使用场景
For-each 节点一般的使用场景是通过循环遍历上游节点传递的参数,实现 For-each 节点内部的业务逻辑。下文将介绍 For-each 节点的使用场景、使用限制、配置方式、内置参数、使用示例。
For-each 节点的使用场景通常是将上游任务的结果作为参数传递到 For-each 节点,For-each 节点循环执行对上游的参数进行遍历。

使用限制
注意:
For-each 节点的最大循环次数为128次,实际循环次数依赖上游输出参数的行数。
循环执行为串行执行,上一个执行完,才会执行下一个。
配置方式
创建 For-each 节点
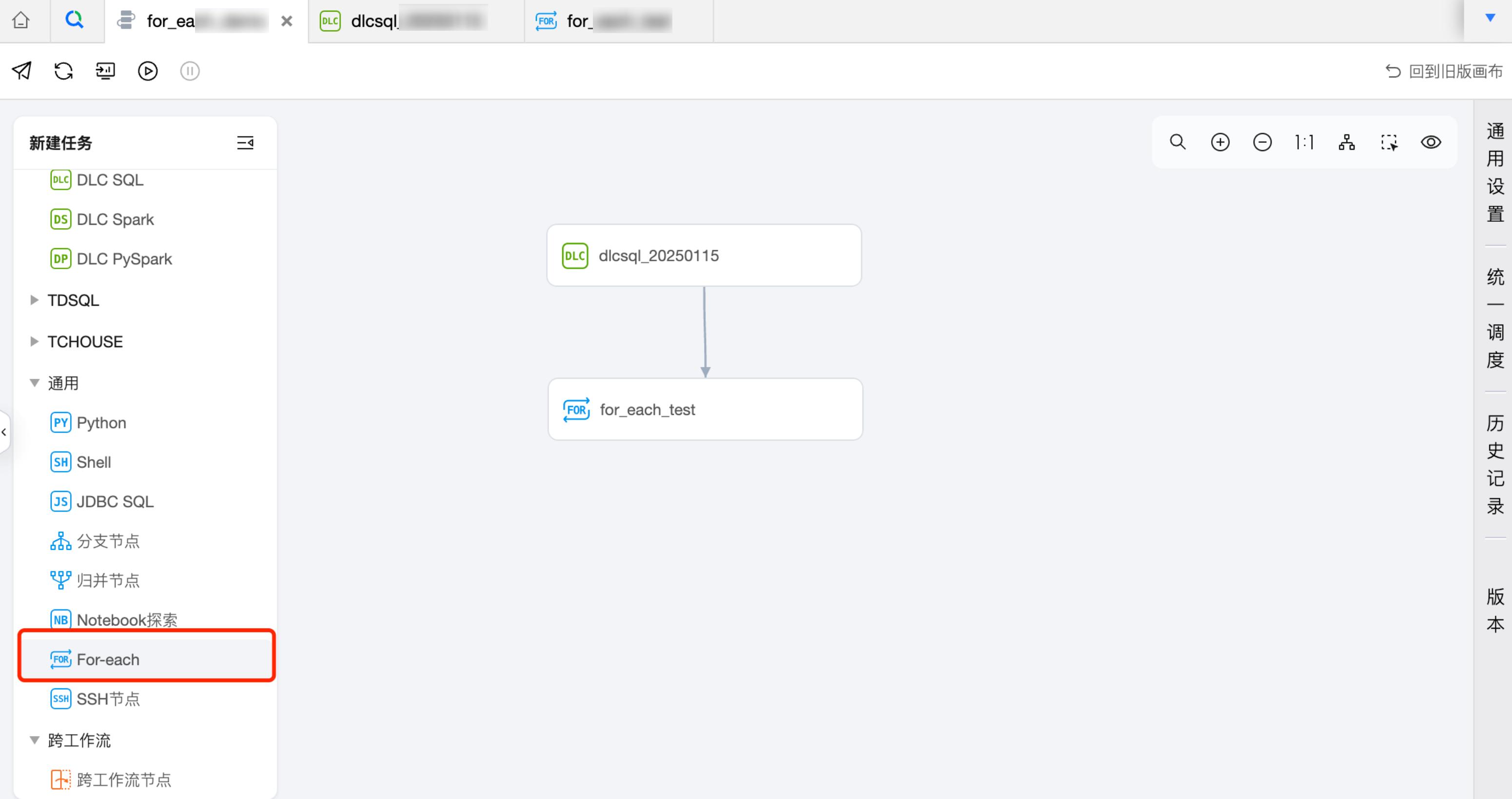
1. 在新建任务列表,任务类型选择通用 For-each 节点。
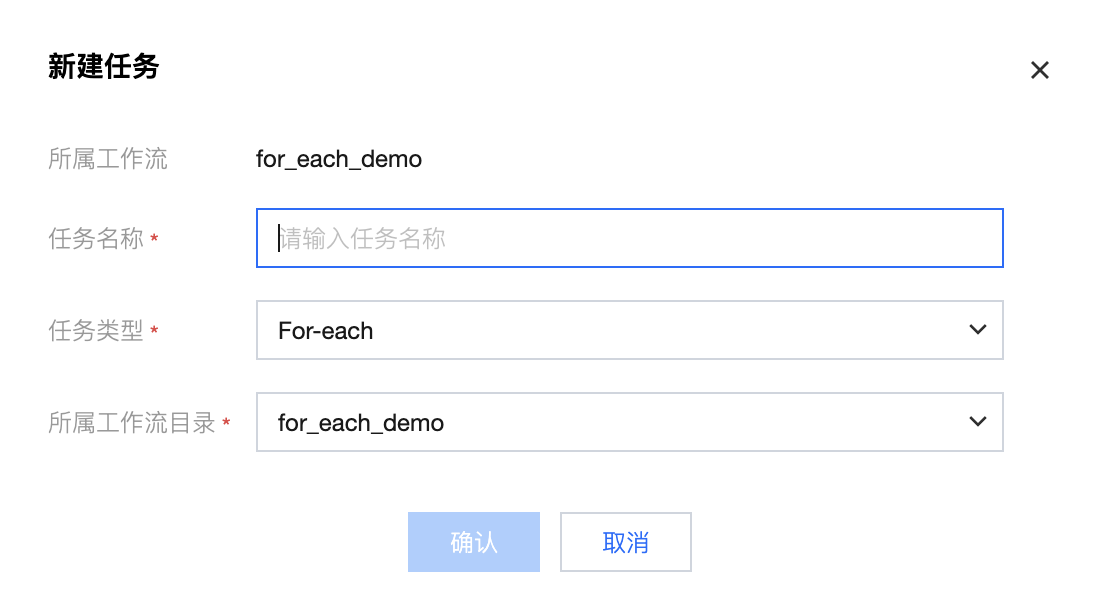
2. 进入新建任务弹窗中,填写任务名称、所属工作流等信息,单击确认。
配置 For-each 节点
For-each 节点的配置页类似一个工作流配置页面,下面具体介绍功能。
上方操作栏
包含保存、提交、锁定、刷新、项目参数、任务运维、实例运维、配置调度资源组等操作。
注意:
For-each 节点不提供测试运行、高级运行、终止运行等操作,若需要验证 For-each 节点是否符合预期,可在配置好后提交到运维中心进行测试执行。
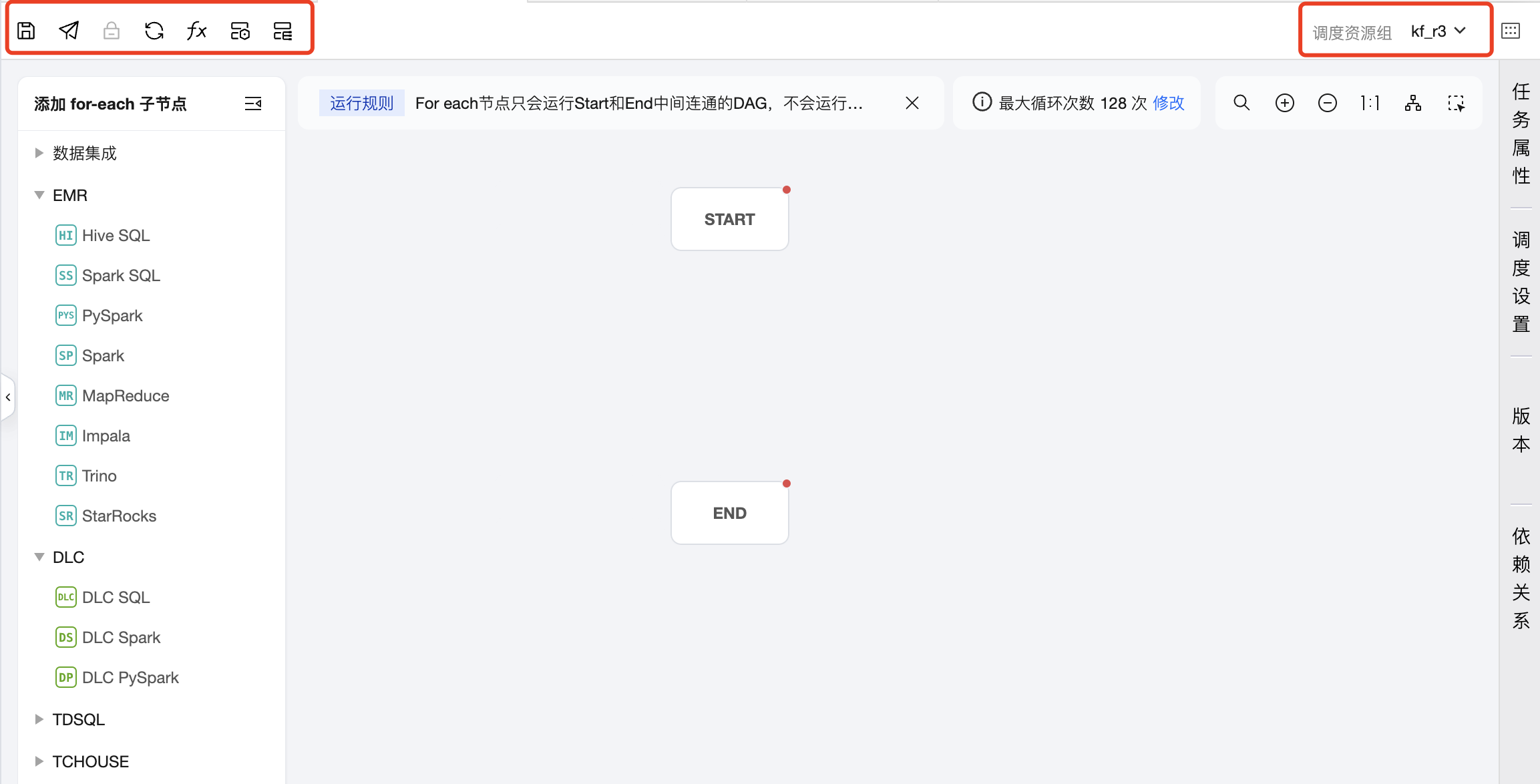
新建子节点区域
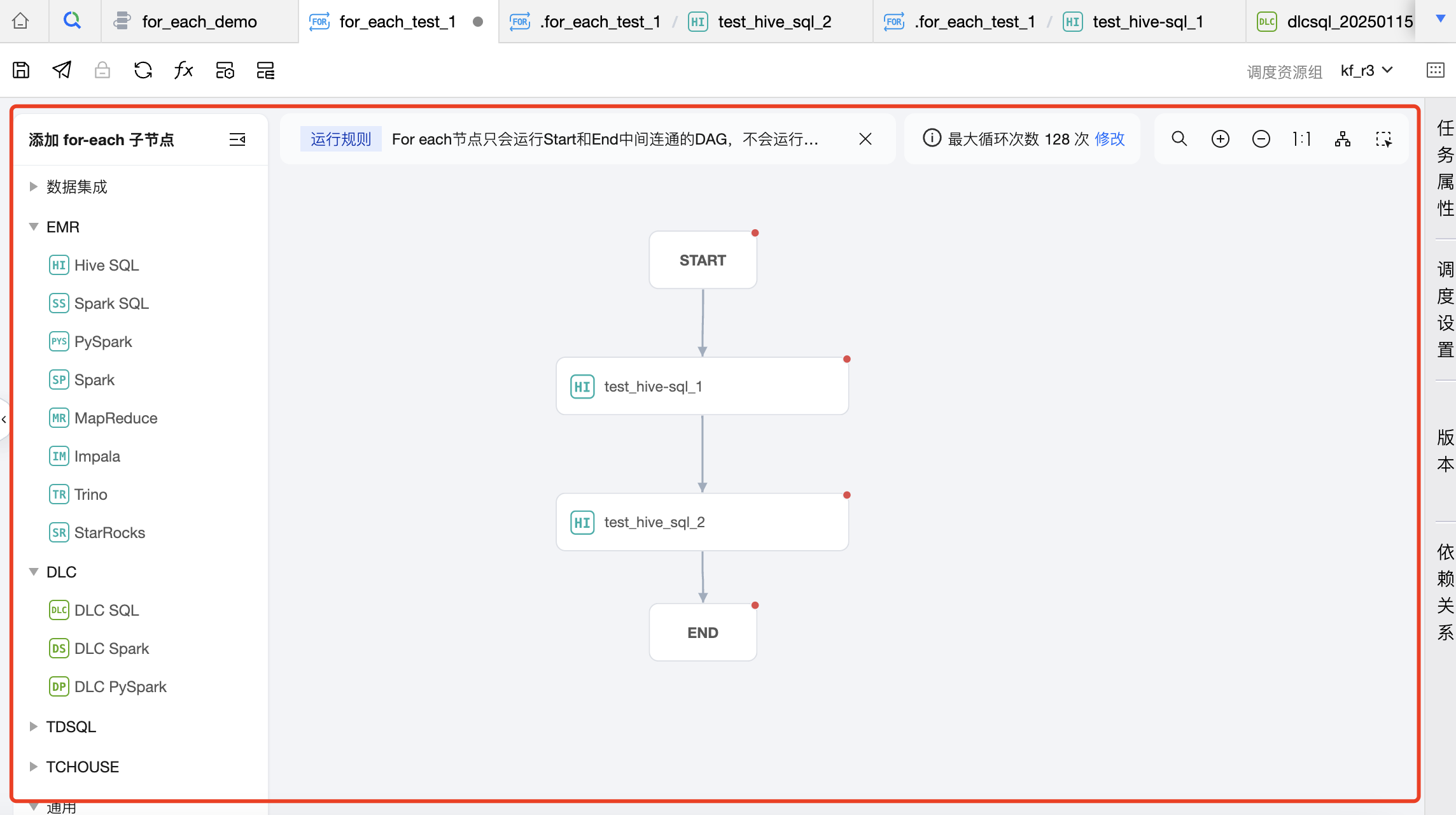
中间区域:用于创建和编排 For-each 节点的子节点,即循环的主体内容,除 For-each、跨工作流节点、分支节点、归并节点外,其余节点都可以作为 For-each 节点的子节点。
