S3 离线单表读取节点配置
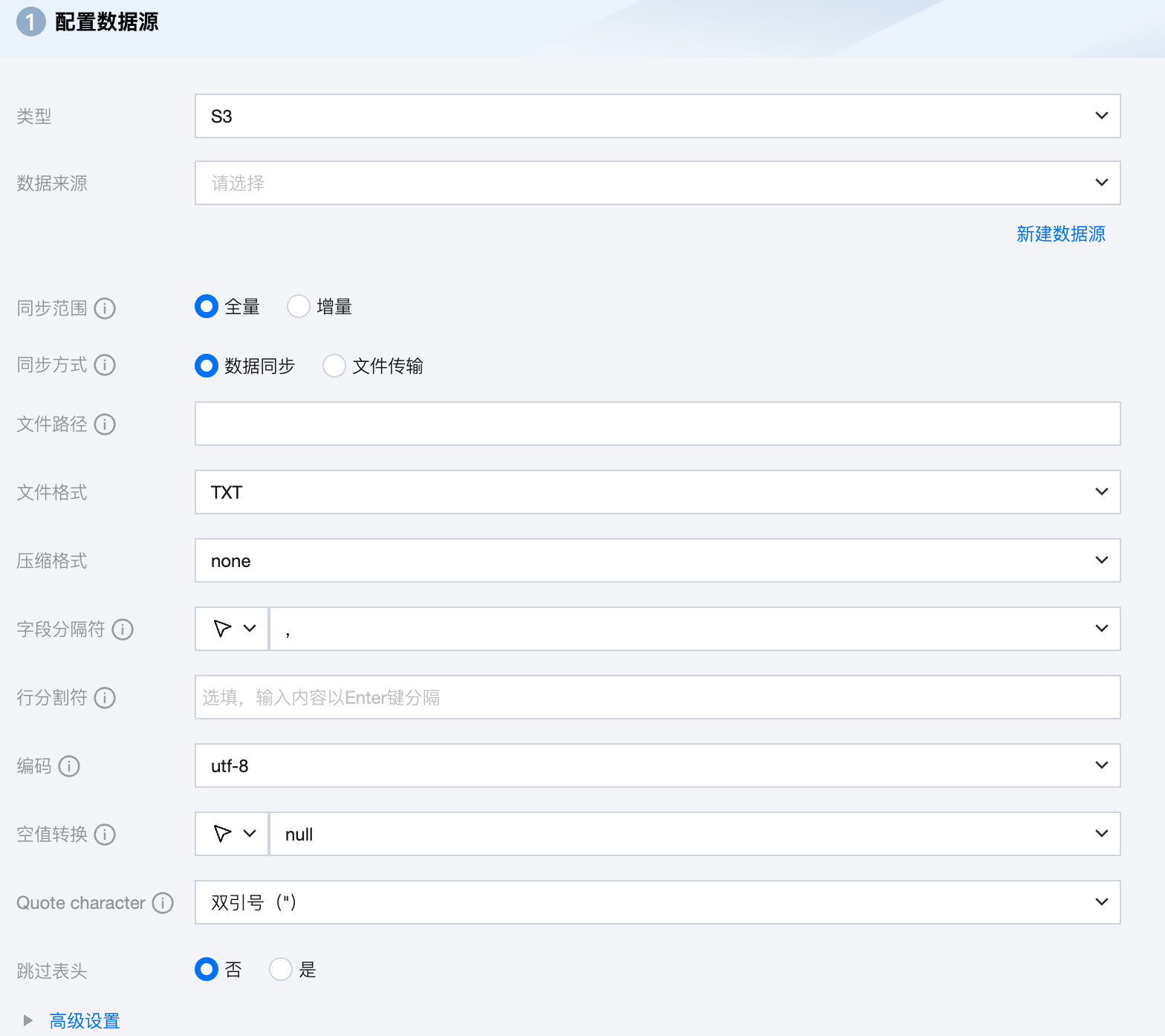
参数 | 说明 |
数据来源 | 选择当前项目中可用的 S3 数据源。 |
同步范围 | 全量:同步范围是文件路径下所有文件。 增量:同步范围是文件路径下上周期计划调度时间至本周期计划调度时间之间更新的文件。调试同步任务时,若选择增量同步则默认同步文件路径下所有文件。 注意: 同步范围仅对文件路径是文件目录的形式有效。若路径具体到文件则同步范围不生效,按照文件进行同步。 |
同步方式 | S3 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP/S3/Azure Blob/Http)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | S3 文件系统的路径,支持使用*通配符。 S3 文件路径需带上桶名称,例如 s3a://bucket_name。 |
文件类型 | S3 支持五种文件类型:TXT、ORC、PARQUET、CSV、JSON。 TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 JSON:表示 JSON 文件格式。 |
字段分隔符 | 在 TXT/CSV 文件类型下,以数据同步的方式读取时设置的字段分隔符,默认填写(,)。 注意: 不支持 ${} 作为分隔符,${a} 将被识别为配置的参数 a。 |
行分割符(选填) | 在 TXT/CSV 文件类型下,以数据同步的方式读取时设置的行分割符。最多支持输入3个值, 输入的多个值均作为行分割符。若不填写,linux 默认是 \\n , windows 默认是 \\r\\n。 注意: 1. 设置多个行分割符会影响读取性能。 2. 不支持${}作为分割符,${a}将被识别为配置的参数 a。 |
编码 | 读取文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空值转换 | 读取时,将指定字符串转为 NULL,NULL 表示一个未知或者不适用的值,不同于0、空字符串或其他数值。 注意: 不支持 ${} 作为指定字符串,${a} 将被识别为配置的参数 a。