Azure Blob 离线单表读取节点配置
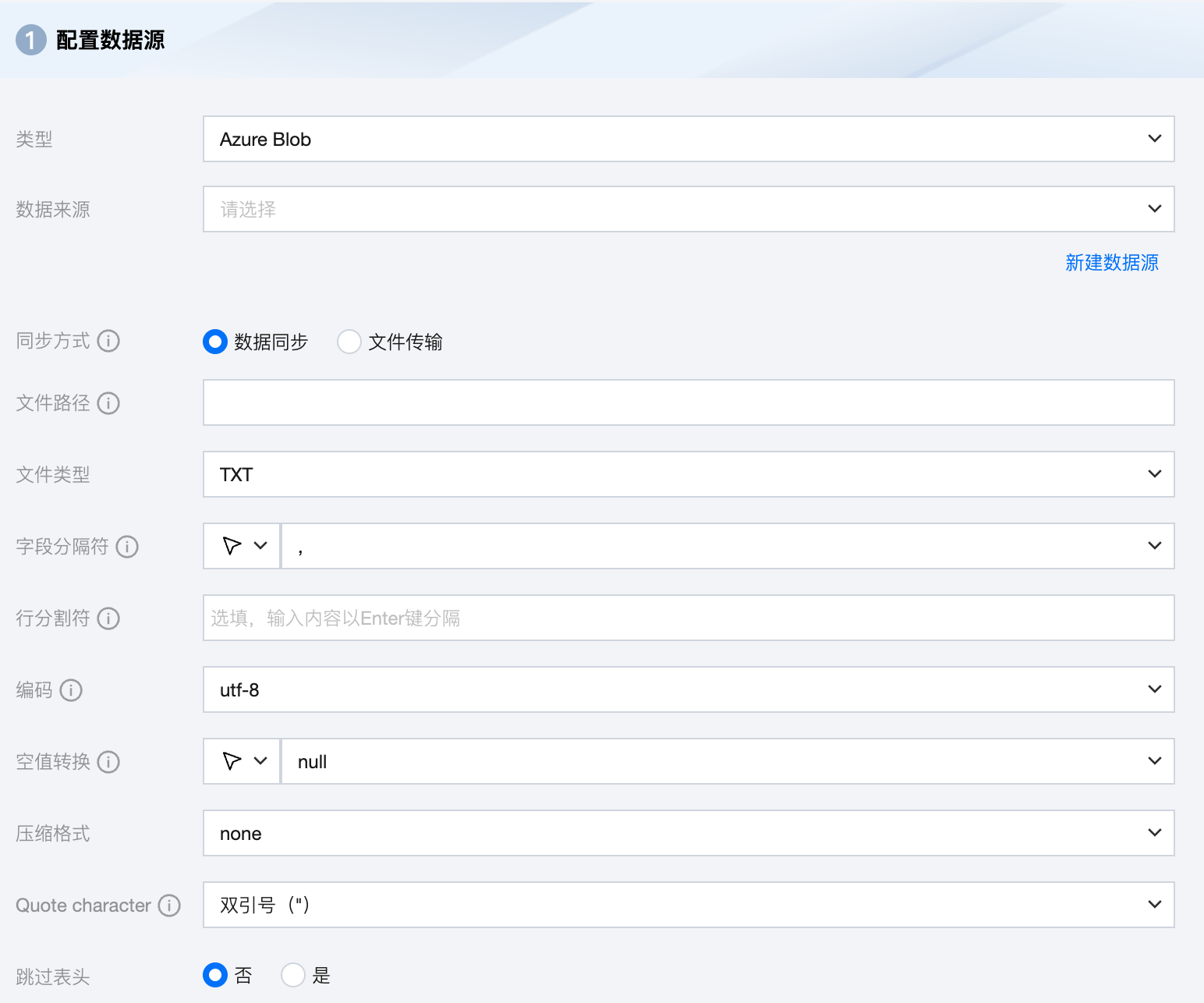
参数 | 说明 |
数据来源 | 选择当前项目中可用的 Azure Blob 数据源。 |
同步方式 | Azure Blob 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP/Azure Blob/S3/Http)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | Azure Blob 文件系统的路径,支持使用 * 通配符。 Azure Blob 文件路径需带上容器名称,例如:Container_name/Directory/ |
文件类型 | Azure Blob 支持五种文件类型:TXT、ORC、PARQUET、CSV、JSON。 TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 JSON:表示 JSON 文件格式。 |
字段分隔符 | 在 TXT/CSV 文件类型下,以数据同步的方式读取时设置的字段分隔符,默认填写(,)。 注意: 不支持 ${} 作为分隔符,${a} 将被识别为配置的参数 a。 |
行分割符(选填) | 在 TXT/CSV 文件类型下,以数据同步的方式读取时设置的行分割符。最多支持输入3个值, 输入的多个值均作为行分割符。若不填写,linux 默认是 \\n , windows 默认是 \\r\\n。 注意: 1. 设置多个行分割符会影响读取性能。 2. 不支持${}作为分割符,${a}将被识别为配置的参数a。 |
编码 | 读取文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空值转换 | 读取时,将指定字符串转为NULL,NULL表示一个未知或者不适用的值,不同于0、空字符串或其他数值。 注意: 不支持 ${} 作为指定字符串,${a} 将被识别为配置的参数 a。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的: hadoop-snappy(hadoop 上的 snappy stream format) framing-snappy(google 建议的 snappy stream format) |