任务类型:单击左侧任务类型可添加子节点,在画布区域可以对子节点进行编排,并建立上下游关系。For-each 节点只会运行 START 和 END 中间连通的 DAG,不会运行非连通或者分叉的 DAG 部分,因此需要将想循环执行的节点放在 START 节点和 END 节点中间,并进行连线。
说明:
可在画布上设置循环次数,默认循环128次,可按需调整,最大循环次数不能超过128次。若实际运行时循环次数超过128次,则超出的执行将被置为失败。实际循环次数依赖上游输出参数的行数。
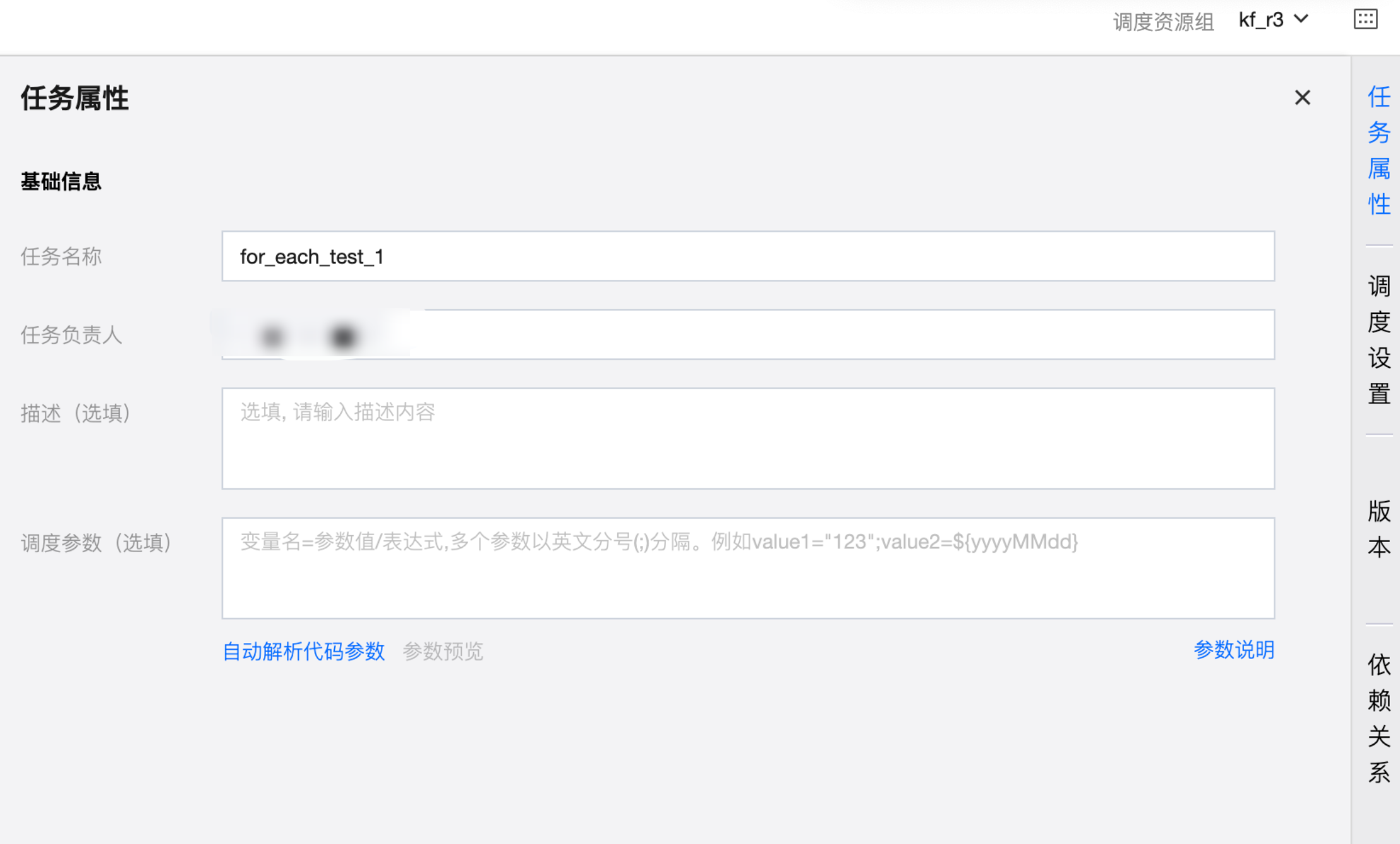
右侧抽屉-任务属性
配置任务基本信息,包含任务名称、任务负责人、描述和调度参数。
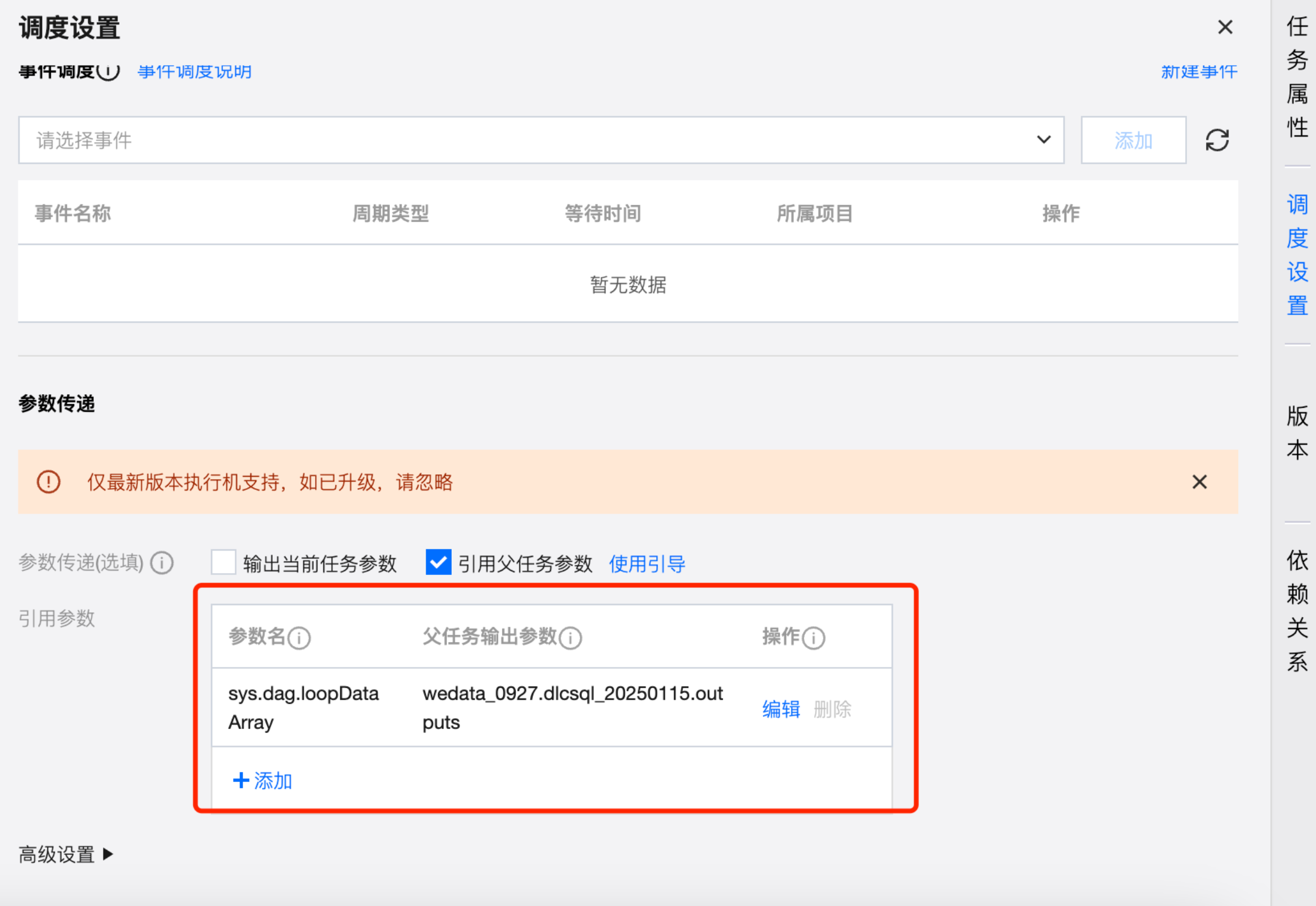
右侧抽屉-调度设置
For-each 节点的调度设置与其他任务类型基本相同,支持为节点配置调度策略、上游依赖、事件依赖、参数传递、高级配置。
说明:
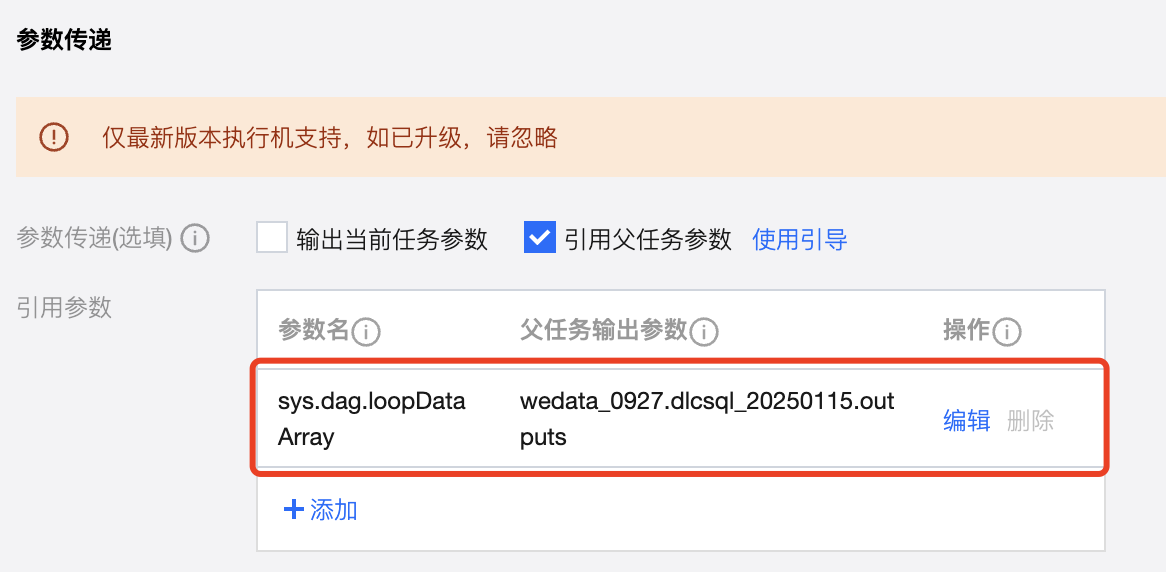
其中参数传递默认需要从上游获取传递的参数,且默认参数名称为:sys.dag.loopDataArray。该参数用于运行时的循环遍历,若未配置则任务将无法提交。
右侧抽屉-版本/依赖关系
当前版本管理中暂未支持 For-each 节点任务配置的查看,仅支持查看任务属性信息。
依赖关系中支持查看 For-each 节点的上下游关系。
配置 For-each 节点中的子节点
在 For-each 节点的 DAG 图中,单击子节点即可进入子节点配置页面。子节点的名称会展示为 For-each 节点名称/子节点名称。子节点的配置与其他基础任务类型的配置基本相同,以下仅介绍差异部分:
上方操作栏
