Qwen3.5-Omni 技术报告精读:一个模型同时"看、听、说",215 项 SOTA 正面挑战 Gemini

Qwen3.5-Omni 技术报告精读:一个模型同时"看、听、说",215 项 SOTA 正面挑战 Gemini

唐国梁Tommy
发布于 2026-06-25 21:40:11
发布于 2026-06-25 21:40:11
闭源天花板,正在被撬动
过去一年,只要谈到"原生多模态",大家的第一反应几乎是 Gemini。
一个模型同时吞掉文本、图像、音频、视频,再自然地说出一段有情绪的回答——这听上去像理所当然的未来,但真正做出来的团队屈指可数。
2026 年 4 月,阿里 Qwen 团队把 Qwen3.5-Omni 的技术报告挂上了 arXiv。它的野心很直接:在 215 项音频与音视频任务上拿下 SOTA,在关键音频任务上超越 Gemini-3.1 Pro,在综合音视频理解上与之打平。
这是开源阵营第一次,在"全模态"这个最难的赛道上,把牌桌掀到同一张桌上。
为什么"全模态"这么难
在此之前,大部分号称"多模态"的模型,其实是多个专用模块的拼接:
- 视觉靠一个冻结的 ViT
- 语音靠外挂的 ASR / TTS
- 文本端独立训练后再"缝"起来
问题是,这种架构只能堆叠能力,很难让模型真正"听懂声音里的情绪"、"看见画面中的节奏"。尤其在流式语音合成、长时长音视频理解、跨模态涌现这三件事上,拼接式方案会暴露出结构性的短板。
Qwen3.5-Omni 想解决的,正是这件事。
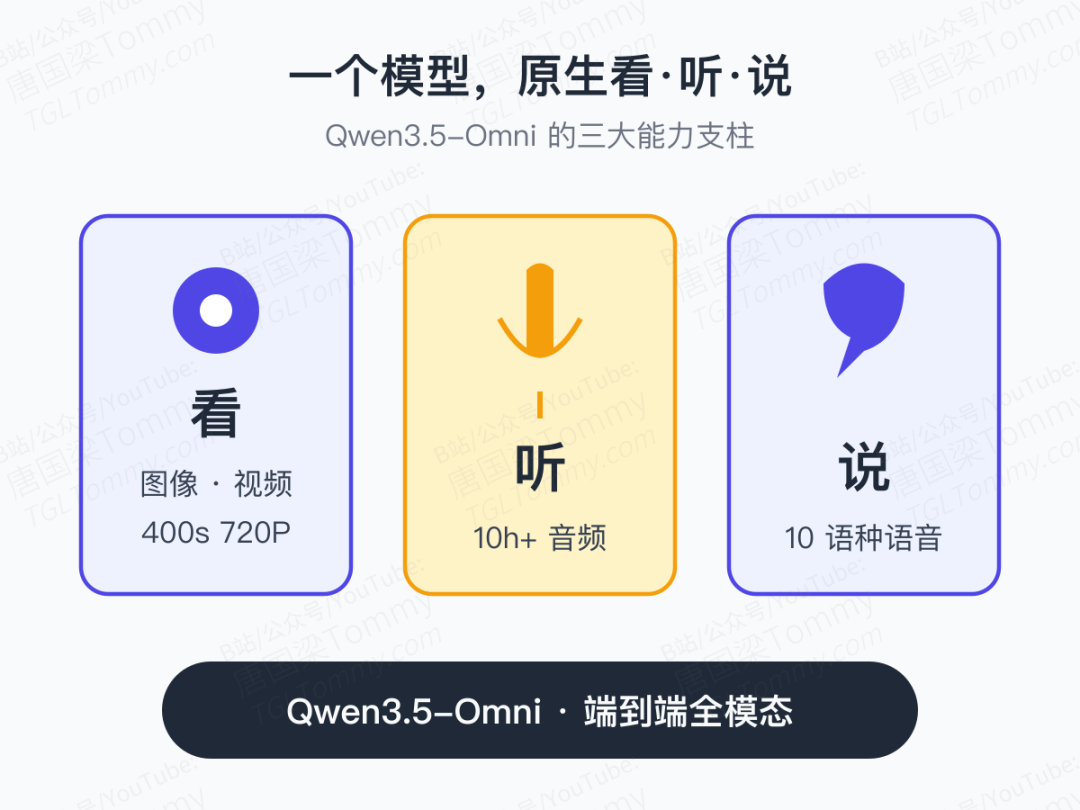
先看几个能打的数字

- 参数规模:数百亿级别
- 上下文长度:256k tokens
- 训练数据:超过 1 亿小时 的异构音视频内容
- 音频理解时长:支持 10 小时以上 连续音频
- 视频处理:400 秒 720P 视频,1 fps 采样
- 多语种:10 种语言 的理解与语音生成
- 基准成绩:215 项 音频与音视频子任务上达到 SOTA
