互联网企业mysql使用规范(军规)

互联网企业mysql使用规范(军规)

Wangzy
发布于 2026-06-22 18:16:27
发布于 2026-06-22 18:16:27
前记:最近购买了沈剑老师架构师相关的大专栏课程在学习,这周学习了互联网企业mysql军规相关的课程内容,自己本身运维以及开发工作中,也频繁接触mysql,通过这个课程感觉收获还是不小的,所以也在此做一个学习总结吧。如果有总结不对的地方,欢迎大家指正交流。
一、基于如下业务场景下,响应时间、吞吐量、扩展性优先,数据库往往最容易成为系统瓶颈。
解放数据库,降数据库磁盘IO,降数据库计算,成为架构设计的核心方向之一。
场景一:互联网前台业务
场景二:数据量较大
场景三:并发量较大
二、如何降低数据库磁盘IO和数据库CPU计算
1、禁止使用存储过程,视图、触发器、Event等。
这些功能会加重数据库的计算负担,我们只让数据库做它最擅长的事情:存储和索引,少干其他事情。
数据库中非必需的CPU计算,尽量挪到应用服务层。
2、禁止使用外键约束,由应用服务来保障完整性。
3、针对读多写少的数据,用缓存来实现读,减少数据库的磁盘IO。
4、大对象,原则上不要存储在数据库里。
大对象的读写,会消耗大量数据库 I/O 和网络带宽。
数据库存储成本高,大对象也占用数据库大量的存储空间。
建议将大对象数据存储在对象存储中,在 MySQL 中只存储对象的元数据(如文件名、大小、MIME类型、创建时间、对象存储中的访问路径/URL)和指向该对象在对象存储中位置的标识符(通常是 URL 或 Key)。应用程序通过数据库查询到元数据和访问路径后,直接与对象存储交互进行读写。
5、应用采用前后端分离架构
前端通过 API 按需请求最小化数据(如 JSON),后端只需返回必要字段,避免全量数据查询。
静态资源直接托管至 CDN 或对象存储(如 Nginx/AWS S3),完全绕过数据库和后端应用层。消除大量静态文件 I/O 请求对数据库的干扰
6、尽量不使用JOIN,如果要用,必须保证表的字符集类型相同,连表的字段要建立索引。
如下例子中,建立t1、t2、t3三个表,t1和t3是相同的字符集(utf8),t2是不同的字符集(latin1)。
create table t1 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t1(cell) values ('111'),('222'),('333');
create table t2 (
cell varchar(3) primary key
)engine=innodb default charset=latin1;
insert into t2(cell) values ('111'),('222'),('333'),('444'),('555'),('666');
create table t3 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t3(cell) values ('111'),('222'),('333'),('444'),('555'),('666');join t1和t2表查询,可以看到t1表扫描了3行数据,t2表扫描了6行数据,命中了笛卡尔积的循环计算。
EXPLAIN select * from t1,t2 where t1.cell = t2.cell;
join t1和t3表查询,可以看到t1表扫描了3条记录,t2表每个只扫描了1条记录,没有走笛卡尔积循环计算。由此可见join表的字符集相同是很重要的一个原则。
EXPLAIN select * from t1,t3 where t1.cell = t3.cell;
7、字段类型,与查询字段赋值类型必须相同
