功能介绍
本文为您介绍通过控制台进行 TCHouse-C 集群数据重分布的能力。目前云数据仓库 TCHouse-C 已经支持通过水平扩容增加集群节点,提高集群的计算和存储能力,但是 ClickHouse 集群上的数据集无法自动均衡分布,需要人工干预才能确保数据均衡,这一直是 ClickHouse 使用和运维上的一大痛点。云数据仓库 TCHouse-C 的数据重分布功能提供了白屏化的方式,支持 Part 或 Resharding 的模式对数据进行集群均衡,该功能当前为白名单功能,如需要使用可 提交工单 申请。
注意事项
1. Resharding 模式会将数据重新插入,过程中的临时数据需要使用额外存储空间,用户在使用 Resharding 模式时需要当前剩余容量超过当前任务的表的存储大小。
2. 一个数据表只能与一个任务绑定,一个集群最多同时只支持一个任务执行中。
3. 本地表数据库必须为 atomic(默认)或 ordinary,且表类型为 Mergetree 家族系列引擎的表(包括非复制表和复制表,不支持物化视图表)。
4. 本地表副本关系必须和 cluster 一致,必须有分布式表作为分片之间的关系。
5. Resharding 数据分布按照分布式表的哈希规则进行重分布;Part 重分布不管分布式表的哈希规则,按照 part 粒度进行均衡。
6. 重分布过程会生成临时表,临时表命名规则为:原表名_ resharding_temp_任务 id_随机数字。等到“待切换”状态时,请先验证临时表数据正确无误,再进行切换。切换完成后,原表数据保存在 “原表名 resharding 任务 id 随机数字” 的表中,验证无误后可进行老数据的删除操作。
7. 重分布过程中原表默认置为只读状态;表级别可以选择 Partition 粒度部分数据重分布,如果重分布的 Partition 没有数据写入,可选择关闭表只读;如果重分布的 Partition 有数据写入,关闭表只读会导致数据不一致。目前不支持选择全部 Partition 下支持可写。
8. 重分布的数据会先保存到临时表中,执行切换的时候会用重分布的数据文件替换原表,该过程中可能读到错误数据,切换时间正常为秒级。
9. 任务进行过程中有可能由于集群问题导致任务暂停,任务暂停后可根据报错进行集群修复或配置,集群修复成功可以继续任务执行。
10. 重分布本地表和分布式表的建表语句字符串必须完全一致。
11. 重分布使用 ReSharding 模式的时候依赖所选 cluster 的所有 shard 有统一的 internal_replication 配置项,都是 true 或 false。
12. 使用云盘做冷热分层的集群,需要在使用重分布功能之前执行一次集群重启。
13. 为了保证数据重分布任务尽快完成,数据迁移任务过程中,需要暂停数据写入,直到数据重分布任务结束。