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的: hadoop-snappy(hadoop 上的 snappy stream format) framing-snappy(google 建议的 snappy stream format) |
Quote character | 无配置:来源端按照数据原内容进行读取 双引号("):来源端将双引号(")内的值作为数据内容进行读取。注意:若数据格式不规范,读取时可能导致OOM。 单引号('):来源端将单引号(')内的值作为数据内容进行读取。注意:若数据格式不规范,读取时可能导致OOM。 |
跳过表头 | 否:读取时,不跳过表头。 是:读取时,跳过表头。 |
S3 离线单表写入节点配置
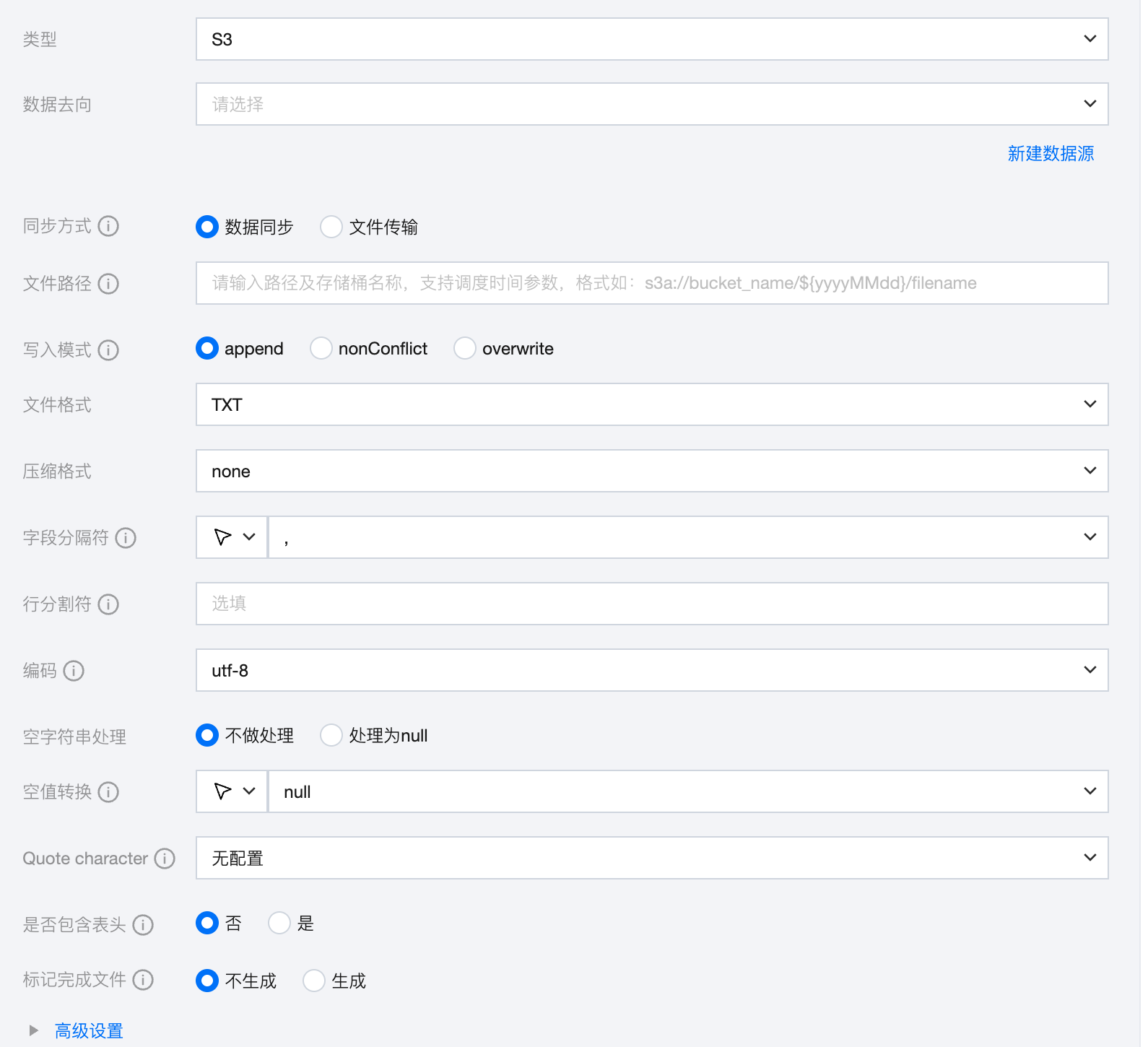
参数 | 说明 |
数据来源 | 选择当前项目中可用的 S3 数据源。 |
同步方式 | S3 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP/S3/Azure Blob/Http)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | 写入 S3 文件系统的路径。 S3 文件路径需带上桶名称,如 s3a://bucket_name。 |
写入模式 | overwrite:写入前清理以文件名为前缀的所有文件。 append:写入前不做任何处理,保证文件名不冲突。 nonConflict:文件名重复时报错。 |
文件类型 | S3 支持四种文件类型:TXT、ORC、PARQUET、CSV。 TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 |
字段分隔符 | 在 TXT/CSV 文件类型下,以数据同步的方式写入时设置的字段分隔符,默认填写(,)。 注意: 不支持 ${} 作为分隔符,${a} 将被识别为配置的参数 a。 |
行分割符(选填) | 在TXT/CSV文件类型下,以数据同步的方式写入时设置的行分割符。输入的多个值均作为行分割符。若不填写,linux 默认是 \\n , windows 默认是 \\r\\n。手动填写时,支持输入一个值作为目标端行分割符写入数据。 注意:不支持 ${} 作为分割符,${a} 将被识别为配置的参数 a。 |
