如何在帧上分割语音数据并计算MFCC
如何在帧上分割语音数据并计算MFCC
提问于 2016-01-08 00:04:54
我理解创建一个自动语音识别引擎的基本步骤。然而,我需要一个清晰的概念,分割是如何做的,什么是帧和样本。我会写下我所知道的,并期待答案--呃,在我错的地方纠正我,并进一步指导我。
据我所知,语音识别的基本步骤是:
(我假设输入数据是wav/ogg (或某种音频)文件)
- 预先强调语音信号:即,应用一个滤波器来强调高频信号。可能类似于: yn = xn - 0.95 xn-1
- 找到话语开始和调整剪辑大小的时间。(可与步骤1互换)
- 将剪辑分割成更小的时间框架,每个片段大约30毫秒长。此外,每段将有大约256帧和两段将有一个100帧分开?(即30*100/256毫秒?)
- 在每一帧(段的1/256)上加汉明窗口?结果是一系列的信号。
- 用X(t)表示的每帧信号的快速傅里叶变换
- Mel过滤器组处理:(尚未详细说明)
- 离散余弦变换:(尚未详细说明--但要知道这将给我一组MFCC,也称为每个输入话语的声矢量。
- Delta和Delta谱:我知道这是用来计算MFCC的增量系数和双δ系数的,不是很多。
- 在此之后,我认为需要使用HMMs或ANNs对对应的音素进行Mel倒谱系数(delta和double delta)的分类,并进行分析,将音素与单词和单词分别与句子进行匹配。
虽然这些对我来说很清楚,但我很困惑第三步是否正确。如果它是正确的,在下面的步骤3,我是否适用于每一帧?另外,在第6步之后,我认为每个帧都有自己的MFCC集,对吗?
提前谢谢你!
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-01-08 11:58:49
将剪辑分割成更小的时间框架,每个片段大约30毫秒长。此外,每段将有大约256帧和两段将有一个100帧分开?(即30*100/256毫秒?)
不是框架而是样本。每帧30 is的8khz采样率为30/1000 * 8000 =240个样本。帧重叠,帧间移位为10 is或80采样。在这张图片上,它的外观如下:
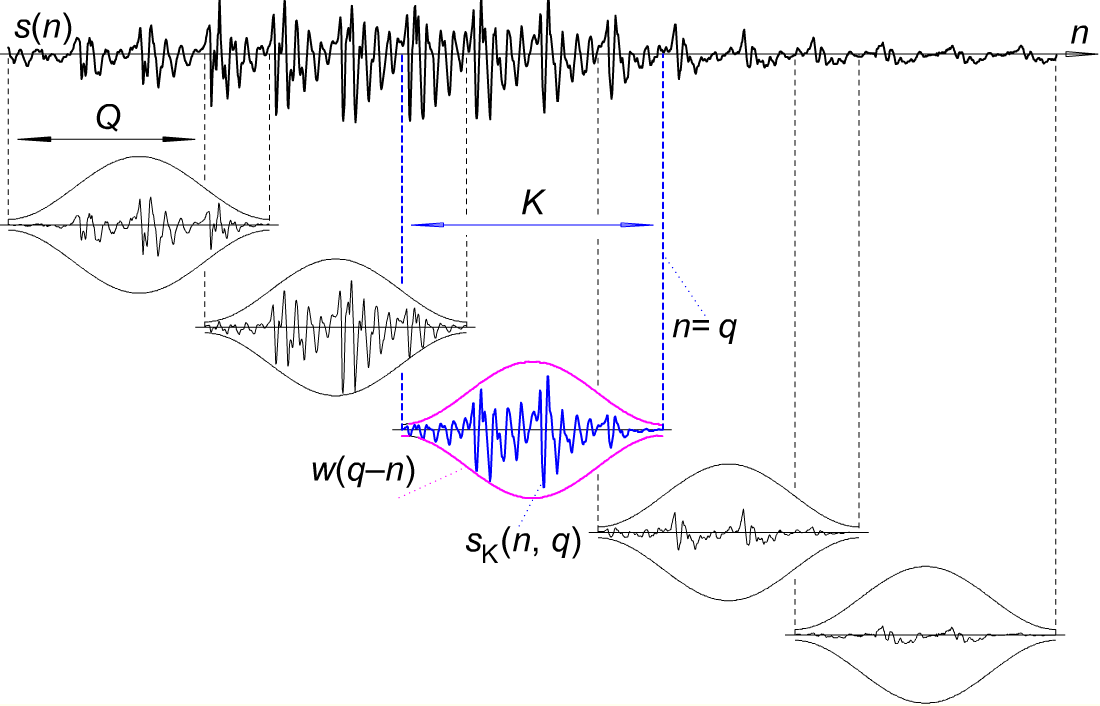
这里Q为80,K为240样品。
如果它是正确的,在下面的步骤3,我是否适用于每一帧?
是
另外,在第6步之后,我认为每个帧都有自己的MFCC集,对吗?
是。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/34672182
复制相关文章
相似问题
腾讯云开发者