警告:
1. 数据量大或者表数量较多的情况下,不建议使用该功能。
2. 为了保证数据重分布任务尽快完成,数据迁移任务过程中,需要暂停数据写入,直到数据重分布任务结束。
操作步骤
1. 登录 云数据仓库 TCHouse-C 控制台,在集群列表中选择对应的集群,单击数据管理 > 数据迁移 > 数据重分布。
2. 可在当前页面查看已有的数据重分布任务列表。
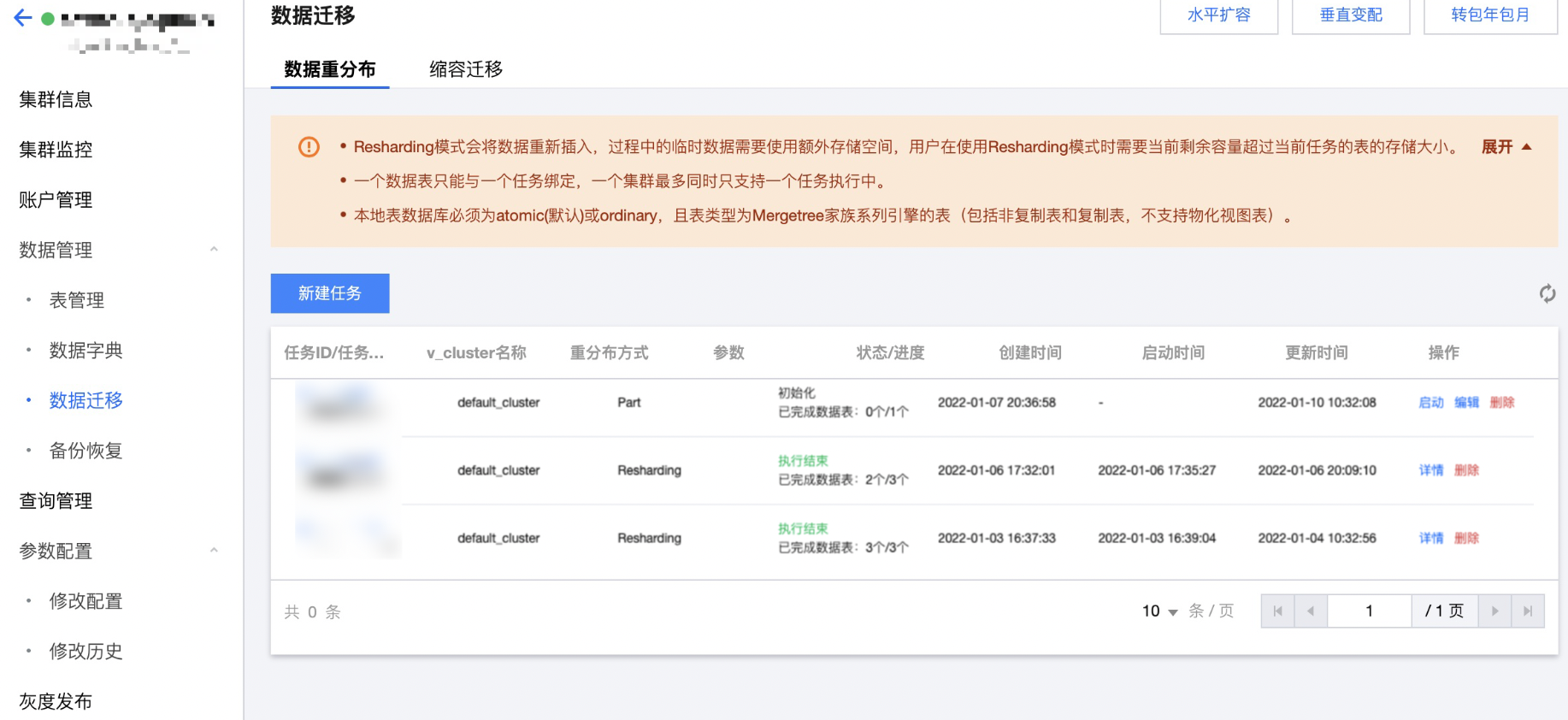
3. 单击新建任务创建新的数据重分布任务,需填写任务名称、选择表所在的 v_cluster,选择迁移模式(Part、Resharding)、选择迁移的分布式表,单击确定提交。
Part 模式 :通过在集群 shard 间迁移 part,来实现 shard 间的数据均衡。这种方式不遵循分布式表的分片规格,更适合 rand()方式的分布式表。Resharding 模式 :通过将原表数据重新按照分布式表的规格写入整个集群,来实现数据的重新写入,达到 shard 间数据均衡,若数据需要基于主键分配到一个分片,则优先使用此种模式。
表级别支持按 Partition 粒度选择对部分数据进行重分布。另外在 Partition 粒度下,可以选择是否打开表可写:如果重分布的 Partition 没有数据写入,可选择关闭表只读;如果重分布的 Partition 有数据写入,关闭表只读会导致数据不一致。
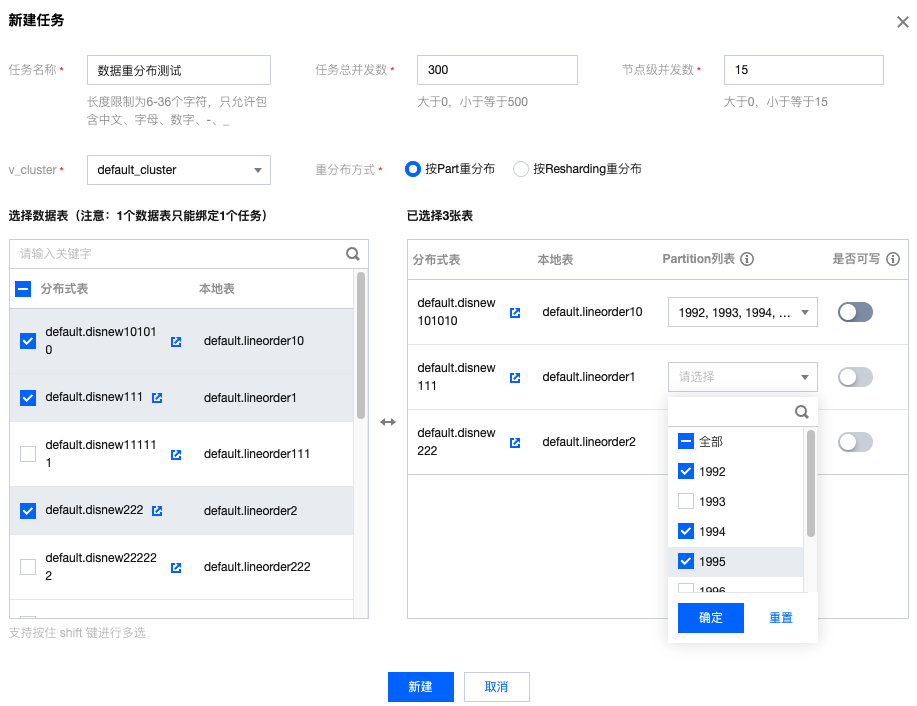
数据重分布功能使用的组件是采用多种并发机制来提升任务的高性能,为了让用户平衡业务负载和重分布对集群的影响,用户可以通过
任务总并发 和 节点级并发数 来调整重分布任务的性能和速度。说明
节点级并发数 表示当 ReSharding 模式时,单台计算节点同时处理的 Partition 粒度的并发度;当 Part 模式时,单台计算节点同时处理的 Part 粒度的并发度。任务总并发 表示整个任务在运行过程中,所有参与任务的节点的总并发数。任意一个参数设置为0,都会导致整个任务进入暂停状态;而且在不同规格集群、不同任务时,具体的参数值可能会有不同的效果,用户可以根据具体情况调整数值大小来调整任务速度和性能以及对集群的负载。
4. 创建完数据重分布任务后,可以对任务进行启动、编辑、删除。编辑与新建窗口类似,可以重新对任务相关信息进行调整。

5. 单击启动,可以开始数据重分布任务,同时云数据仓库 TCHouse-C 实例状态会变为 
状态变更中 (在集群基础页面也会进入 状态变更中 ,但是没有进度条)。
6. 单击详情查看该数据重分布任务包含的表级别的执行信息详情。
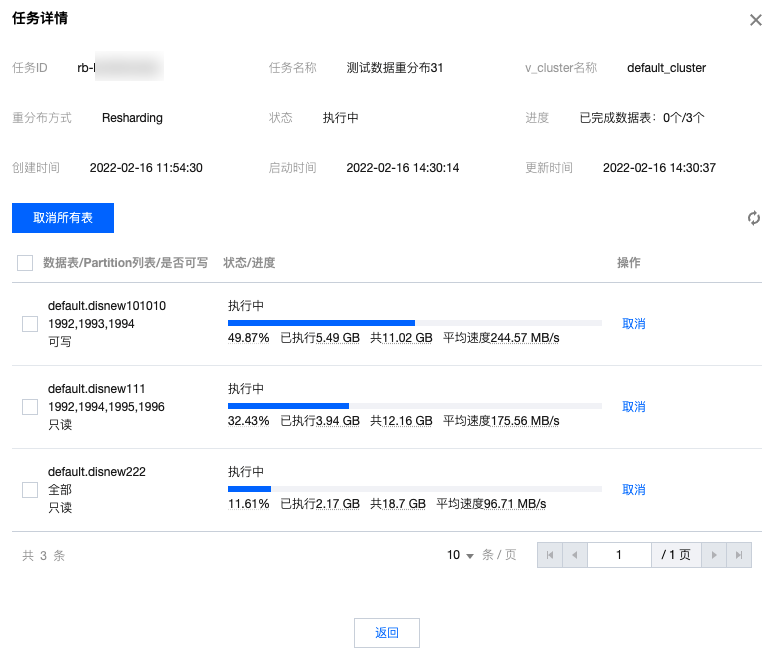
7. 表的数据重分布执行过程会分为3个阶段:
执行中 :表示对表正在进行数据重分布操作,根据模式,可能会涉及一些临时表的创建与删除、part 的移动与删除、数据的读取与写入,此时对集群有一定的读写性能压力等。待切换 :表示分布式表对应的数据完成了重分布,但是还未替代原表,用户需要对表重分布后对应的临时表的数据进行验证,确保重分布的正确性和数据一致性后,执行切换,让业务访问重分布后的表。注意
此时需要用户在切换到重分布后数据源之前,请确保已经完成重分布操作前后数据一致性和准确性校验。切换后的数据表将作为系统读写的唯一数据源。
如果是Partition粒度的重分布,则需要校验Partition维度的数据的重分布操作前后一致性和准确性。
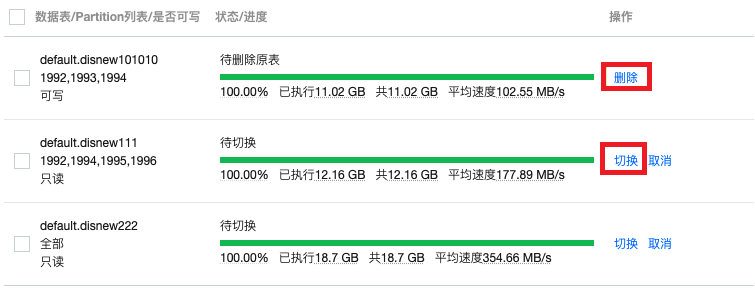
待删除原表 :完成切换操作之后,原来表的数据文件并不会直接删除,用户可以对均衡后的数据进行进一步的验证,确保重分布的正确性后,再执行删除,将重分布前的数据文件彻底删除。执行删除后,表的状态会变为 执行成功 。注意
此操作会永久删除数据重分布前的数据表物理文件,请确保已经完成重分布前后数据一致性和准确性校验,且已完成数据源的切换。
如果是Partition粒度的重分布,则只会删除原表相应Partition包含的数据文件。
8. 此外,在对重分布的表执行切换操作之前,可以选择对表或者整个任务执行取消,会将数据重分布操作进行停止并回滚已有的动作。已执行切换或删除操作的表,不支持取消回滚。
9. 在任务执行过程中,如果集群发生了类似网络抖动、重启或其他意外,有可能或出现暂停状态,并会有暂停原因,用户可以根据具体情况对集群进行调整,或者 提交工单 由腾讯云技术人员来协助处理。
10. 当所有的重分布的表到达最终态(包括已取消、执行成功等状态),该重分布任务也会变为 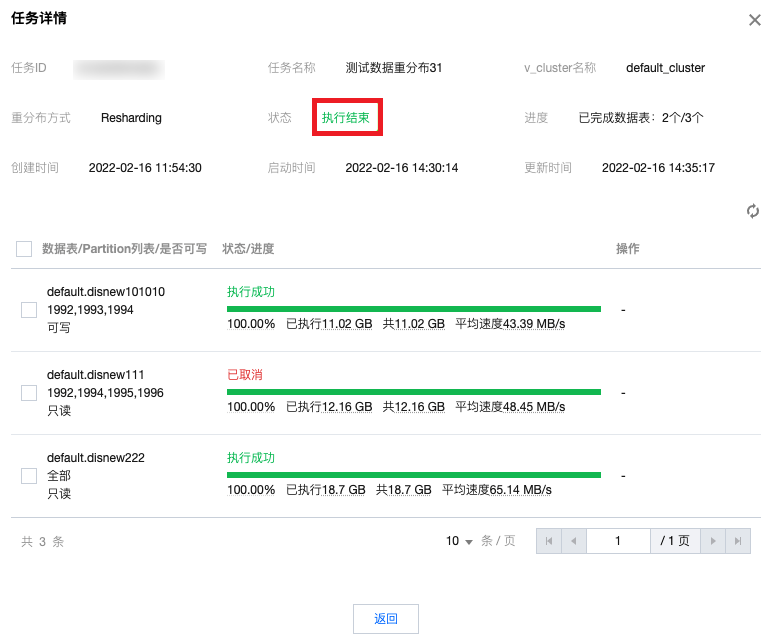
执行结束 ,实例的状态也变为运行中 。
实践教程
重分布场景
1. 扩容后数据不均衡,分布式表 hash 分布不正确。
2. 由于业务插入导致的不均衡问题。
3. 调整表的数据分布策略。
重分布前的参数调整
重分布前建议添加以下参数,在重分布过程中,会有临时表的删除操作,如果没有以下权限,可能导致任务暂停。
<max_table_size_to_drop>0</max_table_size_to_drop><max_partition_size_to_drop>0</max_partition_size_to_drop>
32核以上高配机器进行 resharding 模式重分布时建议适当提高以下参数,原因是在数据重新导入的过程中有大量写入,需要进行提高后台 merge 能力防止出现大量 part,出现 Too Many Part 的错误。
