Headroom:Netflix 工程师开源的上下文压缩工具,省 token 还是烧 token?

Headroom:Netflix 工程师开源的上下文压缩工具,省 token 还是烧 token?

用户11563501
发布于 2026-06-29 12:27:28
发布于 2026-06-29 12:27:28
如果你每天跟 Claude Code 或 Cursor 打交道,大概对一件事深有体会:token 烧得比想象中快。
长日志、RAG 捞回来的文档、多文件扫描结果——这些东西一股脑塞给 AI,还没开始干活,配额先去了小半。
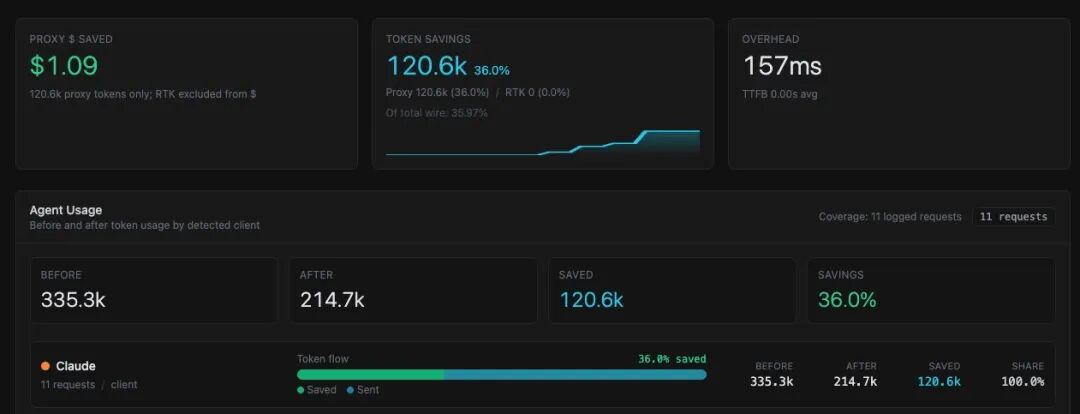
Netflix 工程师 Tejas Chopra 开源的 Headroom (https://github.com/chopratejas/headroom),想解决的就是这个问题。项目上线后迅速冲到 35K+ star,Twitter 上讨论它的帖子来自英文、日文、西班牙文社区,算是近期少有的跨圈层项目。

它做了什么
Headroom 把自己定位成"AI Agent 的上下文压缩层"。在 Agent 把数据发给 LLM 之前,它先拦截下来,做一轮智能压缩。
压缩的不是 prompt 里你写的那段话,而是工具输出、日志、RAG chunks、文件内容、对话历史——那些 AI 要读但你不怎么关心的东西。
官方给的实测数据:
场景 | 压缩前 | 压缩后 | 节省 |
|---|---|---|---|
代码搜索(100 条结果) | 17,765 | 1,408 | 92% |
SRE 故障排查 | 65,694 | 5,118 | 92% |
GitHub Issue 分类 | 54,174 | 14,761 | 73% |
代码库探索 | 78,502 | 41,254 | 47% |
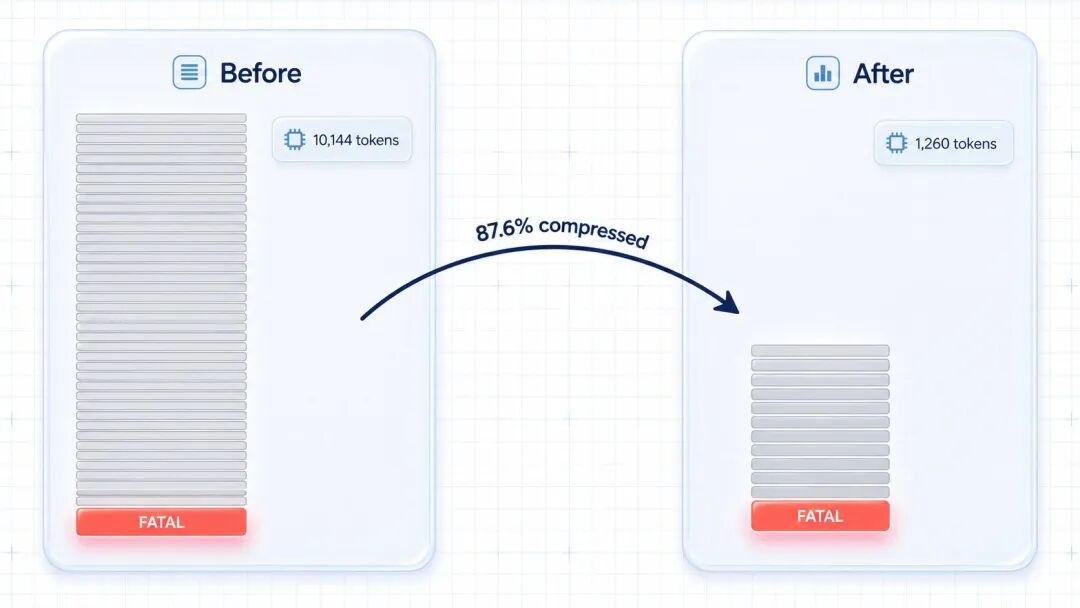
一个演示里,10,144 token 的输入被压到 1,260,而 AI 依然正确找到了同一个 FATAL 错误。
关键设计:可逆压缩
这是 Headroom 和普通摘要工具最大的区别。
