Cloud Studio 已内置 DeepSeek-R1 1.5B、7B、14B、32B 模型,并支持一键部署。
一、创建路径及规格说明
1. 进入 Cloud Studio,在空间模板下单击 DeepSeek-R1 模板。
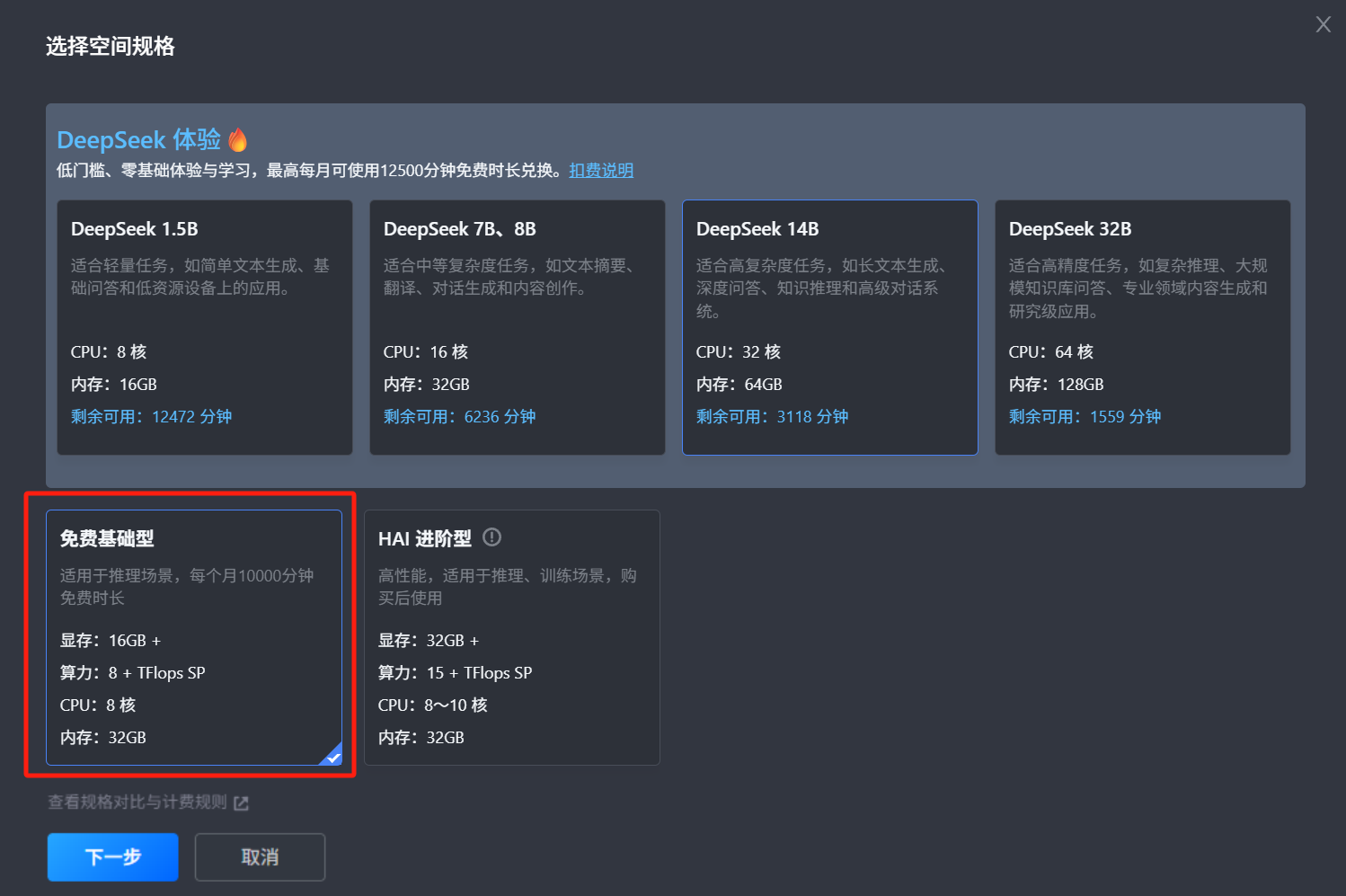
2. 根据需求选择不同规格(DeepSeek 体验、免费基础型、HAI 进阶型)来创建。
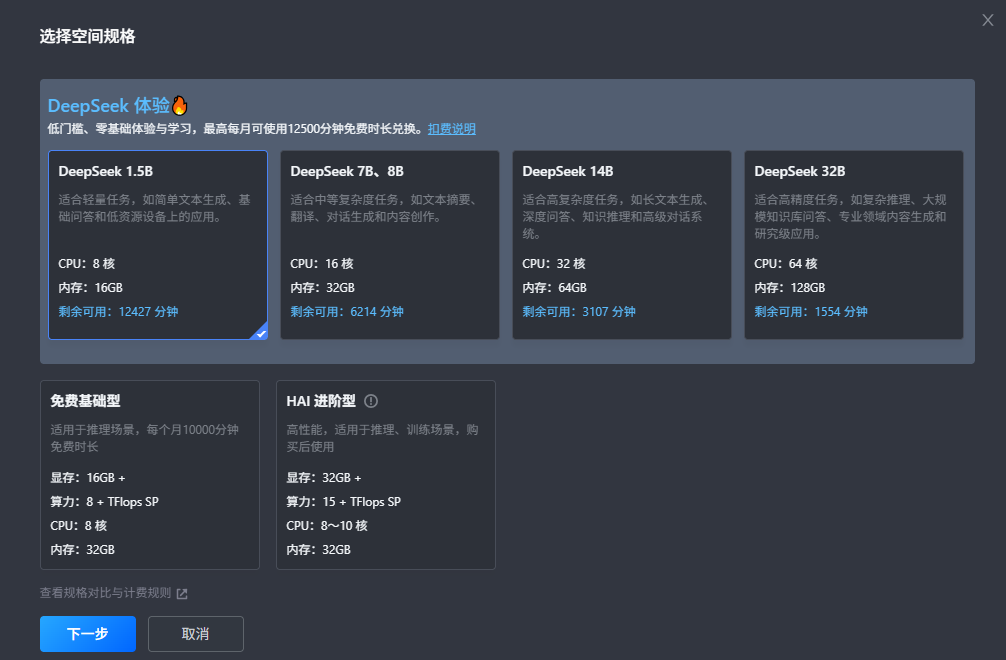
规格对比如下:
名称 | DeepSeek 体验 | 免费基础型 | HAI 进阶型 |
预置环境 | 预装 Ollama。不同规格分别预置DeepSeek 1.5B、7B、8B、14B、32B模型。 Anything-Ollama Open WebUI | 预装 Ollama、DeepSeek-R1 7B、14B、32B 模型。 支持 Open WebUI。 | |
规格 | CPU:8~64核不等 内存:16~128GB不等 | 显存:16GB + 算力:8 + TFlops SP CPU:8 核 内存:32GB | 显存:32GB + 算力:15 + TFlops SP CPU:8~10 核 内存:32GB |
适用场景 | 适用于体验 DeepSeek 蒸馏模型推理。打开即可访问可视化对话界面,上手成本低。 | 16G显存,可用于体验 DeepSeek 7B,最大可到32B但推理速度较慢。 | 32G显存,可用于体验Deepseek 14B、32B。支持模型部署。 |
使用费用 | 默认使用每月10000分钟高性能工作空间免费时长,与通用工作空间免费时长分别计算互不影响。暂不支持付费增加时长。 | ||
说明:
免费基础型资源有限且为动态库存,如出现库存不足提示,可稍后重试或选用其他规格。
二、使用通用工作空间(DeepSeek 体验)进行对话与部署
DeepSeek 体验规格为轻量型,已为您预装并启动了以下服务:
Ollama 服务:支持通过 API 调用 DeepSeek 模型。
Anything-LLM 前端服务:提供交互式聊天界面。
预装模型:
