为了满足客户在不同场景下的数据开发和数据管控流程,WeData 项目空间管理提供了简单模式和标准模式。不同的项目模式会对应不同的引擎配置、数据管控和开发流程。本文将详细介绍 WeData 项目的两种模式。
使用前提
1. 当前功能为白名单功能,若您需使用可 提交工单 联系我们开白使用。
2. 在创建项目时可以看到项目模式的选择。同时,在项目基本信息中也可以看到项目模式,支持从 简单模式升级到标准模式。
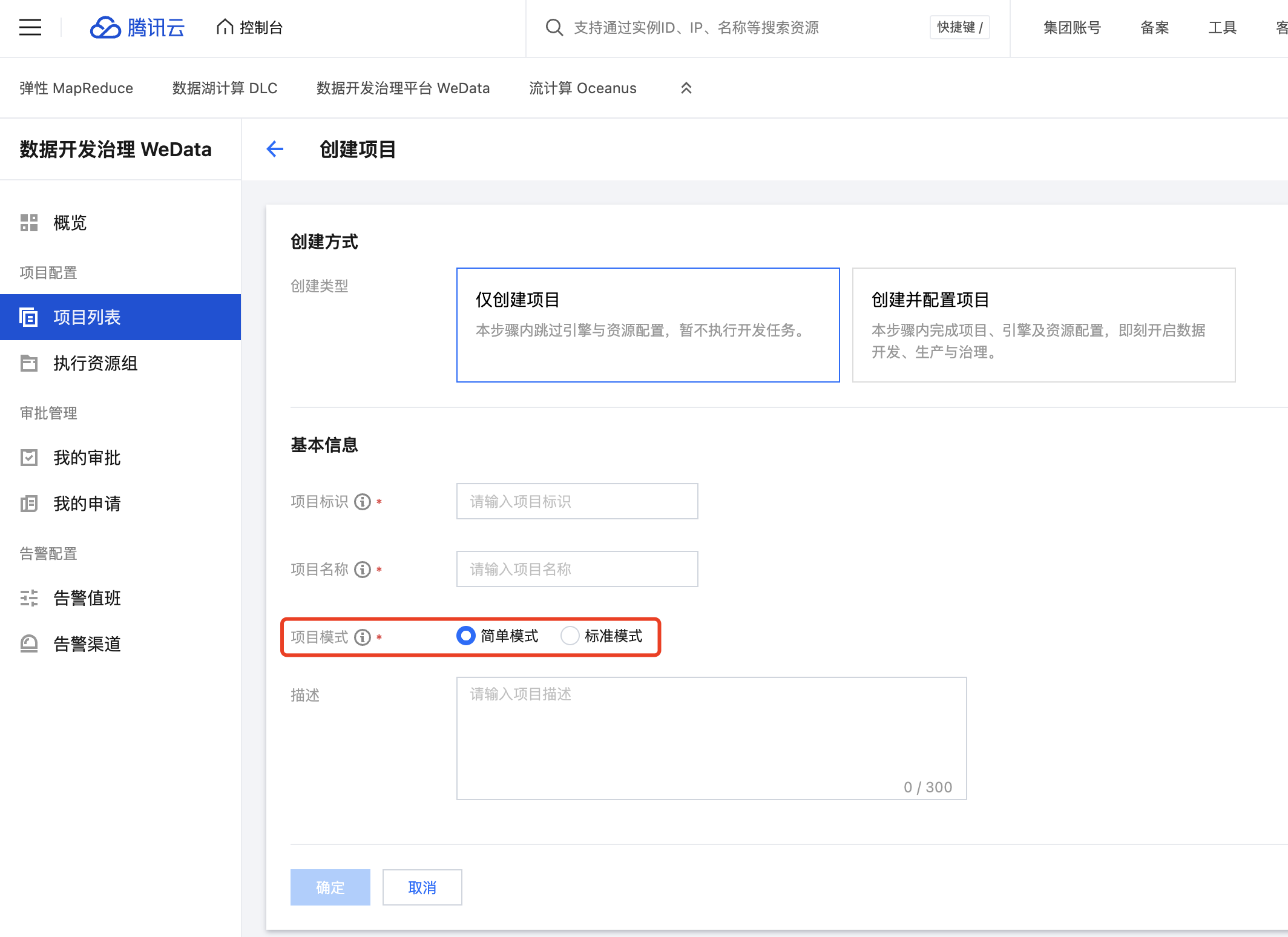
项目标准模式使用限制
注意:
1. WeData 项目标准模式绑定引擎时,开发环境和生产环境暂不支持绑定不同地域下的存算引擎实例。
2. WeData 项目标准模式,暂时不支持数据管理中数据表版本的管理和回滚等操作。因此在数据管理的可视化界面中开发环境删除表无法进行恢复操作。
3. WeData 项目标准模式开启以后不再提供跨项目克隆的功能。无法将标准模式项目的任务等对象通过跨项目克隆的方式发布到其他项目,也无法将其他项目的任务等对象通过跨项目克隆的方式发布到开启标准模式的项目中。
4. 针对 SQL 任务,暂时不支持 SparkSQL 和 Trino 的开发生产隔离。
两种模式的区别
下面分别从项目管理、任务开发流程、数据开发涉及的其他对象、数据集成等几个方面来对比两种模式的区别。
