Rest API 离线单表读取节点配
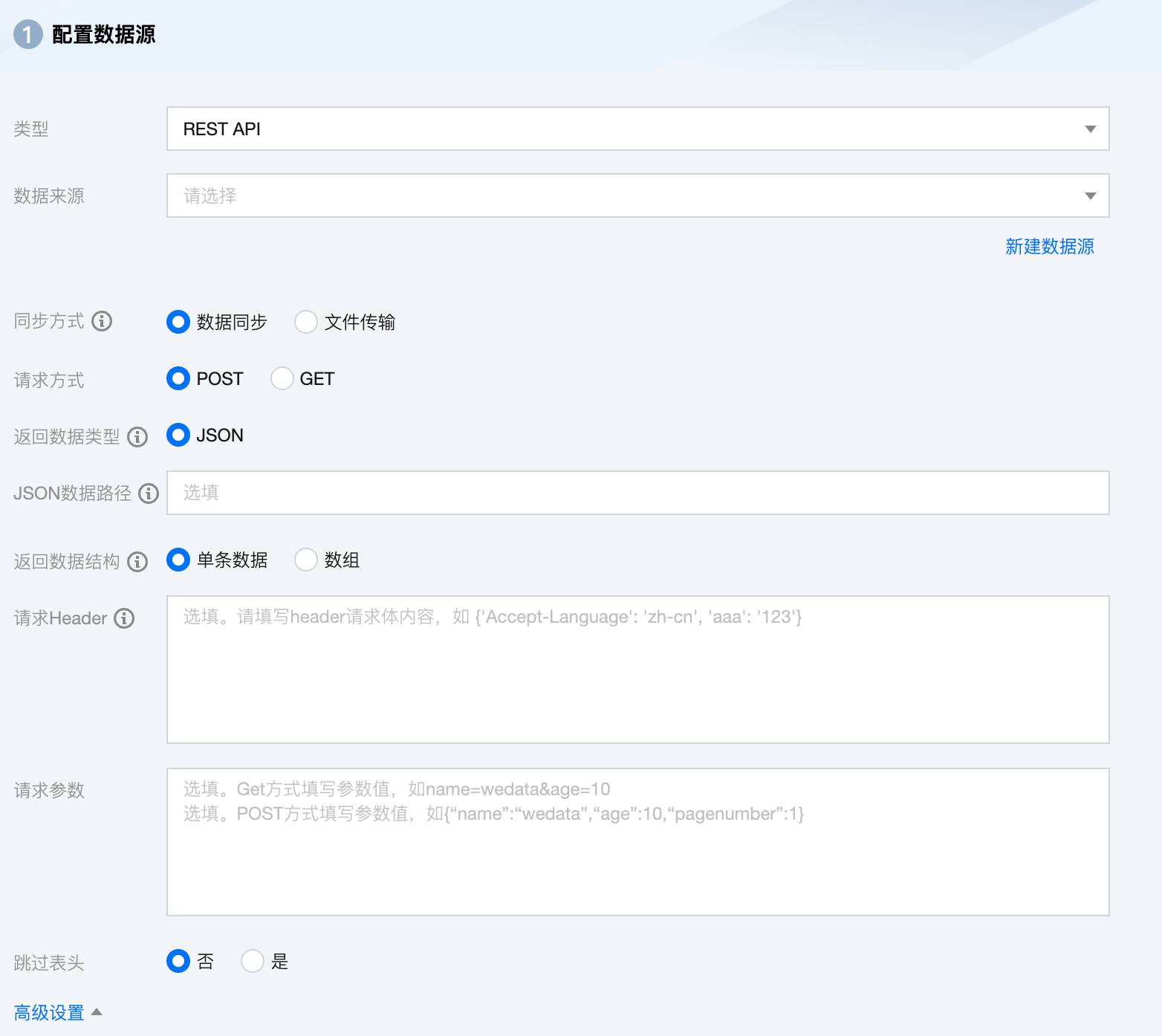
参数 | 说明 |
数据来源 | 可用的 Rest API 数据源。 |
同步方式 | 支持数据同步和文件传输两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 |
请求方式 | 支持 POST 和 GET 两种请求方式 。 POST 方法填入 JSON 类型参数。 GET 方法填入 abc=1&def=1。 |
返回数据类型 | 返回数据的格式,目前仅支持 JSON 数据。 |
JSON 数据路径(选填) | 从返回结果中查询单个 JSON 对象或者 JSON 数组的路径。 |
返回数据结构 | 支持单条 JSON 数据、JSON 数组数据。 |
请求 Header(选填) | 传递给 RESTful 接口的 header 信息。 |
