从 64 到百万租户:Milvus 多租户选哪层,别撞上 65536 的天花板
原创
从 64 到百万租户:Milvus 多租户选哪层,别撞上 65536 的天花板
原创
术哥
发布于 2026-06-21 12:45:44
发布于 2026-06-21 12:45:44
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 144 篇,Milvus 最佳实战「2026」系列第 13 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

Milvus 多租户四层频谱与隐藏约束
图 1:Milvus 多租户全景——四层频谱、65536 隐藏约束与演进时间线
Milvus 官方文档里有句很抓人的话:单个集群支持百万级租户。这个数字对做 SaaS、RAG 和 Agent 平台的团队吸引力不小——百万租户要是每个租户单独建一张表,关系型数据库早就顶不住了。
但翻完官方的多租户文档(multi_tenancy.md),你会发现它给了一张四种策略的对比表,却没回答一个更要紧的问题:为什么是四层,而不是一层?这四层之间到底是什么关系?
要搞清楚这个,光看文档不够,得回到源码和版本演进里找答案。翻完一圈源码(截至 2026-06 的 master 分支)和社区 Issue,我大致理清了 Milvus 多租户的设计逻辑,它远比一张对比表复杂,也比大多数人想象的更工程化。
说明:本文内容基于 Milvus 源码(github.com/milvus-io/milvus,master 分支截至 2026-06)、官方文档(v2.6.x / v3.0.x)和 GitHub Issue/PR 分析整理而成,源码级验证基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置参数、容量约束和选型建议仅供参考,实际效果请以你的 Milvus 版本、集群规模和业务数据测试结果为准。如果有实际多租户使用经验,欢迎在评论区分享交流。
1. 四层粒度不是并列菜单,是一条隔离频谱
官方文档把四种策略摆成一张对比表:Database 级、Collection 级、Partition 级、Partition Key 级。这种排列方式很容易让人误以为它们是四个平行的选型,挑一个用就行。
但真去翻源码和配置默认值,结论完全不同。这四层其实是一条隔离强度递减、可扩展性递增的频谱,每一层都是在前一层的隔离天花板上做了一次可扩展性突围。
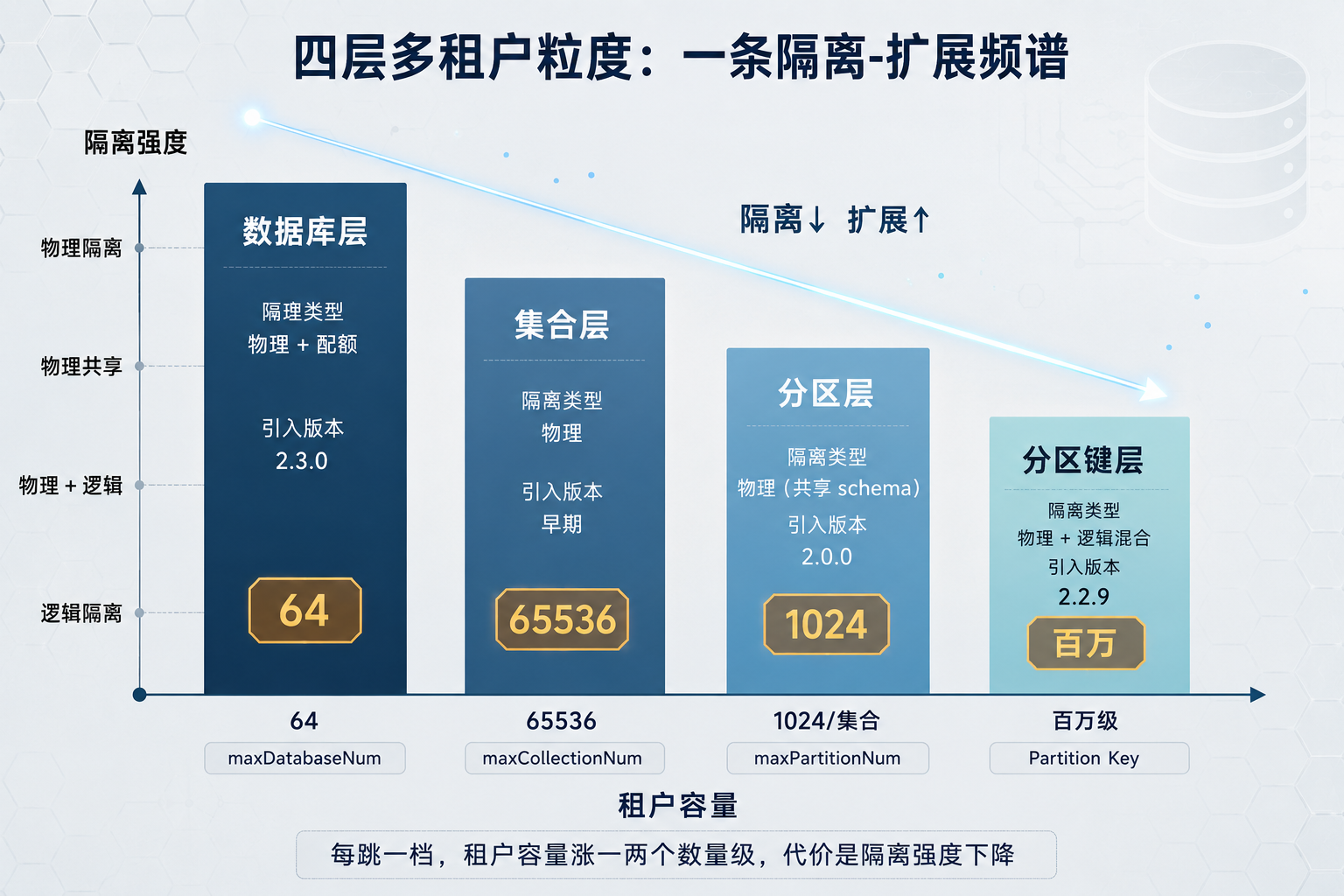
四层多租户隔离-扩展频谱图
图 2:四层多租户粒度的隔离-扩展频谱——横轴租户数(64→65536→1024→百万),纵轴隔离强度
先看四层的默认上限(均来自 configs/milvus.yaml 和 pkg/util/paramtable/):
