为什么这些工作是分开的,而不是在一起[KMeans集群]
为什么这些工作是分开的,而不是在一起[KMeans集群]
提问于 2022-08-05 20:45:04
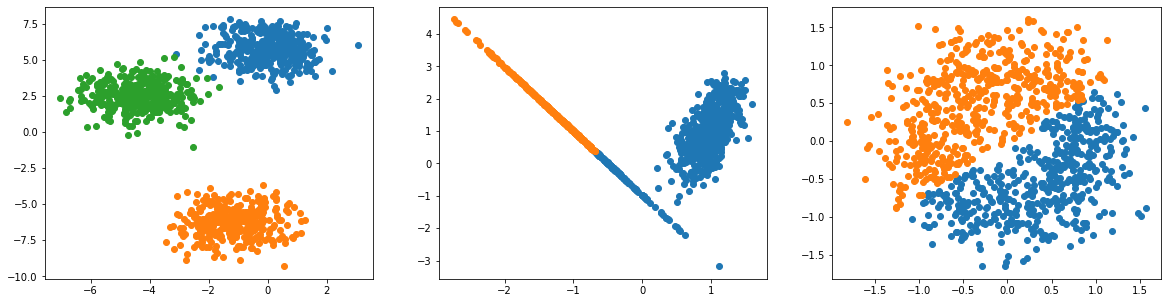
我试图在3个数据集上绘制来自KMeans模型的结果。这些程序的代码如下:
blobsX, blobsY = make_blobs(n_samples=1000, n_features=2, random_state=177)
classX, classY = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, random_state=177)
circleX, circleY = make_circles(n_samples=1000, noise=0.3, random_state=177)当我运行模型并在单独的代码块中绘制它们时,它可以工作:
kmeans = KMeans(n_clusters=3)
label = kmeans.fit_predict(blobsX)
labels = np.unique(label)
for i in labels:
plt.scatter(blobsX[label == i , 0] , blobsX[label == i , 1] , label = i)
plt.show()
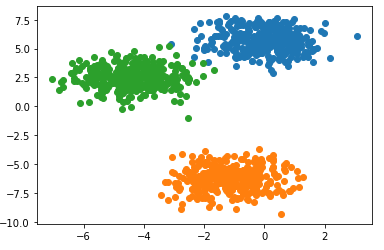
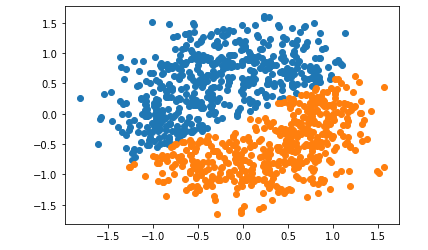
kmeans = KMeans(n_clusters=2)
label = kmeans.fit_predict(classX)
labels2 = np.unique(label)
for i in labels2:
plt.scatter(classX[label == i , 0] , classX[label == i , 1] , label = i)
plt.show()
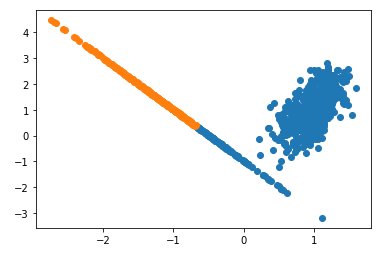
kmeans = KMeans(n_clusters=2)
label = kmeans.fit_predict(circleX)
labels3 = np.unique(label)
for i in labels3:
plt.scatter(circleX[label == i , 0] , circleX[label == i , 1] , label = i)
plt.show()
当我试图将它们放在同一代码块中的子图中时,只有其中一个模型工作正常,另外两个模型的工作原理如下:
kmeans = KMeans(n_clusters=3)
label = kmeans.fit_predict(blobsX)
labels = np.unique(label)
kmeans = KMeans(n_clusters=2)
label = kmeans.fit_predict(classX)
labels2 = np.unique(label)
kmeans= KMeans(n_clusters=2)
label = kmeans.fit_predict(circleX)
labels3 = np.unique(label)
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(131)
ax2 = fig.add_subplot(132)
ax3 = fig.add_subplot(133)
for i in labels:
ax.scatter(blobsX[label == i , 0] , blobsX[label == i , 1] , label = i)
for j in labels2:
ax2.scatter(classX[label == j , 0] , classX[label == j , 1] , label = j)
for k in labels3:
ax3.scatter(circleX[label == k , 0] , circleX[label == k , 1] , label = k)
plt.show()
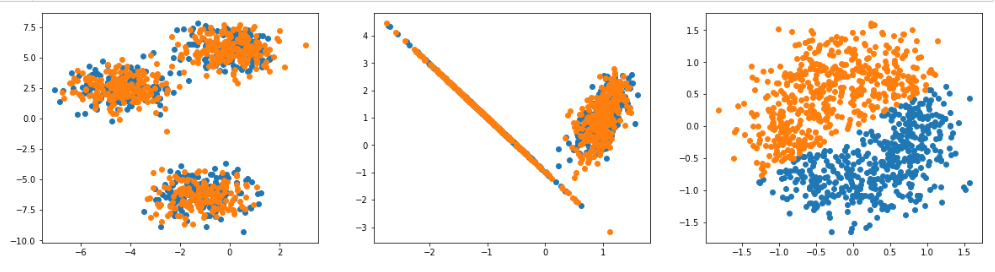
为什么会发生这种情况,解决这个问题的最佳方法是什么?
回答 2
Stack Overflow用户
发布于 2022-08-05 21:56:38
问题是matplotlib正在考虑将集群分组,因为它们在一起。当您没有提到群集的颜色时,就会发生这种情况。
解决这个问题的最好方法是为分散函数提供颜色。然后,它将采取您在情节中提到的颜色,而不是考虑所有的集群是相同的。
快乐编码
Stack Overflow用户
发布于 2022-08-06 02:14:33
只需在拟合和提取标签后立即绘制每一个,并将其放入子图中。一个函数会有所帮助,因为您几乎做了三次相同的事情:
def plot_kmeans_clusters(n_clusters, data, ax):
kmeans = KMeans(n_clusters=n_clusters)
label = kmeans.fit_predict(data)
labels = np.unique(label)
for i in labels:
ax.scatter(data[label == i , 0] , data[label == i , 1] , label = i)
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(131)
ax2 = fig.add_subplot(132)
ax3 = fig.add_subplot(133)
plot_kmeans_clusters(3, blobsX, ax)
plot_kmeans_clusters(2, classX, ax2)
plot_kmeans_clusters(2, circleX, ax3)
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73257244
复制相关文章
相似问题
腾讯云开发者
