前置准备工作
开通 WeData Studio 功能
注意:
购买大数据存算引擎
注意:
WeData Studio 支持对接的大数据存算引擎包括:
1. DLC 引擎:标准引擎-Spark 类型,必须包含“机器学习-Spark MLlib”类型的资源组。
2. EMR 引擎:EMR on CVM-Hadoop 类型,3.5.0版本,必须包含 EG 组件和 Spark 组件。
如果您使用 EMR 引擎,需要检查 EMR 使用的安全组是否放通了 WeData Studio 网段(30.22.32.0/19),若未放通,需要对安全组做如下操作:
入站需要放通:30.22.32.0/19 端口 TCP:8888
Studio 开发 IDE
Studio 整体功能包括:Studio 开发 IDE、数据目录导航、Git 源代码管理三个模块。
进入 Studio 模块
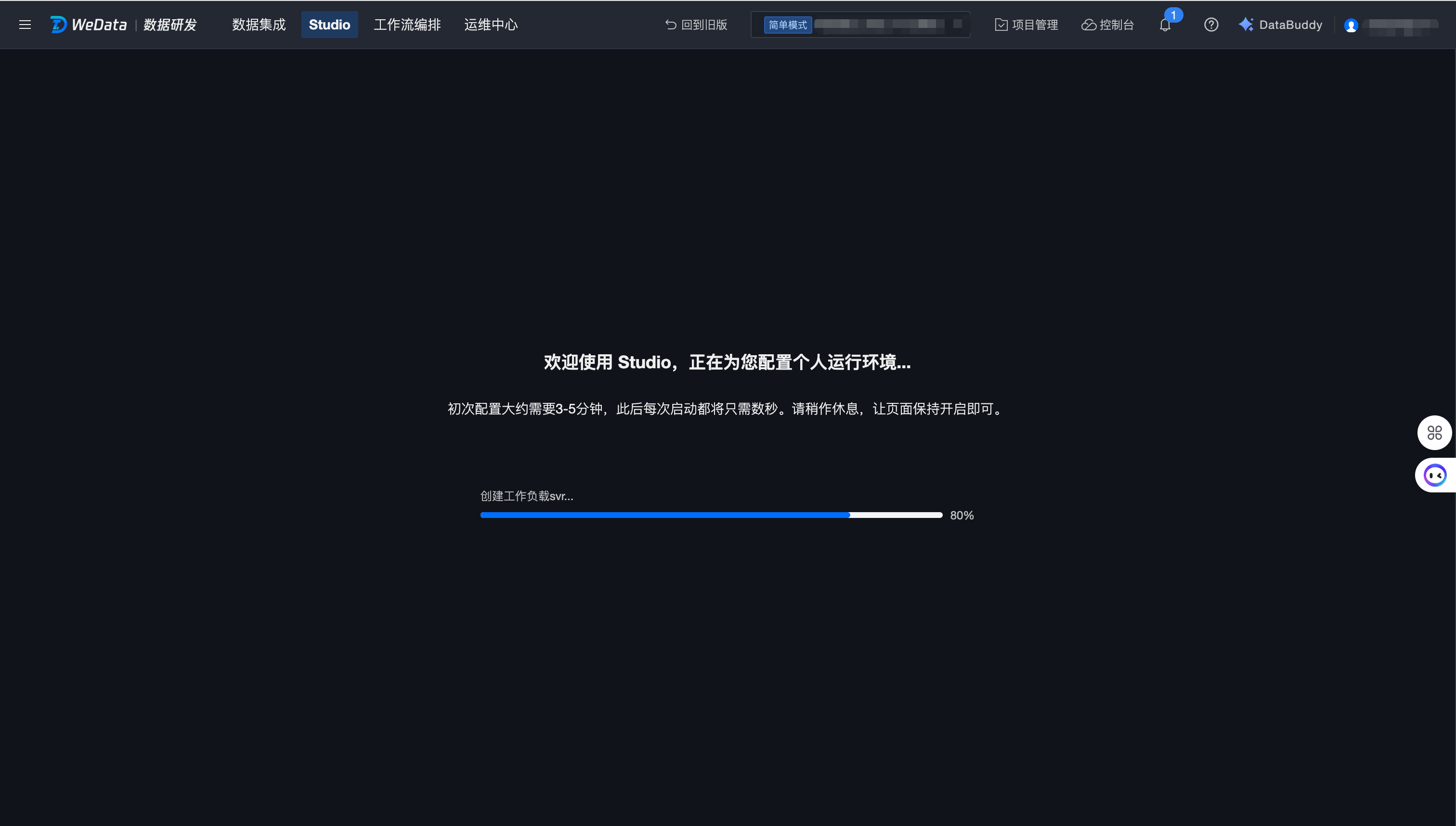
单击数据研发 > Studio,进入 Studio 需要先拉起个人运行环境,按照项目+用户进行隔离,即每个用户在每个项目中独享一个个人运行环境。
首次启动个人运行环境大概需要几分钟,后面再次进入可以做到秒级响应。
文件目录管理
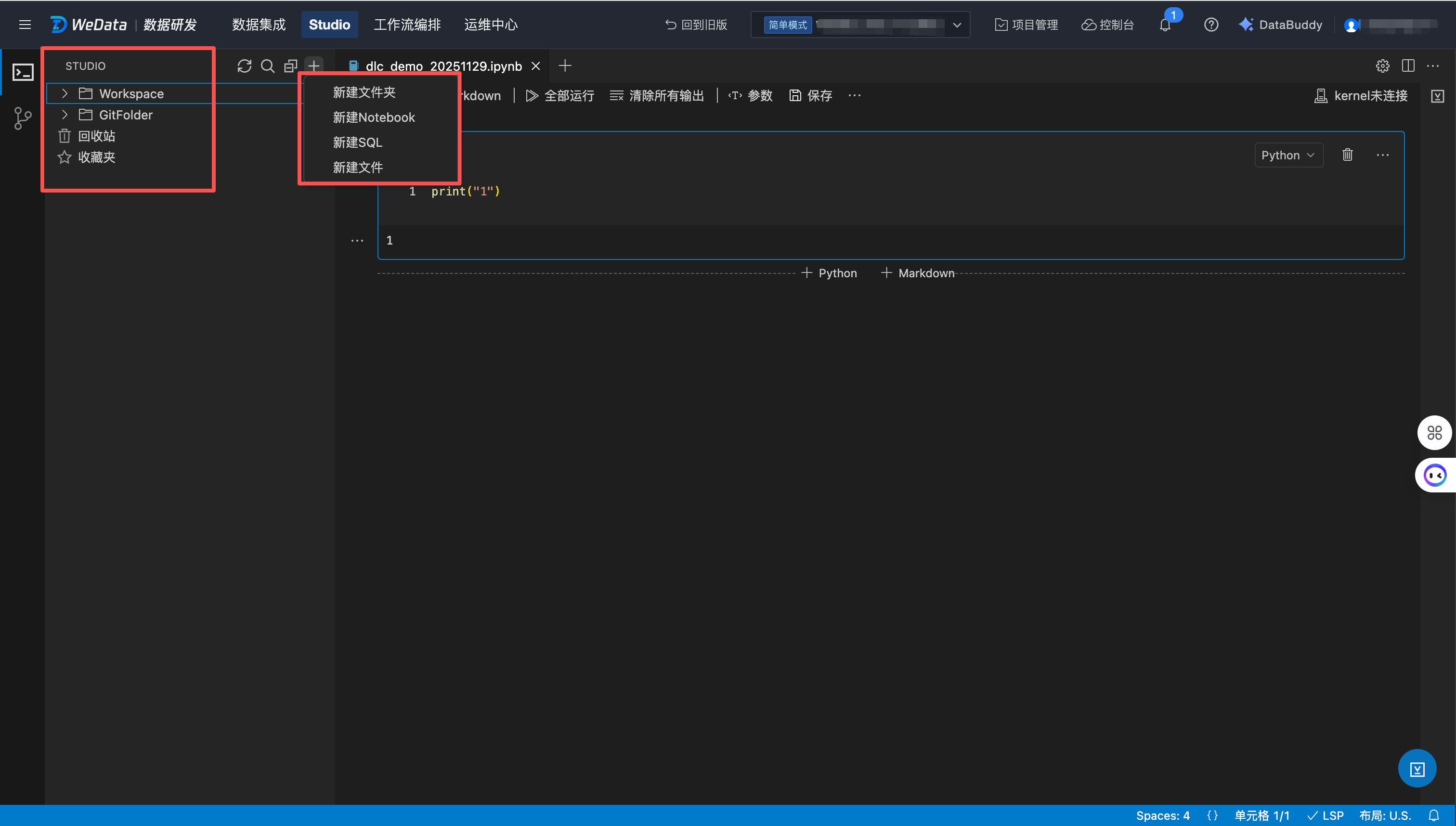
Studio 文件目录结构包括四部分:Workspace、GitFolder、回收站、收藏夹。
Workspace 为本地文件夹。
GitFolder 为 Git 文件夹,支持对接远程 Git 仓库进行代码管理。
回收站用于存放当前用户删除后的文件夹和文件。
收藏夹用于存放当前用户收藏的文件夹和文件。
文件管理操作
Studio 文件目录管理的对象包括:文件夹、Notebook(.ipynb)、SQL(.sql)、文件(.py、.csv 等),各类对象支持的管理操作包括:
操作名称 | Workspace 文件夹 | GitFolder 文件夹 | Notebook、SQL、文件 |
新建文件夹 | ✓ | ✓ | × |
新建 Notebook | ✓ | ✓ | × |
新建文件 | ✓ | ✓ | × |
移动 | ✓ | ✓ | ✓ |
复制 | × | × | ✓ |
复制路径 | ✓ | ✓ | ✓ |
复制相对路径 | ✓ | ✓ | ✓ |
重命名 | ✓ | ✓ | ✓ |
上传 | ✓ | ✓ | × |
下载 | ✓ | ✓ | ✓ |
删除 | ✓ | ✓ | ✓ |
收藏 | ✓ | ✓ | ✓ |
权限配置 | ✓ | × | ✓ |
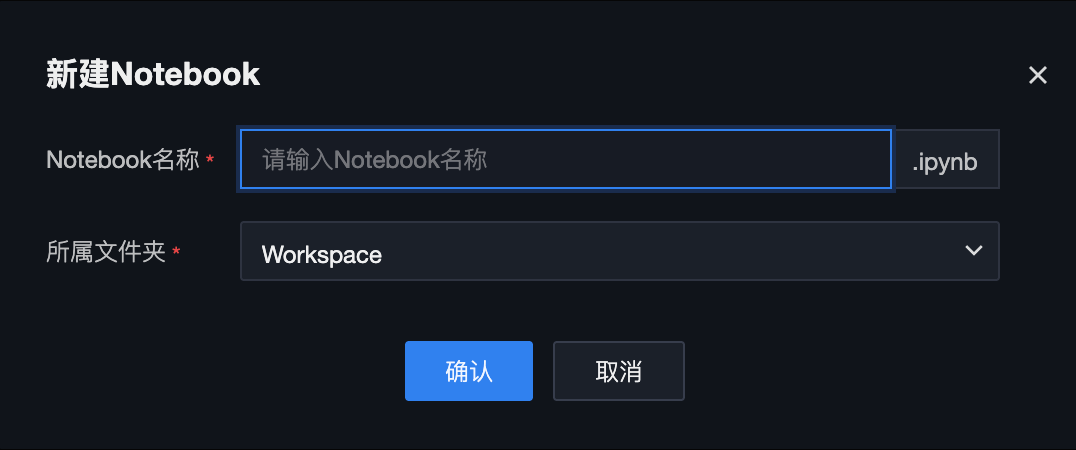
新建 Notebook
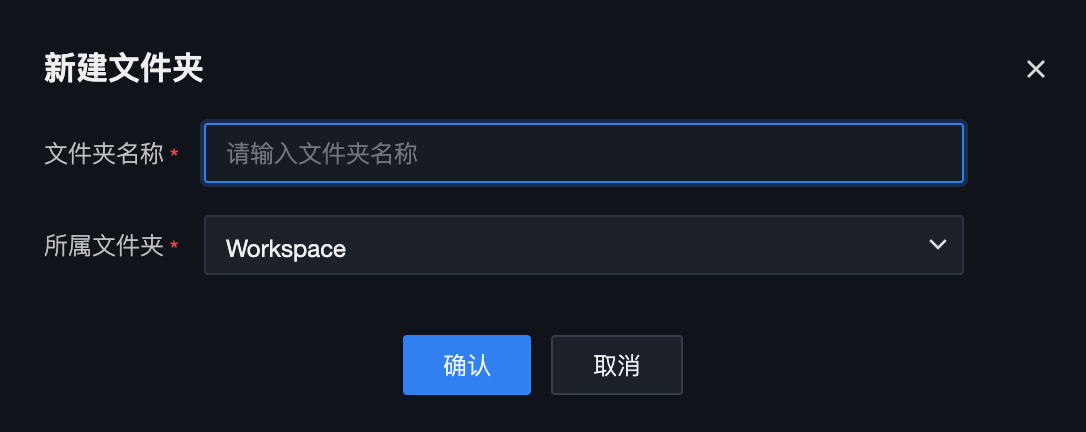
新建文件夹
单击新建文件夹,填写文件夹名称和所属文件夹路径。
新建 Notebook 文件
单击新建 Notebook,填写 Notebook 名称和所属文件夹路径。
编辑 Notebook 文件
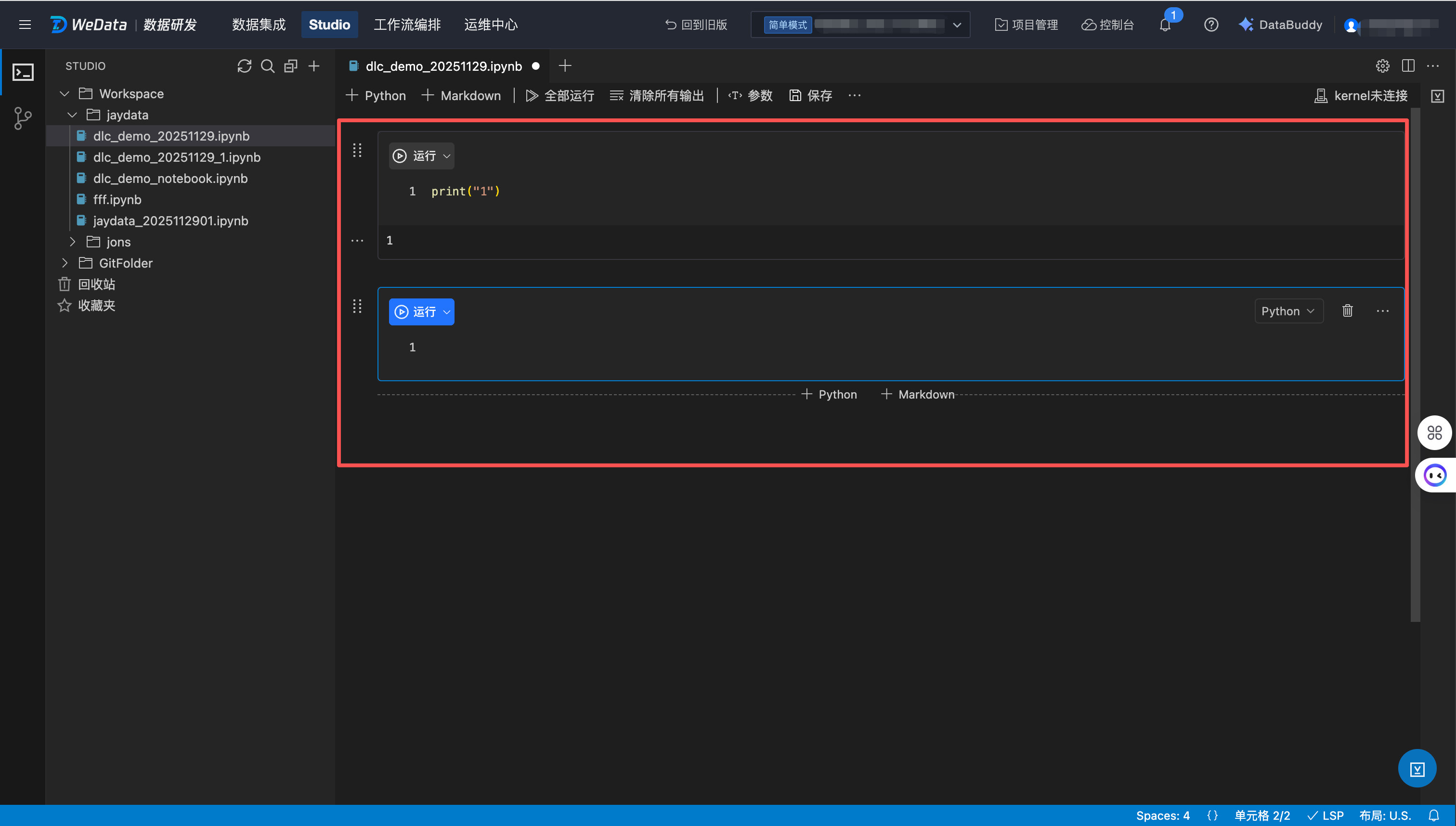
在右侧 IDE 区域,支持新建单元格、剪切单元格、复制单元格、粘贴单元格、删除单元格、移动单元格、编辑单元格、修改单元格语言类型等一系列操作。
运行 Notebook
运行 Notebook 文件需要选择一个运行内核,WeData 采用远程内核的方式,将任务提交到大数据存算引擎执行,使用的是引擎计算资源。
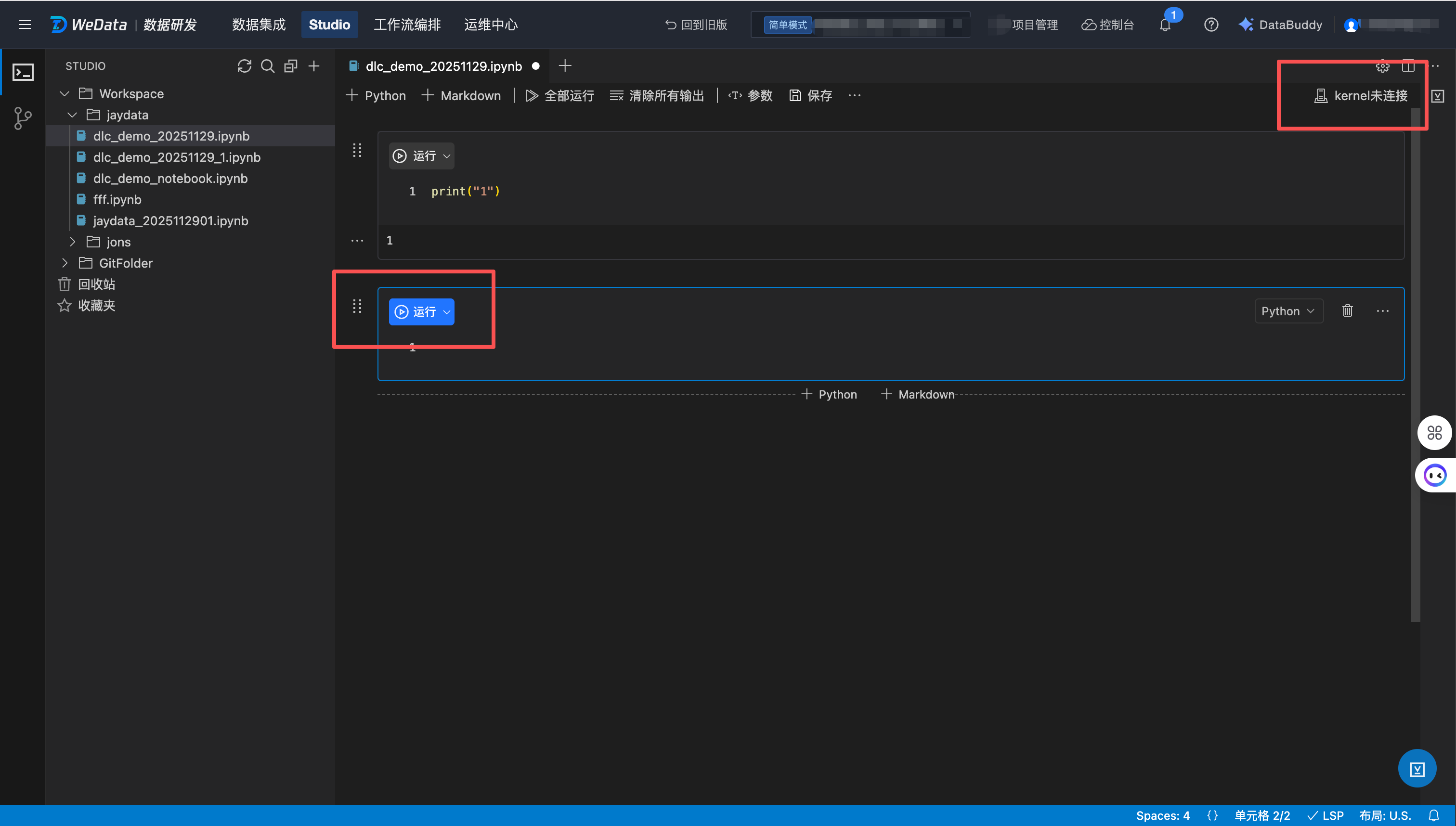
选择内核
1. 单击单元格上方的运行,自动打开创建内核的弹窗;
2. 单击 IDE 右上角 kernel 未连接,打开创建内核的弹窗。
内核配置
以 DLC 引擎为例,假设当前项目仅绑定了 DLC 引擎,则 Notebook 文件等内核配置页面如下:
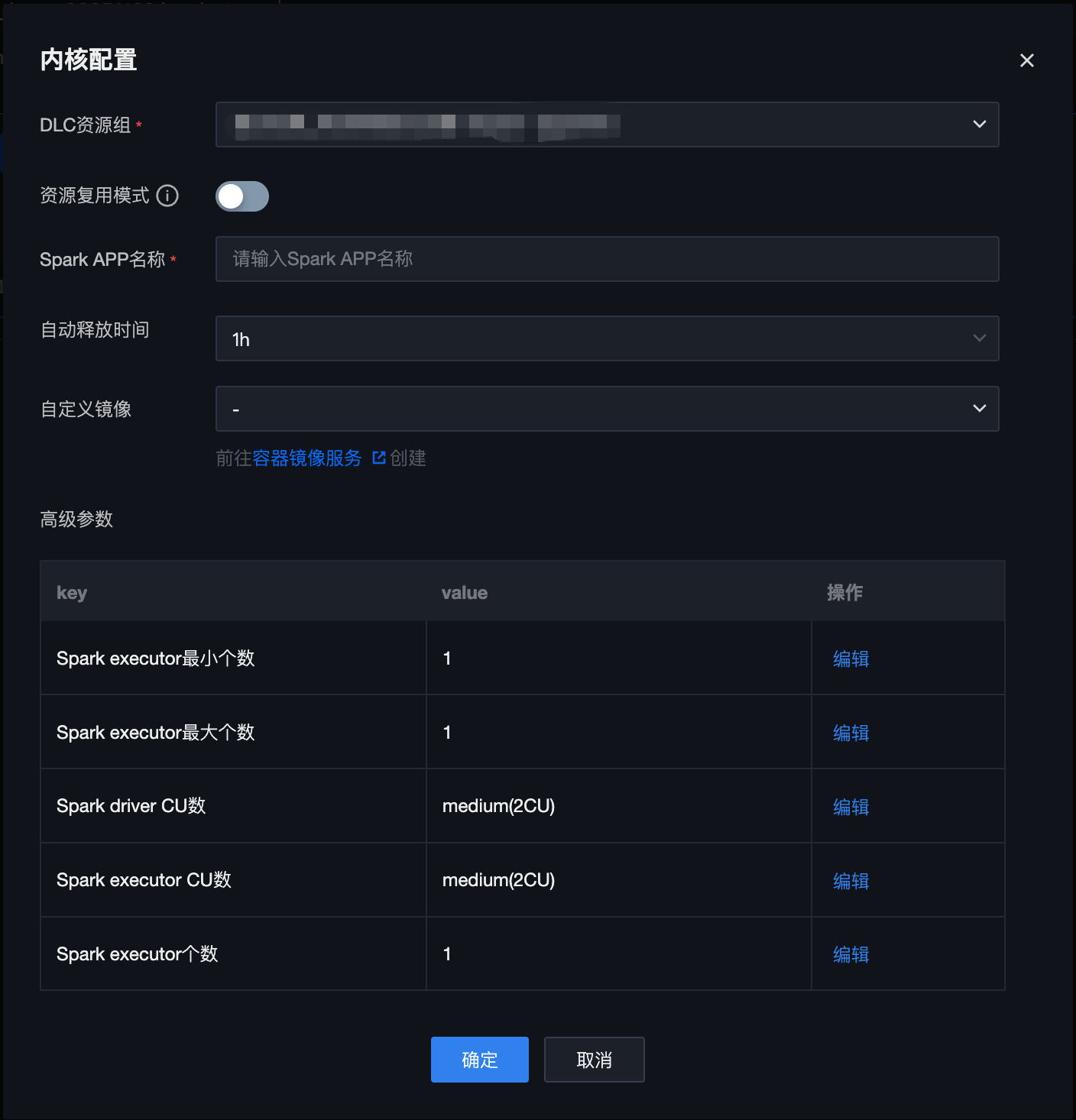
属性项 | 属性项描述 | 使用限制 |
DLC 资源组 | 选择当前项目所绑定的一个 DLC 引擎中的资源组 | DLC 引擎:仅支持标准引擎-Spark 类型的 DLC 引擎; 资源组:仅支持业务场景为“机器学习”类型,框架类型为“Spark MLlib”的资源组。 |
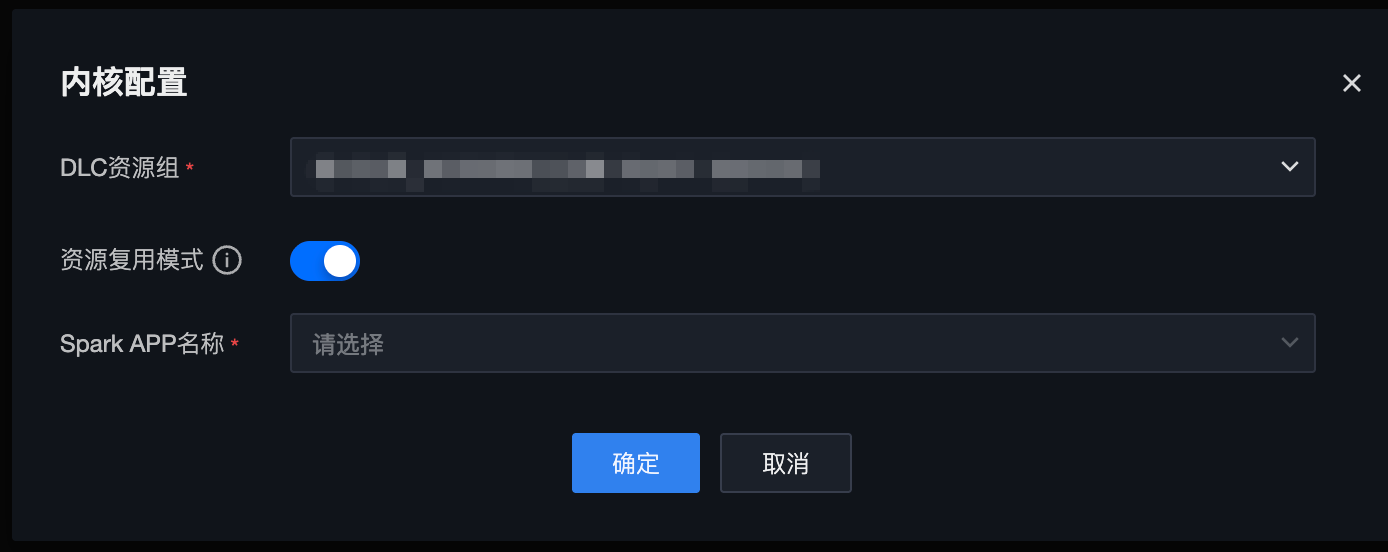
资源复用模式开启 | 开启后,可以选择已经创建好的 Spark APP 创建内核,用于节约引擎资源和缩短内核创建时间 | 如果两个 Notebook 文件使用了同一个 Spark APP,则运行环境会共享。 |
Spark APP 名称 | 支持选择当前项目、当前用户已创建的一个 Spark APP | - |
资源复用模式关闭 | 关闭后,则新建一个 Spark APP | 新建一个 Spark APP 可以实现文件间的运行环境隔离,但通常需要几分钟的时间。 |
Spark APP 名称 | 填写 Spark APP 名称,便于后续复用选择 | - |
自动释放时间 | 选择 Spark APP 不活跃自动释放时间 | - |
自定义镜像 | 默认为 DLC 资源组内置镜像,支持用户选择 TCR 自定义镜像 | - |
高级参数 | 填写创建的 Spark APP 规格参数 | - |
查看运行结果
针对 DataFrame 数据结构,当使用 display()函数进行数据展示时,以及 SQL 语法的数据查询结果的场景,WeData 进行了定向优化,支持对数据结果进行表格化的展示和操作。
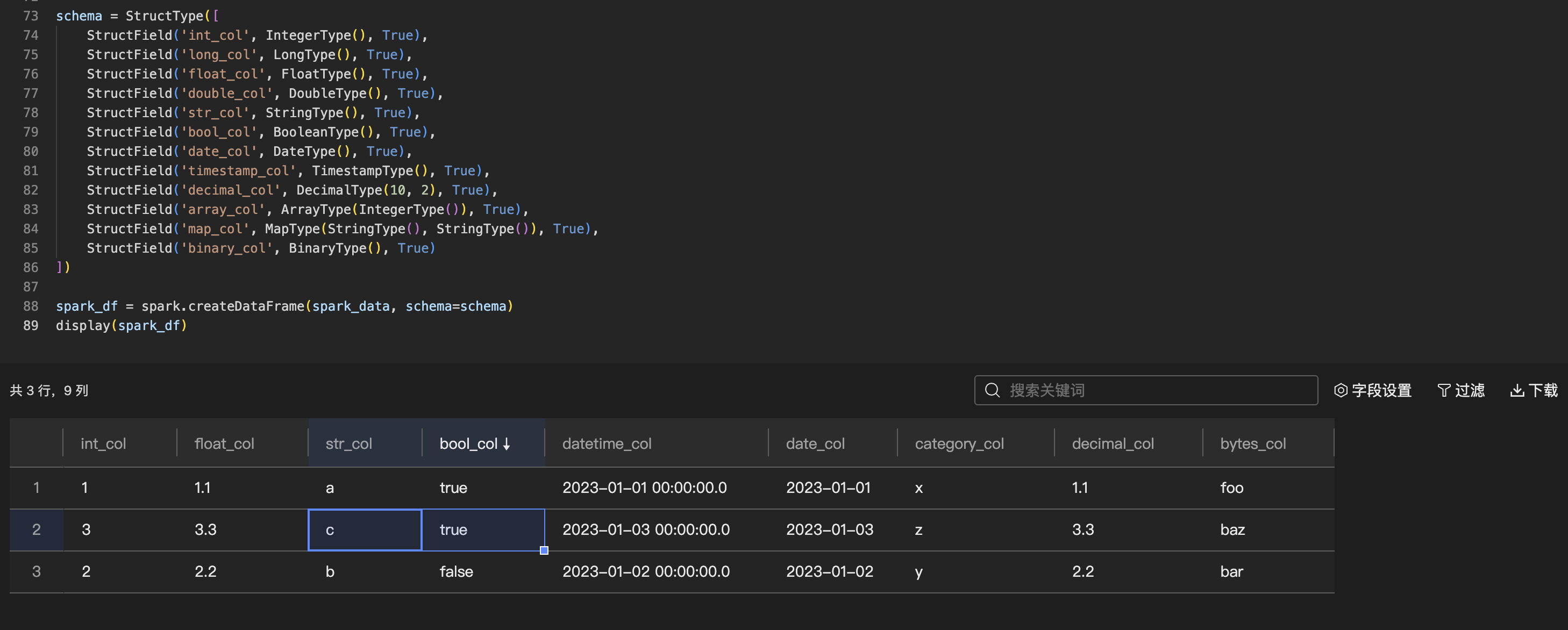
数据结果查看
支持数据结果的预览,可以圈选自定义区域的数据,进行右键和快捷键复制;支持单击列名进行升降序排序。
说明:
最多支持预览1万行数据,数据量大小不超过2M。
数据检索
支持输入关键字进行模糊搜索,检索结果可高亮展示;单击"<"、">"按钮可以实现多个检索结果之间的切换。

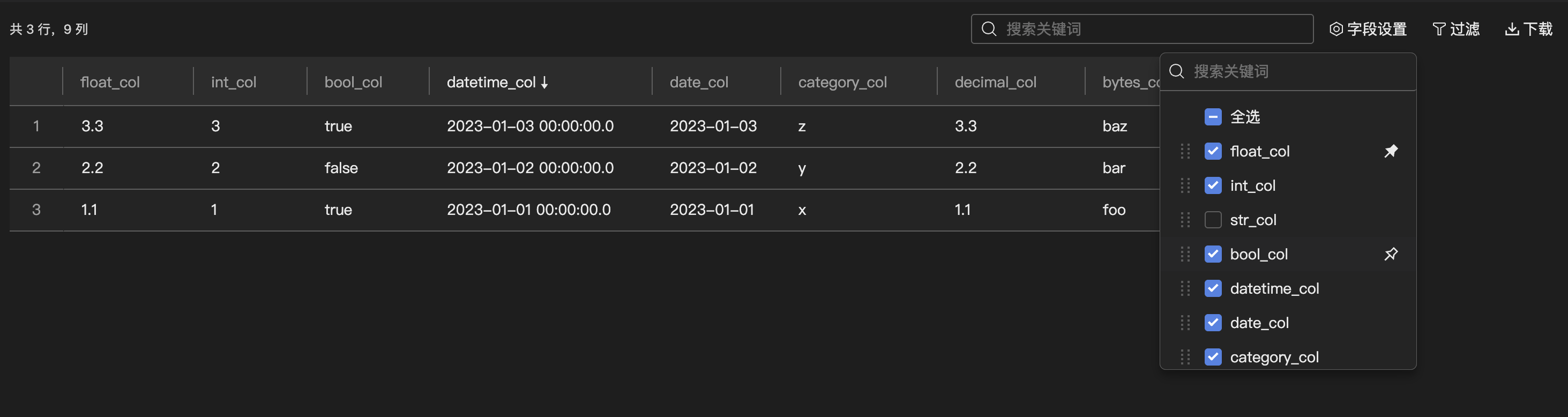
字段设置
支持配置数据结果展示的列名,可以单击图钉按钮置顶展示指定字段。
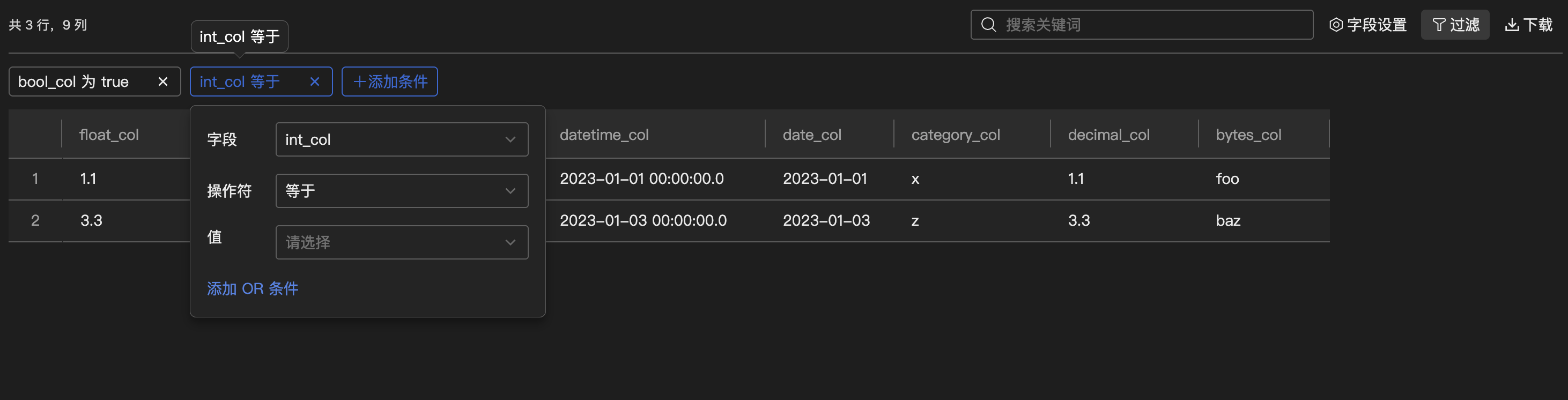
字段过滤
单击过滤按钮,可以添加多个筛选条件对数据结果过滤。
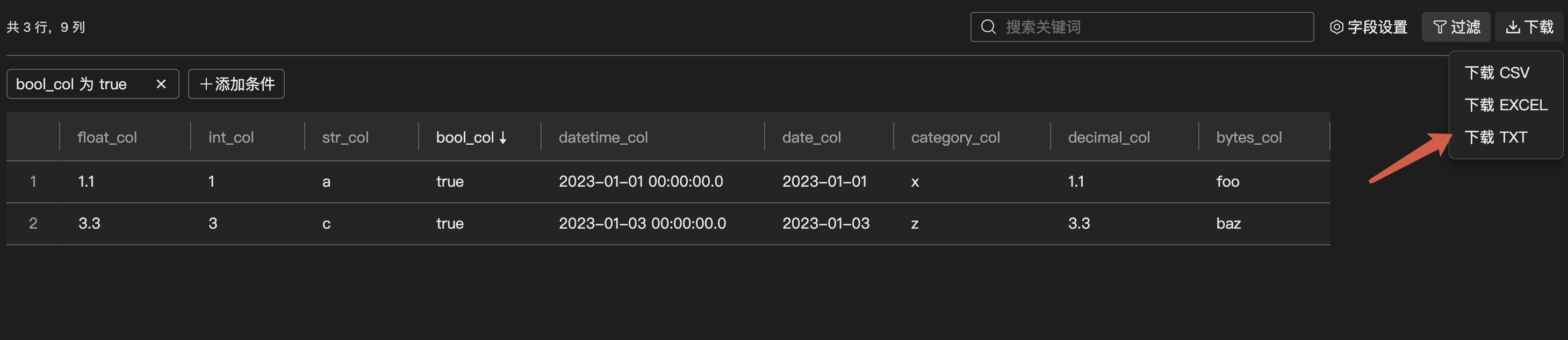
数据下载
单击下载,可以将数据结果下载为 csv、excel、txt 文件。
说明:
最多支持下载1万行数据,数据量大小不超过2M。
动态参数实现
Notebook 支持定义动态参数,实现参数化文件代码调试的功能。
参数的定义
1. 通过代码定义。
通过 dlcutils.widgets.text()函数定义参数名称、默认值、标签:
函数名称 | 参数定义 | 举例说明 |
dlcutils.widgets.text(name: str, default: str, label: str = "") | name:参数名称 default:参数默认值 label:参数标签 | dlcutils.widgets.text("fav_food" , "bean","favorite food") |
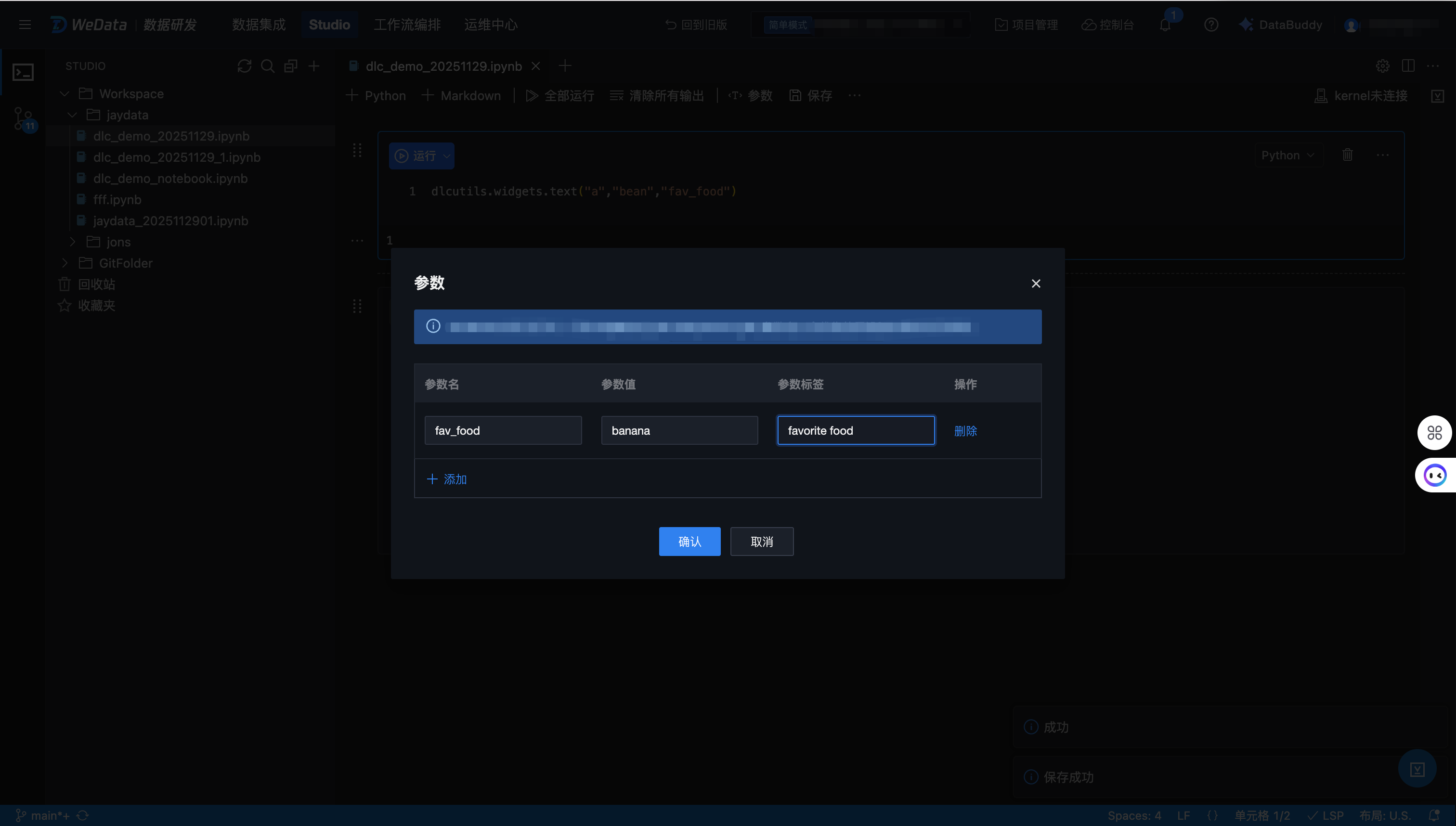
2. 通过可视化界面定义。
单击上方工具栏“参数”按钮,在弹窗中输入参数名、参数值、参数标签:
参数的获取
通过 dlcutils.widgets.get()函数获取参数的取值:
函数名称 | 参数定义 | 举例说明 |
dlcutils.widgets.get(name: str) | name:参数名称 | dlcutils.widgets.get(fav_food) |
