Spring Cloud Sleuth是一款用于构建分布式跟踪系统的Spring Cloud组件。它可以帮助我们追踪请求从开始到结束的整个流程,并收集所需的信息以进行监视和调试。本文将介绍如何在Spring Boot应用程序中集成Spring Cloud Sleuth。
Spring Cloud Sleuth和ELK(Elasticsearch、Logstash和Kibana)是一种流行的组合,可用于实现分布式跟踪和日志分析。
在 全链路监控:方案概述与比较 一文中,我们有详细介绍过分布式链路跟踪的实现理论基础。
Spring Cloud Sleuth是一个基于Spring Cloud的分布式跟踪解决方案。它使用了Google Dapper的思想,通过在服务调用链路上添加唯一的traceId和spanId来追踪请求的流转情况。而MDC(Mapped Diagnostic Context)则是log4j和logback等日志框架中的一个功能,它可以在日志输出时动态添加一些关键信息,便于问题的定位和排查。
Supported dependencies Id Description Required version activemq Java Message Service API via Apache ActiveMQ >=1.4.0.RC1 activiti-basic Activiti BPMN workflow engine >=1.2.0.RELEASE and <2.0.0.M1 actuator Production ready features to help you monitor and m
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
由于微服务架构中每个服务可能分散在不同的服务器上,因此需要一套分布式日志的解决方案。spring-cloud提供了一个用来trace服务的组件sleuth。它可以通过日志获得服务的依赖关系。基于sleuth,可以通过现有的日志工具实现分布式日志的采集。
在Spring Boot中,选择构建系统是一项重要任务。建议使用Maven或Gradle,因为它们可以为依赖关系管理提供良好的支持。Spring不支持其他构建系统。
点击关注公众号,Java干货及时送达 由于微服务架构中每个服务可能分散在不同的服务器上,因此需要一套分布式日志的解决方案。 spring-cloud提供了一个用来trace服务的组件sleuth。它可以通过日志获得服务的依赖关系。基于sleuth,可以通过现有的日志工具实现分布式日志的采集。 这里使用的是ELK,也就是elasticsearch、logstash、kibana。 一、sleuth 第一步:sleuth管理端 sleuth一般单独放在一个工程中。需要添加如下依赖 <dependency>
从上周六 7 号到今天的 11 号,我都在医院,小孩因肺炎已经住院了,我白天和晚上的时间需要照顾娃,只能在娃睡觉的时候肝文了。对了,医院没有宽带和 WiFi,我用的手机开的热点~
可观察性可以通过分布式系统下各种组件交互的可见性来帮助识别应用程序中的问题和调试问题。
Spring Cloud Sleuth是Spring Cloud生态系统中的一个分布式追踪解决方案,可以帮助开发人员实现对分布式系统中请求链路的追踪和监控。在分布式系统中,一个请求可能会经过多个服务节点,如果没有一种追踪工具进行监控,那么当出现问题时,开发人员可能需要花费很长的时间来排查问题。而Spring Cloud Sleuth则提供了一种简单易用的解决方案,帮助开发人员快速定位和排查问题。
错过了这一篇,你可能再也学不会 Spring Cloud 了!Spring Boot做为下一代 web 框架,Spring Cloud 作为最新最火的微服务的翘楚,你还有什么理由拒绝。赶快上船吧,老船长带你飞。终章不是最后一篇,它是一个汇总,未来还会写很多篇。
.markdown-body{word-break:break-word;line-height:1.75;font-weight:400;font-size:15px;overflow-x:hidden;color:#333}.markdown-body h1,.markdown-body h2,.markdown-body h3,.markdown-body h4,.markdown-body h5,.markdown-body h6{line-height:1.5;margin-top:35px;margin-bottom:10px;padding-bottom:5px}.markdown-body h1{font-size:30px;margin-bottom:5px}.markdown-body h2{padding-bottom:12px;font-size:24px;border-bottom:1px solid #ececec}.markdown-body h3{font-size:18px;padding-bottom:0}.markdown-body h4{font-size:16px}.markdown-body h5{font-size:15px}.markdown-body h6{margin-top:5px}.markdown-body p{line-height:inherit;margin-top:22px;margin-bottom:22px}.markdown-body img{max-width:100%}.markdown-body hr{border:none;border-top:1px solid #ddd;margin-top:32px;margin-bottom:32px}.markdown-body