DeepSeek-R1-Distill-Qwen-1.5B:适合轻量级任务,如简单文本生成、基础问答和低资源设备上的应用。
DeepSeek-R1-Distill-Qwen-7B:适合中等复杂度任务,如文本摘要、翻译、对话生成和内容创作。
DeepSeek-R1-Distill-Llama-8B:与7B类似,性能略有提升,适合更复杂的文本生成和理解任务。
DeepSeek-R1-Distill-Qwen-14B:适合高复杂度任务,如长文本生成、深度问答、知识推理和高级对话系统。
DeepSeek-R1-Distill-Qwen-32B:适合高精度任务,如复杂推理、大规模知识库问答、专业领域内容生成和研究级应用。
在 DeepSeek 体验规格中选择其中一种,单击下一步,然后进行相关使用。
使用方法1:通过 Anything LLM 快速体验
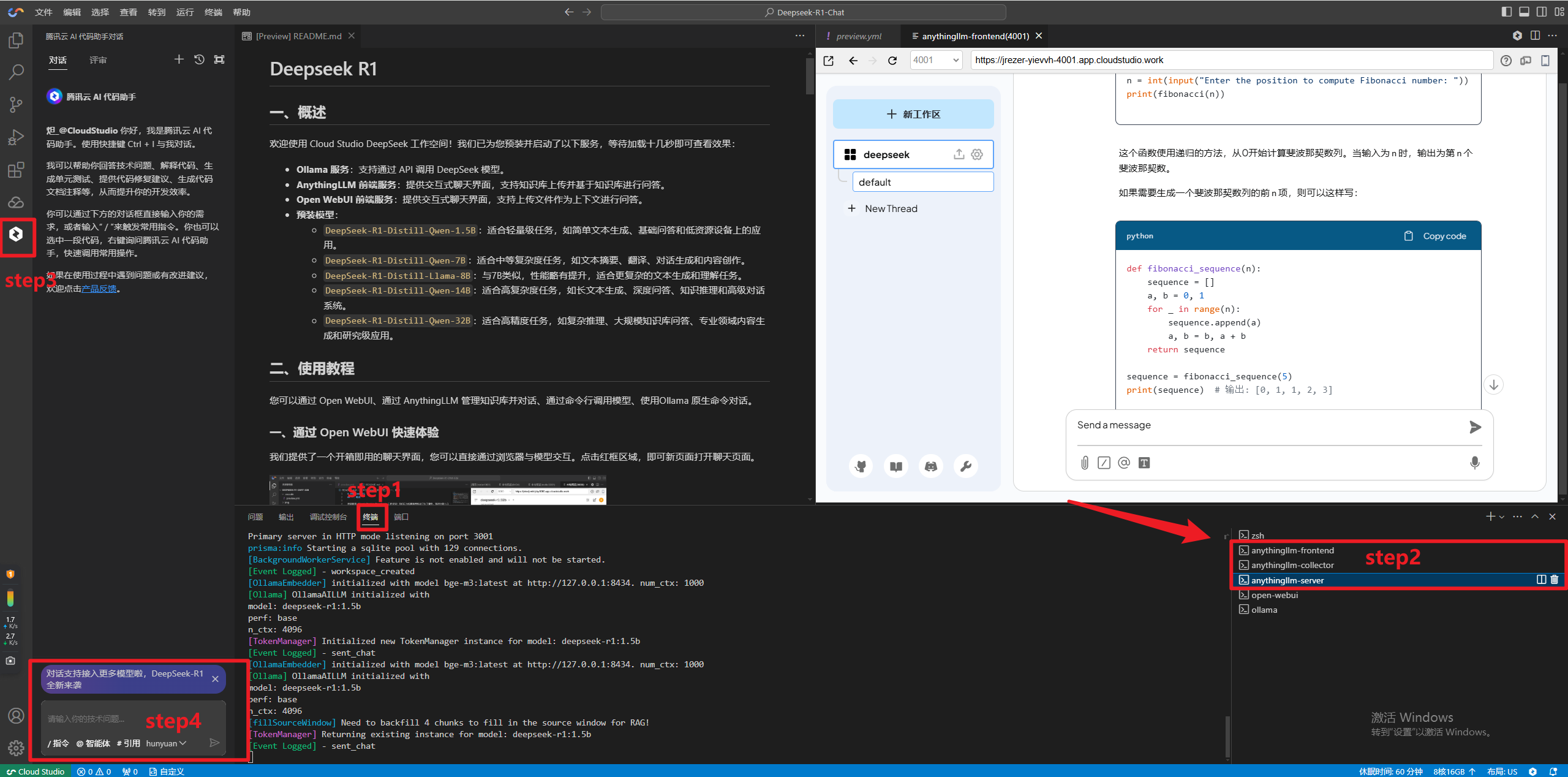
我们提供了一个开箱即用的聊天界面,您可以直接通过浏览器与模型交互。等待页面加载完成即可查看到下图中的界面。单击红框区域,即可新页面打开聊天页面。
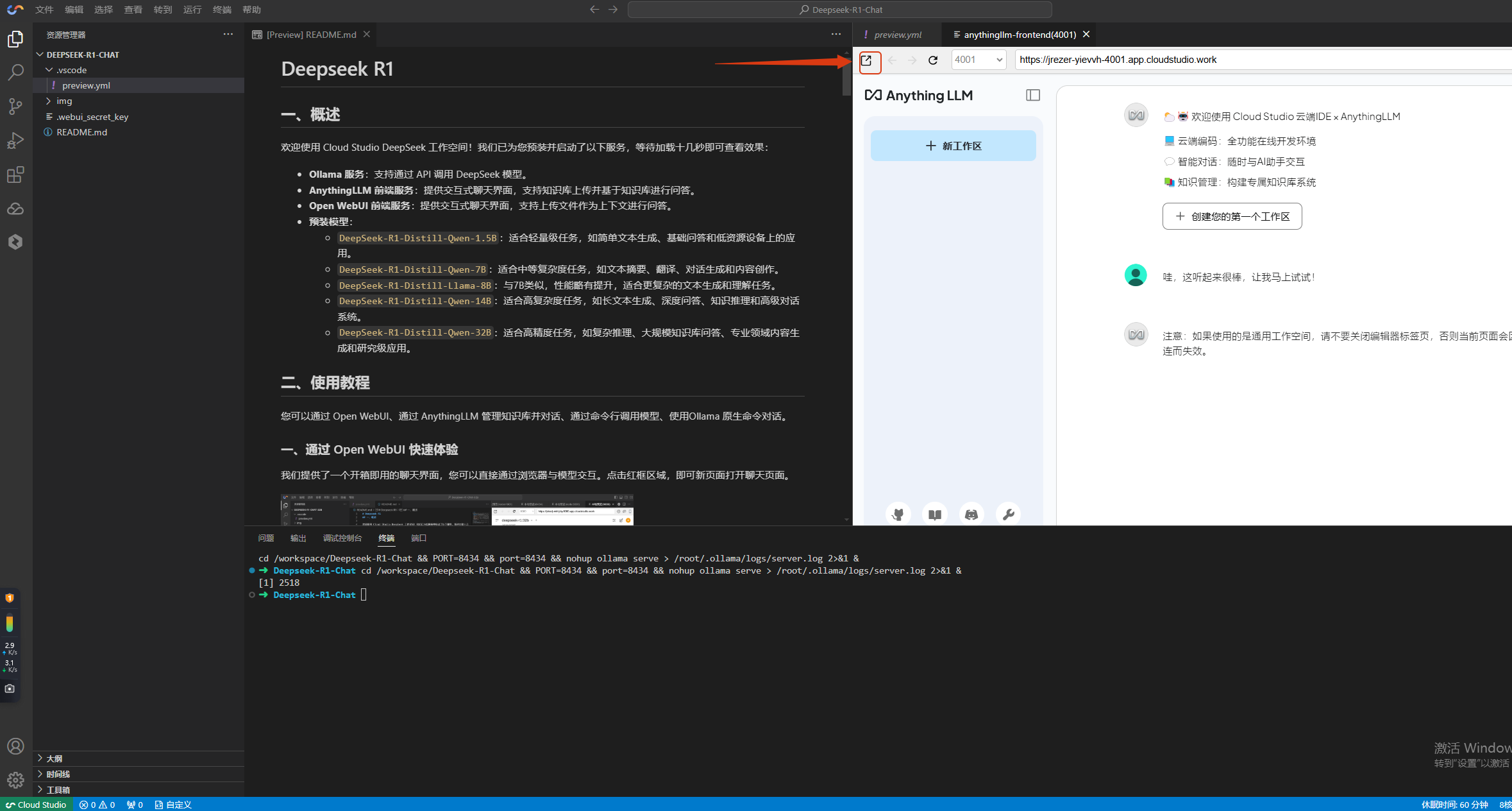
您也可以点开您的工作空间。如果您的浏览器地址是:
XXXXXX.app.cloudstudio.work/,可以在中间修改对应 服务端口(Anything LLM: 4001、Open WebUI: 8080)访问,如:https://XXXXXX-4001.app.cloudstudio.work/。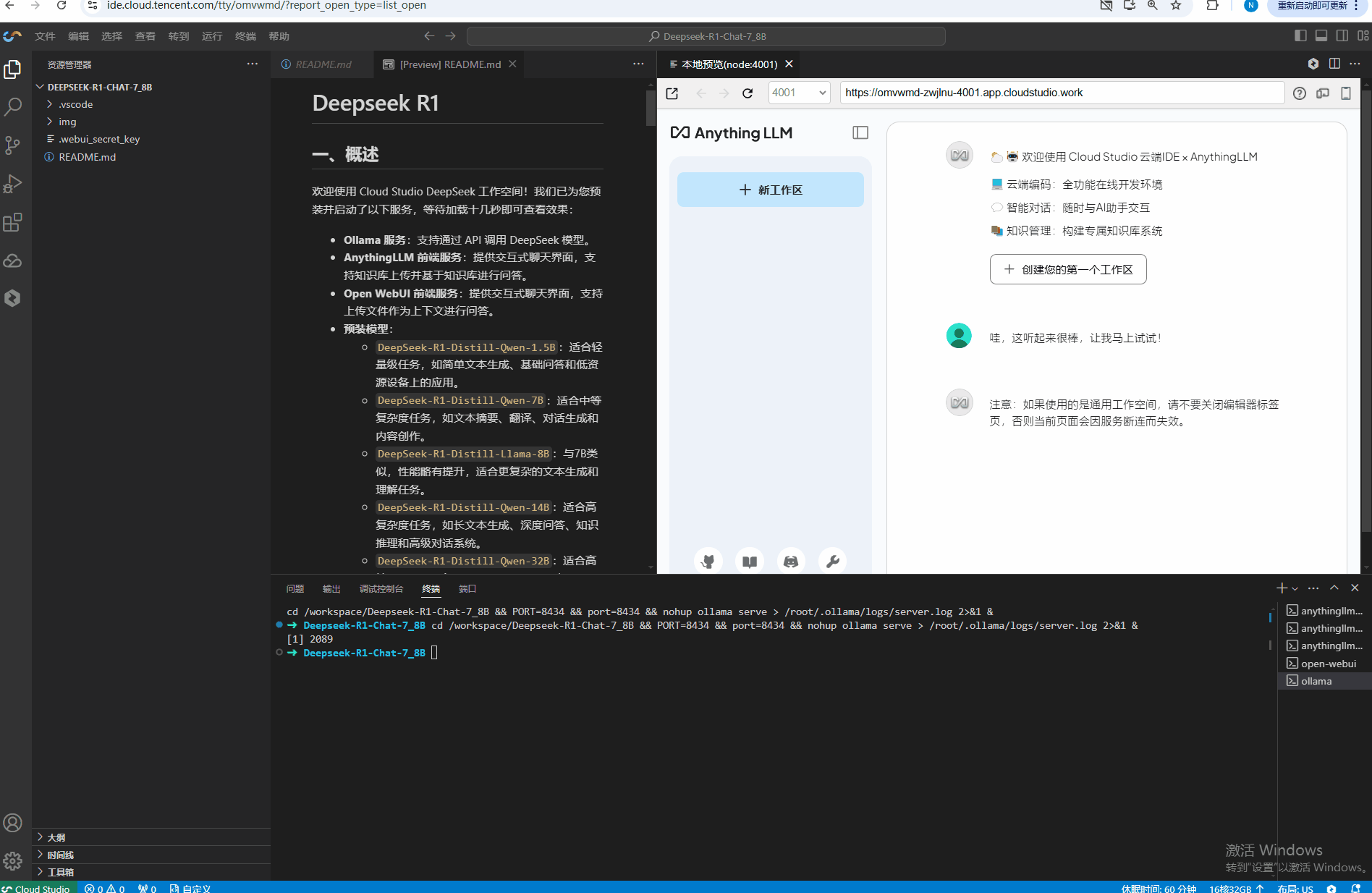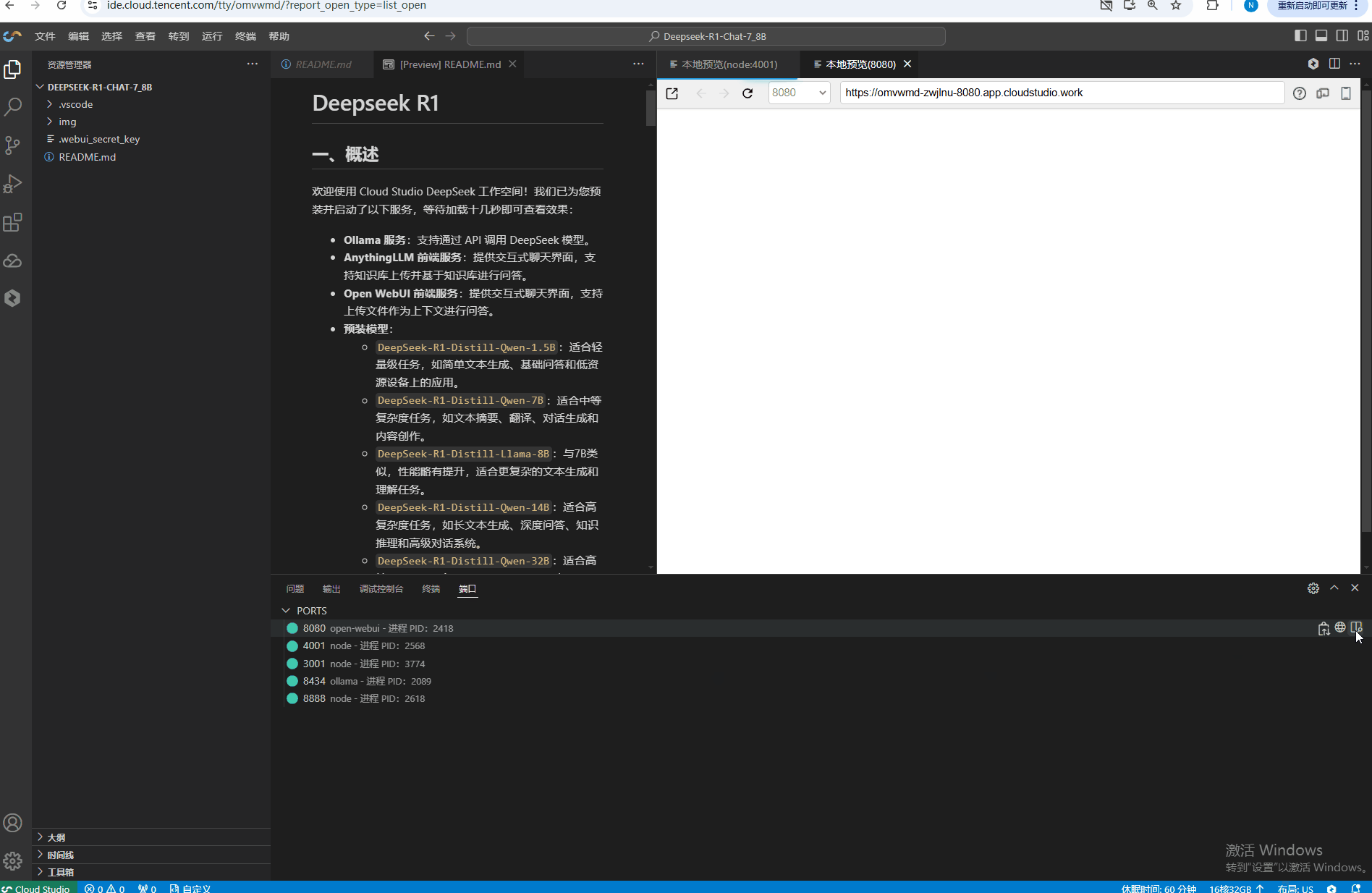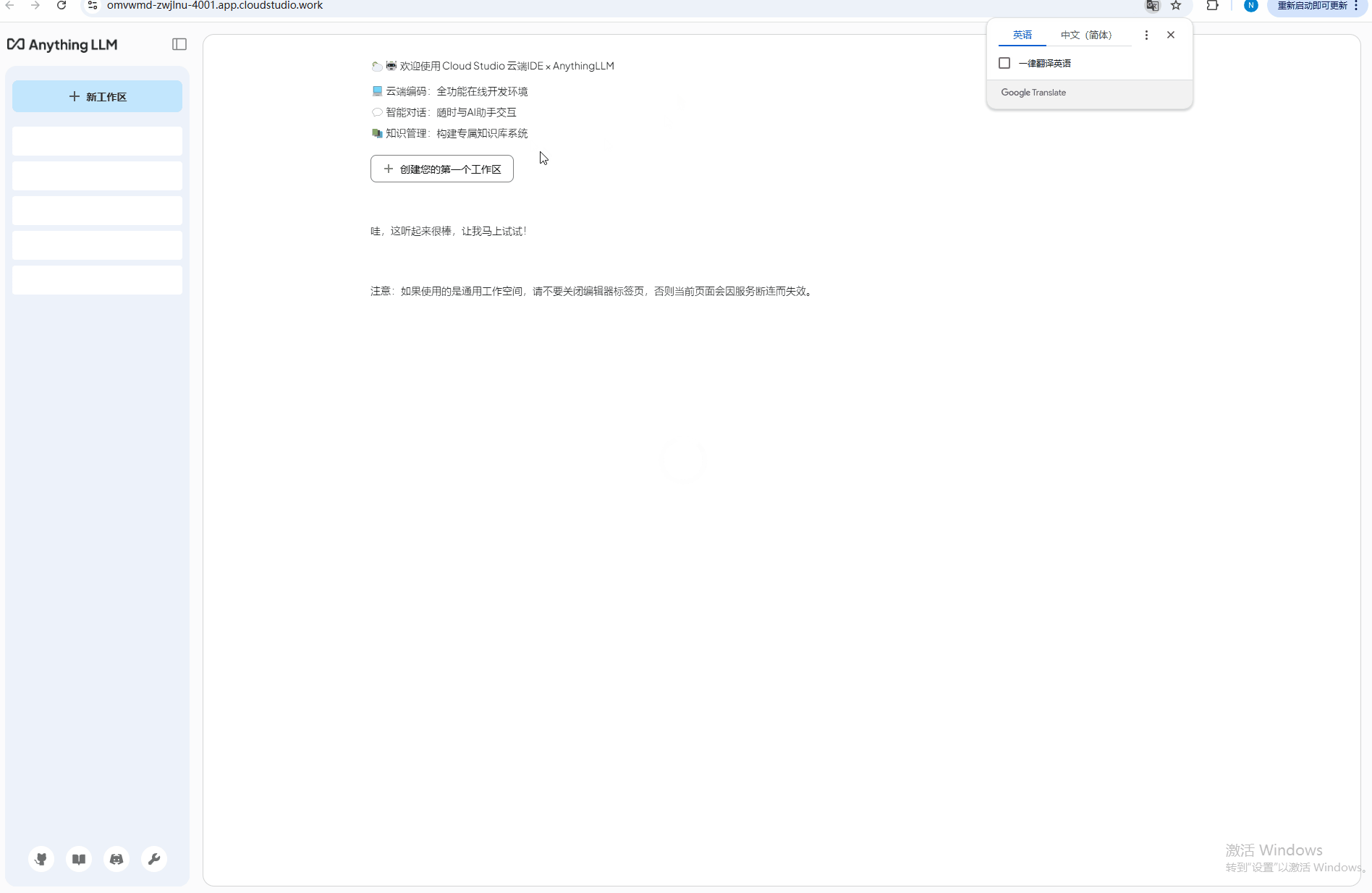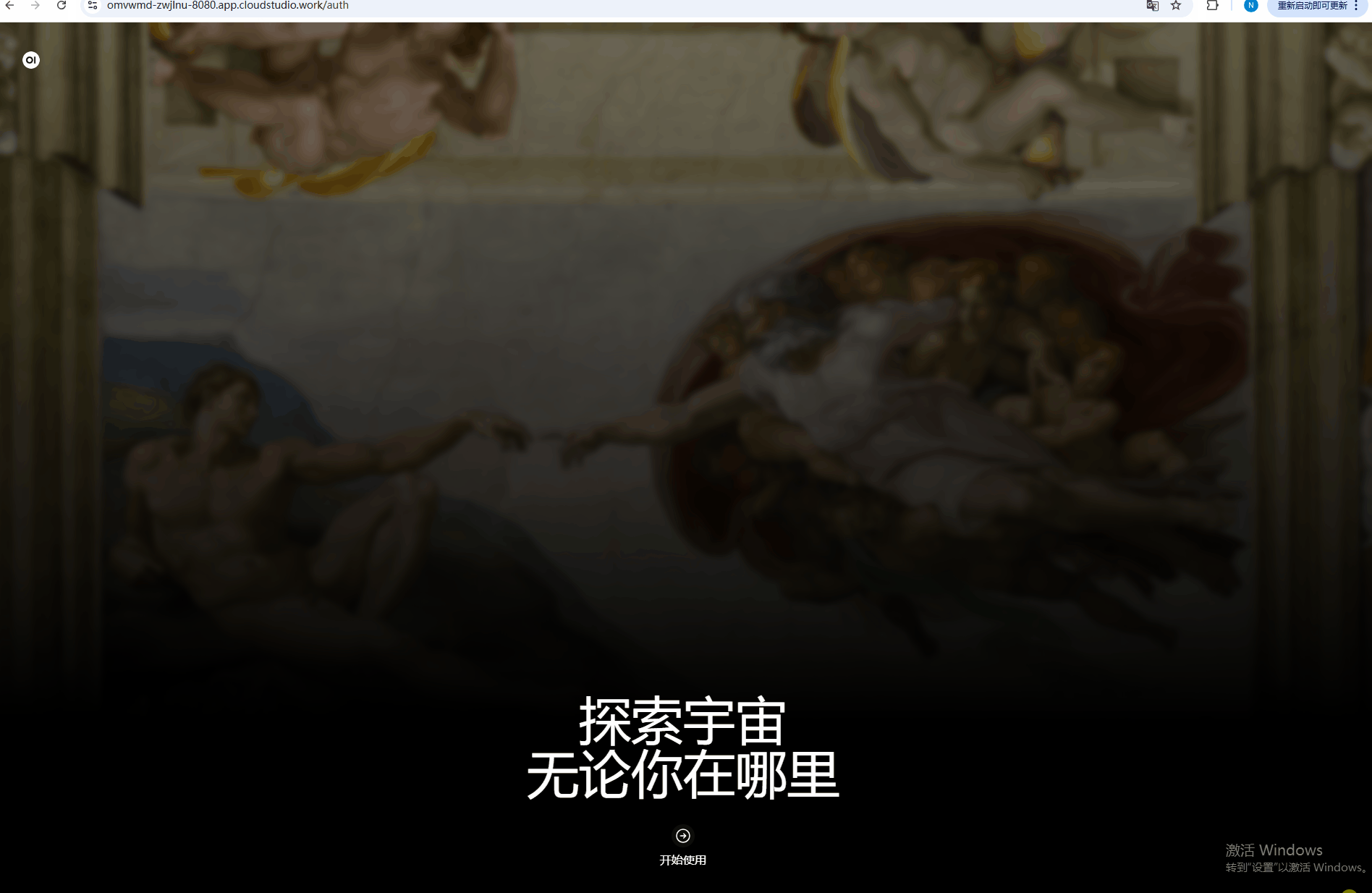
操作步骤
1. 访问 Anything LLM
当前环境已配置为默认启动该服务,可直接访问。如果希望修改启动命令,可以前往