操作栏中没有跳转到任务运维和实例运维的入口,因为子节点在运维中心没有独立的运维页面,仅可对 For-each 节点进行运维。
操作栏提供了打开上级节点的功能,即在子节点操作即可打开对应的 For-each 节点。
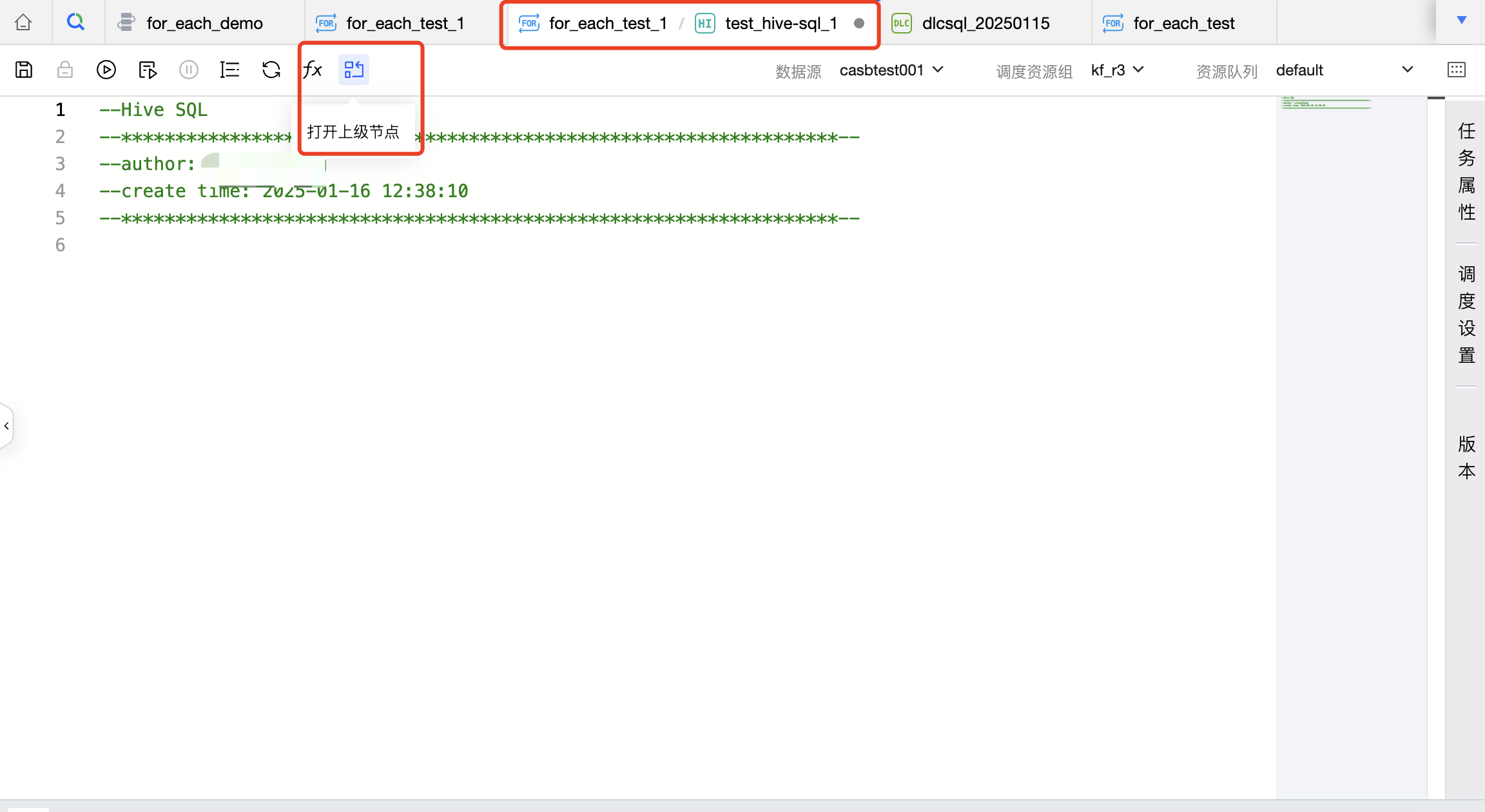
调度配置
因为 For-each 的子节点会遵循 For-each 节点的调度配置执行,因此 For-each 的子节点无需单独配置调度策略。
For-each 的子节点的调度设置支持配置上游任务和参数传递。
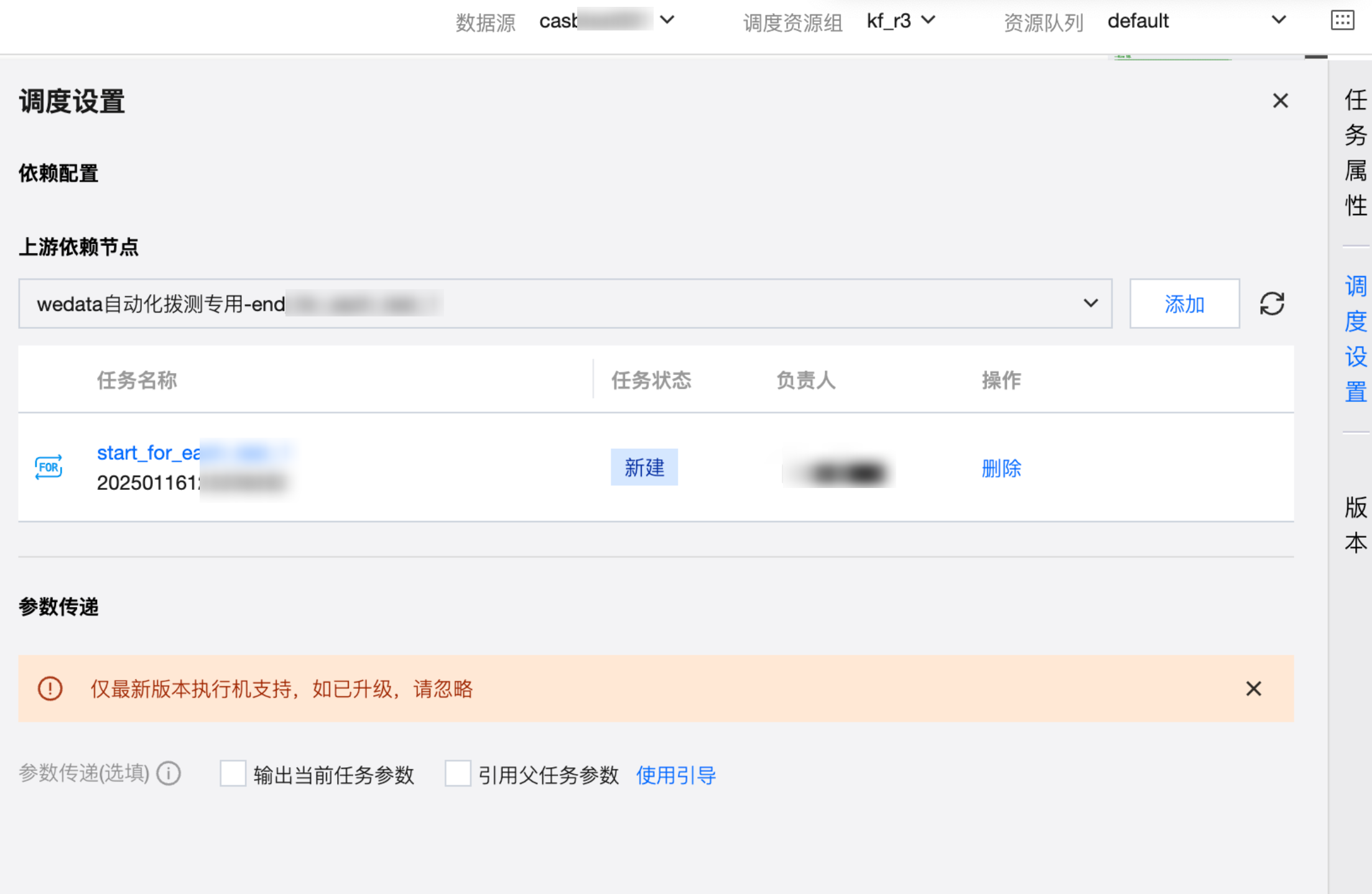
提交到调度
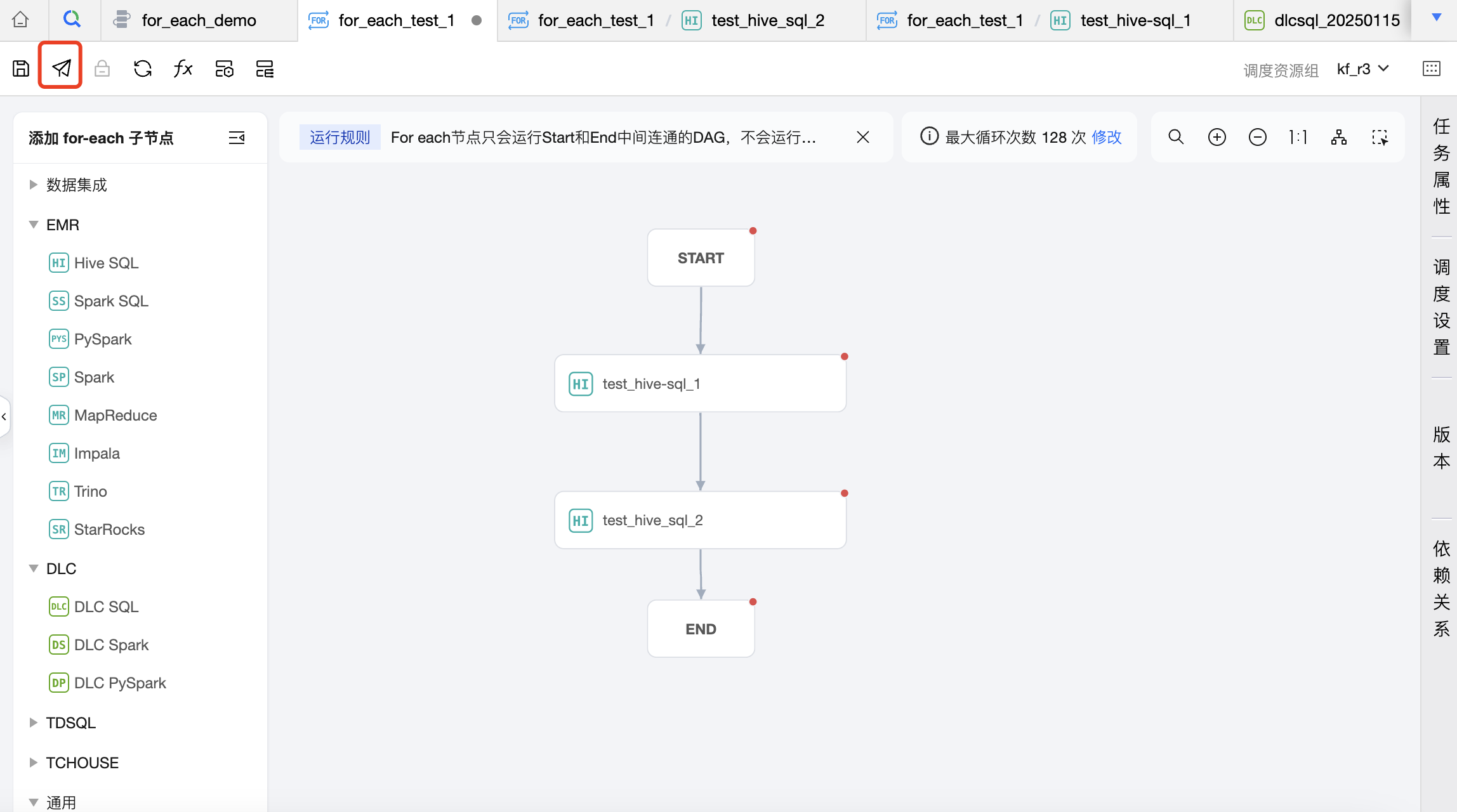
您可在 For-each 节点或 For-each 节点所在工作流中操作提交,提交到调度后的任务将按照调度配置进行周期执行。
For-each 节点操作入口:
For-each 节点所在工作流操作入口:
内置参数
参数介绍
在For-each 任务中的子节点中,可以使用内置参数来获取上游任务传递过来的数组。For-each 节点接收到的参数需为二维数组或者一维数组或者单个值的格式,否则任务会执行失败。
上游传递的参数名称为 sys.dag.loopDataArray,该参数配置方式如下图。
假设上游节点传递的参数值为二维数组,一共三行、四列数据,列分别表示 ID、姓名、年龄和性别。具体如下表:
001 | Jack | 21 | 男 |
002 | Helen | 22 | 女 |
003 | Emily | 23 | 女 |
在子节点中可用参数如下:
内置参数名称 | 参数含义 | 基于上表参数返回的值为 |