create table t1 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t1(cell) values ('111'),('222'),('333');当查询语句中where后的值类型(数值)和表cell列定义的字符型不同时,遍历了3条记录。
EXPLAIN select * from t1 where cell=111;
当查询语句中where后的值类型和表cell列定义的字符型相同时,只遍历了1条记录。
EXPLAIN select * from t1 where cell='111';
8、禁止负向查询,与%开头的模糊查询。
如下创建的user表,id为索引,非唯一(non unique),允许空(null)
create table user (
id int,
name varchar(20),
index(id)
)engine=innodb;
insert into user values(1,'wangzy');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');如下例子可以看到负向查询,会查询全表数据
EXPLAIN select * from user where id != 1;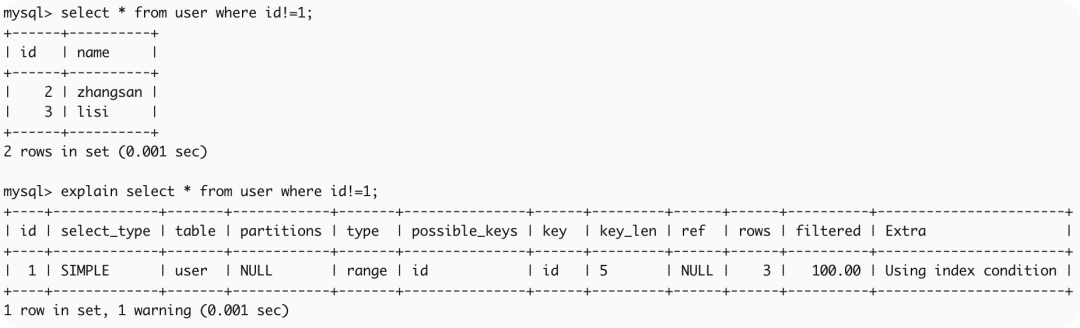
9、禁止在列上进行函数或表达式计算
10、字段必须定义为NOT NULL,并提供默认值
如下例子可以看到,如果值为空没有默认值的列,数据查询必须要加个非空的过滤条件。


11、联合索引,区分度最高的放在最左边;联合索引,列个数不要超过5个
三、数据库使用规范
1、数据库行为规范:
a、禁止在服务器上私自安装mysql客户端,来访问数据库
b、账号禁止给别人用
c、禁止以任何形式,例如:session log导出数据
d、禁止跳过工单,跳过审批,私自操作数据库
e、禁止在业务高峰期(8:00-18:00)进行批量操作
f、沙箱环境,等同线上环境,禁止写入数据
2、基础规范:
a、必须使用InnoDb
b、必须要有注释
c、必须使用utf8或utf8mb4
3、表规范:
a、不要使用分区表
b、必须要有主键,且主键不宜过长
c、大字段,访问频率低的属性,垂直拆分
4、字段规范:
建议使用tinyint替代enum
5、索引规范:
使用覆盖索引减少磁盘IO
order by ,group by, distinct要加索引
核心功能SQL必须通知DBA,以确认索引有效性
6、sql规范:
禁止select
insert into 必须指定列
拒绝复杂sql,将大SQL拆分成多条简单的SQL
应用程序必须捕获数据库异常
四、MyISAM和InnoDB相关知识点介绍:
1、MyISAM会直接存储总行数,InnoDB则不会,需要按行扫描。
潜台词是,对于select count(*) from t;如果数据量大,MyISAM会瞬间返回,而InnoDB则会一行行扫描。
数据量大的表,InnoDB不要轻易select count(*),性能消耗极大。
常见坑:
只有查询全表的总行数,MyISAM才会直接返回结果,当加了where条件后,两种存储引擎的处理方式类似。
2、MyISAM支持全文索引,InnoDB5.6之前不支持全文索引
实践:
不管哪种存储引擎,在数据量大并发量大的情况下,都不应该使用数据库自带的全文索引,会导致小量请求占用大量数据库资源,而要使用《索引外置》的架构设计方法
启示:
大数据量+高并发量的业务场景,全文索引,MyISAM也不是最优之选
3、MyISAM不支持事务,InnoDB支持事务
实践:
事务是选择InnoDB非常诱人的原因之一,它提供了commit,rollback,崩溃修复等能力。在系统异常崩溃时,MyISAM有一定几率造成文件损坏。但是,事务也非常耗性能,会影响吞吐量,建议只对一致性要求较高的业务使用复杂事务。
画外音:
Can't open file 'XXX.MYI'.碰到过么?