这些数字单独看都不算轰动,但把它们摆在一起——尤其是"1 亿小时训练数据 + 256k 上下文 + 10 小时音频"——你就知道这是一个认真为长时多模态场景重新设计的模型,而不是把已有模型再套一层皮。
核心架构:Thinker 想、Talker 说
Omni 系列一直沿用 Thinker + Talker 的双组件思路:
- Thinker 负责理解和推理,吸收多模态输入,做思考
- Talker 负责生成和表达,把想法以自然语音的方式说出来
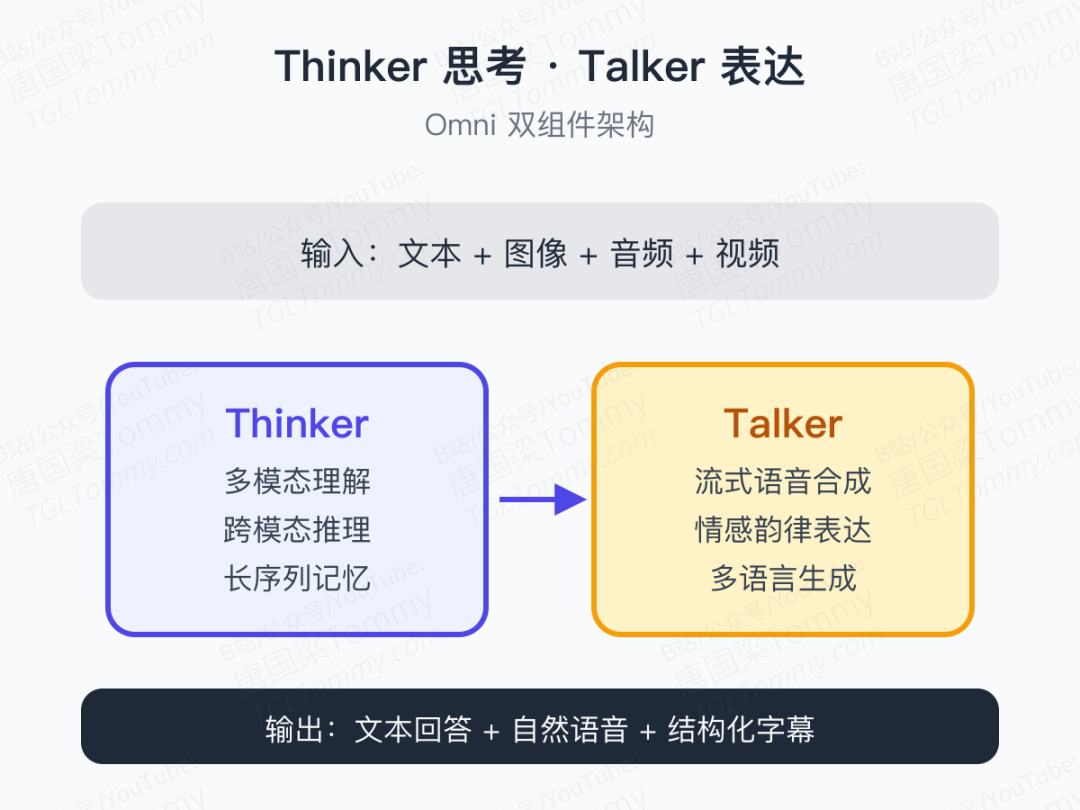
这次的关键升级,是给这两个组件同时换上了 Hybrid Attention MoE(混合注意力专家混合) 框架。

通俗地讲,它在长序列推理中做了两件事:
- 混合注意力:不同层用不同粒度的注意力机制,局部密集 + 全局稀疏,兼顾精度与效率
- 专家路由:不同类型的 token(视觉 / 音频 / 文本)可以动态分配给最擅长处理它的专家
