为什么需要研发 TDSQL Boundless
为解决业务增长中单机数据库的性能瓶颈与分库分表方案的固有不足,腾讯云研发了 TDSQL Boundless。以下是研发背后的核心考量:
目标一:突破单机性能限制
随着业务发展与数据量增长,单机 MySQL 面临硬盘、内存、CPU 等硬件上限。单纯升级硬件不仅成本高,也无法从根本上解决扩展性问题。
目标二:应对分库分表方案的常见挑战
尽管分库分表架构在扩展性和可用性上有所提升,但依然存在明显短板:
兼容性不足,增加业务复杂性:分库分表(Sharding)方案通常无法完全兼容 MySQL 语法与功能,例如很难支持全局索引、跨分片范围(Range)查询、跨表联合查询与分布式事务一致性等等,业务开发需深度理解数据分布逻辑,业务迁移和改造门槛高。尤其在传统行业,系统复杂、表结构众多,改造代价巨大。
弹性扩展能力弱,需要预先设置分片规则:分库分表(Sharding)方案属于预规划分配模式,需要在业务支出前预先规划分片数量,更适合业务场景稳定或有明确规律的场景。一旦分片数量确定后续调整很困难,扩容缩容往往涉及数据重分布与迁移,流程繁重、难以在线完成,无法适应业务快速变化与敏态需求。例如,电商大促之后,需要将多个 MySQL 实例合并为一个实例时,往往需要通过数据导出导入进行数据搬迁合并,操作复杂且耗时长。
海量存储的成本高:基于 B+Tree 的存储引擎(如 InnoDB)在存储效率上不占优,尤其当数据规模增大、冷数据比例升高时,存储成本显著增加。
TDSQL Boundless 的解决思路
为了解决分库分表(Sharding)方案的这些不足,我们推出了 TDSQL Boundless。它高度兼容 MySQL 语法,支持灵活弹性伸缩,用户无需关心数据如何分布。同时,它采用 LSM-Tree 存储结构,压缩效率更高,更适合存储海量数据,能有效降低存储成本。

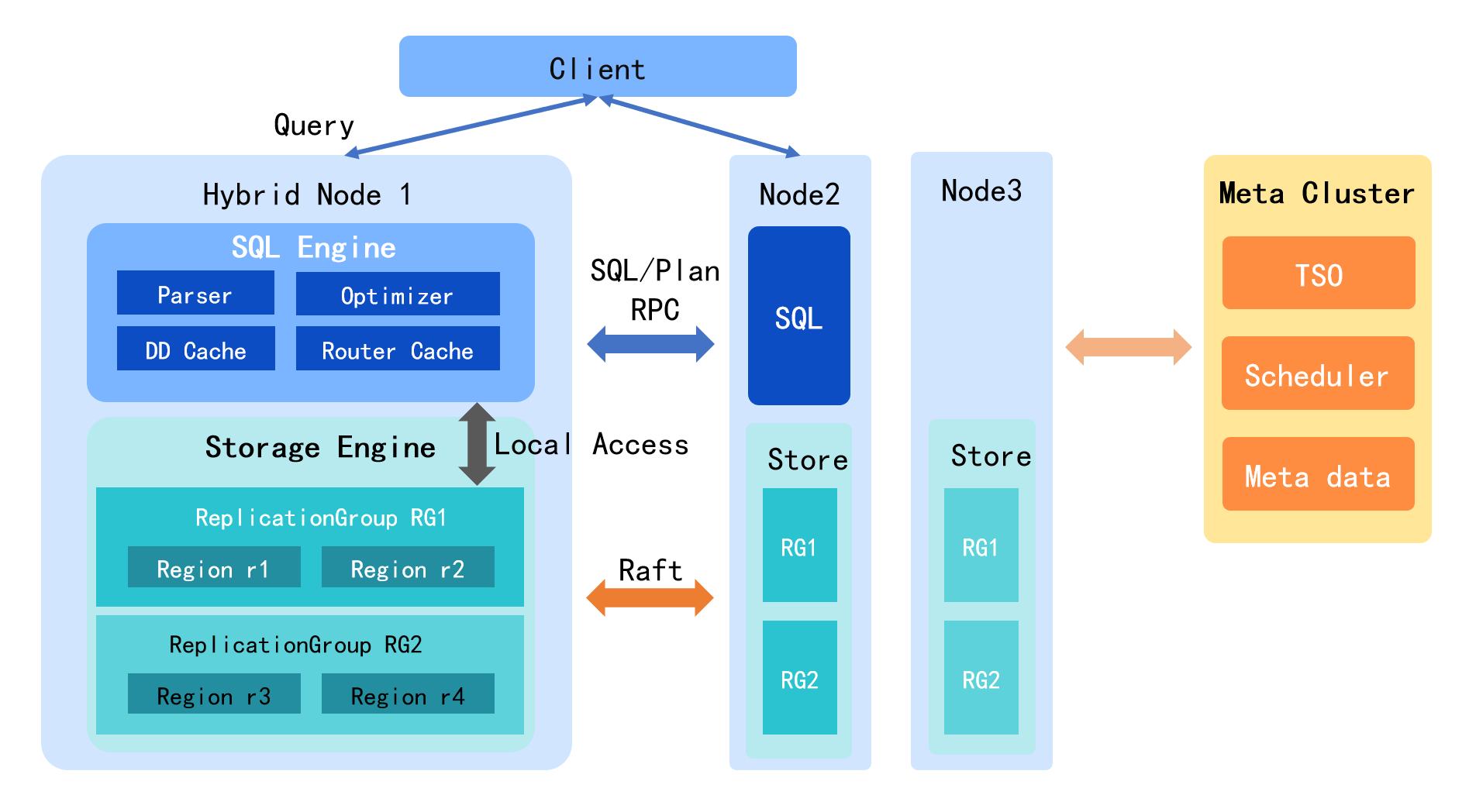
整体架构
TDSQL Boundless 采用存算分离的弹性扩缩容架构,由三个核心组件构成:
组件 | 角色和功能 |
SQLEngine(计算层) | 负责 SQL 解析、查询优化、执行计划生成 具备路由管理、MPP 并行计算、Online DDL 等分布式能力 无状态设计,支持快速扩缩容 |
Storage Engine(存储层) | 负责数据持久化存储 通过 Raft 协议实现多副本数据同步 根据节点负载自动执行数据拆分、合并与迁移 |
MetaCluster(元数据管理) | 分配全局事务时间戳 协调存储层数据调度任务 确保分布式事务一致性与系统状态同步 |
工作流程:客户端接入计算层,计算层通过 RPC 访问存储层数据,控制层统一协调时间戳分配与任务调度,实现各层资源的独立弹性伸缩。