使用限制
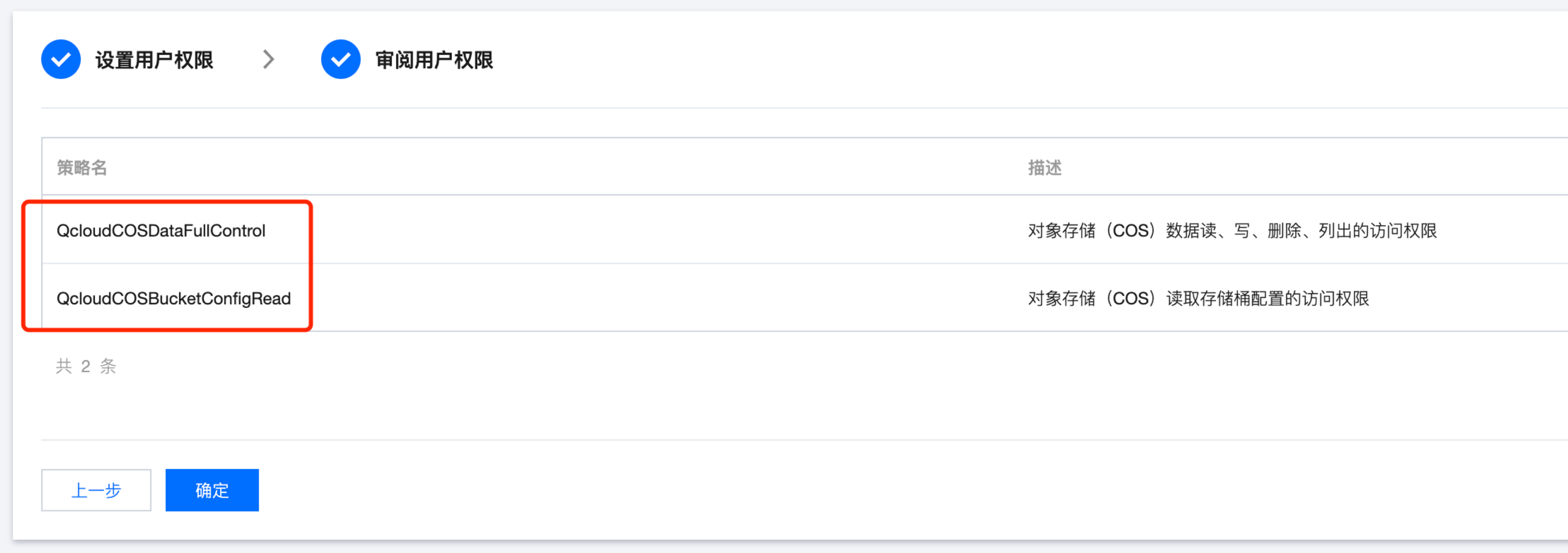
建议在配置子账号授权数据的读写权限的同时,追加 QcloudCOSBucketConfigRead、QcloudCOSDataFullControl 两项策略权限。因为 Spark 在操作 COS 文件时部分情况下需要 headBucket 权限。
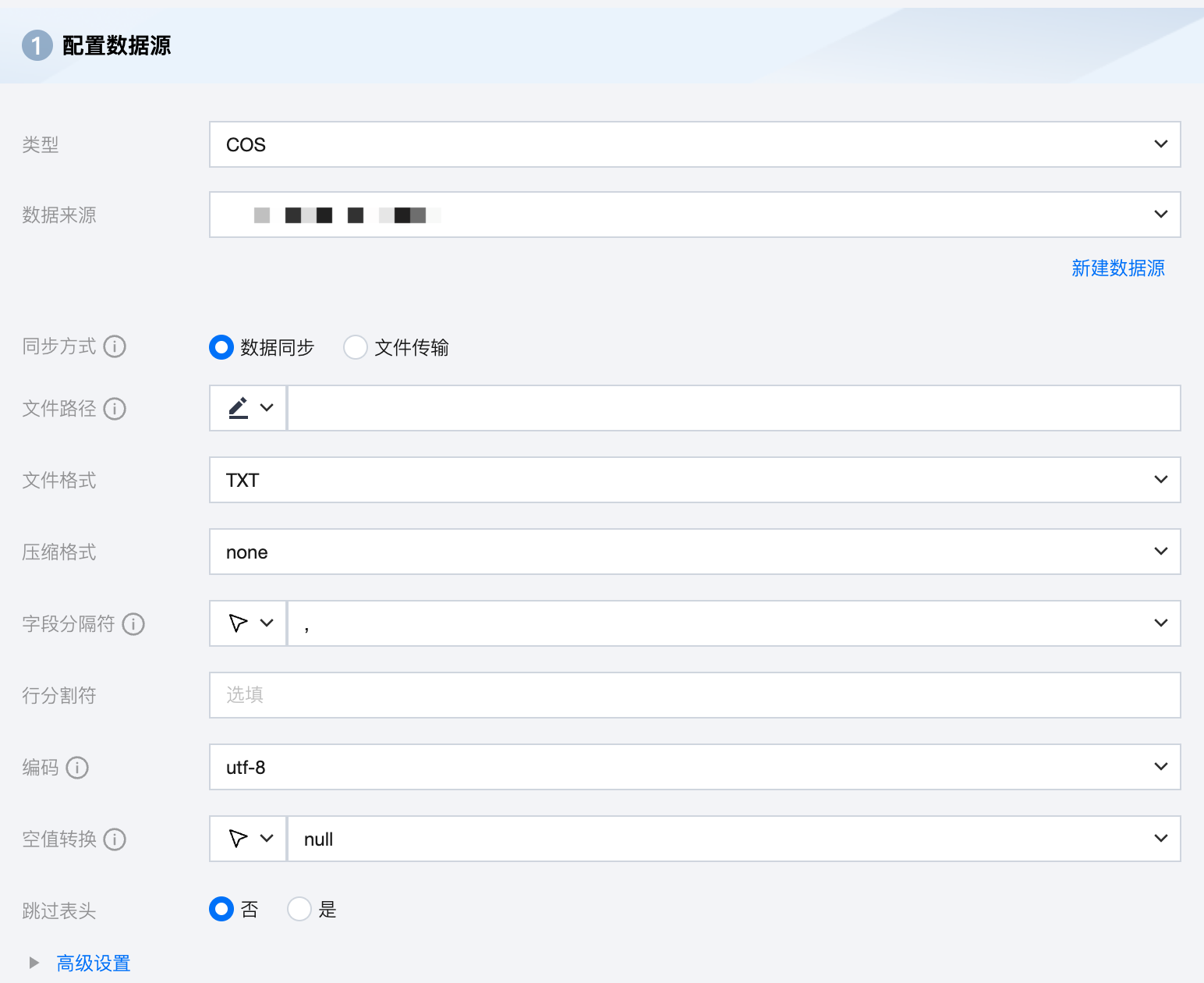
COS 离线单表读取节点配置
参数 | 说明 |
数据来源 | 选择当前项目中可用的 COS 数据源。 |
同步方式 | COS支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意:文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP)的数据源,且来源端、目标端同步方式均需要为文件传输 |
文件路径 | COS文件路径需带上桶名称,如 cosn://bucket_name。 说明:文件路径能够根据通配符*实现部分匹配,支持匹配以xxxx开头的文件夹/文件、以xxxx结尾的文件夹/文件 如cosn://bucket_name/*.txt |
文件格式 | COS 支持五种文件类型:TXT 、ORC 、PARQUET、CSV、JSON。 TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 JSON:表示 JSON 文件格式。 |
压缩格式 | 文件压缩方式,目前支持:none、deflate、gzip、bzip2、lz4、snappy。 说明: 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的 hadoop-snappy(hadoop 上的 snappy stream format)和 framing-snappy(google 建议的 snappy stream format)。 |
字段分隔符 | 读取的字段分隔符,当文件格式为 TXT 或 CSV 时,需要指定字段分隔符,如果不指定默认为逗号(,)。 其他可用分隔符:' \\t ' 、' \\u001 ' 、' | '、' 空格 ' 、 ' ;' ' , '。 如果您想将每一行作为目的端的一列,分隔符请使用行内容不存在的字符。例如,不可见字符\\u0001。 说明: 仅文件格式为 TXT 、CVS 支持填写行分割符。 |
