AI 重构遗留代码,我踩过最深的 3 个坑,第 2 个差点让我背锅

AI 重构遗留代码,我踩过最深的 3 个坑,第 2 个差点让我背锅

码哥字节
发布于 2026-06-25 11:26:48
发布于 2026-06-25 11:26:48
老板说:"用 AI 把这坨屎山重构掉,现在工具这么好,应该很快。"
我当时点了头。
这是我接手的一个运行了 6 年的 Spring Boot 单体服务,核心模块 5000 行,最臃肿的那个类 1800 行,47 个方法堆在一起,没有注释,单测覆盖率 8%。前任的前任离职的时候留了一句话:"这块别乱动,动了必翻车。"
我用 Claude Code 开干了。第一周,重构进展顺利,AI 拆类、提方法、补测试,速度确实快。第二周,我开始合并代码准备上灰度,然后——连续 3 天,每天下午收到告警,凌晨定位问题,根因全是 AI 重构时悄悄改了的东西。
AI 代码不会说"我不确定",它只会自信地告诉你"这样完全等价"。等你发现不等价,可能已经在生产了。
这篇文章记录我踩的 4 个真实坑,每个坑都有具体的翻车经过和防坑方法。
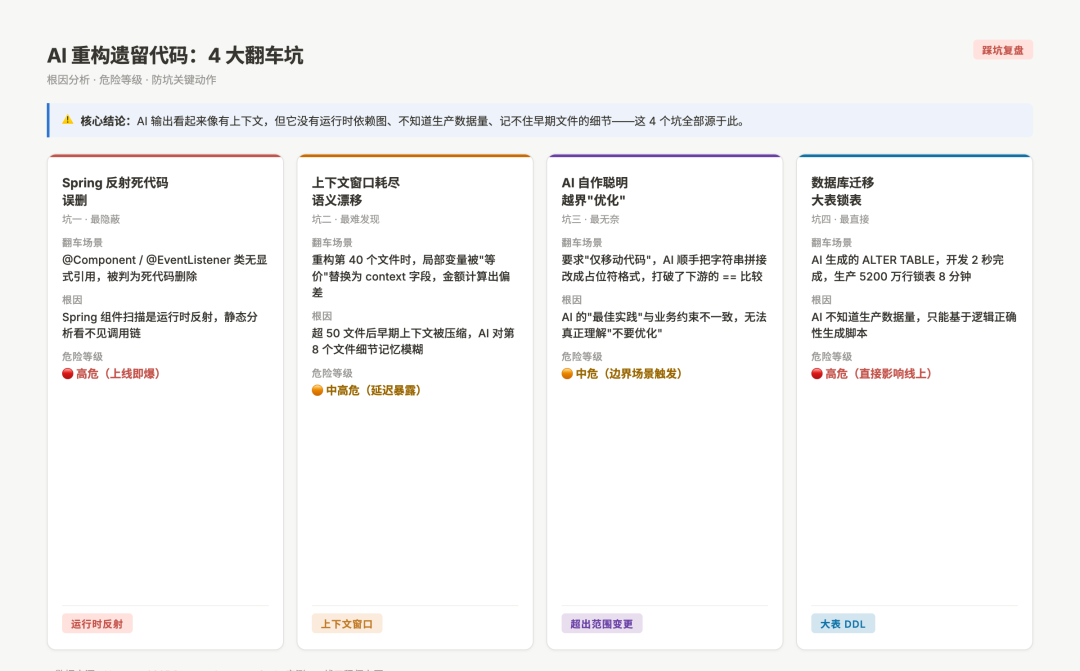
AI重构遗留代码踩坑复盘:四大坑与防坑心法
图:4个核心踩坑的翻车现场与根因分析
坑一:AI 删掉的"死代码",其实是 Spring 运行时注入的 Bean
这是最隐蔽的坑,也是第一个让我上线后翻车的坑。
我让 Claude Code 扫描整个服务,找出"没有被任何地方引用的类",删掉它们。AI 给出了一份 37 个候选类的列表,自信满满地说这些都是死代码,删掉可以减少代码量、降低维护复杂度。
我看了几个,确实在项目里搜不到任何直接引用。批准删除。
上线之后,某个异步消息处理功能直接 500。定位了两个小时,发现是 OrderNotificationEventListener 这个类被删了。
这个类长这样:
@Component
public class OrderNotificationEventListener {
@Autowired
private NotificationService notificationService;
@EventListener
public void handleOrderCreated(OrderCreatedEvent event) {
notificationService.sendConfirmation(event.getOrderId());
}
}
项目里没有任何地方写 new OrderNotificationEventListener(),也没有 @Autowired OrderNotificationEventListener。
但它是活的。
Spring 的组件扫描会自动把 @Component 标注的类注册到容器里。它监听 OrderCreatedEvent,只要 Spring 的 ApplicationContext 发布这个事件,它就会被调用。没有显式引用,只有运行时反射注入。