影响模块 | 简单模式 | 标准模式 |
项目管理 - 存算引擎配置 | 一个项目绑定的引擎默认只有一个环境,无开发环境和生产环境的区别。 | 一个项目绑定的引擎有两个环境配置:开发环境、生产环境。 目前支持一个地域下的两个引擎实例,或者一个引擎实例的两个数据库,例如,开发环境数据库设置为 db_dev,生产环境数据库设置为 db_prod。 |
项目管理 - 系统源 | 一个系统源自动生成一个数据源环境配置,无开发环境和生产环境的区别。 | 一个系统源自动生成一个数据源。 对应两个环境配置:开发环境配置、生产环境配置。 |
项目管理 - 自定义数据源 | 一个自定义数据源只对应一个环境配置,无开发环境和生产环境的区别。 | 一个自定义数据源对应两个环境配置:开发环境配置、生产环境配置。 |
项目管理 - 审批配置 | 默认开启任务提交审批,可以关闭。 | 默认关闭任务提交审批,默认开启发布审批配置,不可关闭。 |
任务开发流程 | 任务开发流程包括: 新建 > 开发 > 调试\\保存 > 提交 > 调度运维 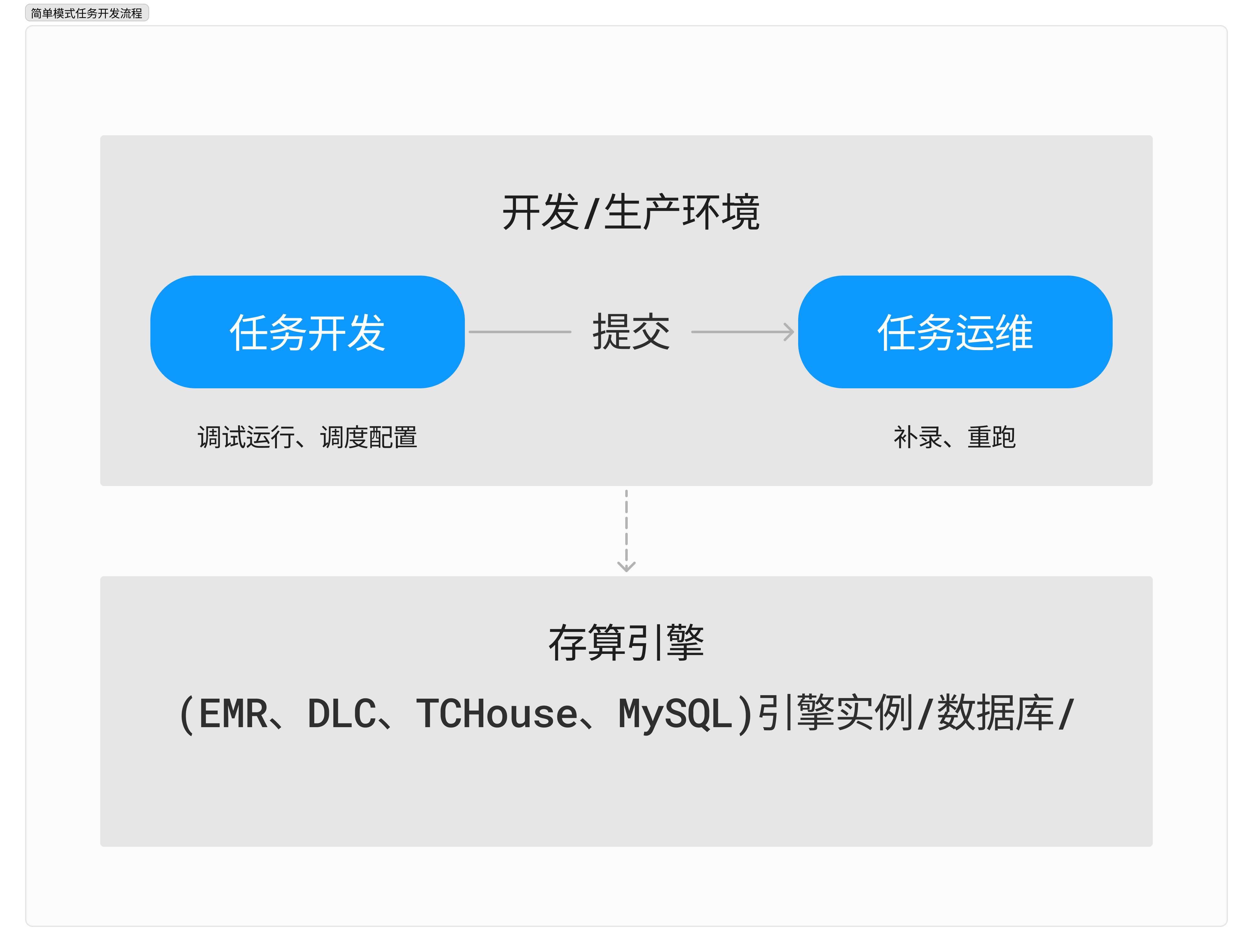 | 任务开发流程包括: 新建 > 开发 > 调试\\保存 > 提交 > 发布 > 调度运维。 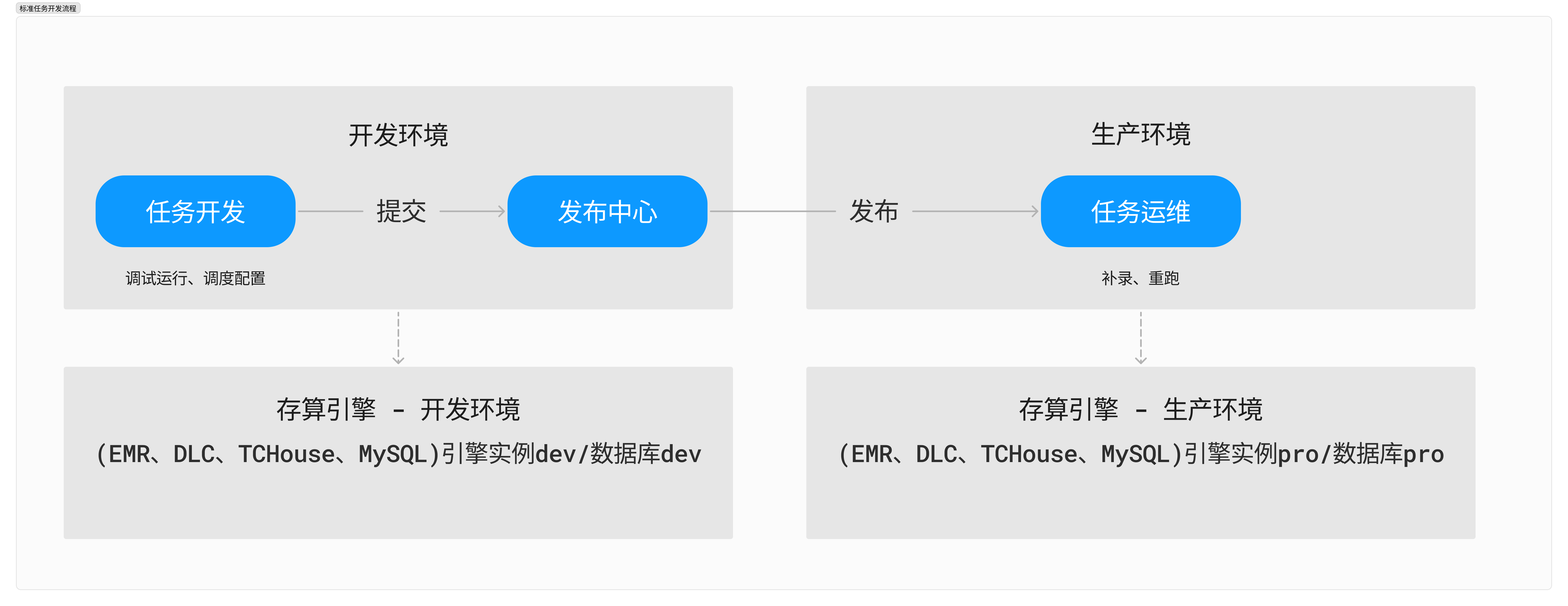 |
