用find_peaks求局部最大值
用find_peaks求局部最大值
提问于 2021-12-06 12:19:33
我使用scipy.signal.find_peaks来尝试为非常波动的数据找到最大值。使用以下数据文件:
import pandas as pd
import numpy as np
from scipy.signal import find_peaks
Data = [95,95,95,95,95,95,95,95,94,94,94,94,94,94,94,94,229,444,457,387,280,188,236,181,183,183,185,186,189,190,190,190,179,165,151,151,161,214,213,213,214,213,212,195,179,160,158,155,114,98,164,346,229,39,134,149,194,1,153,171,187,185,104,102,100,90,90,92,92,92,93,93,93,93,93,93,94,94,94,94,94,11,1,11,11,70,182,104,58,60,134,115,99,97,99,98,98,97,97,97,97,97,97,97,97,97,96,96,96,96,96,96,96,96,96,96,96,96,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,94,94,94,94,94,94,94,94,94,94,94,94,94,94,94,93,93,152,206,221,286,326,341,360,377,391,392,393,393,393,394,406,418,420,422,422,408,389,345,329,276,224,166,113,-6,91,91,91,442,324,387,389,387,443,393,393,393,393,391,381,379,377,303,174,131,0,115,112,112,111,111,109,107,106,104,104,103,102,101,101,101,101,100,100,1,1,12,13,65,138,87]
df2 = pd.DataFrame(Data)
#convert to 1D array
number_column = df.loc[:,'Data']
numbers = number_column.values
#finding peaks for 1D array
peaks = find_peaks(numbers, height = 300, threshold = 1, distance = 5)
height = peaks[1]['peak_heights'] #list of heights of peaks
peak_pos = numbers[peaks[0]]
print(peaks)
#plot the peaks
fig = plt.figure()
ax = fig.subplots()
ax.plot(numbers)
ax.scatter(peak_pos, height,color = 'r', s = 25, label = 'Maxima')
ax.legend我得到了457,346,442,443的局部极值。然而,在这个系统中,我需要得到以下极值值:(457,346,422,443)
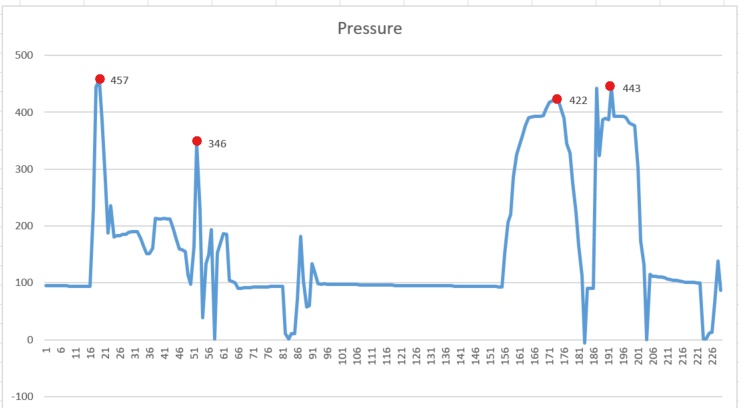
在谋划我的极端时,我要说的是:
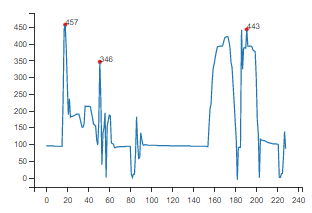
所以,我的问题是,有谁知道如何得到正确的极端,我需要?我只是错过了422的价值,一直在玩设置,但没有成功。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-12-06 12:42:53
您应该将peak_pos = numbers[peaks]行更改为peak_pos = peaks[0],因为峰值给出了峰值的索引,这是要传递给ax.scatter的实际x坐标。
