操作场景
迁移助手支持导入和导出任务、项目参数、函数、事件、数据集成等对象,并抽象出通用的业务流程,便于快速复制业务。在开发与生产集群完全隔离的情况下,您可以通过自定义导出功能,实现类似于发布任务的操作。本文将为您介绍如何将任务从源项目导出并导入到目标项目。
使用限制
注意:
加入项目并成为项目管理员
仅主账号和作为项目管理员的子账号能够进行导入和导出操作,其他角色成员仅支持查看导入、导出任务列表,无操作权限。若您需要成为管理员,需要其他项目管理员在 WeData 项目管理页面内的成员与角色管理中将您添加为管理员。
检查当前用户权限
导出 DLC 任务需要当前操作的子账户具有 cam:PassRole 权限。当前 QcloudWeDataExternalAccess 策略已关联 cam:PassRole 权限。当操作导出 DLC 任务的子账号仅有 QcloudWeDataReadOnlyAccess 策略时,为成功导出任务,您需要为其再添加 QcloudWeDataExternalAccess 策略。
1. 登录腾讯云控制台,进入 访问管理(CAM)页面。
2. 在左侧菜单中选择用户,找到您需要绑定策略的用户。
3. 单击该用户的名称,进入用户详情页。在权限栏搜索 QcloudWeDataExternalAccess,如果已经关联了该策略,下面步骤可以跳过。
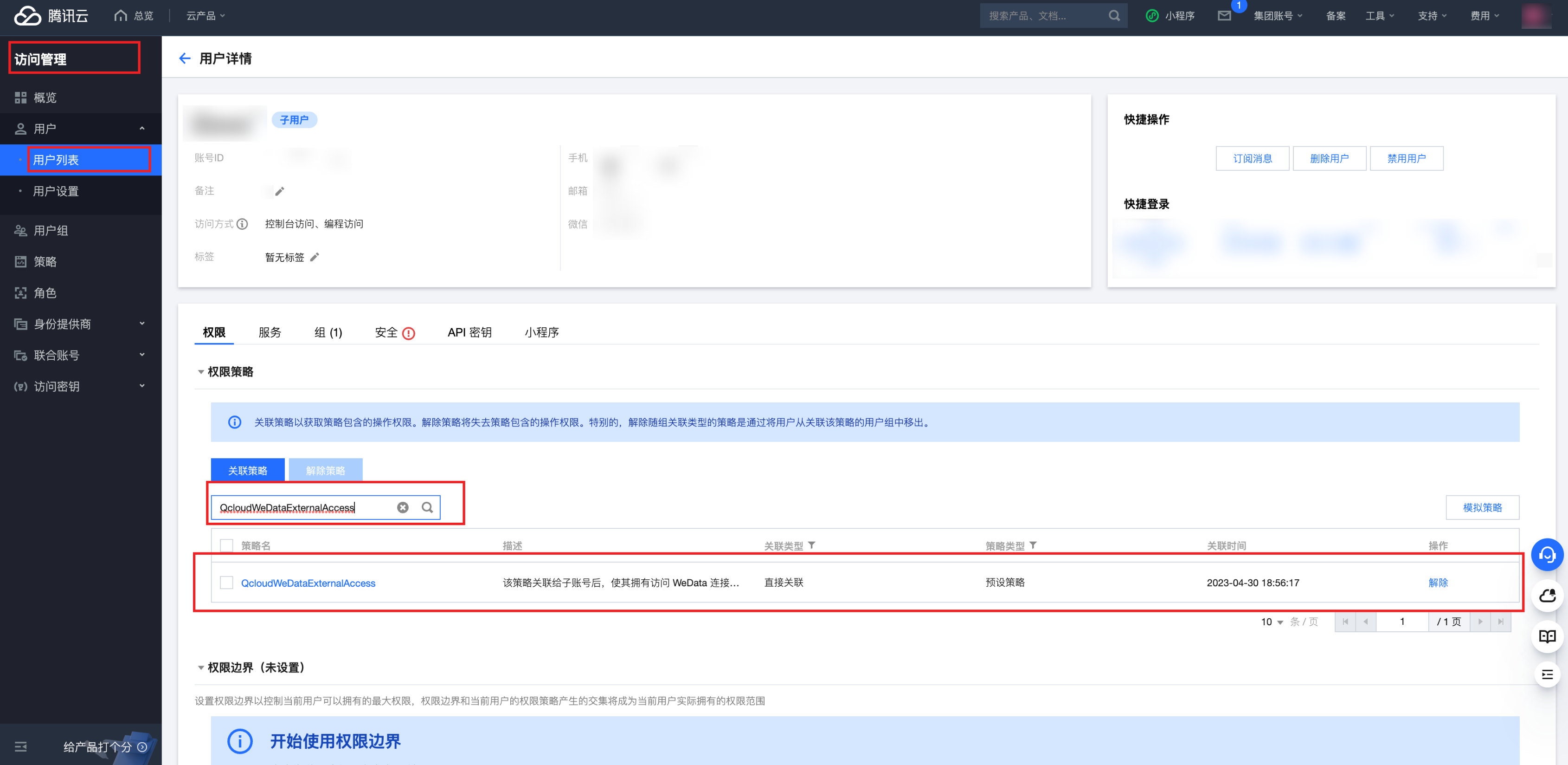
4. 在用户详情页中,找到权限管理模块下的关联策略 。
5. 单击关联策略中的新建关联按钮。选择从策略列表中选取策略关联,并输入 QcloudWeDataExternalAccess。
6. 勾选 QcloudWeDataExternalAccess,单击下一步,完成策略绑定。
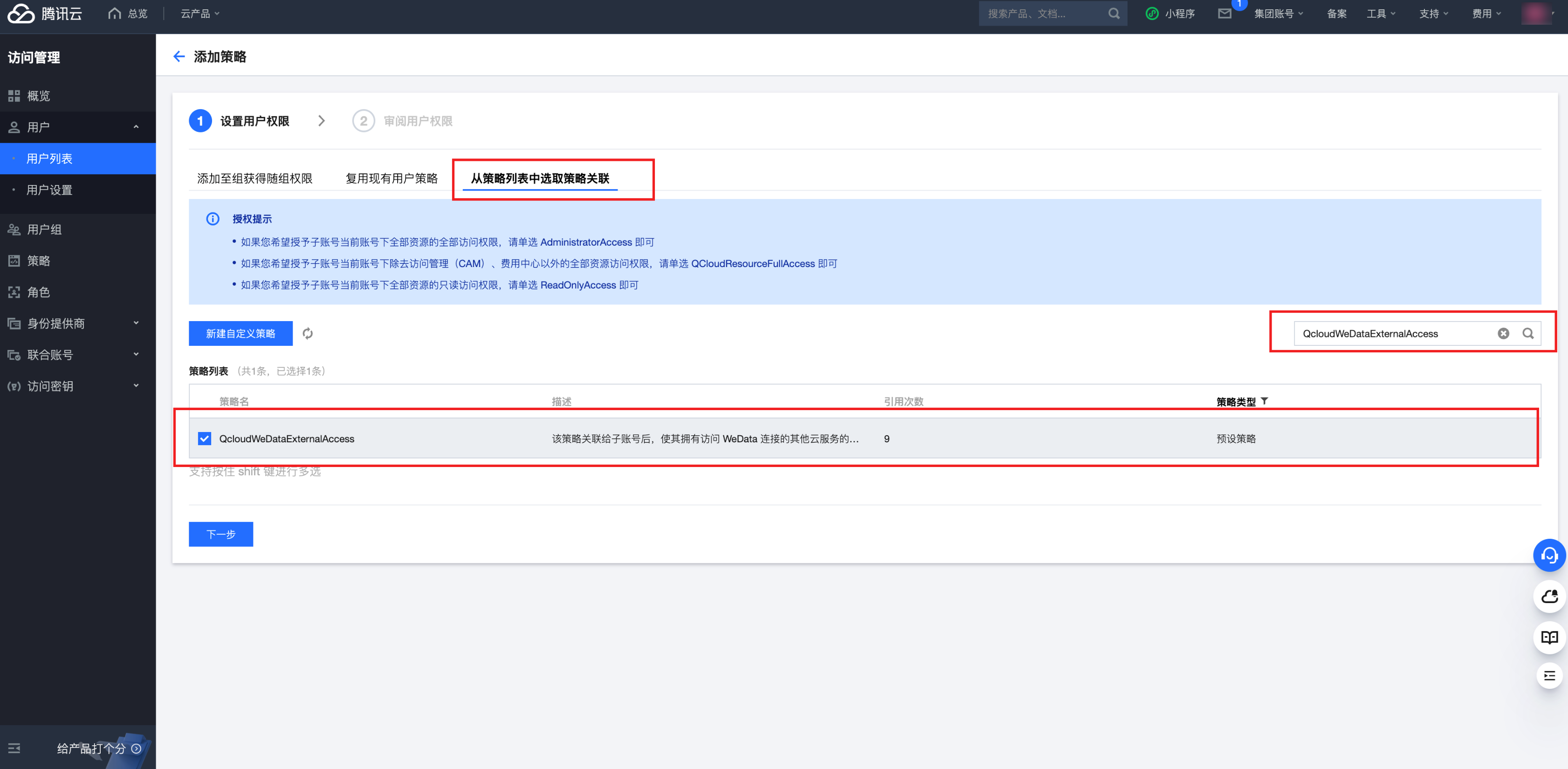
