一、TDSQL Boundless 规格选择
如果是从 InnoDB/B+ Tree 结构的存储迁移,由于 TDSQL 使用 LSM 结构默认会进行压缩,因此可以简单预估为原空间的1/3(单副本)。例如:InnoDB 中有1T数据(单副本,若为一主两备,则总空间为3T),迁移到 TDSQL Boundless 后,单副本空间约为333G,默认三副本则约为1T。数据迁移完成后,将检查磁盘使用率并进行扩缩容。
优先选择高节点配置,少节点数:例如如果总共为12c/24g/600G的资源需求,则4c/8g/200G x 3节点相较2c/4g/100G x 6节点更优。这是由于更多小节点会带来更多比例的分布式事务和节点之间通信开销。
扩容时优先进行垂直扩容;缩容时优先减少节点。
TDSQL Boundless 实现了动态的 CPU / 内存 / 磁盘扩缩容,业务无感知。
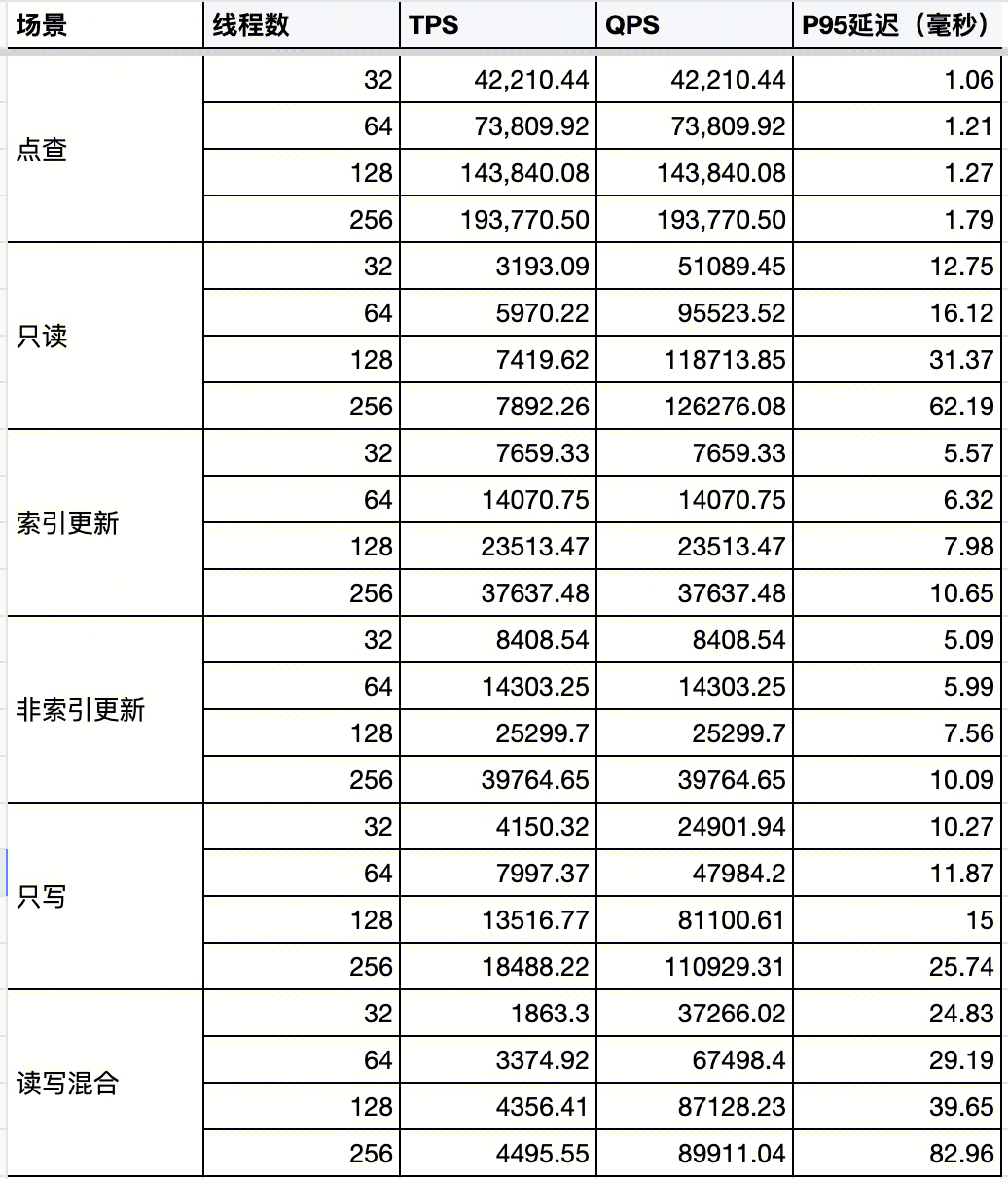
性能参考数据
下表展示了:3节点,16Core CPU / 32GB Memory / 增强型 SSD 云硬盘。32张表,每张表一千万条记录的 Sysbench 性能数据。