小技巧:
MyISAM可以通过lock table表锁,来实现类似于事务的东西,但对数据库性能影响较大,强烈不推荐使用。
4、MyISAM不支持外键,InnoDB支持外键
实践:
不管哪种存储引擎,在数据量大并发量大的情况下,都不应该使用外键,而建议由应用程序保证完整性
5、MyISAM只支持表锁,InnoDB可以支持行锁
分析:
MyISAM:执行读写SQL语句时,会对表加锁,所以数据量大,并发量高时,性能会急剧下降
InnoDB:细粒度行锁,在数据量大,并发量高时,性能比较优异
实践:
网上常常说,select+insert的业务用MyISAM,因为MyISAM在文件尾部顺序增加记录速度极快。
沈剑老师的建议是,绝大部分业务是混合读写,只要数据量和并发量较大,一律使用InnoDB
常见坑:
InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。潜台词是,如果访问没有命中索引,也无法使用行锁,将要退化为表锁
画外音:
Oracle的行锁实现机制不同
6、总结
在大数据量,高并发量的互联网业务场景下,对于MyISAM和InnoDB:
● 有where条件,count()两个存储引擎性能差不多
● 不要使用全文索引,应当使用《索引外置》的设计方案
● 事务影响性能,强一致性要求才使用事务
● 不用外键,由应用程序来保证完整性
● 不命中索引,InnoDB也不能用行锁
在大数据量,高并发量的互联网业务场景下,请使用InnoDB:
● 行锁,对提高并发帮助很大
● 事务,对数据一致性帮助很大
这两个点,是InnoDB最吸引人的地方。
