Scrapy使用自带的XPath选择器和CSS选择器来选择HTML文档中特定部分的内容,XPath是用来选择XML和HTML文档中节点的语言,CSS是为HTML文档应用样式的语言,也可以用来选择具有特定样式的HTML元素。使用XPath选择器和CSS选择器解析网页的速度要比BeautifulSoup快一些。
大语言模型(英文:Large Language Model,缩写LLM)中用户的输入称为:Prompt(提示词),一个好的 Prompt 对于大模型的输出至关重要,因此有了 Prompt Engneering(提示工程)的概念,教大家如何写好提示词
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜
请注意,本文编写于 990 天前,最后修改于 990 天前,其中某些信息可能已经过时。
官网:https://docs.scrapy.org/en/latest/intro/overview.html
我们都知道,爬虫获取页面的响应之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,
Scrapy提供了自己的数据提取方法,即Selector(选择器)。Selector是基于lxml来构建的,支持XPath选择器、CSS选择器以及正则表达式,功能全面,解析速度和准确度非常高。 本节将介绍Selector的用法。 1. 直接使用 Selector是一个可以独立使用的模块。我们可以直接利用Selector这个类来构建一个选择器对象,然后调用它的相关方法如xpath()、css()等来提取数据。 例如,针对一段HTML代码,我们可以用如下方式构建Selector对象来提取数据: from
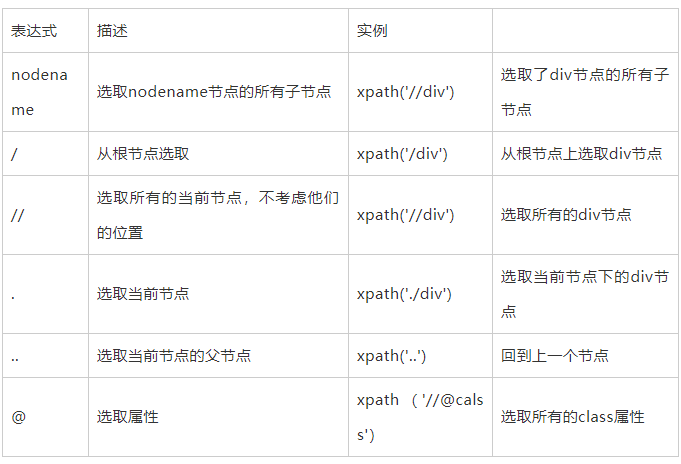
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。几乎所有想要定位的节点都可以用 XPath 来选择。
本文介绍了一个使用Python编写的程序,用于获取指定网页的背景图片并保存到本地。在程序中使用了requests模块发送HTTP请求,lxml模块解析HTML文档,以及os模块操作文件与目录。文章详细介绍了每个模块的作用以及具体的代码实现。
一个有趣的尝试,看到一些微信文章,想要发布到自己的wordpress网站,如果不会php语言,那ai帮助自己一步步来实现,是否可以呢?下面是实现的全过程。
你用 Python 处理过的最大数据集有多大?我想大概不会超过上亿条吧,今天分享一个用 Python 处理分析 14 亿条数据的案例。
3.Start_urls = [‘http://blog.jobbole.com/all-posts/’]
我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数据解析的方法,也就是本章要介绍的Xpath表达式。
为了从网页提取信息,了解网页的结构是非常必要的。我们会快速学习HTML、HTML的树结构和用来筛选网页信息的XPath。 HTML、DOM树结构和XPath 从这本书的角度,键入网址到看见网页的整个过程可以分成四步: 在浏览器中输入网址URL。URL的第一部分,也即域名(例如gumtree.com),用来搜寻网络上的服务器。URL和其他像cookies等数据形成了一个发送到服务器的请求request。 服务器向浏览器发送HTML。服务器也可能发送XML或JSON等其他格式,目前我们只关注HTML。 HTML
使用xpath和css查询响应非常常见,因此响应中还包含两个快捷方式:response.xpath() 和response.css()
关于BeutifulSoup4的用法入门请参考Python爬虫扩展库BeautifulSoup4用法精要,scrapy爬虫案例请参考Python使用Scrapy爬虫框架爬取天涯社区小说“大宗师”全文,爬虫原理请参考Python不使用scrapy框架而编写的网页爬虫程序 本文代码运行环境为Python 3.6.1+scrapy 1.3.0。 >>> import scrapy # 测试样本 >>> html = ''' <html> <head> <base href='http://exam
今天主要整理python的三种解析方法 正则表达式 1、正则解析主要是以//.和//.?的两种从而获得想要获取的数据就比如说在分页爬取的时候中间的 ex = '.03
我们可以看到这个网站总共分为六个大的模块:Latest,Hot,Toplist,Random,Upload,Forums 我爬取的主要是latest,hot,toplist,random这四个模块的图片. 这四个模块对应的url网址分别为:
爬虫基础简介 http协议 概念: 服务器和客户端进行数据交互的一种形式 user-Agent: 请求载体的身份表示 Connection : 请求完毕后,是断开连接还是保持连接 Content-Type : 服务器相应客户端的数据类型 # user-Agent ( NetWork-All-Headers ) Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638
我们要爬取的目标网站是:http://www.netbian.com/,这个网站长这样:
编辑 | JackTian 来源 | 杰哥的IT之旅(ID:Jake_Internet) 转载请联系授权(微信ID:Hc220066)
HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法:发送请求、获取响应、解析并提取数据、保存到本地。