大多数压缩方案是单向的——信息丢了就丢了。Headroom 用的是 CCR(Context Compression with Retrieval):压缩后的内容发给 LLM,原始内容缓存在本地。如果 LLM 觉得信息不够,可以主动调用 headroom_retrieve 把原文拿回来。
相当于给 AI 配了个"按需查阅"的能力,而不是逼它在压缩后的残片里猜。
六种算法,按内容类型路由
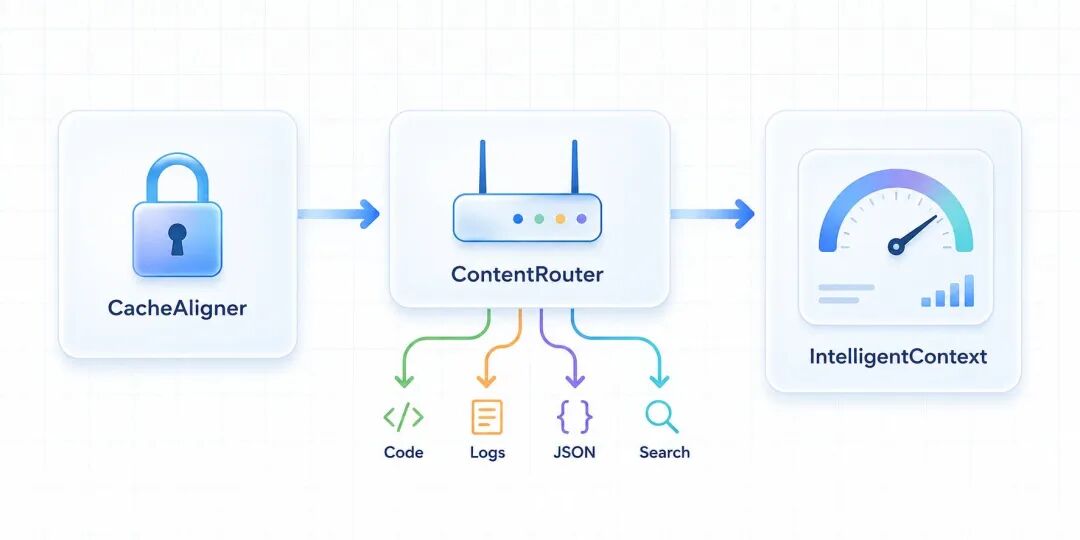
Headroom 内部有 6 种压缩算法,通过 ContentRouter 自动识别内容类型后选择:
- SmartCrusher:处理 JSON,支持嵌套对象和混合类型
- CodeCompressor:基于 AST 做代码压缩,支持 Python、JS、Go、Rust、Java、C++
- Kompress-base:通用文本压缩,基于 HuggingFace 上自训的模型
- Image compression:图片压缩,40-90% 缩减
- CacheAligner:稳定 prompt 前缀,让 Anthropic/OpenAI 的 KV cache 能命中
- IntelligentContext:基于重要性评分做上下文裁剪
三种接入方式
Library 模式:在代码里直接调用 compress(messages),Python 和 TypeScript 都支持。
Proxy 模式:headroom proxy --port 8787 启动一个本地代理,零代码改动,任何语言的客户端都能用。
Agent wrap 模式:headroom wrap claude 一键包装 Claude Code、Codex、Cursor、Aider、Copilot CLI。
兼容性矩阵:
Agent | 支持 |
|---|---|
Claude Code | ✅ |
Codex | ✅ |
Cursor | ✅ |
Aider | ✅ |
Copilot CLI | ✅ |
OpenClaw | ✅ |
Cortex Code | ✅ |
任何兼容 OpenAI API 的客户端,走 headroom proxy 都能用。
输出端也在管
