无论是在本地调试,还是部署到线上,都可以通过观测面板看到 Agent 的调用情况。
我们可以在 Makers 平台中点击要查看的项目,在左侧标签中展开「Agent」,可以看到Metrics 和 Traces 两个观测面板。
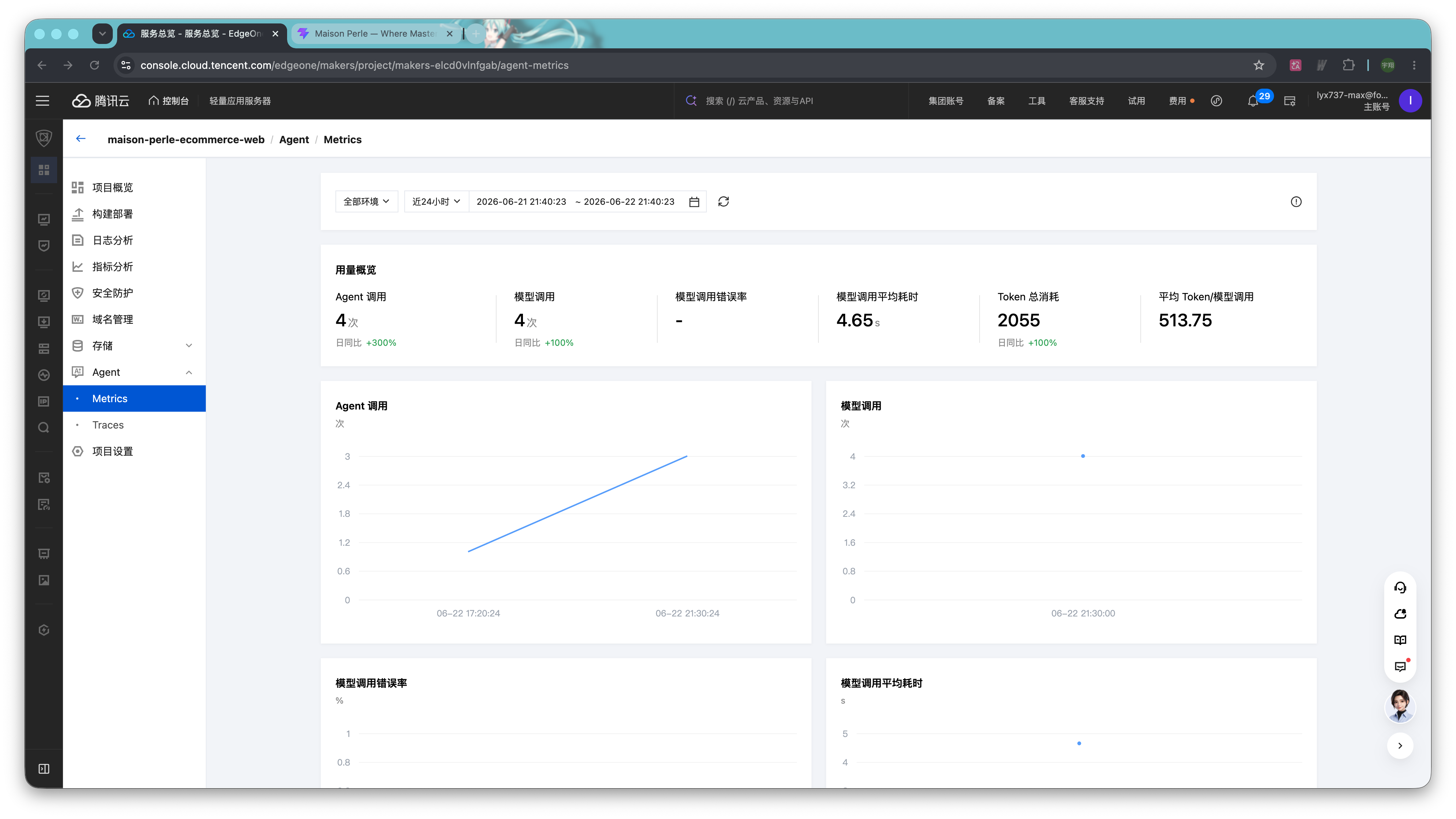
Metrics 更适合看整体状态。比如 Agent 一共被调用了多少次、模型调用了多少次、平均耗时是多少、Token 消耗情况如何、有没有出现错误。它适合用来判断服务整体是否正常:是不是调用量上来了、是不是某个阶段变慢了、是不是 Token 消耗异常。
而 Traces 则更适合看单次执行细节。
