国外大学生都用FPGA做什么项目(十六)

国外大学生都用FPGA做什么项目(十六)

FPGA技术江湖
发布于 2026-06-29 13:04:02
发布于 2026-06-29 13:04:02
阔别已久的大学生项目,今天又开始了,主要是2024年和2026年两年的(之前是到2023年的)。
常规小引:
据我了解,目前国内很多大学是没有开设FPGA相关课程的,所以很多同学都是自学,但是自学需要一定的目标和项目,今天我们就去看看常春藤盟校Cornell University 康奈尔大学开设的FPGA项目课程,大部分课程是有源码的,而且和国内使用习惯类似都是Verilog开发,还是很有借鉴意义的。
项目链接
https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/
项目介绍
2024 年秋季 开发板:CycloneV DE1-SoC
音频/视频 FPGA 到 FPGA
介绍
新冠疫情爆发后,虚拟通信工具迅速普及,重塑了我们对教育和职业环境中团队合作的理解。旨在促进远程通信的数字工具已成为我们学术体验的重要组成部分。考虑到本学期课程的异步性质,自然而然地选择在期末项目中探索如何在FPGA之间实现实时视频和音频通信。使用美国国家电视标准委员会(NSTC)的摄像机和立体声麦克风进行视频和音频数据采集,设计并实现了一种协议,使两个开发板能够成功且同时地交换数据,从而通过GPIO创建了一个视频通话系统。
顶层设计
项目实现了两块 DE-1 SoC FPGA 板之间的双向音视频通信。主要使用 Verilog 语言,通过状态机对视频总线进行读写操作来处理数据采集和传输。此外,还使用 HPS 与 NSTC 摄像头通信。音频数据从麦克风输入端口读取,并通过线路输出端口播放。使用 EBAB 总线主控器来处理与麦克风音频采样和播放相关的复杂操作。EBAB 总线主控器也用于视频播放。视频和音频的工作原理基本相同。总线主控器分别用于处理读取和写入操作,需要注意的是,这两个操作不能同时进行。
当音频或视频播放仅在一个电路板上进行时,该过程相当简单。当准备写入数据时,写入的将是之前状态中读取的数据。本项目的主要难点在于设计一个多板同步方案,确保在双向通信期间,一旦一个电路板完成对其摄像头和麦克风的读取,另一个电路板就能在数据写入的时间间隔内通过 GPIO 接口提供正确的数据。然而,一些因素使得音频比视频更容易处理。首先,音频的可靠性要求并不高。某些数据可能会“丢失”,这意味着它没有成功写入接收器的输出端。假设这种情况不经常发生,偶尔的丢失对输出音频质量没有明显的影响。其次,视频不需要像视频那样进行寻址来将像素颜色映射到 VGA 显示器上的位置。
由于这些关键差异,可以采用不同的方法来创建音频和视频播放,并分别处理它们的通信。这种划分背后的逻辑是,如果音频和视频看似实时地传输,那么任何细微的音频和视频同步偏差对用户来说都不会很明显。这种选择能够创建两个独立的状态机,一个专门用于音频,另一个专门用于视频。这大大简化了设计,并最大限度地降低了通信协议中握手过程的复杂性。
选择使用GPIO端口是因为它们简单易用。可以使用跳线连接FPGA。这种方法确实存在一些局限性,最明显的是长度限制。两个板子需要相对靠近,这在原则上违背了虚拟通信的初衷。不过,项目的重点在于协议设计,该协议可以轻松转换为支持通过不同介质进行数据传输。GPIO方法的另一个主要局限性是不可忽略的时钟偏移和信号失真,尤其是在高频情况下。由于电路板在高速读写引脚方面的限制,许多初步方案都被证明是无效的。最终,这些挑战促使我们设计出一个能够克服硬件限制的系统。
程序/硬件设计
视频