Quote character | 无配置:来源端按照数据原内容进行读取 双引号("):来源端将双引号(")内的值作为数据内容进行读取。 注意:若数据格式不规范,读取时可能导致 OOM。 单引号('):来源端将单引号(')内的值作为数据内容进行读取。 注意:若数据格式不规范,读取时可能导致 OOM。 |
跳过表头 | 否:读取时,不跳过表头。 是:读取时,跳过表头。 |
Azure Blob 离线单表写入节点配置
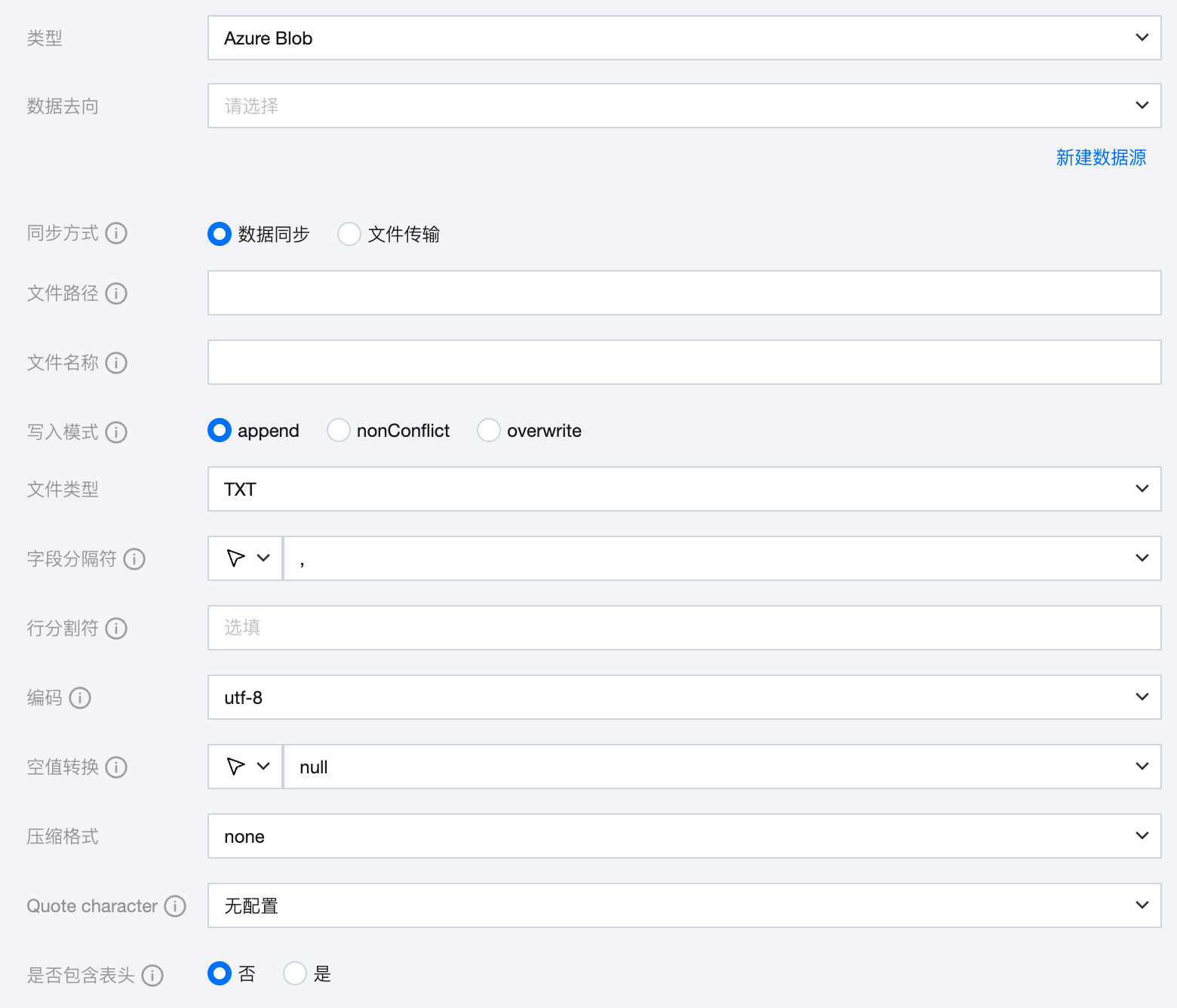
参数 | 说明 |
数据来源 | 选择当前项目中可用的 Azure Blob 数据源。 |
同步方式 | Azure Blob 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP/Azure Blob/S3/Http)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | 写入 Azure Blob 文件系统的明确路径。 Azure Blob 文件路径需带上容器名称,例如:Container_name/Directory/。 |
文件名称 | 写入的文件名称。文件名称支持使用内置大小写转换函数: toLower('<text>'):通过该函数可返回小写格式的字符串。如果字符串中的字符没有对应的小写版本,则该字符在返回的字符串中保持不变。 toUpper('<text>'):通过该函数可返回大写格式的字符串。如果字符串中的字符没有对应的大写版本,则该字符在返回的字符串中保持不变。 |
写入模式 | overwrite:写入前清理以文件名为前缀的所有文件。 append:写入前不做任何处理,保证文件名不冲突。 nonConflict:文件名重复时报错。 |
文件类型 | Azure Blob 支持四种文件类型:TXT、ORC、PARQUET、CSV。 TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 |
字段分隔符 | 在 TXT/CSV 文件类型下,以数据同步的方式写入时设置的字段分隔符,默认填写(,)。 注意: 不支持 ${} 作为分隔符,${a} 将被识别为配置的参数 a。 |
