脚本开发步骤
步骤一:新建文件夹
1. 进入开发空间,在开发空间目录树中单击
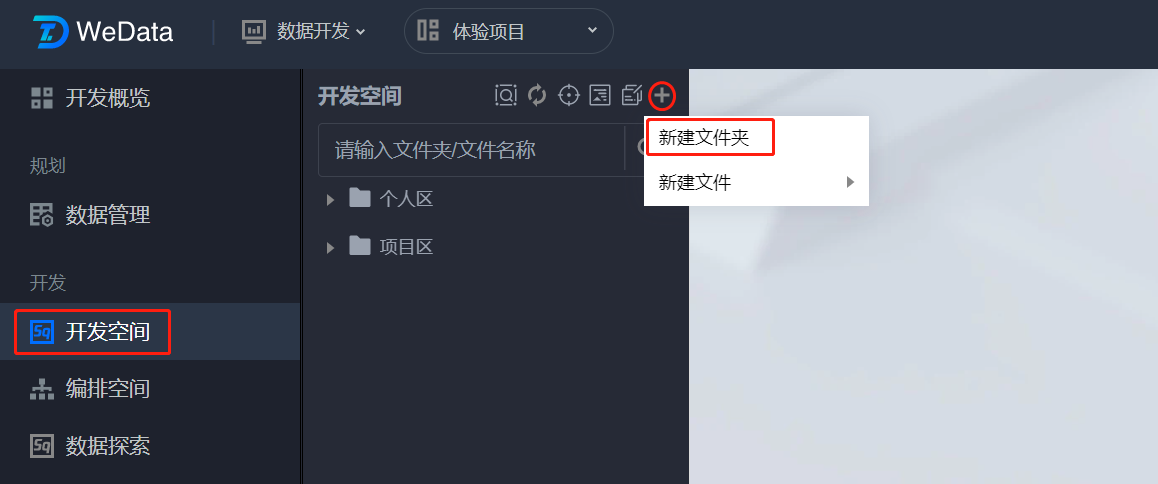
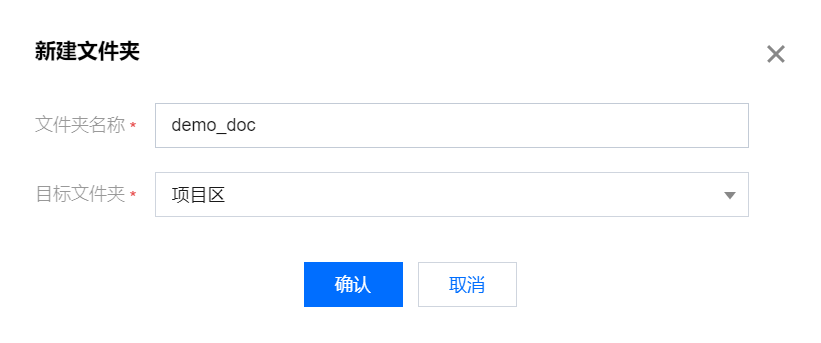
2. 输入文件夹名称并选择目标文件夹,并单击确认。
说明:
WeData 支持创建多级文件夹目录,可以保存新创建的文件夹至根目录,或其他已经创建好的文件夹中。
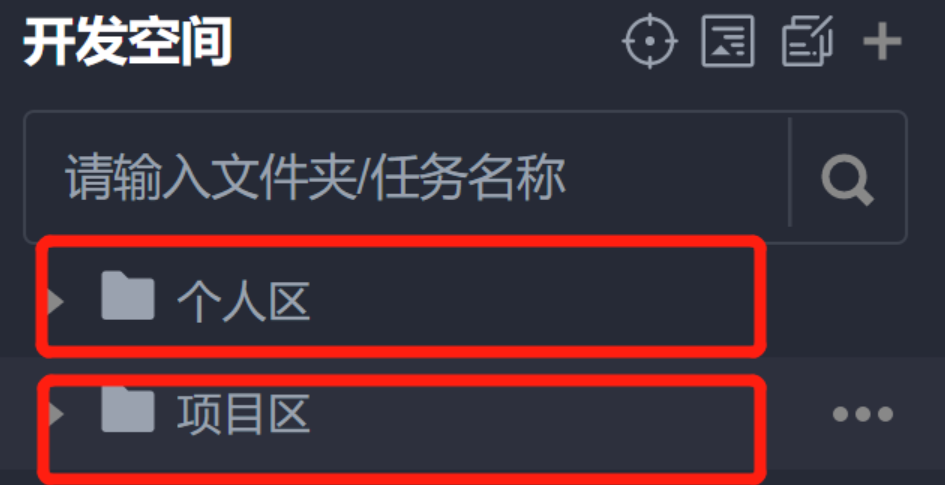
3. 用户可在开发空间下,自由选择将文件夹与文件创建并保存至个人区或项目区。
个人区:在个人区创建或存储的文件夹及文件只能由当前用户查看,其他用户无法查看或编辑管理。
项目区:在项目区创建或存储的文件夹及文件为项目共享文件,可由当前项目下全部用户查看,非项目成员无法查看。
步骤二:新建文件
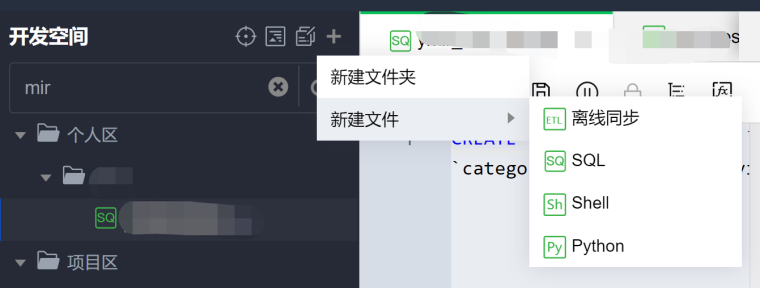
1. 在临时查询页面右键文件夹名称或者单击目录树上方的 ,并选择要创建的文件类型。
2. 在弹窗中填写脚本文件名称并选择目标文件夹,并单击确认。
说明:
文件命名仅支持大小写字母、数字和下划线,且最长可包括100个字符。
步骤三:编辑文件并运行
1. 在脚本的 Tab 页面中,输入相关的代码语句。如下图以 SQL 为例:
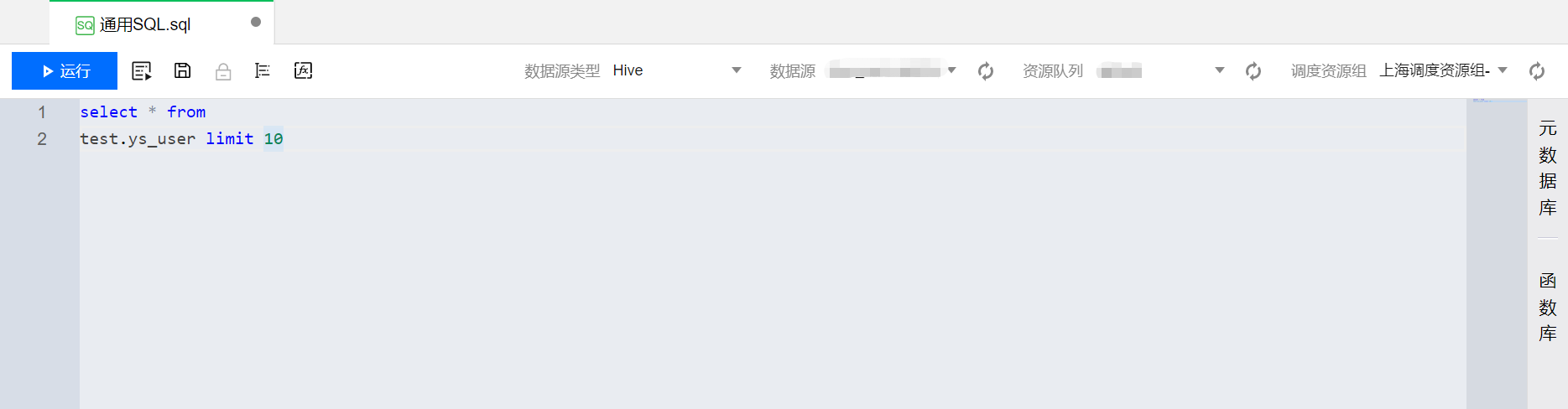
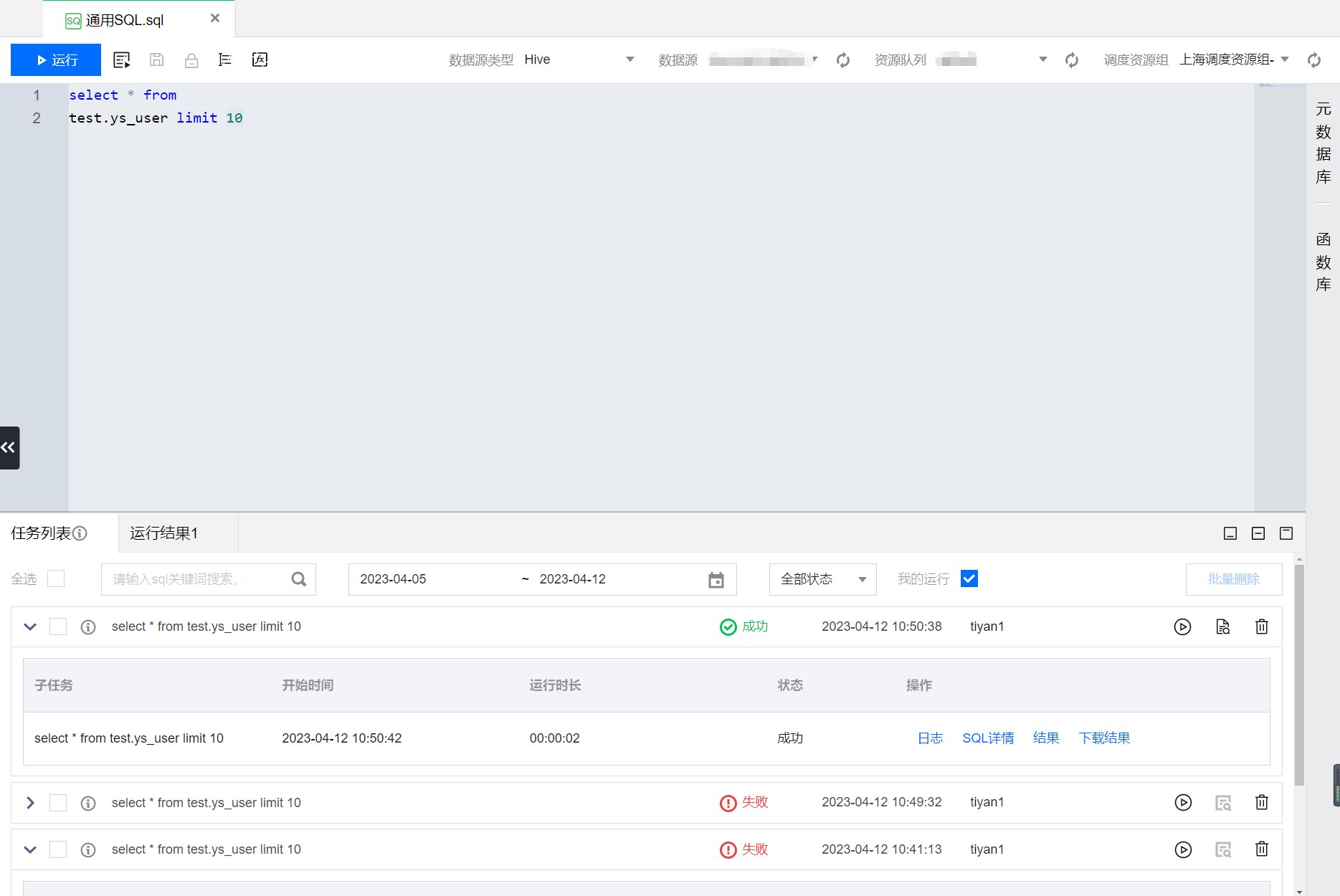
2. 单击运行按钮,运行代码并查看结果。
脚本文件类型
开发空间支持的文件类型为离线同步、SQL、Shell、Python、PySpark,支持新建、编辑、下载、删除等。
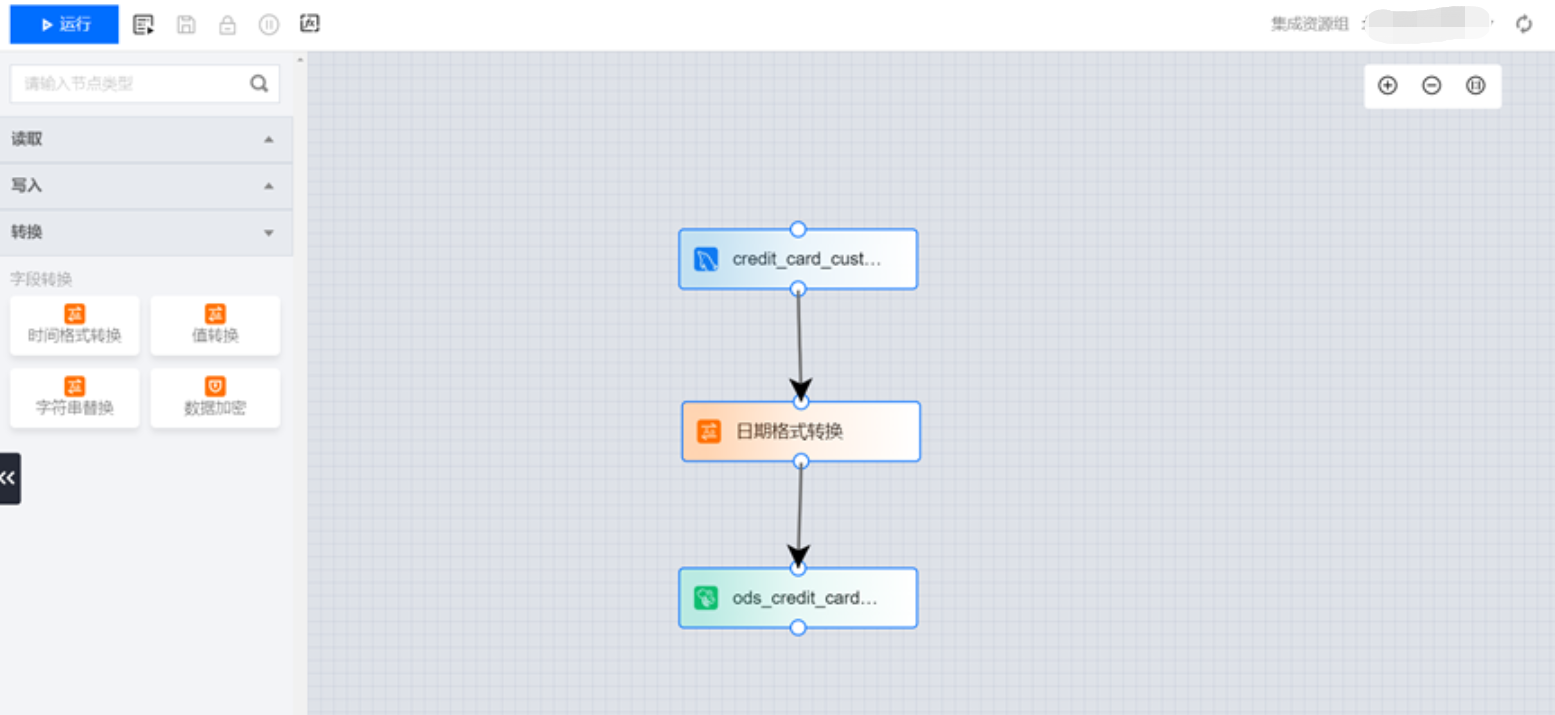
同步文件
说明:
离线同步文件的后缀为“.dg”,支持新建和导入。可支持离线同步流程的配置,包括读取数据源、字段转换、写入数据源配置以及运行、高级运行、保存、格式化和变量查看。
SQL 文件
SQL 文件的后缀为“.sql”,支持新建和导入。可支持多种 SQL 的编辑和调试,包括 Hive SQL,Spark SQL,JDBC SQL、DLC SQL 等,支持 Hive、Oracle 和 Mysql 等数十种数据源选择以及运行、高级运行、保存、格式化和项目变量查看。