NTSC 摄像机直接连接到 FPGA,可以通过硬件协议系统 (HPS) 与其通信。为了在 VGA 显示器上显示摄像机输入,使用外部总线到 Avalon 桥接接口来实现 FPGA 和显示器之间的通信。从 NTSC 摄像机读取数据时,默认分辨率为 320 x 240,这与 VGA 显示器的 640 x 480 分辨率不同。没有直接将 NTSC 摄像机的输入映射到 VGA 显示器并逐像素写入,而是将一个像素映射到四个像素,以充分利用整个显示屏。如果没有这种方法,视频只能占据显示屏的四分之一。使用这种映射方案增加视频尺寸并不会提高分辨率,但认为它可以改善用户体验。理论上,视频播放过程是先读取后写入,但实际上,为了生成缩放后的图像,每次读取后都会进行四次连续写入,每次写入对应一个像素。
图 1:从相机读取到 VGA 像素的映射
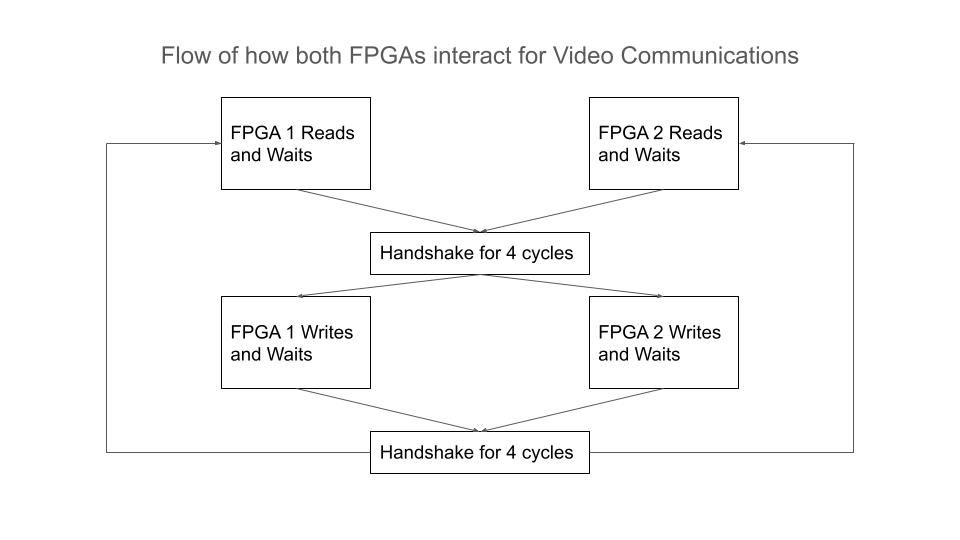
图 2:FPGA 之间的视频通信流程
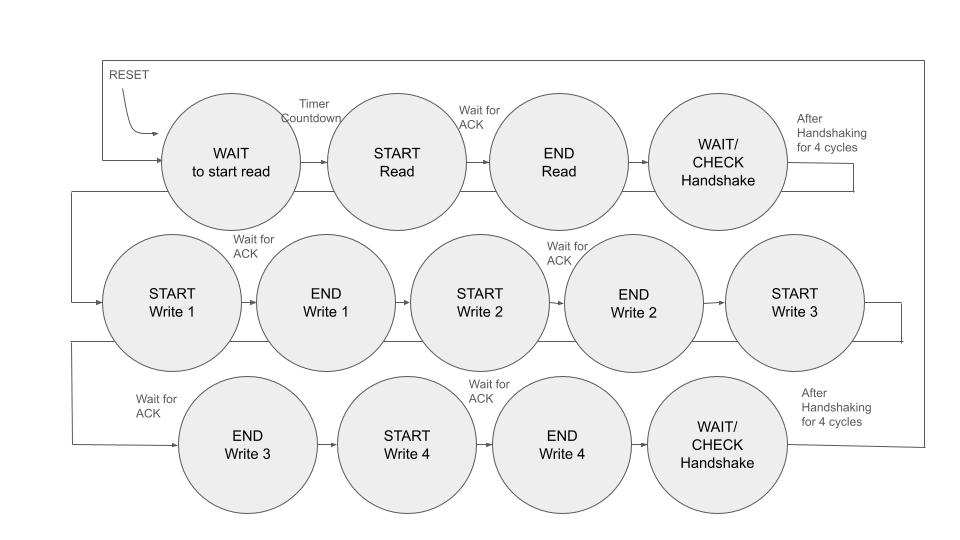
图 3:FPGA 上的视频状态机
两个FPGA都采用上述相同的读写方案。为了使它们能够相互通信,在其中一个状态机中添加了两个握手状态,以确保它们在读取完成后,只有在确认读取已完成三个时钟周期后才会进入写入阶段。为写入操作实现了类似的逻辑,即两个FPGA只有在确认写入完成后才会读取新值。一旦达成一致(通过监控板间交换的标志位),负责跟踪握手的状态机就会进入下一步,并与另一个FPGA通信以执行相同的操作。这种握手方案的主要动机是视频状态机的完成时间并不稳定。实现了一个定时器来防止总线占用,这最终导致完成时间存在32个时钟周期的波动。理论上,如果我们能够合理地假设完成所需的时钟周期数相同,并且板上的时钟频率相同,那么两个状态机默认情况下将在某种程度上保持同步。因为情况并非如此,所以我们依靠握手来实现同步。
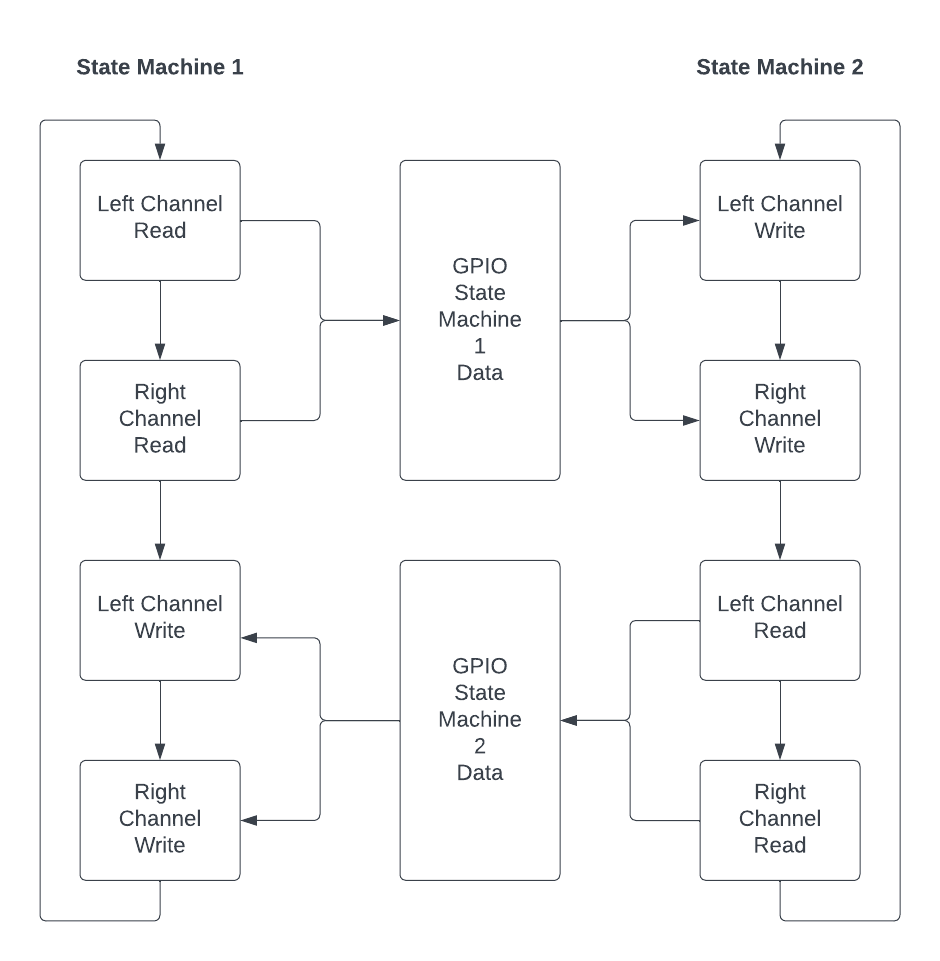
图 4:FPGA 之间的音频通信流程
由于音频能够容忍一些不一致性,因此其实现比视频要简单得多。音频状态机是课程网站“数字信号处理”页面上的音频环回配置的修改版本。音频通信协议不使用任何握手机制,因为通过实验发现它完全没有必要。它首先从麦克风输入端口读取数据,然后写入线路输出端口。由于它也使用 EBAB 总线主控器,因此其读写机制与上面解释的视频机制非常相似。audio_bus_addr 被设置为读取 FIFO 地址,audio_bus_read 被设置为高电平。然后它会返回一个确认信息,并在下一个时钟周期将数据放在 audio_bus_read_data 上。所需的数据被放入 audio_bus_write_data,audio_bus_write 被设置为足够高以写入线路输出端口。然后它会等待写入成功的确认信息,然后再开始新的读取操作。数据交换非常简单直接。读取完成后,数据会被放置在一组 GPIO 引脚上,供另一个 FPGA 使用。写入时,写入数据会从另一组 GPIO 引脚上读取,而另一个 FPGA 则将读取的数据放置在这组引脚上。需要注意的是,这里会执行两次读取和两次写入操作,分别对应左声道和右声道。由于两个状态机无需同步运行,因此无需进行额外的协调。即使出现数据丢失(即 GPIO 引脚上的可用数据在写入之前发生变化),或者出现重复写入(即由于数据变化不够快,导致某个值被写入两次),也不会对音频清晰度造成显著影响。在项目演示中,可以明显听到明显的失真,但这只是因为我们将音频从 32 位压缩到 6 位,以便为视频通信腾出足够的 GPIO 引脚。我们通过保留最高 6 位,然后在接收到该值后将其连接 24 位 0 来实现这一点,这样它就可以保持其 32 位状态。
以下是一些调试图片


结论
总之,实现了两个FPGA板之间的双向视频和音频通信。使用GPIO接口在板间距离、速度和数据完整性方面存在明显的局限性。然而,通过开发一种有效管理后两项的协议,构建了一个稳健的框架,可以轻松扩展以支持其他通信方式。未来,可以添加静音按钮和摄像头关闭等功能。此外,为了扩展功能和实用性,可以放弃GPIO接口,转而支持无线网络通信,从而无需将两个板连接在一起。
代码链接
https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/f2024/nsk62_srg293/5970_final_nsk62_srg293.html