任务数据访问 | 使用项目管理中配置的身份来访问生产环境数据。 | 开发和生产环境可以使用不同的访问账号。 任务调试使用个人账号,调度运行可以使用统一指定的账号。 |
任务开发涉及其他对象 | 函数:提交后直接生效。 工作流、项目参数、资源、数据表保存后直接生效。 | 函数、数据表提交以后在开发环境实例\\数据库中生效,发布后在生产环境实例\\数据库中生效。 工作流、项目参数、资源上传后保存和提交后在开发环境中生效,发布后在生产环境中生效。 |
数据集成 - 离线同步 | 任务流程: 新建 > 开发 > 调试\\保存 > 提交 > 生产环境 开发调试使用数据源的环境配置,提交到调度后,仍然使用数据的环境配置。 | 任务流程: 新建 > 开发 > 调试\\保存 > 提交 > 生产环境 开发调试使用数据源的开发环境,提交到生产环境以后替换成数据源的生产环境。如果开发调试阶段配置的数据库不是数据源开发环境和生产环境的数据库,则不进行替换。 例如,开发环境数据库设置为 db_dev,生产环境数据库设置为 db_prod。 离线同步任务配置使用 db_dev,周期调度使用 db_prod。 离线同步任务配置使用 db_prod,周期调度使用 db_prod。 