压缩输入只是故事的一半。模型写回的内容同样浪费严重——"Great, let me..." 这种开场白、重复你刚给它的代码、对常规操作做深度思考。
Headroom 的 Output Token Reduction 功能(默认关闭)做了两件事:
- Verbosity steering:在 system prompt 末尾加一句"简洁回答,不要复述上下文",不影响 prompt cache
- Effort routing:如果当前轮次只是模型读完工具结果后的续写,自动降低思考深度;新问题或报错则保持全力
headroom learn --verbosity 还能分析你的历史会话,自动学习你偏好的简洁程度。
跨 Agent 记忆
如果你同时用 Claude Code 和 Codex,Headroom 的跨 Agent 记忆可以在它们之间共享上下文,自动去重。headroom learn 还能挖掘失败的会话,把修正写到 CLAUDE.md 或 AGENTS.md 里。
精度测试
官方在标准 benchmark 上的结果:
测试 | 类别 | 基线 | Headroom | 变化 |
|---|---|---|---|---|
GSM8K | 数学 | 0.870 | 0.870 | ±0.000 |
TruthfulQA | 事实性 | 0.530 | 0.560 | +0.030 |
SQuAD v2 | 问答 | — | 97% | 19% 压缩 |
BFCL | 工具调用 | — | 97% | 32% 压缩 |
数学推理零误差,事实性回答反而略有提升。
真实世界的声音:Evan Boyle 的实测
以上都是项目方给出的数据。但真实世界里,有人拿它跑了一遍。
Evan Boyle,微软 Copilot 团队的工程师,他把 Headroom 集成到 Copilot 里跑了一下午的评估,结论是:结果中性偏负面,多数场景下反而消耗了更多 token。
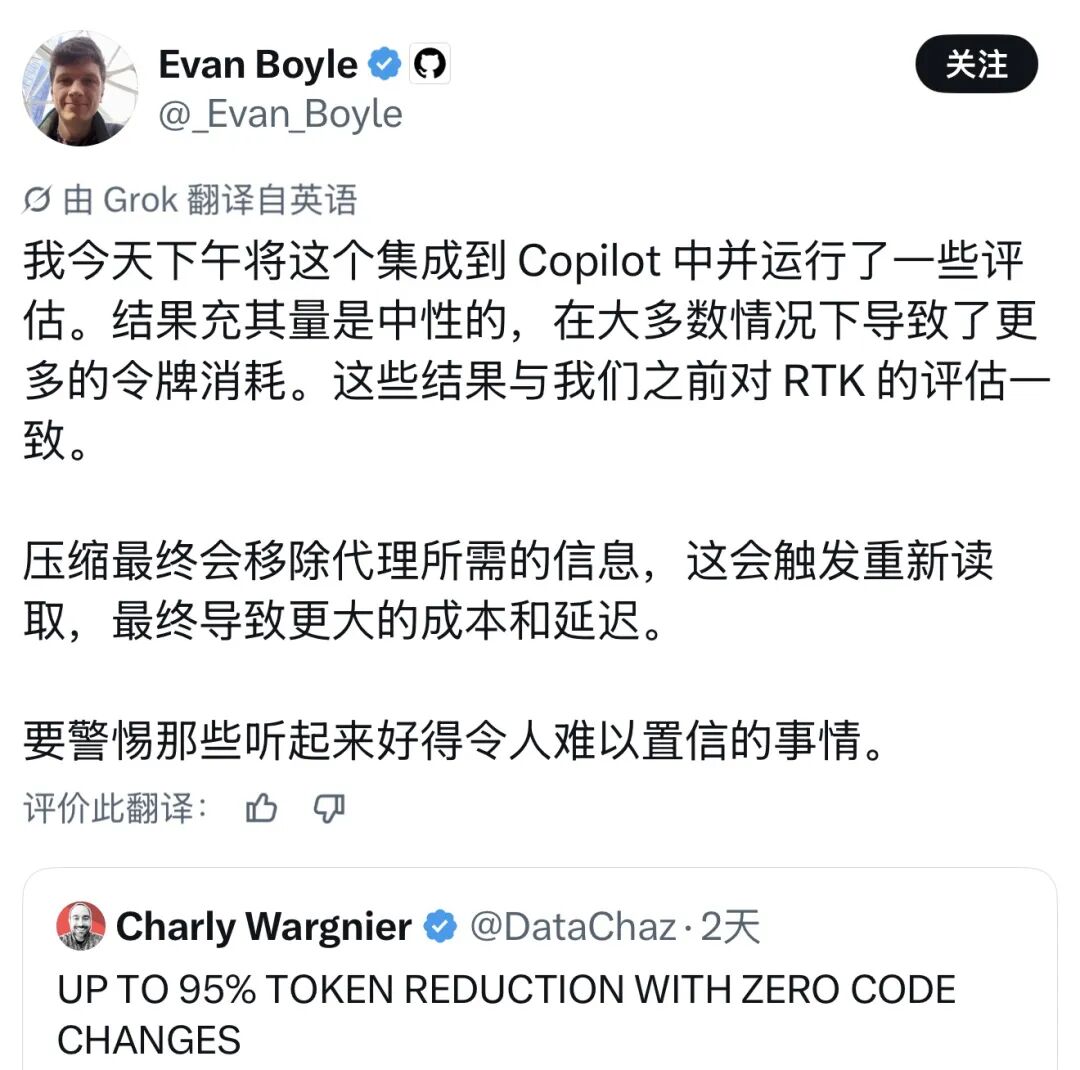
原因不难理解——压缩删掉了 Agent 需要的信息,触发模型重新读取原始内容,最终成本更高、延迟更大。Boyle 的原话是:"Beware of things that sound too good to be true."