行分割符(选填) | 在 TXT/CSV 文件类型下,以数据同步的方式写入时设置的行分割符。输入的多个值均作为行分割符。若不填写,linux 默认是 \\n , windows 默认是 \\r\\n。手动填写时,支持输入一个值作为目标端行分割符写入数据。 注意: 不支持 ${} 作为分割符,${a} 将被识别为配置的参数 a。 |
编码 | 写入文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空值转换 | 写入时,将 NULL 转为指定字符串。NULL 代表未知或不适用的值,不同于0、空字符串或其他数值。 注意: 不支持 ${} 作为指定字符串,${a} 将被识别为配置的参数 a。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的: hadoop-snappy(hadoop 上的 snappy stream format) framing-snappy(google 建议的 snappy stream format) |
Quote character | 无配置:目标端写入数据时不进行引号添加操作,值与来源端一致。 双引号("):目标端写入数据时为每个值自动添加双引号",如"123"。 单引号('):标端写入数据时为每个值自动添加单引号',如'123'。 |
是否包含表头 | 否:写入时,不包含表头。 是:写入时,包含表头。 |
数据类型转换支持
读取
Azure Blob 读取支持的数据类型及转换对应关系如下:
Azure Blob 数据类型 | 内部类型 |
INT | LONG |
DOUBLE | DOUBLE |
STRING,CHAR | STRING |
DECIMAL | DECIMAL |
BOOLEAN | BOOLEAN |
DATE,TIMESTAMP | DATE |
写入
Azure Blob 写入支持的数据类型及转换对应关系如下:
内部类型 | Azure Blob 数据类型 |
LONG | INT |
DOUBLE | DOUBLE |
STRING | STRING,CHAR |
DECIMAL | DECIMAL |
BOOLEAN | BOOLEAN |
DATE | DATE,TIMESTAMP |