请求参数(选填) | get 方法填入 abc=1&def=1。 post 方法填入 JSON 类型参数。 |
请求方式 | 单次运行同步任务时是否多次发起请求,多次请求需配置相应参数及起始 index 值。 |
跳过表头 | 否:同步时,不跳过表头。 是:同步时,跳过表头。 说明: 仅同步方式为数据同步时支持是否跳过表头。 |
数据类型转换支持
类型分类 | 数据集成 column 配置类型 |
整数类 | LONG,INT |
字符串类 | STRING |
浮点类 | DOUBLE,FLOAT |
布尔类 | BOOLEAN |
日期时间类 | DATE |
Rest API 使用示例
场景1: 单条读取
假设 API 的请求参数如下:
// 假设是get请求paramA=a¶mB=b
API 返回的数据结构如下:
{"code": "success","data": {"id": "100","name": "name100"}}
若需要读取返回的所有字段内容,任务可配置为:
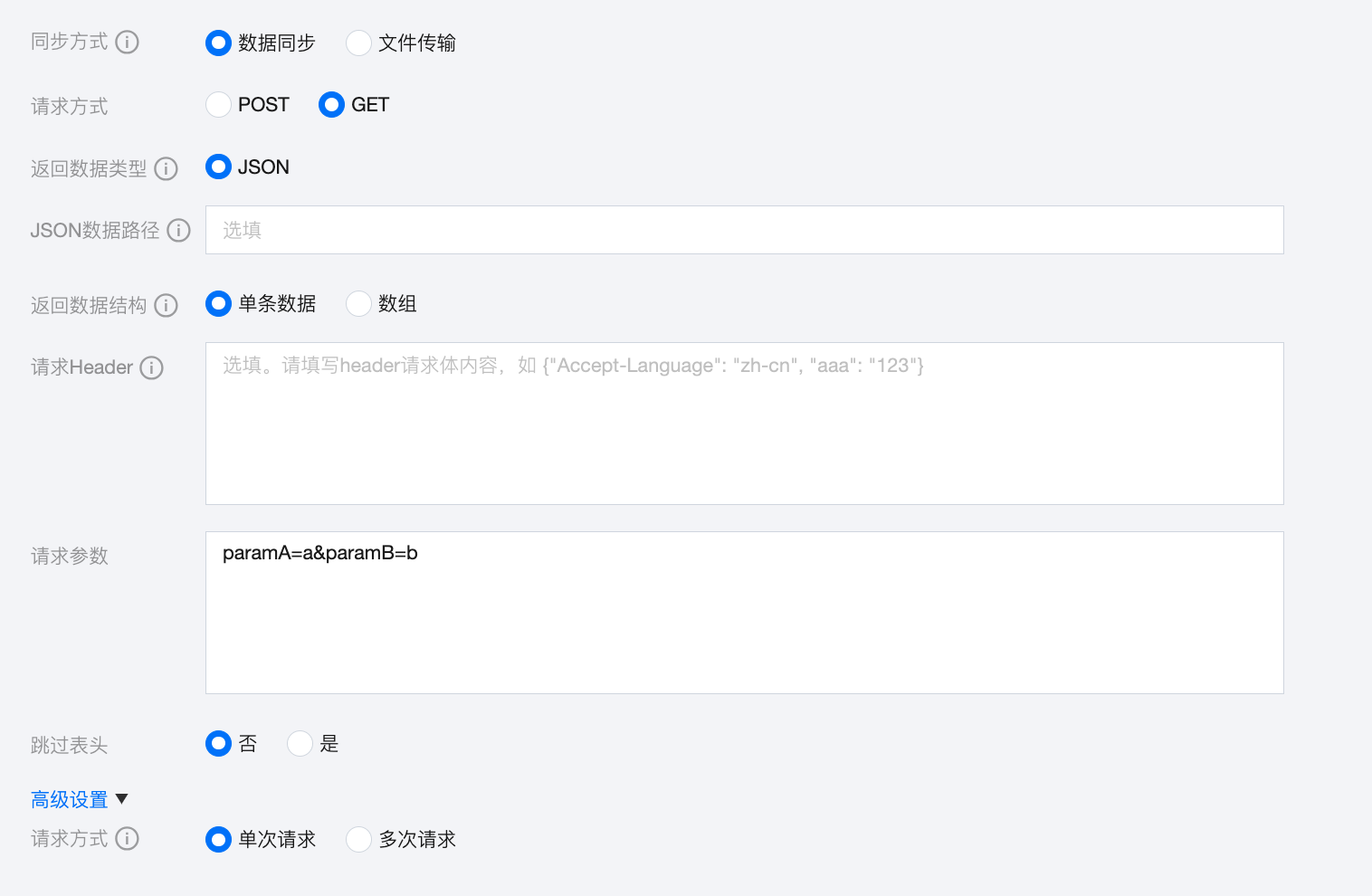
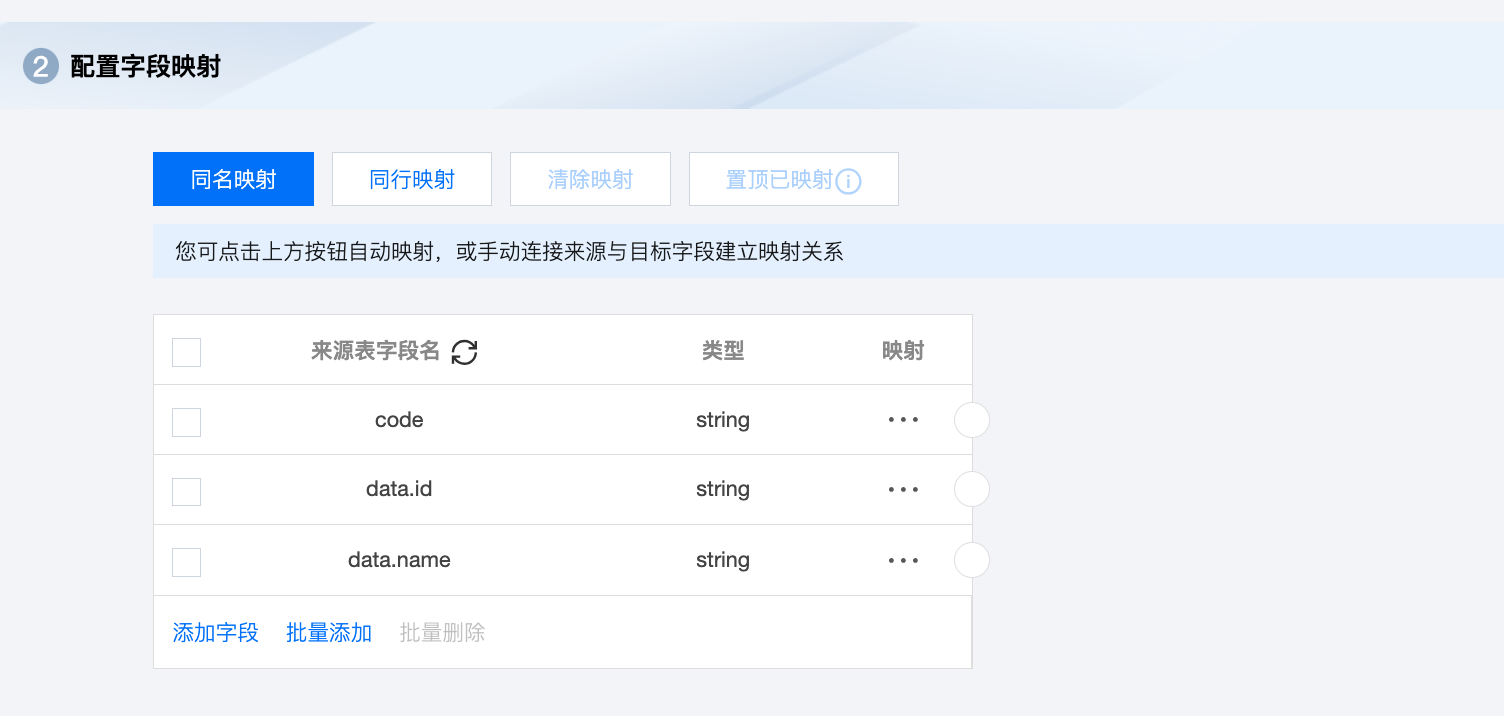
字段可配置为:
场景2: 分页读取
假设 API 的请求参数如下:
// 假设是post请求,其中pageNum是页数{"pageNum": 1,"paramA": "a","paramB": "b"}
API 返回的数据结构如下:
// 其中dataList是业务数据,且是数组的格式{"total": "20","code": "success","dataList": [{"id": 1,"name": "name_1","info": {"infoId": "info_1","infoName": "infoName_1"}},{"id": 2,"name": "name_2","info": {"infoId": "info_2","infoName": "infoName_2"}},{"id": 3,"name": "name_3","info": {"infoId": "info_3","infoName": "infoName_3"}}]}
