任务洞察是基于任务视角,帮助用户可以快速定位已完成的任务的优化分析与优化建议。
前提条件
1. SuperSQL SparkSQL、Spark 作业引擎:
1.1 2024年7月18日后新购引擎默认开启任务洞察
1.2 2024年7月18日前的 Spark 内核版本,需升级引擎内核后即可开启任务洞察,升级方式请参见下文 如何开启洞察功能。
2. 标准 Spark 引擎:
2.1 2024年12月20日后购买引擎,默认支持任务洞察。
2.2 2024年12月20日前购买引擎,暂不支持用户手动开启任务洞察,请 提交工单 联系售后开启。
其余类型引擎暂不支持任务洞察。
操作步骤
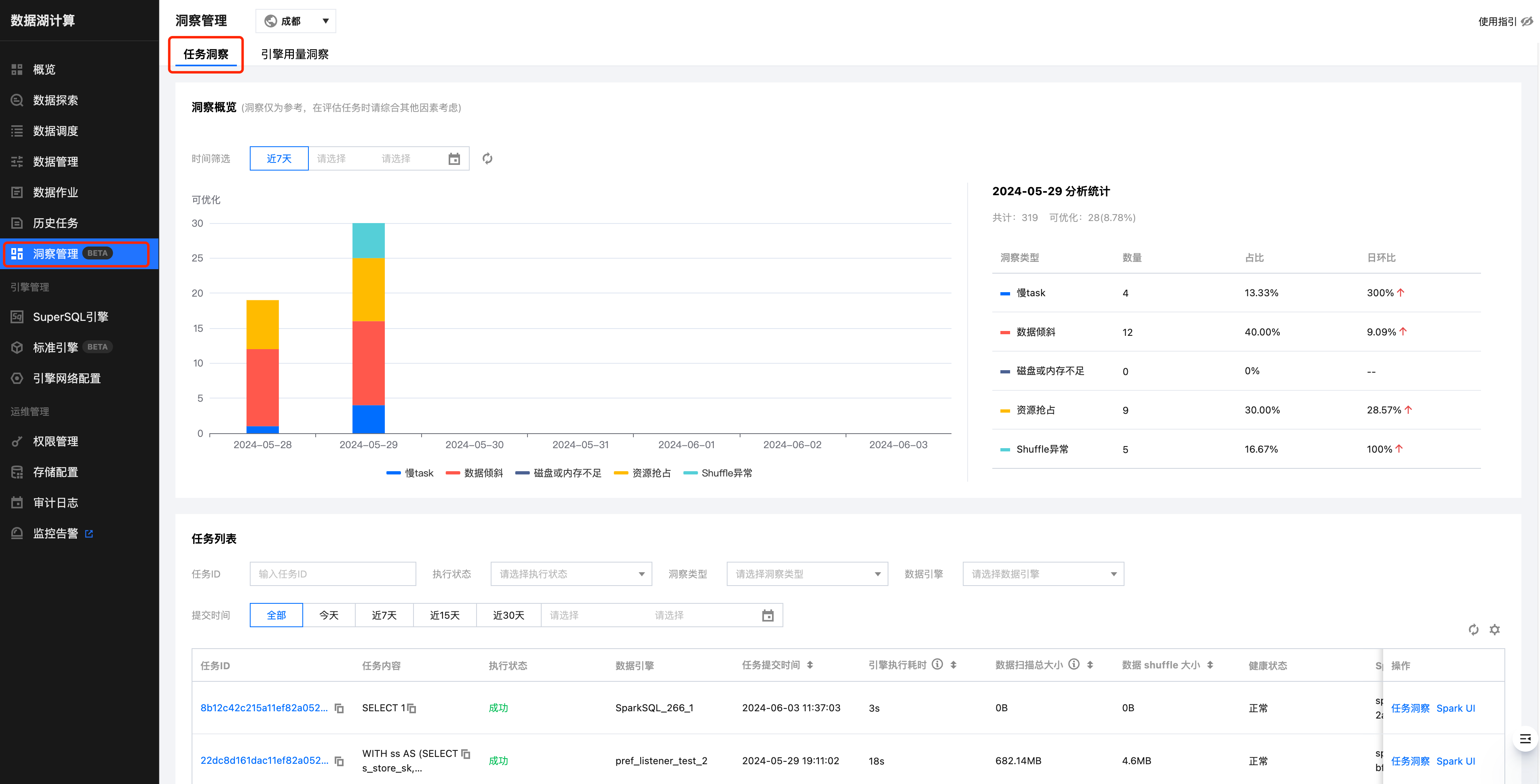
洞察概览
日级别统计洞察出来的待优化的任务分布情况和走势分布,可以对每日的任务有一个更直观的了解。
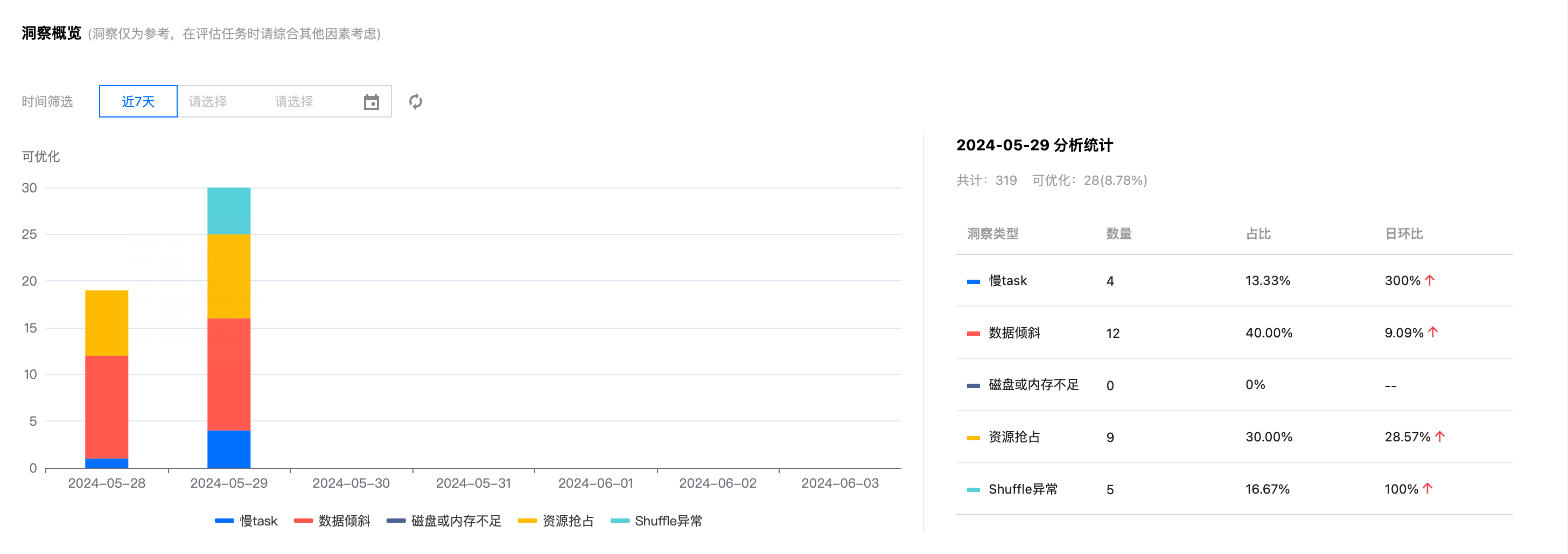
任务洞察
任务洞察功能支持分析每个任务执行过的汇总 metrics 以及洞察可优化的问题。
当任务执行完成后,用户只需要确认需要洞察的任务,在操作栏单击任务洞察即可查看。

根据当前任务的实际执行情况,DLC 任务洞察将结合数据分析及算法规则,给出相应的调优建议。
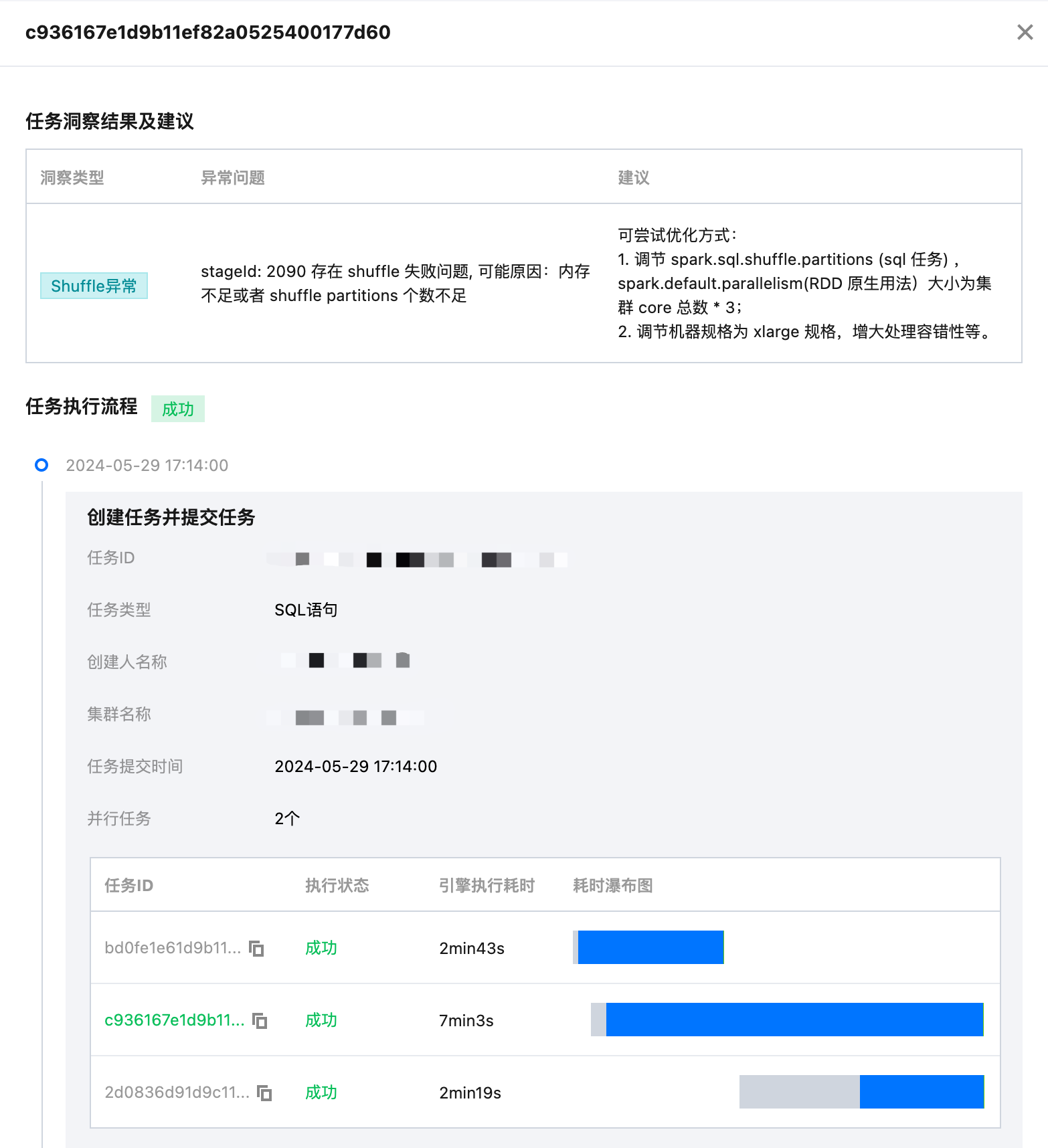
如何开启洞察功能
存量 SuperSQL 引擎需升级内核镜像
注意:
2024年7月18日后新购引擎或者存量引擎已经升级至2024年7月18日后的内核版本,已经自动开启洞察,可跳过本步骤。
操作步骤
1. 进入 SuperSQL 引擎列表页 ,选择需要洞察的引擎。

2. 在引擎详情页,单击内核管理 > 版本升级(默认升级至最新内核)。
洞察重点指标概览
列表的指标名称 | 指标含义 |
引擎执行时间 | Spark 引擎执行的第一个 Task 时间(即任务第一次抢占 CPU 开始执行的时间) |
引擎执行耗时 | 反映真正用于计算耗时,即从 Spark 任务第一个 Task 开始执行到任务结束之间的耗时。 具体的:会统计任务的每个 Spark Stage 第一个 Task 到最后一个 Task 完成时长之和,不包含任务开始的排队耗时(即剔除从任务提交到 Spark Task 开始执行之间的调度等其他耗时),也不包含任务执行过程中多个 Spark Stage 之间因 executor 资源不足而等待执行 Task 所消耗的时间。 |
等待执行耗时(排队耗时) | 从任务提交到开始执行第一个 Spark Task 之间的耗时,其中耗时可能有:引擎第一次执行的冷启动耗时、配置任务并发上限导致的排队时间 、引擎内因资源打满导致的等待 executor 资源的耗时、生成和优化 Spark 执行计划耗时等。 |
