程序运行起来以后,操作系统到底做了什么

程序运行起来以后,操作系统到底做了什么

Lihua奏
发布于 2026-06-23 20:32:49
发布于 2026-06-23 20:32:49
程序运行起来以后,操作系统到底做了什么
当我们运行下面这段代码时,究竟发生了什么?
#include <stdio.h>
int main(void) {
printf("hello\n");
return 0;
}
一般觉得就是:代码 -> 运行。其实中间还有很多步骤
CPU 只认识一种语言
我们所写的:
a = b + c;
CPU 看到的(x86 机器码)可能更像这样:
8B 45 F8
03 45 F4
89 45 EC
这是十六进制表示出来的机器码。不同的 CPU(x86、ARM)有各自的机器码格式,所以一个平台上的机器码,不能直接拿到另一个平台上跑
那么 CPU 只认识机器码,那在"翻译"的时候,是每次运行时翻译,还是运行之前就翻译好? 各自的优势是什么?
- 每次运行时翻译
- 运行速度:慢,因为它是边跑边翻译
- 磁盘占用:小,存的是更接近源代码或中间代码的东西
- 可移植性:强,前提是目标机器上有对应的解释器或运行时
- 运行之前就翻译
- 运行速度:快,因为它直接执行机器码
- 磁盘占用:通常更大
- 可移植性:弱,因为它绑定平台
在上一篇文章中有提到两者结合的方法:Java
- Java -> 先编译成字节码 -> 运行时交给 JVM 翻译
- JIT 尽量减少运行时翻译的损耗
可执行文件里装的是什么
现在知道了源代码最终要变成机器码,那机器码长啥样呢?
MZê ÿ ¸ @ º Í!¸LÍ!
This program cannot be run in DOS mode.
$û®Ç?ü¹?ü¹?ü¹...
差不多长这样。当然,这不是乱码,而是文本编辑器用"显示文字"的方式,强行把一堆原本是数字的内容展示出来
当我们用十六进制转储工具去看,会更清楚一点
偏移量:距离起点的距离
偏移量 实际内容(十六进制)
00000000(从头开始的第 0 个字节) 4D 5A 90 00 03 00 00 00
00000008(从头开始的第 8 个字节) 04 00 00 00 FF FF 00 00
00000010(从头开始的第 16 个字节) B8 00 00 00 00 00 00 00
这里先按 Windows 上常见的 来理解.exe
.exe 不只有机器码。它的文件结构大致分为:
- 文件头(header):描述这个程序的基本信息,比如入口点、各个段的位置等
- 代码段():真正的机器码,CPU 执行的部分
.text - 数据段():全局变量、字符串、已初始化数据等
.data - 重定位信息:装载时修正地址要用到的信息
那 CPU 怎么知道自己该去哪里取指令?
CPU 内部有一个专门的寄存器,叫程序计数器(PC)
程序计数器的作用:永远指向"下一条要执行的指令的地址"
它如何指使 CPU 工作?
- 去 PC 指定的地址取指令
- 执行
- PC 自动指向下一条
- 重复第一步
但这里要注意一件事:CPU 不是自己去猜"这块是代码段,还是数据段"
真正先做这件事的是操作系统。它在装载 的时候,会根据文件头的信息,把 、 这些内容按不同规则映射进内存,再把 PC 对准程序入口。这样 CPU 后面才能顺着往下跑.exe.text.data
编译器是怎么翻译源代码的
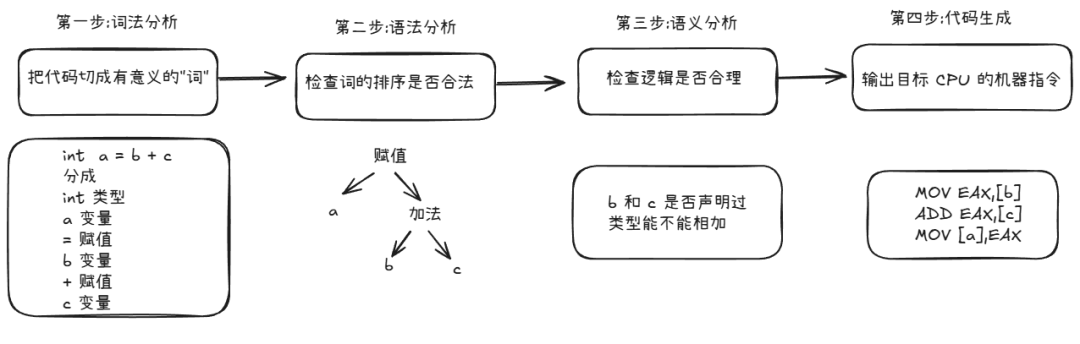
编译器并不是直接把源代码硬翻成机器码就完了,它得先确认这段代码在语法和语义上说得通
比如源代码:
int a = b + c;
分四步做
不同平台需要不同编译器
int a = b + c -> x86 编译器 -> x86 机器码