这也是 Qwen3.5-Omni 敢开 256k 上下文、敢吞 10 小时音频 的底座——没有这层架构重写,长序列的显存与计算都会崩掉。
ARIA:让流式语音终于"像人"
如果说架构是骨架,那么 ARIA 就是让这具骨架开口说话时最关键的那块肌肉。
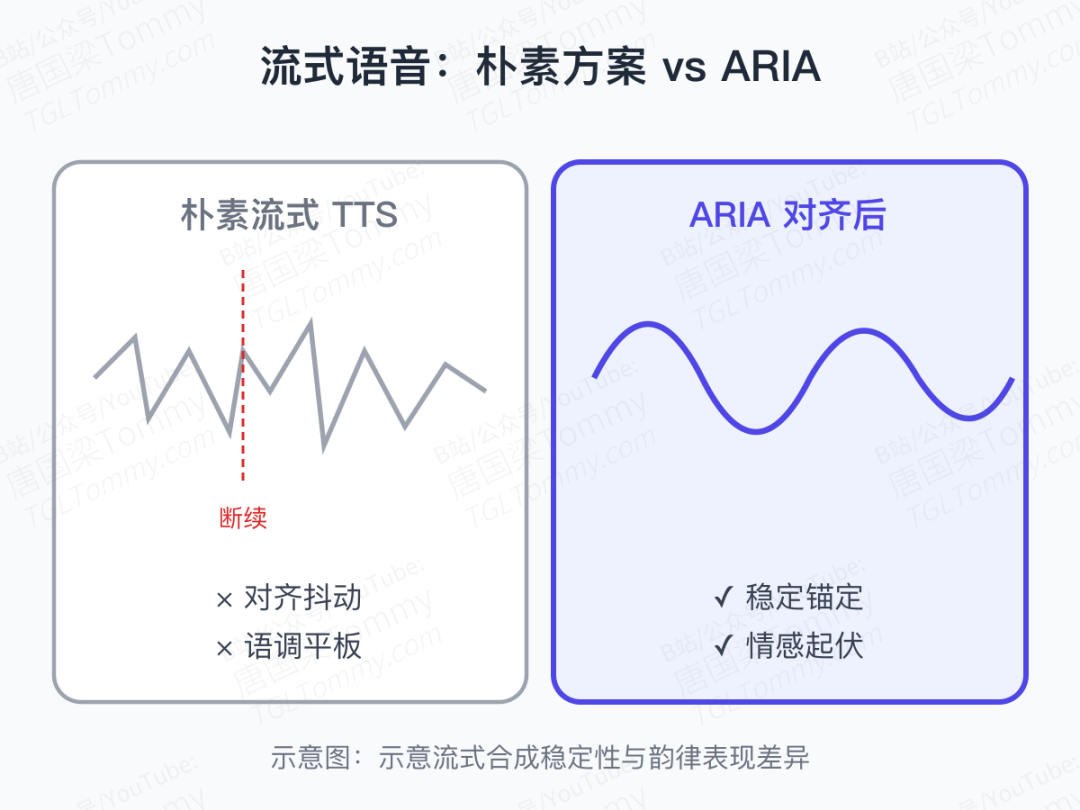
流式语音合成长期有两个顽疾:
- 对齐不稳:生成到一半,文本和语音错位,出现断续或吞字
- 韵律平板:语调平均化,缺少人类讲话中的起伏与呼吸感
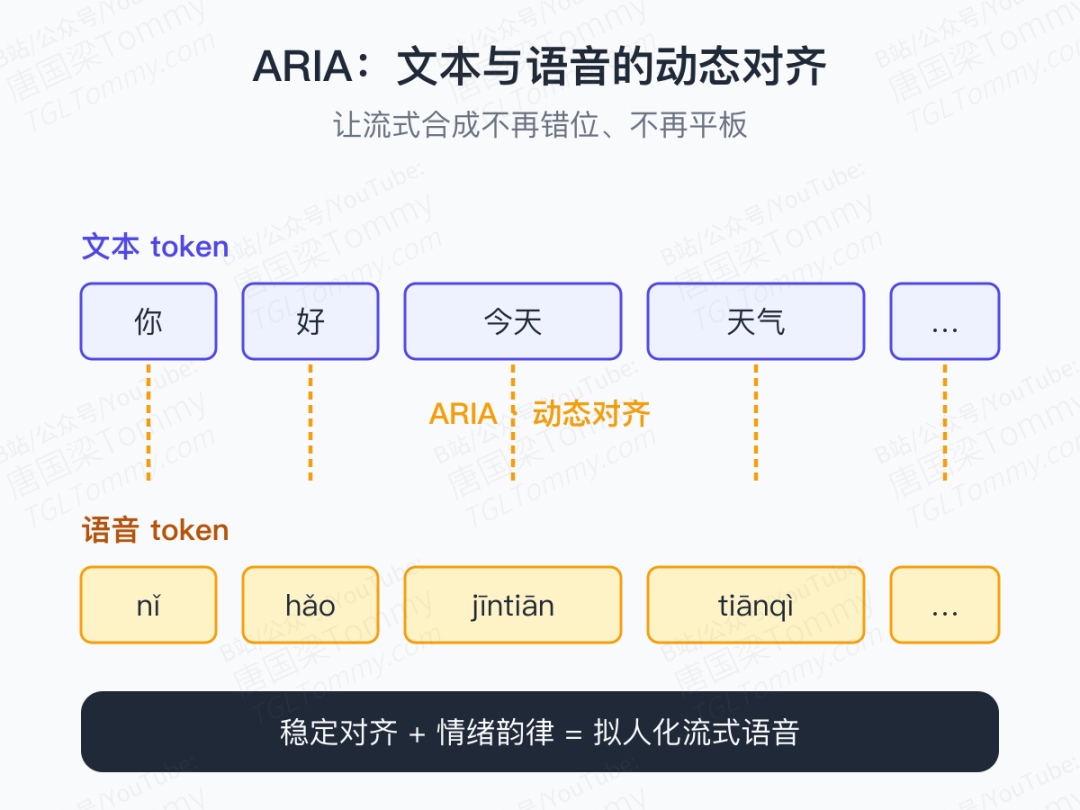
ARIA 的做法是在文本 token 与语音 token 之间做动态对齐,让 Talker 在生成每一段语音单元时,都能精确锚定到对应的语义片段。结果是:
- 流式合成的稳定性显著提升
- 对话语音具备情绪起伏
- 支持 10 种语言的类人表达
对公众号读者更有画面感的一句话是:以前的 AI 语音助手像念稿,Qwen3.5-Omni 的 Talker 像在和你聊天。
超长上下文:把"一整节课"一次性塞进去