行分割符 | 当文件格式为 TXT 或 CSV 时,可以填写行分割符。linux 默认是 \\n , windows 默认是 \\r\\n,手填支持单个字符作为行分割符。 说明: 仅文件格式为 TXT 、CVS 支持填写行分割符。 |
编码 | 读取文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空值转换 | 读取时,将指定字符串转为 NULL。 |
跳过表头 | 否:读取时不包含表头。 是:读取时包含表头。 说明: 仅文件格式为 TXT 、CVS 支持填写。 当来源端包含表头,且选择不跳过表头时,目标端建议选择不包含表头,否则可能导致表头数据重复。 |
COS 离线单表写入节点配置
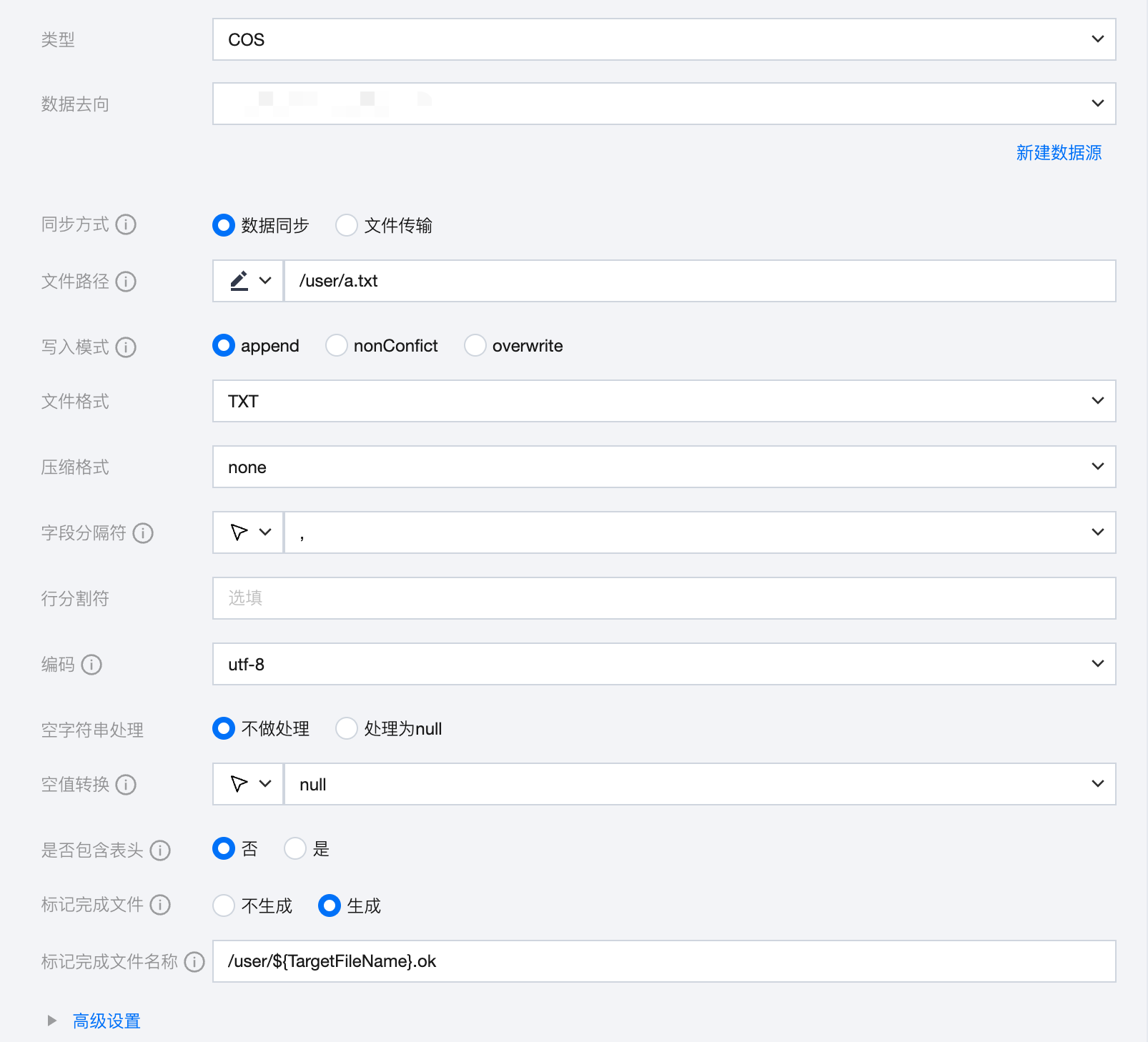
参数 | 说明 |
数据去向 | 选择当前项目中可用的 COS 数据源。 |
同步方式 | COS支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | COS 文件路径需带上桶名称,如 cosn://bucket_name。 说明: 文件路径能够根据通配符*实现部分匹配,支持匹配以 xxxx 开头的文件夹/文件、以 xxxx 结尾的文件夹/文件。 如cosn://bucket_name/*.txt |
写入模式 | COS 支持三种写入模式: append:写入前不做任何处理,直接使用 filename 写入,保证文件名不冲突 。 nonConflict:文件名重复时报错 。 overwrite:写入前清理以文件名为前缀的所有文件,例如,"fileName": "abc",将清理对应目录所有 abc 开头的文件。 |
文件格式 | COS 支持四种文件类型:TXT、CSV、ORC、PARQUET TXT:表示 TextFile 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 |
压缩格式 | 文件压缩方式,目前支持:none、deflate、gzip、bzip2、lz4、snappy。 说明: 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的 hadoop-snappy(hadoop上的snappy stream format)和 framing-snappy(google 建议的 snappy stream format)。 |