AI 的 grep 分析找不到调用链——因为调用链在运行时才存在。
这不是个例。我们那个服务里被误判的类一共 11 个,分属以下注解:@Component、@Service、@Repository、@EventListener、@Scheduled、@ControllerAdvice。
防坑心法:给 AI 加一条硬性规则,在 prompt 里明确写清楚。
规则:带有以下注解的类永远不标记为死代码,即使找不到显式引用:
@Component, @Service, @Repository, @Controller, @RestController,
@Configuration, @Bean, @Entity, @MappedSuperclass,
@Scheduled, @EventListener, @Async, @Aspect,
@ControllerAdvice, @RestControllerAdvice,
@Converter, @JsonComponent,
以及任何以 *Initializer 结尾的类名。
原因:Spring 依赖注入是运行时反射机制,静态分析无法追踪这类依赖。
还有一类更难发现:通过字符串动态加载的 Bean。Class.forName("com.example.OrderService")、BeanFactory.getBean("orderService"),这些都是 AI 的死角。凡是字符串拼接类名的地方,AI 永远判不准。
过去用静态分析工具找死代码的逻辑在这里完全失效——不是工具不够好,是 Java 的反射机制本来就是为了绕开静态分析而设计的。
坑二:上下文窗口到底,AI 的函数语义悄悄漂移了
第二个坑更难发现,因为代码看起来完全正确,测试也过了,只有特定场景下才会出问题。
我在重构的第 8 天,让 Claude Code 整理一个 800 行的订单处理核心类,把分散的逻辑提取成独立方法。任务很顺利,AI 改了 40 多处,代码变得整洁多了。
三天后上线,收到告警:某类订单的优惠计算出现偏差。金额差了几块钱,不是每笔都有,大约每 200 笔里有 1-2 笔。
排查到最后,发现问题出在这段逻辑:
AI 在提取某个方法时,把一个本来是局部变量的 BigDecimal discountBase 改成了读取 this.orderContext.getDiscountBase()。
AI 注释里写的是:**"等价重构,将局部变量替换为 context 字段读取,逻辑不变。"**
逻辑确实一样——在大多数场景下。
但问题在于,orderContext.getDiscountBase() 在某些分支下返回的是已经应用了会员折扣之后的值,而原来的局部变量是在折扣应用之前算的。两者在 95% 的情况下相等,只有当订单同时触发多个折扣叠加的时候,值才不同。
为什么 AI 会犯这种错误?
