背景
随着技术的发展,Serverless 的技术形态和使用姿势,为用户带来了技术和成本二者兼得的益处。一方面,通过商业化 PaaS 产品的技术实力,设计系统架构。另一方面,计费模式从买固定规格改变为弹性按量付费,使得客户的存储按照实际的使用量进行计费,且存储支持弹性扩容,帮助客户有效提升资源利用率并降低业务成本。
例如,某客户在购买集群时,需要指定最小集群存储 200G,但业务初期,实际使用率不到10%,而后期随着业务的上量,在不改动规格的基础上,又要不断给存储扩容。
故而,消息队列 CKafka 专业版推出弹性存储形态。
技术原理
专业版的弹性存储形态,基于「本地存储 + 远程存储」相结合的方式实现。即采用分级存储方案,本地会有少量的云盘热数据,远程存储有大量的冷数据。
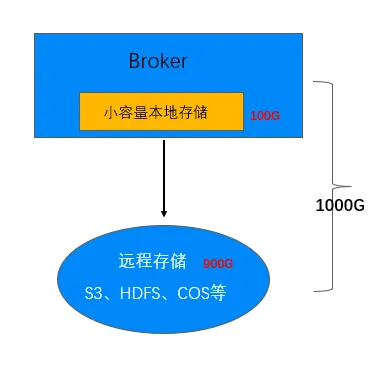
本地存储
本地存储服务写流量/Tail-Read 读,提供与原生 Kafka 一致的延时、可用性和一致性。
远程存储故障或者性能衰退,本地存储支持弹性扩容提供读写服务。
远程存储
远程存储服务 Catch- Up 读,冷热数据分离。
按需使用,按量计费。
未来扩展性良好,支持多模存储,多介质存储。
该技术方案在写入延迟和本地写入延时是一致的,在远程存储出现故障或者毛刺的时候,可以退化为本地存储,再结合自动化运营系统对本地存储形态进行动态扩容。同时,远程的存储相对廉价,可以一定程度上实现降本。
分级存储读写流程
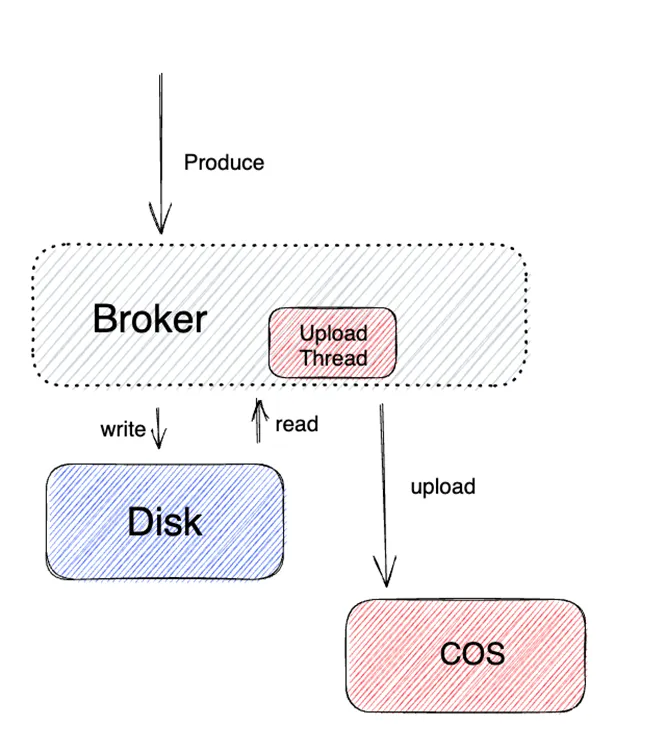
生产流程
生产的主体流程和原生 Kafka 类似,写入到云盘的数据会异步同步到远端存储 COS。
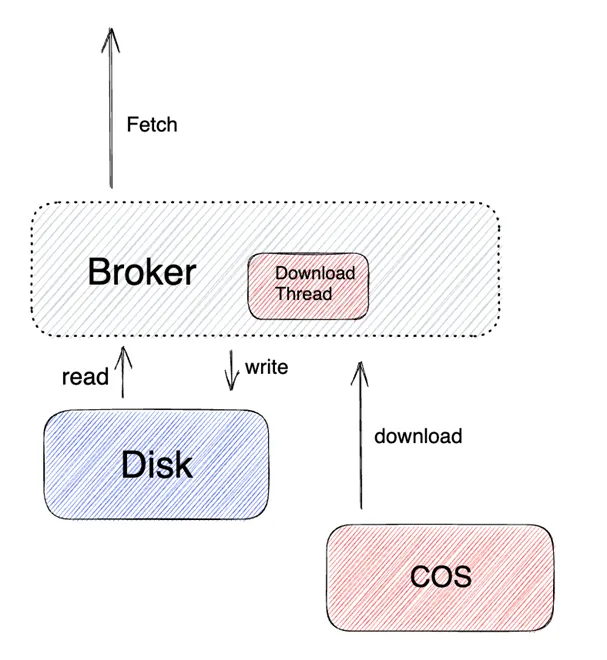
消费流程
消费的流程也是类似的,会根据用户 Consumer 的 Offset 来做一个比较,如果是在本地存储,那么就本地存储优先返回。如果本地存储没有,那就从远端存储里面去实时读取,或者说根据不同的读取策略有不同的读取下载策略,进行消息读取的消费。
功能说明
使用说明
控制台购买集群时:
规格类型,选择专业版;
存储类型,选择弹性存储;
确定其他选项后,发起创建即可。
计费说明
按照消息存储所占用的存储空间大小和存储时长计费。
计费方式,为按量计费(后付费),计量单位为 “XX 元/GB/小时”。
计费粒度,为小时,不足1小时按1小时计算。按1小时内使用的磁盘容量的最大值计费。
观测指标
专业版-弹性存储实例提供了三个指标,便于您观测存储使用情况。
实例级,实例磁盘占用量(MB),指当前实例的存储使用量,包含副本数消耗。
Topic 级,Topic 占用磁盘的消息总量(MB),指当前 Topic 的存储使用量,不包含副本数消耗。
分区级,Partition 占用磁盘的消息总量(MB),指当前 Topic - 分区下的存储使用量,不包含副本数消耗。
使用限制
1. 引擎版本
当前仅在专业版 Kafka 2.8.1 引擎版本下支持弹性存储。
2. 地域
仅在北京、上海、广州、新加坡、中国香港地域下,支持该形态。
3. 开放范围