字段分隔符 | 当文件格式为 TXT 或 CSV 时,选择或手动输入读取的字段分隔符。COS 写入时的字段分隔符,需要您保证与创建的 COS表的字段分隔符一致,否则无法在 COS 表中查到数据。可选:' \\t ' 、' \\u001 ' 、' | '、' 空格 ' 、 ' ;' ' , '。 说明: 仅文件格式为 TXT 、CVS 支持填写行分割符。 |
行分割符 | 当文件格式为 TXT 或 CSV 时,可以填写行分割符。linux 默认是 \\n , windows 默认是 \\r\\n,手填支持单个字符作为行分割符。 说明: 仅文件格式为 TXT 、CVS 支持填写行分割符。 |
编码 | 写入文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空字符串处理 | 不做处理:写入时,不处理空字符串。 处理为 NULL:写入时,将空字符串处理为 NULL。 |
空值转换 | 写入时,将 NULL 转为指定字符串。NULL 代表未知或不适用的值,不同于0、空字符串或其他数值 说明: 仅文件格式为 TXT 、CVS 支持选择。 |
是否包含表头 | 是:写入时,包含表头 否:写入时,不包含表头 说明: 仅文件格式为 TXT 、CVS 支持选择是否包含表头。 |
标记完成文件 | 空白的.ok文件,标志任务传输完成。 不生成:任务完成后,不生成空白的.ok文件。(默认选中) 生成:任务完成后,生成空白的.ok文件 |
标记完成文件名称 | 填写时需包含完整文件路径、名称、后缀,默认在目标路径下按照目标文件名称及后缀生成.ok文件。 支持在数据同步、文件传输模式下使用时间调度参数${yyyyMMdd}等; 支持在文件传输模式下使用内置变量${filetrans_di_src}代表源文件名称。如:/user/test/${filetrans_di_src}_${yyyyMMdd}.ok。 注意: 在文件传输模式下「目标文件名称」中如果使用${filetrans_di_src}引用源文件名称,并且标记完成文件按照目标文件名称及后缀生成.ok文件时,生成的标记完成文件个数取决于来源端的文件数量。 |
