
PDFKit在使用for循环时将文本分割成两个相等的列
提问于 2022-06-03 19:06:21
我试着用PDFKit来生成一个简单的pdf,在很大程度上,pdf是有用的,但是我有一个甲板构建API,它接收了很多卡片,每个对象我都想导出到一个pdf中,它和显示它们的名字一样简单,但是实际上,pdf一次只呈现一张卡片,并且只在一行上,我想要做的是让它把文本分割成列,这样itd看起来就像这样。
column 1 | column 2
c1 c8
c2 c9
c3 c10
c4 c(n)到目前为止,这是我的代码
module.exports = asyncHandler(async (req, res, next) => {
try {
// find the deck
const deck = await Deck.findById(req.params.deckId);
// need to sort cards by name
await deck.cards.sort((a, b) => {
if (a.name < b.name) {
return -1;
} else if (a.name > b.name) {
return 1;
} else {
return 0;
}
});
// Create a new PDF document
const doc = new PDFDocument();
// Pipe its output somewhere, like to a file or HTTP response
doc.pipe(
fs.createWriteStream(
`${__dirname}/../../public/pdf/${deck.deck_name}.pdf`
)
);
// Embed a font, set the font size, and render some text
doc.fontSize(25).text(`${deck.deck_name} Deck List`, {
align: "center",
underline: true,
underlineColor: "#000000",
underlineThickness: 2,
});
// We need to create two columns for the cards
// The first column will be the card name
// The second column will continue the cards listed
const section = doc.struct("P");
doc.addStructure(section);
for (const card of deck.cards) {
doc.text(`${card.name}`, {
color: "#000000",
fontSize: 10,
columns: 2,
columnGap: 10,
continued: true,
});
}
section.end();
// finalize the PDF and end the response
doc.end();
res.status(200).json({ message: "PDF generated successfully" });
} catch (error) {
console.error(error);
res.status(500).json({
success: false,
message: `Server Error - ${error.message}`,
});
}
});目前,这确实生成了一个我想要的列顺序,但是这个解决方案有一个极端的警告,那就是,如果卡片文本不是很长,那么下一张卡片就会从同一行开始,如果我能找到一种方法让文本占据这一行的全部宽度,那将是有用的,但是我没有看到与之相关的任何事情。