${sys.dag.loopDataArray} | 获取赋值节点的数据集 | [["001","Jack","21","男"],["002","Helen","22","女"],["003","Emily","23","女"]] |
${sys.dag.foreach.current} | 获取当前遍历值,即获取当次循环对应行的数据 | 第一次循环: ["001","Jack","21","男"] 第二次循环: ["002","Helen","22","女"] 第三次循环: ["003","Emily","23","女"] |
${sys.dag.loopTimes} | 获取当前遍历次数,即从1开始计算,获取当次循环对应的是第几次循环 | 第一次循环: 1 第二次循环: 2 第三次循环: 3 |
${sys.dag.offset} | 当前偏移量,即从0开始计算,获取当次循环对应的是第几次循环 | 第一次循环: 0 第二次循环: 1 第三次循环: 2 |
${sys.dag.foreach.current[n]} | 上游赋值节点的输出结果为二维数组时,每次遍历时获取当前数据行的n列的数据。(n从0开始) 上游赋值节点的输出结果为一维数组时,获取n列数据。(n从0开始) | 第一次循环:${dag.foreach.current[0]}: 001 第二次循环:${dag.foreach.current[1]}: Helen 第三次循环:${dag.foreach.current[2]}: 23 |
${sys.dag.loopDataArray[n][m]} | 上游赋值节点的输出结果为二维数组时,获取数据集中具体n行m列的数据。(n、m从0开始) | ${dag.loopDataArray[0][0]}: 001 ${dag.loopDataArray[2][3]}: 女 |
参数使用示例