层级 | 默认租户上限 | 引入版本 | 隔离强度 |
|---|---|---|---|
Database | 64( | 2.3.0 | 物理 + 配额容器 |
Collection | 65536( | 早期 | 物理 |
Partition | 1024 / collection( | 2.0.0 | 物理(共享 schema) |
Partition Key | 百万级 | 2.2.9 | 物理 + 逻辑混合 |
这四个数字摆一起就能看出规律:租户容量每跳一档,就涨一两个数量级,代价是隔离强度往下降一格。Database 只能撑 64 个租户,换来的是物理隔离加配额控制;Partition Key 能撑到百万,代价是多租户挤在同一个 collection 里,靠哈希路由做逻辑隔离。
每一层都在突破上一层的瓶颈
Zilliz 工程师 qinglingye 在 2023 年的一篇复盘(基于 2.2.8 时代)还原过 Partition Key 引入前的选型困境,三种方案全是死胡同:
- 每租户一个 collection:隔离强,但 collection 数量爆炸
- 每租户一个 partition:1024 的上限根本不够 SaaS 用
- 用标量字段
tenant_id做过滤:没有分区裁剪,每次查询全表扫描
前两种撞的是物理隔离的容量天花板,第三种撞的是逻辑隔离的性能天花板。Partition Key(2.2.9 引入,SegmentFault 官方特性稿和 PR #24995 可互证)就是为了同时打穿这两个天花板。
所以与其问该选哪一层,不如问你的租户密度在哪一档。据 qinglingye 的工程经验:ToC 场景(百万级租户)走 Partition Key,因为物理隔离不现实;ToB 场景(数万级租户)走 Collection 级,靠 2.3.4 之后的内存和协程优化撑起单集群数万 Collection;强监管场景走 Database 级。
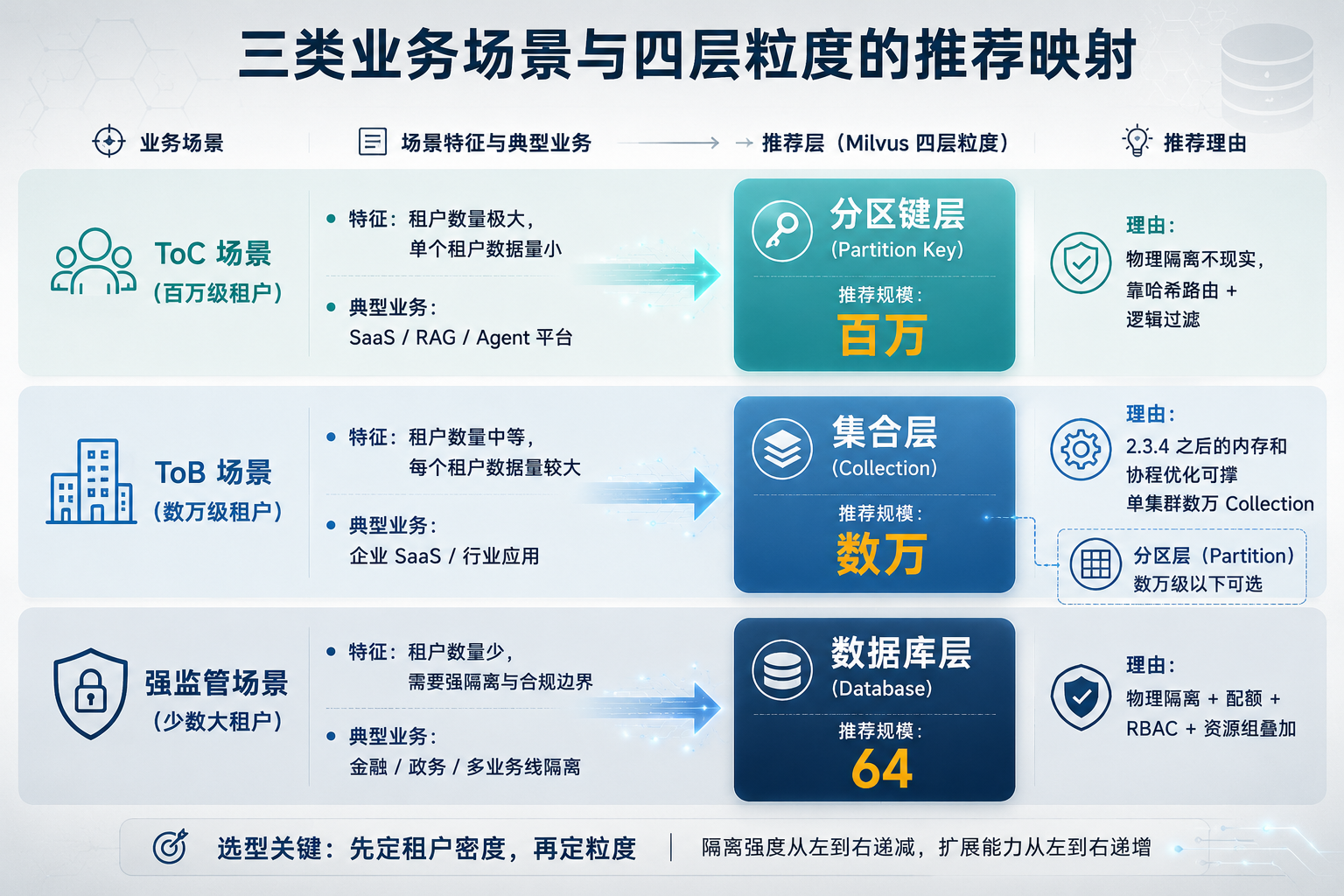
ToC/ToB/强监管场景映射图
图 3:ToC / ToB / 强监管 三类场景与四层粒度的推荐映射
2. Partition Key 的两面性:从性能优化变成安全机制
Partition Key 是四层里设计相当复杂、演进曲折的一层。它最早被设计成纯粹的性能优化手段,后来却在 SaaS 场景里被迫承担起安全职责——这条演变线很能说明 Milvus 多租户的补丁式成熟过程。
不是每租户一分区,是哈希到固定 16 桶
很多人对 Partition Key 有个误解:以为它是每租户一个物理分区。官方文档(multi_tenancy.md v2.6 和 v3.0 两版表述完全一致)其实写得很清楚:Partition Key 模式下,数据会被自动路由到 16 个物理分区。