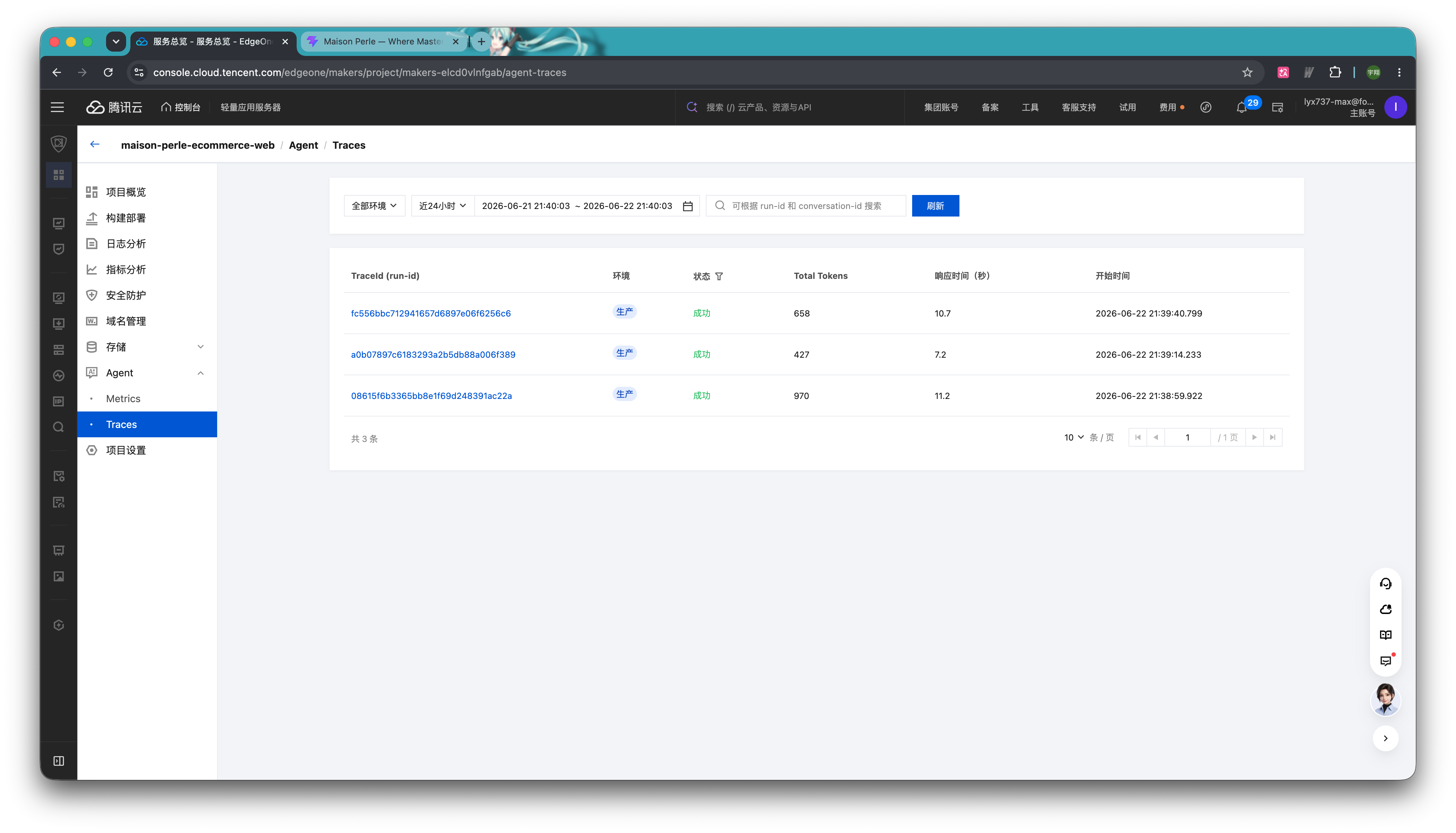
每一次 Agent 请求都会形成一条完整的调用链。展开后可以看到这次请求里模型调用了几次、调用了哪些工具、工具入参是什么、返回了什么、每一步耗时多久。如果某一步报错,也可以直接在对应节点看到错误信息。有了观测能力,开发者就不是靠猜来修 Agent,而是能沿着链路定位问题。对于 MVP 来说,这一点很重要:早期用户反馈往往很碎,只有把运行链路看清楚,才能判断是 Prompt 要改、工具要改,还是外部依赖要替换。
5. 构建版本
