
在MSSQL上没有将谓词推到左联接中
我试图优化一些复杂的观点,这被简化为一个简单的问题。
MSSQL将连接两个表,部分位于主查询谓词上。问题是,在连接表实际离开之前,服务器不会使用这个谓词,结果是从表读取更多的数据,查询速度更慢。
样本数据
为了说明这个问题,我创建了一个简单的示例,表示视图数据的一部分:
create table A (
ID numeric not null identity,
D date not null,
);
create table B (
ID numeric not null identity,
A_ID numeric not null,
DATE_FROM date not null,
DATE_TO date not null
)
declare @i int = 0
declare @j int
declare @k int
declare @batch int = 1000
declare @a_id int
declare @month date
begin transaction
while @i < 2000
begin
set @j = 0
set @month = dateadd(mm, @i, '1950-01-01')
while @j < 20
begin
insert into a (d) values (@month);
select @a_id = scope_identity()
set @k = 0
while @k < 30
begin
insert into b ( a_id, date_from, date_to )
values ( @a_id, @month, dateadd(dd, round(rand() * 100, 0), @month) );
set @k = @k + 1;
if (@batch = 0)
begin
set @batch = 1000
commit;
begin transaction
end
set @batch = @batch - 1;
end
set @j = @j + 1;
end
set @i = @i + 1;
end
commit
alter table A add constraint A_PK primary key (ID);