7. 绑定成功后,该用户即可使用 QcloudWeDataExternalAccess 策略中定义的权限。
操作步骤
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,找到需要使用任务开发功能的目标项目。
3. 选择项目后,单击右上角进入项目管理页面。
4. 在项目管理页面中,选择左侧列表中的导出任务或导入任务。迁移助手包含导出任务和导入任务两个功能,分别对应将任务从项目中导出为压缩包,以及将压缩包上传至项目并生成任务。
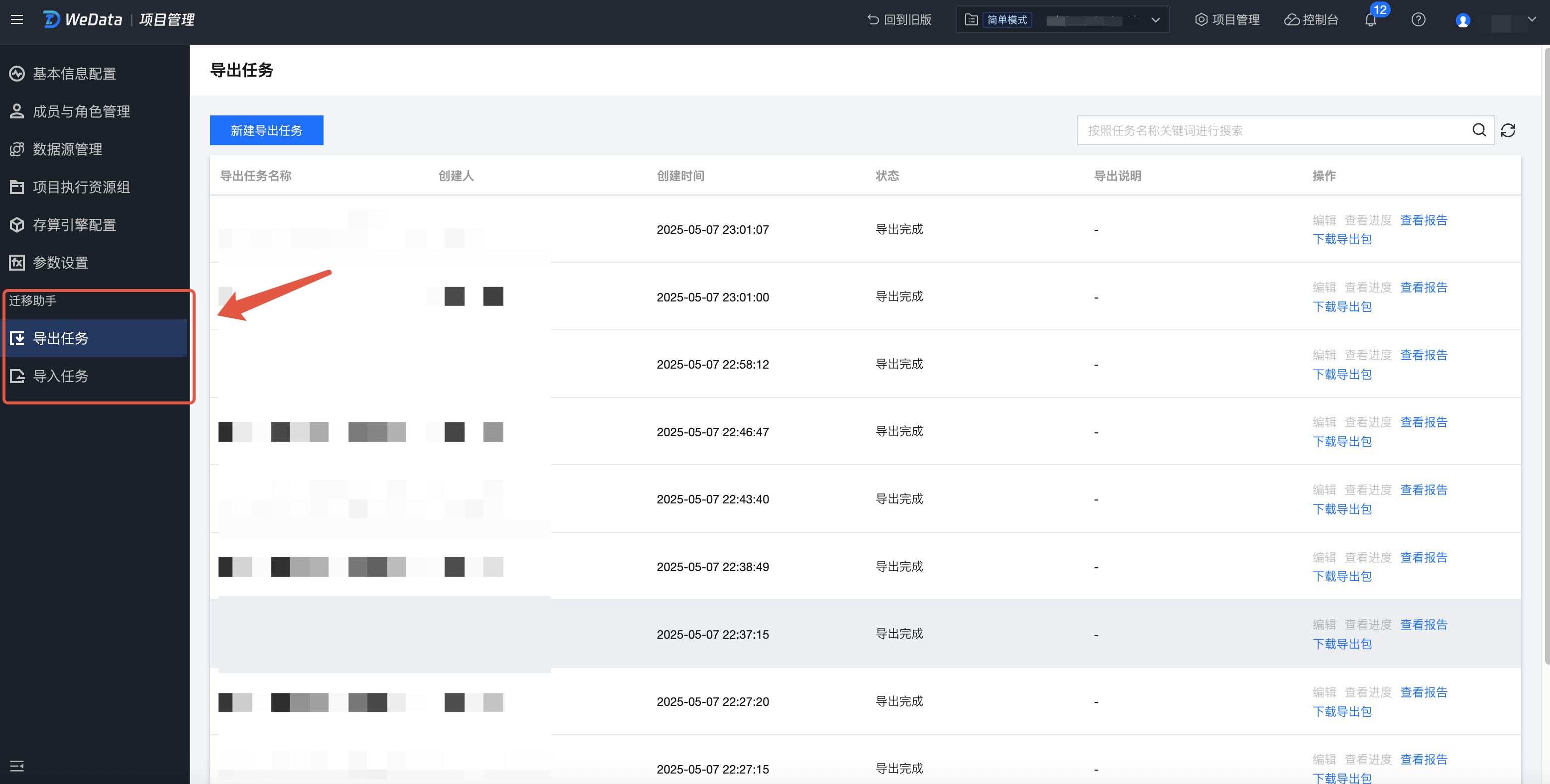
导出任务
1. 选择左上角的新建导出任务,在弹出对话框内填写导出任务名称及说明。
2. 选择导出对象。导出对象包括编排空间任务、项目参数、函数、代码模板、事件、数据集成-离线同步任务、数据集成-实时同步任务。选择完成后单击页面底部下一步。