下面介绍以上参数在子节点中是如何使用的,内置参数目前支持在脚本任务、离线集成任务、非脚本类任务中使用。
适用子节点任务类型 | 说明 | 使用示例 |
脚本类子节点 | 可直接在 SQL 脚本中使用上述内置参数。 |  |
离线集成子节点 | 所有输入框都可以支持系统变量使用。 例如:来源和目标库、来源和目标表、筛选条件、高级参数、前置 SQL、后置 SQL、COS 路径。 | 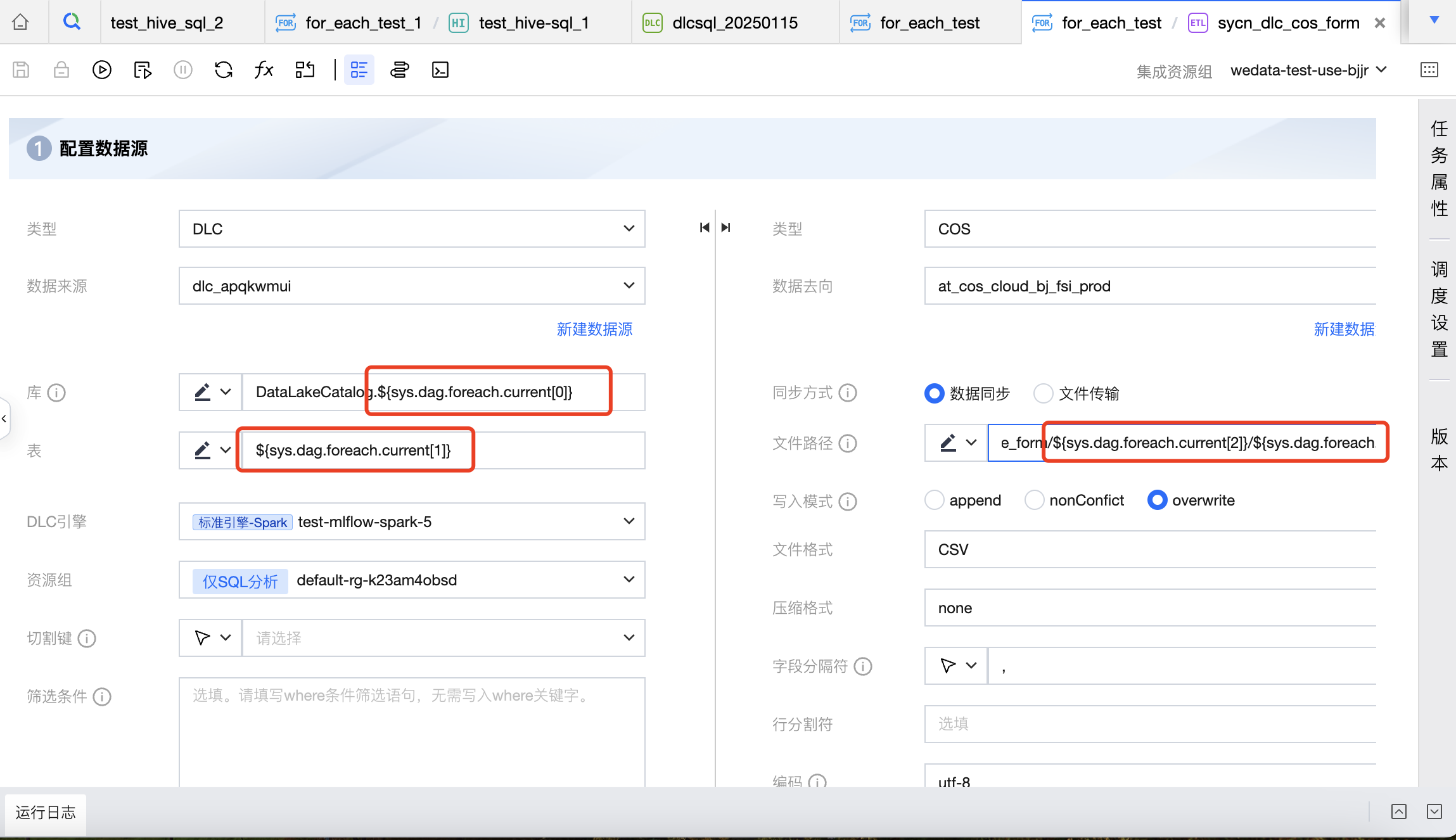 |
非脚本类子节点 | 非脚本任务节点:EMR-Spark、TCHouse-X、DLC Spark、DLC PySpark、MapReduce支持使用内置变量,具体可配置项为: EMR-Spark-jar:程序入口参数、应用参数、作业参数。 EMR-Spark-zip:执行参数、应用参数 TCHouse-X:程序入口参数、作业参数 DLC Spark:程序入口参数 DLC PySpark:入口参数、依赖资源、conf 参数 MapReduce:输出目录、命令行参数 | 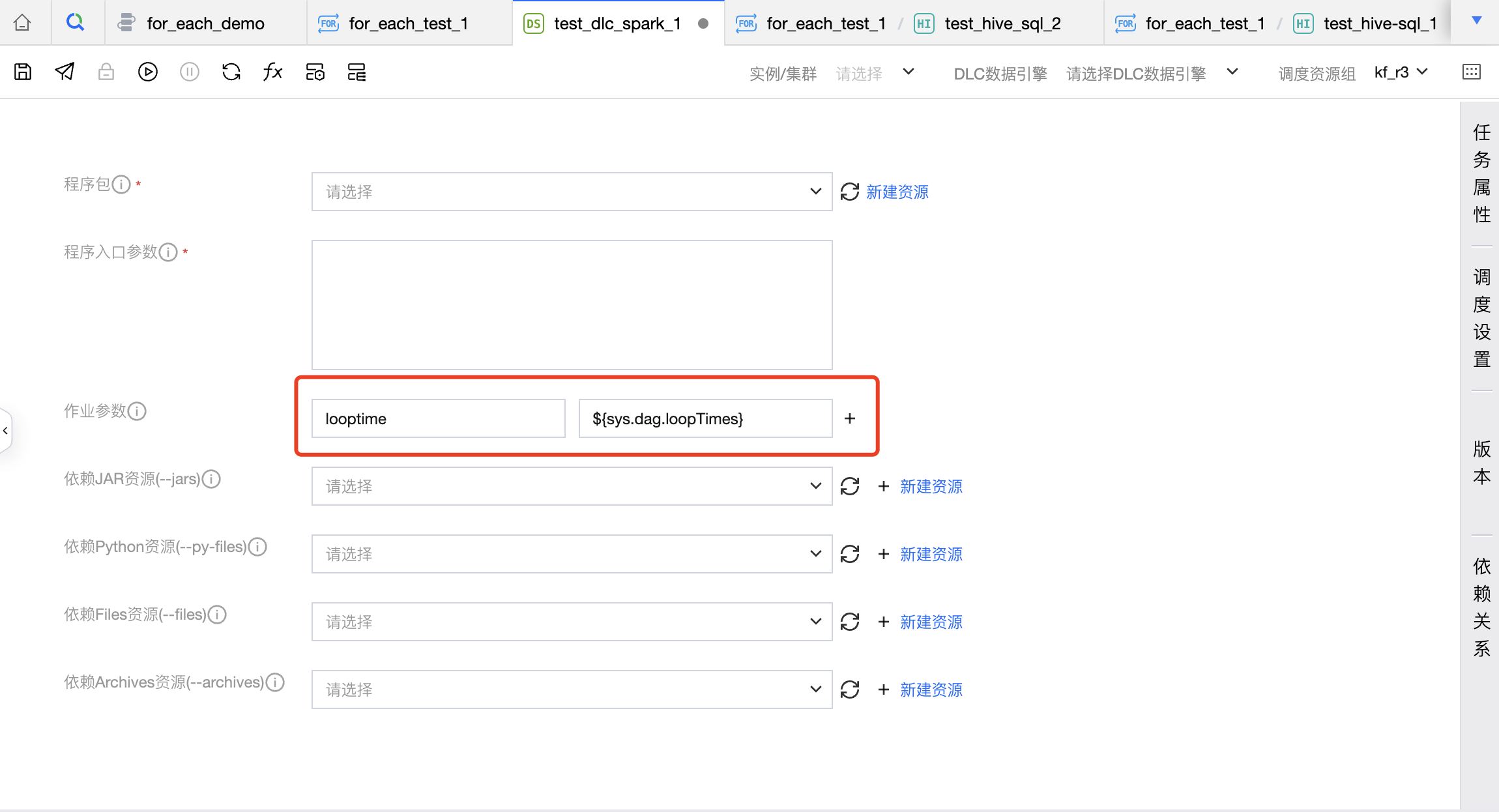 |
使用示例
业务场景
不同城市的数据存在不同的 DLC 表中,用户期望将这些数据同步到不同的 COS 文件中。若不使用 For-each 节点,有几个城市,则用户需配置几个数据集成任务,任务配置效率较低。
若使用 For-each 节点,可以将来源 DLC 表的信息和去向 COS 文件的信息放在一张表中,配置一个任务将表信息作为参数传递给 For-each 节点。然后在 For-each 节点中读取参数,并使用内置参数配置数据集成任务,即可实现用户预期的效果。下面介绍具体的配置方式。
第一步:配置上游任务,获取数据集成任务表来源和去向信息,并传递参数到下游。
1. 建立周期任务工作流,详细操作步骤请查看 周期工作流通用开发流程。