回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-04 11:44:45
我认为问题在于,您依赖于PDFKit的文本" flow“API/逻辑,而当两张卡片不够大,无法在列上流动,并且在一列中得到两张卡片时,您就会遇到问题。
我想说的是,您真正想要的是基于初始文本示例创建一个表。
PDFKit还没有一个表API (还没有),所以您必须自己弥补。
这里有一种方法,您可以了解事物的维度:
- 页面大小
- 文本单元格的大小(手动为您自己选择,或者使用PDFKit来告诉您某个文本的大小)。
然后,使用这些大小来计算文本中可以容纳多少行和列。
最后,您将遍历over列,然后为每一页遍历行,将文本写入这些逐行的“坐标”(我通过“偏移”跟踪这些坐标,并使用它来计算最终的“位置”)。
const PDFDocument = require('pdfkit');
const fs = require('fs');
// Create mock-up Cards for OP
const cards = [];
for (let i = 0; i < 100; i++) {
cards.push(`Card ${i + 1}`);
}
// Set a sensible starting point for each page
const originX = 50;
const originY = 50;
const doc = new PDFDocument({ size: 'LETTER' });
// Define row height and column widths, based on font size; either manually,
// or use commented-out heightOf and widthOf methods to dynamically pick sizes
doc.fontSize(24);
const rowH = 50; // doc.heightOfString(cards[cards.length - 1]);
const colW = 150; // doc.widthOfString(cards[cards.length - 1]); // because the last card is the "longest" piece of text
// Margins aren't really discussed in the documentation; I can ignore the top and left margin by
// placing the text at (0,0), but I cannot write below the bottom margin
const pageH = doc.page.height;
const rowsPerPage = parseInt((pageH - originY - doc.page.margins.bottom) / rowH);
const colsPerPage = 2;
var cardIdx = 0;
while (cardIdx < cards.length) {
var colOffset = 0;
while (colOffset < colsPerPage) {
const posX = originX + (colOffset * colW);
var rowOffset = 0;
while (rowOffset < rowsPerPage) {
const posY = originY + (rowOffset * rowH);
doc.text(cards[cardIdx], posX, posY);
cardIdx += 1;
rowOffset += 1;
}
colOffset += 1;
}
// This is hacky, but PDFKit adds a page by default so the loop doesn't 100% control when a page is added;
// this prevents an empty trailing page from being added
if (cardIdx < cards.length) {
doc.addPage();
}
}
// Finalize PDF file
doc.pipe(fs.createWriteStream('output.pdf'));
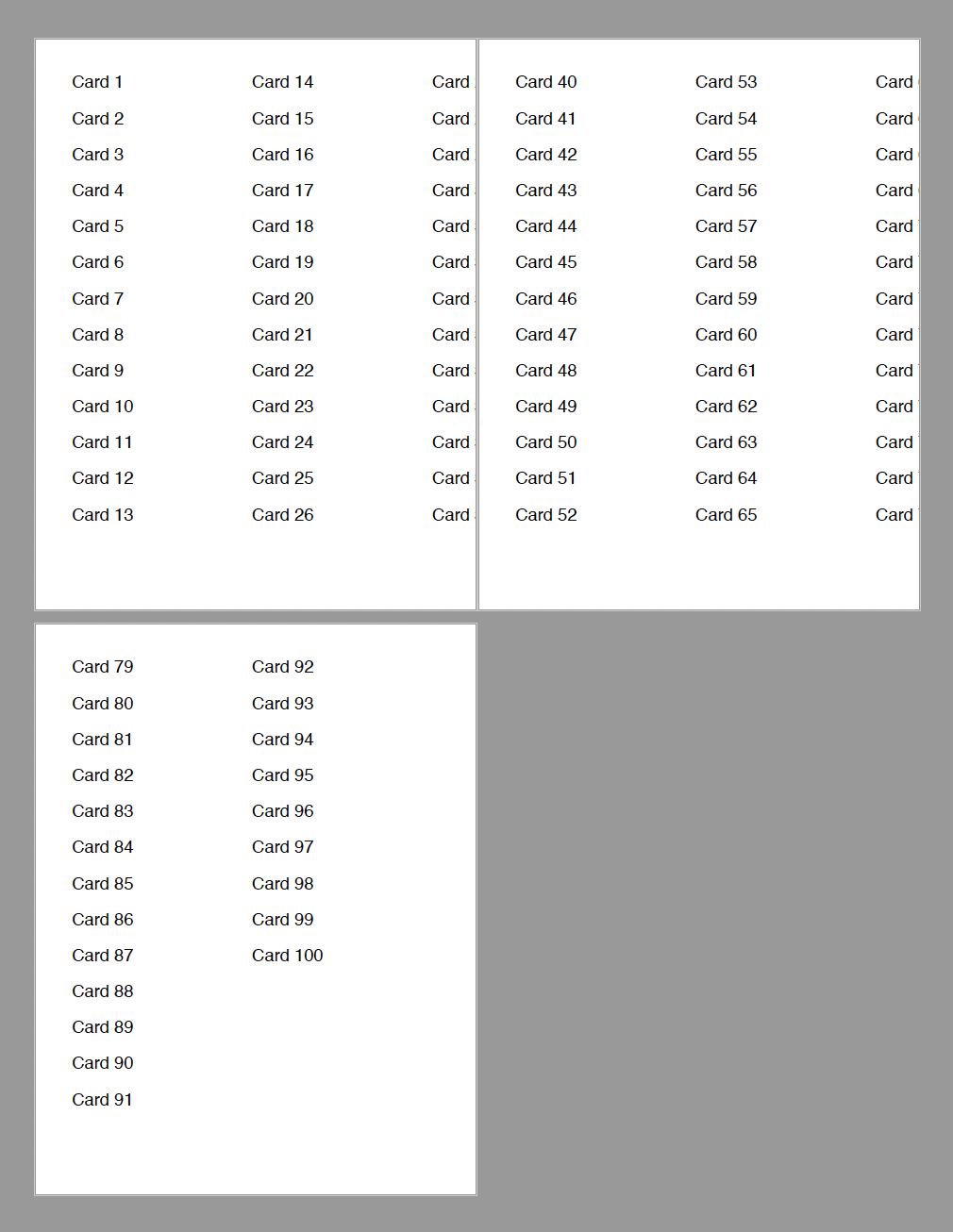
doc.end();当我运行它时,我得到了一个PDF,它有4页,如下所示:

改变colW = 250和colsPerPage = 3
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72496768
复制相关文章








点击加载更多


腾讯云开发者