累计 CPU * 时(消耗 CU * 时) | 统计参与计算所用 Spark Executor 每个 core 的 CPU 执行时长总和,单位小时(不等价集群拉起机器的时长,因机器拉起后不一定会参与到任务计算,最终集群消耗 CU 计费以账单为准)。 在 Spark 场景下约等于 Spark Task 执行时长串行加和 (秒) /3600 (单位小时) |
数据扫描大小 | 该任务从存储读取的物理数据量,在 Spark 场景下约等于 Spark UI 中 Stage Input Size 之和 |
输出总大小 | 该任务处理完数据后输出的记录大小,在 Spark 场景下约等于 Spark UI 中 Stage Output Size 之和。 |
数据 shuffle 大小 | 在 Spark 场景下约等于 Spark UI 中 Stage Shuffle Read Records 之和。 |
输出文件个数 | (该指标的收集需要 Spark 引擎内核升级至 2024.11.16 之后的版本) 任务通过 insert 等语句写出的文件个数总和 |
输出小文件个数 | (该指标的收集需要 Spark 引擎内核升级至 2024.11.16 之后的版本) 小文件定义:输出的单个文件大小 < 4MB 则定义为小文件(参数 spark.dlc.monitorFileSizeThreshold 控制,默认 4MB,引擎全局或任务级别均可支持配置) 本指标定义:任务通过 insert 等语句写出的小文件个数总和 |
并行任务 | 展示任务并行执行的情况,方便分析受影响的任务(最多200条) |