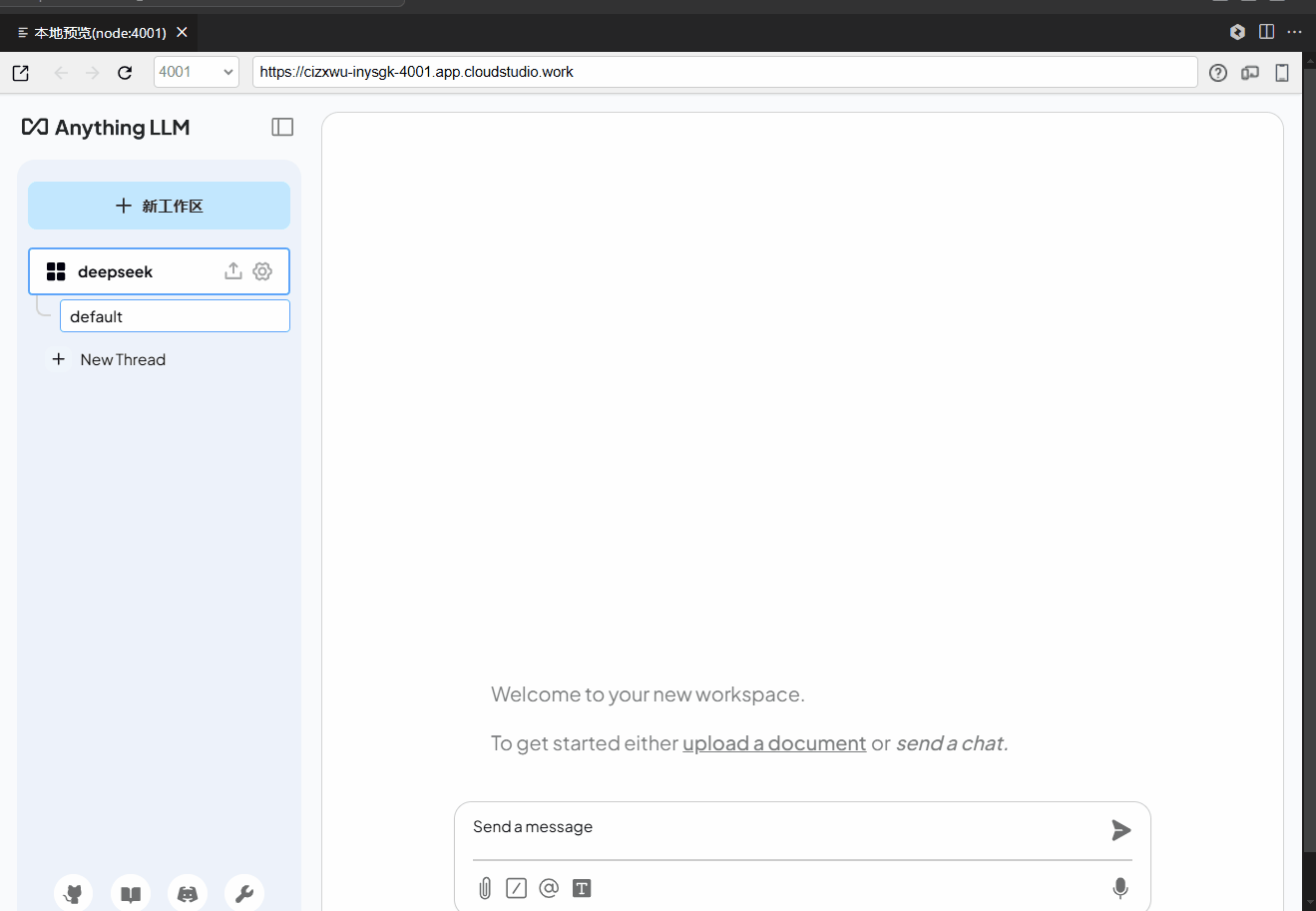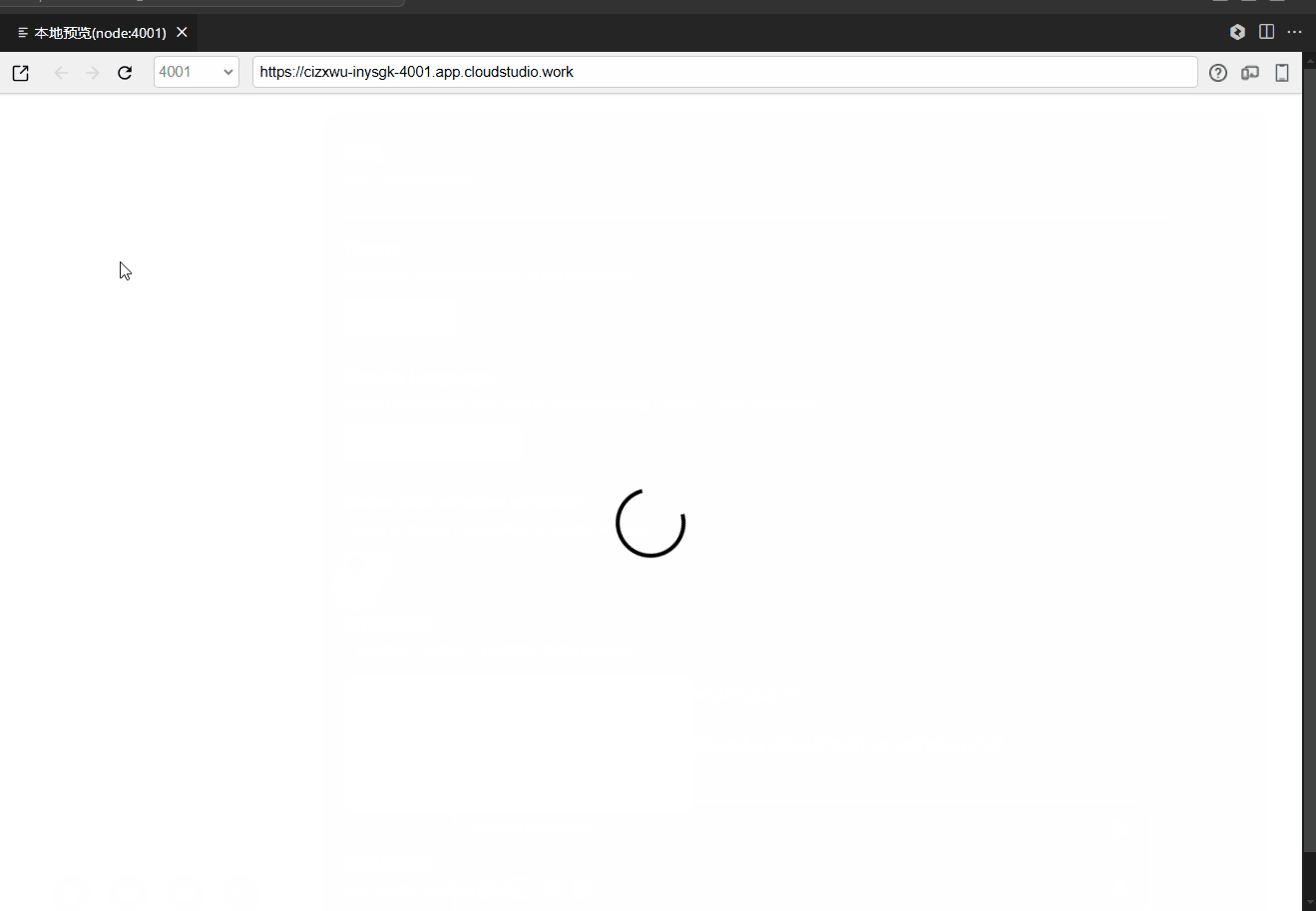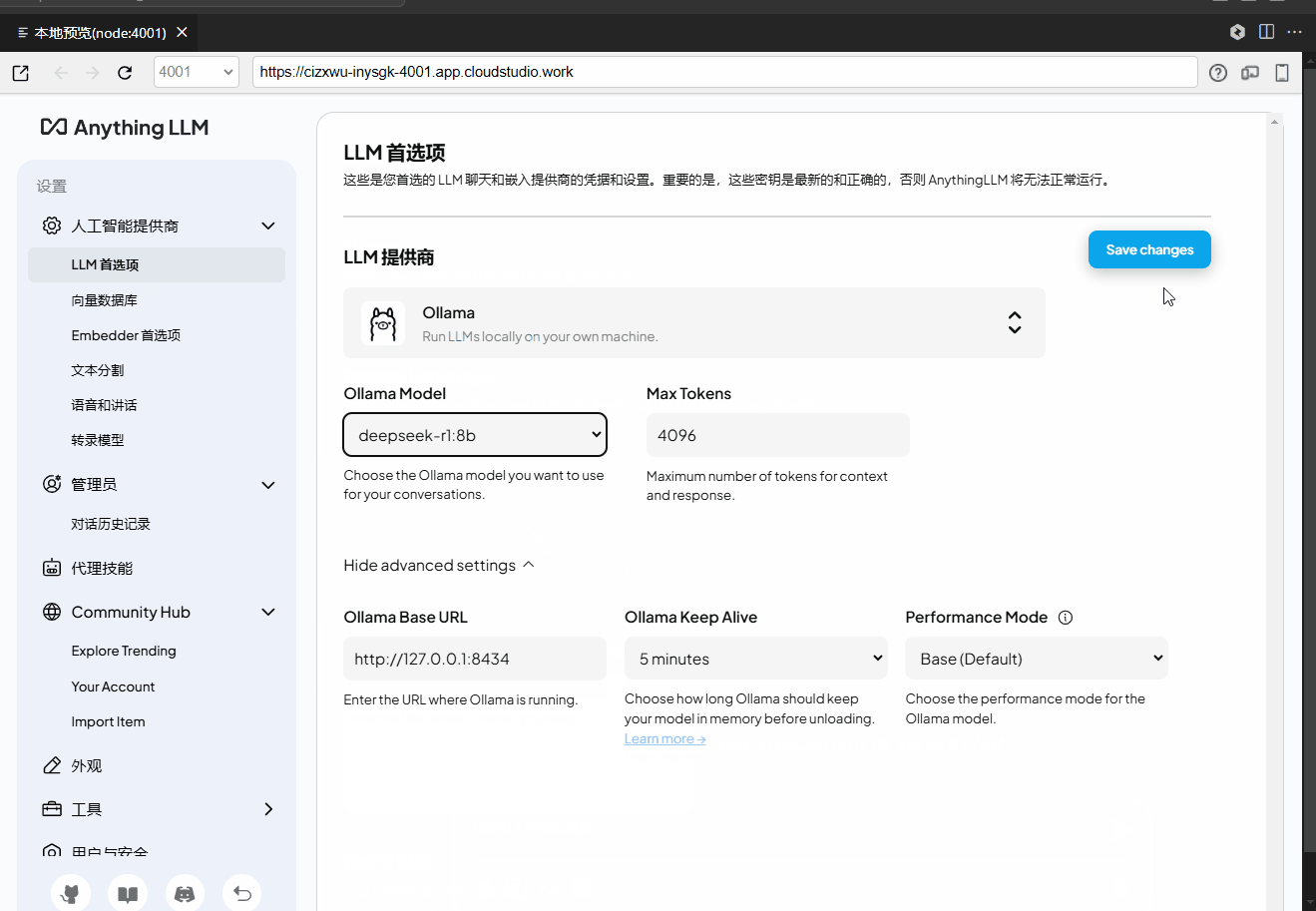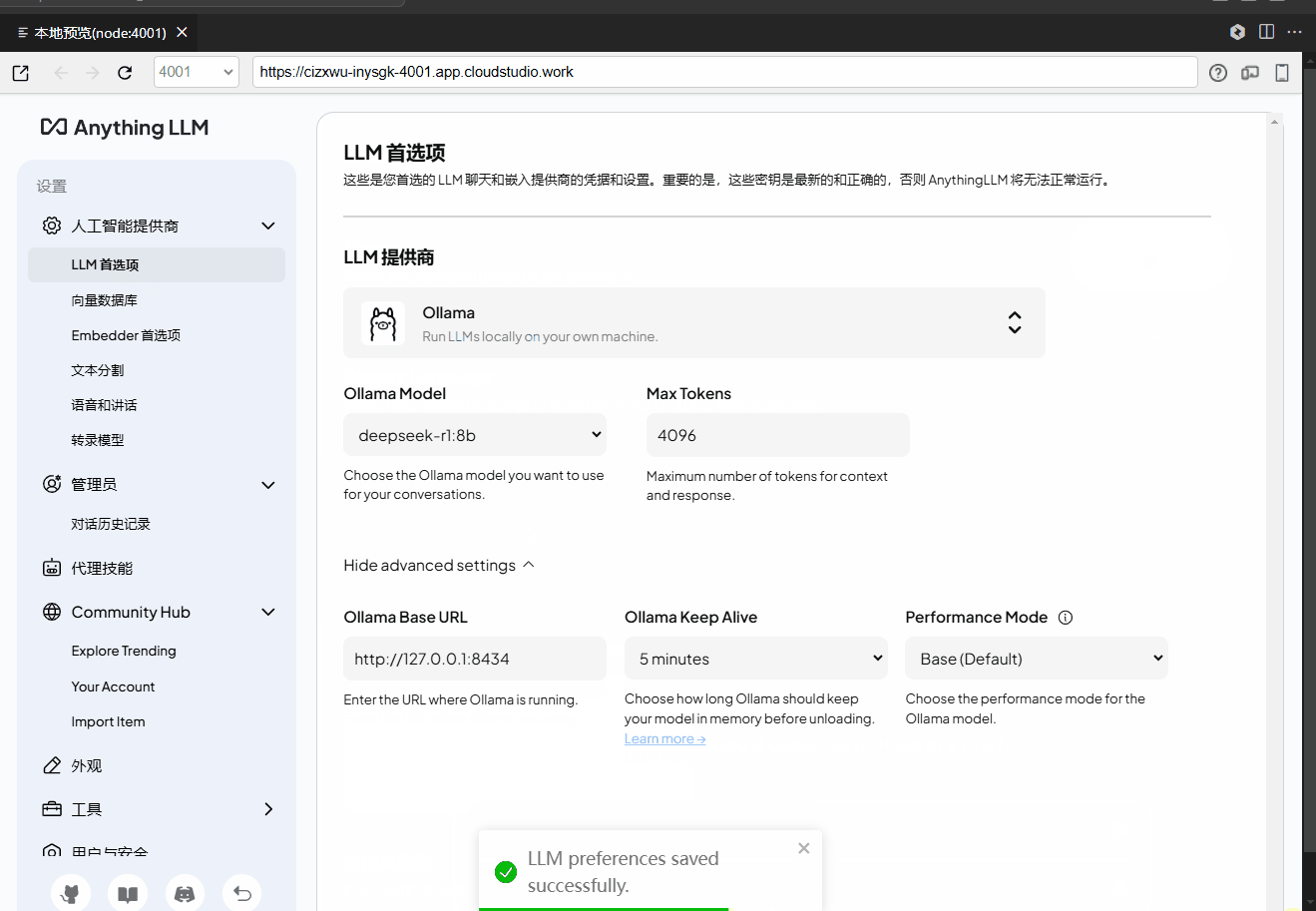
.vscode/preview.yml修改。2. 选择模型
在界面左下角的设置中,单击LLM 首选项,切换 DeepSeek-R1 模型版本。
说明:
Ollama 服务商的端口号是8434。
3. 开始对话
输入问题或指令,单击发送即可获取模型回复。
4. 在其他设备打开
您可以复制链接地址后在其他设备打开。也可 hover 下方红框处并扫码,即可在移动端打开。
示例:生成代码
输入:
用 Python 实现一个斐波那契数列生成函数。
预期输出:
def fibonacci(n):a, b = 0, 1result = []for _ in range(n):result.append(a)a, b = b, a + breturn result
如果遇到网页展示有问题,可返回编辑器终端,查看报错信息并询问 AI 代码助手。
使用方法2:通过命令行调用模型
您可以使用
curl 直接与 Ollama 服务(端口号 8434)交互,适用于自动化任务或脚本调用。 基础请求示例
调用 deepseek-r1:1.5B
curl -X POST http://localhost:8434/api/generate \\-H "Content-Type: application/json" \\-d '{"model": "deepseek-r1:1.5b","prompt": "用一句话解释量子计算","stream": false}'
调用 deepseek-r1:7B
curl -X POST http://localhost:8434/api/generate \\-H "Content-Type: application/json" \\-d '{"model": "deepseek-r1:7b","prompt": "写一篇关于可再生能源的短文(200字)","stream": false}'