多模态模型拼到最后,比的是"它能消化多少原始信号"。

- 10 小时音频:足以覆盖一节完整课程、一本有声书、一整档深度播客
- 400 秒 720P 视频(1 fps):可以容纳一条完整短片、一场 7 分钟的演示视频
对用户而言,这意味着无需切片、无需人工摘要,模型直接读完再回答。
十种语言,带情绪的语音生成
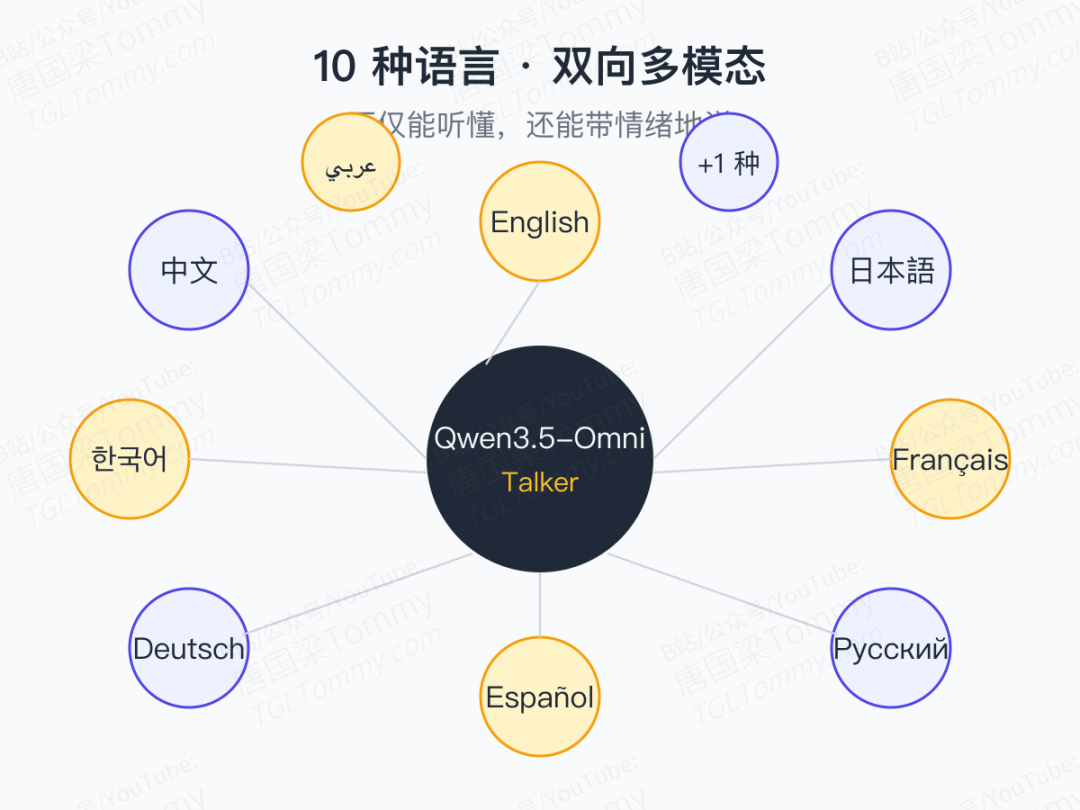
Qwen3.5-Omni 支持 10 种语言的双向多模态处理——既能听懂,也能说。
更关键的是,它被训练为"带情感表达"的语音生成,而不是单纯的 TTS。从技术报告的描述看,情感承载的能力来自 Talker + ARIA 的联合训练,而不是事后调音。
这对跨境播客、多语种语音客服、本地化内容分发等场景,是一次可用性层面的跃迁。
惊喜彩蛋:Audio-Visual Vibe Coding
这是整篇报告里最"未来感"的一段——团队明确把它列为涌现能力。
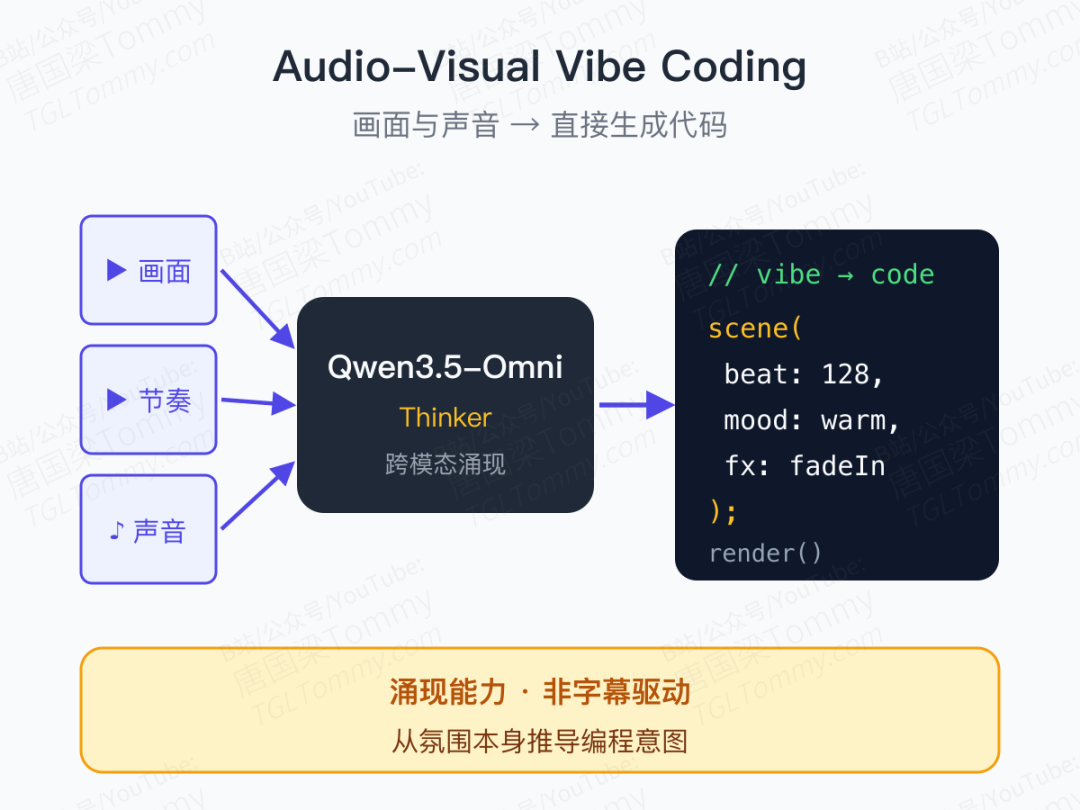