离线同步任务配置使用 db_other,周期调度依然使用 db_other。 注意: 当前项目的标准模式不会影响数据集成 > 离线同步任务开发流程。会影响编排空间 > 离线同步的任务开发流程。 |
数据集成 - 实时同步 | 任务: 新建 > 开发 > 调试\\保存 > 提交 > 生产环境 开发调试使用数据源的环境配置,提交到调度后,仍然使用数据的环境配置。 | 任务: 新建 > 开发 > 调试\\保存 > 提交 > 生产环境 开发调试使用数据源的生产环境配置,提交到生产环境以后仍然使用数据源的生产环境配置。 例如,开发环境数据库设置为 db_dev,生产环境数据库设置为 db_prod。 实时同步任务配置只能选择到 db_prod,实时任务提交后使用 db_prod。 实时同步任务配置使用 db_other,实时任务提交后使用 db_other。 注意: 当前项目的标准模式不会影响数据集成 > 实时同步任务的开发流程。 |
两种模式的适用场景
简单模式:适用于数据开发流程不需非常严格的小型数据开发团队,使用简单、快捷,数据开发、数据运维角色即可完成全部的数据开发和运维工作。
标准模式:适用于对数据开发流程要求更规范、生产环境数据权限要求更严格的中大型数据开发团队。开发过程更规范和安全,需要数据开发、数据运维和发布审批人一起协作完成数据开发和运维工作。
