Redis Cluster 采用 Gossip 协议

Redis Cluster 采用 Gossip 协议

码农戏码
发布于 2026-06-25 19:53:26
发布于 2026-06-25 19:53:26
在分布式系统中,需要提供维护节点元数据信息的机制,所谓元数据是指节点负责哪些数据、主从属性、是否出现故障等状态信息。
常见的元数据维护方式分为集中式和无中心式。
Redis Cluster 采用 Gossip 协议实现了无中心式。
Redis Cluster 中使用 Gossip 主要有两大作用:
1、去中心化,以实现分布式和弹性扩展;
2、失败检测,以实现高可用;
节点通信
Redis Cluster 中的每个 Redis 实例监听两个 TCP 端口,6379(默认)用于服务客户端查询,16379(默认服务端口+10000)用于集群内部通信。集群中节点通信方式如下:
1、每个节点在固定周期内通过特定规则选择几个节点发送 Ping 消息;
2、接收到 Ping 消息的节点用 Pong 消息作为响应。
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点故障、新节点加入、主从关系变化、槽信息变更等事件发生时,通过不断的 Ping/Pong 消息通信,经过一段时间后所有的节点都会知道集群全部节点的最新状态,从而达到集群状态同步的目的。
具体规则如下:
集群的周期性函数 clusterCron() 执行周期是 100ms,为了保证传播效率,每10个周期,也就是 1s,每个节点都会随机选择5个其它节点,并从中选择一个最久没有通信的节点发送 ing消息,源码如下:
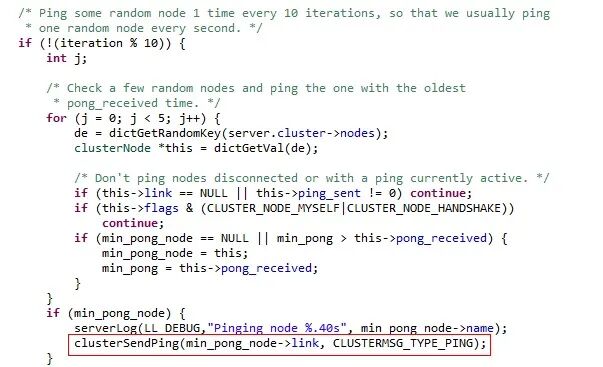
这样还是没法保证效率,毕竟5个节点是随机选出来的,其中最久没有通信的节点不一定是全局“最久”。
因此,对哪些长时间没有“被”随机到的节点进行特殊照顾:
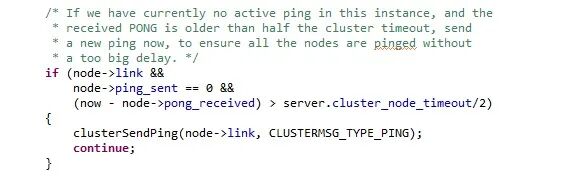
每个周期(100ms)内扫描一次本地节点列表,如果发现节点最近一次接受 Pong 消息的时间大于 cluster_node_timeout/2,则立刻发送 Ping消息,防止该节点信息太长时间未更新。
源码如下:
关键参数 cluster_node_timeout
从上面的分析可以看出,cluster_node_timeout 参数对消息发送的节点数量影响非常大。当带宽资源紧张时,可以适当调大这个参数,如从默认15秒改为30秒来降低带宽占用率。
但是,过度调大 cluster_node_timeout 会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发现的速度,因此需要根据业务容忍度和资源消耗进行平衡。
同时整个集群消息总交换量也跟节点数成正比。
Reference
https://www.cnblogs.com/smalltechnologyjun/p/15858962.html
https://www.cnblogs.com/gaoyanbing/p/17358598.html
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号