视频链接
https://youtu.be/vh8FgNfBv20?si=lTzK2nUxPOMlxzPY
DE1-SoC上的FM解调
项目介绍
使用 RTL-SDR 模块和 Raspberry Pi 在 DE1-SoC 开发板上搭建了一个系统,用于解调实时 FM(调频)广播信号,从而实现实时信号处理,输出清晰、即时的音频。将 RTL-SDR 用作接收器,并将其连接到 Raspberry Pi 以提取 I 和 Q 值。这些值通过 TCP Socket传输到 DE1-SoC 的硬处理器系统 (HPS)。HPS 接收到 I 和 Q 值后,对其进行解调、滤波,然后发送到数模转换器 (DAC),用于播放 WVBR 的音频。
顶层设计
原理和来源
由于这门课的重点是使用FPGA(现场可编程门阵列)进行硬件加速,预期FPGA在处理复杂的实时计算方面会表现出色。也知道无线电接收和解调信号是实时进行的,所以认为FPGA非常适合探索用于调频解调的数字信号处理。最初的目标是在FPGA上实现一个完整的软件定义无线电(SDR)系统。然而,考虑到最终项目是独立完成的,而且时间有限,决定缩小范围,专注于在HPS上进行解调,因为这对我来说是一个全新的领域。
背景数学
IQ调节
在软件定义无线电 (SDR) 中,IQ 调制用于将射频信号表示为两个正交分量:I(同相)和 Q(正交)。I 分量对应于信号的实部,与余弦波对齐;而 Q 分量对应于虚部,与正弦波对齐(相位差为 90°)。复信号 I+jQ 共同完整地表示了信号的幅度和相位。这种正交分解使得对复杂的调制信号进行编码和处理成为可能。
在调频信号的背景下,发射信号可以表示为:
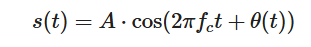
这里:
- fc是载波频率,
- θ(t)是编码调制信号的瞬时相位。
该信号的 IQ 表示为:
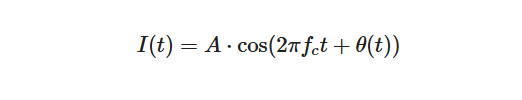
和
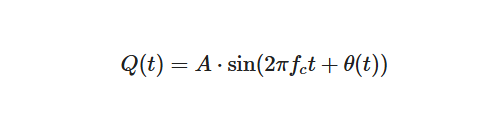
IQ解调
IQ解调通过将调制后的射频信号与两个本振信号混频来提取原始基带信息:一个余弦波用于I分量,一个正弦波用于Q分量。这些操作将信号移至基带,同时保持其幅度和相位不变。余弦波和正弦波的正交性确保I分量和Q分量之间互不干扰,从而能够精确地重构发射信号。通过分析得到的IQ分量,可以提取幅度和相位信息以供后续处理。
利用IQ值进行FM解调
利用IQ值进行FM解调依赖于检测信号瞬时相位的变化。由于FM信号的信息编码在相位变化而非幅度变化中,因此相位角至关重要。
θ可计算如下:
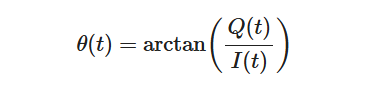
为了提取频率调制,我们对相位求时间导数。瞬时频率 f(t)由导数θ(t)给出:
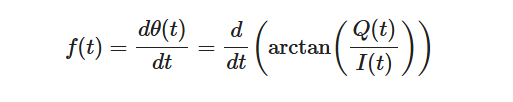
该导数给出了相位变化率,它与信号的瞬时频率偏移成正比。瞬时频率偏移对应于原始调制信号。这种调频解调技术也称为相位鉴别。
导数近似
在代码中,首先对连续的 I/Q 值求出近似导数,然后对该近似导数的实部和虚部取反正切值,从而得到相位导数。虽然这种方法精度较低,但它简化了 C 代码。
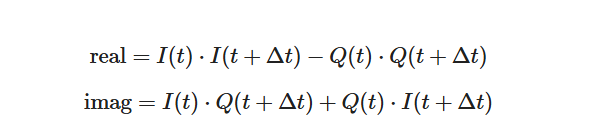
这两个表达式近似表示导数的实部和虚部,分别反映了从一个时间样本到下一个时间样本的同相分量和正交分量的变化。
接下来,对虚部和实部取反正切值,以计算相位角的导数:
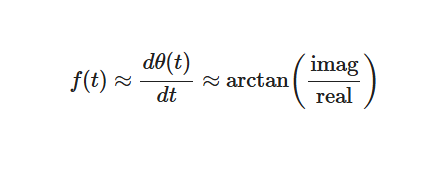
硬件/软件权衡
由于时间紧迫,且当时独自一人工作,因此决定在HPS上使用C语言实现FM解调。虽然C语言编程更简单,但在FPGA上的速度却比Verilog慢。不过,音频播放正常,因此对于本项目而言,这种在简易性和性能之间的权衡是可以接受的。接下来,计划继续推进项目,直接用Verilog实现解调计算。这将充分利用FPGA的并行处理能力,提高速度和效率,并实现FM信号的实时处理。通过将计算转移到FPGA,目标是优化系统整体性能,并降低HPS的计算负载。