<background_pool_size>64</background_pool_size><background_schedule_pool_size>64</background_schedule_pool_size>
重分布使用建议
1. Resharding 模式时会将数据重新写入,过程中对集群负载压力较大,建议用户在业务压力小的时候使用。
2. 为了提高重分布性能,建议在使用 Part 模式前可以适当手动使用 optimize 语句触发 Merge,提高 Part 大小,可以减小传输数据量。
性能数据
测试环境1
内核版本:21.8.12.29。
高可用:高可用。
计算节点类型:高 IO 型。
计算节点规格:64核256G。
计算节点数量:4(2shard)、8(4shard)、16(8shard)。
计算节点存储:本地盘14280GB。
ZK 节点规格:16核64G。
ZK 节点数量:3。
ZK 节点存储:增强型 SSD 云硬盘100GB。
数据生成工具:
ssb-dbgen 。测试场景1
场景:2shard 扩容到4shard。
Resharding 模式
序号 | 表个数 | 数据总量 | 总耗时 | 平均速度 |
1 | 1 | 335GB | 2分58秒 | 1.878GB/s |
2 | 1 | 898GB | 9分18秒 | 1.609GB/s |
3 | 2 | 670GB | 5分23秒 | 2.074GB/s |
4 | 2 | 1796GB | 13分25秒 | 2.23GB/s |
5 | 4 | 1340GB | 11分17秒 | 1.979GB/s |
6 | 4 | 3592GB | 24分33秒 | 2.439GB/s |
Part 模式
序号 | 表个数 | 数据总量(迁移part量) | 总耗时 | 平均速度 |
1 | 1 | 335GB(180GB) | 1分44秒 | 1.737GB/s |
2 | 1 | 898GB(476GB) | 6分27秒 | 1.229GB/s |
3 | 2 | 792GB(397GB) | 4分50秒 | 1.370GB/s |
4 | 2 | 1796GB(952GB) | 11分38秒 | 1.364GB/s |
5 | 4 | 1675GB(903GB) | 10分28秒 | 1.438GB/s |
6 | 4 | 3592GB(2379GB) | 28分6秒 | 1.411GB/s |
测试场景2
场景:4shard 扩容到8shard。
Resharding 模式
序号 | 表个数 | 数据总量 | 总耗时 | 平均速度 |
1 | 1 | 1034GB | 3分39秒 | 4.715GB/s |
2 | 2 | 2068GB | 6分58秒 | 4.95GB/s |
3 | 4 | 4136GB | 13分1秒 | 5.301GB/s |
Part 模式
