为什么在消息轨迹上看,某一条消息只有生产记录,没有推送给客户端的记录?
这个问题通常可能由以下情况导致:
1. 曾经在控制台或客户端,修改或重置这个 Topic 订阅的 Offset 信息,导致当前消费位点超过了这条消息,这个时候这条消息其实就已经是 ack 状态。
2. 当前 Topic 存在消息堆积,没办法将已生产的消息立即推送给用户,并且当前 Topic 所在的命名空间配置的 TTL 过短,导致消息在还没有推送给用户前,就已经被自动确认。在这种场景下,需要分析消息堆积是否符合预期,如不符合预期,则建议通过提高消费速度,或者调大 TTL 时间,来确保消息能够被及时推送给用户。
3. 此条消息为延迟消息,但是当前 Topic 对应的 TTL 时间配置的比延迟时间要短,因此在当前消息推送之前,这条消息就已经被自动 ack 了,导致没有推送给客户端。
4. 这个订阅配置了 Tag 信息,由于这条消息的 Tag 与订阅不一致,因此当前消息被过滤。
5. 当前订阅模式为 Key-Shared 模式,但是这条消息前的消息还没有被对应的客户端 ack,由于需要保证相同 key 的消息顺序性,导致当前消息不会推送。
为什么在消息轨迹上看,某个 Topic 的部分分区消息推送时延较大?
需要判断当前消息是否为延迟消息,并且观察分区是否存在消息积压。如果以上指标都无异常,并且分区的订阅较多时,需要排查是否当前分区达到消费的 TPS 上限。由于专业集群默认的消费 TPS 上限为 10000,在绝大多数情况下不会达到阈值,只有流量特别大的 Topic 可能会遇到,在这种情况下需要调大 Topic 分区数量,并观察是否能够缓解。
为什么生产者在短期内出现频繁断连重连,并且生产的部分消息出现大量重复?
这个问题最常见的原因是生产的某些延时消息延迟时间超过 10 天,某些低版本的 SDK 对于生产延迟超过 10 天的报错解析不够完善,会造成延迟消息之后的部分消息不断重复生产的情况。建议用户排查日志中是否出现
DELAY TIME IS TOO LONG 的报错,如果出现需要排查代码延迟消息相关配置。为什么使用的是 2.x 版本的 Java SDK,明明没有使用 negativeAcknowledge() 或者 ackTimeout() 相关配置,控制台消息轨迹中却出现重推记录?
Pulsar 2.x 版本的 Java SDK 中,如果配置了死信队列相关策略(DLQ Policy),则会默认创建一个 30s 的 ackTimeout 自动重推的配置。当客户端代码中如果执行的是离线业务,或者计算密集型业务,在较长时间后才能 ack 的情况时,就比较有可能超过 30s 的 ackTimeout 时间导致重推。如果用户对重推敏感,并且需要使用 DLQ Policy 时,建议升级到 3.x 版本的 Java 客户端。
为什么 Pulsar 服务端突然不给客户端推送消息,部分/全部分区消费速度为0?
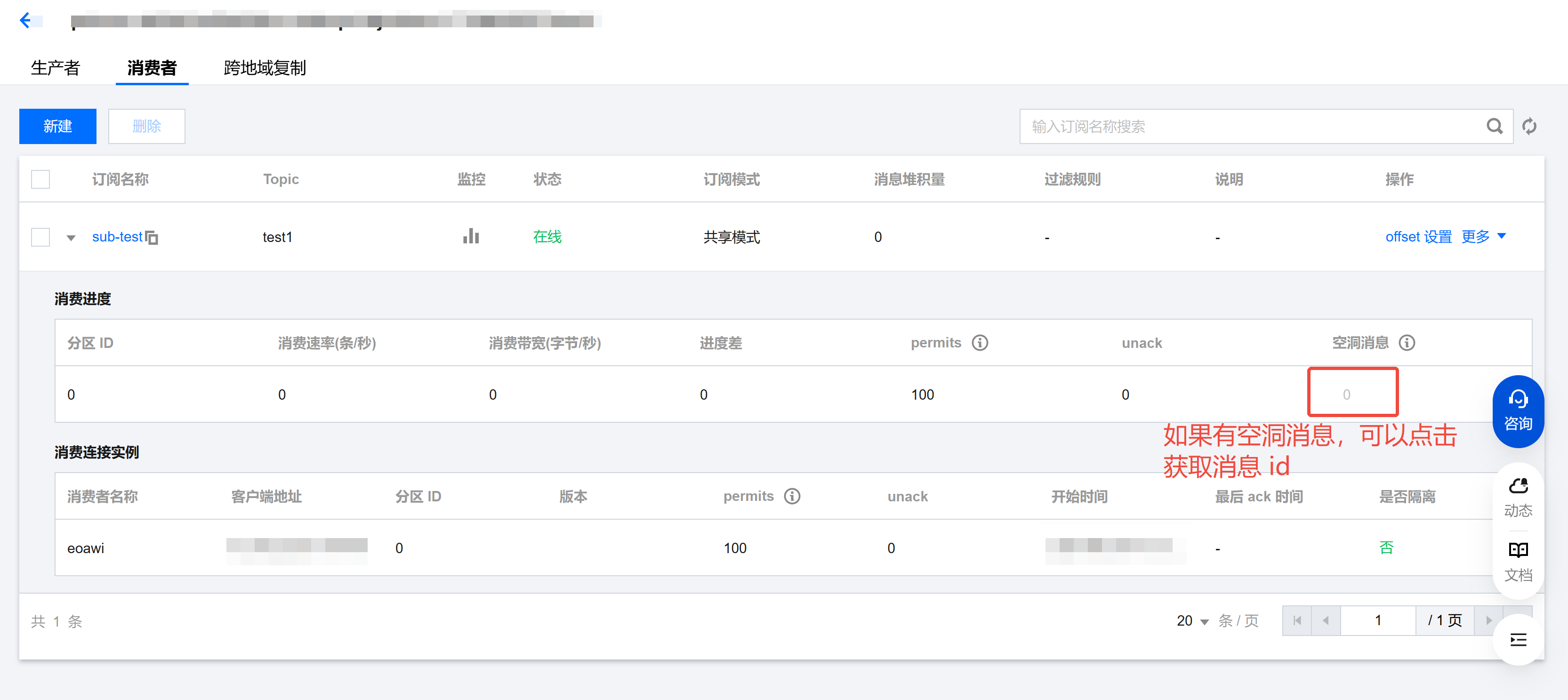
Pulsar 为了均衡不同 Topic 和不同客户端性能,会设置默认的 Topic 每个分区订阅的最大已接收未确认消息数量(unack 数量),默认 5000 可参考使用限制。观察订阅是否达到 unack 消息上限可观察订阅的 unack 消息指标是否达到配额上限。
当推送给某个分区的订阅下的所有 unack 消息( unack 消息指的是消息推送后,客户端没有进行 ack()/negativeAcknowledge()/reconsumeLater() 等操作确认消息)超过 5000 条时,服务端就不会继续推送给这个分区的订阅消费者继续推送消息。解决办法通常如下:
1. 需要先排查消息未确认是由于本身业务属于长耗时的业务,本身处理时间长造成较多消息未确认;还是由于业务代码存在某些逻辑异常时,在异常处理时没有将消息及时 ack,造成消息空洞。排查方式可以从 Topic 分区订阅中获取空洞消息的 msgId,之后在消息轨迹中查询消息内容和推送记录,具体介绍请参考空洞消息。
