产品名 | 作为流数据源 | 作为批流数据源 | 作为维表 |
消息队列 Kafka | 支持 | - | - |
消息队列 CMQ | 支持 | - | - |
日志消费 CLS | 支持 | - | - |
数据库 Redis | - | - | 支持(Flink-1.11) |
数据库 PostgreSQL CDC | 支持 | 支持 | 支持 |
数据库 MySQL CDC | 支持 | 支持 | 支持 |
数据库 MongoDB CDC | 支持 | - | - |
数据仓库 Kudu | - | 支持 | - |
数据仓库 Hive | 支持 | - | 支持 |
数据仓库 Hbase | - | 支持 | 支持 |
数据仓库 ClickHouse | - | 支持 | 支持 |
数据仓库 PostgreSQL | - | 支持 | 支持 |
Oracle(JDBC) | - | 支持 | 支持 |
前提条件
1. 已开通 Oceanus 服务。
2. Oceanus 集群和云数据 TCHouse-C 集群须在同一个 VPC 下。
3. 流计算作业 SQL 作业需运行于流计算独享集群,若还没有集群,请参见 创建独享集群。
操作步骤
1. 登录云数据仓库 TCHouse-C ,创建目标表:
若您的任务有 update 和 delete 操作,可以通过 CollapsingMergeTree 来实现。
CREATE TABLE test.test ON CLUSTER default_cluster(`id` Int32,`Sign` Int8)ENGINE = CollapsingMergeTree(Sign)ORDER BY id
若您到任务中不需要 update,可以通过 MergeTree 来实现。
CREATE TABLE test.test ON CLUSTER default_cluster(`id` Int32)ENGINE = MergeTree()ORDER BY id
2. 在 Oceanus 控制台发布 SQL 作业,详细操作请参见 SQL作业开发。
2.1 登录 流计算 Oceanus 控制台,单击左侧导航工作空间,点击工作空间,进入作业管理页面。
2.2 单击新建作业,作业类型选中 SQL 作业,输入作业名称,并选择一个运行中的集群。
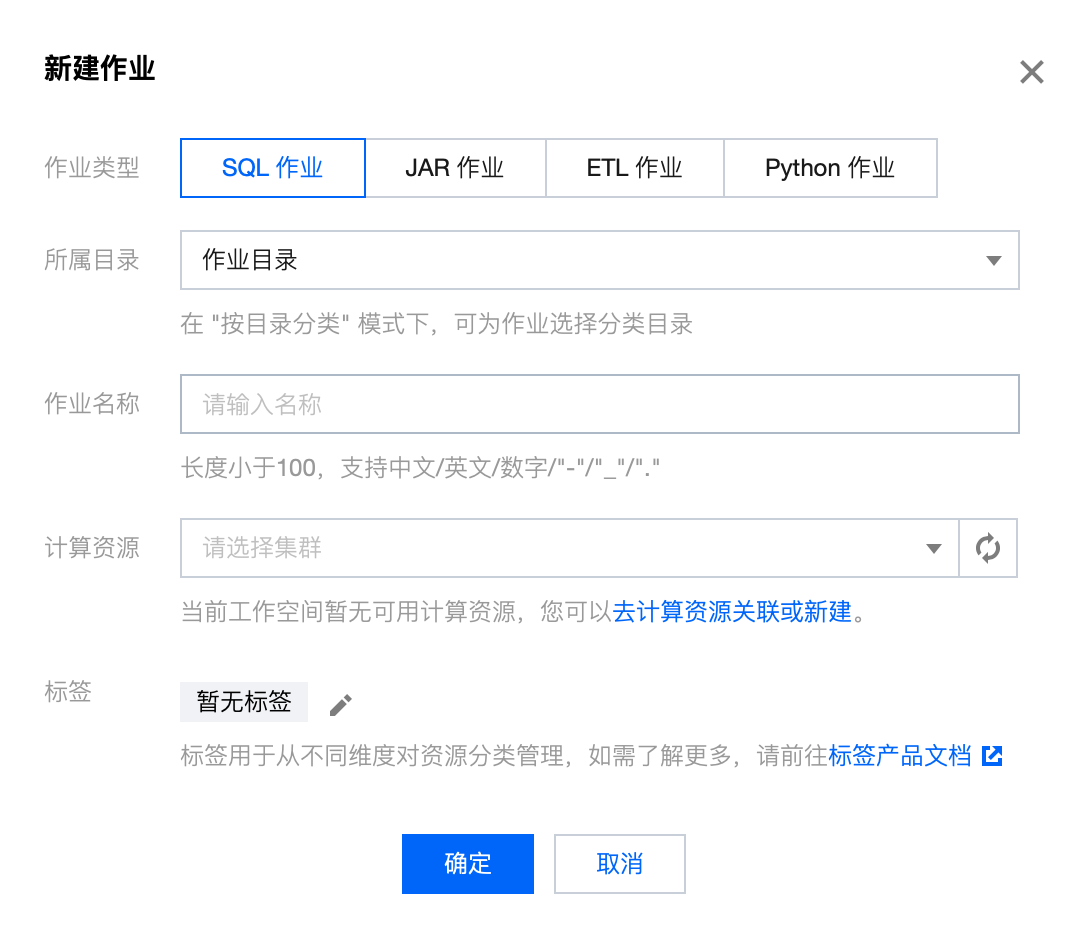
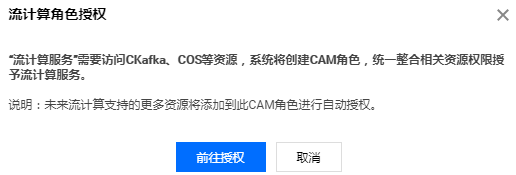
2.3 获取流计算服务委托授权。
2.4 编写 SQL 语句,并完成字段映射。
授权完成后,可在开发调试的代码编辑框中输入 SQL 语句,可无需另外准备数据快速创建作业。示例语句具体执行的内容如下:
MySQL-CDC Source(学生信息作为 cdc 源表):
CREATE TABLE `student` (`id` INT NOT NULL,PRIMARY KEY (`ID`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc',-- 必须为 'mysql-cdc''hostname' = 'YoursIp',-- 数据库的 IP'port' = '3306',-- 数据库的访问端口'username' = '用户名',-- 数据库访问的用户名(需要提供 SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, SELECT, RELOAD 权限)'password' = 'YoursPassword,-- 数据库访问的密码'database-name' = 'mysqltestdb',-- 需要同步的数据库'table-name' = 'student' -- 需要同步的数据表名);