这个 16 很关键。它意味着所有租户的数据是哈希分桶到固定的 16 个物理分区里,多个租户共享同一个物理分区。Partition Key 能扩展到百万级租户、隔离却比前几层弱,根子就在这——它不受每 collection 1024 分区的上限约束,靠的是逻辑过滤加分区裁剪。
路由用的是哈希取模,源码在 pkg/util/typeutil/hash.go 的 HashKey2Partitions:
switch scalarField.Data.(type) {
case *schemapb.ScalarField_LongData:
// Int64 走 murmur3 哈希
value, _ := Hash32Int64(key)
case *schemapb.ScalarField_StringData:
// String 走 crc32,截取前 100 字节
value := HashString2Uint32(key)
default:
return nil, merr.WrapErrParameterInvalidMsg(
"currently only support DataType Int64 or VarChar as partition key Field")
}
hashValues = append(hashValues, value%numPartitions)这里有个官方文档没提的细节:Int64 和 String 两种 key 类型用了完全不同的哈希算法。Int64 走 murmur3,String 走 crc32(而且只截前 100 字节)。另外 Partition Key 只支持 Int64 和 VarChar 两种标量类型,不支持向量字段(源码里直接 return 了不支持的类型错误)。
两种类型用不同算法这件事,文档里找不到任何说明,社区也没什么讨论,但它会影响你选 key 类型时的哈希分布均匀性。
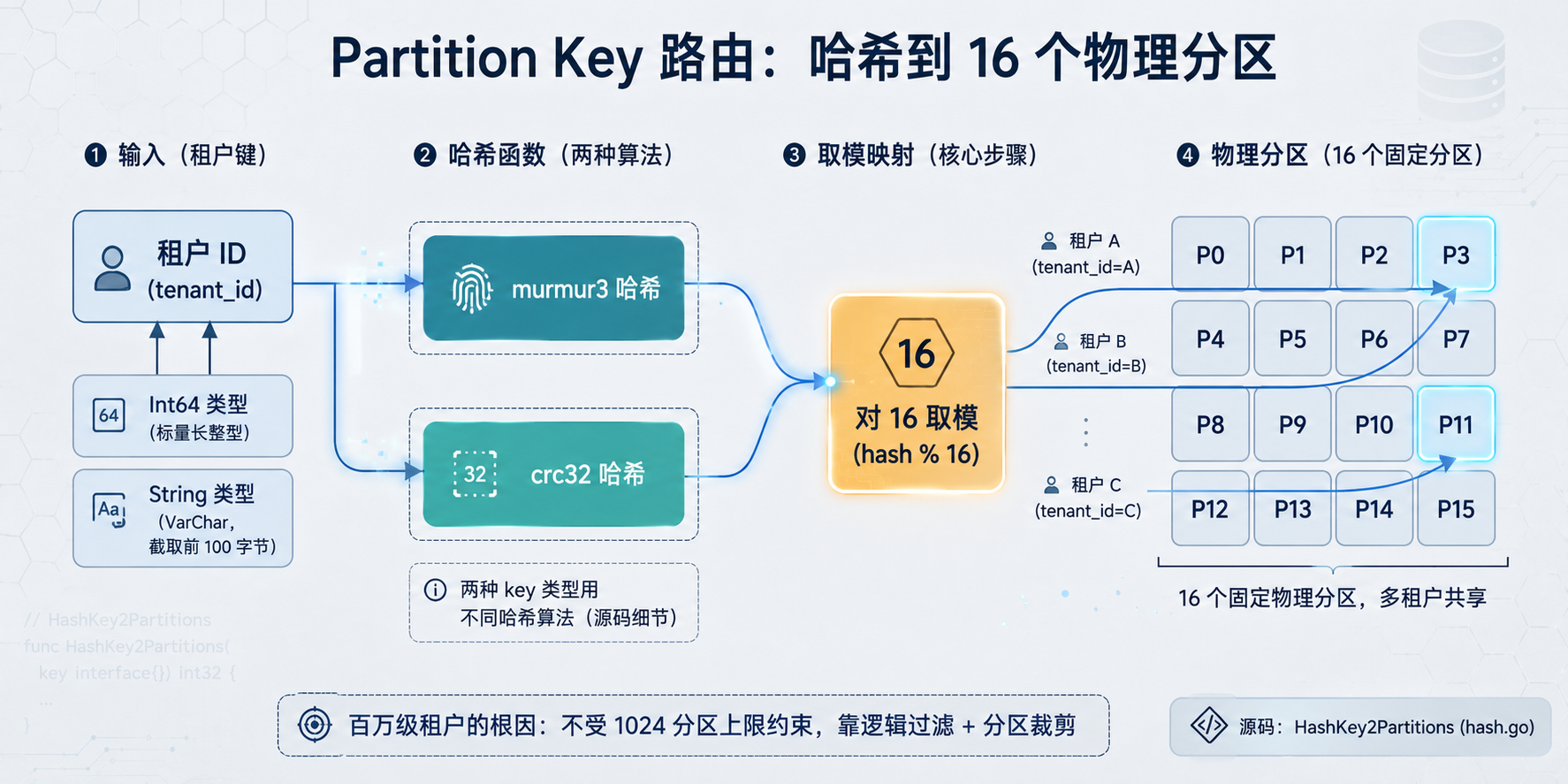
Partition Key 哈希路由流程图
图 4:Partition Key 路由与哈希流程——tenant_id 经 murmur3/crc32 哈希后对 16 取模,落到物理分区
跨租户泄漏:一个真实的正确性风险
Partition Key 默认只做路由优化,搜索时如果忘了带 partition key 过滤条件,系统会老老实实扫所有 16 个物理分区。对单租户场景这没所谓,但对多租户 SaaS 来说,这就是跨租户数据泄漏的口子。
2.4 版本针对这个问题加了个安全补丁:partitionkey.isolation(配置常量定义在 pkg/common/common.go:322)。开启后,搜索表达式必须包含 partition key 的等值过滤,否则直接拒绝执行。
校验逻辑在 internal/util/exprutil/expr_checker.go 的 ValidatePartitionKeyIsolation,规则很严格:
tenant_id == 42 && status > 0允许(AND 语义,能裁剪到单分区)tenant_id == 42 || status > 0拒绝(OR 语义下无法保证只命中单分区)- 不带
tenant_id的表达式直接拒绝
这个补丁的 PR 链很能说明它的演进节奏:#34869(2.4)引入属性,#35025/#35031 修复强制过滤逻辑,#42574(2.5)才在 storagev2 里补上索引支持。
但这个开关默认是关闭的。典型的工程取舍:默认保持性能和兼容性,把强隔离留给需要的人显式开启。代价是,不知道这个开关的用户,多租户隔离其实是裸奔的。
物化视图:isolation 的物理加速载体
翻开搜索路径的源码(internal/proxy/task_search.go 的 setQueryInfoIfMvEnable),会发现 isolation 的校验和物化视图(Materialized View)是绑在一起的。GitHub Issue #29892 的标题说得很直白:Materialized View 的设计目标就是 Improve Filtered Search on Partition Key。
两者是一体两面:isolation 是语义约束(强制你必须带 partition key 过滤),物化视图是物理加速(基于 partition key 预先构建分组视图,搜索时下推加速过滤)。isolation 强制带过滤条件,正是为了让物化视图能做分区裁剪。这俩设计放一起才讲得通。
3. 官方文档没强调的 65536
讲完 Partition Key,回头说一个官方文档几乎没提、但对多租户容量规划影响很大的隐藏约束。
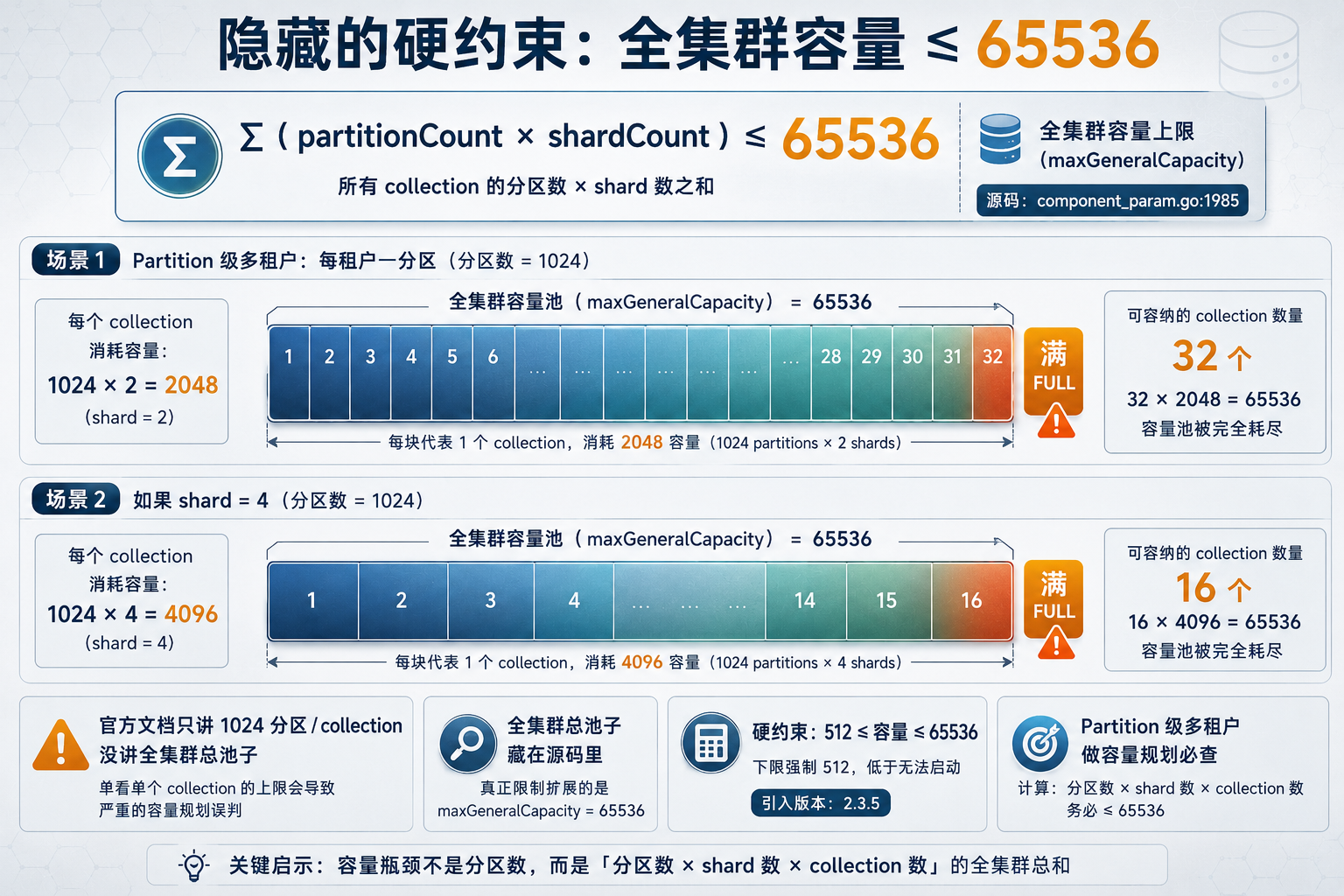
maxGeneralCapacity 容量约束图
图 5:maxGeneralCapacity 容量约束——全集群 partitionCount × shardCount 之和 ≤ 65536
源码 pkg/util/paramtable/component_param.go:1985 里有个配置:
p.MaxGeneralCapacity = ParamItem{
Key: "rootCoord.maxGeneralCapacity",
DefaultValue: "65536",
Doc: "upper limit for the sum of product of partitionNumber and shardNumber",
Formatter: func(v string) string {
if getAsInt(v) < 512 { return "512" }
return v
},