之前用四篇很啰嗦的入门级别的文章,带着大家一起去了解并学习在编写爬虫的过程中,最基本的几个库的用法。
回调函数中,count表示已下载的数据块,size数据块大小,total表示总大小。
前几天给大家分享了Xpath语法的简易使用教程,没来得及上车的小伙伴可以戳这篇文章:在Scrapy中如何利用Xpath选择器从网页中采集目标数据——详细教程(上篇)、在Scrapy中如何利用Xpath选择器从网页中采集目标数据——详细教程(下篇)。今天小编给大家介绍Scrapy中另外一种选择器,即大家经常听说的CSS选择器。
Git是一个流行的版本控制系统。它是开发人员如何在项目中协作和工作的方式。 Git允许您跟踪随着时间推移对项目所做的更改。除此之外,如果您想撤消更改,它还允许您恢复到以前的版本。
尝试了一下用xpath爬取图集谷上面的美女图片,这次选择的是阿朱小姐姐,下面详细介绍如何爬取该网站中阿朱小姐姐的全部套图
https://car.autohome.com.cn/photolist/series/52880/6957393.html#pvareaid=3454450
在音频元素 <mpvoice> 中有一个 src 属性通过其拼接 https://mp.weixin.qq.com/ 域名,以为就可以了,谁知打开一看,还是没有音频数据,页面如下:
文章目录 一、分析网页 翻页查看url变化规律: 第一页:https://movie.douban.com/top250?start=0&filter= 第二页:https://movie.dou
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 有了selenium能够实现可见即可爬 -使用(本质,并不是python在操作浏览器,而是python在操作浏览器驱动(xx.exe),浏览器驱动来驱动浏览器) -0 以驱动谷歌浏览器为例子(建议你用谷歌,最合适)找谷歌浏览器驱动 -0 如果是windows,解压之后是个exe,不同平台就是不同平台的可执行文件 -1 安装模块:pip3 install selenium -2 需要浏览器驱动(ie,火狐,谷歌浏览器。。。。驱动得匹配(浏览器匹配,浏览器版本跟驱动匹配)) -3 写代码
之前发了一个国航的滑块模拟操作,没有计算滑块到缺口的位置。 本篇则是用opencv+selenium来对QQ邮箱的滑块进行模拟测试。
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统、谷歌浏览器
在上一篇关于爬虫的博客里,我提到过,整个爬虫分为四个部分,上一篇博客已经完成了前两步,也就是我说的最难的地方,接下来这一步数据解析不是很难,但就是很烦人,但只要你有耐心,一步一步查找、排除就会提取出目标信息,这一步就相当于从接收到的庞大数据中提取出真正想要、有意义的信息,所以对于爬虫来说,应该是很重要的。
作者说 本人秉着方便他人的想法才开始写技术文章的,因为对于自学的人来说想要找到系统的学习教程很困难,这一点我深有体会,我也是在不断的摸索中才小有所成,如果你们觉得我写的不错就帮我推广一下,让更多的人看到。另外如果有什么错误的地方也要及时联系我,方便我改进,谢谢大家对我的支持
在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,低效繁琐,在工作中,有时会遇到需要相当多的图片资源,可是如何才能在短时间内获得大量的图片资源呢?
前面我们一起完成了一个数据清洗的实战教程。现在,我们一起来学习数据采集的相关知识。
mylog.py 日志模块,记录一些爬取过程中的信息,在大量爬取的时候,没有log帮助定位,很难找到错误点
学习了xpath后,又有一个实战二了,利用xpath爬取网站上的图片,由于学的时候疯狂报错,决定再做一遍,然后逐步分析,加深理解,后续学习一下怎么爬取豆瓣评分前100的电影,然后以CSV的格式展示(感觉所有学爬虫的都有白嫖豆瓣电影这个项目。)
爬取网络上的图片是一种常见的需求,它可以帮助我们批量下载大量图片并进行后续处理。本文将介绍如何使用 Python 编写一个简单的爬虫,从指定网页中获取女神图片,并保存到本地。
需求:爬取站长素材的高清图片的爬取https://sc.chinaz.com/tupian/
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器,但是现在谷歌的无头比较火,下面展示谷歌的无头)
上一讲中我给你讲了如何使用八爪鱼采集数据,对于数据采集刚刚入门的人来说,像八爪鱼这种可视化的采集是一种非常好的方式。它最大的优点就是上手速度快,当然也存在一些问题,比如运行速度慢、可控性差等。
5、综合案例 复选框 5.1、案例效果 📷 5.2、分析和实现 功能分析 全选 为全选按钮绑定单击事件。 获取所有的商品项复选框元素,为其添加 checked 属性,属性值为 true。 全不选 为全不选按钮绑定单击事件。 获取所有的商品项复选框元素,为其添加 checked 属性,属性值为 false。 反选 为反选按钮绑定单击事件 获取所有的商品项复选框元素,为其添加 checked 属性,属性值是目前相反的状态。 代码实现 <!DOCTYPE html> <html
一个多线程素材下载爬虫,实现多线程素材下载,包含素材包rar,素材图及素材描述,应用了经典的生产者与消费者模式,不过数据没有下载全,容易出现卡死的问题,期待后期能够解决相关问题,可以算是一个半成品,供大家参考和学习,有更好的多线程解决方案也可以交流!
领取专属 10元无门槛券
手把手带您无忧上云

 云服务器
云服务器 即时通信 IM
即时通信 IM ICP备案
ICP备案 对象存储
对象存储 实时音视频
实时音视频