int a = b + c -> ARM 编译器 -> ARM 机器码
只靠编译还不够,还得链接
首先你如果是这样做的,那没有问题
int add(int a, int b) {
return a + b;
}
int main(void) {
add(3, 5);
return 0;
}
但是,如果分成两个文件,事情就不一样了
// main.c
int main(void) {
add(3, 5);
return 0;
}
// math.c
int add(int a, int b) {
return a + b;
}
生成的 会出现一个问题:main.obj
- 它知道自己要调用
add - 但它在自己这个 里找不到 的实现
.objadd - 所以这里只能先留下一个"待会再填的地址"
你会发现,上面这两个 都只是半成品.obj
这时候,链接器就出现了,负责把这些半成品拼成一个完整程序
main.obj + math.obj -> [链接器] -> main.exe
它负责做的事大致有:
- 把所有 的代码和数据拼起来
.obj - 扫描这些还没填好的引用
- 把它们真正补到对应的函数或变量地址上
- 输出完整的
.exe
那么,如果调用一个函数,但忘记把那个函数所在的 交给链接器,会在编译阶段报错,还是链接阶段报错?.obj
答案是:链接阶段报错
编译阶段主要检查:
- 语法是否正确
- 类型对不对
- 你写的东西像不像一段合法代码
链接阶段主要检查:
- 这些被调用的函数和变量,最后到底能不能找到真正实现
那新的问题来了
int main(void) {
add(3, 5);
return 0;
}
这里明明没定义 ,为什么有时候以前还能编过?add
这是因为早期 C 语言里有一个隐式声明规则
它会自动假设:
"add 是一个返回 int、参数未知的函数"
先继续编译,把真正地址留给后面的链接器去补
但这个规则现在早就废除了。现代 C 里,更正常的做法是:
- 在头文件 里写声明
.h - 在 文件里写实现
.c - 通过 先让编译器知道这个函数确实存在
#include
启动代码和库文件
链接器把 合并成 ,光靠你自己写的 还不够,通常还需要两样东西.obj.exe.obj
第一个:启动代码
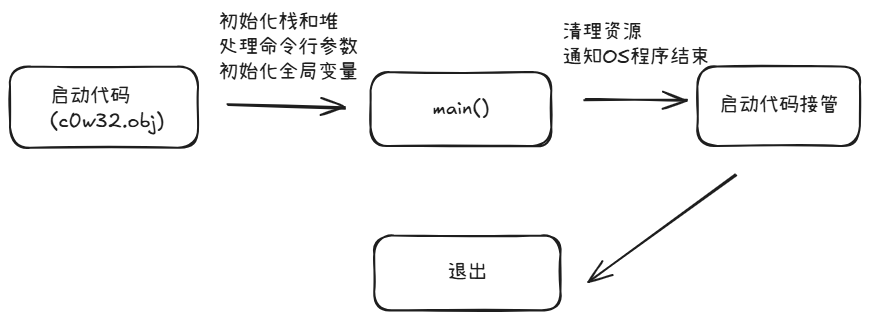
你写的 往往不是程序真正开始执行的第一行。真正最先跑的,通常是一段启动代码main()
它负责的事包括:
- 初始化运行环境
- 准备栈和堆
- 处理命令行参数
- 初始化全局变量
- 最后再去调用
main()
第二样:库文件(.lib)
这里要区分一下:
- 静态库,通常也是
.lib - 导入库,在 Windows 下很多时候也叫
.lib
你写代码时用到的 、、,都不是你自己实现的。它们通常都在库里printfsqrtmalloc
- 库文件的本质,可以先理解成一堆 打包在一起
.obj - 链接器会从里面把你真正用到的那部分拿出来
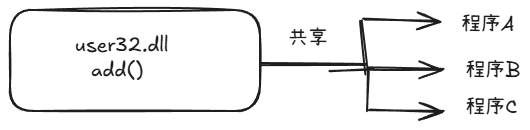
DLL 文件与导入库
静态库有个问题:代码是直接复制进 的.exe
比如:
程序A.exe 内含某段公共代码
程序B.exe 内含某段公共代码
程序C.exe 内含某段公共代码
如果三份程序都带着几乎一样的代码,那磁盘和内存都会重复
DLL 的思路就是:代码只保存一份,多个程序共享
这时,链接时你拿到的 ,很多时候就不是函数本体了,而更像是一张"路标".lib
某个函数在某个 DLL 里
程序运行时去那里找
于是编译链接后的 ,不会直接把这段代码塞进去,而是把"以后去哪里找它"这件事记下来.exe
那好处和坏处分别是什么?