当任务中无 update 时:
CREATE TABLE clickhouse_sink (`id` INT) WITH (-- 指定数据库连接参数'connector' = 'clickhouse', -- 指定使用clickhouse连接器'url' = 'clickhouse://xxx:8123', -- 指定集群地址,可以通过ClickHouse集群界面查看-- 如果ClickHouse集群未配置账号密码可以不指定--'username' = 'root', -- ClickHouse集群用户名--'password' = 'root', -- ClickHouse集群的密码'database-name' = 'test', -- 数据写入目的数据库'table-name' = 'test', -- 数据写入目的数据表'sink.batch-size' = '1000' -- 触发批量写的条数);
当任务中包含 update 和 delete 操作:
CREATE TABLE clickhouse_upsert_sink_table (`id` INTPRIMARY KEY (`id`) NOT ENFORCED -- 如果要同步的数据库表定义了主键, 则这里也需要定义) WITH (-- 指定数据库连接参数'connector' = 'clickhouse', -- 指定使用clickhouse连接器'url' = 'clickhouse://xxx:8123', -- 指定集群地址,可以通过ClickHouse集群界面查看-- 如果ClickHouse集群未配置账号密码可以不指定--'username' = 'root', -- ClickHouse集群用户名--'password' = 'root', -- ClickHouse集群的密码'database-name' = 'test', -- 数据写入目的数据库'table-name' = 'test', -- 数据写入目的数据表'table.collapsing.field' = 'Sign', -- CollapsingMergeTree 类型列字段的名称'sink.batch-size' = '1000' -- 触发批量写的条数);
OCeanus ClickHouse_Sink 参数:
参数值 | 必填 | 默认值 | 描述 |
connector | 是 | - | 当要使用 ClickHouse 作为数据目的(Sink)需要填写,取值 clickhouse |
url | 是 | - | ClickHouse 集群连接 url,可以通过集群界面查看,举例 'clickhouse://127.1.1.1:8123' |
username | 否 | - | ClickHouse 集群用户名 |
password | 否 | - | ClickHouse 集群密码 |
database-name | 是 | - | ClickHouse 集群数据库 |
table-name | 是 | - | ClickHouse 集群数据表 |
sink.batch-size | 否 | 1000 | connector batch 写入的条数 |