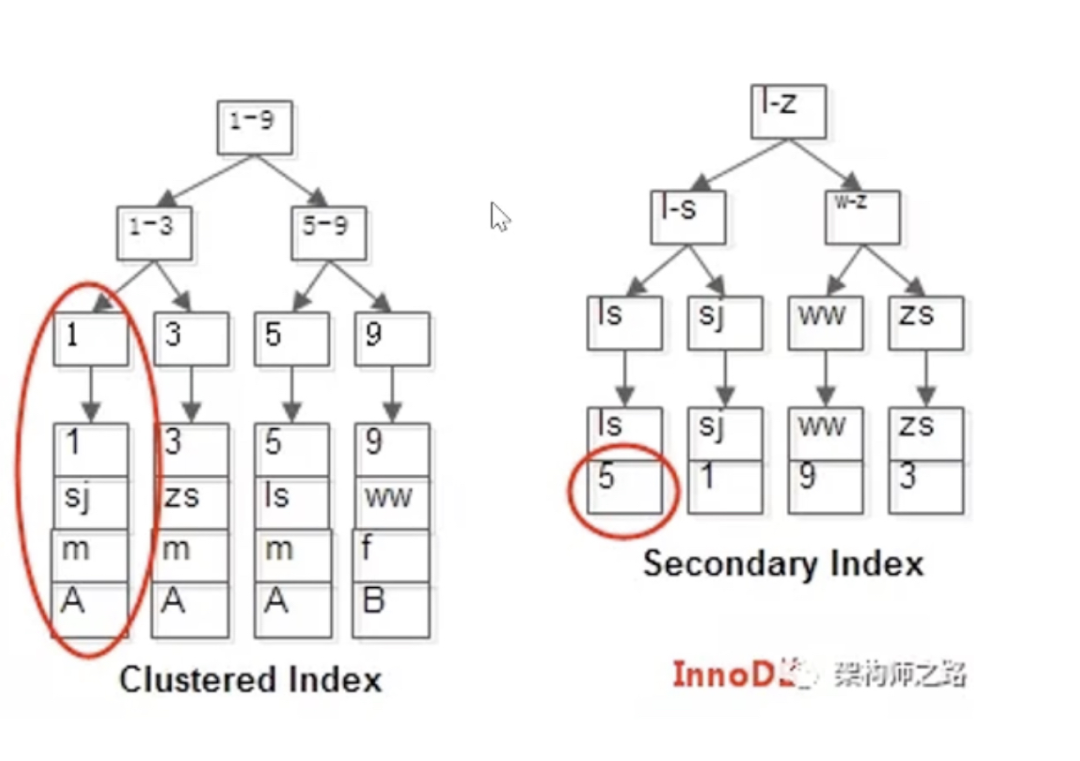
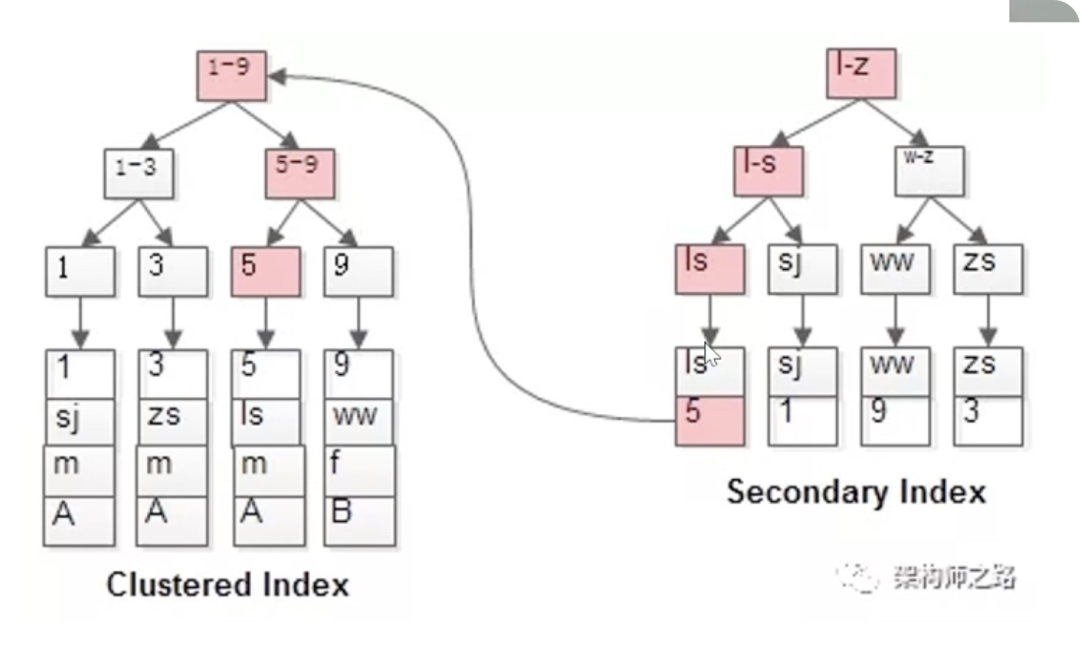
五、聚集索引(Clustered Index)和辅助索引(Secondary Index)
假设有数据表t(id PK, name KEY, sex, flag);
其中:
(1)id是主键;
(2)name建了普通索引;
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
如下图所示,InnoDB引擎中,
Clustered Index(主键索引),按主键构造B+树,叶节点存储完整行数据。
Secondary Index(普通索引) ,叶节点存储普通索引键值 + 主键值(非完整数据)。
如果主键值过长,会导致普通索引节点存储空间撑大,所以建议主键值不宜过长。
六、表的垂直拆分:
垂直拆分是指,将一个属性较多,一行数据较大的表,将不同的属性拆分到不同的库(表)中,以降低单库(表)大小,达到提升性能的目的的方法。
垂直拆分后,各个库(表)有什么特点?
a. 每个库(表)的结构都不一样
b. 每个库(表)的属性至少有一列交集,一般是主键
c. 所有库(表)的并集是全量数据
当一个表属性很多时,如何来进行垂直拆分呢?
主要依据以下几点:
(1)将长度较短,访问频率较高的属性尽量放在一个表里,这个表暂且称为主表;
(2)将字段较长,访问频率较低的属性尽量放在一个表里,这个表暂且称为扩展表;
(3)经常一起访问的属性,也可以放在一个表里;
画外音:优先考虑1和2。
为何要将字段短,访问频率高的属性放到一个表内?