好处:
- 多个程序可以共享同一份代码
- 某些公共库升级后,依赖它的程序不用各自再拷一遍
坏处:
- DLL Hell(DLL 地狱)
它的意思就是:程序 A 依赖某个 DLL 的旧版本,程序 B 升级后把这个 DLL 换成了新版本,结果 A 下次运行就崩了
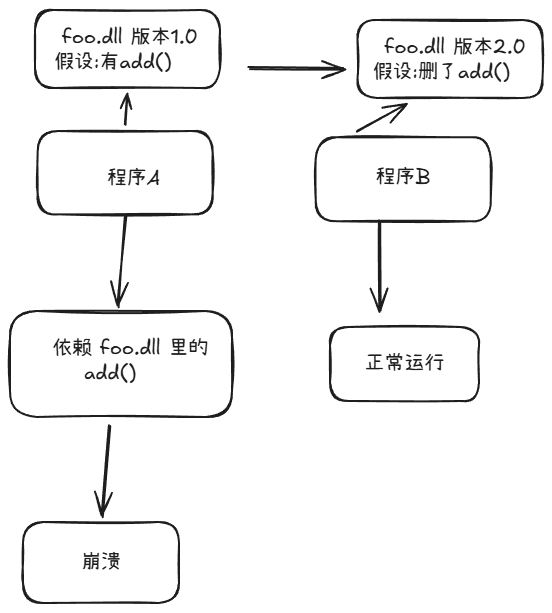
后来微软引入了并行程序集这类机制,允许不同版本的 DLL 同时存在,每个程序明确声明自己依赖哪个版本,互不干扰
程序为什么还要靠操作系统来装载
.exe 文件里虽然已经有机器码了,但还不能直接执行,因为编译时并不知道自己将来会被放到内存的哪里
假设:
程序里有一个变量 a,地址是多少?
编译器:现在还不知道
因为运行时内存里可能已经有别的程序了,你的程序最终会被装到哪里,这是加载前无法完全确定的
所以解决办法是:
- 有些地方先记录相对位置
- 有些地方保留重定位信息
- 等真正装载时,再把地址修正好
比如:
变量 a 在程序起点往后 100 字节处
那如果程序这次被加载到 0x00400000
- 变量 的真实地址 =
a0x00400000 + 100
下次如果被加载到 0x00600000
- 变量 的真实地址 =
a0x00600000 + 100
那问题又来了,如果程序 A 和程序 B 都觉得自己在 ,不就撞地址了吗?0x00400000
这就轮到虚拟内存出场了
操作系统会给每个进程各自准备一套独立的虚拟地址空间
程序A 以为自己在: 0x00400000 -> MMU -> 实际物理地址:0x10000000
程序B 以为自己在: 0x00400000 -> MMU -> 实际物理地址:0x20000000
所以表面上看,两个程序都"占着"同一个地址,其实它们看到的是各自的假地址,背后对应的是不同的物理内存
也就是说:
- 重定位信息 -> 解决"程序加载到哪里"这个问题
- 虚拟内存 -> 解决"多个程序看起来地址一样会不会冲突"这个问题
应用程序和操作系统,到底是什么关系
看到这里,题目里最关键的一层其实才刚出来
应用程序并不是直接去控制硬件的。大多数时候,它只是表达"我想做什么",真正负责分配资源、管理权限、和硬件打交道的,是操作系统
拿最开头那句 举例printf("hello\n")
它表面上只是打印一句话,但背后大致是这样的:
- 你的程序先调用