在构建部署页,你可以管理所有托管代码的版本,点击「更多」按钮还可以实现版本回滚。迭代过程中的每一次改动都有可能引入新问题,Makers 的构建版本和回滚能力,可以让开发者在新版本异常时先恢复到上一个稳定版本,再慢慢排查原因。这样 Agent 可以持续迭代,但线上服务不至于因为一次改动导致长时间不可用。
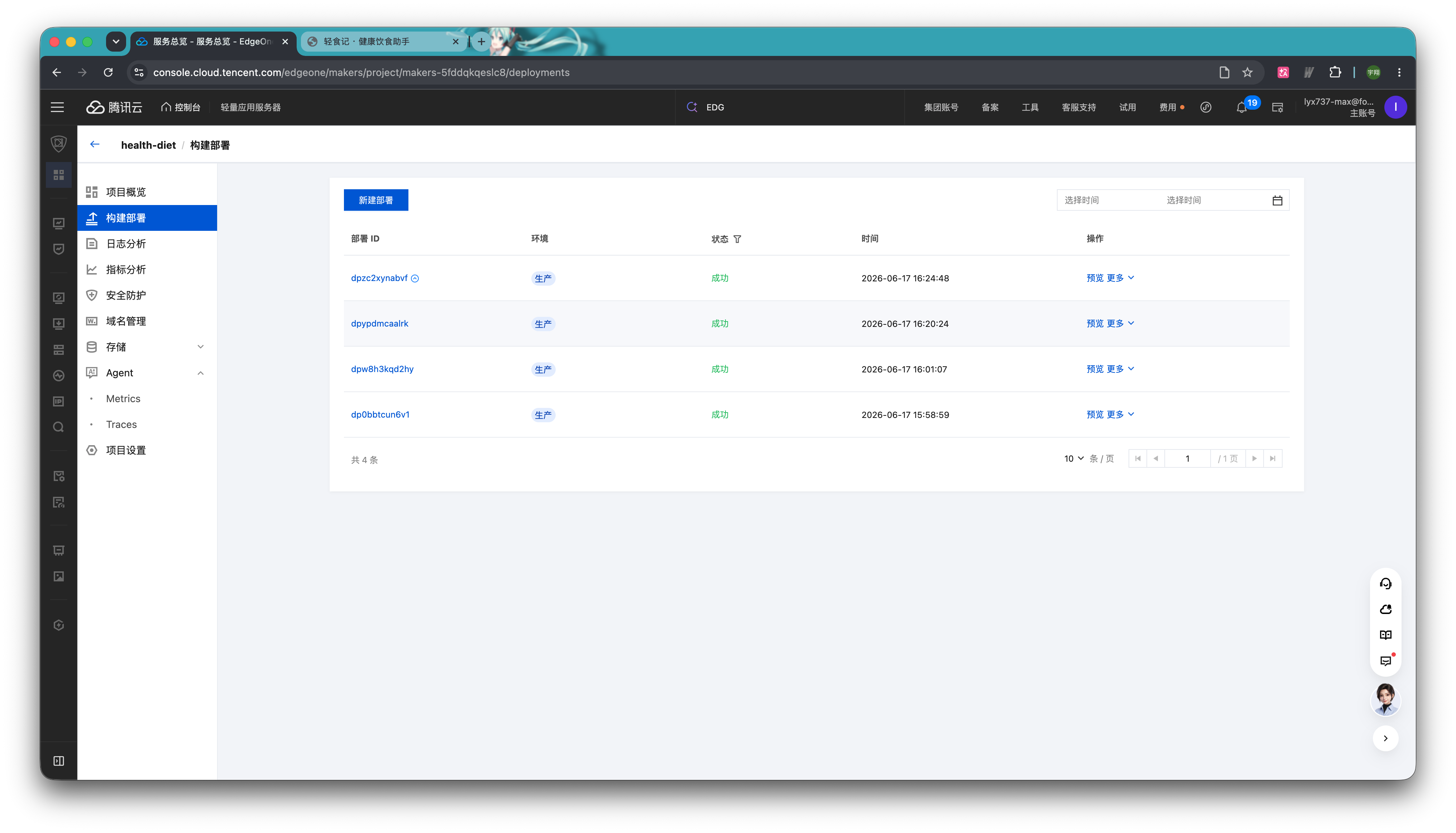
假设你对 Agent 代码进行了调整,想要同步到平台构建新版本,有两种方法能实现。
5.1 自动触发
如果你的代码托管在代码仓库,并且是使用代码仓库上传的形式部署的。那么只要再次往仓库的 main 分支推送新版本代码,Makers 平台会自动触发新建部署,无需额外操作。
