
我遇到了一个梯度计算内部错误。
我正在自定义数据集上运行此代码(https://github.com/ayu-22/BPPNet-Back-Projected-Pyramid-Network/blob/master/Single_Image_Dehazing.ipynb),但遇到了此错误。RuntimeError: one of the variables needed for gradient computation has been modified by an in place operation: [torch. cuda.FloatTensor [1, 512, 4, 4]] is at version 2; expected version 1 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
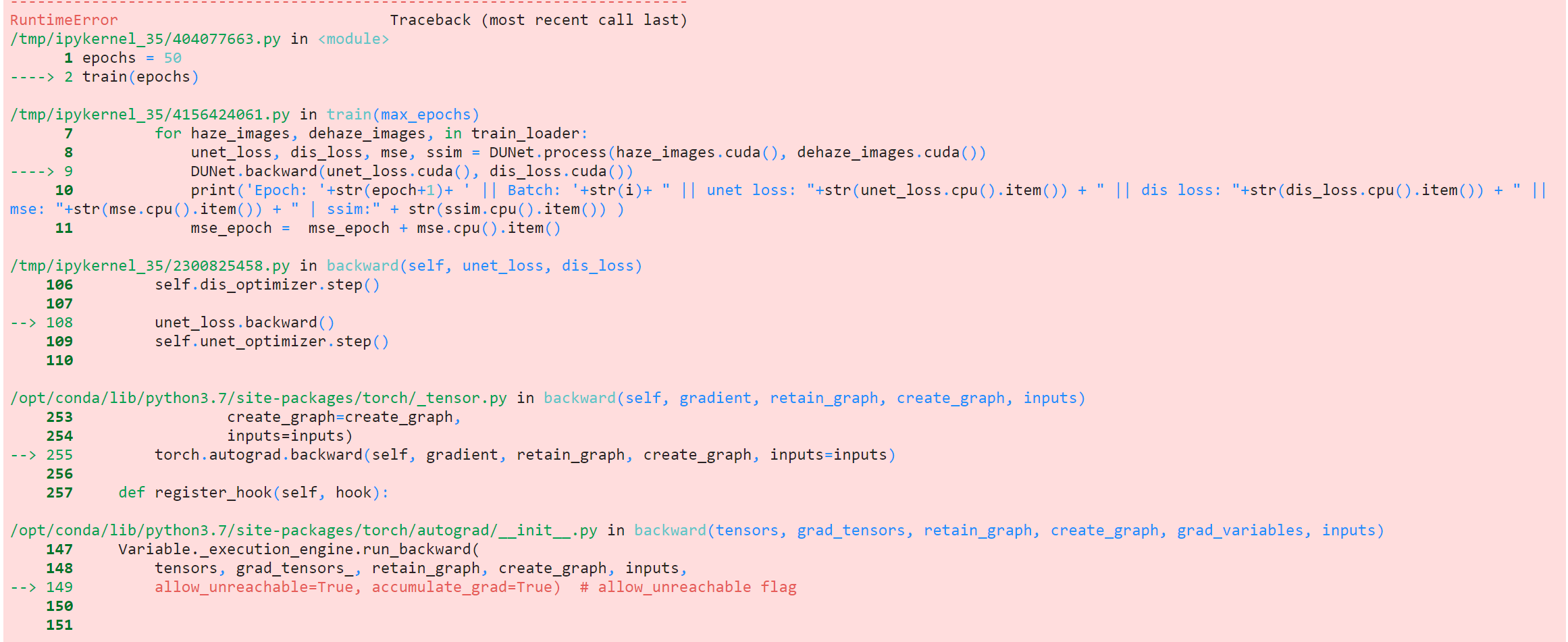
请参阅上面的代码链接,以澄清错误发生在何处。
我正在自定义数据集上运行此模型,数据加载器部分粘贴在下面。
import torchvision.transforms as transforms
train_transform = transforms.Compose([
transforms.Resize((256,256)),
#transforms.RandomResizedCrop(256),
#transforms.RandomHorizontalFlip(),
#transforms.ColorJitter(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
])
class Flare(Dataset):
def __init__(self, flare_dir, wf_dir,transform = None):
self.flare_dir = flare_dir
self.wf_dir = wf_dir
self.transform = transform
self.flare_img = os.listdir(flare_dir)
self.wf_img = os.listdir(wf_dir)
def __len__(self):
return len(self.flare_img)
def __getitem__(self, idx):
f_img = Image.open(os.path.join(self.flare_dir, self.flare_img[idx])).convert("RGB")
for i in self.wf_img:
if (self.flare_img[idx].split('.')[0][4:] == i.split('.')[0]):
wf_img = Image.open(os.path.join(self.wf_dir, i)).convert("RGB")
break
f_img = self.transform(f_img)
wf_img = self.transform(wf_img)
return f_img, wf_img
flare_dir = '../input/flaredataset/Flare/Flare_img'
wf_dir = '../input/flaredataset/Flare/Without_Flare_'
flare_img = os.listdir(flare_dir)
wf_img = os.listdir(wf_dir)
wf_img.sort()
flare_img.sort()
print(wf_img[0])
train_ds = Flare(flare_dir, wf_dir,train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_ds,
batch_size=BATCH_SIZE,
shuffle=True)要更好地了解dataset类,可以将我的dataset类与上面粘贴的链接进行比较。
Stack Overflow用户
发布于 2022-04-08 15:55:41
您的代码被卡在所谓的GAN网络的“反向传播”中。
您定义的向后图形应该如下所示:
def backward(self, unet_loss, dis_loss):
dis_loss.backward(retain_graph = True)
self.dis_optimizer.step()
unet_loss.backward()
self.unet_optimizer.step()所以在你的后向图中,你先传播dis_loss,它是鉴别器和对抗性损失的组合,然后是传播unet_loss,它是UNet,SSIM和ContentLoss的组合,但是unet_loss连接到鉴别器的输出损失。因此,当您在为dis_loss存储向后图形之前,在进行unet_loss优化程序步骤时,Py手电筒会给出这个错误,我建议您按以下方式修改代码:
def backward(self, unet_loss, dis_loss):
dis_loss.backward(retain_graph = True)
unet_loss.backward()
self.dis_optimizer.step()
self.unet_optimizer.step()这将开始你的训练!但是你可以用你的retain_graph=True做实验。
和伟大的工作在BPPNet的工作。
https://stackoverflow.com/questions/71793678
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号