项目标准模式的配置方式和工作原理
标准模式在项目绑定引擎和创建数据源时,提供了开发环境和生产环境的配置,同时提供了访问开发环境和生产环境的账号配置。针对项目绑定的存算引擎,系统会根据引擎配置的信息自动生成数据源,数据源有自己的开发环境和生产环境的属性。一般情况下对应两个不同的 JDBC 的连接串。
下面以 EMR 的配置为例,做简单的说明。
1. 在存算引擎配置中设置开发环境和生产环境设置同样的 EMR 集群实例,设置不同的数据库。例如,开发环境数据库为 wedata_dev,生产环境数据库为 wedata_pro。同时开发环境账号默认为任务运行映射的 EMR 账号,生产环境访问账号为指定子账号映射的 EMR 账号。
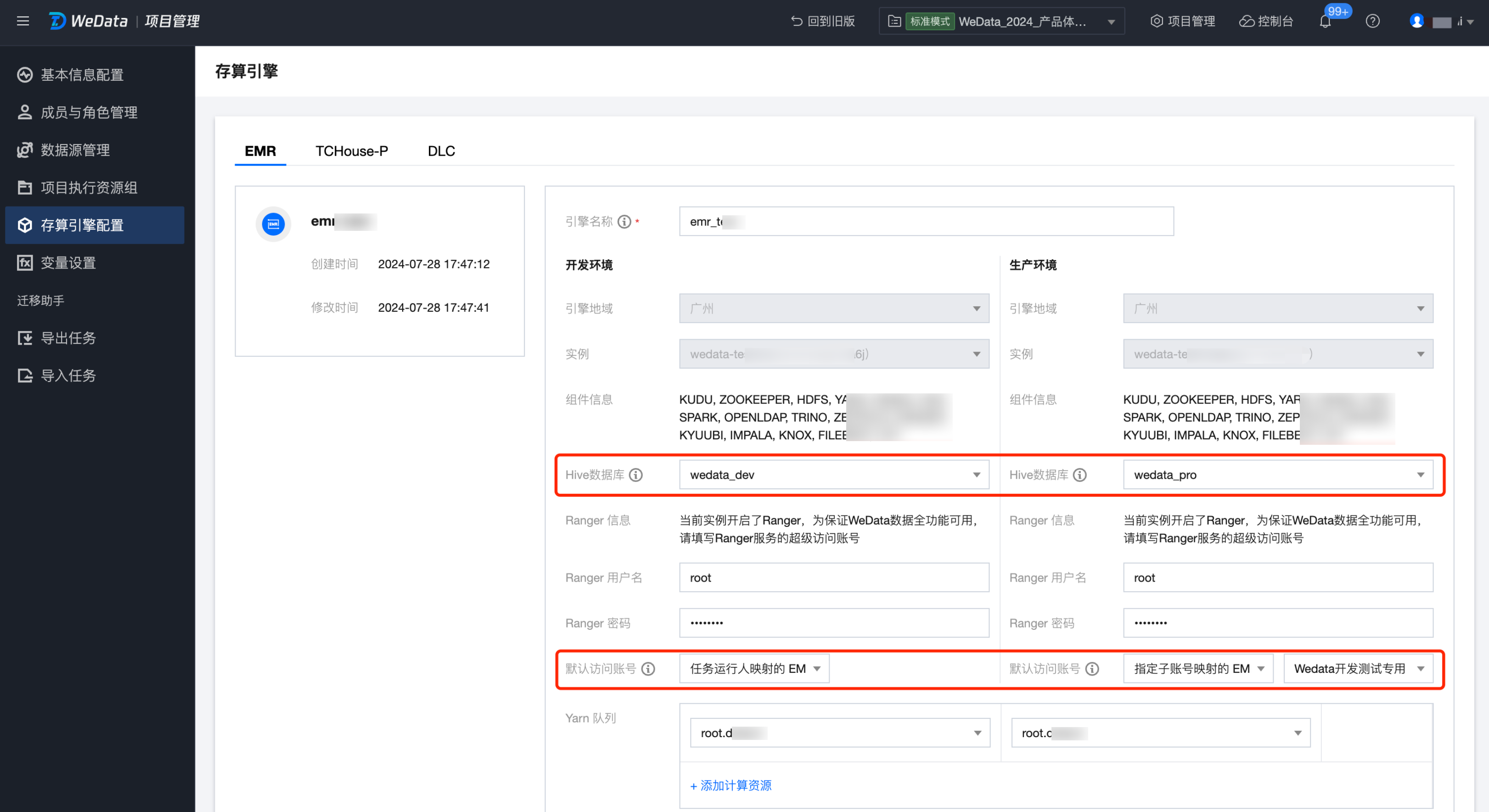
也可以将开发环境和生产环境设置为不同的 EMR 集群实例、相同的数据库。例如,开发环境引擎实例为 wedata_dev,生产环境引擎实例为 wedata_pro,数据库均为 default 数据库。同时开发环境账号默认为任务运行映射的 EMR 账号,生产环境访问账号为指定子账号映射的 EMR 账号。
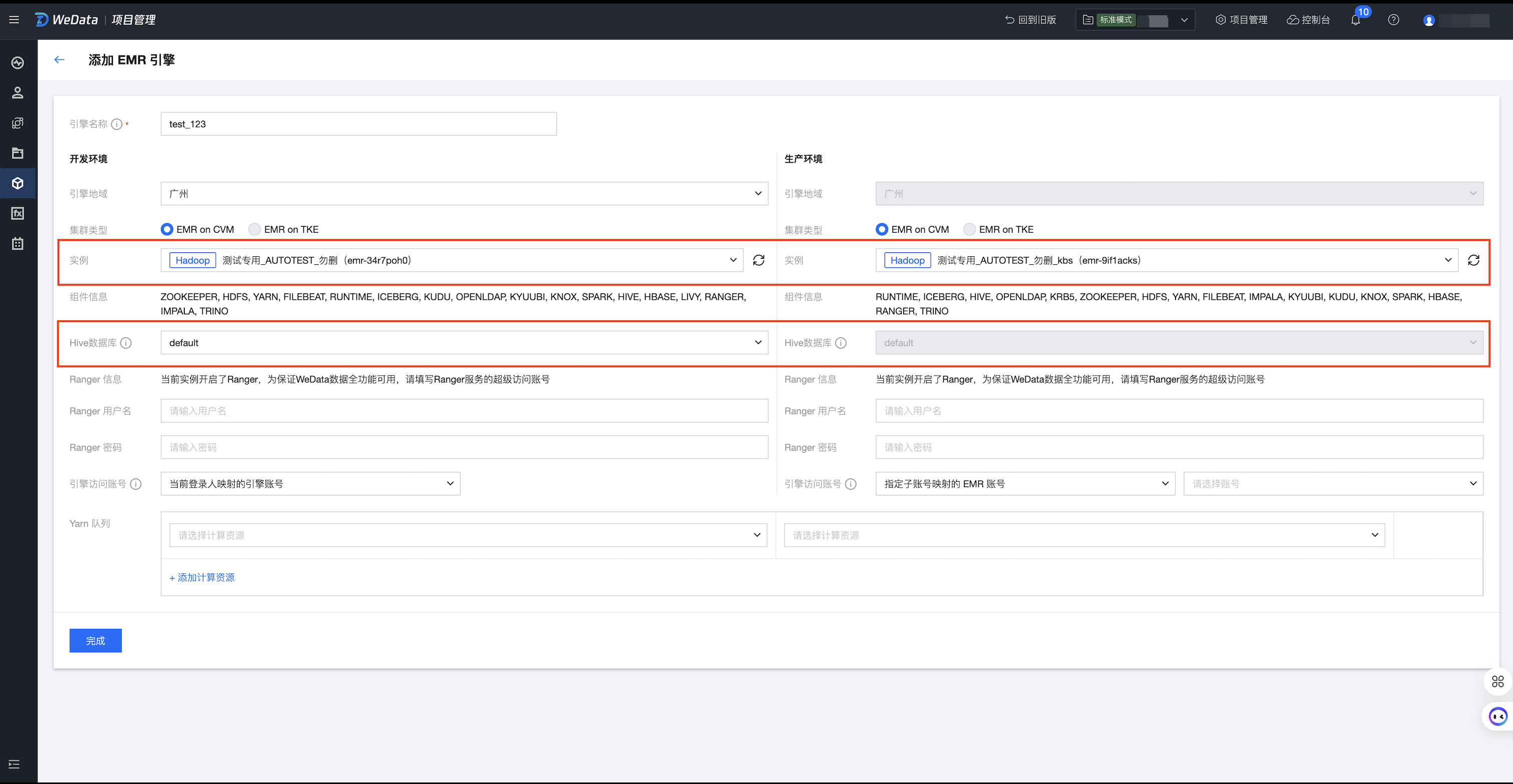