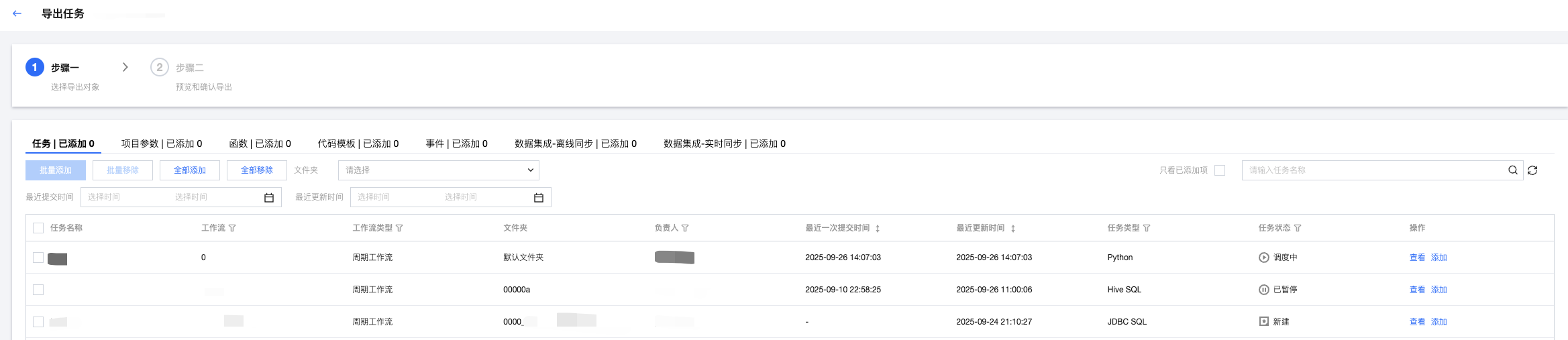
3. 选择导出任务的版本,包括最新保存和调度中版本优先两个选项:
最新保存:导出任务最新一次保存的内容。
调度中版本优先:优先导出任务调度中的版本(生产版本),如果没有调度中的版本则导出最新一次保存的内容。
4. 预览无误后单击开始导出,弹出对话框会展示导出状态。
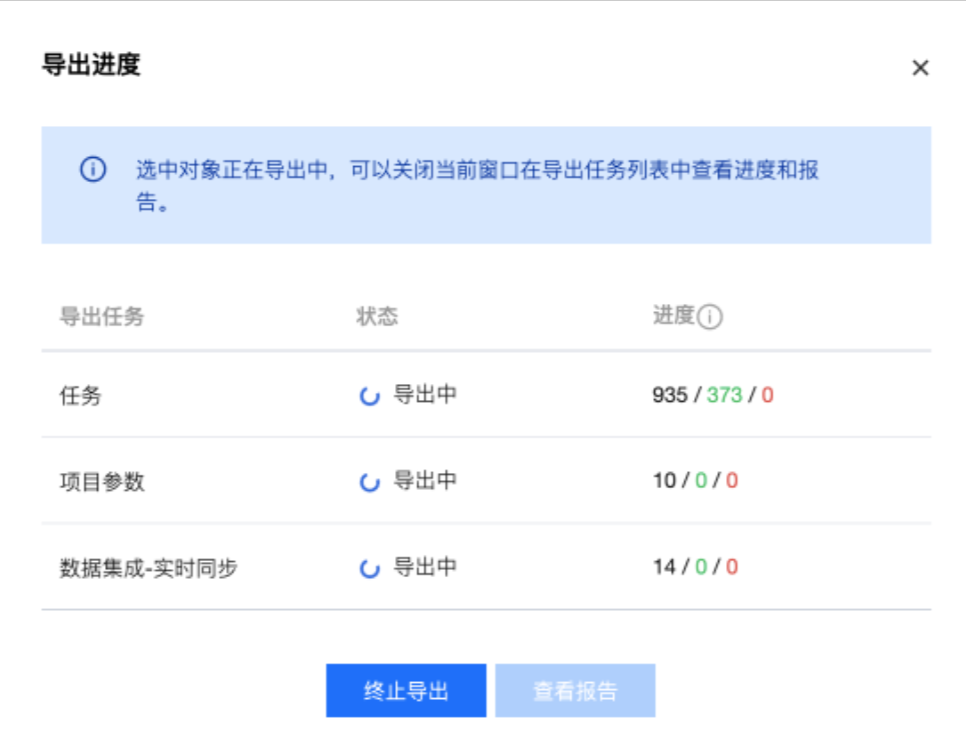
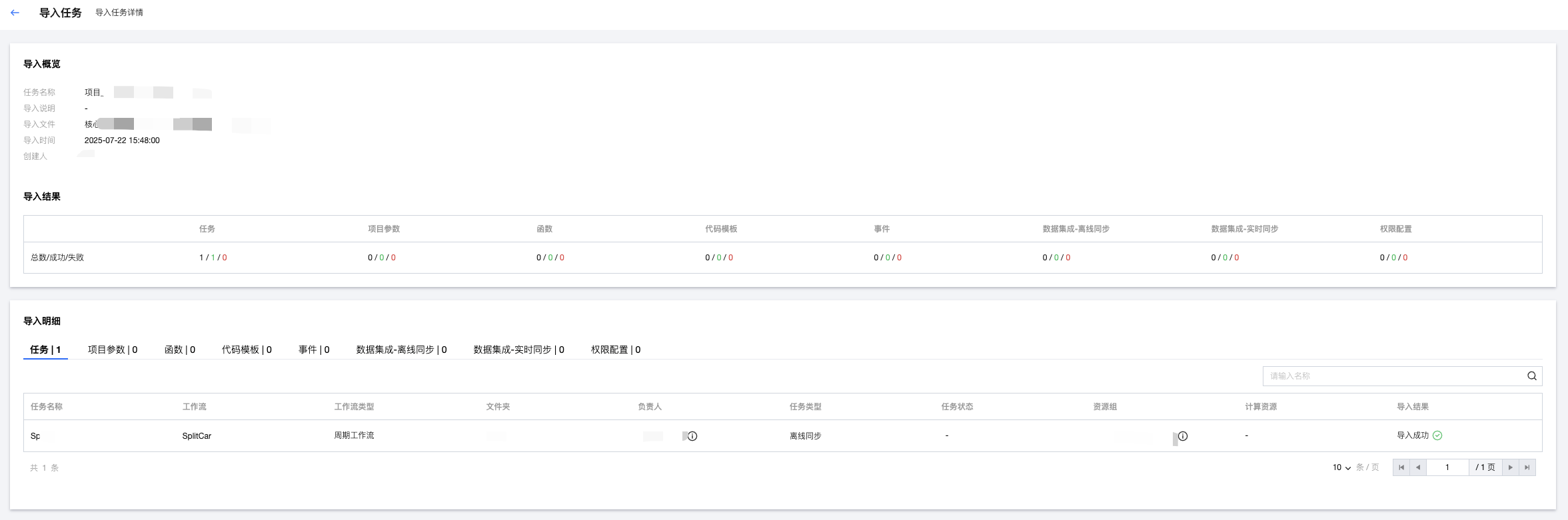
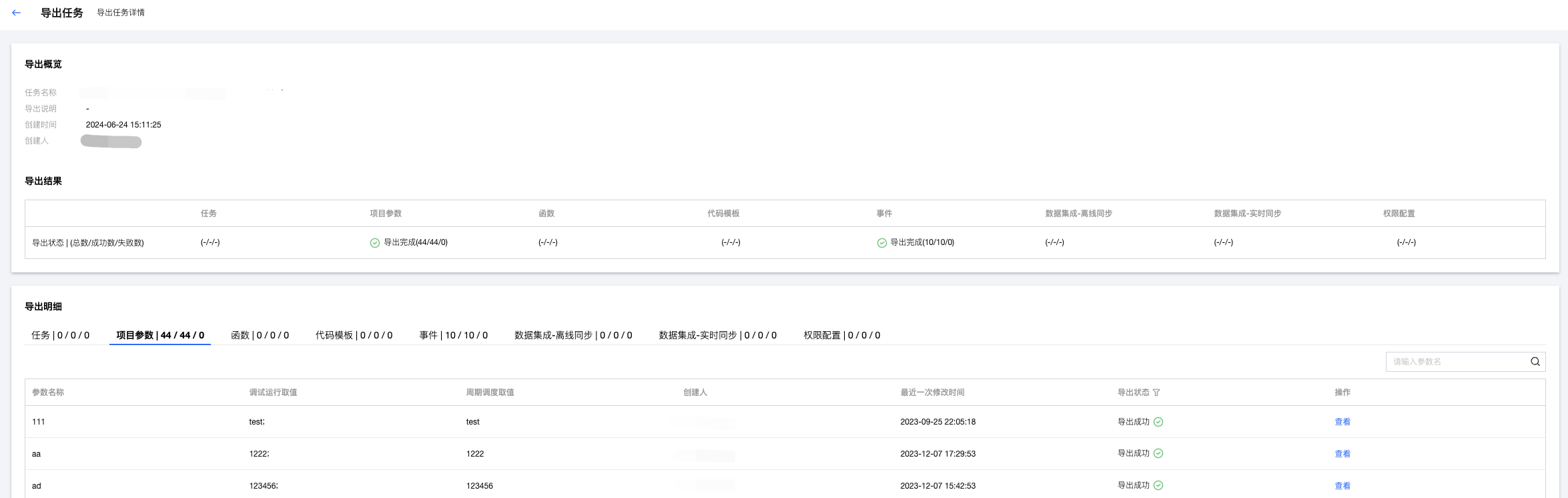
5. 查看导出报告
导出结果中可以查看导出状态,包括导出成功、导出失败、部分成功,可以分别查看导出总数、成功数和失败数。
支持查看导出明细,如果导出状态为失败,可以查看失败原因。