二、TDSQL Boundless 的使用
推荐使用场景
业务分库分表场景:迁移至 TDSQL Boundless 后,无需再分库分表。如原使用 TDSQL MySQL InnoDB 分布式的业务,或是业务自己进行分库分表的业务。
存储成本高的业务场景:TDSQL Boundless 默认具备压缩能力,可以显著降低存储成本。
写入量大的场景:比如流水日志类场景。
HBase 替换场景:提供二级索引支持、跨行事务支持等。
SQL 限制和差异点
TDSQL Boundless SQL 语法上兼容 MySQL 8.0,有小部分限制:
不支持外键。
不支持虚拟列、GEOMETRY 类型、降序索引、全文索引。
自增字段 cache 默认100,可以保证全局唯一,不保证全局单调递增。如将自增 cache 设为1,可以保障全局单调递增,但会影响批量显式指定自增值的写入性能。
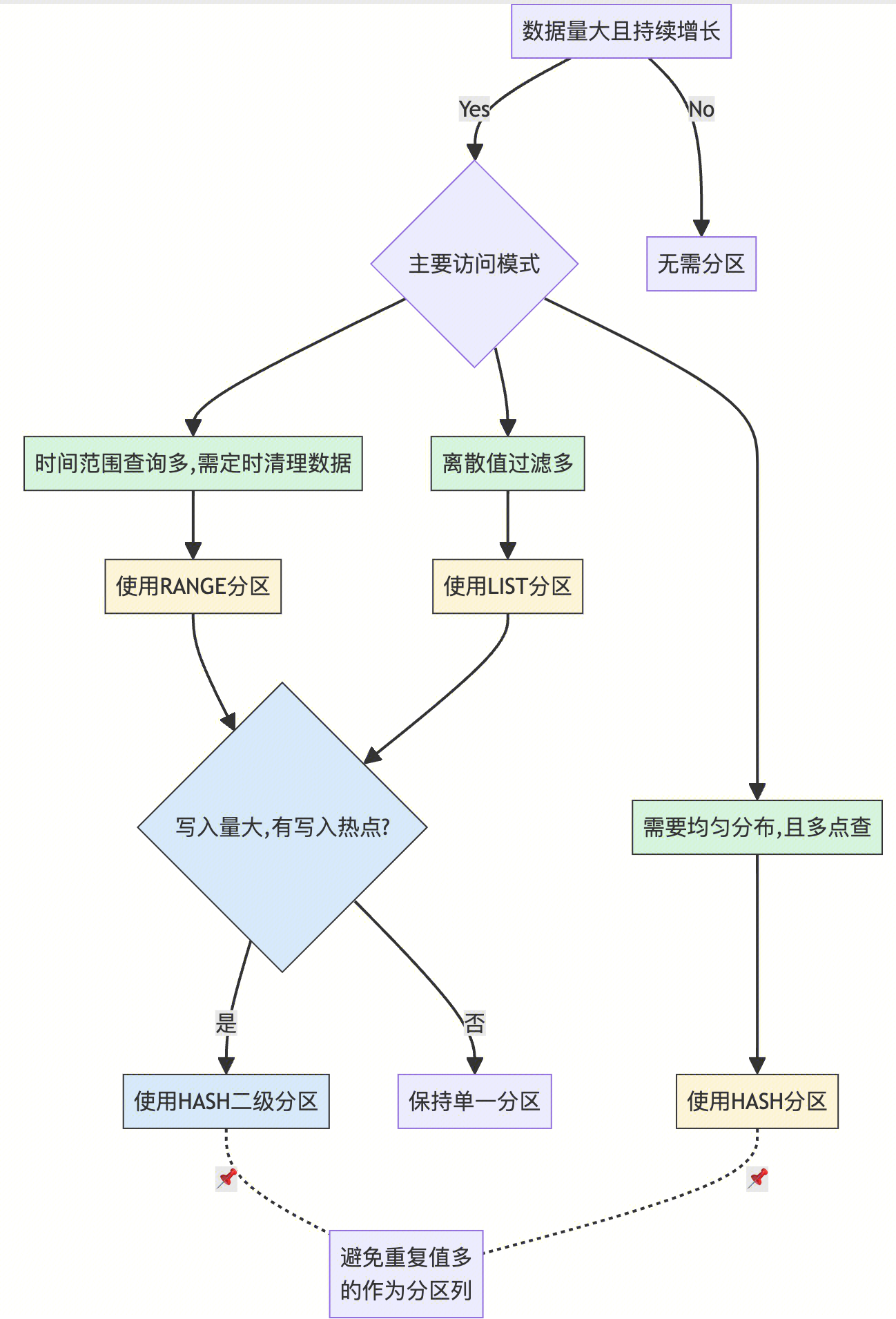
分区表
推荐使用 HASH 分区以打散写入热点,分区数量建议为节点数的整数倍;查询时优先使用 HASH 分区列,避免将重复值较多的列作为分区列。