编码 | 写入文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空字符串处理 | 不做处理:写入时,不处理空字符串。 处理为 NULL:写入时,将空字符串处理为 NULL。 |
空值转换 | 写入时,将 NULL 转为指定字符串。NULL 代表未知或不适用的值,不同于0、空字符串或其他数值。 注意: 不支持 ${} 作为指定字符串,${a} 将被识别为配置的参数 a。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的: hadoop-snappy(hadoop 上的 snappy stream format) framing-snappy(google 建议的 snappy stream format) |
Quote character | 无配置:目标端写入数据时不进行引号添加操作,值与来源端一致。 双引号("):目标端写入数据时为每个值自动添加双引号",如"123"。 单引号('):标端写入数据时为每个值自动添加单引号',如'123'。 |
是否包含表头 | 否:写入时,不包含表头。 是:写入时,包含表头。 |
标记完成文件 | 空白的 .ok 文件,标志任务传输完成。 不生成:任务完成后,不生成空白的 .ok 文件。(默认选中) 生成:任务完成后,生成空白的 .ok 文件 |
标记完成文件名称 | 填写时需包含完整文件路径、名称、后缀,默认在目标路径下按照目标文件名称及后缀生成 .ok 文件。 支持在数据同步、文件传输模式下使用时间调度参数 ${yyyyMMdd} 等。 支持在文件传输模式下使用内置变量 ${filetrans_di_src} 代表源文件名称。 例如:/user/test/${filetrans_di_src}_${yyyyMMdd}.ok。 注意: 在文件传输模式下「目标文件名称」中如果使用${filetrans_di_src}引用源文件名称,并且标记完成文件按照目标文件名称及后缀生成.ok文件时,生成的标记完成文件个数取决于来源端的文件数量。 |



