基于腾讯云 ES 引擎和生态优势,帮助客户通过更轻量的研发和运维投入,轻松构建 RAG、AI 搜索等应用。本文档将详细说明各原子服务的计费方式和单价策略,遵循按需付费原则,提供预付费资源包与按量计费两种方式,帮助客户根据实际业务场景精细化成本管理。
计费方式 | 说明 |
按量计费 | 按照实际调用接口消耗的资源量进行计费,每小时对腾讯云账户进行结算和扣费,正式使用前请保证账户处于非欠费状态。 |
预付费资源包 | 一次性预付有效期内费用,用于抵扣使用对应原子服务产生的费用,有效期为自购买日后的一年。 |
免费额度
购买方式
在账单结算时,系统将按照“免费体验次数 > 资源包 > 后付费”的顺序进行结算。
计费内容包含直接调用 API 和在控制台使用相关原子服务在线体验,调用失败不计费。
开通后付费
当开通智能搜索开发原子服务后,默认情况下会自动打开后付费,免费体验次数使用完后,若未购买预付费资源包,将会自动转入后付费。如需开启或关闭后付费模式结算,请前往控制台 -> 资源管理 -> 后付费设置 开通或关闭后付费。
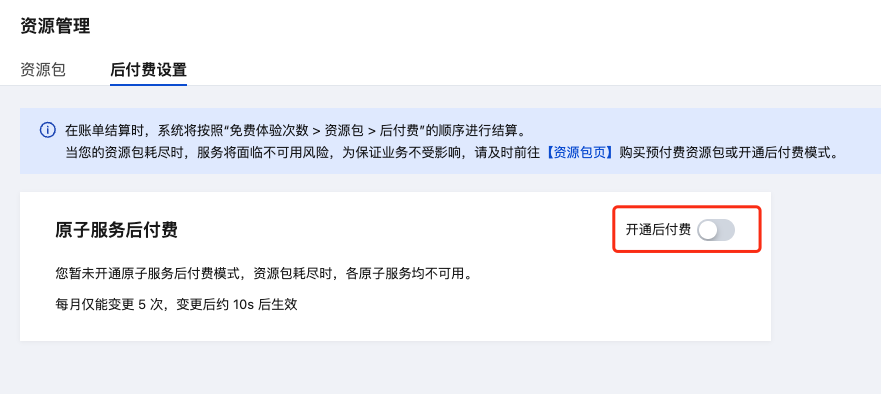
说明:
后付费设置每月仅能变更 5 次,变更后约 10s 后生效,请不要频繁变更。
购买资源包
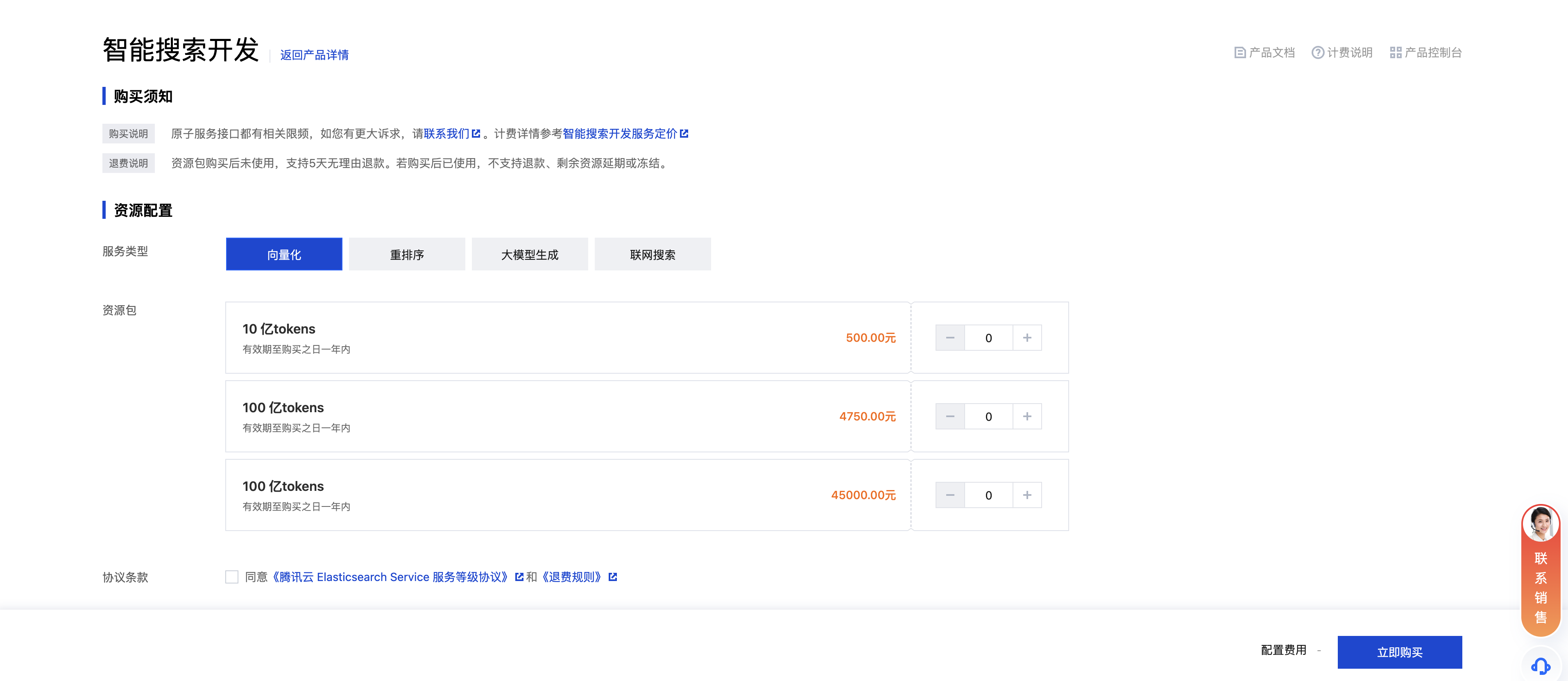
按量计费定价
文档解析(Document Parsing)
文档解析服务按原始文档成功解析的页数计费,单价如下:
服务 | 刊例(元/页) |
doc-llm | 0.2 |
说明:
doc-llm 文档解析服务是按页收费,对不同文档计费规则如下:
doc、docx、ppt、pptx、pdf 按页计量。
jpeg、png等图片格式以一张图为一页。
xlsx、txt、md、csv 以 1 份为一页。
文本切片(Text Chunking)
文本切片服务按千 token 计费,单价如下:
服务 | 刊例(元/千 tokens) |
doc-tree-chunk | 0.03 |
doc-chunk | 0.00002 |
说明:
doc-tree-chunk 服务是基于 doc-llm 文档解析服务实现的文档切片,默认会分为解析和分片的两种费用,具体如下:
输入文件为 pdf/docx/doc/ppt/pptx 文档格式和 jpg/png 等图片格式时,需要计算文档解析费用(按页计费)。
输入文件为 txt/md/xlsx/xls 格式时,仅需工程解析,不需要付费。
两种方式输入的文件都需要计算拆分消耗的费用,按 token 消耗数量计费。
doc-chunk 服务是基于分隔符、文本长度进行切片,适用于规则性较强的文本,这里统计的 token 为原始文本的字符长度。
向量化(Embedding)
纯文本 Embedding 服务按千 token 计费,单价如下:
模型 | 维度 | token 限制 | 语言 | 刊例(元/千 tokens) |
bge-base-zh-v1.5 | 768 | 512 | 中文 | 0.0005 |
KaLM-embedding-multilingual-mini-v1 | 896 | 131072 | 多语言 | 0.0005 |
bge-m3 | 1024 | 8194 | 多语言 | 0.0005 |
Conan-embedding-v1 | 1792 | 512 | 中文 | 0.0005 |