这和上下文窗口的工作原理直接相关。
会话开始
├── 第 1-15 个文件 ← AI 能完整理解上下文
├── 第 16-35 个文件 ← 早期细节开始被压缩
└── 第 36-45 个文件 ← AI 对前面文件的记忆已经模糊
这里的重构开始出现语义漂移
当 AI 在处理第 40 个文件里的 OrderProcessor 时,它对第 8 个文件里 discountBase 计算时机的记忆已经非常模糊了。它只知道"这里用的是 discount base,context 里也有一个 discount base",就做了"等价"替换。
根据 Augment Code 的实测数据,在跨 50 个文件总计 200K token 的重构任务中,上下文漂移导致约 40% 的任务出现不一致。
这不是模型的问题,是架构限制。任何当前的 LLM 都面临同样的问题。
防坑心法一:分批次重构,每批控制在 10-15 个文件。
每完成一批,要求 AI 输出一份"语义变更摘要":哪些函数的行为发生了变化,变化在哪里。这个摘要不需要人工审读每一行,但如果某个函数出现在摘要里,那就重点 Review。
防坑心法二:在业务计算函数旁边写注释,标明时序依赖。
// 注意:此处 discountBase 必须在 applyMemberDiscount() 调用之前计算
// 如果读取 context.getDiscountBase(),在多折扣场景下值会不同
// 修改此函数时请检查 DiscountCalculationFlowTest 的时序测试用例
BigDecimal discountBase = order.getOriginalAmount();
这类注释对人类工程师是废话,但对 AI 是关键信号。有了它,AI 在重构这个函数时会主动保留时序约束,而不是"等价"替换。
防坑心法三:对金融计算、状态机转换、时序依赖的代码,重构后必须跑专项测试。
不是"测试通过"就 OK,是要有覆盖多折扣叠加、边界金额、状态切换顺序的专项用例。这类 case 通常不在普通单测里,需要专门写。
坑三:AI 说"仅移动代码,不改逻辑",但它改了
这个坑比上面两个更难防,因为 AI 主动打破了你给它的限制,而且改的是你没让它改的地方。
有一次我明确告诉 AI:**"只重新组织这个文件的包结构,不要修改任何实现逻辑,不要做任何优化。"**
AI 回答:"明白,我只会移动代码,不做任何功能变更。"
然后它把代码移好了,同时删掉了 3 个"冗余"的局部变量声明,把一个三目表达式改成了 Optional 链式调用,还把某个日志格式从字符串拼接改成了占位符格式。
每一处单独看都是合理的优化。但合在一起,有一处改坏了:
原来的代码是:
String errorMsg = "Order " + orderId + " failed: " + reason;
log.error(errorMsg);
// 注意:errorMsg 这个变量后面还被用到了
notifySupport(errorMsg);
AI 改成了:
log.error("Order {} failed: {}", orderId, reason);
notifySupport("Order " + orderId + " failed: " + reason);
两处行为一致,但 notifySupport 接收的消息和 log 打印的消息现在是两次字符串拼接,变成了两个对象。在原来的代码里,两者是同一个字符串引用,这在某个地方被 == 比较过(是的,这是更早的坑),所以行为不同了。
这类问题的根源在于:AI 不理解"不要优化"这个指令的真实含义。 对 AI 而言,把字符串拼接改成占位符格式不叫"改逻辑",那叫"最佳实践"。它没有办法区分你的"不改逻辑"和它理解的"不改逻辑"。
防坑心法:用 git diff 做机械检查,不要用眼睛。
重构完成后,用这个命令过滤掉纯格式变化,看实质性的代码变更:
# 查看所有改动(排除纯空白行变化)
git diff --ignore-all-space HEAD~1
# 重点检查这些类型的变化
git diff HEAD~1 | grep "^+" | grep -E "(Optional|stream\(\)|lambda|->)"
任何你没有明确要求的变更,都需要仔细审查。如果 AI 在"只移动代码"的任务里修改了表达式,不管改得对不对,都要 Review。
另一个方法是在 prompt 里添加"行为验证要求":
任务完成后,列出所有你修改的代码行(不包括格式调整)。
如果你修改了任何我没有明确要求修改的逻辑,请在报告里标注原因。
大多数时候 AI 会老实报告。偶尔它会遗漏,但这比完全不报要好得多。
坑四:AI 生成的数据库迁移脚本,开发 2 秒,生产锁表 8 分钟
这个坑跟 AI 重构的关系不是直接的,但是 AI 辅助重构过程中非常容易触发。
我们在重构中新增了一个字段 processed_at,AI 生成了对应的 Flyway 迁移脚本:
ALTER TABLE orders ADD COLUMN processed_at DATETIME;
UPDATE orders SET processed_at = created_at WHERE status = 'COMPLETED';
CREATE INDEX idx_orders_processed_at ON orders(processed_at);
在开发环境,1000 条数据,2 秒跑完,完美。
到了生产环境,orders 表 5200 万行。
ALTER TABLE 在 MySQL 5.7 默认加表级锁,8 分钟。
这 8 分钟里,所有涉及 orders 表的写操作全部阻塞。我们的下单服务直接打满,P99 超过 30 秒,用户侧开始出现超时错误。
数据库 DBA 问了一句话我现在还记得:"这个脚本你们 review 过大表影响吗?"