例如:当数据源类型为 Spark 时,提供“高级设置”,支持 Spark SQL 参数配置。
目前支持 SQL 操作的数据源类型如下:
任务类型 | 支持的数据源类型 | 数据源来源 |
SQL 任务 | Hive | 系统源&自定义源 |
| SparkSQL | 系统源 |
| Impala | 系统源&自定义源 |
| TCHouse-P | 系统源 |
| Graph Database | 自定义源 |
| TCHouse-X | 自定义源 |
| DLC | 系统源&自定义源 |
| Mysql | 自定义源 |
| PostgreSQL | 自定义源 |
| Oracle | 自定义源 |
| SQL Server | 自定义源 |
| Tbase | 自定义源 |
| IBM Db2 | 自定义源 |
| 达梦数据库 DM | 自定义源 |
| Greenplum | 自定义源 |
| SAP HANA | 自定义源 |
| Clickhouse | 自定义源 |
| DorisDB | 自定义源 |
| TDSQL-C | 自定义源 |
| StarRocks | 自定义源 |
| Trino | 系统源&自定义源 |
| Kyuubi | 系统源&自定义源 |
Shell 文件
Shell 文件的后缀为“.sh”,支持新建和导入。用于 Linux Shell 文件的在线开发。支持 Shell 文件运行、高级运行、项目变量查看引用、编辑和保存。
支持界面 Shell 脚本直接执行 hdfs 相关命令。需要在 shell 脚本中手动添加下环境变量:
export HADOOP_CONF_DIR=/usr/local/cluster-shim/v3/conf/emr-xxx/hdfs
emr-xxx 需要替换为用户自己的 emr 引擎 id。
引用资源
Python 文件
Python 文件的后缀为“.py”,支持新建和导入。用于 Python 文件的在线开发。支持 Python 文件运行、高级运行、项目变量查看引用、编辑和保存,版本支持 Python2 和 Python3。

引用资源
PySpark 文件
PySpark 文件的后缀为“.py”,支持新建和导入。用于 Python 文件的在线开发。支持通过 Python 编写 Spark 应用程序。支持运行、高级运行、项目变量查看引用、编辑和保存,版本支持 Python2 和 Python3。
引用资源