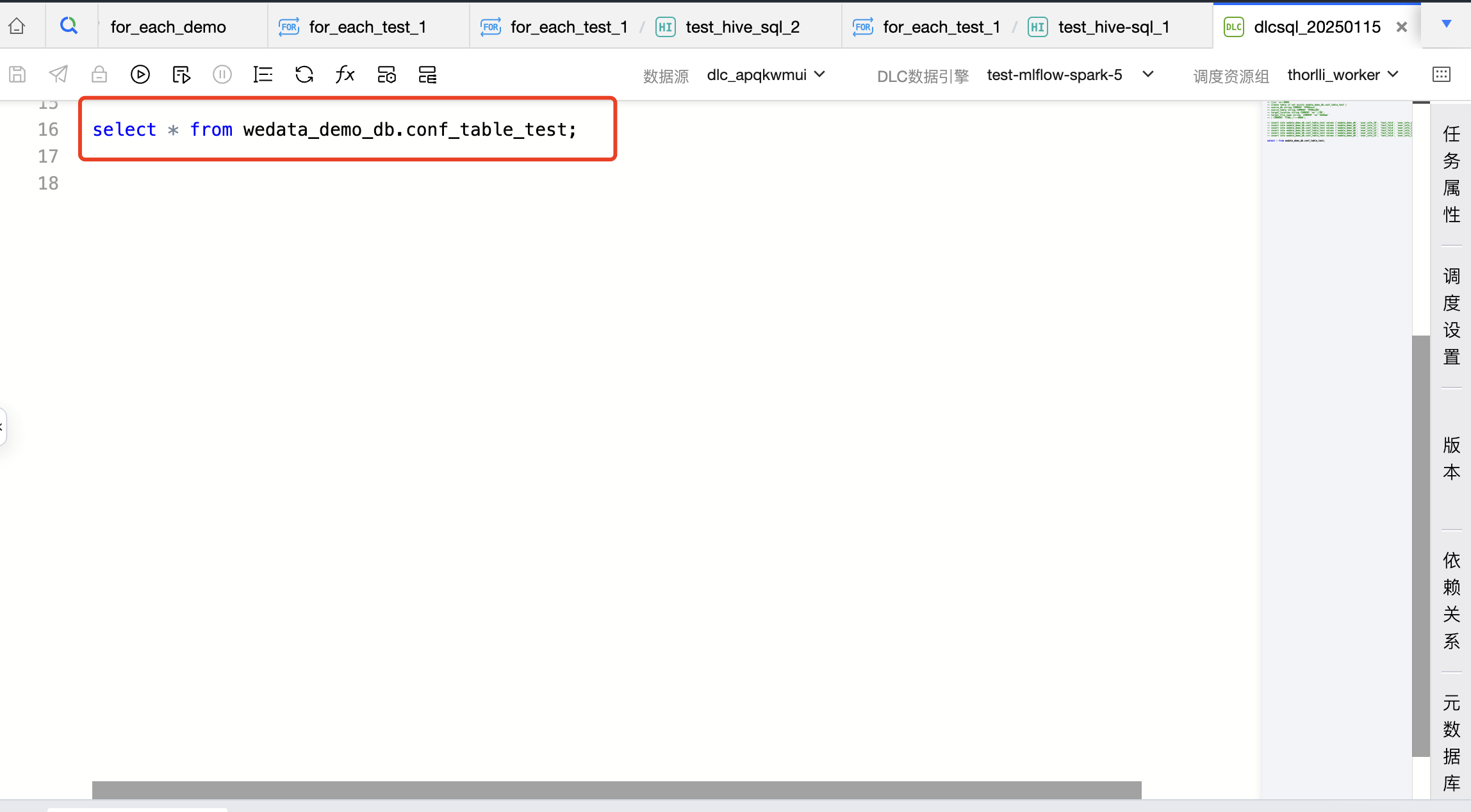
2. 将数据集成来源库信息、来源表信息、去向库信息、去向表信息存储在一张 DLC 表 wedata_demo_db.conf_table_test 中。创建一个 DLC SQL 任务,在 DLC SQL 任务中读取表 wedata_demo_db.conf_table_test 中的数据。
代码如下:
select * from wedata_demo_db.conf_table_test;
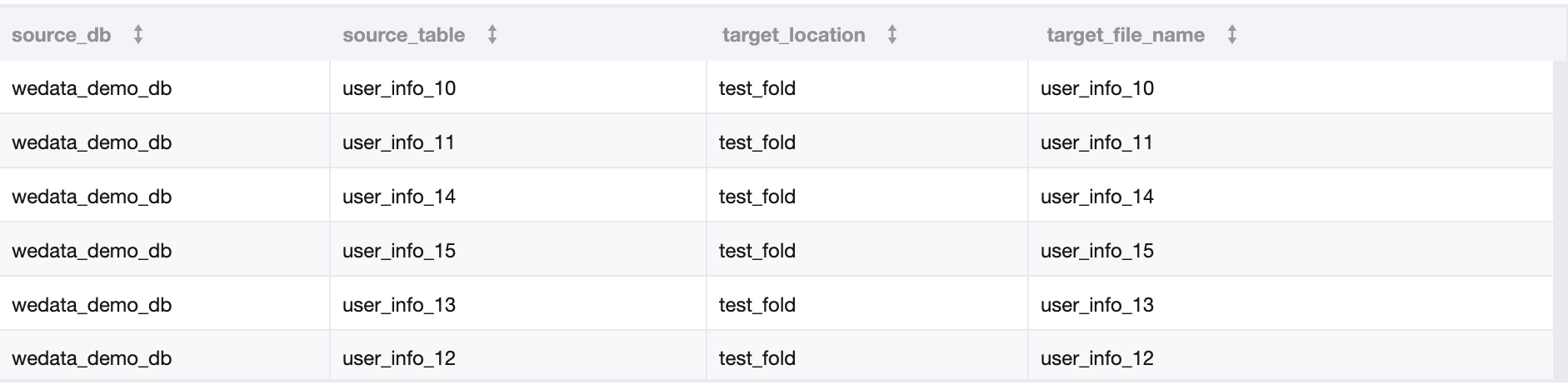
3. 表 A 中的数据如下:
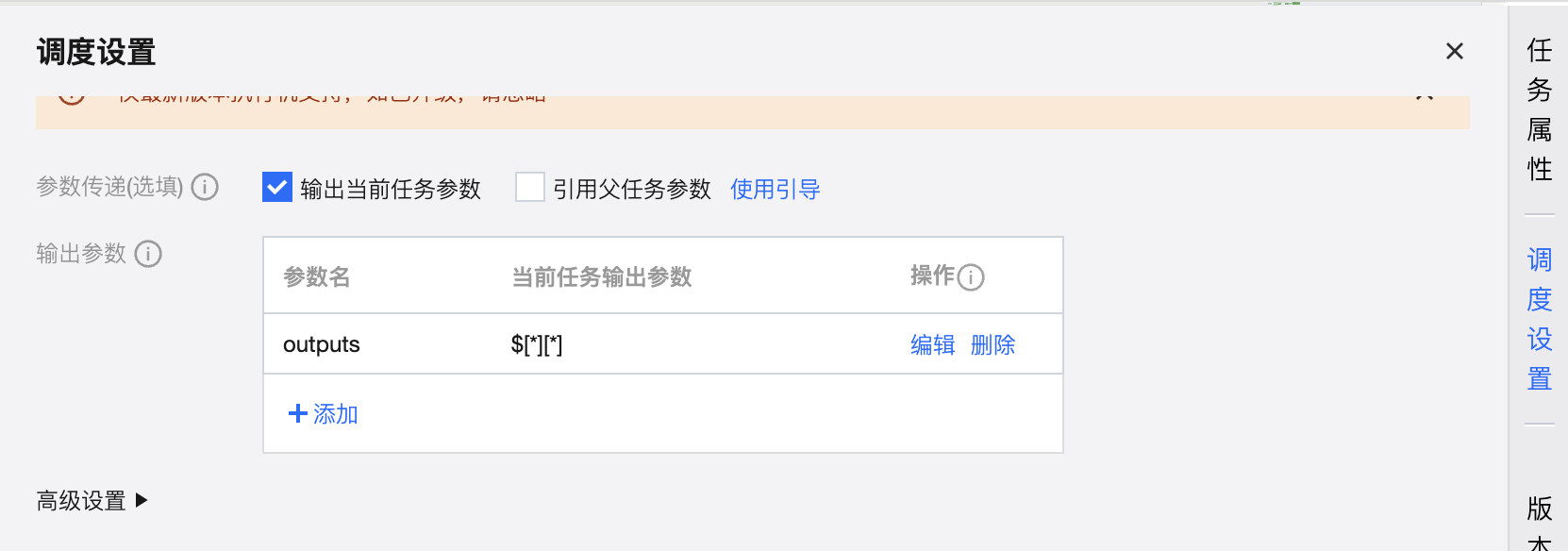
4. 参数传递中的配置如下:
定义参数名称和当前任务输出参数,使用 $[*][*] 表示将二维数组都传递给下游。
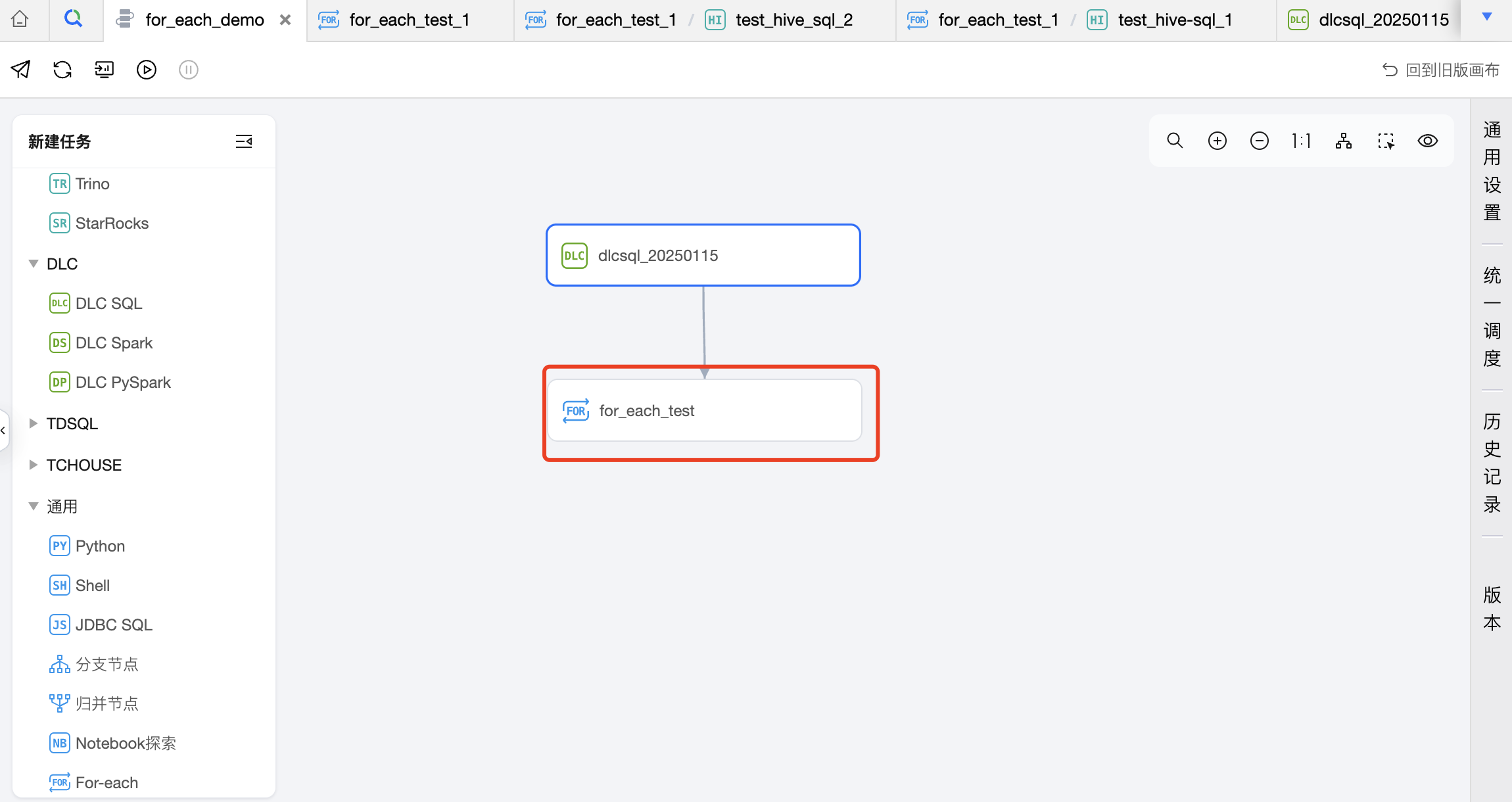
第二步:创建 For-each 节点,并配置 For-each 节点的子节点-数据集成任务。
1. 在工作流中创建一个 For-each 节点,并与 DLC SQL 任务建议上下游关系。
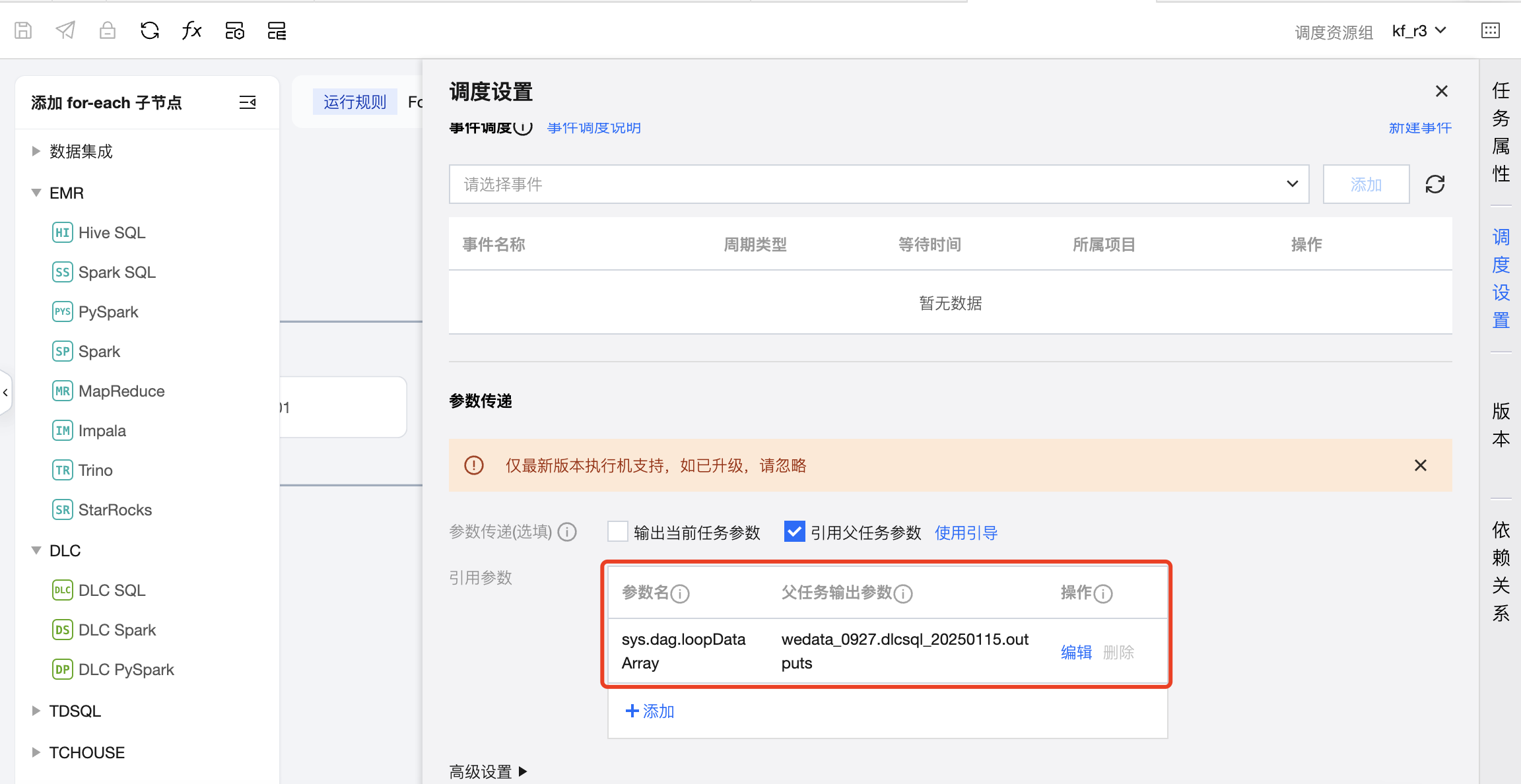
2. 在工作流中双击 For-each 节点,进入 For-each 节点配置页,并配置 For-each 节点。
配置 For-each 任务的基础信息和调度信息,其中重点需要配置引用父任务参数,在参数传递模块定义参数并配置父任务输出参数,从上游 DLC-SQL 中读取传递参数。
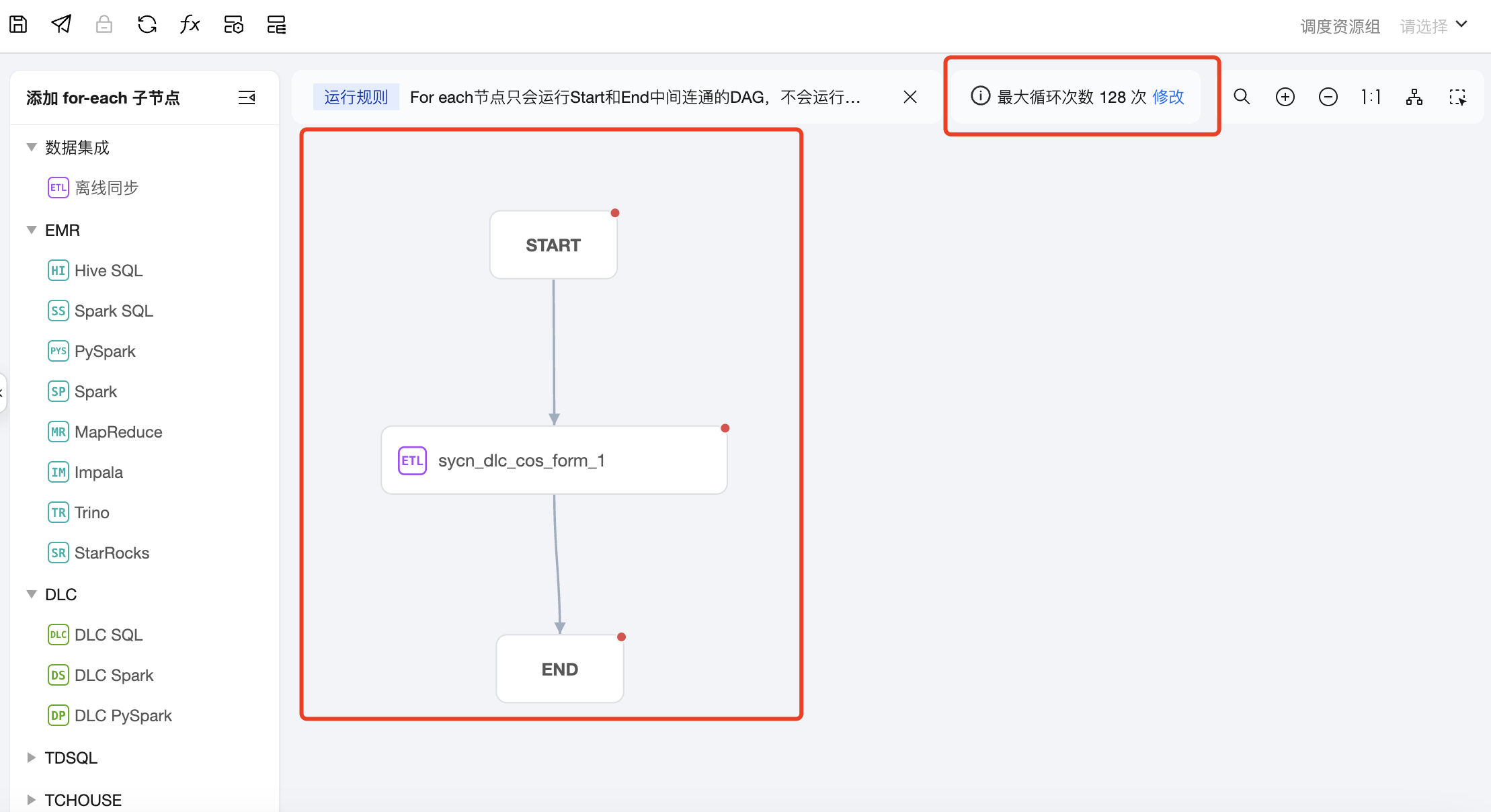