说明:
在 Notebook 调试运行时,代码输出的参数取值,将使用弹窗中的参数值替换函数定义的默认值。
文件版本管理
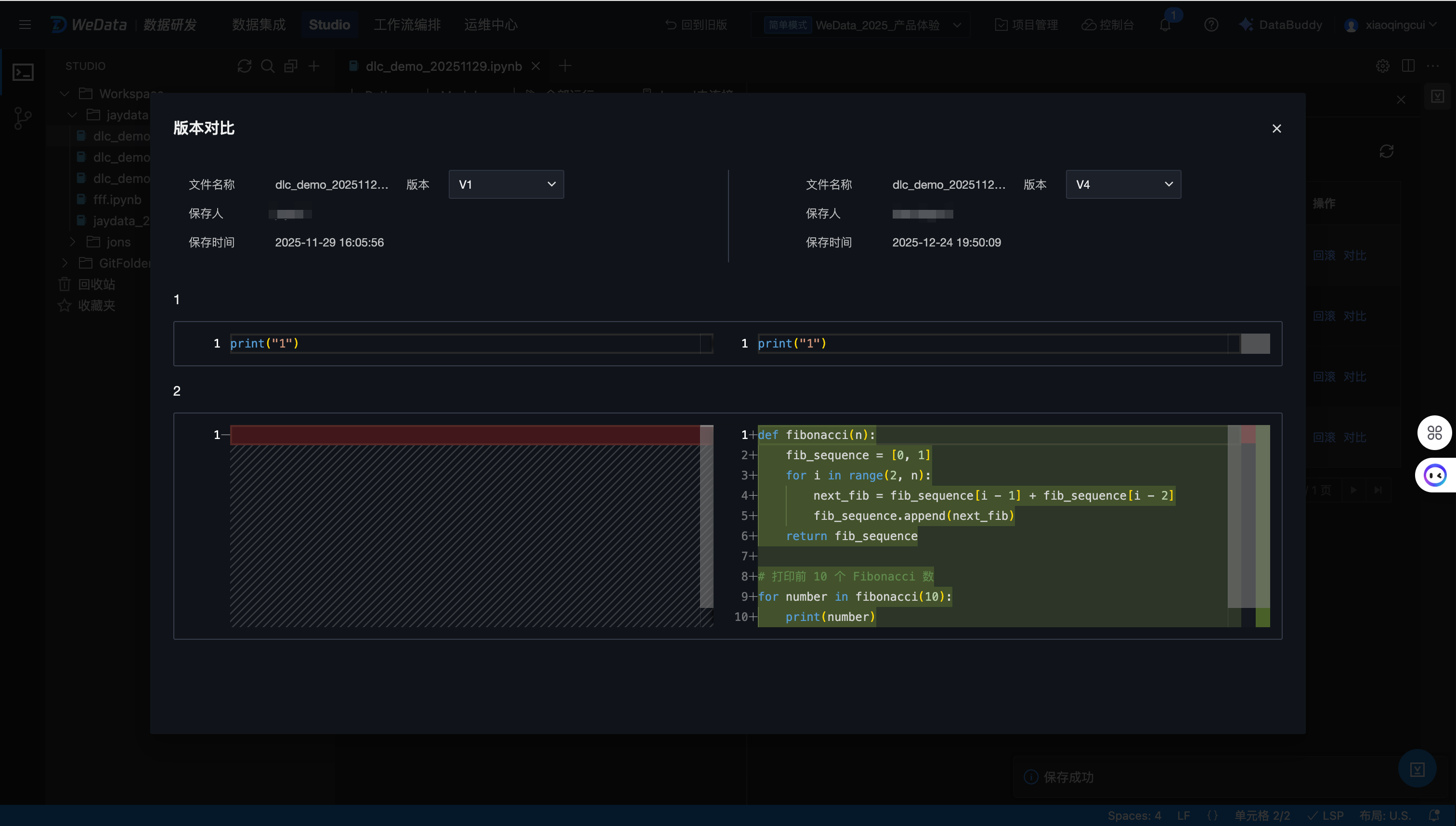
单击保存,会对当前文件生成一个保存版本,单击右侧“版本记录”可以查看所有历史版本,支持版本对比、版本回滚等操作。
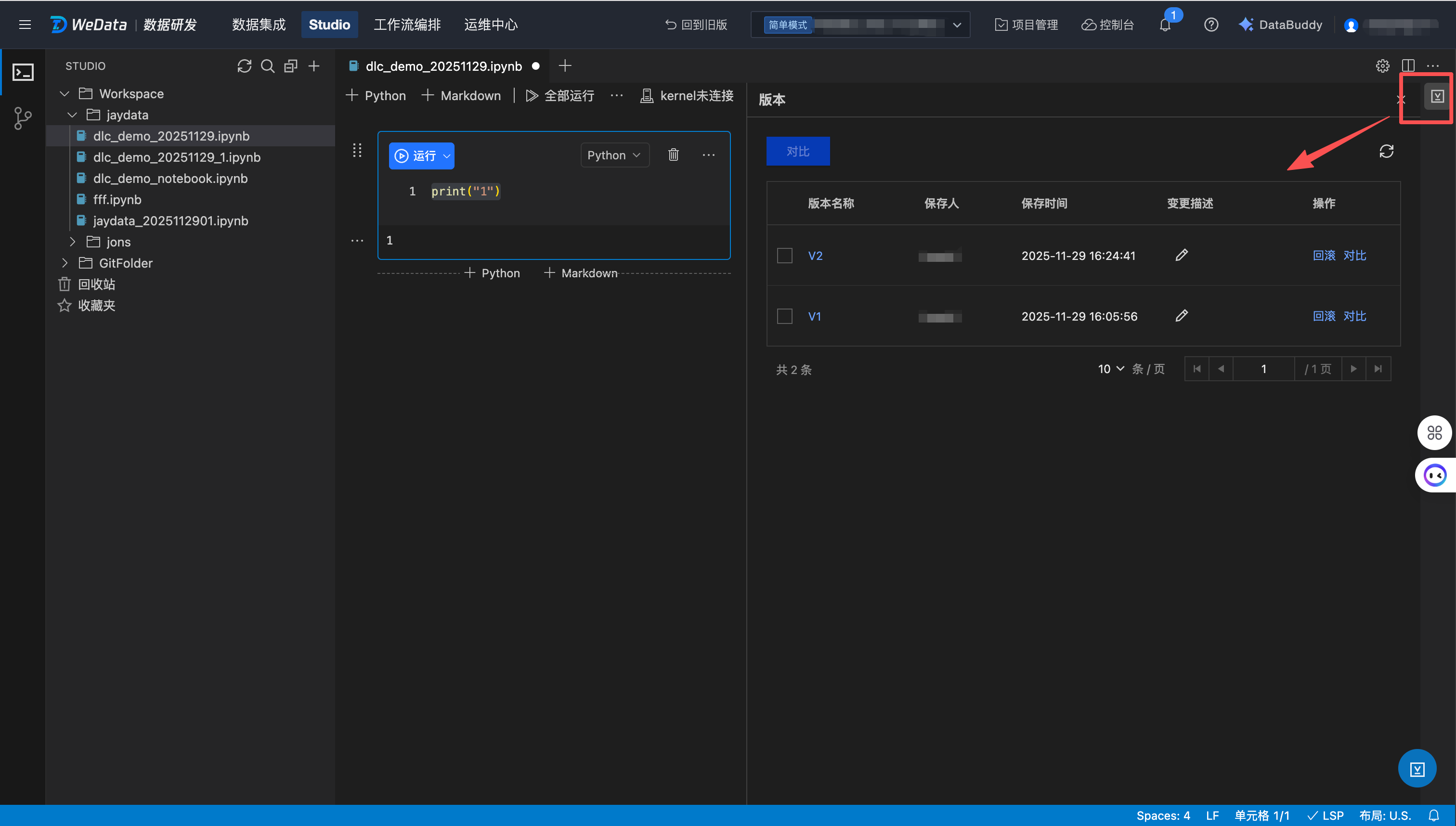
版本对比:
文件权限管理
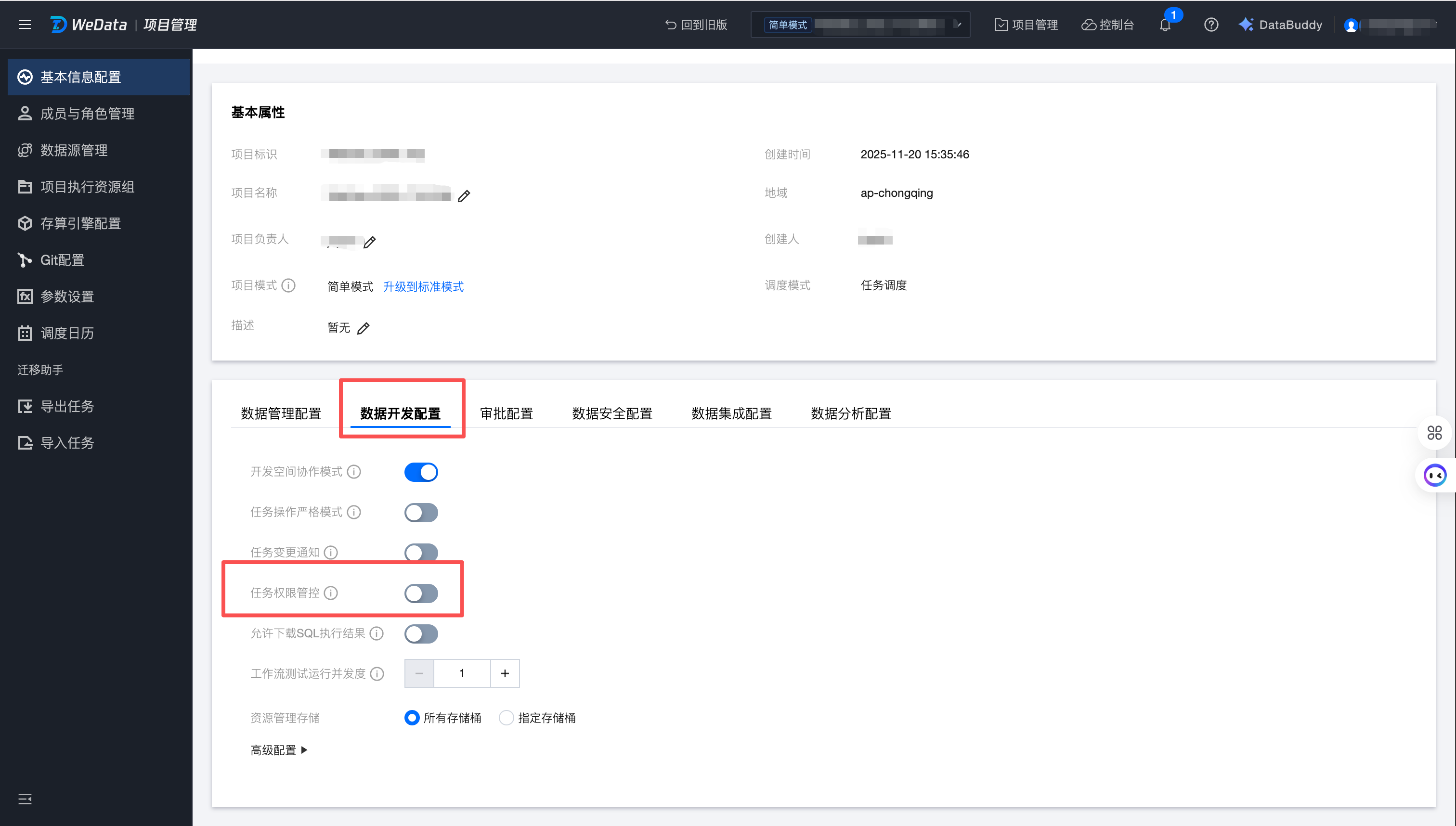
1. 进入“项目管理 > 数据开发配置”,开启任务权限管控的开关。
说明:该功能仅对 DLC 引擎生效,EMR 引擎暂不支持。
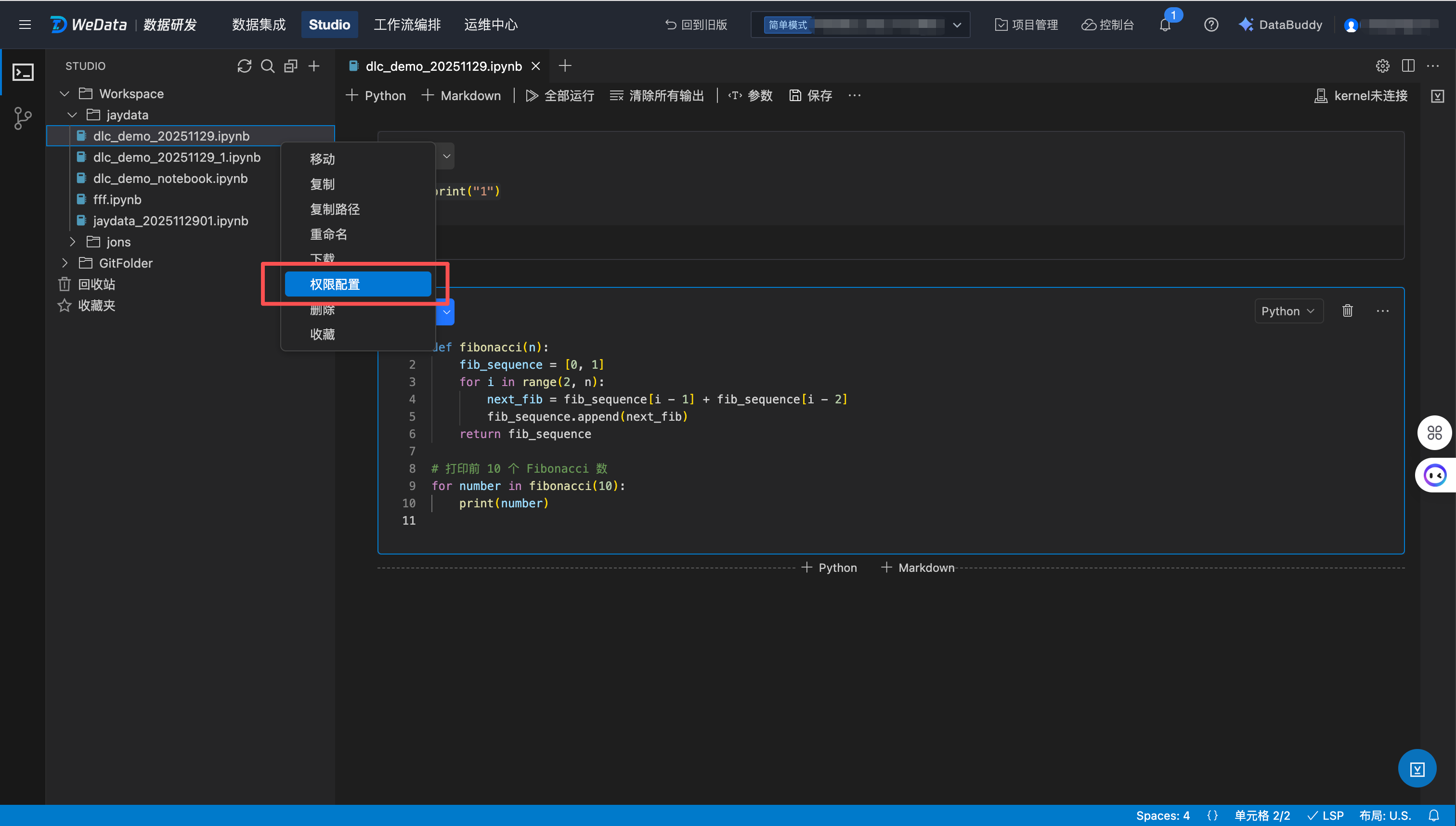
2. 进入 Studio,右键 Workspace 中的文件夹或文件名称,选择权限配置。
说明:
仅 Workspace 支持文件权限管理,GitFolder 不支持配置权限,项目下的所有成员均可见、可操作。
3. 在权限配置的弹窗中,可以增加、编辑或删除权限配置项。
项目管理员,默认拥有所有文件夹和文件的管理权限。
文件夹或文件的创建者,默认拥有所创建对象的管理权限。
文件夹中的子文件或文件,默认继承父文件夹的权限配置。
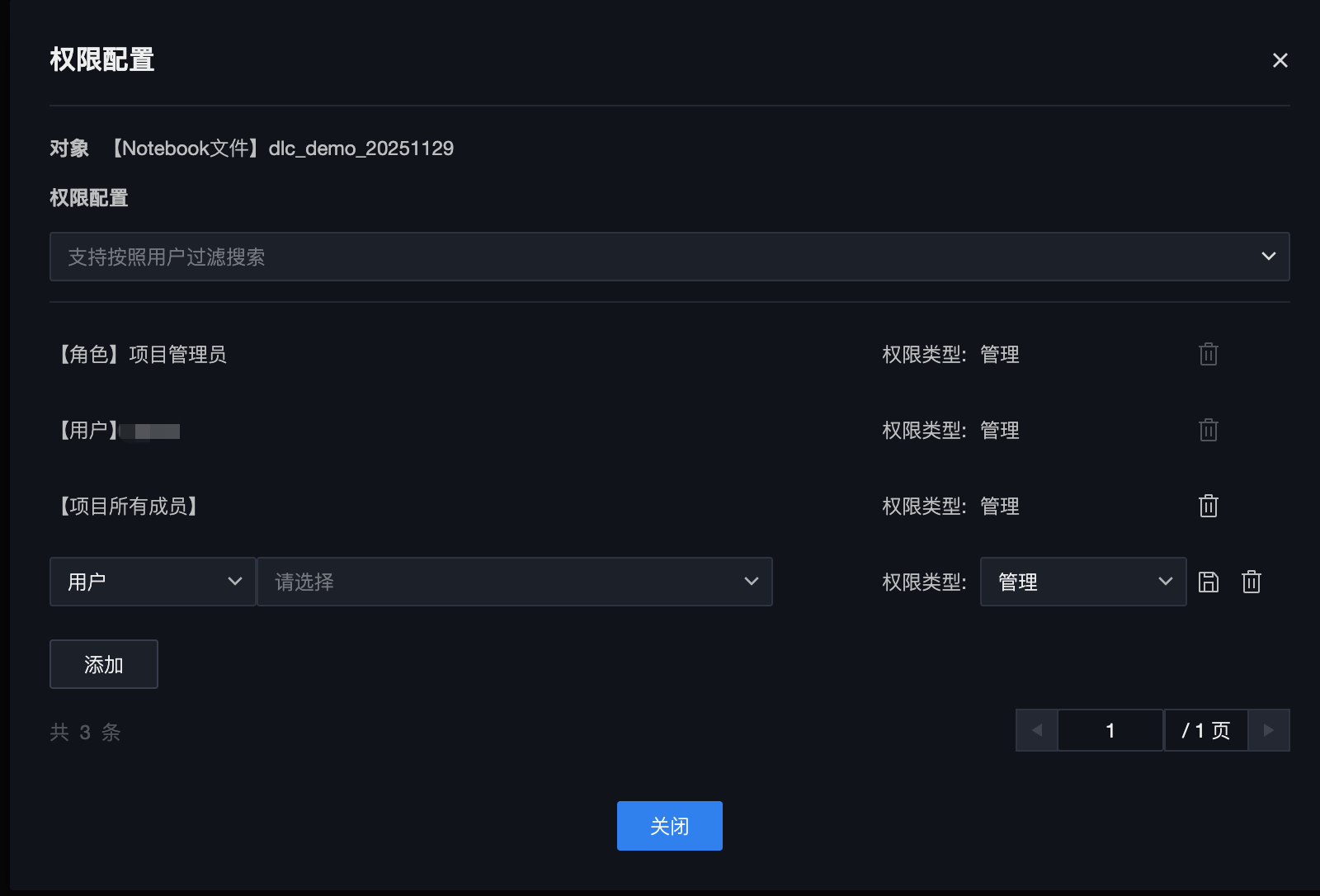
属性项 | 属性项说明 |
授权对象 | 支持选择:角色、用户、项目所有成员 |
权限项 | 支持选择:管理、无 |
数据目录
数据检索
数据目录按照 Catalog、库、表、字段的层级进行展示,支持用户在开发过程中进行浏览,并通过代码的方式进行数据访问。
注意:
使用数据目录的前置条件为,当前项目绑定的 DLC 引擎所在地域已经开通了 TC-Catalog。
单击搜索,可以输入 Catalog 名、库名、表名模糊搜索。