硬件和软件设计
硬件详情
RTL-SDR模块通过USB接口连接到树莓派4B。树莓派4B连接到以太网交换机,DE1-SoC也连接到同一交换机,并通过TCP协议进行通信。
结果&结论
该项目基于 RTL-SDR、树莓派和 FPGA SoC 搭建了一套实时 FM 收音机系统,成功实现了 FM 广播信号的接收、解调和音频播放。通过实际测试,作者能够稳定收听 WVBR-FM 电台,并发现天线方向、周围环境和障碍物对接收质量有显著影响,良好的天线布置能够明显降低噪声并提升音频效果。
虽然系统已经实现了基本功能,但目前 FM 解调主要依赖软件处理,用户操作流程也较为繁琐。未来计划将 FM 解调算法迁移到 FPGA 中实现硬件加速,并增加频率调谐、增益控制等用户界面功能,进一步提升系统性能和易用性。
代码
项目地址:
https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/f2024/ayl48/ayl48/ayl48.html
C 代码
https://drive.google.com/file/d/16tS8VLRiU2I3SbHiRvO6ks_cF3TW2tAP/view?usp=drive_link
Qsys 布局
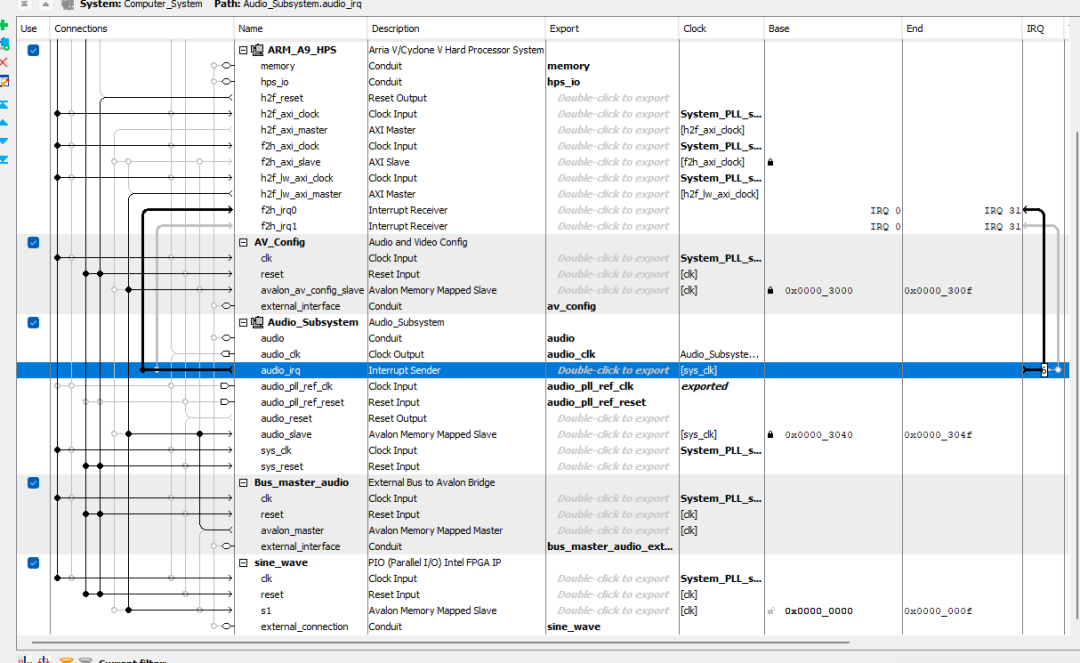
实时套利交易系统
套利是一种交易算法,交易者通过监控不同市场中某资产(通常是股票)的价格,来寻找其价格的最低点和最高点。然后,他们以低价买入股票,以高价卖出。但由于市场价格波动迅速,速度对于盈利至关重要。本文尝试利用现场可编程门阵列(FPGA)的速度和并行处理能力来构建一个套利交易系统。该系统使用的FPGA是Altera/Intel的DE1 SoC。
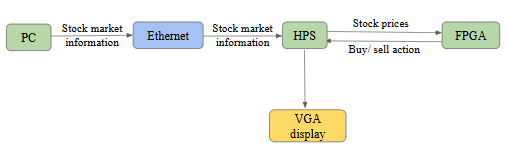
图1. 项目结构流程图
以太网
DE1 SoC 支持 100Mbps 的以太网。以太网用于以如下格式向 DE1-SoC 板的 HPS 发送数据包:
"<股票名称>, <ASE交易所价格>,<BSE交易所价格>,<CSE交易所价格>"
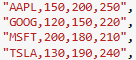
图2. 通过以太网发送的数据包
HPS
DE1-SoC 上的硬处理器系统 (HPS) 负责管理以太网通信和可视化。它建立网络连接以接收实时股票市场数据,解析传入的数据包以提取股票价格。然后,这些数据被传输到 FPGA 进行处理。
HPS采用循环缓冲区结构进行动态数据管理,确保高效的库存信息存储和检索。它维持着持续的数据流,并动态更新缓冲区,仅保留最新的相关信息。
此外,HPS 还配置和控制 VGA 显示接口,设置必要的帧缓冲区内存。它将缩放因子和图形布局等默认可视化参数发送到 FPGA 进行实时渲染。
FPGA
FPGA负责套利交易系统的主要计算工作。交易逻辑采用Verilog语言实现,旨在比较三个不同市场的股票价格,并确定最佳买卖策略以把握套利机会。该逻辑实时处理数据输入,充分利用FPGA的并行运算能力,最大限度地降低延迟。
它从三个市场(市场 A、市场 B 和市场 C)获取股票价格输入,并对其进行处理以识别套利机会。对于每只股票,FPGA 会比较各市场的价格,并针对每个市场输出买入、卖出或持有的操作。例如,如果市场 A 的股票价格最低,而市场 C 的价格最高,则 FPGA 会将市场 A 的相应输出设置为“买入”,将市场 C 的相应输出设置为“卖出”。这些决策在一个时钟周期内完成,确保了金融应用所需的响应速度。
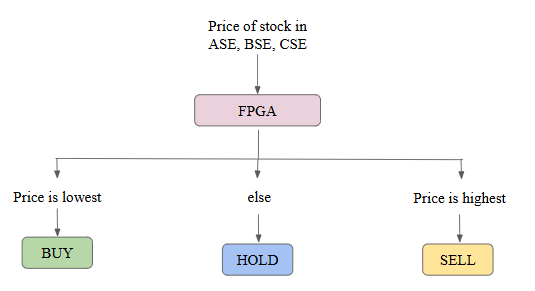
图 3. 基于 FPGA 的套利交易算法
该设计通过使用数组来存储和更新每只股票的最新操作,从而实现了对多只股票的处理。这使得系统能够同时管理多只股票的交易,凸显了FPGA在处理并行进程方面的固有优势。