3. 在 For-each 节点中创建子任务-数据集成任务,并与 START 和 END 节点进行连线,配置最大循环次数。
说明:
连线方式为:将鼠标移动至 START 节点框下边缘中部,当鼠标变成手型图标时,按住鼠标左键不放并向下拖动。此时从 START 节点可拖拽出表示依赖关系的射线。保持鼠标左键按住不动,将鼠标移动至任务节点上边框中部,当鼠标变成手型图标时放开鼠标,即可完成节点间连线。
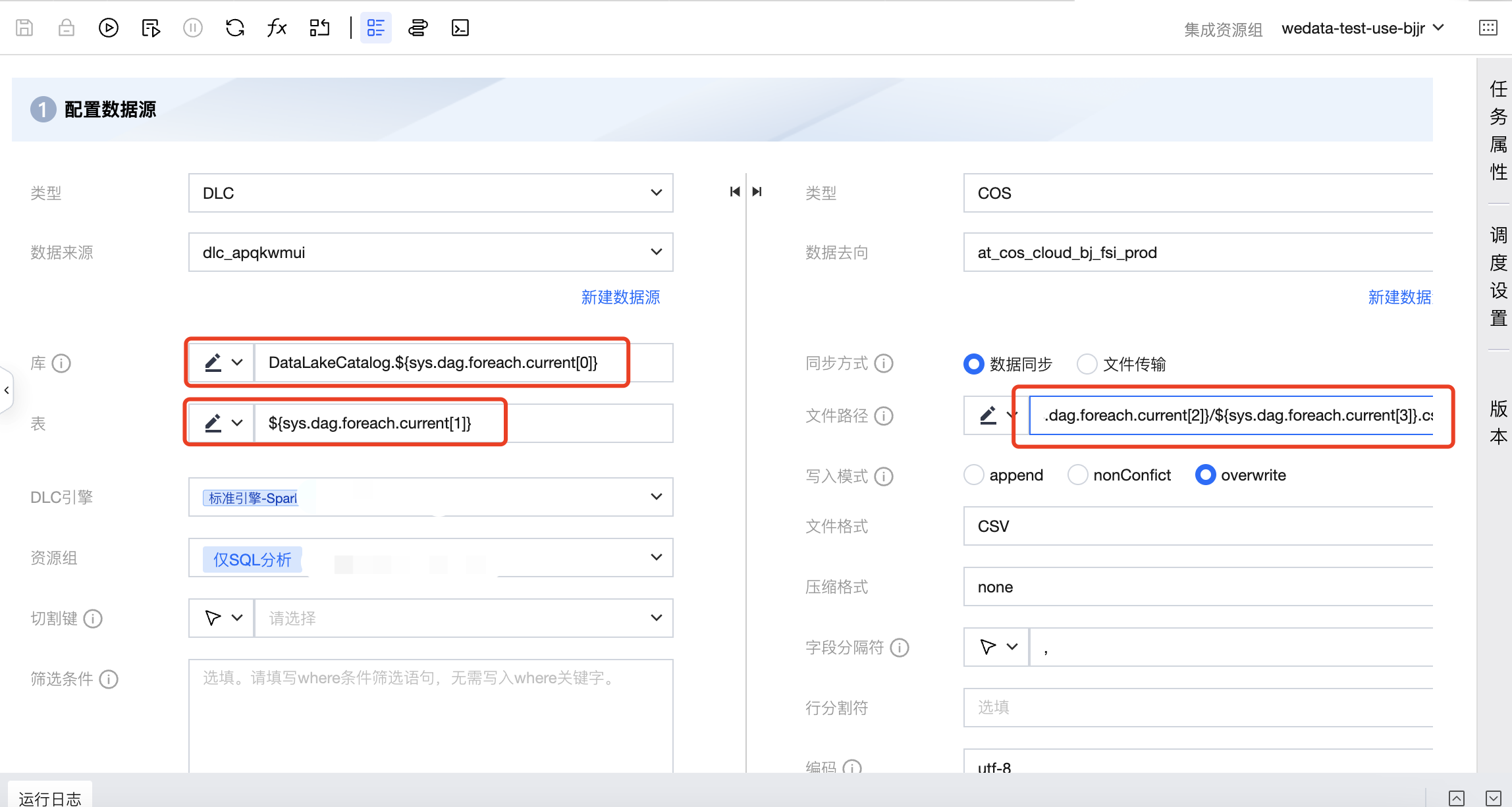
4. 单击数据集成任务,进入数据集成任务并配置。
其中来源库名配置需引用内置参数,配置为 DataLakeCatalog.${sys.dag.foreach.current[0]},表示每次遍历的来源库名是动态变化的,具体的库名会从上游传递的参数中获取,这里表示从上游参数的本次遍历对应行的第0列数据,即来源库信息。
来源表配置为:${sys.dag.foreach.current[1]},表示每次遍历的来源表名是动态变化的,具体的表名会从上游传递的参数中获取,这里表示从上游参数的本次遍历对应行的第1列数据,即来源表信息。
去向的 COS 路径配置为:COS:/Bucket Name/dlc_write_form/${sys.dag.foreach.current[2]}/${sys.dag.foreach.current[3]}.csv,表示每次遍历的 COS 路径都是动态变化的,这里使用了本次遍历对应行的第2、3列数据进行拼接获取最终的 COS 路径。
以上面的数据为例,集成任务来源库表和去向 COS 路径如下:
来源库表 | 去向 COS 路径 |
DataLakeCatalog.wedata_demo_db.user_info_10 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_10.csv |