alter table B add constraint B_PK primary key (ID);
alter table B add constraint A_FK foreign key (A_ID) references A(ID);
create index AI on A(D);
create index BI on B(A_ID, DATE_FROM, DATE_TO) include (ID);示例(慢速)查询
我试图优化的查询非常简单:
select A.id
, B.id
, B.DATE_FROM
, B.DATE_TO
from A
left join B on B.A_ID = A.ID and A.D between B.DATE_FROM and B.DATE_TO
where A.D = '2000-01-01'结果约为80 And ,其查询计划如下:
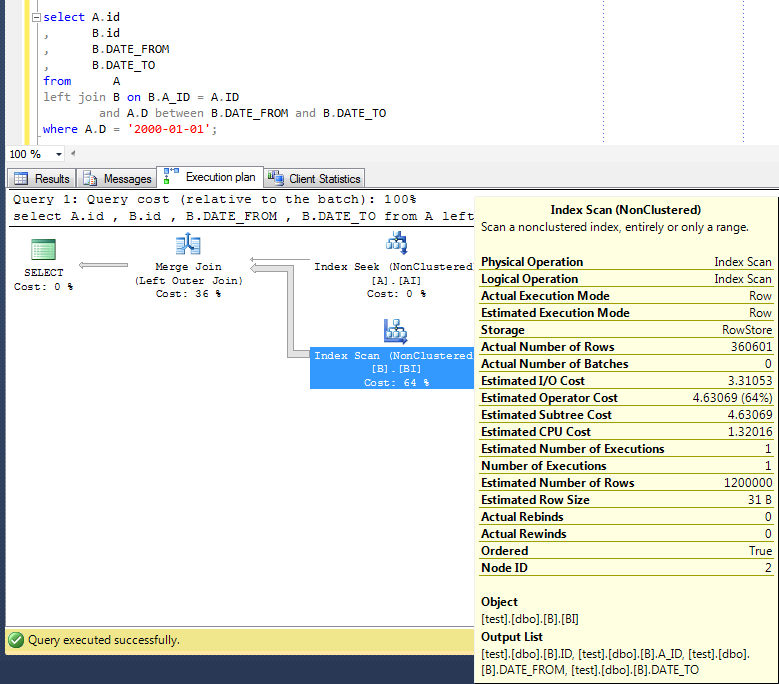
基本相同(快速)查询
如果我在左侧联接中右边使用谓词日期:
select A.id
, B.id
, B.DATE_FROM
, B.DATE_TO
from A
left join B on B.A_ID = A.ID
and '2000-01-01' between B.DATE_FROM and B.DATE_TO
where A.D = '2000-01-01'突然间,MSSQL实际上可以使用它并加速到0ms:
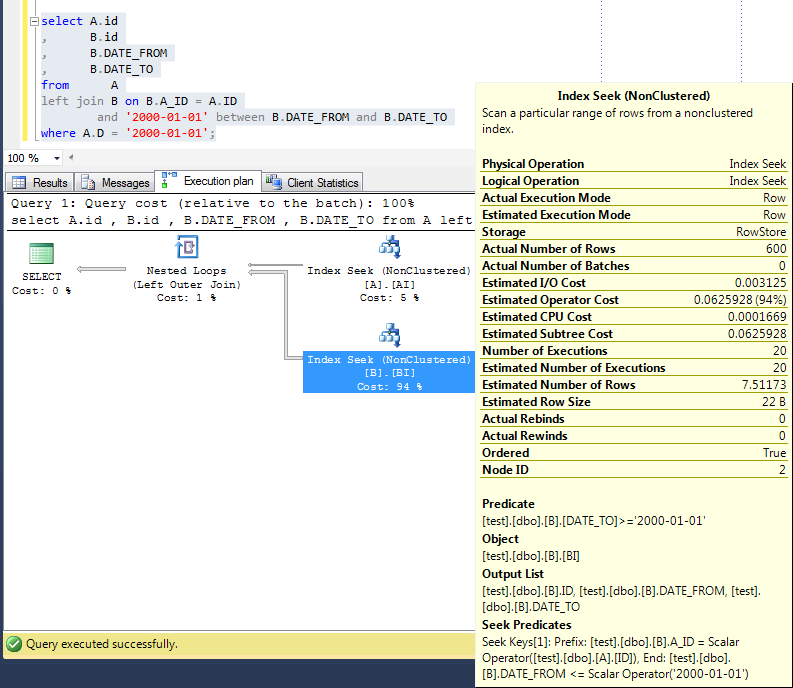
问题
如果我删除/更改了索引IA或IB或数据量,这两个计划看起来都不一样,但相同的情况仍然存在:没有谓词正在读取已连接的表,查询速度更慢。
问题是为什么MSSQL为这些查询创建了不同的计划--和--如何在第一个示例中更有效地加入?请注意,我不能使用第二个查询,因为它只是视图的一部分,在视图中谓词是未知的。
编辑1
关于艾伦的答案,还有一个考验。如果在谓词中只使用ID和DATE_FROM,那么优化器也会在谓词上筛选B:
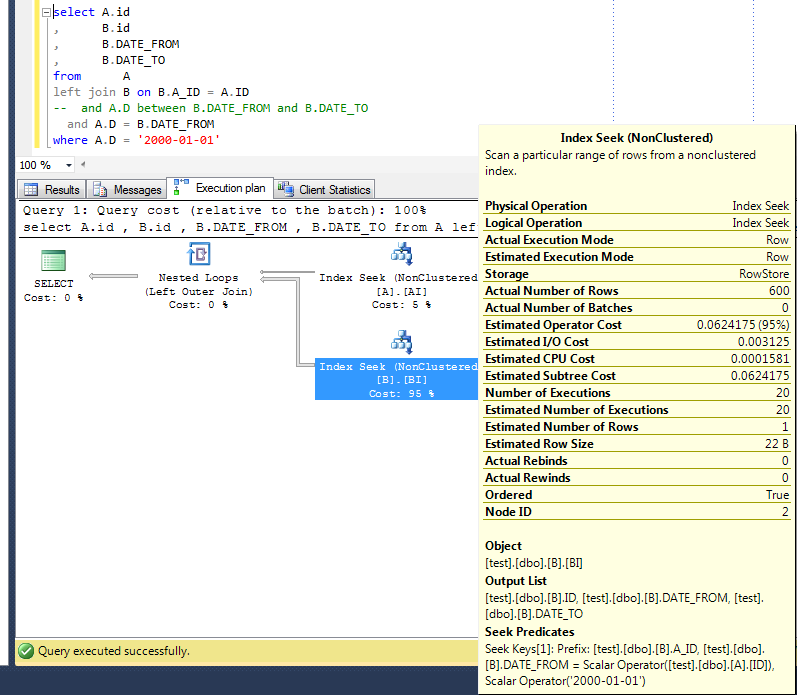