流式输出(实时逐句返回)
将
stream 参数设为 true: curl -X POST http://localhost:8434/api/generate \\-H "Content-Type: application/json" \\-d '{"model": "deepseek-r1:7b","prompt": "详细说明如何训练一个神经网络","stream": true}'
使用方法3:Ollama 原生命令使用
除了 HTTP API,您还可以直接通过
Ollama 命令行工具与模型交互。 1. 查看已安装模型
输入如下:
ollama list
输出示例:
NAME ID SIZE MODIFIEDdeepseek-r1:1.5b a42b25d8c10a 1.1 GB 5 days agodeepseek-r1:7b 0a8c26691023 4.7 GB 5 days agodeepseek-r1:8b 28f8fd6cdc67 4.9 GB 5 days ago
2. 启动交互式对话
启动输入如下:
ollama run deepseek-r1:1.5b
输入
/bye或者 Ctrl + D 退出对话。 示例对话流程:
>>> 推荐一个适合初学者的机器学习项目DeepSeek: 一个手写数字识别系统是一个不错的入门项目,可以使用MNIST数据集和Python的scikit-learn库快速实现...>>> 如何评估模型性能?DeepSeek: 常用方法包括划分训练集/测试集、交叉验证、计算准确率/精确率/召回率等指标...>>> /bye
3. 模型管理
命令 | 说明 |
ollama pull deepseek-r1:7b | 重新拉取模型(更新时使用) |
ollama rm deepseek-r1:7b | 删除模型 |
4. 切换模型
如需切换到 7B 模型,可在退出当前进程后再次输入以下代码即可:
ollama run deepseek-r1:7b
注意:
当前机器为 CPU,模型推理速度较慢,建议使用1.5B模型。更大参数模型建议使用 HAI 进阶型。