code{word-break:break-word;border-radius:2px;overflow-x:auto;background-color:#fff5f5;color:#ff502c;font-size:.87em;padding:.065em .4em}.markdown-body code,.markdown-body pre{font-family:Menlo,Monaco,Consolas,Courier New,monospace}.markdown-body pre{overflow:auto;position:relative;line-height:1.75}.markdown-body pre>code{font-size:12px;padding:15px 12px;margin:0;word-break:normal;display:block;overflow-x:auto;color:#333;background:#f8f8f8}.markdown-body a{text-decoration:none;color:#0269c8;border-bottom:1px solid #d1e9ff}.markdown-body a:active,.markdown-body a:hover{color:#275b8c}.markdown-body table{display:inline-block!important;font-size:12px;width:auto;max-width:100%;overflow:auto;border:1px solid #f6f6f6}.markdown-body thead{background:#f6f6f6;color:#000;text-align:left}.markdown-body tr:nth-child(2n){background-color:#fcfcfc}.markdown-body td,.markdown-body th{padding:12px 7px;line-height:24px}.markdown-body td{min-width:120px}.markdown-body blockquote{color:#666;padding:1px 23px;margin:22px 0;border-left:4px solid #cbcbcb;background-color:#f8f8f8}.markdown-body blockquote:after{display:block;content:""}.markdown-body blockquote>p{margin:10px 0}.markdown-body ol,.markdown-body ul{padding-left:28px}.markdown-body ol li,.markdown-body
Sleuth是Spring Cloud的组件之一,它为Spring Cloud实现了一种分布式追踪解决方案,兼容Zipkin,HTrace和其他基于日志的追踪系统,例如 ELK(Elasticsearch 、Logstash、 Kibana)。
使用Spring Cloud Sleuth实现分布式跟踪的过程非常简单,只需添加必要的依赖和配置即可。
Spring Boot 2.0不支持@EnableZipkinServer,所以需要下载Zipkin的服务器
如果应用程序在运行过程发生问题,大多数开发人员都难以跟踪日志。这可以通过用于Spring Boot应用程序的Spring Cloud Sleuth和ZipKin服务器来解决。
目前,Spring Cloud已在南京公司推广开来,不仅如此,深圳那边近期也要基于Spring Cloud新开微服务了。 于是,领导要求我出一套基于Spring Cloud的快速开发脚手架(近期开源)。在编写脚手架的过程中,也顺带总结一下以前在项目中遇到的问题: 使用Hystrix时,如何传播ThreadLocal对象? 我们知道,Hystrix有隔离策略:THREAD以及SEMAPHORE。 如果你不知道Hystrix的隔离策略,可以阅读我的书籍《Spring Cloud与Docker微服务架构实战》,或
案例代码:https://github.com/q279583842q/springcloud-e-book
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。 现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最为广泛的开源实现是 Twitter 的 Z
北京时间2021-12-01,Spring Cloud 2021.0.0正式发布。话说,2021年都快过完了呀,怎么才第一个版本呢?如果对比去年2020.0.0版本发布时间是2020-12-22的话,发现还是有“进步”的哈。
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前端请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
官方文档:https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.1.3.RELEASE/single/spring-cloud-sleuth.html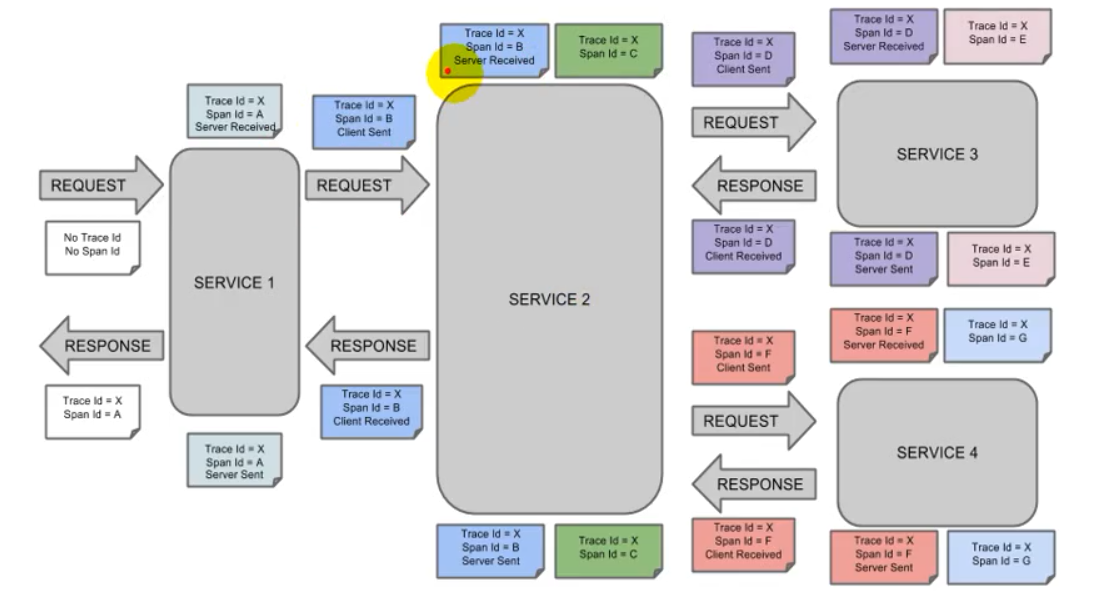
这个demo使用Spring Sleuth来收集tracing 数据并将其发送到OpenZipkin, OpenZipkin作为OpenShift服务部署,并由一个持久的MySQL数据库镜像支持。可以从Zipkin控制台查询tracing 数据,该控制台通过OpenShift route公开。日志集成也可以使用trace id将相同业务请求的分布式执行捆绑在一起。