序号 | 表个数 | 数据总量(迁移part量) | 总耗时 | 平均速度 |
1 | 1 | 1034GB(524GB) | 3分19秒 | 2.633GB/s |
2 | 2 | 2068GB(1049GB) | 6分35秒 | 2.656GB/s |
3 | 4 | 4136GB(2097GB) | 12分3秒 | 2.900GB/s |
测试场景3
场景:4shard 扩容到4shard。
Resharding 模式
序号 | 表个数 | 数据总量 | 总耗时 | 平均速度 |
1 | 1 | 1034GB | 10分16秒 | 1.679GB/s |
2 | 2 | 2068GB | 20分34秒 | 1.676GB/s |
3 | 4 | 4136GB | 37分12秒 | 1.853GB/s |
测试环境2
内核版本:21.8.12.29。
高可用:高可用。
计算节点类型:大数据型。
计算节点规格:64核256G。
计算节点数量:16。
计算节点存储:本地盘2142720GB。
ZK 节点规格:16核64G。
ZK 节点数量:3。
ZK 节点存储:增强型 SSD 云硬盘500GB。
测试场景1
场景:2shard 扩容到4shard。
Resharding 模式
序号 | 表个数 | 数据总量 | 总耗时 | 平均速度 |
1 | 1 | 773GB | 7分21秒 | 1.752GB/s |
2 | 2 | 1585GB | 15分43秒 | 1.681GB/s |
3 | 4 | 3209GB | 32分9秒 | 1.664GB/s |
Part 模式
序号 | 表个数 | 数据总量(迁移part量) | 总耗时 | 平均速度 |
1 | 1 | 774GB(393GB) | 4分47秒 | 1.371GB/s |
2 | 2 | 1548GB(786GB) | 9分53秒 | 1.563GB/s |
3 | 4 | 3096GB(1572GB) | 19分18秒 | 1.358GB/s |
测试场景2
场景:4shard 扩容到8shard。
Resharding 模式
序号 | 表个数 | 数据总量 | 总耗时 | 平均速度 |
1 | 1 | 855GB | 4分37秒 | 3.087GB/s |
2 | 2 | 1667GB | 9分6秒 | 3.053GB/s |
3 | 4 | 3292GB | 18分49秒 | 2.916GB/s |
Part 模式
序号 | 表个数 | 数据总量(迁移part量) | 总耗时 | 平均速度 |
1 | 1 | 1072GB(542GB) | 3分21秒 | 2.697GB/s |
2 | 2 | 2144GB(1084GB) | 6分24秒 | 2.823GB/s |
3 | 4 | 4288GB(2167GB) | 12分34秒 | 2.874GB/s |