}翻译过来就是:全集群所有 collection 的分区数 × shard 数之和不能超过 65536,下限强制 512。这个约束在 2.3.5 引入,创建 collection 和 partition 时都会校验(分别在 internal/rootcoord/create_collection_task.go:114 和 ddl_callbacks_create_partition.go)。
官方文档只讲每 collection 最多 1024 分区,却没讲全集群还有这么个总池子。我用 maxGeneralCapacity、partition shard limit 65536 等关键词反复搜了一圈 GitHub Issue 和技术博客,几乎找不到任何讨论——既没有官方解释,也没有用户踩坑反馈。
这才是它危险的地方。算笔账就清楚:假设你用 Partition 级多租户,每租户一个 partition,单 collection 跑 1024 分区配 2 个 shard(默认值),一个 collection 就吃掉 2048 的容量。65536 的总池子,只能撑 32 个这样的 collection。shard 数再大点、collection 再多点,号称的 1024 分区就打折了。
这个约束是 Partition 级和 Partition Key 级多租户做容量规划时绕不开的硬约束,但它躺在源码里,不翻代码根本看不见。
你在项目里用的是哪一层多租户?有没有被容量上限卡过?评论区聊聊。
4. Database 不是命名空间,是配额和权限容器
Database 级多租户容易被人低估。表面上看它就是个带名字的容器,隔离强度跟 Collection 级差不多。但翻完源码会发现,Database 的隔离强度来自一整套配额和权限机制的叠加,而不是名字前缀。
2.3 才正式落地
配置项的 Version 字段是硬证据:maxDatabaseNum 标注的引入版本是 2.3.0(pkg/util/paramtable/component_param.go)。对应的 git 历史是 Support Database 系列 PR:#23952、#24653、#24769。
也就是说,2.0 和 2.1 时代只有 Collection 和 Partition 两层粒度,Database 级多租户是后来才补上的。这能解释为什么 Database 的默认上限只有 64——它从一开始就不是为海量租户设计的,而是为少数几个需要强隔离的大租户(比如不同业务线、不同合规边界)准备的。
隔离强度来自 Property 叠加
Database 真正的隔离能力藏在它的 property 体系里。常量定义在 pkg/common/common.go:288-298:
// database level properties
DatabaseReplicaNumber = "database.replica.number"
DatabaseResourceGroups = "database.resource_groups"