FPGA 的输出信号被传回 HPS,HPS 随后汇总结果并在 VGA 显示器上可视化显示。FPGA 和 HPS 之间的紧密集成确保了无缝的数据流和交易算法的实时执行。
VGA显示器
使用640x480视频图形阵列(VGA)显示器实时可视化结果。绘制了一张折线图,显示交易公司每次购买后资产的变化以及每个证券交易所的价格波动。
HPS 发送显示器的配置详情,例如分辨率、不同股票或趋势的颜色编码和布局参数,而 FPGA 则处理这些视觉效果的渲染。
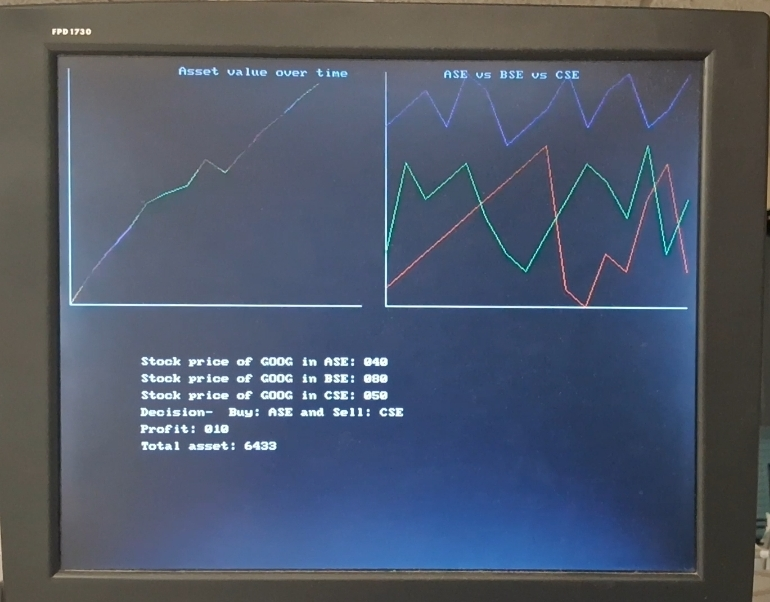
图 4. VGA 输出
(在右侧的图中,红线对应 ASE,绿线对应 BSE,蓝线对应 CSE)
测试
单元测试
在将系统集成到套利交易系统之前,系统的各个单元都经过了单独测试。
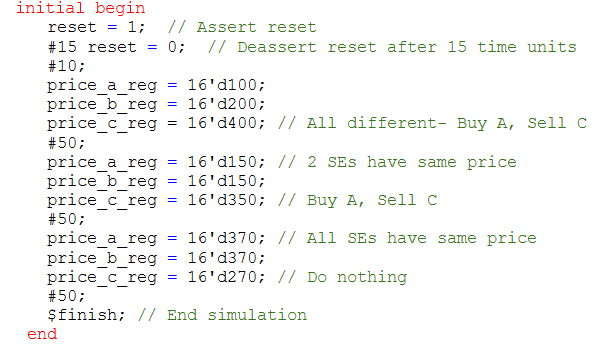
a)交易算法
该交易算法在 Modelsim 上进行了边缘情况测试,以确定它是否能够正确识别最低价和最高价,从而确定交易。
测试输入:
测试结果:
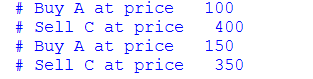
集成测试
以下交易已录入系统:

预期输出:
资产 = 1750 (期初余额 = 100)
实际产量:1750
结论与未来展望
总之,本项目成功展示了利用FPGA的速度和并行处理能力实现实时套利交易系统。通过使用Altera/Intel的DE1-SoC,设计了一个能够高效监控多个市场股票价格并基于套利机会做出实时交易决策的系统。然而,该系统仍有改进空间。
- 可以对交易算法进行改进 ,使其融入更复杂的策略,例如预测分析和机器学习模型,从而做出更好的决策。
- 以太网连接 可以直接在 FPGA 上实现,以进一步降低延迟并支持高频交易。
- 该系统需要在真实/实时的股票市场中进行实施 ,以评估其实际运行情况。
参考代码及项目地址
https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/f2024/vp278/vp278/5790_final_report_Vidhula.html
视频链接
https://youtu.be/G_bnTPfqCzA?si=h_UXJIBOGDkJlDvD
2024年春季 开发板:CycloneV DE1-SoC
基于FPGA的多核Rivest-Cipher-4
介绍
随着数字技术的飞速发展,网络安全变得日益重要。Rivest Cipher 4(RC4)作为一种流密码,在20世纪90年代声名鹊起。
本项目旨在通过设计并实现一个基于模块化有限状态机(FSM)的加密解密电路,来探索RC4的重要性。本项目深入研究了数字系统设计,并探讨了RC4在互联网通信加密中的作用。该算法在DE1-SoC FPGA开发板上实现。用户界面包括用于设置密钥的滑动开关、用于解密监控的十六进制显示屏以及用于指示密钥状态的LED指示灯。在功能方面,该系统基于密钥初始化并打乱S数组,使用RC4执行加密和解密操作,并包含一个暴力破解机制来演示算法的漏洞,从而凸显了开发稳健加密方法的必要性。
顶层设计
- 原则
RC4 算法因其动态性和实时性而具有显著优势,能够确保通信双方之间加密和解密的一致性。其简洁性和快速的计算速度使其成为 HTTPS/SSL 等协议中加密的首选算法。然而,近期披露的信息表明该算法存在潜在的安全风险。在传统的实现中,RC4 通常使用 256 字节的密钥长度。RC4 算法生成一个字节数组(S 数组),其中每个字节都与消息字节进行异或运算以解码消息。用户输入一个密钥,该密钥会影响算法生成的 S 数组的状态。
以下是RC4算法实现的基本步骤。
初始化 S 阵列:
- 1.初始化 S 数组,将 0 到 255 的数字填充到地址 0 到 255。
- 2.使用用户输入的密钥打乱 S 数组的顺序。
加密/解密;
- 1.对于每个需要加密/解密的数据段:
-取键的第一个字节作为索引,并从键中检索相应的字节值。
-将此字节保留为 N,并在密钥中交换这两个字节。
- 2.计算这两个字节的总和。