数据访问
支持在代码中通过 PySpark 的方式读写数据目录中的内容。
快捷操作:
1. 单击数据表、字段后方的插入,可以将表名、字段名插入到右侧 IDE 中。
2. 单击数据表、字段后方的复制,可以将表名、字段名复制到粘贴剪贴板,后续可以在 IDE 中粘贴使用。
Git 源代码管理
初始化 Git 配置
每个项目可以绑定多个 Git 仓库的地址,由项目管理员或其他有项目管理权限的用户配置,项目中的每一个用户,都需要初始化自己的个人配置,才能正常使用 Git 相关功能。
项目 Git 配置(公网访问)
1. 进入项目管理 > Git配置。
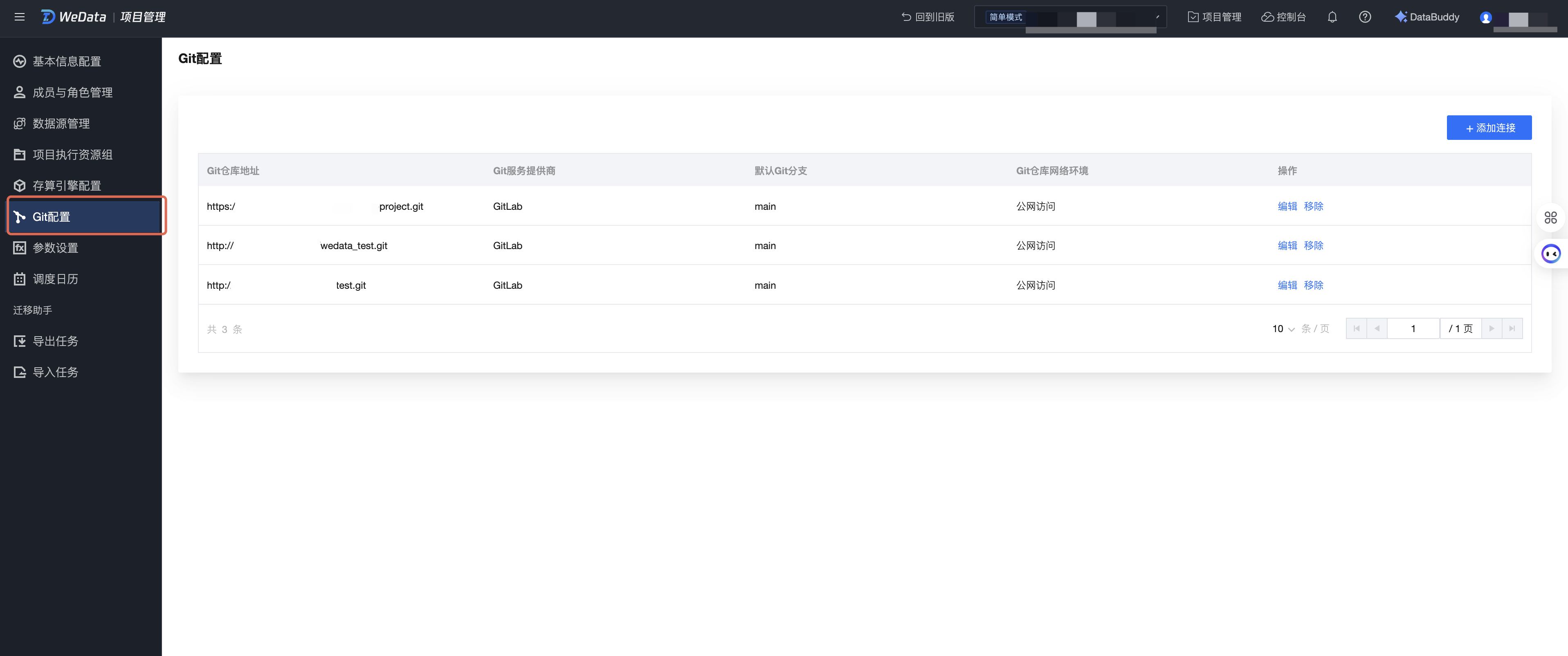
2. 单击添加连接,新增远程 Git 仓库地址的绑定。
依次输入所要使用的 Git 仓库地址、Git 供应商、默认 Git 分支等信息,如果您的远程 Git 仓库是可以公网访问的,则 Git 仓库网络环境选择“公网访问”,然后依次完成初始化网络配置、网络连通性测试。
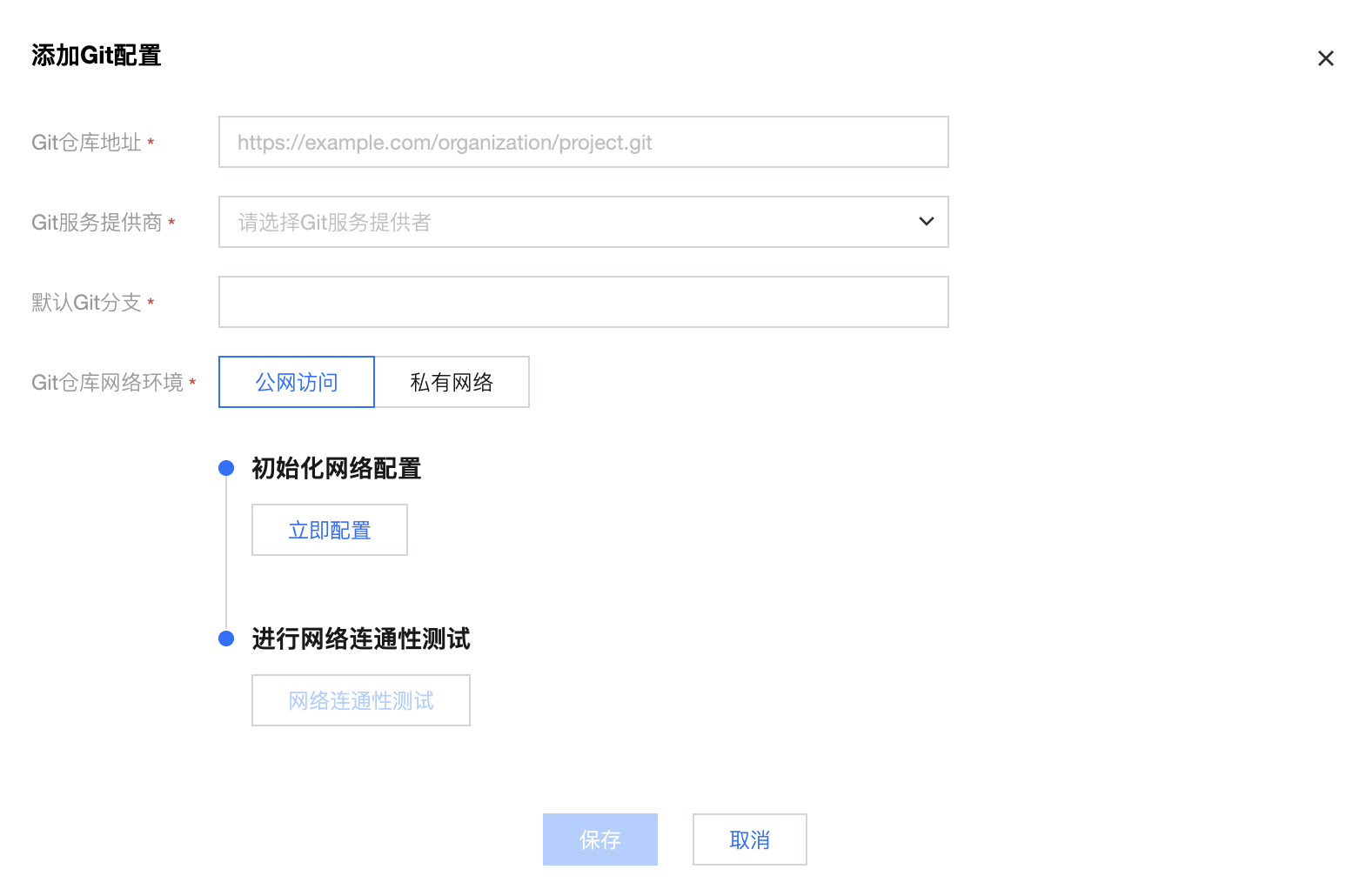
3. 网络连通性测试通过后,保存项目 Git 配置,然后进入个人信息 > 个人配置中完成个人 Git 权限配置。
项目 Git 配置(私有网络)
注意:
如果您的远程 Git 仓库部署在私有网络环境中,请按照此流程进行配置。目前仅支持 HTTP 协议,不支持 HTTPS 协议。
1. 创建终端节点服务。
1.1 进入腾讯云私有网络控制台,选择“私有连接 > 终端节点服务”,单击新建。
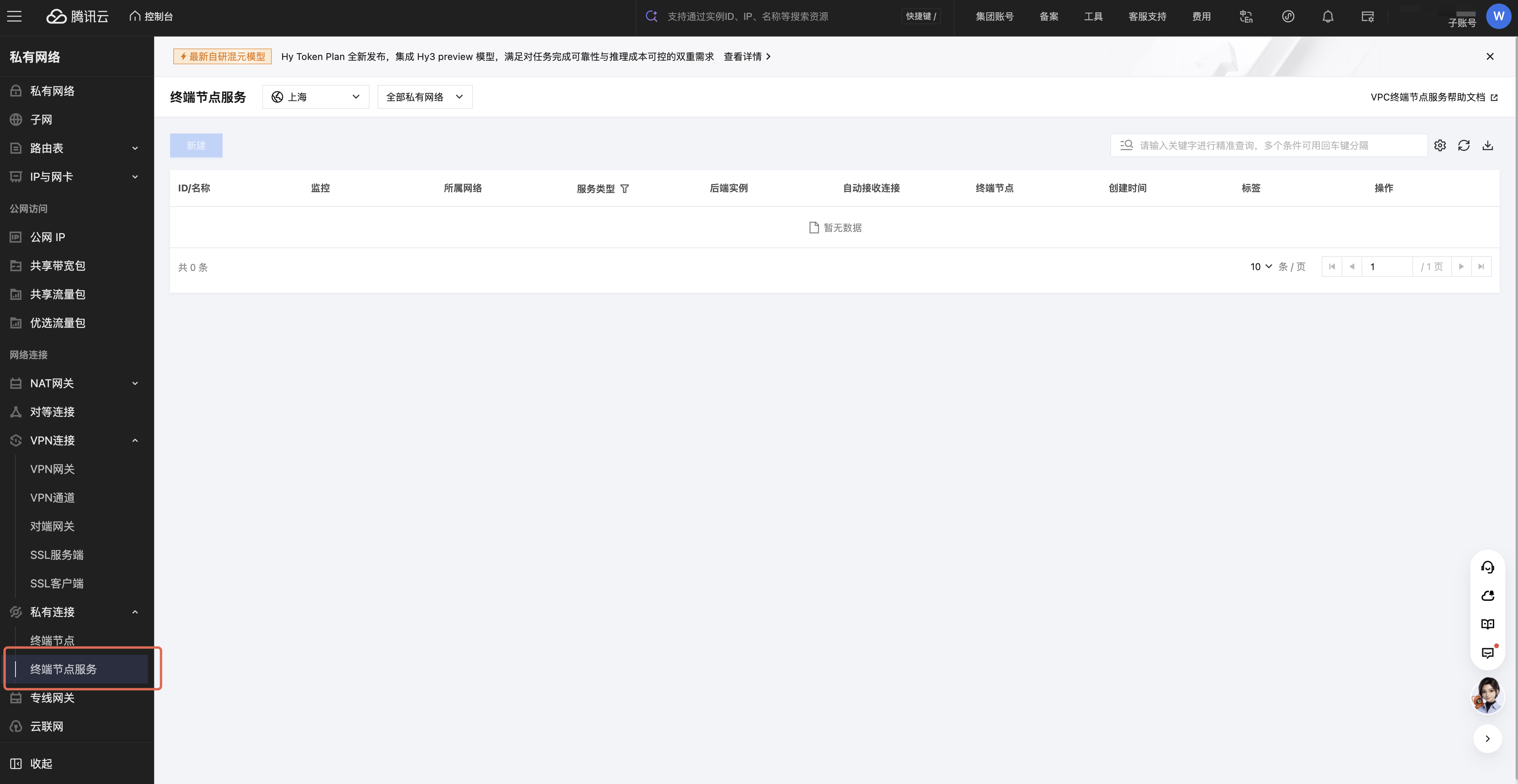
1.2 完成终端节点服务配置,详情可以参考 终端节点服务操作手册。
注意:
终端节点服务需要与 WeData 在相同的地域。
1.3 创建完成后,记录终端节点服务 ID,格式为 vpcsvc-xxxxxxxx,后续填入 WeData。