所谓 Audio-Visual Vibe Coding(音视频氛围编程),指的是:
你给模型一段视频或音频,它能直接生成对应的代码。
注意,这不是"根据字幕生成代码",而是直接从画面节奏、声音情绪中推导出编程意图。
配合报告里提到的脚本级结构化字幕 + 自动场景分割 + 精确时间戳同步,一条全新的工作流已经浮出水面:视频 → 结构化语义 → 可执行代码 / 动效。
这可能比任何基准分数都更值得关注。
215 项 SOTA 的含金量
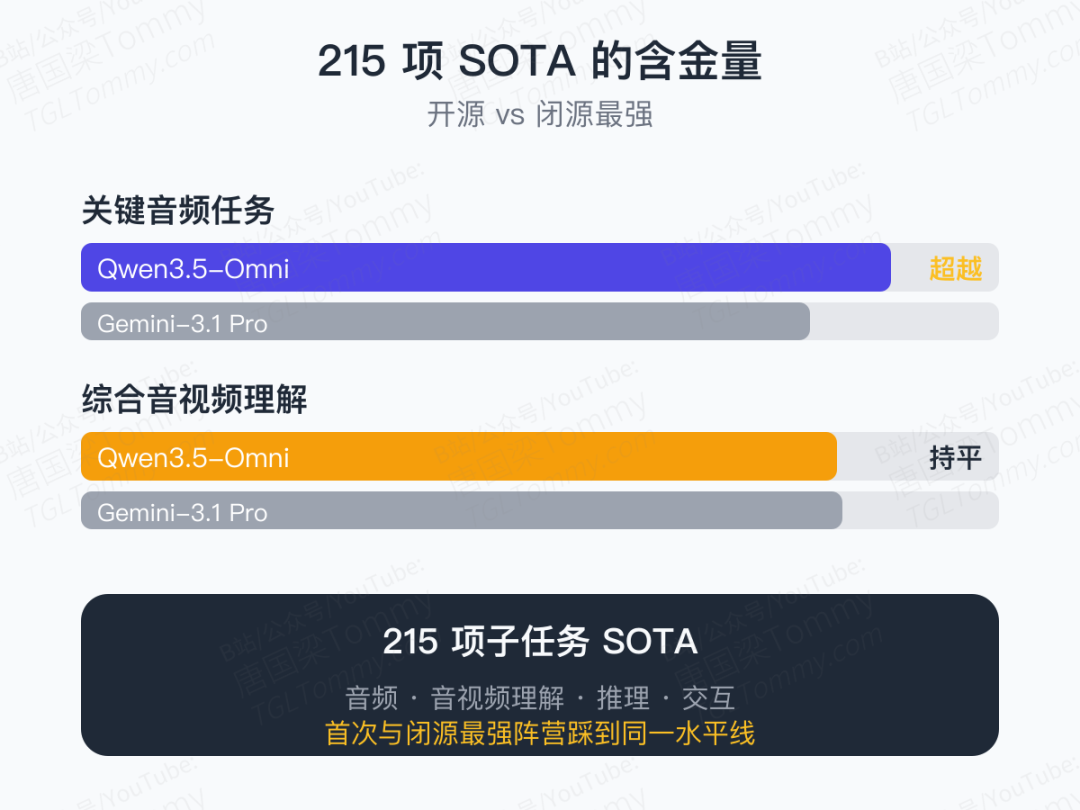
215 这个数字听起来有点虚,但拆开看就能明白它的分量:
- 超越 Gemini-3.1 Pro 的,是"关键音频任务"——也就是大家最看重的语音理解与生成链路
- 与 Gemini-3.1 Pro 持平 的,是综合音视频理解——这是最难的复合任务
换句话说,开源模型第一次在全模态赛道上,和闭源最强阵营踩到了同一条水平线。
它能带来什么?