sink.flush-interval | 否 | 1000 (单位:ms) | connector 异步线程刷新写入 ClickHouse 间隔 |
table.collapsing.field | 否 | - | CollapsingMergeTree 类型列字段的名称 |
sink.max-retries | 否 | 3 | 写入失败时的重试次数 |
local.read-write | 否 | false | 是否写入本地表。默认 false 不开启写入本地表策略 |
table.local-nodes | 否 | - | local node 列表,举例 '127.1.1.10:8123,127.1.2.13:8123'(需要使用 http port) |
sink.partition-strategy | 否 | balanced | 数据分发策略,支持 balanced/shuffle/hash。当设置 sink.write-local 为 true 时启用。取值为 hash 时需要配合 sink.partition-key 使用。取值说明:balanced 轮询模式写入 shuffle 随机挑选节点写入 hash 根据 partition-key hash 值选择节点写入 |
sink.partition-key | 否 | - | 当设置 sink.write-loal 为 true 且 sink.partition-strategy 为 hash 时需要设置,值为所定义表中的字段 |
scan.fetch-size | 否 | 100 | 每次从数据库读取时,批量获取的行数 |
scan.by-part.enabled | 否 | false | 是否启用读ClickHouse 表 part。若启用,必须先在所有节点上使用命令'STOP MERGES'和'STOP TTL MERGES'停止表的后台merge和基于TTL的数据删除操作,否则读取的数据会不正确 |
scan.part.modification-time.lower-bound | 否 | - | 用于根据 modification_time 过滤 ClickHouse 表 part 的最小时间(包含),格式 yyyy-MM-dd HH:mm:ss |
scan.part.modification-time.upper-bound | 否 | - | 用于根据 modification_time 过滤 ClickHouse 表 part 的最大时间(不包含),格式 yyyy-MM-dd HH:mm:ss |
lookup.cache.max-rows | 否 | 无 | 查询缓存(Lookup Cache)中最多缓存的数据条数 |
lookup.cache.ttl | 否 | 无 | 查询缓存中每条记录最长的缓存时间 |
lookup.max-retries | 否 | 3 | 数据库查询失败时,最多重试的次数 |
注意
定义 WITH 参数时,通常只需要填写必填参数即可。当您启用非必填参数时,请您一定要明确参数含义以及可能对数据写入产生的影响。
2.5 进行逻辑运算。
此示例中,只进行了简单的 Join 没有进行复杂的运算。详细运算逻辑可参见 Oceanus 运算符和内置函数 或者 Flink 官网 Flink SQL 开发。
INSERT INTOclickhouse_sinkSELECTidFROMstudent
2.6 发布运行 SQL 作业。
3. 登录 云数据仓库 TCHouse-C ,并查看数据。
select * from test.test ;