2. 配置终端节点服务白名单。
进入终端节点服务详情页,单击白名单 > 添加,输入 WeData 所在腾讯云账号的主账号 UIN,确认添加成功。
注意:
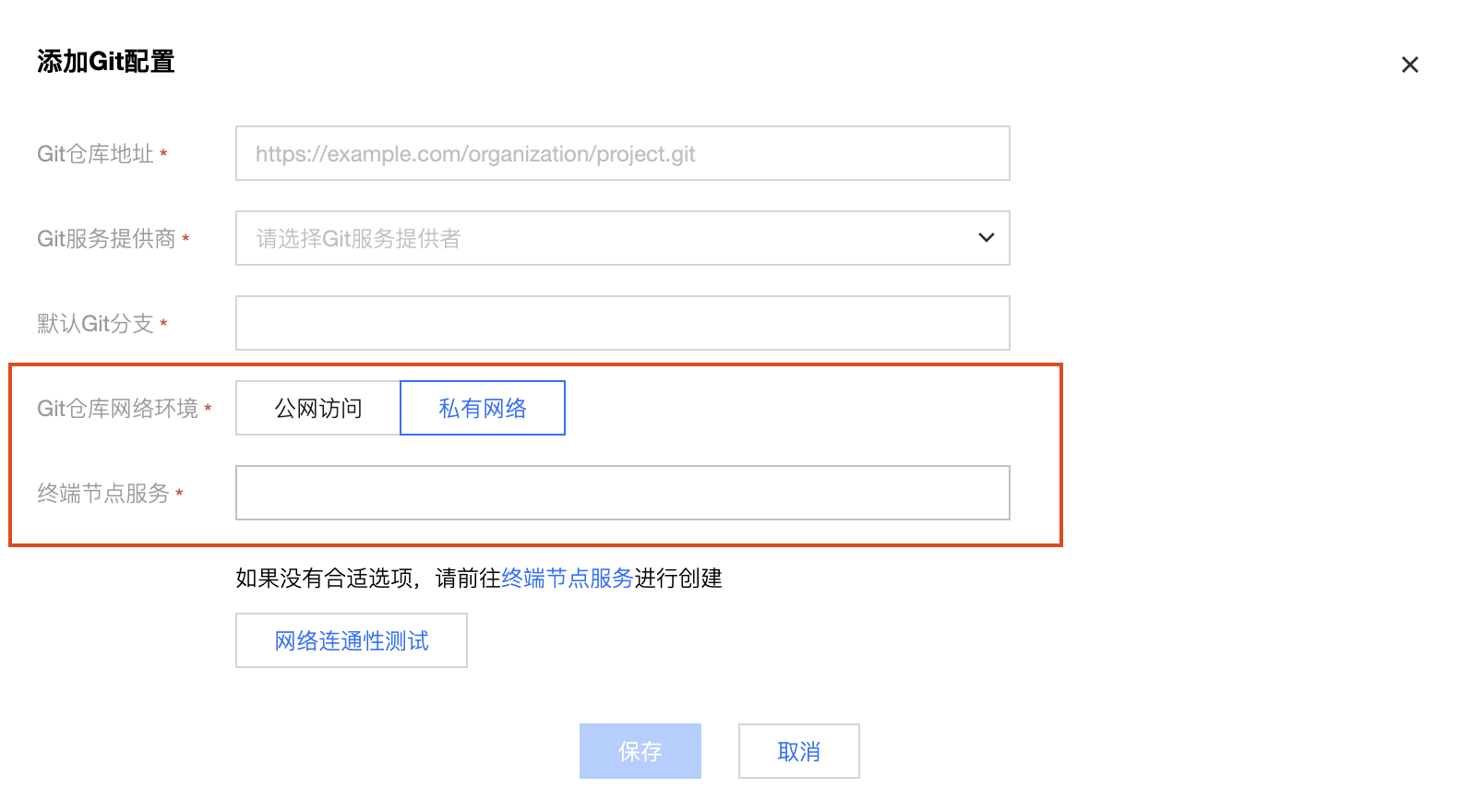
3. 完成 WeData Git 配置。
进入项目管理 > Git配置 > 添加连接,Git 仓库网络环境选择“私有网络”,将步骤 2 中的终端节点服务 ID 填入“终端节点服务中”,然后单击网络连通性测试,测试通过后即可保存配置。
个人 Git 配置
1. 单击个人信息 > 个人配置,在 Git 权限配置中,填写用户名、Token 信息。
2. 单击连通性测试,测试通过后,才可以单击初始化个人运行环境 。
3. 将 Studio 的个人运行环境与远程 Git 仓库进行连接,后续可以将 Studio 中的代码进行远程 Git 仓库托管。
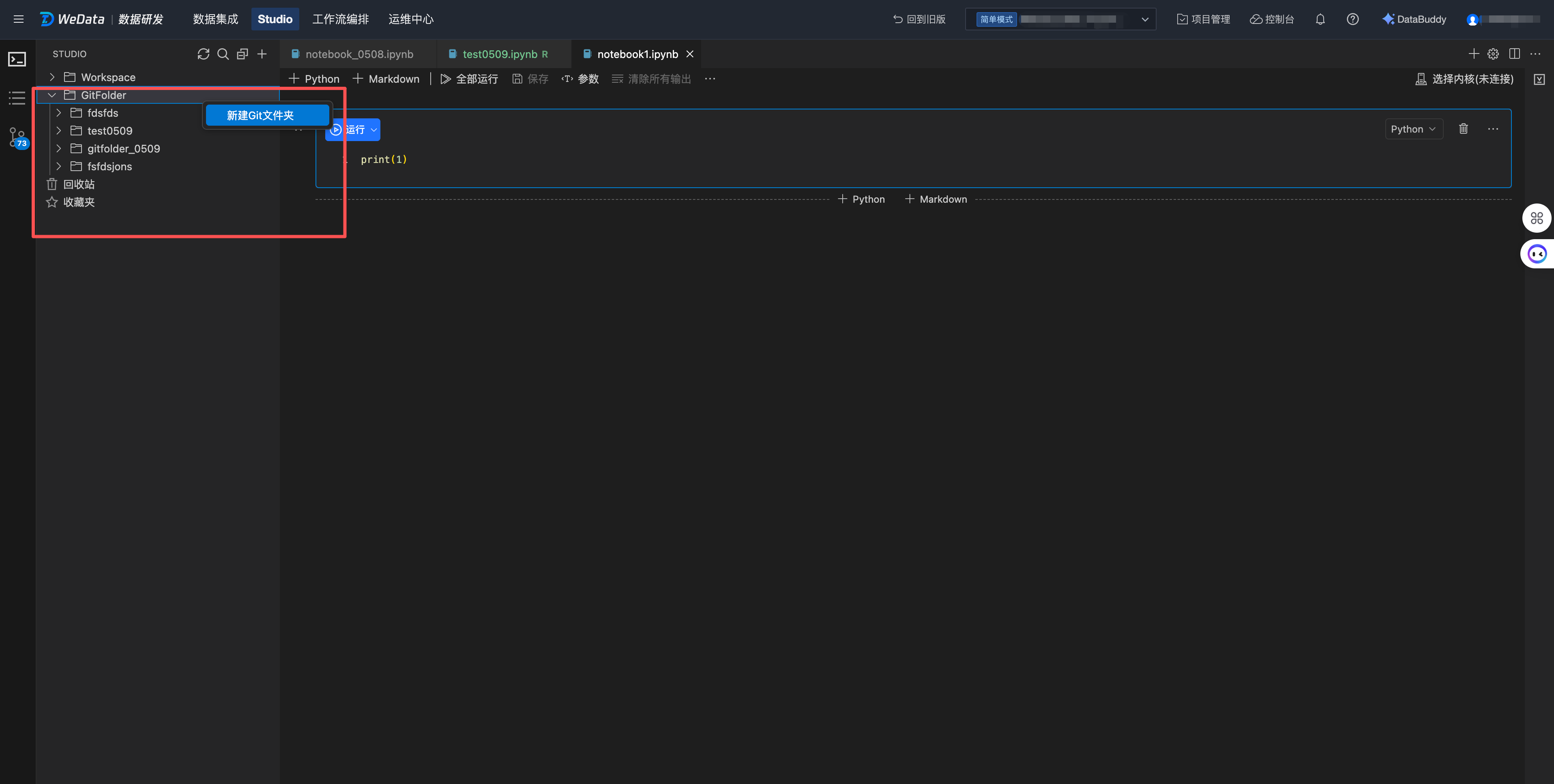
新建 Git 文件夹
1. 上述初始化配置完成后,再次进入 Studio,在 GitFolder 中创建 Git 文件夹。
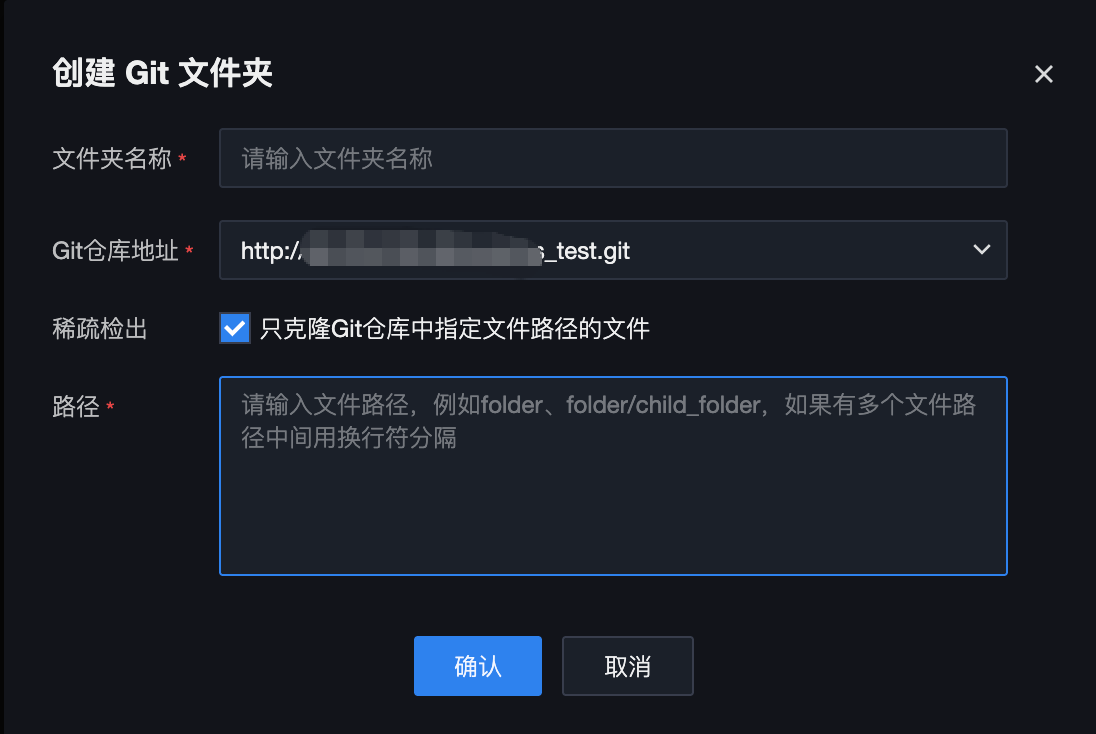
2. 完成 Git 文件夹配置。
文件夹名称:输入文件夹名称。
Git 仓库地址:选择项目中已经绑定的一个远程 Git 仓库。
稀疏检出(可选):如果勾选,则需要输入指定的文件路径,后续将自动拉取指定文件路径下的文件;如果不勾选,则默认会拉取远程 Git 仓库中的所有文件。
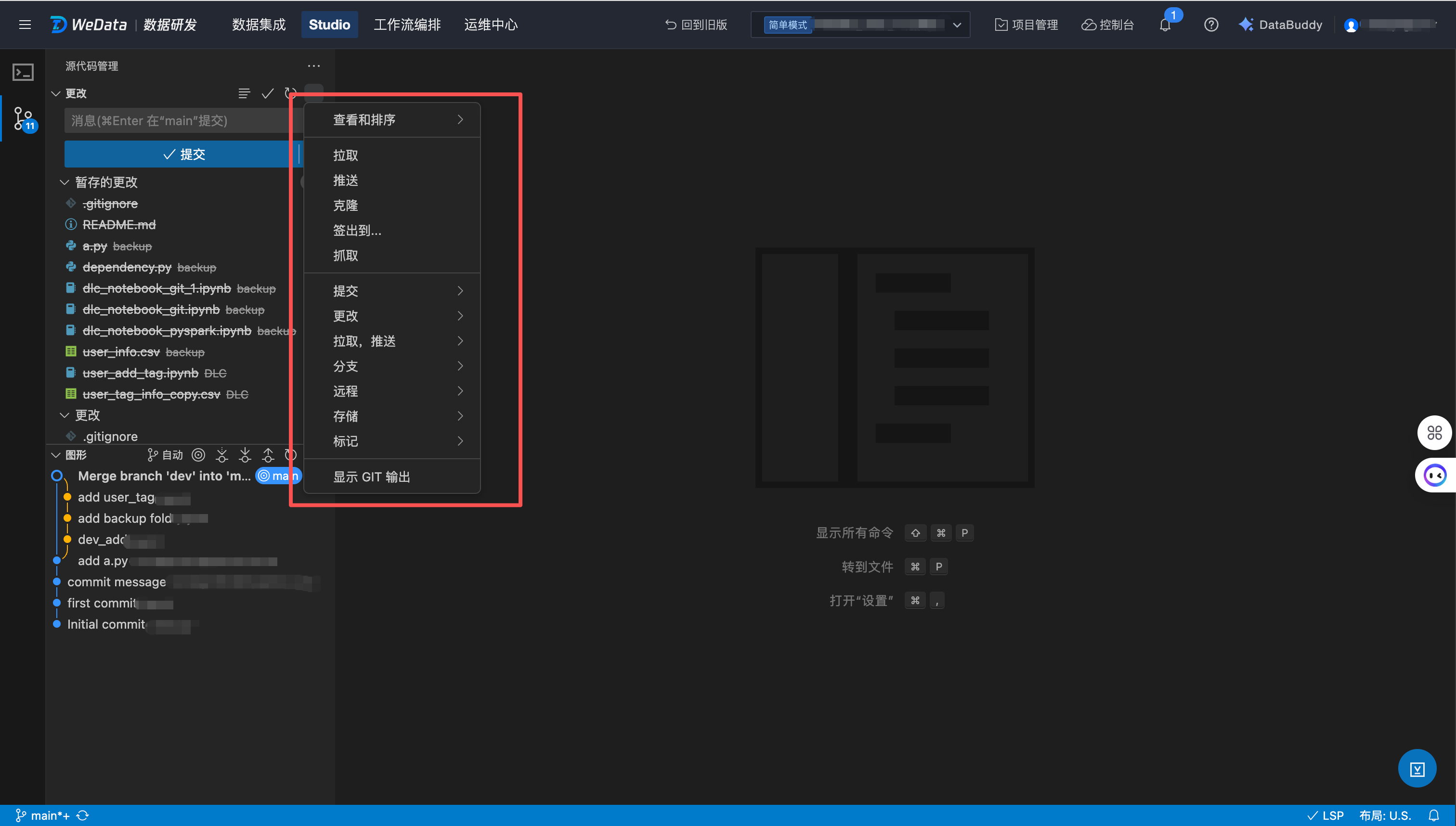
Git 管理操作
单击进入 Git 源代码管理功能,可对 Git 文件夹进行 Git 管理操作,包括但不限于:
提交(commit):将本地的变更提交到工作分支,并添加变更描述。
推送(push):将新的分支推送到远程 Git 仓库。