- 3.从数据中检索一个字节进行加密/解密。
- 4.对步骤 2 和 3 中获得的两个字节进行异或运算,以实现加密/解密。
- 5.取密钥的第二个字节,将其加到字节 N 上作为索引。
- 6.重复上述步骤,直到遍历完所有元素。
- 算法
以下步骤是 C 语言中的算法实现 [1]。
- 初始化
通过向地址 0 到 255 写入 0 到 255 来初始化 S 数组。
for(int i = 0; i <= 255; i++){
s_array[i] = i;
}
- 洗牌
根据用户输入的密钥对 S 数组进行重新排列。
int j = 0;
int i;
int temp_1;
for(i = 0; i <= 255; i++){
j = (j + s_array[i] + secret_key[i % 3]) % 256;
//swap s_array[i] with s_array[j]
temp_1 = s_array[i];
s_array[i] = s_array[j];
s_array[j] = temp_1;
}
在本次设计中,密钥长度为 24 位。将其分成 3 段,每段 8 位。例如,如果密钥为 24'b10101010_11111111_00000000,则 secret_key[0] 为 8'b00000000,secret_key[1] 为 8'b11111111,secret_key[2] 为 8'b10101010。此外,在我们的 HDL 设计中,变量j 的长度为 8 位,因此可以忽略% 256 ,因为当j达到 255 时,它会自动溢出,这与% 256 的效果相同。
- 加密与解密
由于 RC4 是一种对称算法,这意味着如果我们将该算法应用于一条消息,它将对其进行加密;如果我们将相同的算法应用于一条已加密的消息,它将对其进行解密。因此,加密和解密都使用完全相同的算法。该算法如下:
int i = 0;
int j = 0;
int k;
int temp_2;
int sum;
int factor;
//loop ends until reaching the message length
//In our design each message is 32 bytes long
for(k = 0; k <= 31; k++){
i = (i + 1) % 256;
j = (j + secret_key[i]) % 256
//swap s_array[i] with s_array[j]
temp_2 = s_array[i];
s_array[i] = s_array[j];
s_array[j] = temp_2;
//get the XOR factor
sum = s_array[i] + s_array[j];
factor = secret_key[sum % 256];
//write to the output using 8 bit-wise XOR
RAM[k] = factor ^ ROM[k];
}
RAM 是存储处理结果信息的内存,而 ROM 则包含待加密或待解密的信息。
结构
下图展示了该项目的硬件结构。
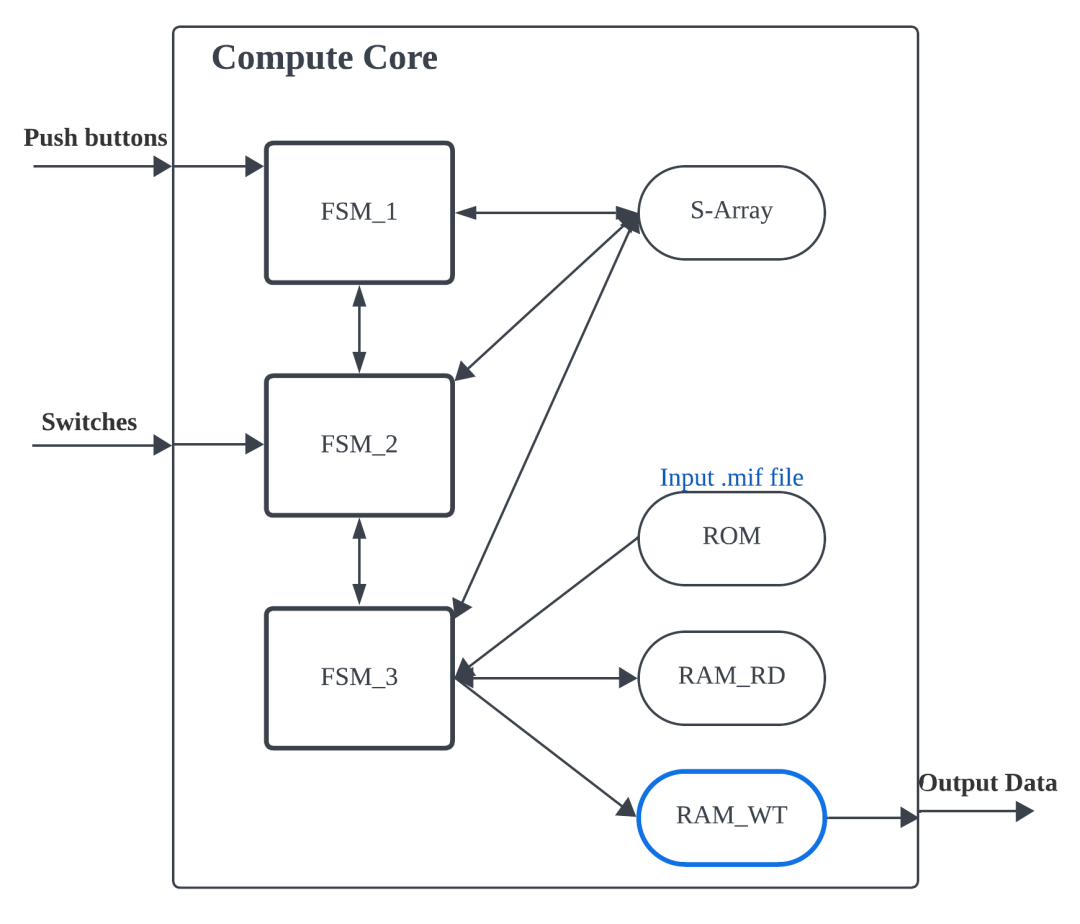
图 1.单个核心的结构。
如图 1 所示,FSM_1 负责初始化,FSM_2 负责数据打乱,FSM_3 能够逐字符地加密或解密消息。计算核心从 DE1-SoC 上的开关和按钮状态获取输入,并输出成功解密的消息。每个计算核心配备三个有限状态机 (FSM) 和四个存储器。S 数组是一个 8x256 的存储器,这意味着它包含 256 个元素,每个元素为 8 位。RAM 和 ROM 均为 8x32,这意味着它们各自包含 32 个 8 位元素。S 数组的 RAM 用于存储 S 数组数据,而 ROM 用于存储用户待加密和待解密的消息。RAM_RD 存储加密后的消息,RAM_WT 存储解密后的消息。此外,FSM_1 还负责初始化 S 数组。 FSM_1 执行完毕后,FSM_2 根据开关(即用户输入的密钥)对 S 数组进行打乱。打乱后,按下 KEY_1 会触发 FSM_3 从 ROM 中读取数据并应用加密算法。随后,它将加密后的数据写入 RAM_RD 存储器。之后,按下 KEY_0 会启动 FSM_1、FSM_2 和 FSM_3,重复上述步骤解密消息。不同之处在于,FSM_2 从 RAM_RD(加密消息)而不是 ROM 中读取数据。然后,它将解密后的消息写入 RAM_WT 存储器并将其输出到顶层模块。此外,DE1-SoC 上的十六进制显示屏会以时钟周期数显示操作时间。