高级设置(选填) | 可根据业务需求配置参数。 |
数据类型转换支持(数据同步方式)
COS Select 通过 CAST 函数确定您输入数据的数据类型,一般而言,如果您未通过 CAST 函数进行数据类型指定,COS Select 将把输入数据类型视为 string 类型。
读取
COS 数据类型 | 内部类型 |
INTEGER | LONG |
FLOAT、DECIMAL | DOUBLE |
STRING | STRING |
TIMESTAMP | DATE |
BOOL | BOOLEAN |
写入
内部类型 | COS 数据类型 |
LONG | INTEGER |
Double | FLOAT、DECIMAL |
STRING | STRING |
DATE | TIMESTAMP |
BOOLEAN | BOOL |
COS 脚本 Demo
如果您配置离线任务时,使用脚本模式的方式进行配置,您需要在任务脚本中,按照脚本的统一格式要求编写脚本中的 reader 参数和 writer 参数。
"job": {"content": [{"reader": {"parameter": {"path": "/","nullFormat": "null", //空值转换"compress": "gzip", //压缩格式"lineDelimiter": "\\n", //行分隔符"hadoopConfig": {"fs.defaultFS": "cosn://source-bucket","fs.cosn.userinfo.secretId": "******","fs.cosn.tmp.dir": "/tmp/hadoop_cos","fs.cosn.trsf.fs.ofs.tmp.cache.dir": "/tmp/","fs.cosn.userinfo.secretKey": "******","fs.cosn.bucket.region": "ap-beijing","fs.cosn.impl": "org.apache.hadoop.fs.CosFileSystem","fs.cosn.trsf.fs.ofs.bucket.region": "ap-beijing","fs.cosn.trsf.fs.ofs.user.appid": "******"},"column": ["*"],"defaultFS": "cosn://source-