5.2 手动构建
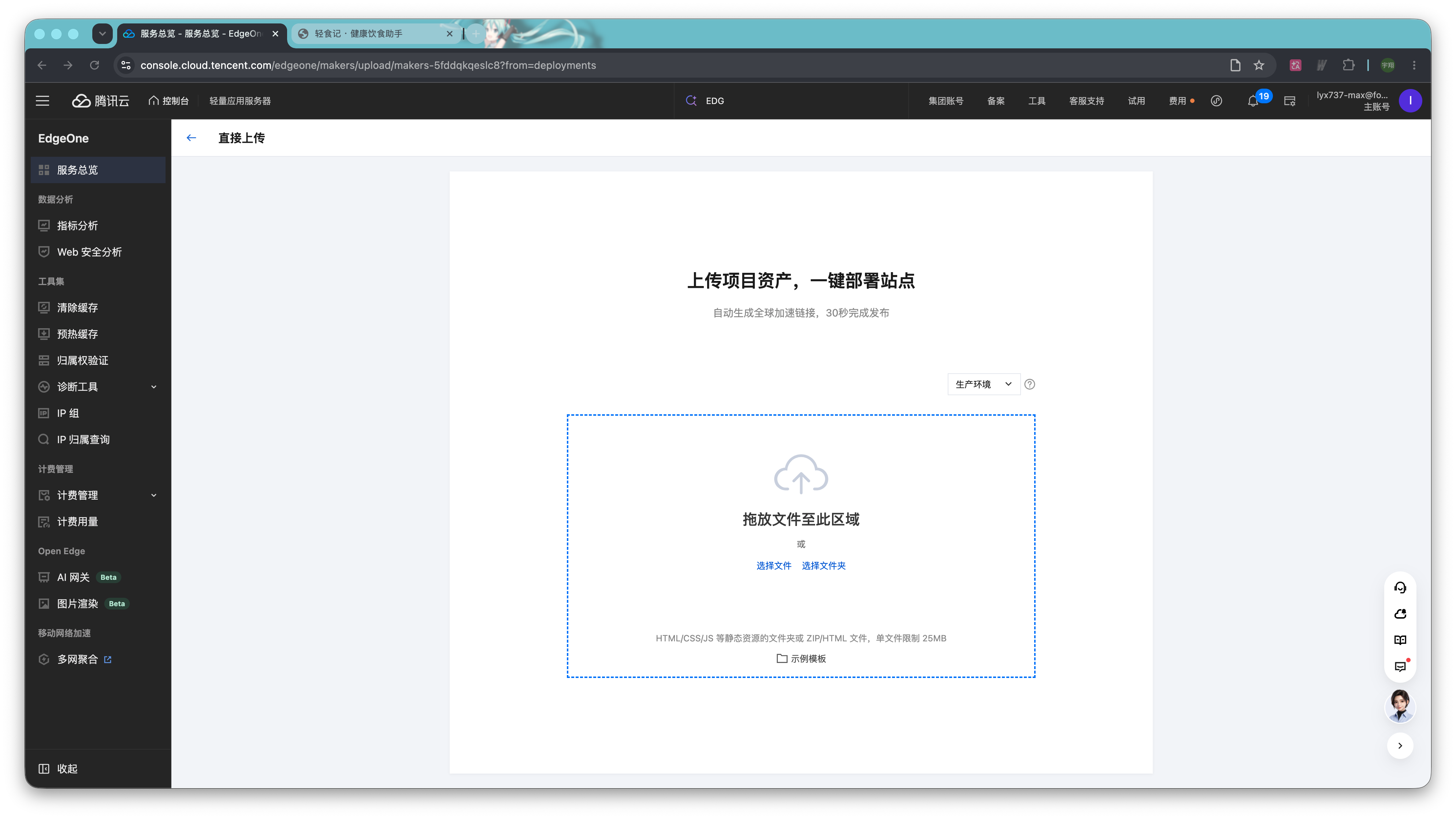
如果你的代码是本地上传,那么构建新版本时,需要进入项目的构建部署页。
点击「新建部署」按钮,上传新的代码文件或文件夹,再点击「开始部署」即可完成构建。
结语
到这里,我们就实现了基于 Makers 已经提供好的 Agent 模板,把珠宝电商场景里的商品知识、用户咨询、风格推荐和转化引导逻辑接入的全流程。先明确 Agent 要帮用户解决什么问题,再整理商品信息、材质参数、款式特点和常见问答,把商品理解、导购推荐、用户追问和咨询转化串成完整链路,最后通过部署、观测和持续迭代,让它真正变成一个能承接用户咨询、提升选购效率的智能导购工具。