此外,该设计还具备暴力破解密码的能力。密钥由 24 位组成。由于 DE1-SoC 上开关的限制,SW9 代表密钥的第 24 位,而 SW8 到 SW0 连接到 secret_key[8:0]。所有其他位均硬连线为 0。当用户按下 KEY_2 时,该设计启动对密钥的暴力破解。破解密钥的步骤与之前所述相同。有限状态机不再使用开关作为密钥;而是遍历从 24'b00..00 到 24'b11..11 的密钥,并对每个密钥应用算法,直到找到正确的密钥。由于消息使用 ASCII 码编码,该设计会逐个检查解密后的数据。如果数据落在 ASCII 码的字母或数字范围内,则标记为正确。当内存中的所有 32 个数据项都被标记为正确时,当前密钥就被认为是正确的密钥。
顶级模块
暴力破解过程会遍历从 24'b00...00 到 24'b11...11 的所有 16,777,216 个密钥。此过程大约需要 5 小时才能完成。因此,我们实现了16 个计算核心,以便在破解过程中并行遍历密钥。顶层结构如下:
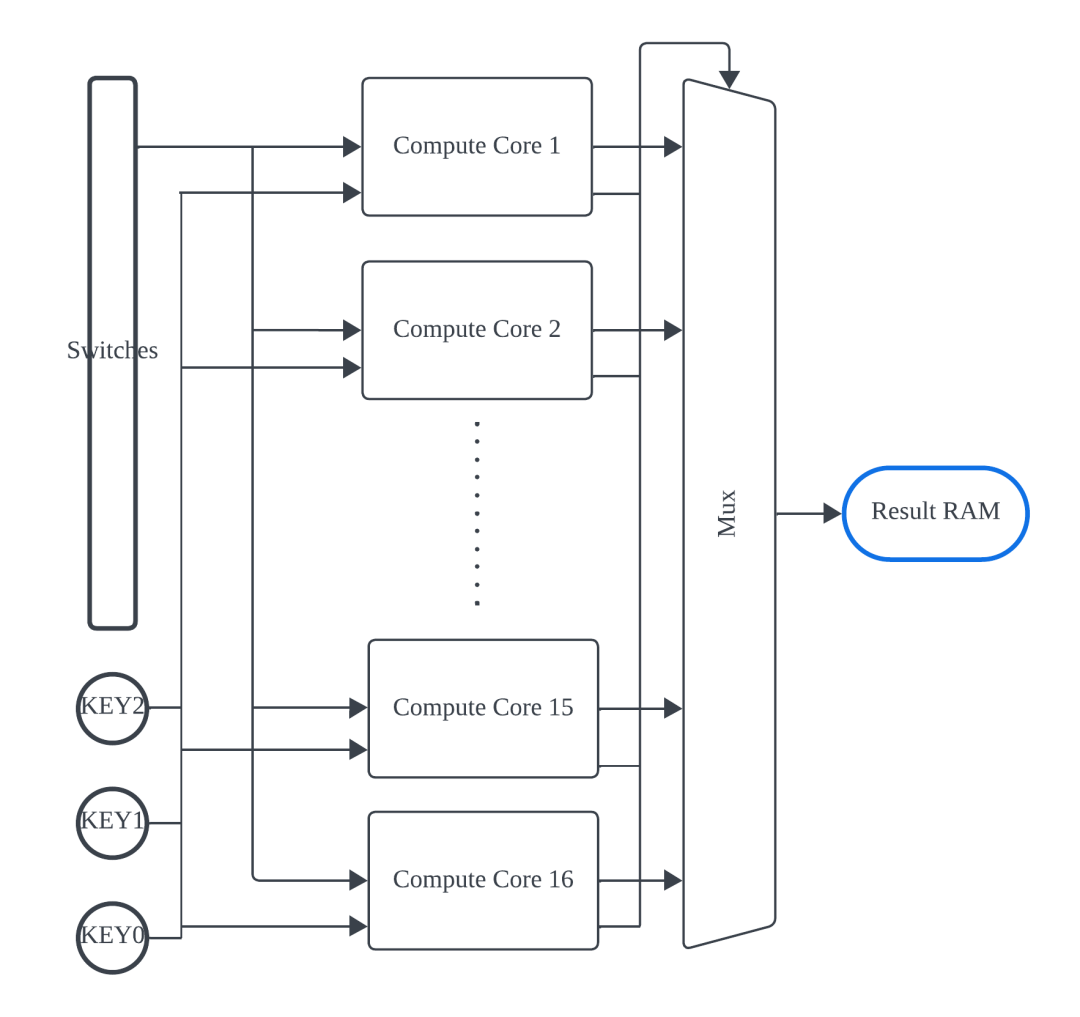
图 2.顶层设计结构。
如图 2 所示,每个计算核心接收来自开关和按钮的输入,并将算法应用于各自核心内的存储器。这种多核设计的原理是将密钥范围(从 24'b00..00 到 24'b11..11)划分为 16 个段。每个核心计算特定范围内的密钥。由于并行计算,这种设计显著缩短了计算时间。理想情况下,这种多核设计在时钟周期方面可以实现 16 倍的加速。实际加速情况将在结果部分讨论。16 个核心同时 处理不同的密钥,并同时输出 16 条解密后的消息。然而,只有一个核心能够识别出正确的密钥。当一个核心标记出 32 个正确的数据条目时,它会输出一个正确的信号,该信号作为多路复用器中的选择信号。然后,来自正确核心的消息被写入结果 RAM。
硬件设计
有限状态机
本项目的核心在于三个有限状态机(FSM)及其接口。这些设计在ModelSim中进行仿真,并在Quartus 18.1中进行综合。下图流程图展示了每个FSM的基本原理。
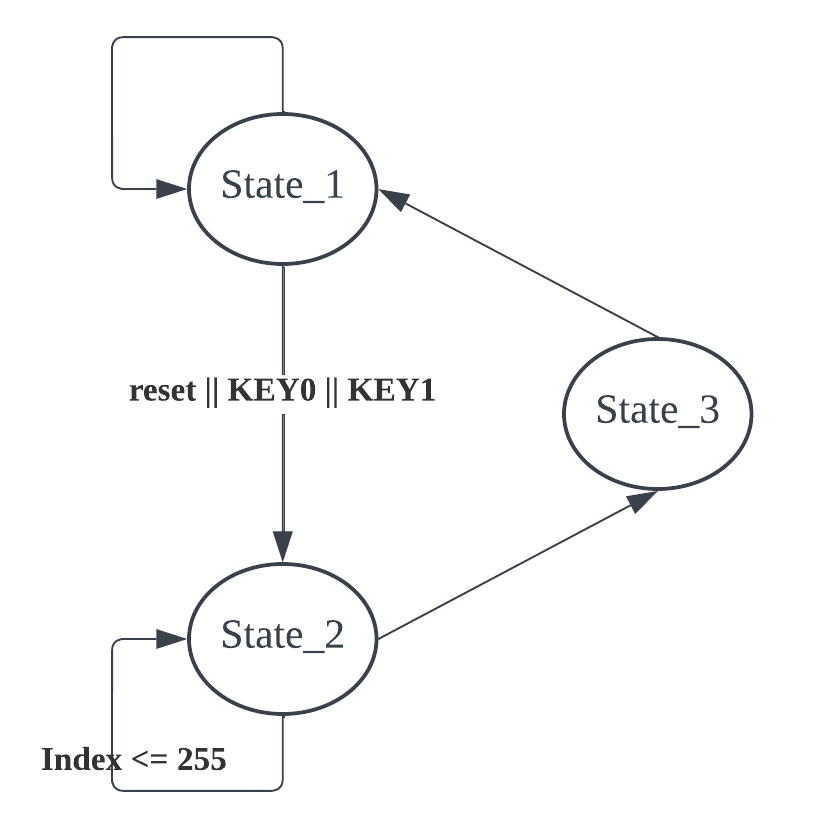
图 3.第一个有限状态机的流程图。
该有限状态机实现了算法的初始化部分。各状态的目的和功能如下所示:
表 1.第 1 个有限状态机的状态函数。

当第一个有限状态机(FSM)完成操作后,它会向第二个FSM发送完成信号。随后,第二个FSM会根据用户输入的密钥启动S数组的打乱过程。由于该FSM代表了算法的硬件实现,因此其状态(校验状态除外)会随着时钟的变化而依次变化。下图和表格说明了第二个FSM的工作原理。
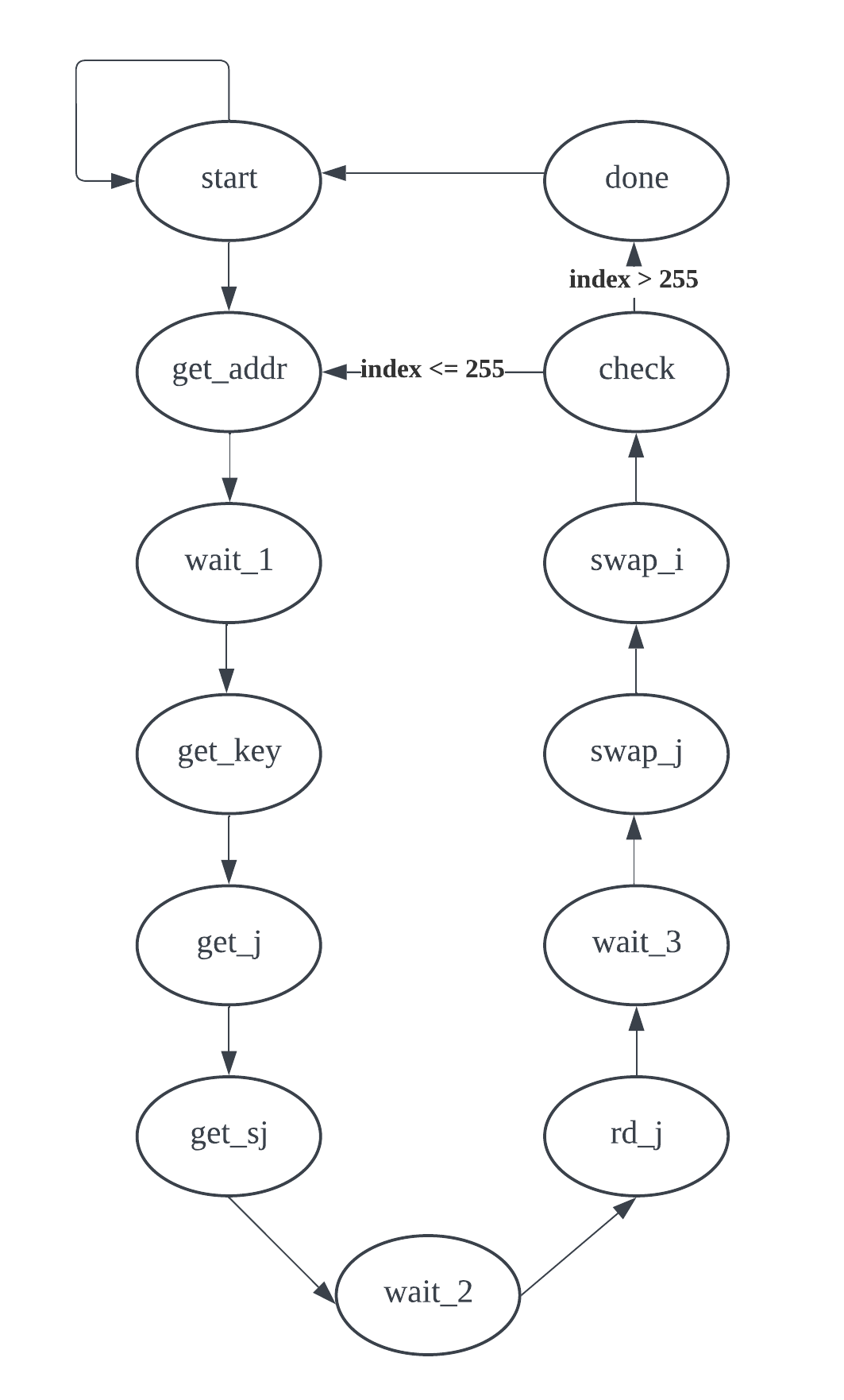
图 4.第二个 FSM 的流程图。表 2.第二有限状态机的状态函数。
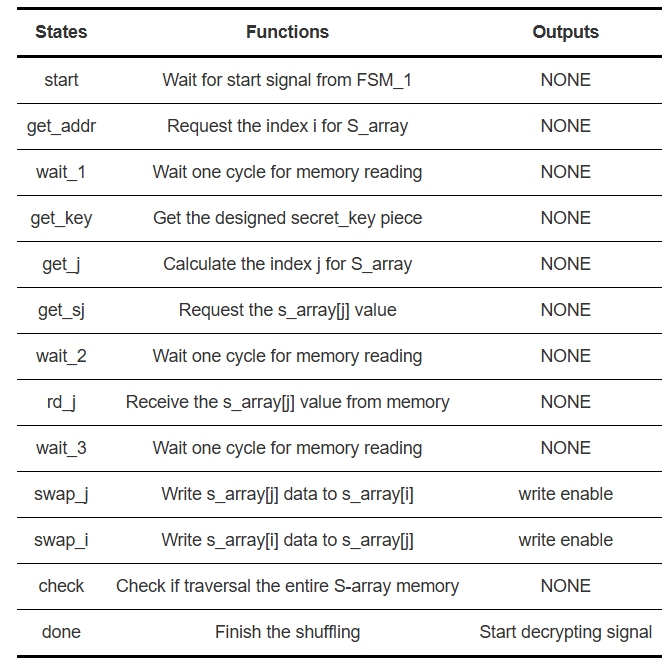
如图 4 和表 2 所示,FSM_2 作为算法中混洗的硬件实现。它按顺序执行各个状态,根据用户输入的密钥对 S 数组中的元素进行混洗。在检查状态,FSM 会验证是否已遍历 S 数组中的所有元素。如果没有,则将索引“i”加 1,并返回到 get_addr状态,重复此过程,直到索引“i”达到 255。到达完成 状态后,FSM 发出start_decryption信号,触发第三个 FSM。
下图和表格表示了第三个有限状态机的原理,该状态机实现了算法的加密或解密部分。
