
别等到系统炸了才明白:架构决策就是一场残酷的优先级游戏
 >**我花了10年才悟透的真相:90%的架构灾难,不是因为技术选错了,而是因为优先级排错了。** 我是老李,一个在电商和SaaS战场摸爬滚打10年的架构师。今天我要撕开一个行业潜规则:**你以为在做"技术决策",其实你在玩"生死排序"——排对了,系统稳如老狗;排错了,半夜被洪峰摁在地上摩擦。** 这不是鸡汤,这是我用3次线上事故、2次被老板骂、1次差点被开除换来的血泪教训。 ---- ## 一、我的至暗时刻:一个错误的排序,差点毁掉整个项目 ### 故事背景:日订单500的"微服务灾难" 2019年,我刚升架构师不久,意气风发。公司要做一个B2B采购平台,日订单量预估500单。我当时脑子一热:**"既然要做就做到位,上微服务、上K8s、上服务网格!"** 结果呢? **3个月后的惨状:** - 开发效率暴跌60%:简单改个字段要跨3个服务 - 运维成本暴涨:6个人的团队,2个专职搞K8s - 上线延期2个月:光调试服务间调用就折腾了1个月 - 老板暴怒:**"你是来做架构的,还是来炫技的?"** **更扎心的是:** 系统上线后日订单才200多,那些"高大上"的架构根本用不上。我像个小丑,搭了个航空母舰去打蚊子。 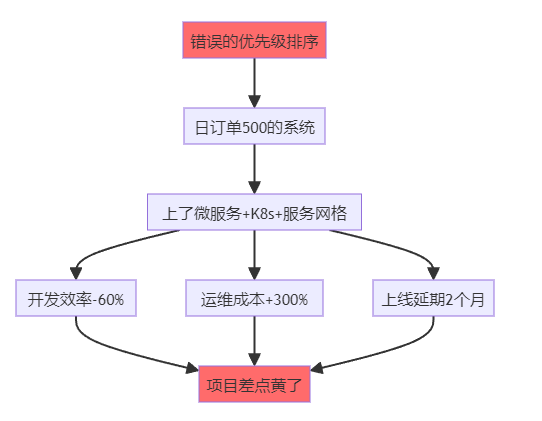 **那一刻我明白了:架构不是技术拼图,是针对"此刻最疼的地方"做减痛手术。** 当时的核心痛点应该是: 1. **快速交付** > 功能完整 > 成本可控 2. 而不是:高并发 > 团队自治 > 弹性扩展 **我把优先级排反了。技术再牛逼,解决不了当下的问题,就是耍流氓。** ---- ## 二、SaaS的残酷真相:每个阶段的痛点完全不同 做了10年后,我总结出一个铁律:**SaaS系统的架构演进,本质就是一场"痛点排序持续重排"的游戏。你要么主动重排,要么被业务打脸。** ### 阶段1:0到1的MVP(日活<1000) **核心痛点排序:交付速度 >> 功能覆盖 >> 成本** **典型场景:** 一个创业公司要做CRM系统,团队3个人,要在2个月内上线。 **错误决策(我见过的):** ❌ CEO:"我们要做成Salesforce那样的!" ❌ CTO:"那就上微服务、上中台、上数据湖!" 结果:6个月过去了,连客户列表都没做完,钱烧光了 **正确排序:** 优先级: 1. 交付速度: 用单体应用,PHP/Python/Node.js都行,快速跑通MVP 2. 功能覆盖: 先做客户管理+销售跟进+简单报表,够用就行 3. 成本可控: 用云服务器+MySQL+Redis,月成本控制在5000元内 技术选型: - 单体应用(Laravel/Django/Express) - 关系型数据库(MySQL/PostgreSQL) - 对象存储(OSS/S3) - 一键部署(Docker Compose) 验收标准: - 2个月内上线 - 核心功能可用 - 月成本<5000元 **血泪教训:MVP阶段,能用Excel解决的,就别写代码。** ---- ### 阶段2:1到10的增长期(日活1K-1W) **核心痛点排序:稳定性 >> 性能瓶颈 >> 数据一致性** **典型场景:** CRM系统火了,日活从500涨到5000,系统开始频繁卡顿,客户投诉暴增。 **我经历的真实案例:** 某SaaS公司,客户从50家涨到500家,系统每天下午3-5点必卡,客户疯狂投诉。 **定位痛点(花了1周):** 问题1: 报表查询拖垮主库 原因: 所有查询打在主库,没有读写分离 解决: 加1个从库 + Redis缓存 问题2: 大客户的数据把小客户挤爆 原因: 没有租户隔离,共用一个线程池 解决: 按租户分配资源配额 问题3: 定时任务在高峰期抢资源 原因: 所有定时任务都在下午3点跑 解决: 错峰调度 + 异步队列 **新的优先级排序:** |痛点|权重|解决方案| |:-:|:-:|:-:| |**稳定性**|40%|读写分离 + 缓存 + 监控告警| |**性能**|30%|索引优化 + 慢查询治理| |**数据一致性**|20%|关键操作加事务 + 幂等设计| |成本|10%|暂时可以不管| **效果:** 1个月后,系统稳定性从每天宕机2次 → 月度可用性99.5%。 ---- ### 阶段3:10到100的爆发期(日活1W-10W) **核心痛点排序:多租户隔离 >> 数据安全 >> 弹性扩展** **典型场景:** 某HR SaaS,签了几个大客户(每家5000+员工),小客户开始抱怨系统卡。 **这是我见过最惨的案例:** 某公司签了一个10万人的大客户,结果: - 大客户跑批量导入,把整个系统拖崩 - 其他500个小客户全部无法使用 - 当天流失了30个小客户 - CEO差点把CTO开了 **问题根源:没有租户隔离,所有客户共享资源。** **重新排序后的架构:** 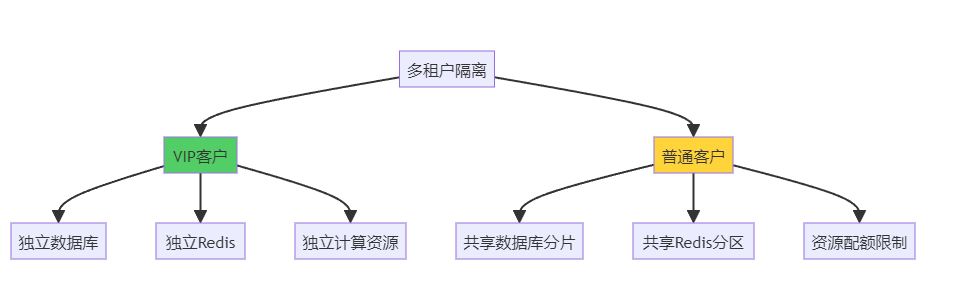 **新的优先级:** 优先级排序: 1. 多租户隔离: 大客户独立部署,小客户共享资源 2. 数据安全: 租户数据物理隔离,审计日志完备 3. 弹性扩展: 按租户动态分配资源 4. 成本优化: 小客户密度部署,大客户按需付费 技术选型: - 数据库分片(按租户ID分库分表) - 资源隔离(K8s Namespace + Resource Quota) - 限流熔断(按租户维度限流) - 独立部署(VIP客户独立集群) **血泪教训:SaaS最怕的不是技术问题,而是一个大客户把所有小客户干翻。** ---- ### 阶段4:100到1000的平台化(日活10W+) **核心痛点排序:可扩展性 >> API治理 >> 数据资产** **典型场景:** 从单一产品扩展到多产品线,需要建平台。 **我踩过的坑(2021年):** 公司从CRM扩展到ERP、OA、财务,4条产品线各自为战: - 用户体系有4套 - 权限系统有4套 - 消息通知有4套 - 数据完全不通 **客户疯了:** "我买了你们3个产品,为什么要注册3次账号?" **重新排序:** |原优先级(错误)|新优先级(正确)| |:-:|:-:| |快速上新功能|**平台能力复用**| |各产品独立迭代|**统一用户/权限/数据**| |性能优化|**API标准化治理**| **中台架构:** 统一能力层: - 用户中心: 统一账号、登录、SSO - 权限中心: RBAC + 数据权限 - 消息中心: 统一通知、邮件、短信 - 审计中心: 操作日志、数据追溯 产品层: - CRM: 调用统一能力 - ERP: 调用统一能力 - OA: 调用统一能力 - 财务: 调用统一能力 数据层: - 主数据管理(客户、员工、组织) - 数据血缘追溯 - 统一数据口径 **效果:** 新产品上线时间从6个月 → 2个月,复用率从0% → 70%。 ---- ## 三、洪峰来了:非线性暴涨会让所有优先级失效 ### 我被双11教育的惨痛经历 2020年双11,我们给某电商平台做了订单系统。日常订单量2万单,我们优化了查询性能,P99延迟从200ms → 50ms。 **我得意洋洋:** "看,我们的系统多快!" **结果双11当天:** - 0点开始,订单量暴涨到50万单/小时(**25倍峰值**) - 系统直接崩溃,数据库连接池打满 - 订单成功率跌到60%,客户疯狂投诉 - 老板凌晨2点打电话骂我:"你那些优化有屁用!" **我的错误:** 把"性能优化"排在第一位,忽略了"峰值韧性"。 **重新排序后的架构:** 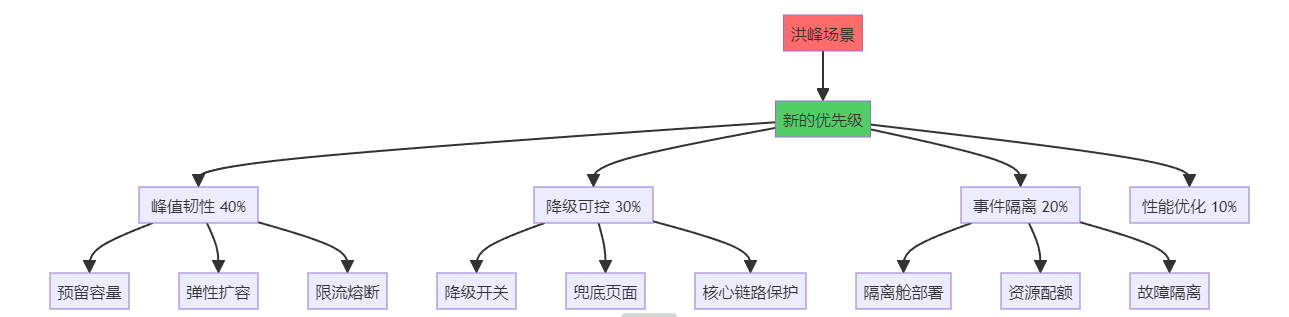 **具体措施(2021年双11):** |策略|实施方案|效果| |:-:|:-:|:-:| |**隔离舱**|营销页、商详页、下单页分舱部署|互不影响| |**限流**|核心下单链路舱内限流|保护库存/支付| |**降级**|非核心功能降级(推荐、评论)|核心成功率+15%| |**兜底**|失败降级到兜底页|投诉-41%| |**预热**|峰前静态化+CDN预热|流量削峰30%| **结果:订单成功率从60% → 99.2%,用户投诉下降41%。** **我的领悟:洪峰不讲道理,它只看你有没有准备好隔离、限流、降级、兜底。** ---- ## 四、一套可落地的"优先级排序方法论" 这是我用3年时间,踩过无数坑后总结的操作手册: ### Step 1:量化痛点(不要靠感觉) **错误方式:** 产品:"系统有点慢" 开发:"那我优化一下" 老板:"成本有点高" **正确方式:用数据说话** 痛点清单(2024年Q1): 痛点1 - 稳定性: 数据: 月度可用性97.8%(目标99.5%) 影响: 每周宕机2次,客户投诉127次 权重: 40% 痛点2 - 性能: 数据: 报表查询P99=3.2秒(目标<1秒) 影响: 客户抱怨"卡顿",NPS评分-15分 权重: 30% 痛点3 - 成本: 数据: 月服务器成本18万(同行8万) 影响: 毛利率从40% → 28% 权重: 20% 痛点4 - 交付速度: 数据: 新功能上线周期平均6周 影响: 销售抱怨"竞品都有,我们没有" 权重: 10% **关键:用可度量的数据证明痛点,而不是靠感觉。** ---- ### Step 2:明确目标与约束(写下来,不要猜) **业务目标:** 目标1: 月度可用性从97.8% → 99.5% 验收: 连续3个月无重大故障 目标2: 报表查询P99从3.2秒 → <1秒 验收: 客户NPS评分提升20分 目标3: 服务器成本从18万 → 12万/月 验收: 毛利率恢复到35% **技术约束:** 约束1: 必须兼容现网1000+客户,不能停机迁移 约束2: 团队只有8个人,学习曲线不能太陡 约束3: 改造周期不超过3个月 约束4: 不能影响Q2的3个大客户交付 ---- ### Step 3:方案评分(算分,不要拍脑袋) **至少准备3个方案:** |方案|描述|稳定性|性能|成本|交付速度|综合分| |:-:|:-:|:-:|:-:|:-:|:-:|:-:| |**A:保守优化**|加缓存+读写分离|7分|6分|8分|9分|**7.3分**| |**B:隔离+限流**|租户隔离+降级|9分|7分|6分|6分|**7.6分**| |**C:重构架构**|微服务化改造|10分|9分|4分|3分|**6.9分**| **权重:** 稳定性40% + 