
在分区数据上运行groupByKey/ reduceBuKey,但使用不同的键
提问于 2017-01-13 00:07:13
我有一个((id, ts), some value)类型的排序RDD。仅在id字段上使用自定义分区器对此进行分区。
math.abs(id.hashCode % numPartitions)现在,如果我在这个分区的RDD上运行以下两个函数,它会涉及数据集的洗牌和重新分区吗?
val partitionedRDD: ((id:Long, ts:Long), val:String) = <Some Function>
val flatRDD = orderedRDD.map(_ => (_._1.id, (_._1.ts, _._2)))我想知道的是,flatRDD.groupByKey()和flatRDD.reduceByKey()是否将具有与partitionedRDD或Spark相同的分区,并重新洗牌数据集并创建新的分区?
谢谢你,德维

回答 1
Stack Overflow用户
回答已采纳
发布于 2017-01-13 01:44:57
是的,在groupByKey或reduceByKey上执行flatRDD必然会导致另一次洗牌。
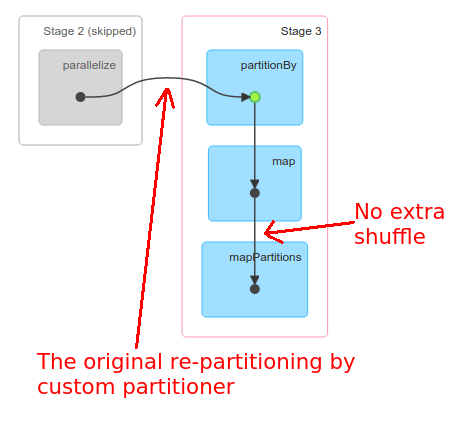
因为您知道flatRDD已经被id分区了,所以您可以安全地假设具有相同id的所有记录都驻留在一个分区中。因此,如果您想要groupBy(id),您可以使用mapPartitions (与preservesPartitioning = true一起)并分别对每个分区执行该操作,从而防止Spark对您的数据进行洗牌:
flatRDD.mapPartitions({ it =>
it.toList
.groupBy(_._1).mapValues(_.size) // some grouping + reducing the result
.iterator
}, preservesPartitioning = true)这不会引起额外的洗牌:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41629953
复制相关文章







腾讯云开发者