三、使用高性能空间(免费基础型)进行对话与部署
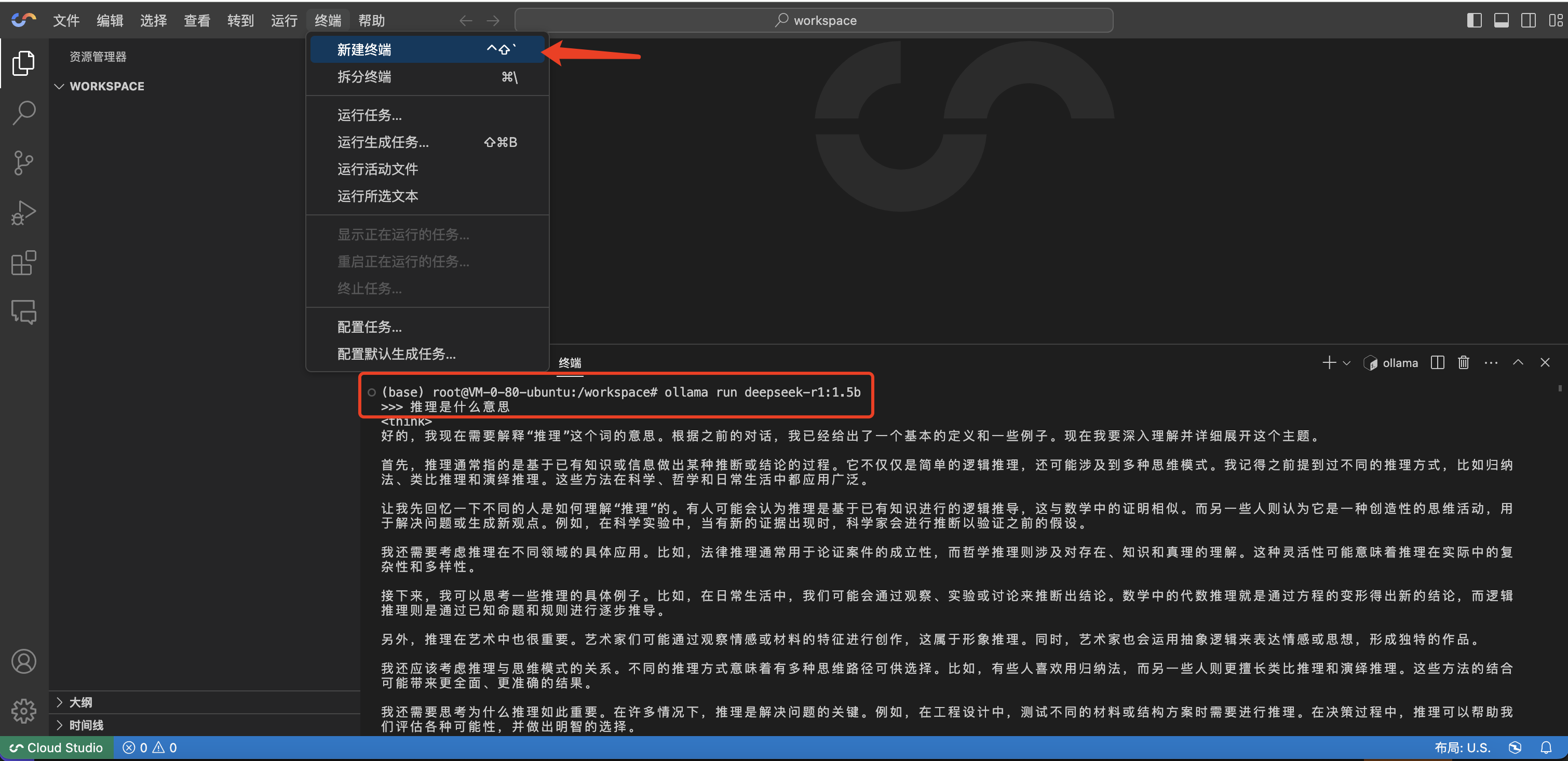
选择免费基础型,单击下一步来进行相关使用。
高性能工作空间开机自启动 Ollama 服务,可单击终端 > 新建终端。
1.查看模型列表
输入以下命令查看已下载的模型并启动:
ollama list # 查看当前已经下载的模型,当前工作空间已预装 DeepSeek-R1 1.5B、7B、8B、14B、32B 五种模型。ollama run [NAME] # 运行想要启动的模型,NAME是模型的名称,如 ollama run deepseek-r1:32b。
可查看到当前已经有的模型列表
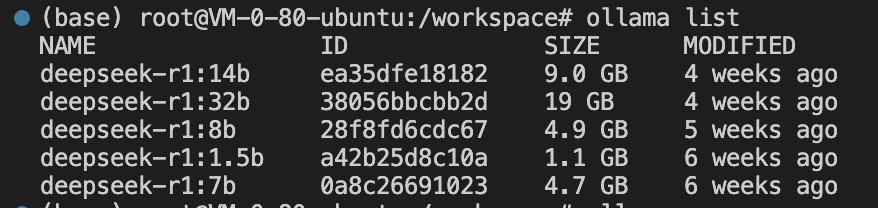
2. 访问 AnythingLLM 或 Open WebUI 页面
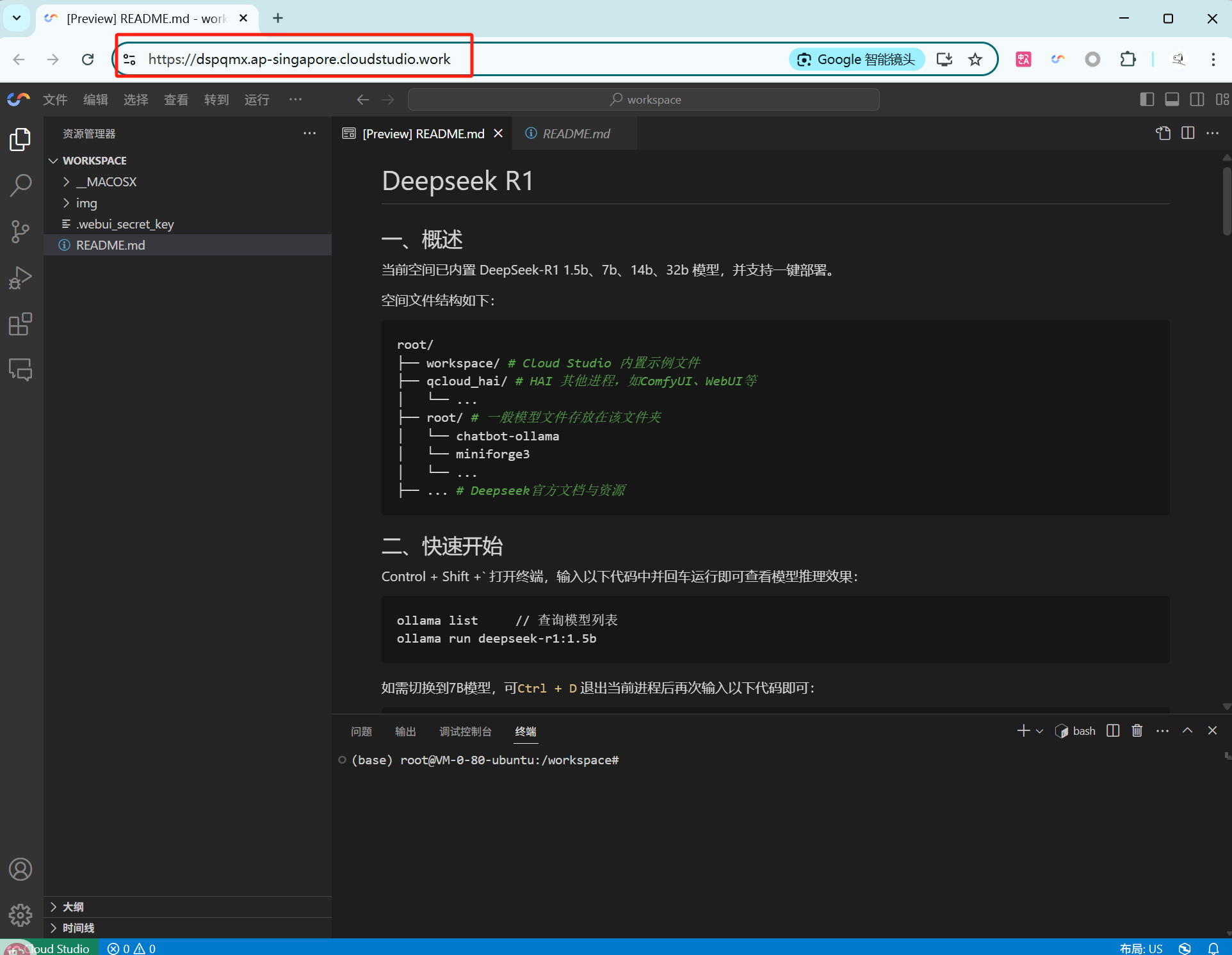
1. 保存打开的工作空间地址,例如:
https://dspqmx.ap-singapore.cloudstudio.work/。免费基础型空间的链接具有特定格式,因此当我们打开工作空间时,地址格式如下:
# 如上述例子所示,即${spaceKey}=dspqmx、${region}=ap-singaporehttps://${spaceKey}.${region}.cloudstudio.work
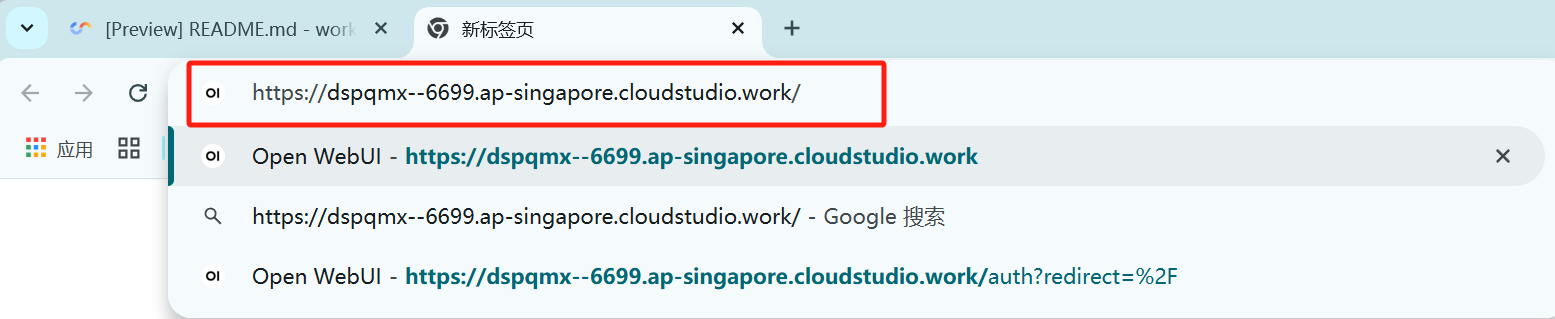
2. 拼接所需的端口号,回车即可前往模板页面。例如,这里打开 Open WebUI 的端口号是 6699,则链接为
https://dspqmx--6699.ap-singapore.cloudstudio.work/。由于免费基础空间的链接拼接具有特定规则,因此在跳转到端口页面时,地址格式如下:
# 如上述例子所示,即${spaceKey}=dspqmx、${port}=6699、${region}=ap-singaporehttps://${spaceKey}--${port}.${region}.cloudstudio.work
说明:
当前模板的端口号如下:
ollama —— 6399AnythingLLM 预览页面 —— 6889Open WebUI 预览页面 —— 6699
3. 设置 Ollama 模型
AnythingLLM
需要进入 LLM 首选项,LLM 供应商选择 Ollama,Ollama Base URL 输入
https://${spaceKey}--6399.${region}.cloudstudio.work后,即可在 Ollama Model 选择想要使用的模型。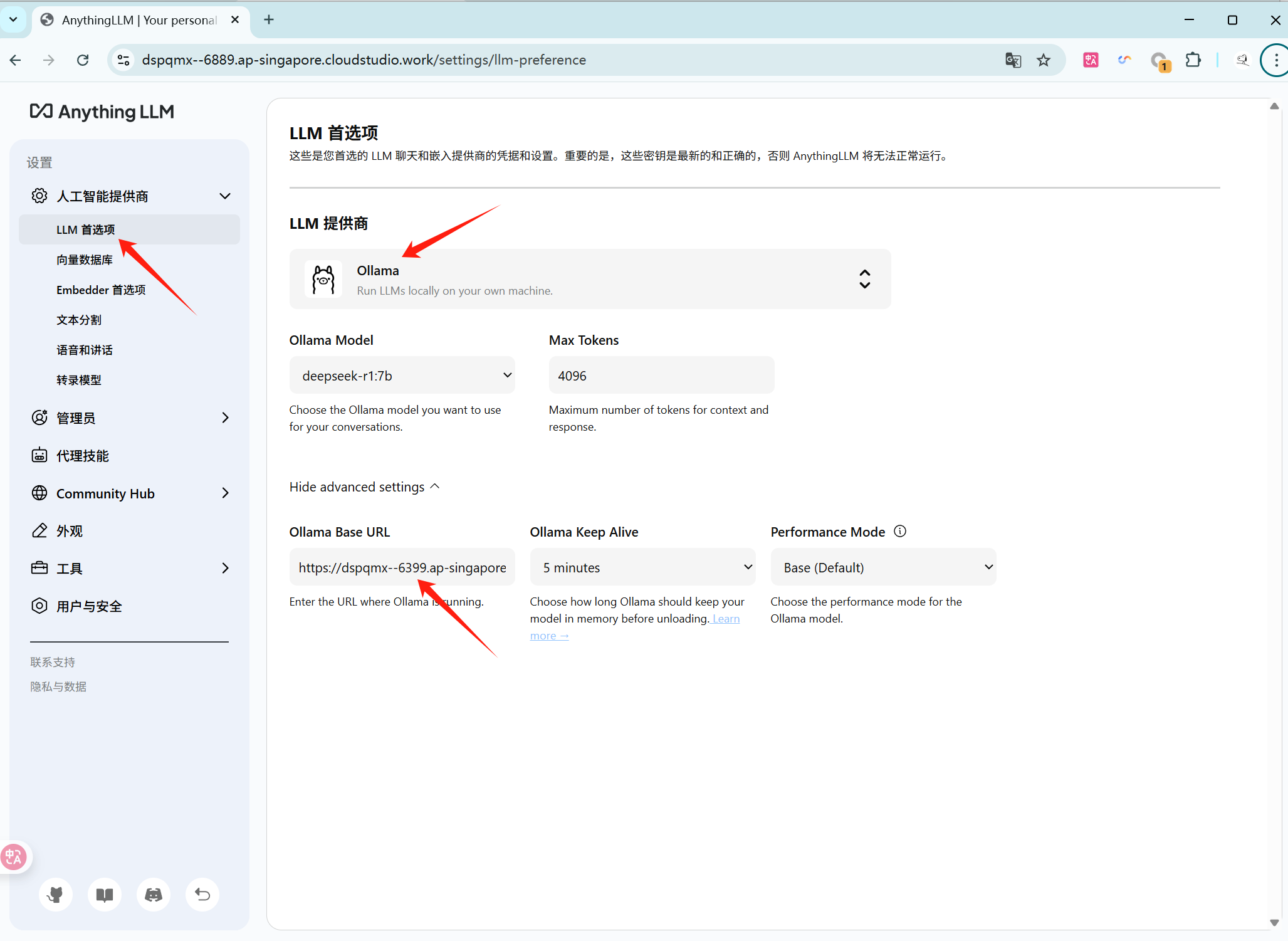
Open WebUI
需要进入 Settings,选择 Connections,在 Manage Ollama API Connections 输入
https://${spaceKey}--6399.${region}.cloudstudio.work后,即可在对话页选择想要使用的模型。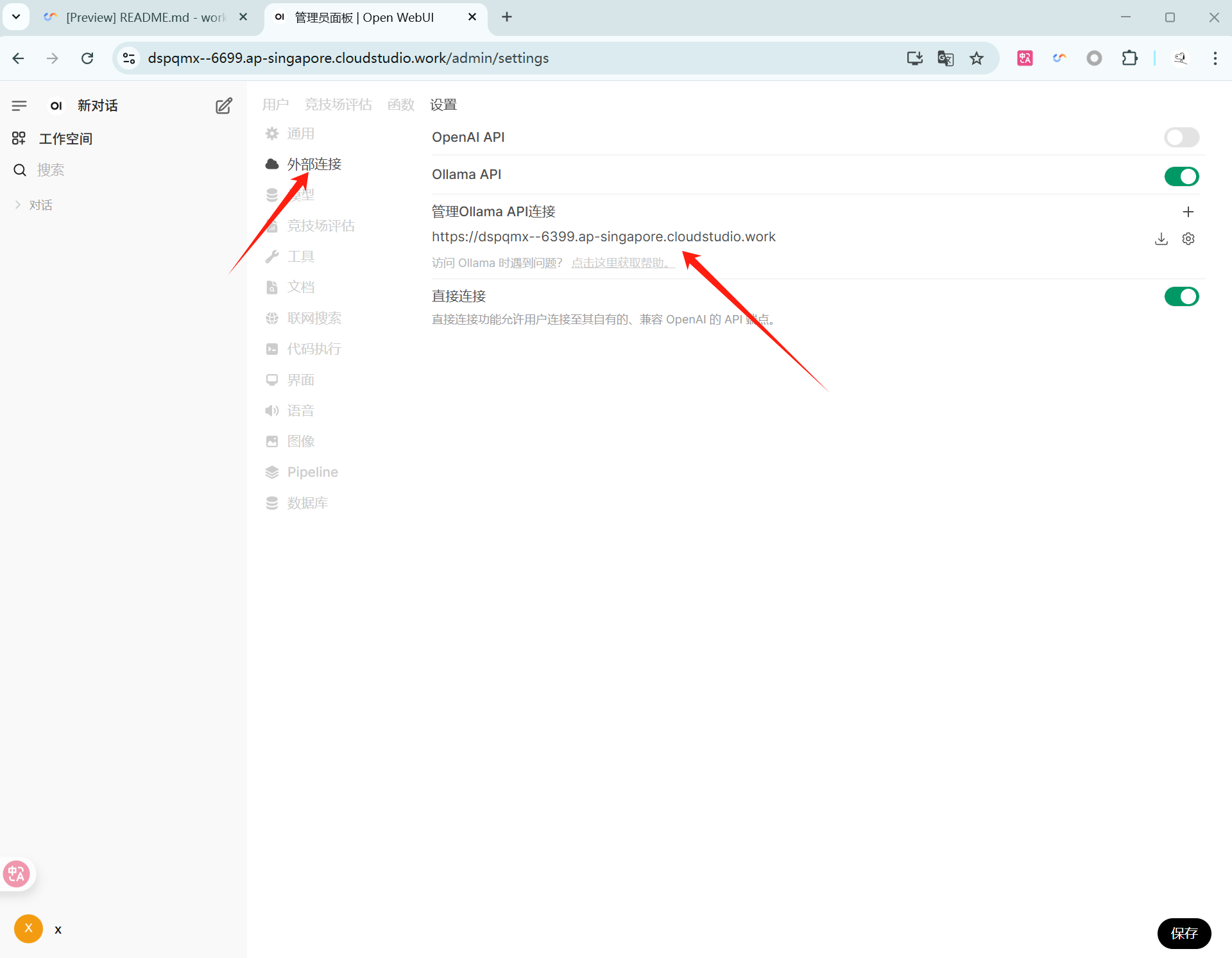
四、使用高性能工作空间(HAI 进阶型)进行对话与部署
1. 购买算力
选择 HAI 进阶型后单击下一步。如遇到授权提示,根据提示信息完成授权即可。
注意:
当前不支持协作者账号授权访问,请使用主账号或子账号。
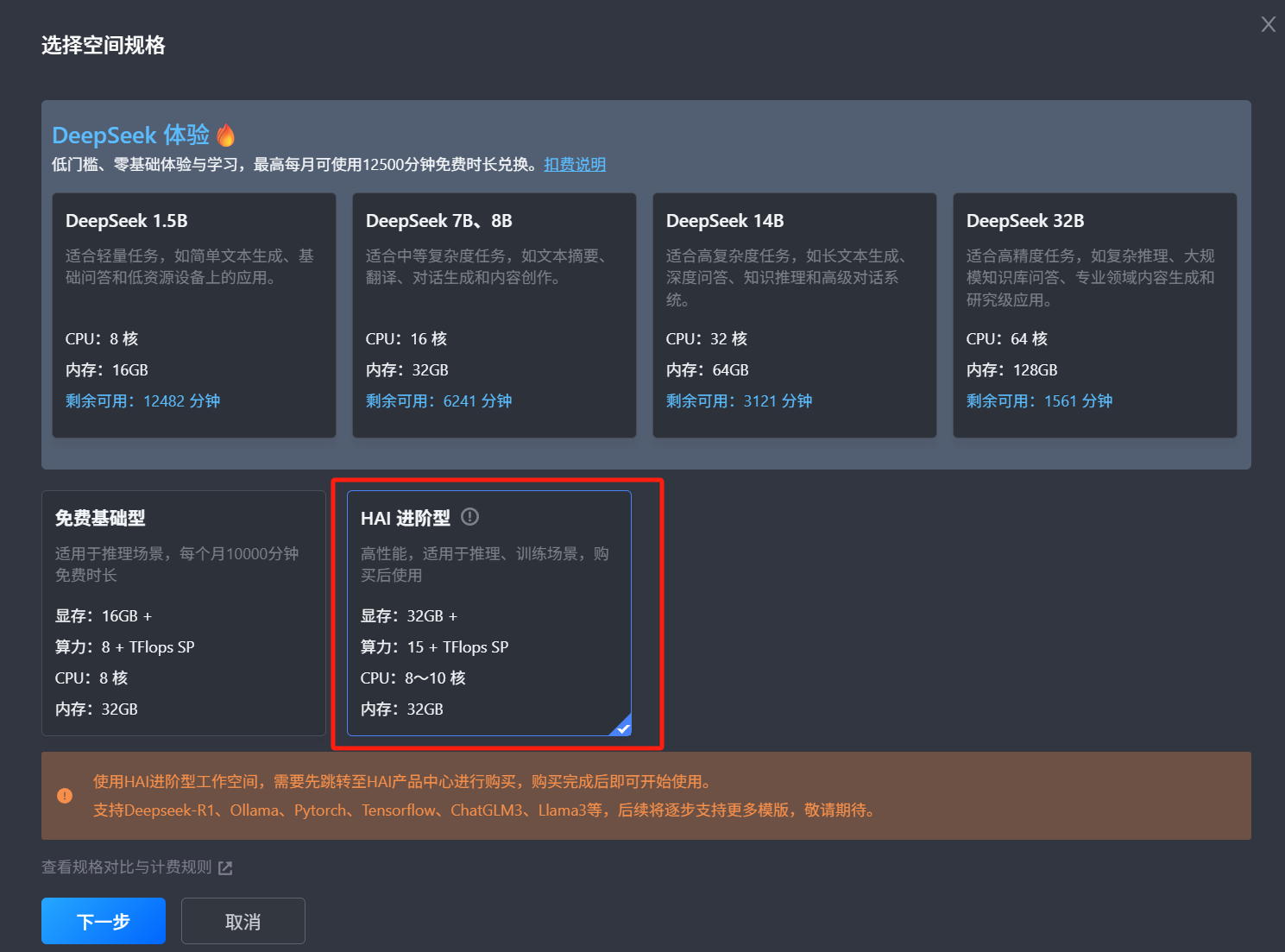
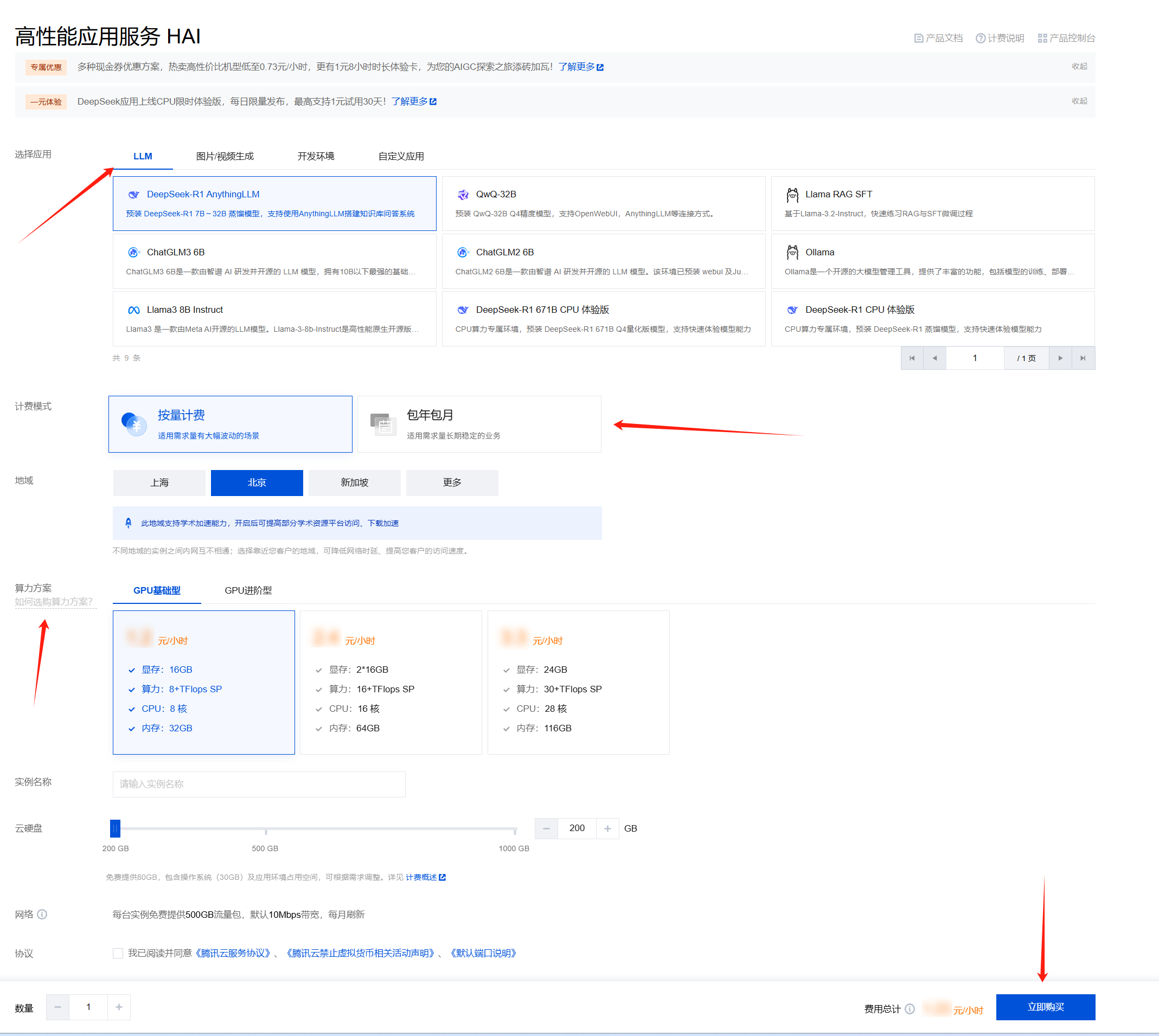
根据个人意向配置选购方案,填写实例名称,阅读并勾选协议,立即购买后,自动跳转到 Cloud Studio 创建工作空间。如账户余额为负请及时续费。
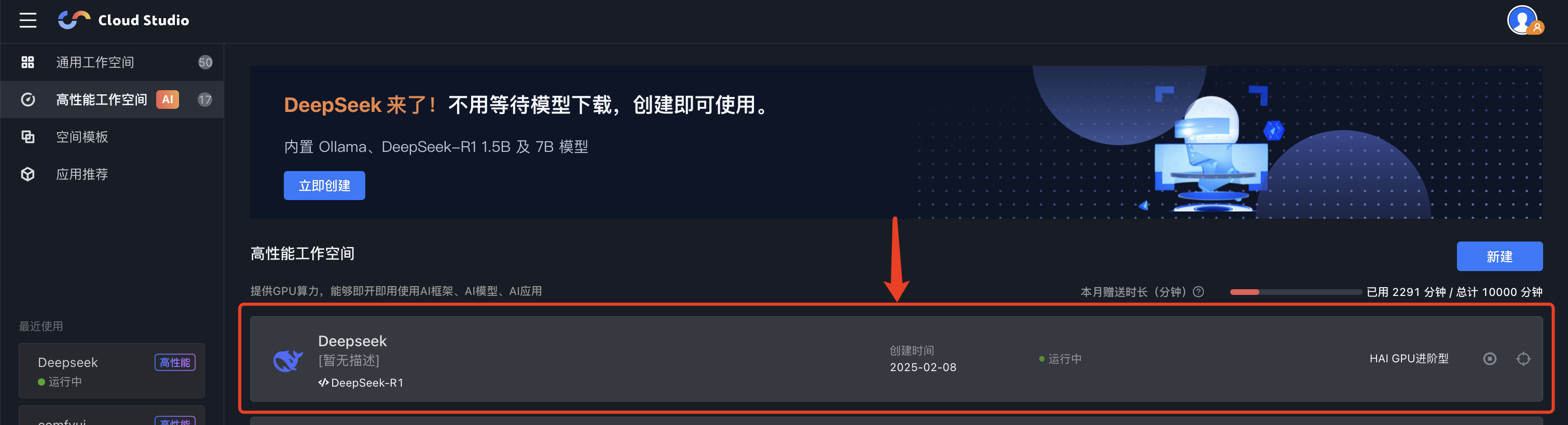
HAI 实例开机需要大约2-5分钟,状态为运行中,即可点击进入。
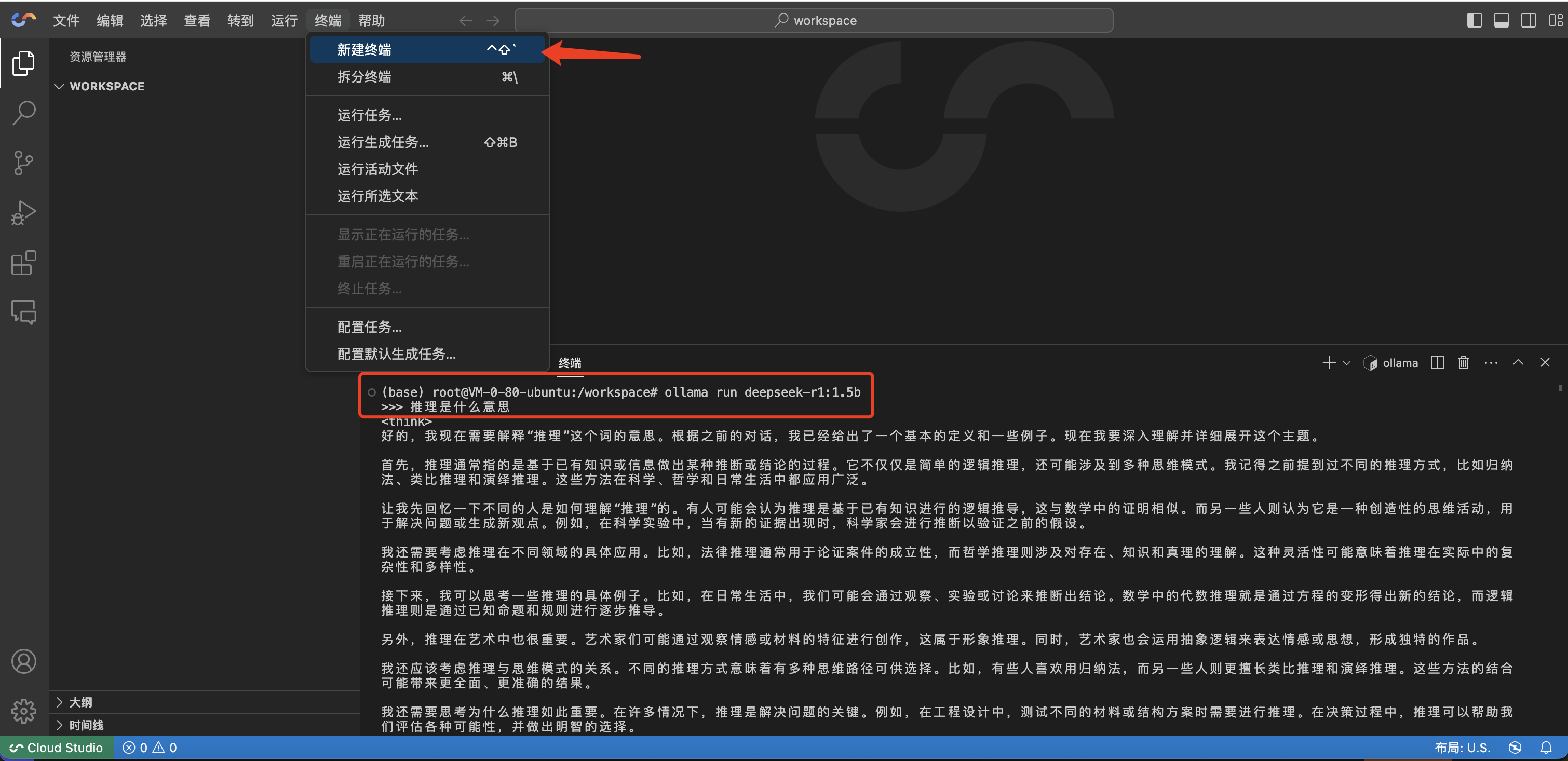
2. 在终端对话
与基础型类似,打开后新建终端并输入命令即可完成对话。
3. 使用 Chatbot UI / OpenWeb UI 对话
注意:
该功能仅限付费版可用。