拉取(pull):从远程 Git 仓库拉取内容到本地。
分支合并(merge):将工作分支的更改合并到另一个分支,例如主分支。
解决合并冲突:在分支合并过程中,如果遇到代码冲突,支持识别和解决。
查看历史记录:查看当前分支的历史记录。
Notebook 任务编排
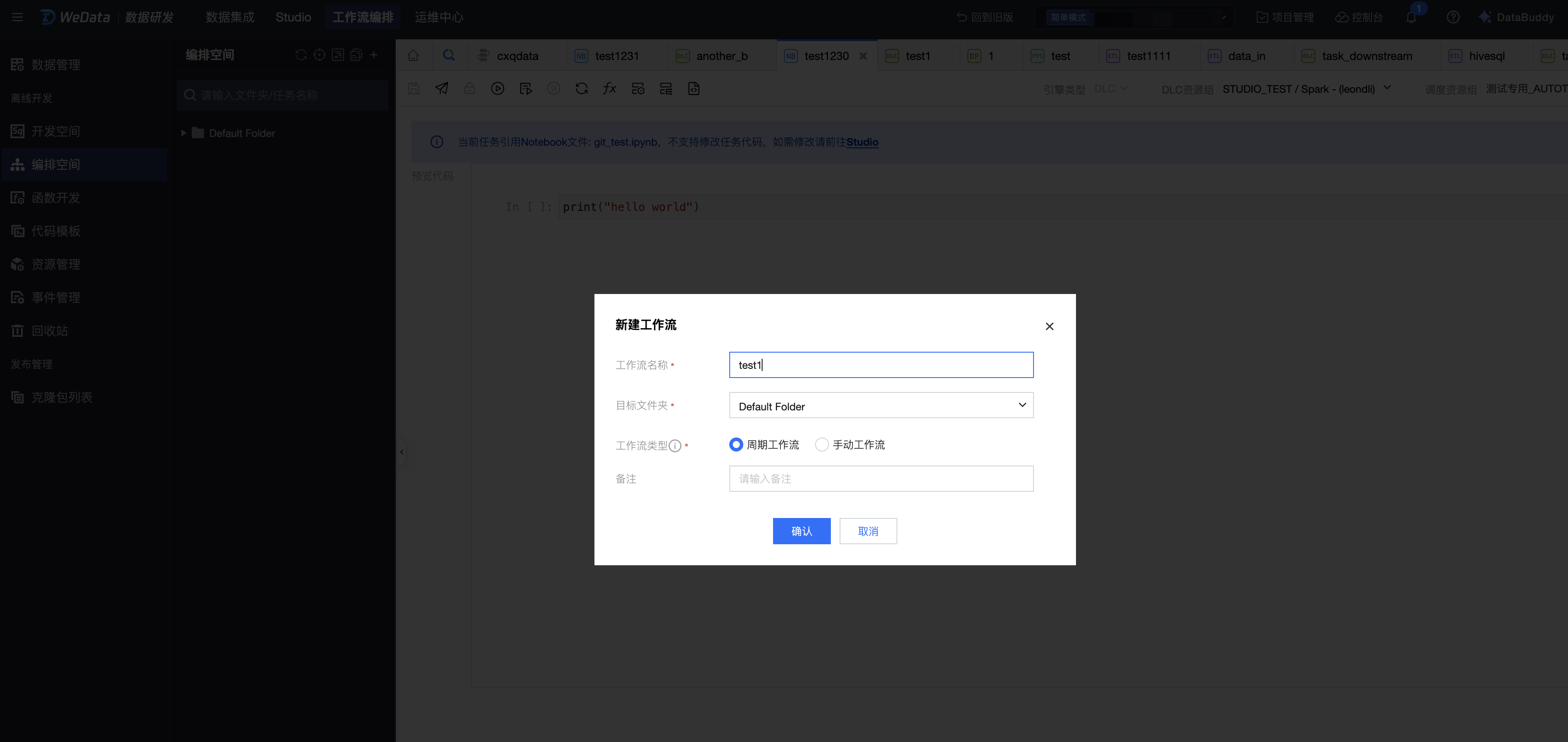
新建工作流
1. 进入数据研发 > 工作流编排。
2. 在编排空间目录中新建一个工作流。
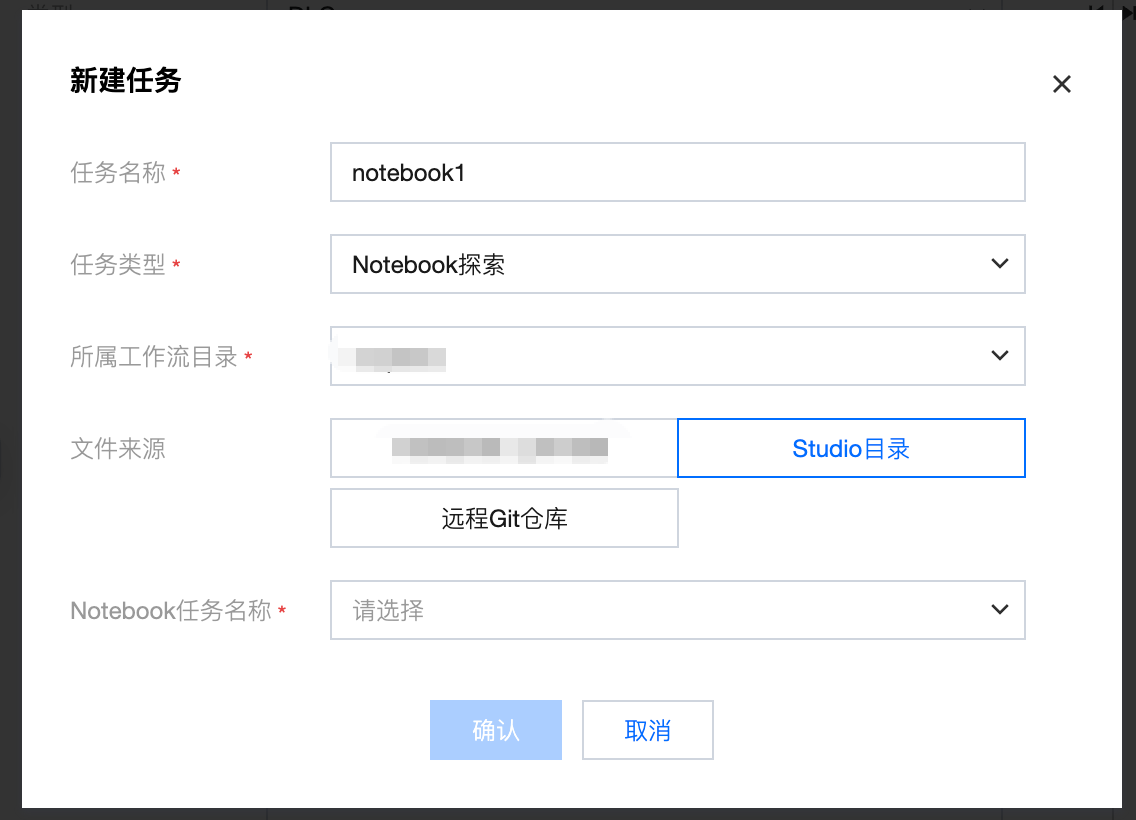
新建 Notebook 任务
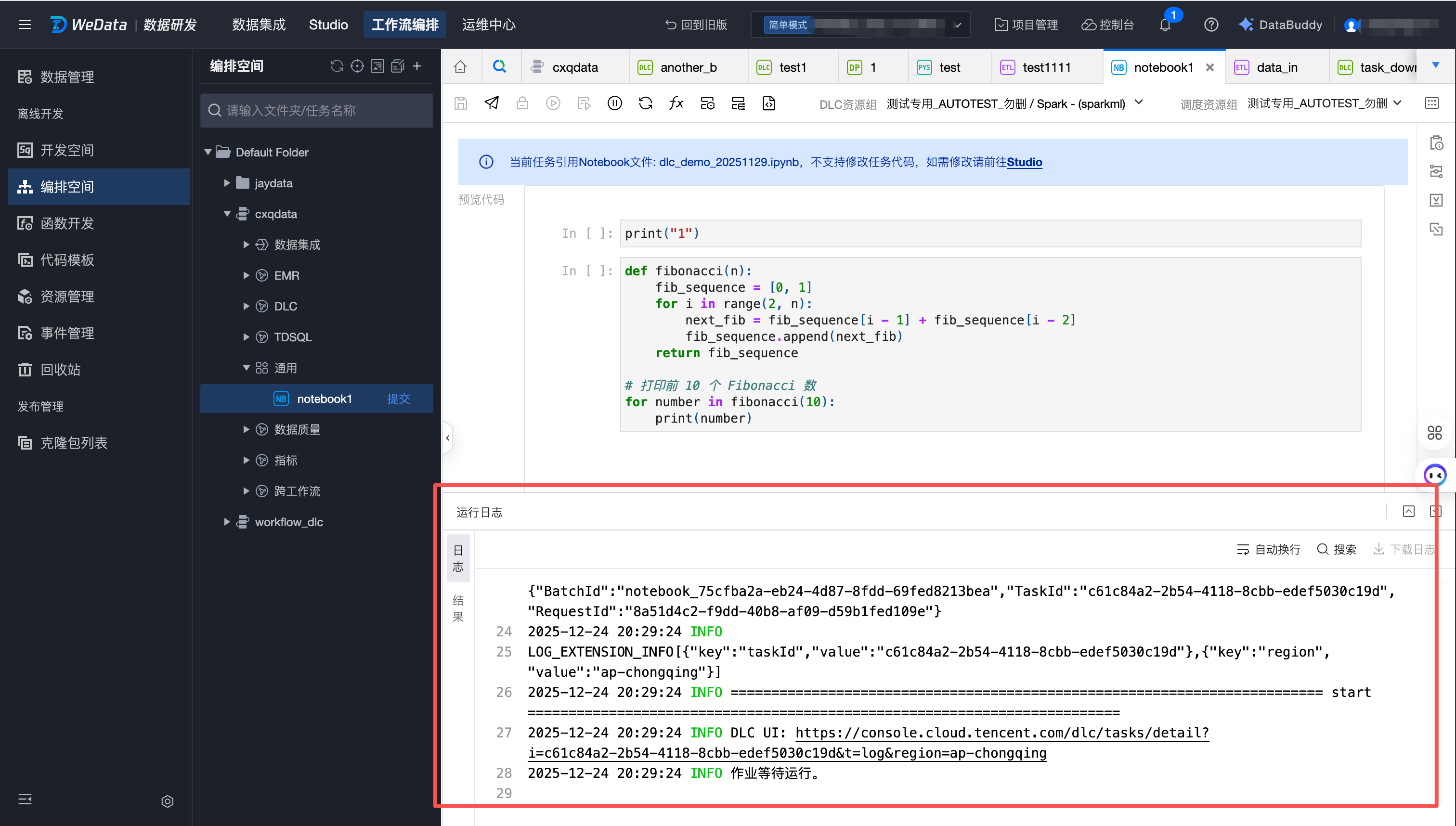
1. 进入离线开发 > 编排空间,新建 Notebook 任务,可以引用一个现有的 Notebook 文件,文件来源支持选择 Studio 目录、远程 Git 仓库。
如果是 Studio 目录,选择 Studio Workspace 或 GitFolder 中的一个 Notebook 文件。
如果是远程 Git 仓库,选择项目所绑定的远程 Git 仓库和分支中的一个 Notebook 文件。
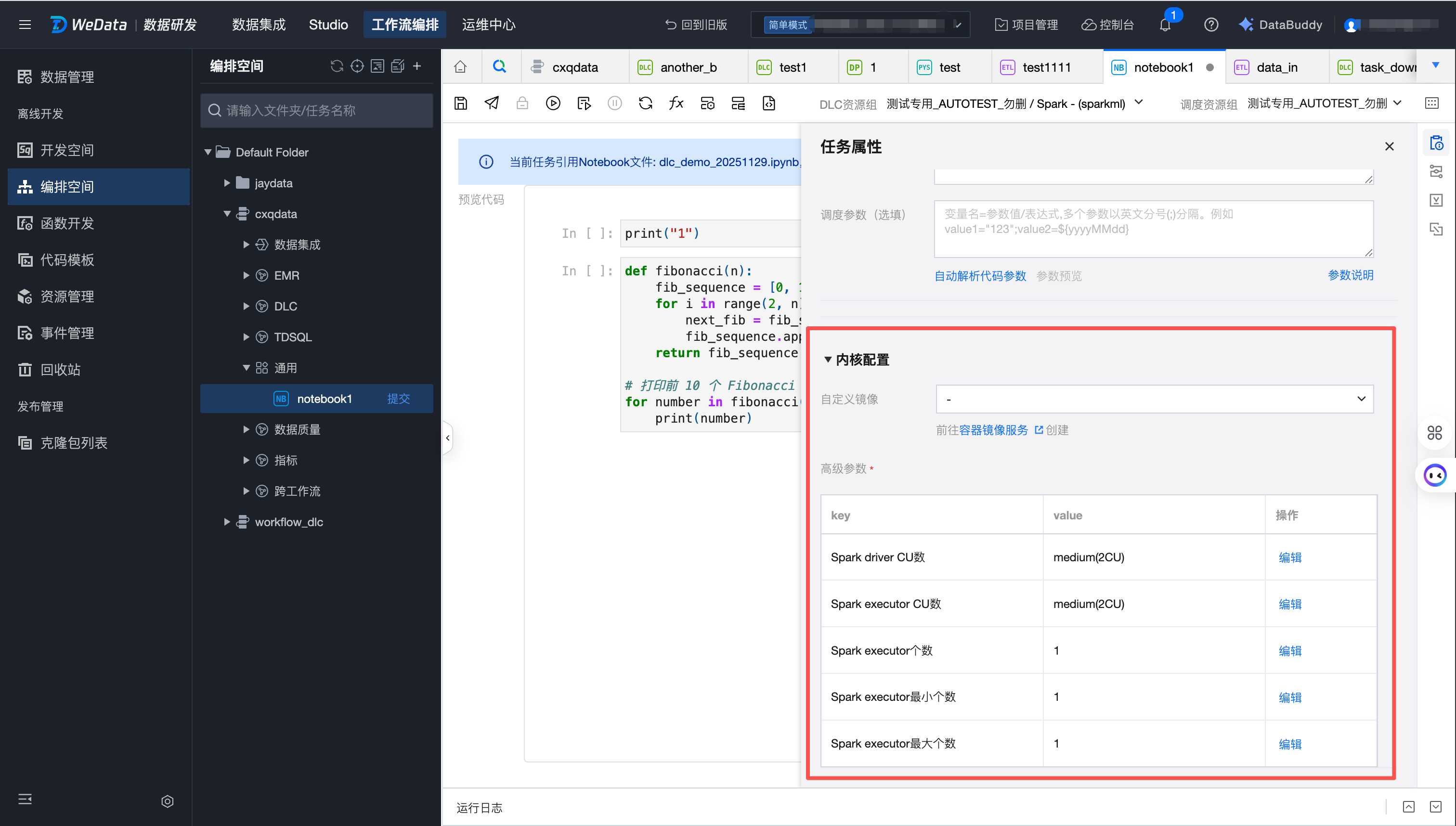
Notebook 任务配置
注意:
编排空间 Notebook 任务与 Studio 目录或者远程 Git 仓库中的 Notebook 文件之间为引用关系,不允许在编排空间修改文件内容,但可以修改运行 Notebook 文件的环境配置。
1. 在页面右上方选择所要连接的存算引擎和调度资源组信息。
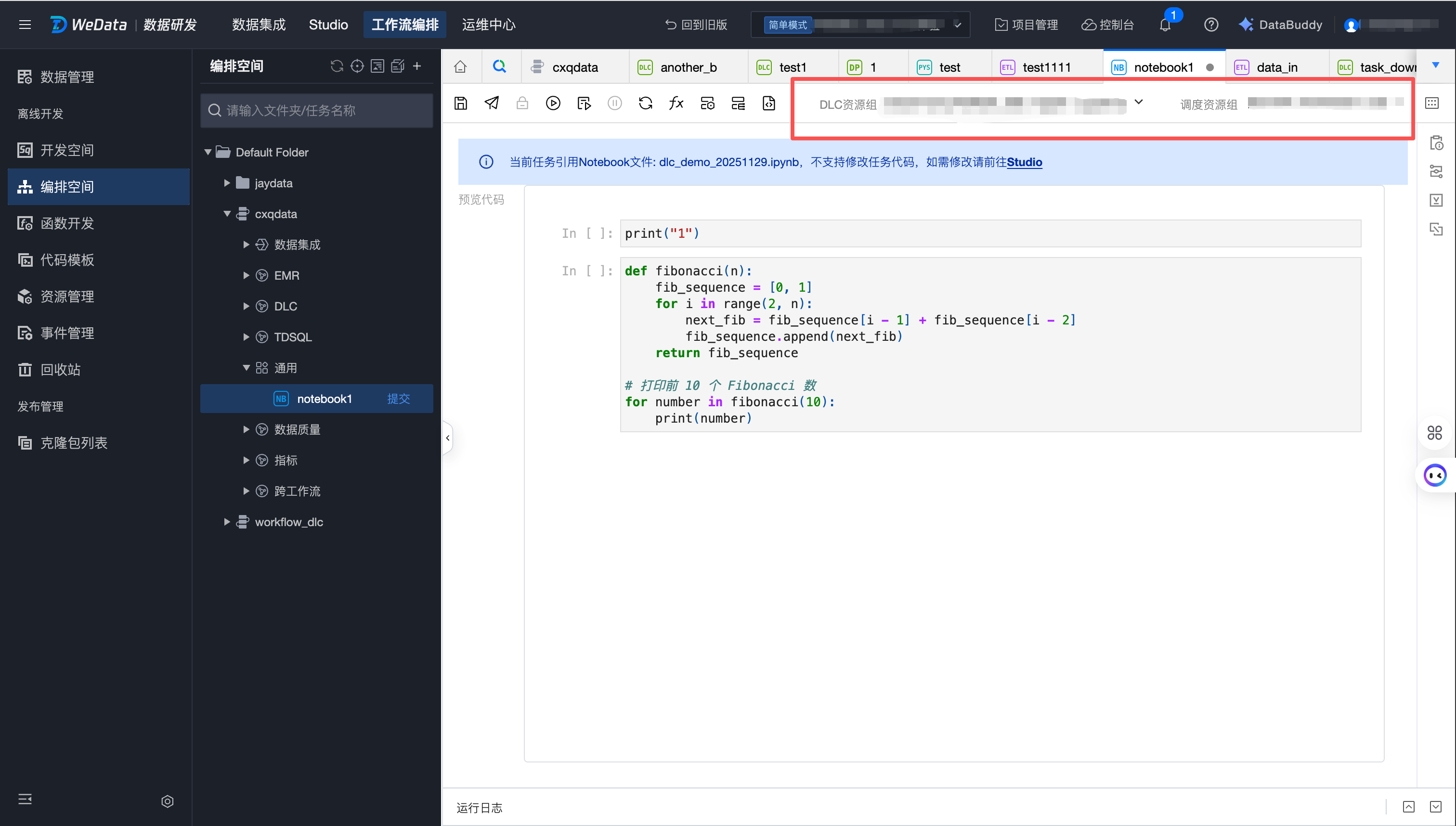
2. 在侧边栏的“任务配置”中,可以调整镜像和规格参数。
Notebook 任务运行
单击运行,对当前 Notebook 任务进行调试,调试运行成功后,可以进行任务提交。