欢迎来到菜鸟SpringCloud实战入门系列(SpringCloudForNoob),该系列通过层层递进的实战视角,来一步步学习和理解SpringCloud。
通过上一篇《分布式服务跟踪(整合logstash)》,我们虽然已经能够利用ELK平台提供的收集、存储、搜索等强大功能,对跟踪信息的管理和使用已经变得非常便利。但是,在ELK平台中的数据分析维度缺少对请求链路中各阶段时间延迟的关注,很多时候我们追溯请求链路的一个原因是为了找出整个调用链路中出现延迟过高的瓶颈源,亦或是为了实现对分布式系统做延迟监控等与时间消耗相关的需求,这时候类似ELK这样的日志分析系统就显得有些乏力了。对于这样的问题,我们就可以引入Zipkin来得以轻松解决。 Zipkin简介 Zipkin
Spring Cloud是一个用于构建分布式系统的开源框架,基于Spring Boot提供了一系列工具和服务,用于简化分布式系统的开发和部署。它提供了众多特性,包括服务发现、负载均衡、配置管理、熔断器、网关等,帮助开发者构建弹性、可伸缩、高可用的分布式系统。本文将详细介绍Spring Cloud的主要组件和关键特性。
假设我们有一个微服务架构,其中包括两个服务:用户服务和订单服务。当用户下单时,订单服务会向用户服务发送一个请求,获取用户的信息。此时,我们可以使用Spring Cloud Sleuth来跟踪这个请求的整个调用链路,包括每个服务的处理情况和耗时。具体代码如下:
一般来说要解决这两个问题或者与之类似的问题,就需要用到调用链监控工具。那么调用链监控工具是怎么实现问题的快速定位的呢?这就需要我们理解调用链监控的基础实现原理,我们来看一张图:
在这篇文章中,我们将讨论和探究springboot中的CommandLineRunner接口,将涉及这个接口的不同特性,以及何时使用这个接口。
文章目录 1. spring sleuth- 服务追踪 1.1. Zipkin 1.1.1. 服务端的安装 1.1.2. 客户端使用 1.2. 参考文章 spring sleuth- 服务追踪 Zipkin Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服
本文示例基于Spring Boot 1.5.x实现,如对Spring Boot不熟悉,可以先学习我的这一篇:《Spring Boot 1.5.x 基础学习示例》。关于微服务基本概念不了解的童鞋,可以先阅读下始祖Martin Fowler的《Microservice》,本文不做介绍和描述。
PS:5年前就见过别人演示这种系统,当时才开始搞分布式系统,现在想想确实没有你想不到的功能,只有你做不到的,分布式链路跟踪确实是开发和运维的神奇,良好的定位问题,线上问题的发现。
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可。
本篇文章涉及底层设计以及原理,以及问题定位和可能的问题点,非常深入,篇幅较长,所以拆分成上中下三篇:
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
随着互联网业务的不断发展,传统的单体应用逐渐无法满足日益复杂的业务需求和用户量的增长。微服务架构应运而生,它将应用拆分成一系列小型、自治的服务,使得应用的开发、测试、部署和扩展更加灵活高效。Spring Cloud Alibaba 是 Spring Cloud 与 Alibaba 开源的一系列微服务组件的集合,为构建弹性可扩展的微服务架构提供了强有力的支持。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
◆ Sleuth与Zipkin技术 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案,Sleuth可以结合Zipkin做链路跟踪。Spring Cloud Sleuth的服务链路跟踪功能可以帮助我们快速发现错误根源,以及监控分析每条请求链路上的请求性能。Sleuth的主要工作原理是拦截请求,并在日志中加入额外的Span和Trace的相关信息。从Sleuth 2.0.0开始,Sleuth使用Brave作为调用链工具库。Brave是一个用于捕捉分布式系统之间调用信息的工具
通过之前的N篇博文介绍,实际上我们已经能够通过使用它们搭建起一个基础的微服务架构系统来实现我们的业务需求了。但是,随着业务的发展,我们的系统规模也会变得越来越大,各微服务间的调用关系也变得越来越错综复杂。通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一条复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都有可能引起请求最后的失败。这时候对于每个请求全链路调用的跟踪就变得越来越重要,通过
官网:http://openjdk.java.net/projects/code-tools/jmh/
备注:zipkin 服务端,可以直接前往官网https://zipkin.io/下载jar包运行。当然也可以整合在spring cloud中(常见)
今天这篇文章陈某介绍一下链路追踪相关的知识,以Spring Cloud Sleuth和zipkin这两个组件为主,后续文章介绍另外一种。
众所周知,Spring Cloud Sleuth有两种方式整合Zipkin: HTTP直连Zipkin方式 MQ方式,架构如下图: Spring Cloud Edgware及更高版本中
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与, 参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
领取专属 10元无门槛券
手把手带您无忧上云