DatabaseDiskQuotaKey = "database.diskQuota.mb"
DatabaseMaxCollectionsKey = "database.max.collections"
DatabaseForceDenyWritingKey = "database.force.deny.writing"
DatabaseForceDenyReadingKey = "database.force.deny.reading"
DatabaseForceDenyDDLKey = "database.force.deny.ddl"
DatabaseForceDenyCollectionDDLKey = "database.force.deny.collectionDDL"
DatabaseForceDenyPartitionDDLKey = "database.force.deny.partitionDDL"这套 property 能为单个租户的 Database 单独设定:副本数、资源组绑定、磁盘配额、最大 collection 数,以及细到 collection DDL、partition DDL、flush、compaction 都能单独熔断的 DDL 开关。再叠加 RBAC(#24653 给 Database API 加了权限校验,#33803/#33804 后续补强)和资源组,这才撑起了官方文档里物理隔离加企业级隔离的承诺。
一个容易被忽略的细节:DB Property 在容量校验里优先于全局 quota。源码 create_collection_task.go:117-154 的逻辑是,先查 DB 有没有设 database.max.collections,设了就用 DB 级的,没设才回退到全局 maxCollectionNumPerDB。这意味着你可以给不同租户的 Database 设完全不同的容量上限,全局配置只是兜底。
5. 演进真相:底层管道在换,多租户模型没变
最后讲一个直接关系已上线用户的结论:Milvus 从 2.6 到 3.0,多租户模型本身没变,变的是支撑它的底层管道。
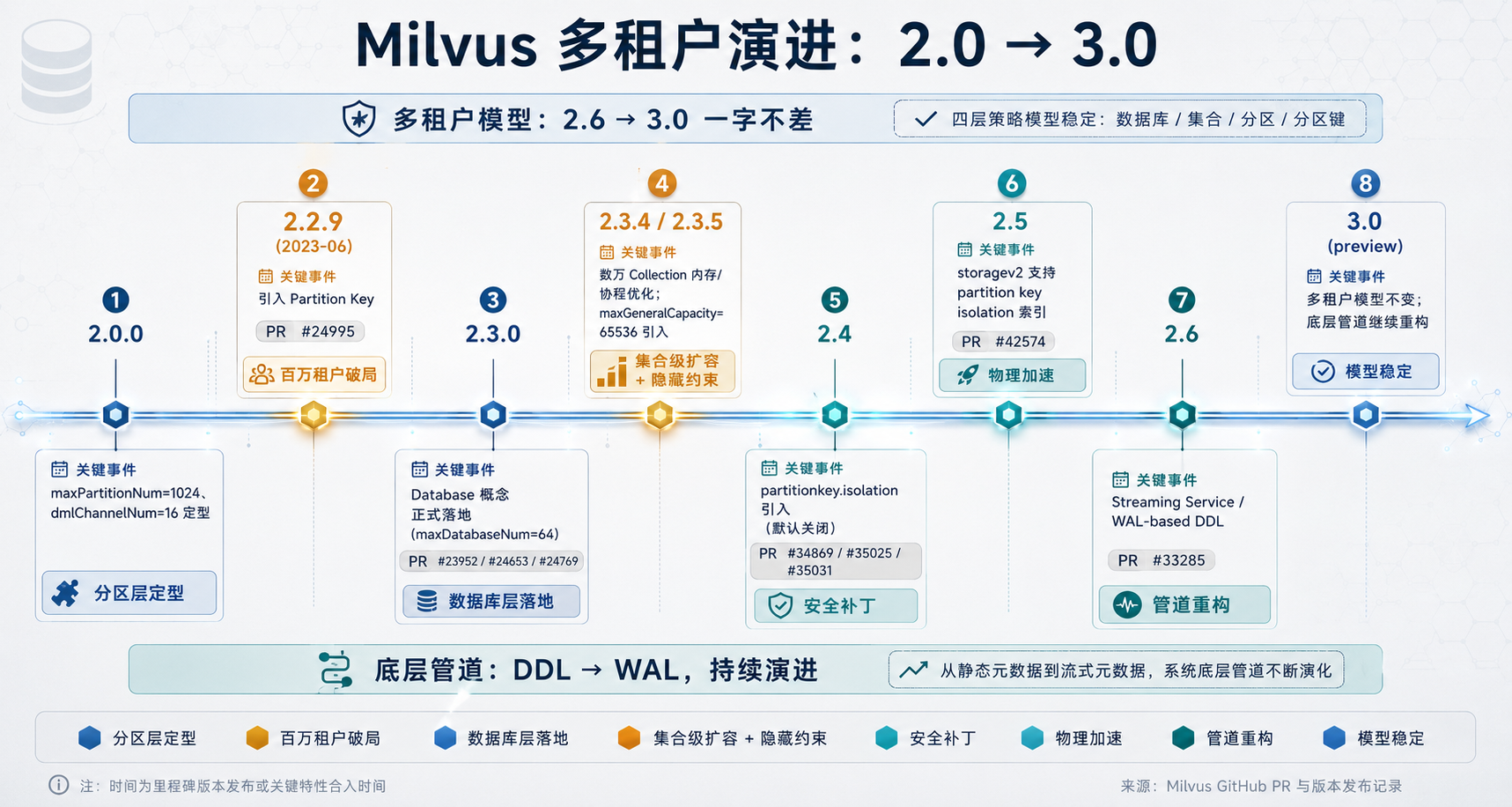
Milvus 多租户演进时间线
图 6:Milvus 多租户演进时间线——2.0 到 3.0 的八个里程碑
先梳理关键版本节点(均来自配置 Version 字段和 git log):
版本 | 关键事件 |
|---|---|
2.0.0 |
|
2.2.9(2023-06) | 引入 PartitionKey,解决百万租户的物理隔离困境 |
2.3.0 | Database 概念正式落地( |
2.3.4 / 2.3.5 | 单集群数万 Collection 的内存/协程优化; |
2.4 | Partition Key Isolation( |