6. 导出完成后,回到列表页单击“下载导出包”,即可将导出包保存到本地。

支持导出的对象类型
1. 支持的工作流类型:周期工作流、手动工作流。
2. 支持的其他对象类型包括:
对象分类 | 对象类型 | 是否支持 | |
编排空间 | 数据集成 | 离线同步 | 是 |
| EMR | Hive SQL | 是 |
| | Spark SQL | 是 |
| | PySpark | 是 |
| | Spark | 是 |
| | MapReduce | 是 |
| | Impala | 是 |
| | Trino | 是 |
| | StarRocks | 是 |
| DLC | DLC SQL | 是 |
| | DLC Spark | 是 |
| | DLC PySpark | 是 |
| TDSQL | TDSQL PostgreSQL | 是 |
| TCHouse | TCHouse-P | 是 |
| | TCHouse-X | 是 |
| | TCHouse-X SQL | 是 |
| 通用 | Python | 是 |
| | Shell | 是 |
| | JDBC SQL | 是 |
| | Kettle | 是 |
| | 分支节点 | 是 |
| | 归并节点 | 是 |
| | Notebook 探索 | 是 |
| | For-each | 是 |
| | SSH | 是 |
| 跨工作流 | 跨工作流节点 | 是 |
项目参数 | | 项目参数 | 是 |
函数 | | 函数 | 是 |
代码模板 | | 代码模板 | 是 |
事件 | | 事件 | 是 |
数据集成 | | 离线同步 | 是 |
| | 实时同步 | 是 |
导入任务
1. 选择左上角的新建导入任务,在弹出对话框内上传导出后的压缩包,并单击文件校验,校验导入文件的格式和内容。校验成功后填写导入说明,单击开始导入。