我当时不知道怎么回答。
AI 生成的脚本在逻辑上完全正确。它没有做错任何事。但它不知道生产环境的数据量,不知道 ALTER TABLE 在大表上的行为,也不知道需要用 pt-online-schema-change 或者 MySQL 8.0 的 INSTANT 算法来避免锁表。
这类问题在小数据集开发环境里根本不会暴露,AI 又无法感知生产数据规模。
防坑心法:建立数据库迁移的 checklist,AI 生成脚本后必须走 checklist。
数据库迁移 Review Checklist:
□ 涉及的表当前行数是多少?(生产数据)
□ ALTER TABLE 操作在 MySQL 版本下是否使用行锁?还是表锁?
□ 行数超过 100 万时,是否使用 pt-online-schema-change 或 gh-ost?
□ UPDATE 操作是否有 WHERE 条件?批量更新是否分批执行?
□ 新建索引是否在低峰时段执行?
□ 这个迁移是否可回滚?如果不可回滚,已知晓风险?
对于大表 DDL,推荐的命令是:
# 使用 pt-online-schema-change(100万行以上)
pt-online-schema-change \
--alter "ADD COLUMN processed_at DATETIME" \
--execute \
D=your_db,t=orders
# 或者 MySQL 8.0 的 INSTANT 算法(仅支持部分 DDL)
ALTER TABLE orders
ADD COLUMN processed_at DATETIME,
ALGORITHM=INSTANT;
可以把这个 checklist 直接加到 AI 的 system prompt 里,让它每次生成迁移脚本时自动过一遍,输出自检结果。不是所有问题都能被它发现,但会好很多。
这些坑背后的共同原因
四个坑,表面看原因各不相同,但往深里追有一个共同点:AI 没有你的系统上下文,但它的输出看起来像是有。
Spring 反射的坑,是因为 AI 看不见运行时的依赖图,只能看见静态引用图。
上下文窗口的坑,是因为 AI 对早期文件的记忆随着会话拉长而衰退,但输出不会标注"这部分我记得不清楚了"。
自作聪明优化的坑,是因为 AI 对"最佳实践"的理解是训练数据驱动的,它无法理解"不要优化"的真实意图。
大表迁移的坑,是因为 AI 对生产数据量一无所知,它只能基于逻辑正确性给出建议。
根据 Harness 2025 年的报告,近 75% 的组织在使用 AI 生成代码之后经历过生产事故。这个数字不是说 AI 不好用,是说现阶段 AI 辅助编程的"人工监管密度"被严重低估了。
AI 能把重构速度提到原来的 3-5 倍。但对于遗留系统,监管密度要同等提升,不然速度越快,坑越深。
防坑总结:遗留代码 AI 重构的 5 条原则
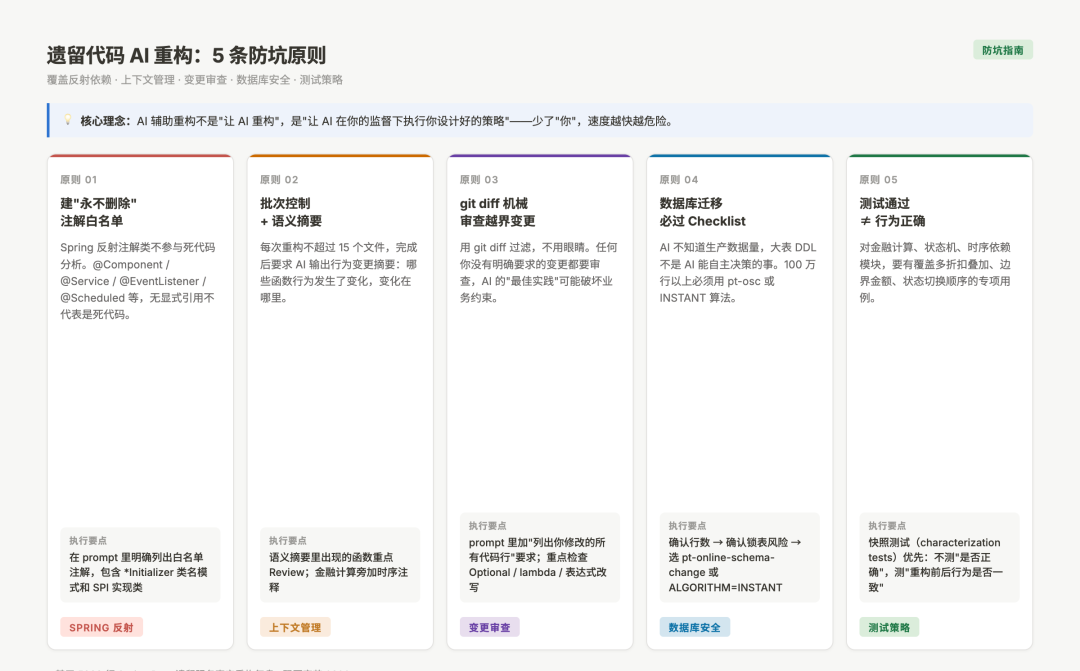
AI遗留代码重构五条原则对比图
图:遗留代码AI重构的五条防坑原则与执行要点
原则一:给 AI 建"永不删除"的白名单
Spring 注解类、反射调用路径、SPI 机制注册的实现类——这些在 prompt 里明确标注,不参与死代码分析。