2. 根据上面的引擎配置,默认生成系统数据源。由于开发和生产环境对应的集群一致,数据库不一致,所以生成的 Hive 数据源样例如下:
开发环境:
jdbc:hive2://ip:port/wedata_dev生产环境:
jdbc:hive2://ip:port/wedata_pro3. 在编排空间的 HiveSQL 任务开发和测试运行时,会使用数据源的开发环境配置(
jdbc:hive2://ip:port/wedata_dev),使用的账号是运行人对应的 EMR 账号。任务进行提交和发布以后,在任务运维中的周期调度时,会使用数据源的生产环境配置(jdbc:hive2://ip:port/wedata_pro),使用的账号是生产环境中配置的指定子账号。4. 因此,在 HiveSQL 的 SQL 语句中,如果不写对应的数据库名称,开发和测试运行时会自动读取\\写入 wedata_dev 数据库,在周期调度时会自动读取 \\ 写入 wedata_pro 数据库。从而达到在开发阶段使用开发数据库、生产阶段使用生产数据库的目的。
insert into user_infoselect * from table_1-- 调试运行读取wedata_dev.table_1的数据,写入wedata_dev.user_info-- 周期运行读取wedata_pro.table_1的数据,写入wedata_pro.user_info
5. 如果在 HiveSQL 的 SQL 语句中,写了对应的数据库,则仍然使用 SQL 语句中的数据库,则不能起到开发环境和生产环境隔离的效果。
insert into other_db.user_infoselect * from other_db.table_1-- 调试运行读取other_db.table_1的数据,写入other_db.user_info-- 周期运行读取other_db.table_1的数据,写入other_db.user_info
注意:
目前 WeData 编排空间的 SQL 任务类型中,SparkSQL 任务的 Hive 数据源、Trino 任务暂时不能通过上面的方式实现开发和生产环境的隔离,建议使用项目参数的形式实现开发和生产环境的隔离。
简单模式升级到标准模式
WeData 提供了将项目简单模式升级到标准模式的功能,用户可以将已有的简单模式项目升级到标准模式。升级过程不可逆,请谨慎评估和操作。
1. 在 WeData 项目管理 > 基本信息配置 > 项目模式属性中,可以查看当前项目的模式,如果是简单模式,单击旁边的升级到标准模式可以进行升级。
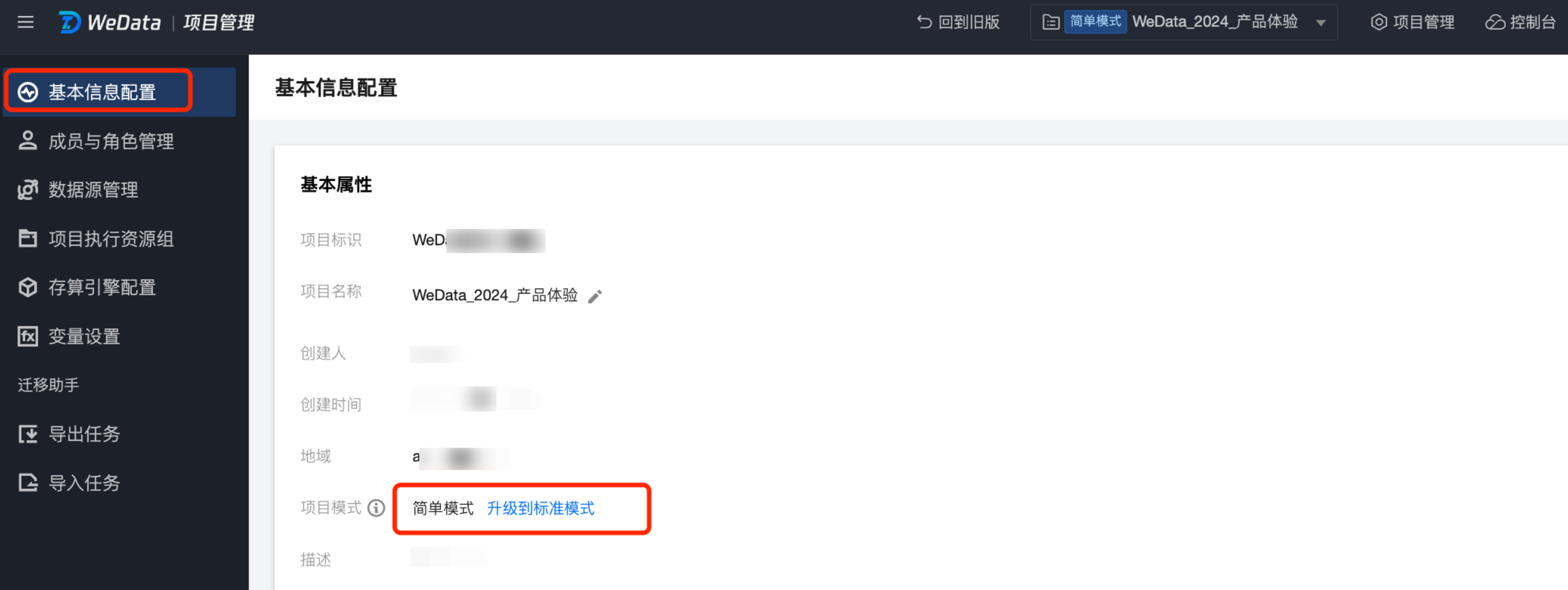