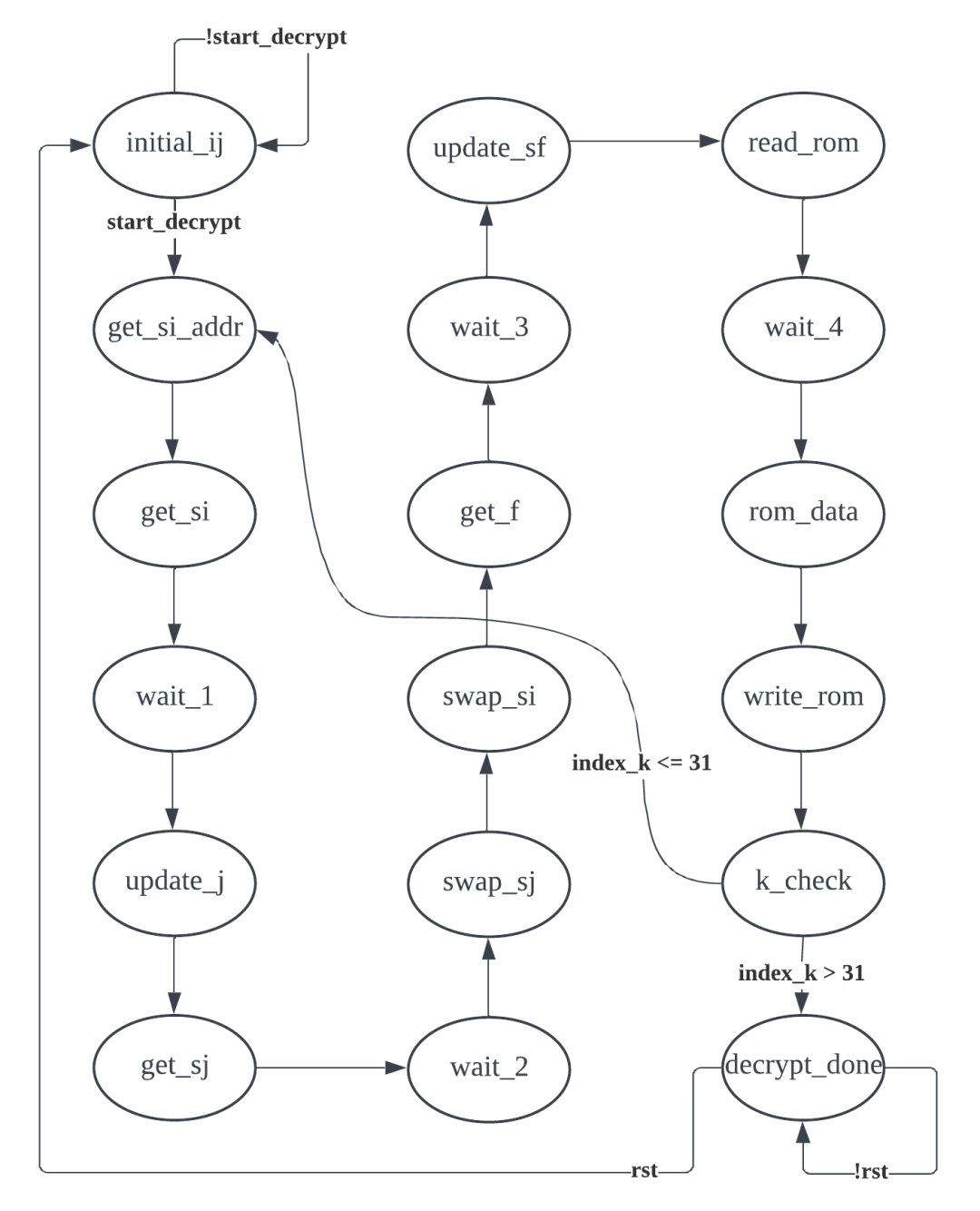
图 5.第 3 个有限状态机的流程图。
与 FSM_2 相同,FSM_3 也是一个顺序执行的状态机,因为它实现了算法的加密/解密部分(如前所述,该过程完全相同)。在图 5 中,FSM_3 初始处于initial_ij状态,将索引 i 和 j 初始化为 0,并等待来自 FSM_2 的触发信号。接收到触发信号后,它依次执行以下状态:通过将索引 i 加 1 来计算索引 i,并通过加上密钥片段来计算索引 j。然后,它执行交换状态,交换 s_array[i] 和 s_array[j] 的值。交换后,FSM 将它们相加,并利用该结果获得所需的密钥片段(24 位密钥中的 8 位)。该结果称为因子。然后,将因子与 ROM 中的消息进行异或运算,以加密/解密消息。最后,将结果写入结果 RAM。
暴力破解和多核
设计还包含暴力破解功能。首先,用户手动将可读的 .mif 文件输入到 ROM 中。然后,用户通过开关设置密钥,并按下 KEY1 进行加密。通常情况下,用户可以使用相同的密钥通过按下 KEY0 解密加密后的信息。但是,如果用户忘记了密钥,则可以按下 KEY3 进行暴力破解。其原理是,上述 FSM 将执行相同的步骤。区别在于破解模式,破解模式下 FSM 不将开关作为用户输入的密钥。相反,它们会遍历密钥,从 24'b00..00 到 24'b11..11。因此,当按下 KEY3 时,电路会产生一个破解信号,该信号也会重置第一个 FSM 以重新执行破解过程。此外,当第三个有限状态机处于write_ram状态时,它会检查解密后的消息是否正确,方法是验证解密后的数据是否在 ASCII 范围内。如果所有 32 个解密后的数据都在 ASCII 范围内,则当前密钥正确,我们就能得到正确的消息。
此外,从 24'b00..00 遍历到 24'b11..11 会生成 16,777,216 个密钥,这个过程大约需要 5 个小时。因此,我们采用了 16 个核心,每个核心负责处理密钥的特定范围,因为密钥范围被平均分成了 16 段。来自正确核心的消息将被写入结果 RAM。这显著缩短了操作时间,减少了 16 倍。
结论
总之,本项目中使用的RC4软件算法来源于开源资源。探讨了RC4在网络安全领域的重要性,尤其是在数字技术快速发展的今天。通过在DE1-SoC FPGA板上采用模块化有限状态机(FSM)方法实现加密解密电路,深入研究了RC4在通信加密中的作用。设计中使用的存储器是来自Altera IP目录的IP核。利用滑动开关控制密钥、LED指示密钥状态等功能,系统展示了无缝的加密解密过程,并通过暴力破解机制突显了算法的漏洞。值得注意的是,多核设计在最坏情况下实现了惊人的16倍加速,凸显了方法的效率和有效性。这些发现表明,在不断发展的数字环境中,需要持续创新加密方法以加强数据保护。
参考
[1] 知乎。“计算机网络学习笔记”[在线]。网址:https://zhuanlan.zhihu.com/p/537881813
[2] 贸泽电子。“DE1-SoC 用户手册”[在线]。网址:https://www.mouser.com/datasheet/2/598/DE1-SoC_User_manual_v06-1214842.pdf
[3] Joe Skovira 教授提供的 html 模板。
演示视频
https://www.youtube.com/watch?v=PnWV4ZPzV5U&list=PLDqMkB5cbBA7nUwrxsLgtrOsce9UgJXJb&index=3
代码及项目链接
https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/s2024/rz443_hw768_bt362/rz443_hw768_bt362/ece5760_final.html
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号