2.5 | storagev2 支持 partition key isolation 索引(#42574) |
2.6 | Streaming Service / WAL-based DDL(#33285,Milestone 2.6.0) |
3.0(preview) | 多租户模型不变,底层管道重构 |
v2.6 和 v3.0 的四策略模型一字不差
我把本地文档镜像里的 multi_tenancy.md v2.6.x 和 v3.0.x 两版做了逐字对比,四策略的定义、决策矩阵、选型优先级完全一致,没有任何调整。
这对已上线用户是个定心丸:升级到 3.0 不会破坏你现有的多租户设计。四层粒度作为对外契约是稳定的,真正的改进全在看不见的地方。
真正的变化:DDL 走了 WAL
GitHub Issue #33285(官方架构设计 Issue,归属 Milestone 2.6.0)里有一条原话:RootCoord 的 DDL 操作(create/drop collection、create/drop partition)从 2.6 起改为通过 streaming service / WAL 来广播。
这件事对多租户的影响,得结合源码看。旧架构里,partition 创建走的是外部消息队列(Pulsar/Kafka/Rocksmq 三选一),新架构换成内嵌的 WAL。设计文档里明确提到几个好处:DDL 具备幂等性、可重放、跨节点一致;减少对外部消息队列的依赖,有望提升 channel 数量上限(原文 increasing channel upper limit possibility)。
源码里已经能看到证据:internal/rootcoord/ddl_callbacks_create_partition.go 的 broadcastCreatePartition 用 broadcaster.Broadcast 广播创建事件,还做了基于 partition name 的 O(1) 幂等检查(重复创建直接返回已存在的 ID)。对 Partition 级多租户(频繁建 partition)和 Collection 级多租户(频繁建 collection),这套机制都更稳。
设计文档里还提到一个新约束:每个 pchannel 同一时刻只能由一个 stream node 写。这对多租户的写热点要在 channel 分配层规避,算是新架构带来的新功课。
一个值得提醒的坑:usePartitionKeyAsClusteringKey
补一个从 Issue 里挖出来的踩坑点。配置 dataCoord.usePartitionKeyAsClusteringKey(默认 false)的设计意图是一 key 两用——让 partition key 同时充当 clustering key,搜索时既走分区裁剪又走聚簇加速,听起来很美。