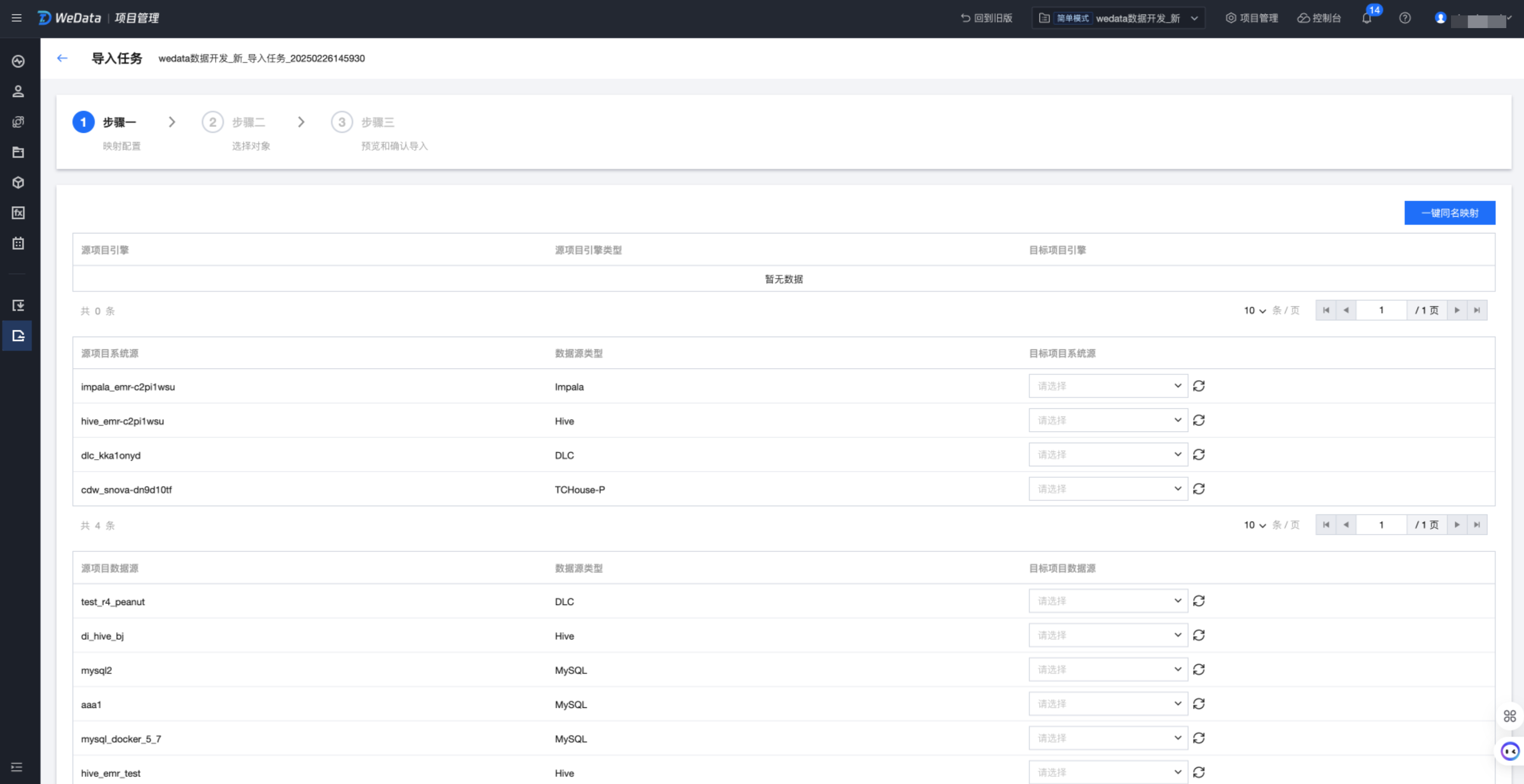
2. 将源项目下任务所需的配置项映射到目标项目,需要配置内容包括存算引擎、系统源、自定义源、队列信息、执行资源组。例如:
源项目中某个 PySpark 任务的配置项是 EMR 引擎,那么在目标项目中需要选择对应的 EMR 引擎进行映射。
源项目中某个 Hive SQL 任务的配置项是 Hive 数据源,那么在目标项目中需要选择一个对应的 Hive 数据源进行映射。
导入时的可选参数包括:
参数 | 描述 |
重名策略 | 如果目标项目下存在同名的任务、项目参数、函数等对象时,通过选择“覆盖”或者“跳过”为每个同名对象设定策略。 |
任务提交策略 | 设定导入任务的提交策略: 全部不提交:导入任务后,默认全部不提交调度,用户需要手动提交; 全部提交:导入任务后,源项目中已调度运行的任务在下个调度周期动态生效,未调度的任务将自动启动调度。 