请注意,此更改返回的结果通常不同,但在这里返回相同的结果(我猜这里不重要)。
编辑2
关于TT的评论(以及Allan的回答),我改变了测试数据,以获得更多的随机性,因此A.d并不总是在B中开始的间隔。我只更改了insert into A
insert into a (d) values (dateadd(dd, round(rand() * @j, 0), @month));并且优化器开始像预期的那样工作:
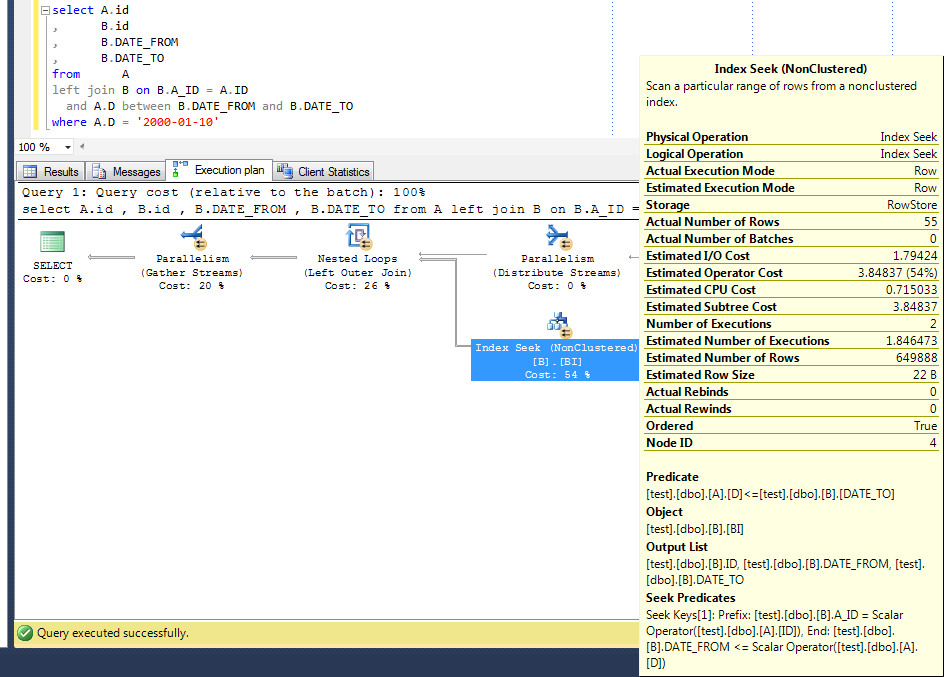

回答 1
Stack Overflow用户
发布于 2016-02-23 03:24:32
我不得不把这作为一个答案,因为它正变得越来越重要,需要评论:
因为这两个查询并不相同,所以Server的操作方式不同。
对于您来说,它们在测试示例中可能是语义上的,但它们不是针对优化器/编译器的。
联接子句在WHERE之前处理。这一点在外部联接中尤其明显,其中ON子句中的参数的含义与where子句中的参数的含义不同.
因此,在第一个例子中,您会说--给我左边的所有人,然后在匹配日期列上右侧做一个外部联接(在没有匹配的地方给我NULL )。最后,上面写的是日期的具体位置。
但是,在第二步中,添加了一个额外的约束,并说给我左边的所有,在右边做一个外部连接,日期在特定的日期之间(在没有匹配的地方给我NULL )。然后在最后处理这个地方。
如此微妙但意义重大的不同。
您可以很快看到它们是不同的,因为您不必通过规则引擎进行编译和优化,但是引擎必须遵循它的规则。
但是,如果没有更多关于正在发生的事情的信息,我可以给出的关于“优化”的任何建议都可能无关紧要,因为查询的其他部分没有显示出来。
基于这一解释,我认为您甚至将不得不将查询完全重构,如果可能的话,将其重构为多个部分。
然后您可以利用一些临时表(而不是表变量),因此您可以首先完成所有内部连接,然后在处理所有内部连接时执行外部连接。通过这种方式,您可以将大量数据过滤掉,并在外部联接的顶部使用临时结果。
不管你是否被允许在你的情况下这么做,我不知道--但考虑到你的“约束”,问题可能是“无法解决的”。
https://stackoverflow.com/questions/35575985
复制






腾讯云开发者