图文 Embedding 服务支持文本和图片两种模态输入,分别以 token 和图片数量计费,单价如下:
模型 | 维度 | token 限制 | 语言 | 刊例 |
WeCLIPv2-Base | 768 | 72 | 多语言,中文最优 | 文本:0.0005 元/千 tokens 图片:0.0003 元/张 |
WeCLIPv2-Large | 768 | 72 | 多语言,中文最优 | 文本:0.0005 元/千 tokens 图片:0.0005 元/张 |
重排序(Rerank)
重排序服务按千 token 计费,单价如下:
模型 | token 限制 | 语言 | 刊例(元/千 tokens) |
bge-reranker-large | 514 | 中文、英文 | 0.0001 |
bge-reranker-v2-m3 | 8194 | 多语言 | 0.0005 |
大模型生成(LLM)
大模型生成服务按千 token 计费,单价如下:
系列 | 模型 | token 限制 | 刊例(元/千 tokens) |
deepseek | deepseek-r1 | 最大输入128k 最大输出8k | 输入:0.004 输出:0.016 |
| deepseek-v3(0324) | 最大输入128k 最大输出8k | 输入:0.002 输出:0.008 |
| deepseek-r1-distill-qwen-32b | 最大输入128k 最大输出8k | 输入:0.002 输出:0.006 |
hunyuan | hunyuan-turbo | 最大输入28k 最大输出4k | 输入:0.0024 输出:0.0096 |
| hunyuan-large | 最大输入28k 最大输出4k | 输入:0.004 输出:0.012 |
| hunyuan-large-longcontext | 最大输入128k 最大输出6k | 输入:0.006 输出:0.018 |
| hunyuan-standard | 最大输入30k 最大输出2k | 输入:0.0008 输出:0.002 |
| hunyuan-standard-256K | 最大输入250k 最大输出6k | 输入:0.0005 输出:0.002 |
联网搜索(Online Search)
联网搜索服务按调用次数计费,可结合大模型进行使用,单价如下:
服务 | 刊例(元/千次) |
sogou | 65 |
bing(暂时关停) | 65 |
baidu(暂时关停) | 65 |
说明:
推荐您使用 sogou 服务,提供稳定的联网搜索服务,bing 和 baidu 服务由三方服务厂商提供,受限于三方服务,有关停风险,请酌情使用。
资源包定价
资源类型维度的定价
资源类型 | 资源包规格 | 刊例价 |
文档解析 | 1千页 | 200 |
| 1万页 | 1700 |
| 10万页 | 9800 |
| 100万页 | 75000 |
文本切片 | 1千万 tokens | 300 |
| 1亿 tokens | 2850 |
| 10亿 tokens | 27000 |
文本向量化 | 10亿 tokens | 500 |
| 100亿 tokens | 4750 |
| 1000亿 tokens | 45000 |
图片向量化 | 100万张 | 500 |
| 1000万张 | 4750 |
| 1亿张 | 45000 |