但 GitHub Issue #32329(2024-05-19)明确记录:开启这个开关后,major compaction 会挂起。复现步骤就是设置 usePartitionKeyAsClusteringKey: true 然后跑脚本。这说明两个机制的合并路径在 2.4 时期还没完全稳定。默认 false 的谨慎态度,是有原因的。
Partition Key 管数据写到哪个分区(路由),Clustering Key 管 segment 内部数据怎么排序(聚集)。一个是宏观分布,一个是微观聚集。想一 key 两用,现阶段还是先观望。
写在最后
Milvus 的多租户不是一张选型表能讲完的。把它拆开看,三条线在交织:
四层粒度是一条隔离和扩展的频谱,每一层都在突破上一层的瓶颈——Database(64 级)到 Collection(6.5 万级)到 Partition(千级)再到 Partition Key(百万级)。
Partition Key 从纯粹的性能优化,演变成需要安全补丁(partitionkey.isolation)兜底的隔离机制,而物化视图是它的物理加速载体——语义约束和物理加速一体两面。
Database 的隔离强度不来自名字,而来自配额、DDL 熔断、RBAC、资源组的叠加,DB Property 优先于全局配置。
再加上两个容易被忽略的真相:全集群的 partition × shard ≤ 65536 是个文档没强调的硬约束;2.6 到 3.0 是管道重构而非模型变更。
说到底,Milvus 多租户的成熟,靠的不是某一个精巧的设计,而是分散在 rootcoord、proxy、datacoord、RBAC 里的渐进式补丁。这种演进方式的好处是兼容性好、风险可控;代价是很多关键约束散落在源码里,得自己挖。
如果你正在做多租户选型,建议把容量约束(65536)和 isolation 开关当成两个必查项。前者决定你能不能撑住目标租户数,后者决定你的多租户隔离到底是真的还是假的。这两个点官方文档都没讲透,但踩坑成本不低,建议收藏一份备用。
相关资源
官方多租户文档:https://milvus.io/docs/multi_tenancy.md
Streaming Service 设计 Issue:https://github.com/milvus-io/milvus/issues/33285
Materialized View 设计 Issue:https://github.com/milvus-io/milvus/issues/29892
compaction 挂起 Bug:https://github.com/milvus-io/milvus/issues/32329
Milvus 仓库:https://github.com/milvus-io/milvus
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号