
从列中的值匹配的不同行中将1个值相加在一起
提问于 2020-06-17 08:36:59
我目前有两个数据集。第一份包含了我所制定的价值观的足球队的列表。
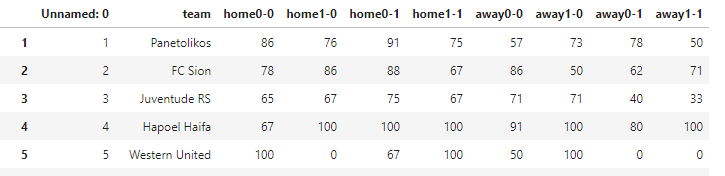
我有第二个数据集,列出了今天要参加比赛的球队的名单。
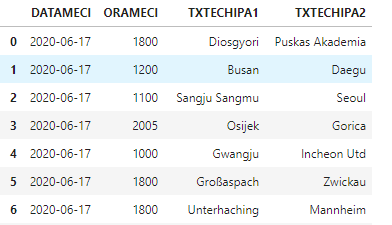
我想要做的是在dataset2中加上两支互相比赛的球队的平均数量,这样结果就是
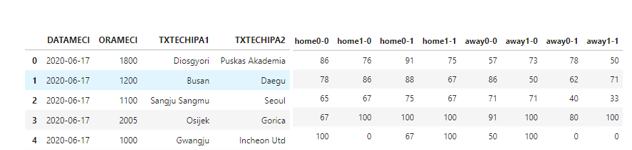
我看过堆栈溢出,没有找到任何能够帮助我的东西。我对与潘达斯合作相当陌生,所以我不确定这是否可能。
作为一个例子,数据集:
data1 = {
'DATAMECI': ['17/06/2020', '17/06/2020'],
'ORAMECI': ['11:30', '15:30'],
'TXTECHIPA1': ['Everton', 'Man City'],
'TXTECHIPA2': ['Hull', 'Leeds'],
}
data2 = {
'Team': ['Hull', 'Leeds','Everton', 'Man City'],
'Home0-0': ['80', '78','80', '66'],
'Home1-0': ['81', '100','90', '70'],
'Away0-1': ['88', '42','75', '69'],
}期望的输出是
Desired = {
'DATAMECI': ['17/06/2020', '17/06/2020'],
'ORAMECI': ['11:30', '15:30'],
'TXTECHIPA1': ['Everton', 'Man City'],
'TXTECHIPA2': ['Hull', 'Leeds'],
'Home0-0': ['80', '72'],
'Home1-0': ['86', '85'],
'Away0-1': ['86', '56',],
}
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-06-18 00:37:05
与对行进行迭代不同的另一个选项是,您可以合并数据集,然后对列进行迭代。
我还注意到您想要的输出是四舍五入的,所以我也有
样本:
data1 = pd.DataFrame({
'DATAMECI': ['17/06/2020', '17/06/2020'],
'ORAMECI': ['11:30', '15:30'],
'TXTECHIPA1': ['Everton', 'Man City'],
'TXTECHIPA2': ['Hull', 'Leeds'],
})
data2 = pd.DataFrame({
'Team': ['Hull', 'Leeds','Everton', 'Man City'],
'Home0-0': ['80', '78','80', '66'],
'Home1-0': ['81', '100','90', '70'],
'Away0-1': ['88', '42','75', '69'],
})
Desired = pd.DataFrame({
'DATAMECI': ['17/06/2020', '17/06/2020'],
'ORAMECI': ['11:30', '15:30'],
'TXTECHIPA1': ['Everton', 'Man City'],
'TXTECHIPA2': ['Hull', 'Leeds'],
'Home0-0': ['80', '72'],
'Home1-0': ['86', '85'],
'Away0-1': ['86', '56',],
})代码:
import pandas as pd
cols = [ x for x in data2 if 'Home' in x or 'Away' in x ]
data1 = data1.merge(data2.rename(columns={'Team':'TXTECHIPA1'}), how='left', on=['TXTECHIPA1'])
data1 = data1.merge(data2.rename(columns={'Team':'TXTECHIPA2'}), how='left', on=['TXTECHIPA2'])
for col in cols:
data1[col] = data1[[col + '_x', col + '_y']].astype(int).mean(axis=1).round(0)
data1 = data1.drop([col + '_x', col + '_y'], axis=1)输出:
print(data1)
DATAMECI ORAMECI TXTECHIPA1 TXTECHIPA2 Home0-0 Home1-0 Away0-1
0 17/06/2020 11:30 Everton Hull 80.0 86.0 82.0
1 17/06/2020 15:30 Man City Leeds 72.0 85.0 56.0Stack Overflow用户
发布于 2020-06-17 10:36:03
谢谢你添加数据。下面是一种使用循环的简单方法。循环通过df2 (即将到来的比赛)。从df1 ( teams )中找到参与团队的相应行。现在,您将从df1中得到2行。平均所需列并将其添加到df2中。考虑到与数据集类似的结构,下面是一个示例:
df1 = pd.DataFrame({'team': ['one', 'two', 'three', 'four', 'five'],
'home0-0': [86, 78, 65, 67, 100],
'home1-0': [76, 86, 67, 100, 0],
'home0-1': [91, 88, 75, 100, 67],
'home1-1': [75, 67, 67, 100, 100],
'away0-0': [57, 86, 71, 91, 50],
'away1-0': [73, 50, 71, 100, 100],
'away0-1': [78, 62, 40, 80, 0],
'away1-1': [50, 71, 33, 100, 0]})
df2 = pd.DataFrame({'date': ['2020-06-17', '2020-06-17', '2020-06-17', '2020-06-17', '2020-06-17', '2020-06-17', '2020-06-17'],
'time': [1800, 1200, 1100, 2005, 1000, 1800, 1800],
'team1': ['one', 'two', 'three', 'four', 'five', 'one', 'three'],
'team2': ['five', 'four', 'two', 'one', 'three', 'two', 'four']})
for i, row in df2.iterrows():
team1 = df1[df1['team']==row['team1']]
team2 = df1[df1['team']==row['team2']]
for col in df1.columns[1:]:
df2.loc[i, col]=(np.mean([team1[col].values[0], team2[col].values[0]]))
print(df2)对于您的样本数据集:
for i, row in data1.iterrows():
team1 = data2[data2['Team']==row['TXTECHIPA1']]
team2 = data2[data2['Team']==row['TXTECHIPA2']]
for col in data2.columns[1:]:
data1.loc[i, col]=(np.mean([int(team1[col].values[0]), int(team2[col].values[0])]))
print(data1)结果:
DATAMECI ORAMECI TXTECHIPA1 TXTECHIPA2 Home0-0 Home1-0 Away0-1
0 17/06/2020 11:30 Everton Hull 80.0 85.5 81.5
1 17/06/2020 15:30 Man City Leeds 72.0 85.0 55.5页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62433980
复制相关文章









腾讯云开发者