重排序 | 10亿 tokens | 500 |
| 100亿 tokens | 4750 |
| 1000亿 tokens | 45000 |
大模型生成 | 1万点 | 100 |
| 10万点 | 950 |
| 100万点 | 9000 |
| 1000万点 | 85000 |
联网搜索 | 1万次 | 650 |
| 10万次 | 6200 |
| 100万次 | 58500 |
抵扣系数
各个模型的抵扣系数不同,实际资源包的消耗根据抵扣系数进行换算,换算公式:资源包用量 = 实际用量 * 抵扣系数。
计费计算示例:
1. 客户甲用了 bge-reranker-large 1百万token,用了 bge-reranker-v2-m3 2百万token,那么换算下来抵扣的资源包:1百万 * 0.2 + 2百万 * 1 = 2.2百万token。
2. 客户乙在用了deepseek-r1 输入1百万token、输出2百万token,同时用了 hunyuan-turbo 输入3百万、输出4百万,那么换算下来抵扣的资源包:1百万 * 0.4 + 2百万 * 1.6 + 3百万 * 0.24 + 4百万 * 0.96 = 8160 点(注意:点横向对标token的单位为千token)
以下是各个资源类型的抵扣系数:
资源类型 | 模型服务 | 抵扣系数 |
文档解析 | doc-llm | 1 |
文本切片 | doc-tree-chunk | 1 |
| doc-chunk | 0.00066667 |
文本向量化 | bge-base-zh-v1.5 | 1 |
| KaLM-embedding-multilingual-mini-v1 | 1 |
| bge-m3 | 1 |
| conan-embedding-v1 | 1 |
图片向量化 | WeCLIPv2-Base | 0.6 |
| WeCLIPv2-Large | 1 |
重排序 | bge-reranker-large | 0.2 |
| bge-reranker-v2-m3 | 1 |
大模型生成 | deepseek-r1 | 输入:0.4,输出:1.6 |
| deepseek-v3 | 输入:0.2,输出:0.8 |
| deepseek-r1-distill-qwen-32b | 输入:0.2,输出:0.6 |
| hunyuan-turbo | 输入:0.24,输出:0.96 |
| hunyuan-large | 输入:0.4,输出:1.2 |
| hunyuan-large-longcontext | 输入:0.6,输出:1.8 |
| hunyuan-standard | 输入:0.08,输出:0.2 |
| hunyuan-standard-256K | 输入:0.05,输出:0.2 |
联网搜索 | sogou | 1 |
| bing(关停) | 1 |
| baidu(关停) | 1 |
抵扣系数说明:
抵扣系数是一种用于统一不同模型服务计费标准的换算比率。以向量化服务为例:当您不确定哪个 Embedding 模型最适合业务需求时,可以直接购买通用的"向量化资源包"。该资源包支持所有 Embedding 模型,系统会根据实际调用模型的抵扣系数(例如:模型A的1次调用 = 1.2 个资源单位,模型B 的 1 次调用 = 0.8 个资源单位)自动折算消耗的资源量。这种设计既避免了前期选型困难,又能确保资源的高效利用。