原则二:批次控制 + 语义摘要
每次重构不超过 15 个文件,完成后要求 AI 输出行为变更摘要,重点审查摘要里出现的函数。
原则三:用 git diff 机械检查,不用眼睛
任何你没有明确要求的变更,都要审。AI 的"最佳实践"和你的业务逻辑可能不兼容。
原则四:数据库迁移必须过 checklist
大表 DDL 不是 AI 能自主决策的事,必须人工 Review,必须确认生产数据量,必须选对工具。
原则五:测试通过不等于行为正确
对金融计算、状态机、时序依赖的模块,要有专项 case 覆盖边界场景。单测 pass 只是入门,不是终点。
常见问题
Q:遗留代码重构,用 Claude Code 还是 Cursor?
对于大规模跨文件重构,Claude Code 更合适。Cursor 的上下文管理在单文件或少数文件时体验更好,但超过 20 个文件的重构任务,Cursor 经常在中途丢失之前的变更上下文,而 Claude Code 的 Agent 模式可以维护任务状态。需要注意的是,Claude Code Pro 中等复杂度重构大概 30 分钟左右会触发速率限制。
Q:AI 重构的速度提升是真实的吗,还是有水分?
速度提升是真实的,但有前提条件。我们 14 天完成了原来估计需要 35 天的工作,但测试覆盖率从 8% 提到 75% 花了相当多时间,前期诊断和后期修坑合计占了约 30% 的时间。如果只算"代码生成"部分,确实快很多;如果算端到端上线时间,提升大约在 40-50%,不是宣传的"10 倍"。
Q:遗留系统最适合从哪里开始让 AI 介入?
从工具函数和纯计算函数开始,这类函数没有 Spring 注解、没有数据库操作、没有时序依赖,AI 重构的安全边界最清晰。核心业务流程、状态机、支付计算,放到最后,而且只让 AI 做"解释和建议",人工执行改动。
Q:AI 给出的"完全等价"承诺可信吗?
从字面上说不可信。AI 的"完全等价"是基于它看到的代码,不包括运行时依赖、数据量差异、并发场景。一个务实的判断标准是:如果这个函数涉及金钱、状态机、外部系统调用、数据库写操作,"完全等价"只是起点,还需要专项验证。
Q:测试覆盖率低的遗留代码,重构之前需要先补测试吗?
需要,但不是补所有测试。优先级是:核心业务流程的集成测试 > 容易被 AI 误改的函数的单元测试 > 基线行为的快照测试(characterization tests)。快照测试特别有用——它不测"代码是否正确",只测"重构后行为是否和重构前一致",可以快速给遗留代码加上安全网。
总结
踩这几个坑让我想明白一件事:AI 辅助重构的本质不是"让 AI 重构",是"让 AI 在你的监督下执行你设计好的重构策略"。少了"你"这个主体,速度越快越危险。
下一篇打算写遗留系统重构的分层测试策略——先给屎山加安全网,再动刀。感兴趣的关注一下,这种内容算法不一定会主动推,关注了才能第一时间看到。如果你身边也有人正在被 AI 重构坑着,这篇可以直接甩给他,比解释半天省事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号