注意: 数据集成-实时同步任务暂不支持自动提交,导入后需要手动提交任务。 |
负责人策略 | 为导入的任务设定负责人: 默认:优先使用导入对象原负责人作为导入后的负责人,如果原负责人在目标项目中不存在,则使用导入任务运行人作为导入后的负责人。 导入任务运行人:统一将导入任务运行人作为导入对象的负责人。 指定子账号:指定一个子账号作为导入对象的负责人,该子账号需要为当前项目成员 |
3. 选择导入对象,并单击下一步。
4. 预览无误后单击开始导入,弹出对话框会展示导入状态。
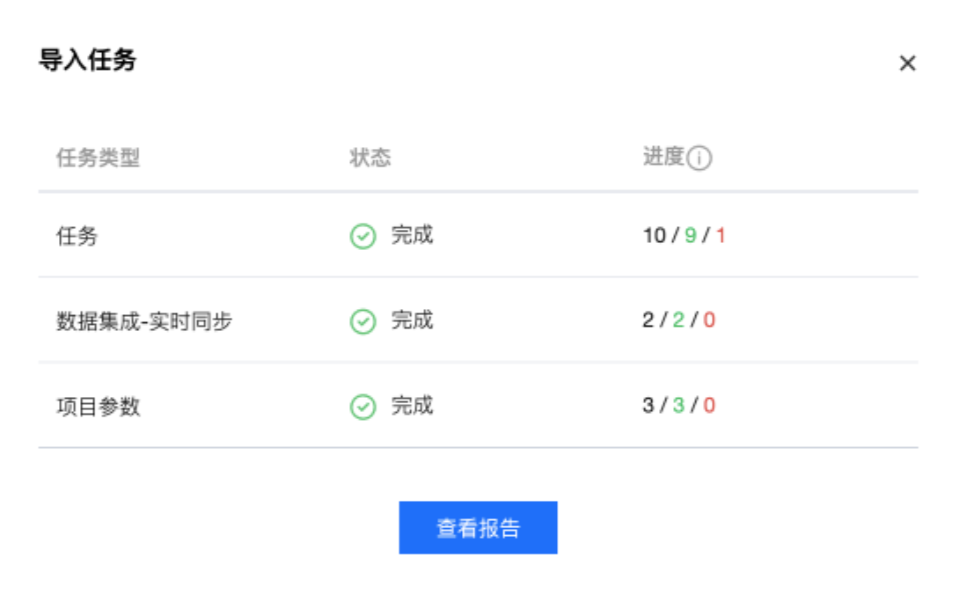
5. 导入完成后,可以查看导入结果:
导入结果中可以查看导入状态,包括导入成功、导入失败、部分成功,可以分别查看导入总数、成功数和失败数。
支持查看导入明细,如果导入状态为失败,可以查看失败原因。