bucket", //源文件路径"skipHeader": "false", //是否跳过表头"fieldDelimiter": ",", //字段分割符"encoding": "utf-8", //编码方式"fileType": "text" //文件类型},"name": "hdfsreader"},"transformer": [],"writer": {"parameter": {"path": "/","fileName": "part","nullFormat": "null", //空值转换"compress": "gzip", //压缩格式"hadoopConfig": {"fs.defaultFS": "cosn://sink-bucket","fs.cosn.userinfo.secretId": "******","fs.cosn.tmp.dir": "/tmp/hadoop_cos","fs.cosn.trsf.fs.ofs.tmp.cache.dir": "/tmp/","fs.cosn.userinfo.secretKey": "******","fs.cosn.bucket.region": "ap-beijing","fs.cosn.impl": "org.apache.hadoop.fs.CosFileSystem","fs.cosn.trsf.fs.ofs.bucket.region": "ap-beijing","fs.cosn.trsf.fs.ofs.user.appid": "******"},"defaultFS": "cosn://sink-bucket", //目标文件路径"emptyAsNull": false,"writeMode": "append", //写入模式"suffix": "parquet", //文件后缀"fieldDelimiter": ",", //字段分隔符"encoding": "utf-8", //编码方式"fileType": "parquet" //文件类型},"name": "hdfswriter"}}],"setting": {"errorLimit": { //脏数据阈值"record": 0},"speed": {"byte": -1, //不限制同步速度,正整数表示设置最大传输速度 byte/s"channel": 1 //并发数量}}}