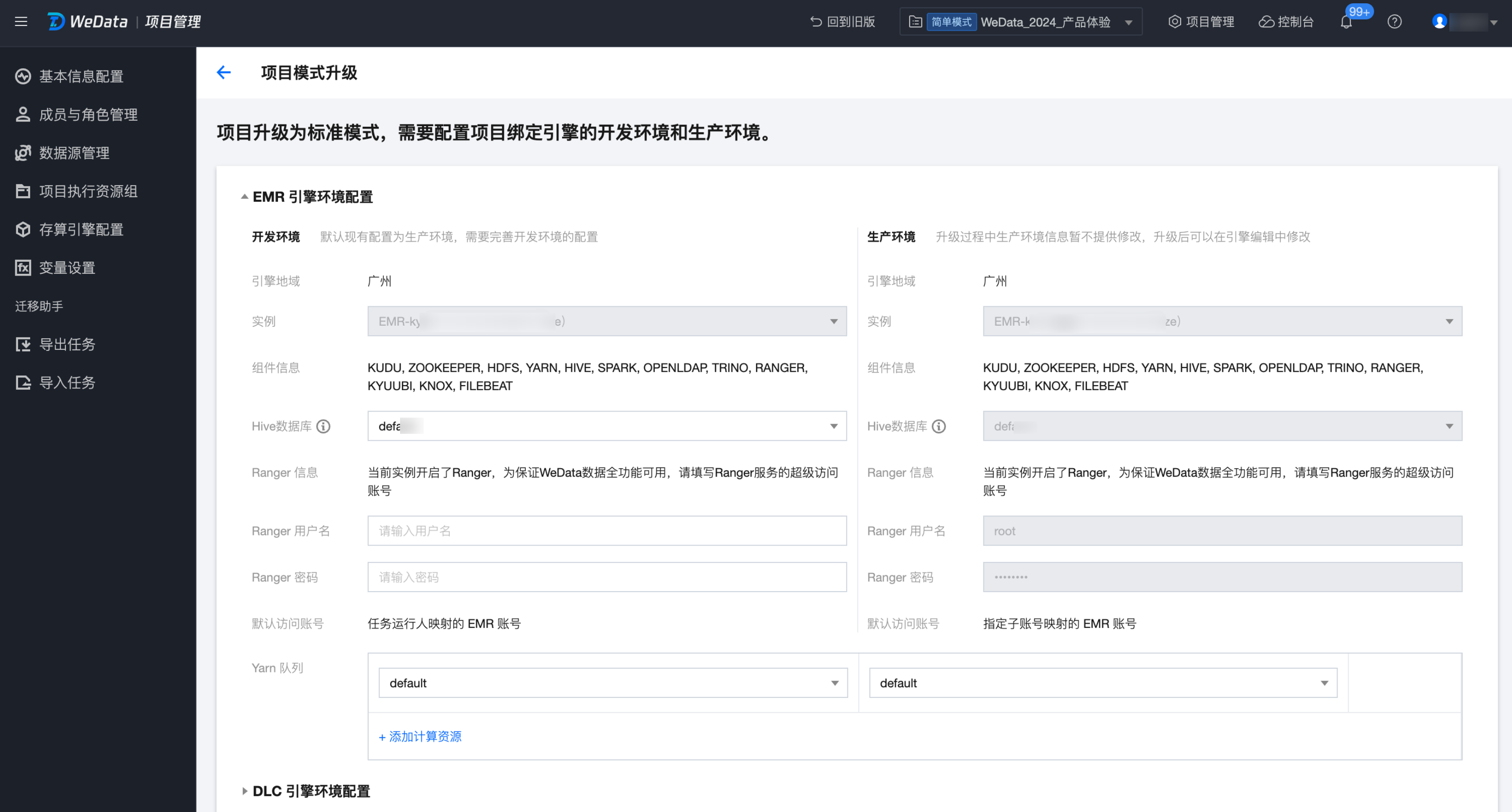
2. 升级前会进行升级条件的校验,校验通过后进入升级页面。下图分别是 EMR、DLC 以及自定义数据源的升级界面。
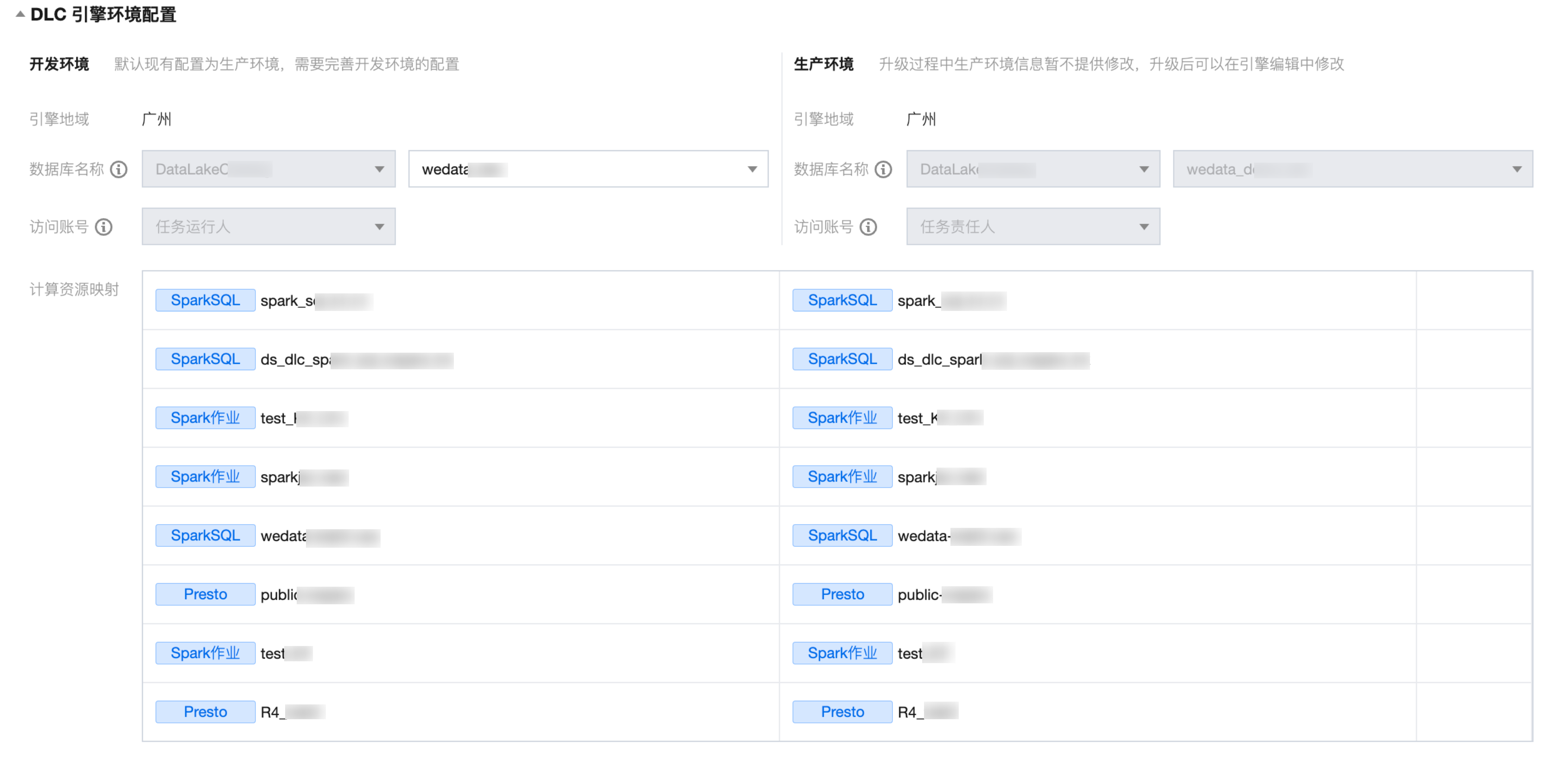
DLC 引擎环境配置:
EMR 数据源环境配置:
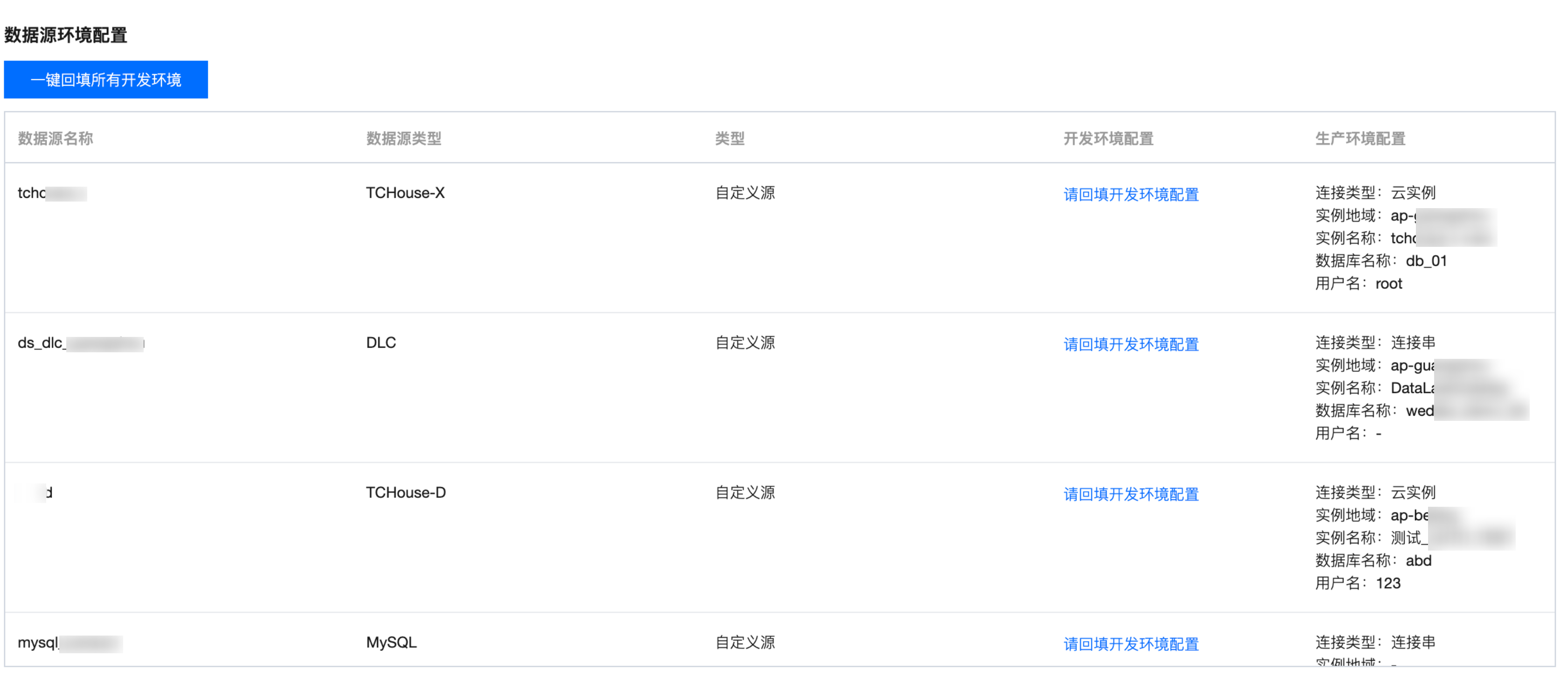
3. 完善和确认升级过程中的必填参数,其中必填参数包括存算引擎开发环境的配置、确认回填数据源开发环境配置、勾选同意升级的复选框,单击升级按钮完成升级。升级过程的时间依赖于项目中存算引擎和数据源的数量。
升级注意事项
注意:
1. 升级前系统会自动检测当前项目是否满足升级条件,升级条件满足才可以进行升级。
2. 升级过程中会将项目当前存算引擎配置信息默认设置为生产环境配置,用户需要填写开发环境配置;同时,会将项目当前数据源的配置信息默认设置为数据源的生产环境配置,用户需要确认一键回填开发环境配置信息后才能正常升级。
3. 升级后跨项目克隆功能不再提供新建功能,历史的克隆信息会保留。升级的项目也不能再作为跨项目克隆的目标项目。
4. 升级后默认会关闭任务提交的审批,开启任务等对象的发布审批,不可关闭。
5. 升级过程不可逆,升级后无法再回到简单模式。