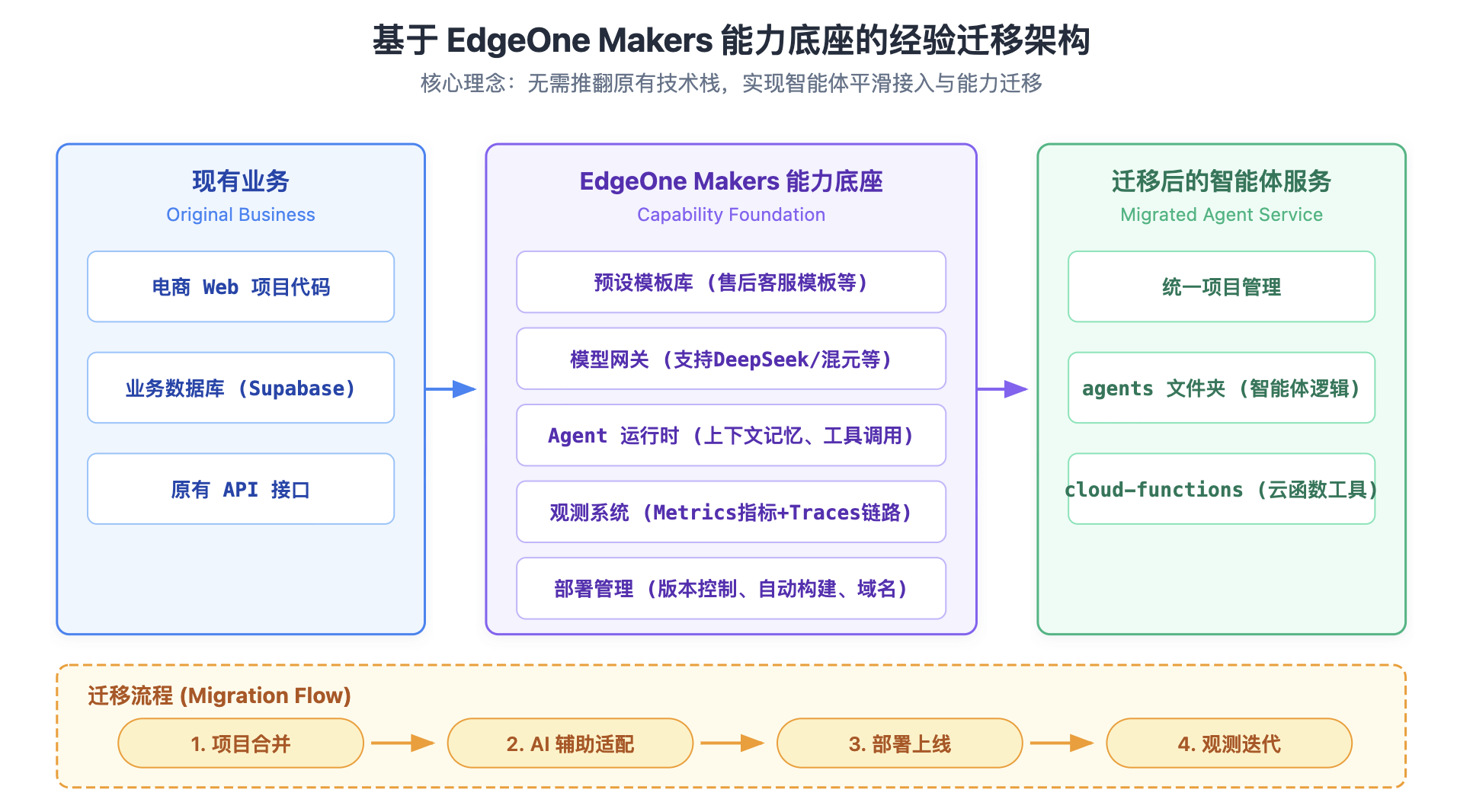
这也是 Makers 的价值所在。它没有把开发者锁定在某一种框架、语言或模型里,而是把模型接入、工具调用、上下文记忆、沙箱运行、观测排查和部署上线这些通用能力提前打通。开发者真正需要关注的,是自己的业务场景:珠宝商品该如何被理解,用户在选购时最关心哪些细节,怎样让推荐结果既符合审美偏好,又能服务实际的购买决策。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号