洞察算法概览
洞察类型 | 算法描述(正在持续改进和新增算法) |
资源抢占 | 统计指标:第一个 Stage 的 submissionTime 到第一个 Task 开始执行时间之间的延迟时长. 告警规则:当 SQL 任务的 Task 启动延迟同时满足以下任一条件时触发告警:延迟时长超过 Stage 提交时间 1 分钟以上;延迟时长超过任务总运行时长的 20%。 |
shuffle 异常 | stage 执行出现 shuffle 相关错误栈信息 |
慢 task | stage 中 task 时长 > stage 里其他 task 平均时长的2倍(不同运行时长和数据量的任务,阈值公式会有动态调整) |
数据倾斜 | task shuffle 数据 > task 平均 shuffle 数据大小的2倍 (不同运行时长和数据量的任务,阈值公式会有动态调整) |
磁盘或内存不足 | stage 执行错误栈信息中包含了 oom 或者 磁盘不足的信息 或者 cos 带宽限制报错 |
输出较多小文件 | (该洞察类型的收集需 Spark 引擎内核升级至 2024.11.16 之后的版本) 参考列表中的指标 "输出小文件个数" ,满足下述一个条件则判定为 "存在输出较多小文件" : 1. 分区表,若某个分区写出的小文件超过 200 个 2. 非分区表,输出小文件总数超过 1000 个 3. 分区、非分区表写出文件超过 3000 个,平均文件大小小于 4MB |