要使峰值达到422,我们可以将阈值设置为None (这样您就不会限制自己与邻居的垂直距离),并使距离更大,例如10。
然后可以将高度添加为文本注释:
import pandas as pd
import numpy as np
from scipy.signal import find_peaks
import matplotlib.pyplot as plt
Data = [95,95,95,95,95,95,95,95,94,94,94,94,94,94,94,94,229,444,457,387,280,188,236,181,183,183,185,186,189,190,190,190,179,165,151,151,161,214,213,213,214,213,212,195,179,160,158,155,114,98,164,346,229,39,134,149,194,1,153,171,187,185,104,102,100,90,90,92,92,92,93,93,93,93,93,93,94,94,94,94,94,11,1,11,11,70,182,104,58,60,134,115,99,97,99,98,98,97,97,97,97,97,97,97,97,97,96,96,96,96,96,96,96,96,96,96,96,96,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,95,94,94,94,94,94,94,94,94,94,94,94,94,94,94,94,93,93,152,206,221,286,326,341,360,377,391,392,393,393,393,394,406,418,420,422,422,408,389,345,329,276,224,166,113,-6,91,91,91,442,324,387,389,387,443,393,393,393,393,391,381,379,377,303,174,131,0,115,112,112,111,111,109,107,106,104,104,103,102,101,101,101,101,100,100,1,1,12,13,65,138,87]
df = pd.DataFrame({'Data':Data})
# convert to 1D array
number_column = df.loc[:,'Data']
numbers = number_column.values
#finding peaks for 1D array
# peaks = find_peaks(numbers, height = 300, threshold = 1, distance = 5)
peaks = find_peaks(numbers, height = 300, threshold = None, distance=10)
height = peaks[1]['peak_heights'] #list of heights of peaks
peak_pos = peaks[0]
print(peaks)
# plot the peaks
fig = plt.figure()
ax = fig.subplots()
ax.plot(numbers)
ax.scatter(peak_pos, height,color = 'r', s = 25, label = 'Maxima')
ax.legend
## add numbers as text annotations
for i, text in enumerate(height):
if text.is_integer():
ax.annotate(int(text), (peak_pos[i], height[i]), size=10)
else:
ax.annotate(text, (peak_pos[i], height[i]), size=10)
plt.show()
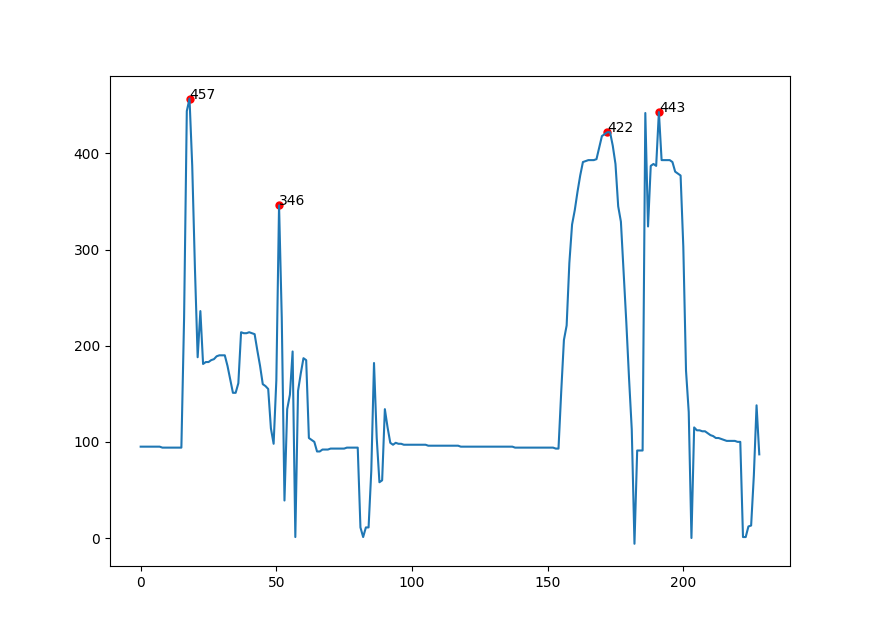
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70251448
复制相关文章
相似问题
腾讯云开发者