目前进阶型空间也具备 Chatbot UI 对话框功能,其体验路径为:
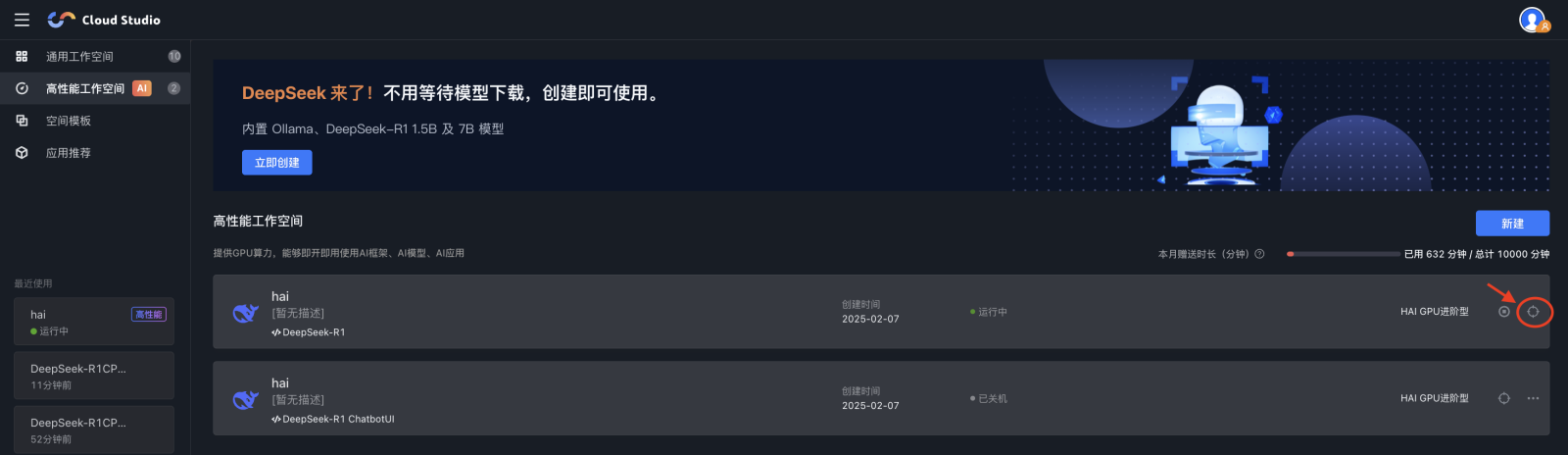
1. 在高性能工作空间列表中,单击已创建的进阶型空间最右侧图标,进入 HAI 资源控制台。
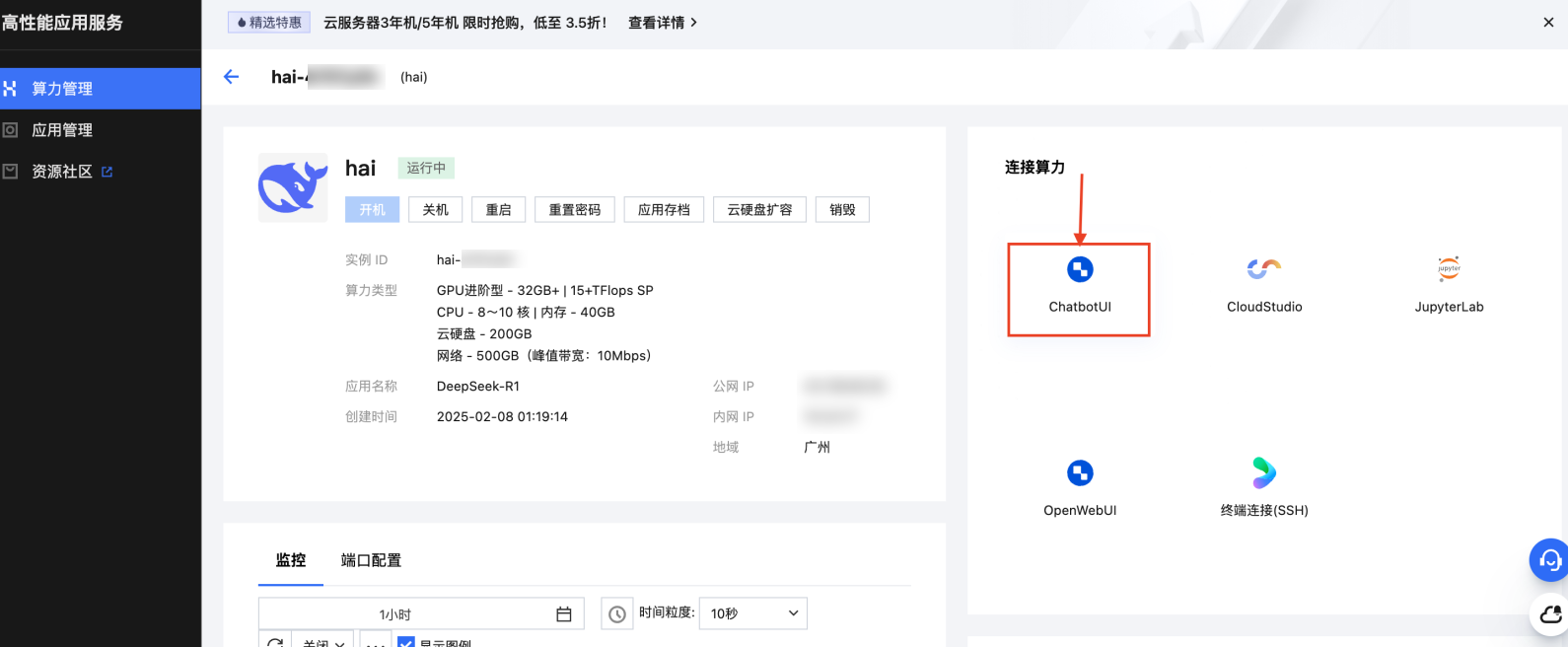
2. 单击 ChatbotUI 图标或 OpenWebUI 图标。
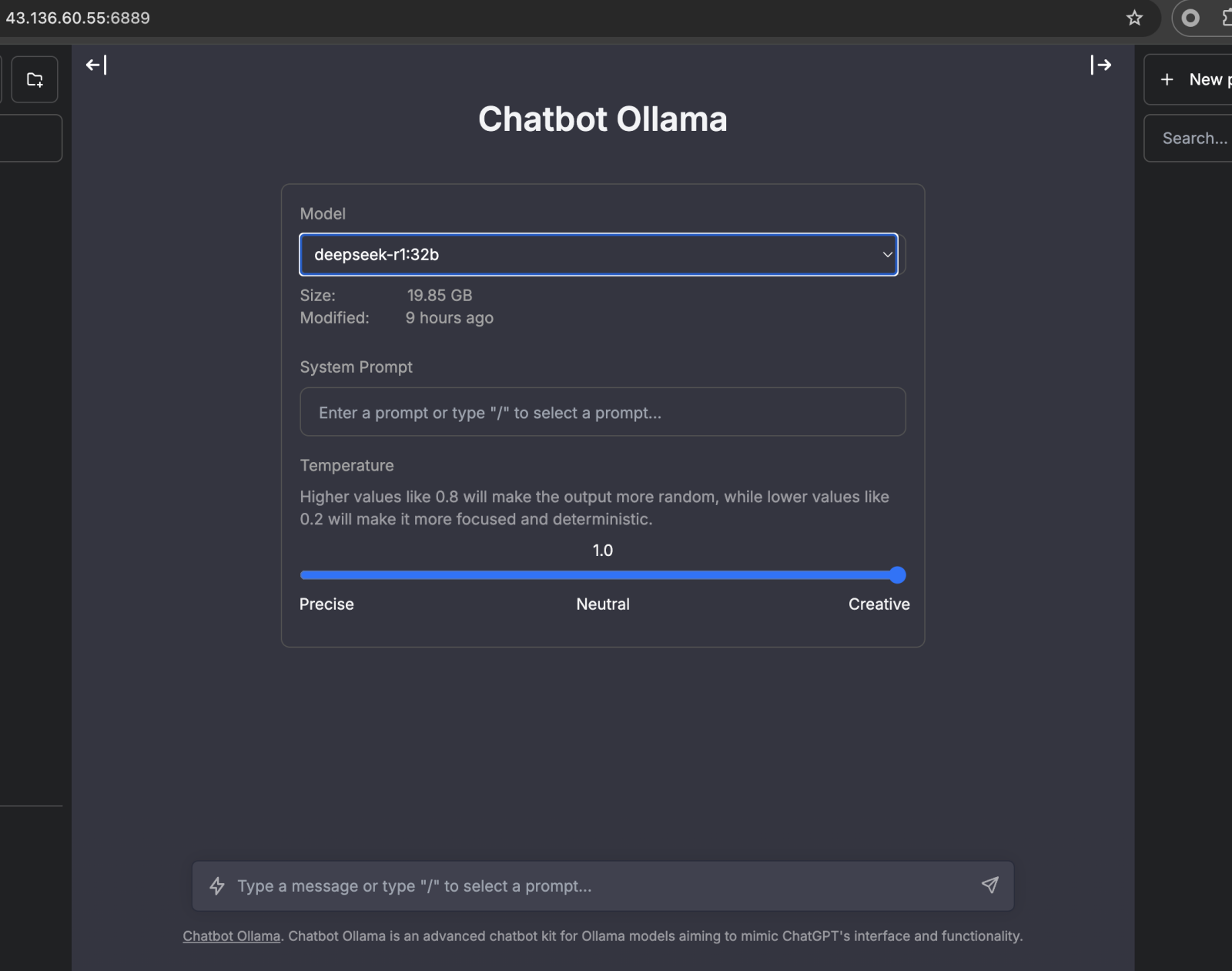
3. 选择模型,进行对话。
各机型服务端口对照表
规格类型 | Ollama 服务端口 | AnythingLLM 预览页面端口 | OpenWebUI 预览页面端口 | 备注 |
DeepSeek 体验 | 8434 | 4001 | 8080 | 可通过修改 .vscode/preview.yml自定义启动端口;访问时可用 https://<空间名>-<端口号>.app.cloudstudio.work/格式。 |
免费基础型 | 6399 | 6889 | 6699 | 工作空间地址格式为 https://${spaceKey}.${region}.cloudstudio.work,拼接端口访问如 https://${spaceKey}--6699.${region}.cloudstudio.work/ |
HAI 进阶型 | 8434(默认) | 无固定前端页面(可通过 Chatbot UI 或 OpenWebUI 组件访问) | 无固定前端页面(可通过 Chatbot UI 或 OpenWebUI 组件访问) | 需在 HAI 资源控制台通过 ChatbotUI / OpenWebUI 图标进入对话界面;实际端口可能因部署方式略有不同,以控制台提示为准。 |
补充说明:
Ollama 是底层模型推理服务,提供 API 接口(默认端口8434,DeepSeek 体验与 HAI 进阶型均为此默认值,免费基础型为 6399)。
AnythingLLM 和 OpenWebUI 是面向用户的可视化对话前端,不同规格预装的前端服务与访问端口有所差异。