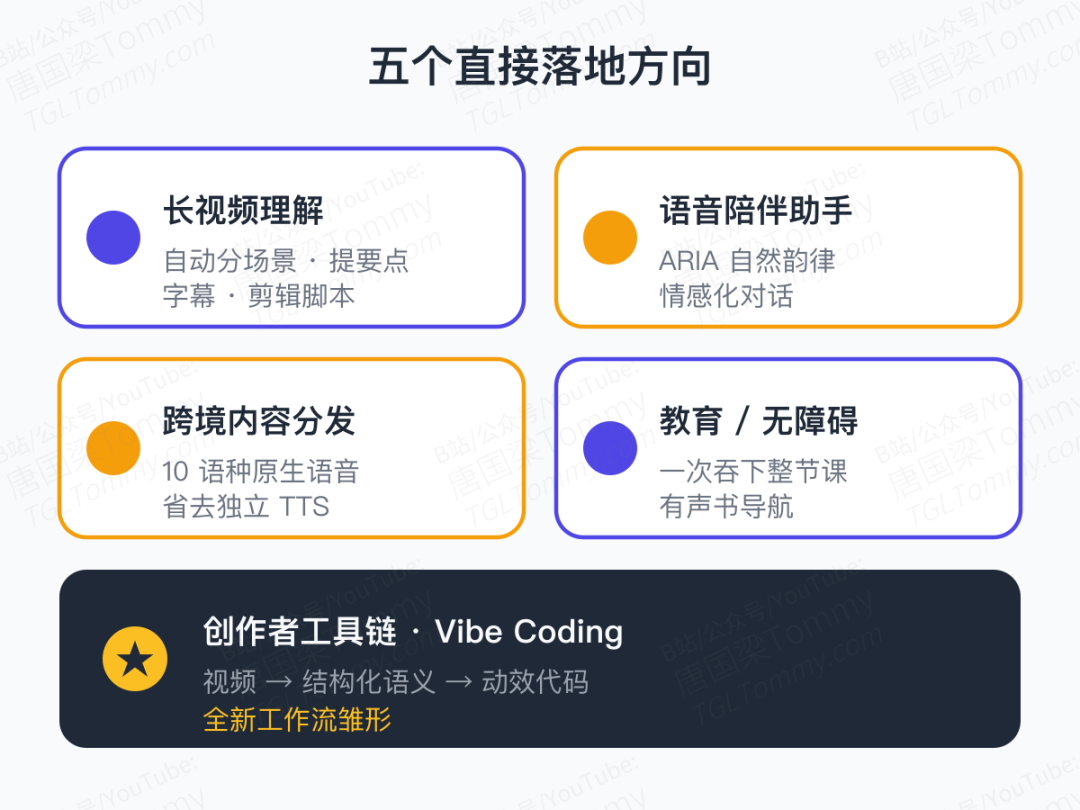
结合上述能力,几个最直接的落地方向:
- 长视频理解 / 自动剪辑:一次吞完 400 秒视频,自动分场景、配字幕、提要点
- 语音陪伴与情感助手:ARIA 带来的自然韵律,让对话不再"AI 味"
- 跨境内容分发:10 语种原生语音生成,省去独立 TTS 模块
- 教育与无障碍:10 小时长音频一次性理解,课程摘要、有声书导航变得可行
- 创作者工具链:Vibe Coding 让"视频 → 动效代码"有了第一个模型级原型
冷静一下:还有哪些限制
再强的模型也不是万能药。从报告本身与公开信息可以推导出几个需要保留的疑问:
- 实际部署成本:数百亿参数 + 256k 上下文,推理成本显著高于常规 LLM
- 10 小时音频的"理解深度":能吃下,不等于能等价理解——长尾事实召回仍是挑战
- Vibe Coding 的泛化性:作为涌现能力,稳定性与可控性还需要更多真实验证
- 215 项 SOTA 的评测口径:需要关注评测集的选取偏好与可复现性
这不是否定,而是给读者一个"保持理性"的锚点。
结语:全模态的拐点,可能就是现在
Qwen3.5-Omni 的价值,不在于又刷新了一次榜单,而在于它用一份扎实的技术报告,把下面这四件事一次性做到了接近闭源最强水平:
- 长时长多模态上下文
- 流式拟人化语音
- 多语言情感表达
- 跨模态涌现能力
对开源社区而言,这可能是"全模态路线"的一次关键拐点;对产品团队而言,这也许就是你重新审视自己技术栈的时间点。
至少从这一篇报告看,"看、听、说"不再是三个模型的事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号