性能30% + 成本20% + 交付10% **结论:选方案B(隔离+限流)** **风险清单:** 风险1: 租户迁移可能影响部分客户 - 缓解: 灰度迁移,提供回滚开关 - 监控: 迁移成功率、客户投诉 风险2: 限流可能误伤正常请求 - 缓解: 动态阈值,白名单机制 - 监控: 限流拦截率、业务成功率 风险3: 改造周期可能超期 - 缓解: 分阶段交付,MVP先行 - 监控: 里程碑进度、交付质量 ---- ### Step 4:灰度试点(先小后大,随时回滚) **试点策略:**  **拉闸指标(自动回滚):** 指标1: 错误率 > 1% → 自动回滚 指标2: 响应时间P99 > 2秒 → 自动回滚 指标3: 客户投诉 > 5条/天 → 人工介入 ---- ### Step 5:复盘与重排(每季度一次) **复盘清单:** ``` 1. 痛点是否解决? - 可用性: 97.8% → 99.6% ✅ - 性能: P99 3.2秒 → 0.8秒 ✅ - 成本: 18万 → 13万/月 ✅ 2. 新的痛点是什么? - 客户开始要求API对接 - 数据导出速度慢 - 移动端体验差 3. 优先级是否需要重排? - 稳定性: 40% → 20%(已达标) - API治理: 0% → 30%(新需求) - 移动体验: 0% → 20%(新需求) - 数据能力: 10% → 20%(升级) 4. 技术债如何回收? - 下线3个临时降级开关 - 合并2个冗余服务 - 清理老代码2000行 ``` ---- ## 五、SaaS架构的5个典型陷阱(我全踩过) ### 陷阱1:盲目追新技术 **案例:** 某公司CTO看了云原生大会,回来就要上K8s + Istio。 **结果:** - 团队学习成本暴涨,离职率+30% - 运维复杂度×10,线上故障频发 - 成本增加2倍,毛利率暴跌 **教训:** 技术选型不是追新,而是解决当下问题。日活5000的系统,Docker Compose够用了。 ---- ### 陷阱2:过度设计 **案例:** 某创业公司做HR SaaS,上来就要做"中台"。 **结果:** - 6个月过去,连员工管理都没做完 - 投资人不给钱了,公司倒闭 **教训:** MVP阶段别谈中台,先把基础功能跑通。 ---- ### 陷阱3:忽视多租户隔离 **案例:** 某公司所有客户共享一个数据库。 **结果:** - 一个大客户的批量导入,拖垮所有客户 - 一天流失30个小客户 - 老板差点把CTO开了 **教训:** SaaS必须做租户隔离,大客户独立部署。 ---- ### 陷阱4:没有降级兜底 **案例:** 某公司双11促销,系统崩溃,没有降级方案。 **结果:** - 订单成功率跌到50% - 客户疯狂投诉,品牌受损 - CEO公开道歉 **教训:** 永远准备好降级开关和兜底页面。 ---- ### 陷阱5:数据架构混乱 **案例:** 某公司4条产品线,数据完全不通。 **结果:** - 客户买了3个产品,数据要手动导3次 - 报表口径不一致,客户投诉 - 销售抱怨"卖不动" **教训:** 早期就要规划主数据管理,统一客户/员工/组织数据。 ---- ## 六、给技术管理者的3条硬核建议 ### 建议1:每季度强制做一次"痛点重排" **操作清单:** ``` # 1. 召集技术/产品/运营开会 # 2. 列出当前TOP5痛点 # 3. 用数据证明痛点(不要靠感觉) # 4. 