免费基础型和 DeepSeek 体验规格可通过拼接端口访问对应的 WebUI 页面(如 https://xxx--6699.region.cloudstudio.work/访问 OpenWebUI)。
HAI 进阶型主要通过 HAI 资源控制台中的 ChatbotUI 或 OpenWebUI 图标直接进入对话,不依赖固定端口拼接访问。
常见问题
如何查看预览?
如何释放端口,关闭某个进程?
1. 可以通过下述命令查看端口占用情况:
lsof -i -P -n
2. 再使用下述命令关闭进程:
kill -9 <进程ID>
空间不足怎么处理?
如果右下角提示空间不足,可单击右下角规格(如“2核4GB”),选择“旗舰型”来升级空间。
免费版工作空间时长用完如何继续使用?
免费版主要用于帮助用户体验产品功能,暂不支持续费。可等待下个月再次发放时长后继续使用。
如何重置 OpenWeb UI 登录账号密码?
1. 首先,请关闭 OpenWebUI 的运行程序,确保程序完全停止。
2. 接下来,找到存放数据的文件夹。该文件夹通常位于系统的 Python 安装目录下,路径类似
root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/open_webui/data/(具体路径可能因环境而有差异)。进入这个文件夹后,您会找到一个名为 "webui.db" 的数据库文件(用于存储系统数据)。3. 为安全起见,建议先备份该文件。然后删除原 "webui.db" 文件,并重新启动 OpenWebUI 程序。系统将自动创建一个新的数据库文件,此时您可以使用初始账号密码登录。
相关文档与资源
Deepseek 官方介绍文档:GitHub - deepseek-ai/DeepSeek-R1
Ollama 官方介绍文档:GitHub - ollama/ollama
更多进阶型操作指南
更多帮助和支持
欢迎加入 Cloud Studio 用户反馈群。当您遇到问题需要处理时,您可以直接通过扫码进入 Cloud Studio 用户群进行提问。
腾讯云工程师实时群内答疑。
扫码入群可先享受产品上新功能。
更多精彩活动群内优享。