为何这么垂直拆分可以提升性能?
(1)数据库有自己的内存缓冲池,会将磁盘上的数据load到缓冲池里;
(2)数据库缓冲池,以row为单位缓存数据;
(3)在内存有限的情况下,在数据库缓冲池里缓存短row,就能缓存更多的数据;
(4)在数据库缓冲池里缓存高频访问row,就能提升缓存命中率,减少磁盘的访问;
假设数据库内存缓冲池为1G,未拆分的user表1行数据大小为1k,那么只能缓存100w行数据。
如果垂直拆分成userbase和userext,其中:
(1)userbase访问频率高,一行大小为0.1k;例如uid,name,passwd,以及一些flag等。
(2)userext访问频率低,一行大小为0.9k;例如签名,个人介绍等。
那边缓冲池就就能缓存近乎1000w行userbase的记录,访问磁盘的概率会大大降低,数据库访问的时延会大大降低,吞吐量会大大增加。
拆表例子:如下用户表user,
将常用字段放到user_base,
长的且不常用字段拆到另一个表user_ext
a、拆分前:
user(
uid bigint,
name varchar(16),
pass varchar(16),
age int,
sex tinyint,
flag tinyint,
sign varchar(64),
intro varchar(256),
...);b、拆分后:
user_base(
uid bigint,
name varchar(16),
pass varchar(16),
age int,
sex tinyint,
flag tinyint,
...);
user_ext(
uid bigint,
sign varchar(64),
intro varchar(256),
...);七、覆盖索引介绍:
如下是沈剑老师在mysql和sqlserver官网查的覆盖索引相关的介绍

创建表user_2,并造一些数据
create table user_2 (id int primary key,name varchar(20),sex varchar(3),flag varchar(3),index(name))engine=innodb;
insert into user_2 values(1,'wangzy','m', 'A');
insert into user_2 values(3,'zhangsan','m', 'A');
insert into user_2 values(5,'lisi','m', 'A');