给出权重(加起来100%) # 5. 写进决策文档,公开透明 ``` **我的模板:** 2024年Q2痛点排序: 1. API稳定性: 40%(客户投诉最多) 2. 移动端体验: 25%(竞品压力) 3. 数据导出速度: 20%(大客户需求) 4. 成本优化: 10%(毛利率压力) 5. 新功能交付: 5%(可以延后) 决策: - Q2重点做API治理 + 移动端改版 - 成本优化Q3再做 - 新功能优先级降低 ---- ### 建议2:建立"拉闸指标"文化 **什么是拉闸指标?** - 当某个指标异常时,自动回滚或降级 - 不需要人工决策,系统自动处理 **我的配置:** 拉闸指标: - 错误率 > 1%: 自动回滚到上一版本 - 响应时间P99 > 2秒: 触发降级开关 - 数据库连接数 > 80%: 拒绝新请求 - CPU使用率 > 85%: 自动扩容 - 客户投诉 > 10条/小时: 短信通知CTO ---- ### 建议3:技术债也要有"回收计划" **我的技术债管理表:** |技术债|产生时间|影响|回收计划|负责人| |:-:|:-:|:-:|:-:|:-:| |3个临时降级开关|2023.11|代码冗余|2024.Q2回收|老李| |2套用户权限系统|2023.06|维护成本高|2024.Q3统一|小王| |老版本API未下线|2022.12|服务器成本|2024.Q2关停|小张| **每季度复盘:哪些技术债可以回收了?** ---- ## 七、最后的狠话:别等系统炸了才明白 我花了10年,踩过无数坑,被老板骂过无数次,才明白一个道理: **架构决策的本质,不是选技术,而是排优先级。** - 日订单500的系统,上微服务是找死 - 多租户SaaS不做隔离,迟早被大客户干翻 - 洪峰场景不做降级,等着半夜被叫起来救火 **我的终极建议:** MVP阶段: - 优先级: 交付速度 > 功能覆盖 > 成本 - 技术: 单体应用 + MySQL + Redis - 验收: 2个月上线,月成本<5000元 增长期: - 优先级: 稳定性 > 性能 > 数据一致性 - 技术: 读写分离 + 缓存 + 监控 - 验收: 可用性99.5%,P99<1秒 爆发期: - 优先级: 多租户隔离 > 数据安全 > 弹性扩展 - 技术: 分片 + 配额 + 独立部署 - 验收: 大客户不影响小客户 平台化: - 优先级: 可扩展性 > API治理 > 数据资产 - 技术: 中台 + 统一能力 + 主数据管理 - 验收: 新产品上线时间减半 洪峰场景: - 优先级: 峰值韧性 > 降级可控 > 事件隔离 - 技术: 限流 + 熔断 + 降级 + 兜底 - 验收: 订单成功率>99%,投诉率-50% **记住:架构不是追新,而是把"当下最疼"解决到位。** **当你能主动重排优先级,洪峰就只是一次演练;当你拒绝重排,它就会成为一次事故。** 我是老李,一个被洪峰教育过、被老板骂过、差点被开除但最终活下来的架构师。 希望你少踩坑,多主动重排。 ---- **最后问你3个问题:** 1. 你的系统现在最疼的3个痛点是什么?能用数据证明吗? 2. 你上次调整架构优先级是什么时候? 3. 你准备好洪峰来临时的降级方案了吗? **如果答不上来,建议你现在就开始做"痛点重排"。** 别等到系统炸了,老板骂你的时候,才想起这篇文章。 那时候,已经晚了。
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号