他进一步补充:"如果这些东西真的有效,它早就成为 harness 的默认行为了。"
这条推文下面,不少用户分享了类似的体验:
- 有人用了三天后,Claude 开始莫名其妙地"移动"文件,旧文件消失,新文件也没创建
- 有人反馈 Codex 和 Claude Code 接入后直接停止工作
- Nous Research 的 Teknium 让 Hermes Agent 评估了 Headroom,结论是"对 Hermes 来说,大部分场景下反而是净 token 成本增加"
- 多位用户表示"不得不完全移除 RTK 才能让 coding agent 正常工作"
Boyle 说他愿意看 SWEBench 或 terminalbench 上能证明改进的跑分数据,但在此之前,他会把精力放在其他优化方向上。
一句话总结
Headroom 解决的不是"怎么省 token"的问题——它解决的是"在不改代码、不改工作流的前提下,怎么让 AI Agent 更省钱"的问题。但至少从目前真实用户的反馈来看,这个方案在通用 coding agent 场景下,可能还不如不用。
笔者很早就关注了这个项目,曾在tokenbank里试图集成这一工具,但经过研究测试下来,工具输出压缩层面有一定的价值,但从用户使用角度来看有些鸡肋,比如它要求以它约定的方式打开,另外隐式的context注入也会带来很多未知的问题。另外,其ccr的亮点,也很有可能导致隐性的工具调用干扰,收益是否明确,还是需要考量的。笔者在实际实现中选择了显性的交接和无损压缩的方式,算是一个在全自动与手工,白盒还是黑盒的一个折中。它的一些会话挖掘的思路值得学习,在tokenbank中也借鉴实现了类似的能力。
如果你还是想试试,花 60 秒装一个,在自己的工作流上跑跑看。毕竟,听别人说什么都不如你自己的体验靠谱。
项目地址:github.com/chopratejas/headroom 文档:headroom-docs.vercel.app 协议:Apache 2.0
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号