printf printf先在 C 运行库里把这段输出整理好- 然后运行库再通过操作系统提供的接口,把这段内容交给控制台
- 操作系统再去调度驱动和硬件,最后你才真的在屏幕上看到
hello
文件读写、网络请求、创建进程、创建线程、申请更多内存,本质上也都差不多
所以应用程序和操作系统的关系,说白了就是:
- 应用程序负责提出需求
- 操作系统负责分配资源
- 操作系统负责隔离不同程序
- 操作系统负责把应用程序的请求真正落到硬件上
这也是为什么,应用程序通常不能想干嘛就干嘛。它得按操作系统给的规则来
栈和堆
程序被加载进内存后,操作系统通常还会额外给它准备几块常用区域
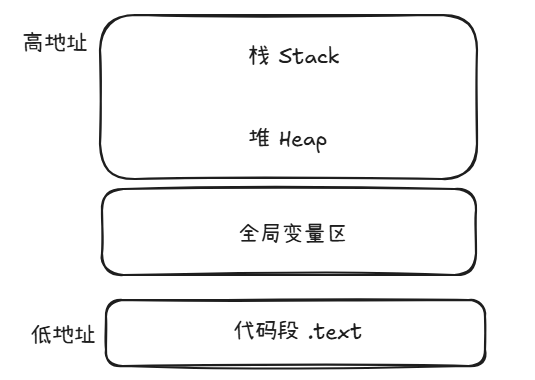
栈
栈是自动管理的临时区域
函数调用时,栈会自动扩张;函数返回时,栈会自动收缩
void c() { int z = 3; }
void b() { int y = 2; c(); }
void a() { int x = 1; b(); }
int main(void) { a(); }
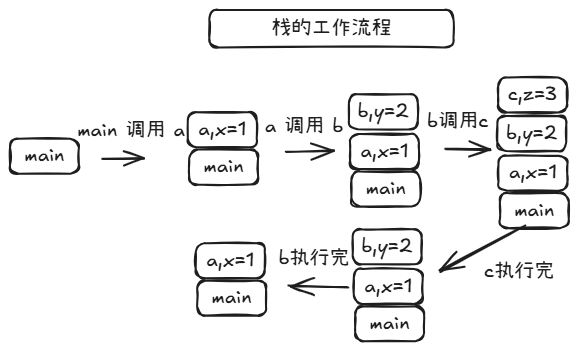
你可以看到, 一层层调用进去时,新的局部变量会一层层压上去。等 执行完,最上面这一层就先退掉,这就是典型的后进先出main -> a -> b -> cc
堆
堆是手动管理的动态区域
当你需要在运行时动态申请一块更灵活的内存时,就会用到堆
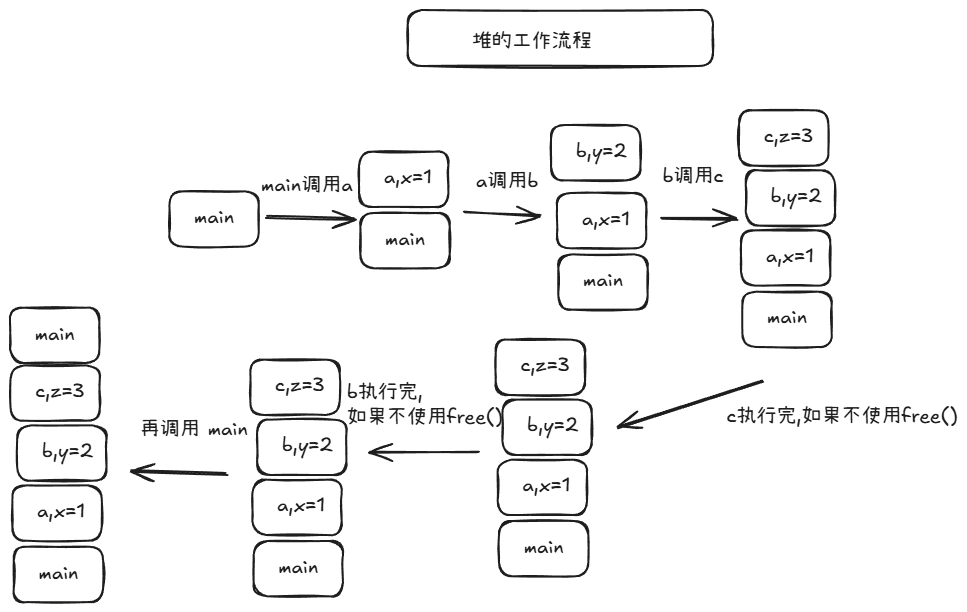
它们的区别可以先这样记:
- 栈:声明变量时自动分配,函数返回时自动释放,速度快,但空间通常比较小
- 堆:用 这类方式主动申请,用 主动释放,更灵活,但管理起来也更麻烦
malloc/newfree/delete
所以可以看出:
- 栈适合短期使用
- 堆适合生命周期更灵活的数据
最后串一下
从你点下"运行"开始,真正发生的事情大致是:
源代码 -> 编译 -> 链接 -> 生成可执行文件 -> 操作系统装载到内存 -> 分配地址空间和运行环境 -> CPU 开始执行机器码 -> 应用程序再通过操作系统去申请各种服务
所以题目里的关系,其实可以压成一句话:
应用程序不是脱离操作系统单独工作的,而是建立在操作系统提供的装载、隔离、调度和服务之上的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号