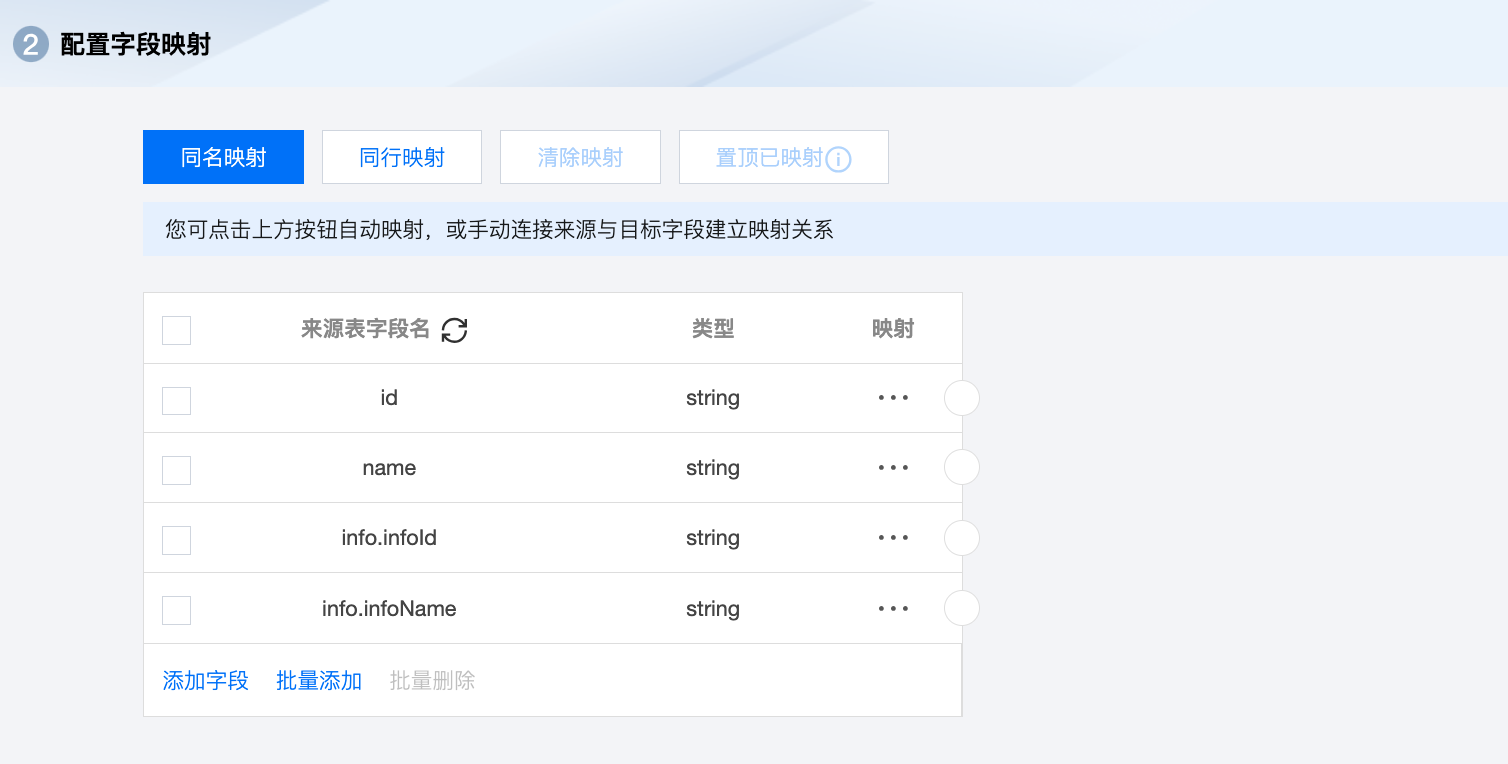
若需要同步第1页到第10页的数据,且期望读取返回结构中 dataList 下的内容,任务可配置为:
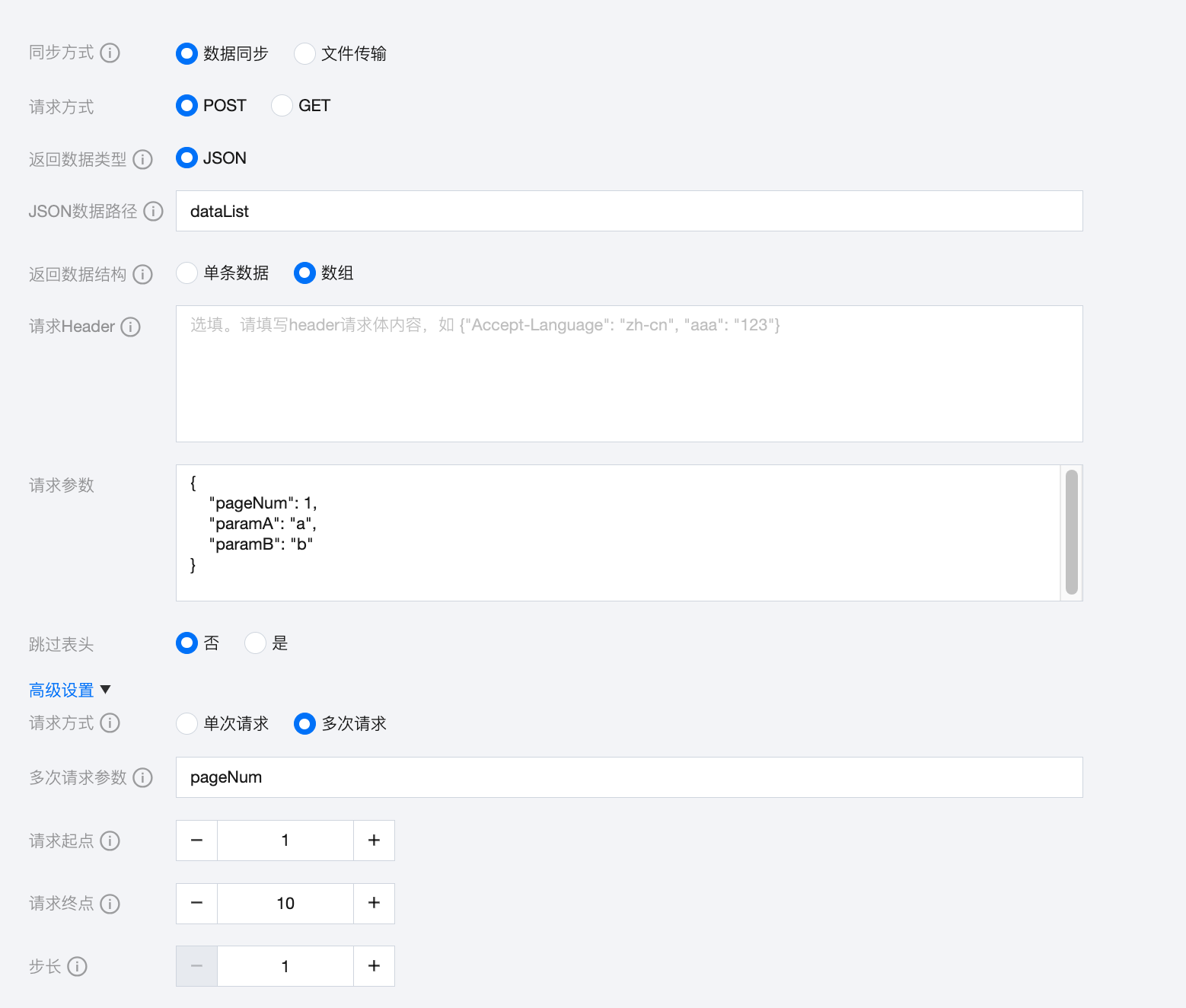
字段可配置为:
Rest API 脚本 Demo
如果您配置离线任务时,使用脚本模式的方式进行配置,您需要在任务脚本中,按照脚本的统一格式要求编写脚本中的 reader 参数。(Rest API 仅支持 reader)
"job": {"syncType": "data", //同步方式,支持数据同步和文件传输"content": [{"reader": {"parameter": {"headers": { //请求Header"Accept-Language": "zh-cn "},"method": "POST", //请求方式,支持GET和POST"responseStructure": "object", //返回的数据类型,支持单挑数据和数组"requestParams": { //请求参数"name": "wedata","pagenumber": 1},"resultKey": "", //JSON数据路径"connection": [ //源url地址{"url": "https://cloud.tencent.com/document/product/1267/105543"}],"skipHeader": "false"},"name": "httpreader"}}],"setting": {"errorLimit": { //脏数据阈值"record": 0},"speed": {"byte": -1, //不限制同步速度,正整数表示设置最大传输速度 byte/s"channel": 1 //并发数量}}}