2. 如果消息属于长耗时业务,空洞消息属于正常情况时,由于消息已经达到最大已接收未确认消息数量(unack)上限,这时候需要业务进行消费者的水平扩容,来提高业务的消费能力。这个时候建议调小单个客户端的 ReceiverQueueSize 配置,建议值为 2500/消费者数量。
3. 如果分析空洞消息后,发现属于消费者业务代码某些场景漏 ack,需要在修复消费者 ack 相关逻辑代码发布新版本后,重启 unack 消息对应的消费者客户端,重启后服务端会自动重新推送 unack 的消息。
为什么在同一个订阅下部署了几十个消费者,可是只有某几个消费者有接收到消息,其余消费者都无法接收到消息?
通常是由于消费者的默认 ReceiverQueueSize 配置过大。不同客户端的默认 ReceiverQueueSize 不同,但是部分为 1000,由于单订阅分区默认的 unack 上限为 5000,如果每个客户端的 ReceiverQueueSize 为 1000 的情况下,当五个客户端同时拉取消息,并且不进行 ack 操作时,unack 上限就会被打满,也就无法继续推送给其他的消费者消息了。
为什么生产了一条1s的延迟消息,但是这条消息服务端没有经过延时,而是马上就推送给消费者客户端了?
为什么最近某个 Topic 的生产流量没有明显变大,但是这个 Topic 的消息存储大小却比平时高了很多?
如果用户在近期没有修改过这个 Topic 对应的命名空间的 ttl/retention 策略的话,通常是由于这个 Topic 的某些订阅存在空洞消息,由于 Pulsar 的机制是只会按照时间顺序由老到新依次顺序删除消息,当出现空洞消息时,这条消息及之前的消息都无法被删除,造成消息存储大小变大。可参考空洞消息进行排查处理。
为什么使用 negativeAcknowledge() 进行重推,但是客户端重启后之前存量消息的重试次数都归零了?
为什么创建生产者/消费者报错 Unauthorized to validateTopicOperation for operation [xxx] on topic ?
当前客户端的 token 没有相关权限,需要在命名空间页面,赋予对应角色对应命名空间的生产/消费权限,可参考配置命名空间权限 。需要注意的是,如果用户使用了重试队列/死信队列相关配置,由于消费者会 ack 原消息,并且往重试队列/死信队列发送新消息,因此需要对应的角色同时具有命名空间的生产和消费权限。
为什么创建生产者向某个 Topic 发送消息时报错 404 & ConnectError?
该报错表示 Pulsar Broker 在其元数据中无法找到生产者尝试连接的目标 Topic。根本原因与 Topic 是否存在,以及 Broker 是否被允许自动创建 Topic 有关。可以通过以下两种业务场景进行排查。
场景一:业务禁用自动创建 Topic 功能,Topic 必须手动创建。
场景二:业务允许自动创建 Topic功能。
为什么客户端连接不上专业集群的接入点?
目前专业版共分为三种接入点:
1. 支撑环境接入点(接入点域名带有 internal)
2. VPC 环境接入点(接入点域名带有 qcloud)
3. 公网环境接入点(接入点域名带有 public)
为什么新消费者配置 tag 过滤后,会覆盖存量的消费者 tag 过滤属性?
目前消息过滤的维度都是订阅级别的维度,同一个订阅下所有消费者用的都是相同的 tag 过滤指标。如果同一个订阅下创建两个消费者,并且配置不同的 tag 的话,后创建的消费者 tag,会覆盖前面创建的消费者 tag。如果想要两个消费者使用不同的 tag 过滤属性,需要对这个 Topic 创建两个订阅,然后对于这两个订阅,设置不同的 tag。详情可以参考标签过滤。