对于需要定期清理过期数据的场景,推荐使用 RANGE 分区。与此同时,如果写入量大且需要打散写入热点,建议采用 RANGE + HASH 二级分区方式建表。查询的谓语条件带上时间列和 HASH 分区列最佳。
分区数不宜过多。例如,若需要保留3年的数据,按天分区会产生1000个分区。建议选择按周或按月分区,以减少分区数量。
分区类型的选择决策,请参考下图:
Online DDL 能力
TDSQL Boundless 支持大部分的 Online DDL(包括部分只需要修改元数据的 Inplace DDL,在此也统称为 Online DDL),具体能力请参考 OnlineDDL 说明。
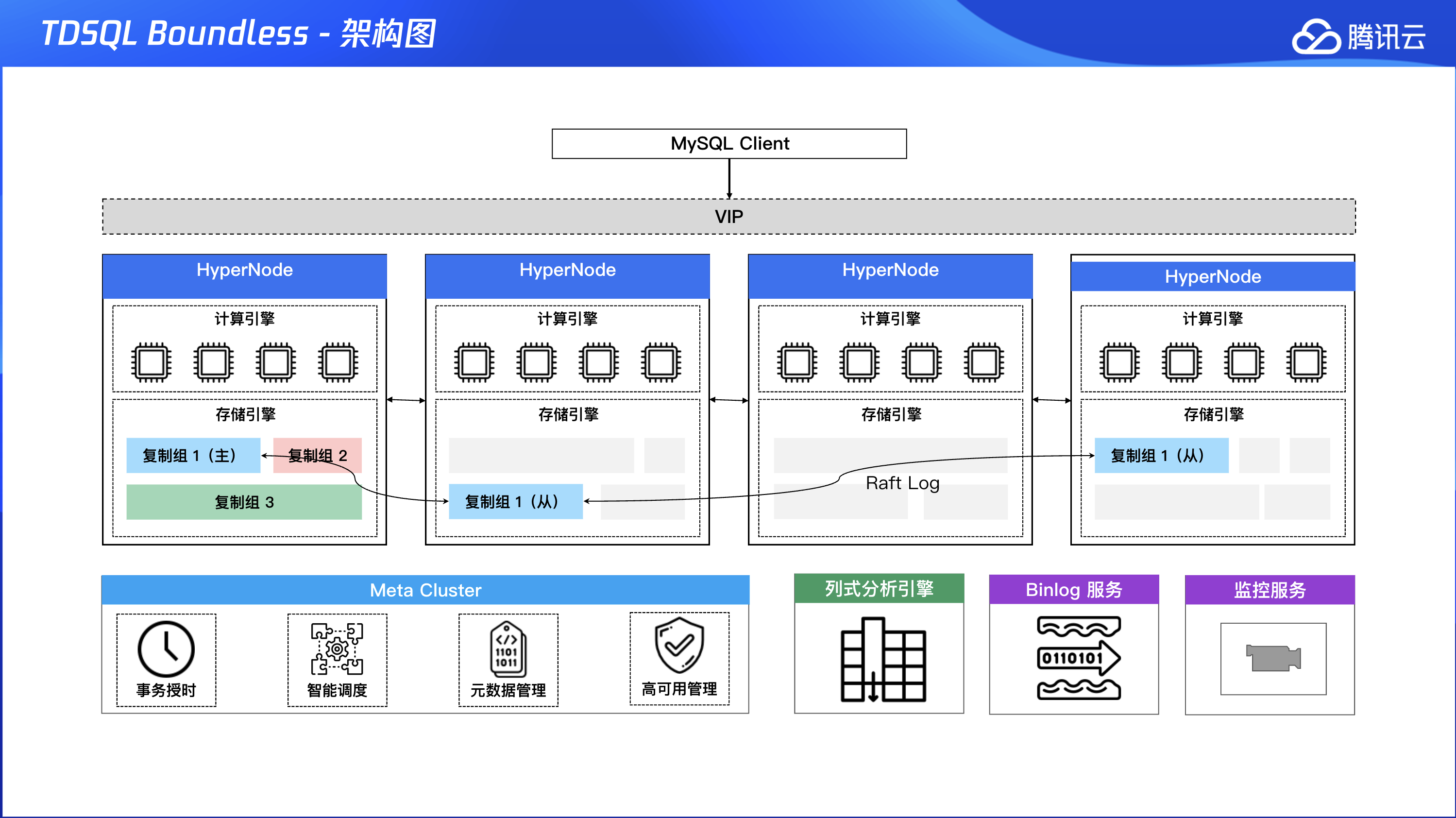
三、TDStore 存储
和传统 MySQL 主从复制不一样,TDSQL Boundless 采用更小的存储管理单位 RG (replica group,复制组)。每个 RG 使用 Raft 协议保证副本的一致性,每个 RG 的 Leader 可以分布到实例的任意节点上,因此,TDStore 的任意节点都可以承载读写的请求,从而可以更充分地使用所有节点的资源。