insert into user_2 values(9,'wangwu','f', 'B');1、命中聚集索引 id
select name from user_2 where id=5; 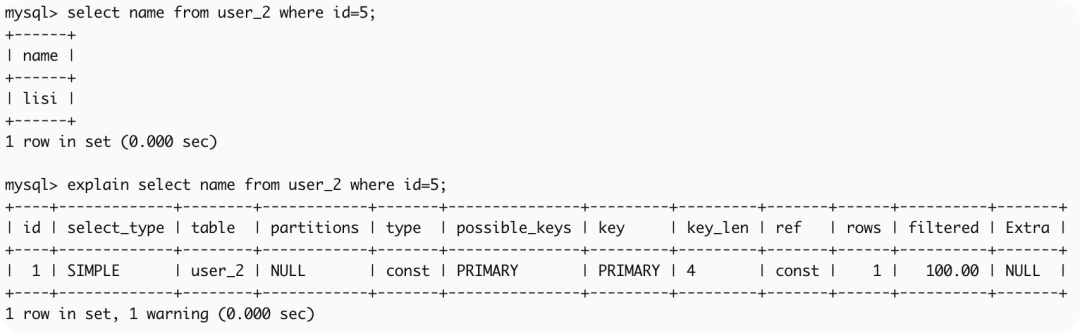
2、命中辅助索引 name
select id from user_2 where name='lisi'; 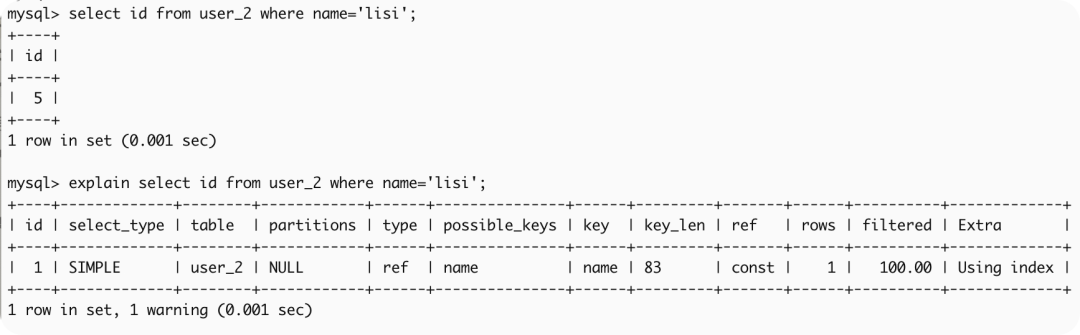
3、命中聚集索引name,索引叶子节点中存储了主键id,通过name的索引数可以获得name和id列,无需回表,符合索引覆盖,效率较高。
select id,name from user_2 where name='wangzy'; 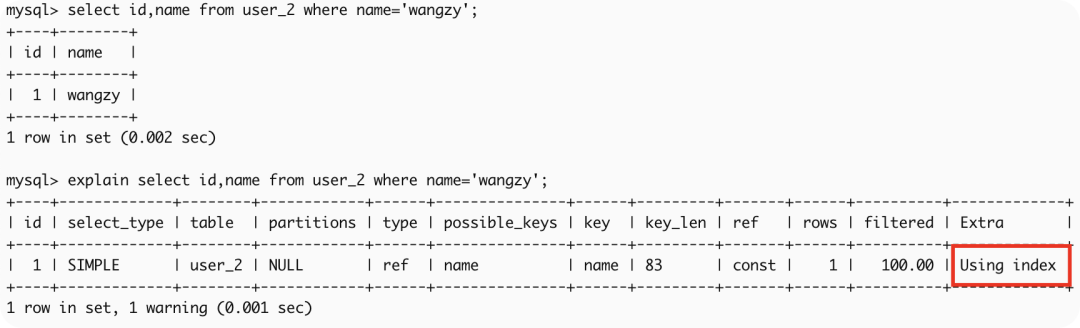
4、命中辅助索引name,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合覆盖索引,需要再次通过id只扫描聚集索引获取sex字段,效率会降低。
select id,name,sex from user_2 where name='wangzy'; 
画外音:Extra为什么不是Using index condition:ICP 作用:将WHERE条件中的索引列过滤下推到存储引擎层执行。
5、命中联合辅助索引,无需回表
修改user_2表的辅助索引,从name改成name和sex的联合索引。
可以看到无论查id、name还是id、name、sex都能够命中索引覆盖,无需回表。
ALTER TABLE user_2 DROP INDEX name;
ALTER TABLE user_2 ADD INDEX idx_name_sex (name, sex);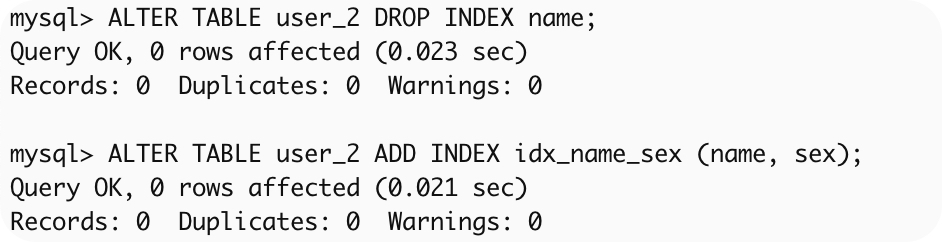

但是,别滥用覆盖索引,索引太多,属性太多,会占用缓冲池降低查询效率。
八、总结
沈剑老师总结:数据库的性能好坏,根本上来说是由访问数据库的service决定。service的研发与测试的负责人应该为对应数据库稳定性负责。
另外总结一个我自己在使用数据库中的一个比较重要的经验:数据库刷数需要提前确认刷数的数据量,并且准备好回退脚本。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号