DataLakeCatalog.wedata_demo_db.user_info_11 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_11.csv |
DataLakeCatalog.wedata_demo_db.user_info_12 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_12.csv |
DataLakeCatalog.wedata_demo_db.user_info_13 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_13.csv |
DataLakeCatalog.wedata_demo_db.user_info_14 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_14.csv |
DataLakeCatalog.wedata_demo_db.user_info_15 | COS:/Bucket Name/dlc_write_form/test_fold/user_info_15.csv |
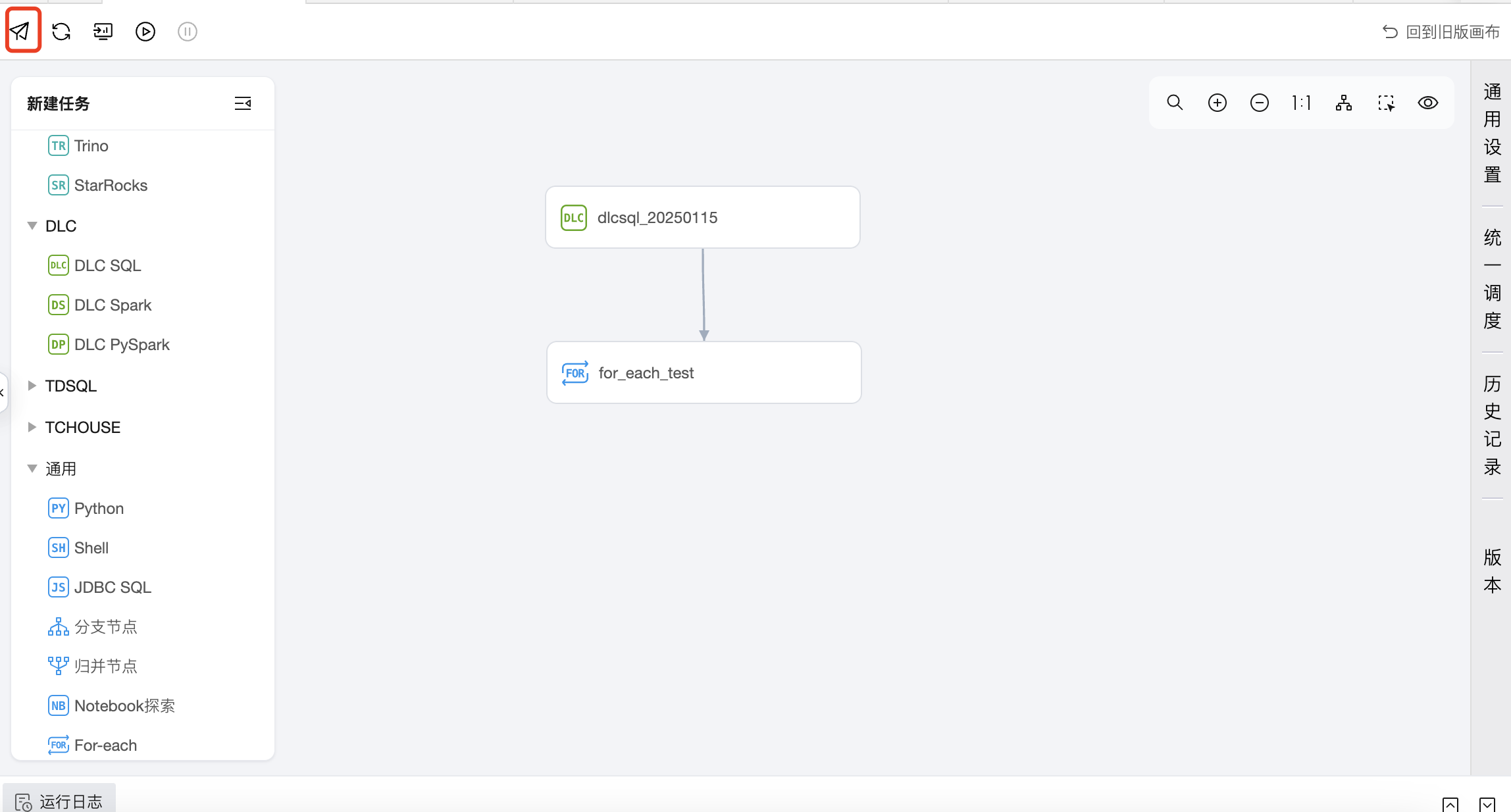
第三步:提交任务
在工作流中进行提交,将上游 DLC SQL 任务和下游的 For-each 任务都提交到调度。
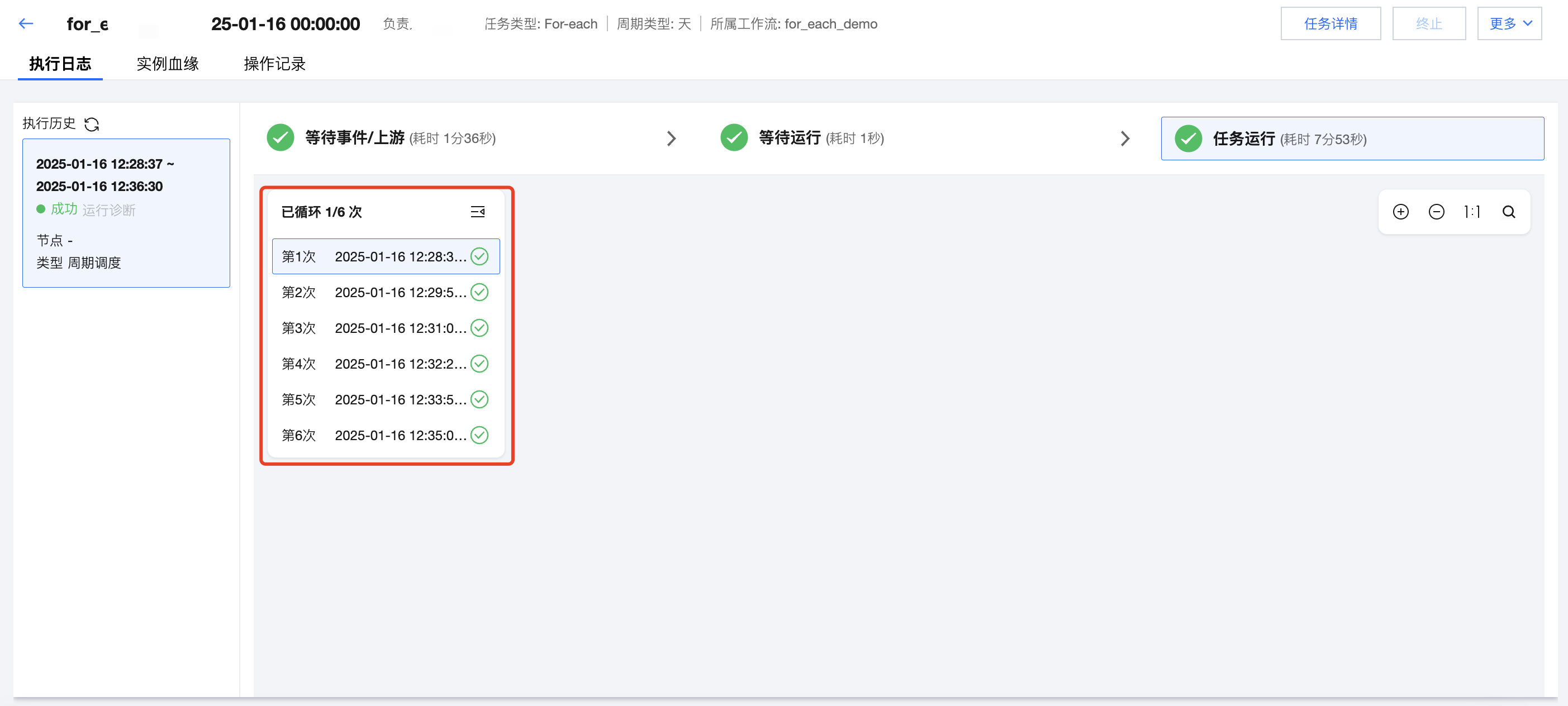
运维中心查看运行情况
在运维中心的实例详情页可以查看 For-each 节点的运行情况。例如,这里上游 DLC SQL 传递了6行数据,因此这里 For-each 的子节点数据集成任务共执行了6次。