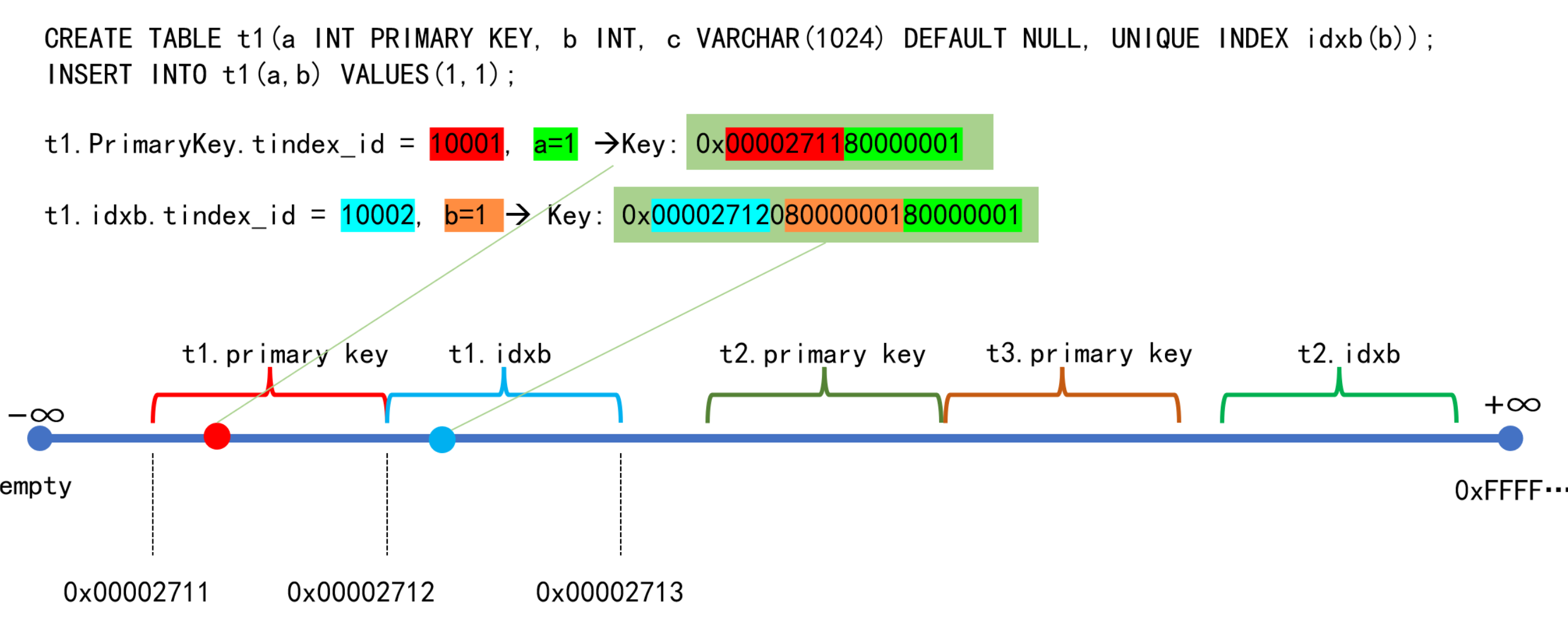
KV 编码和数据空间
在 TDSQL Boundless 中,所有数据都编码为 Key-Value 形式。编码后的 Key 具有 mem-comparable 特性(内存可比较)。
编码规则:系统为每个索引分配一个全局递增的唯一 ID。例如,表 t1 的主键和二级索引各有自己的 ID。同一索引的所有数据,其编码后的 Key 拥有相同的前缀(如 t1 主键的前缀是00002711),因此它们在逻辑上是连续的。
数据空间:数据可以被视为分布在一条无限长的数轴上,每个 Key 占据一个唯一位置。拥有相同前缀的索引数据会集中分布在这条线上的一个连续区间内。这样的一个数据区间称为一个 Region。
因此,同一索引的数据在空间上是连续的,但同一张表的不同索引可能分布在不同的、不连续的 Region 中。
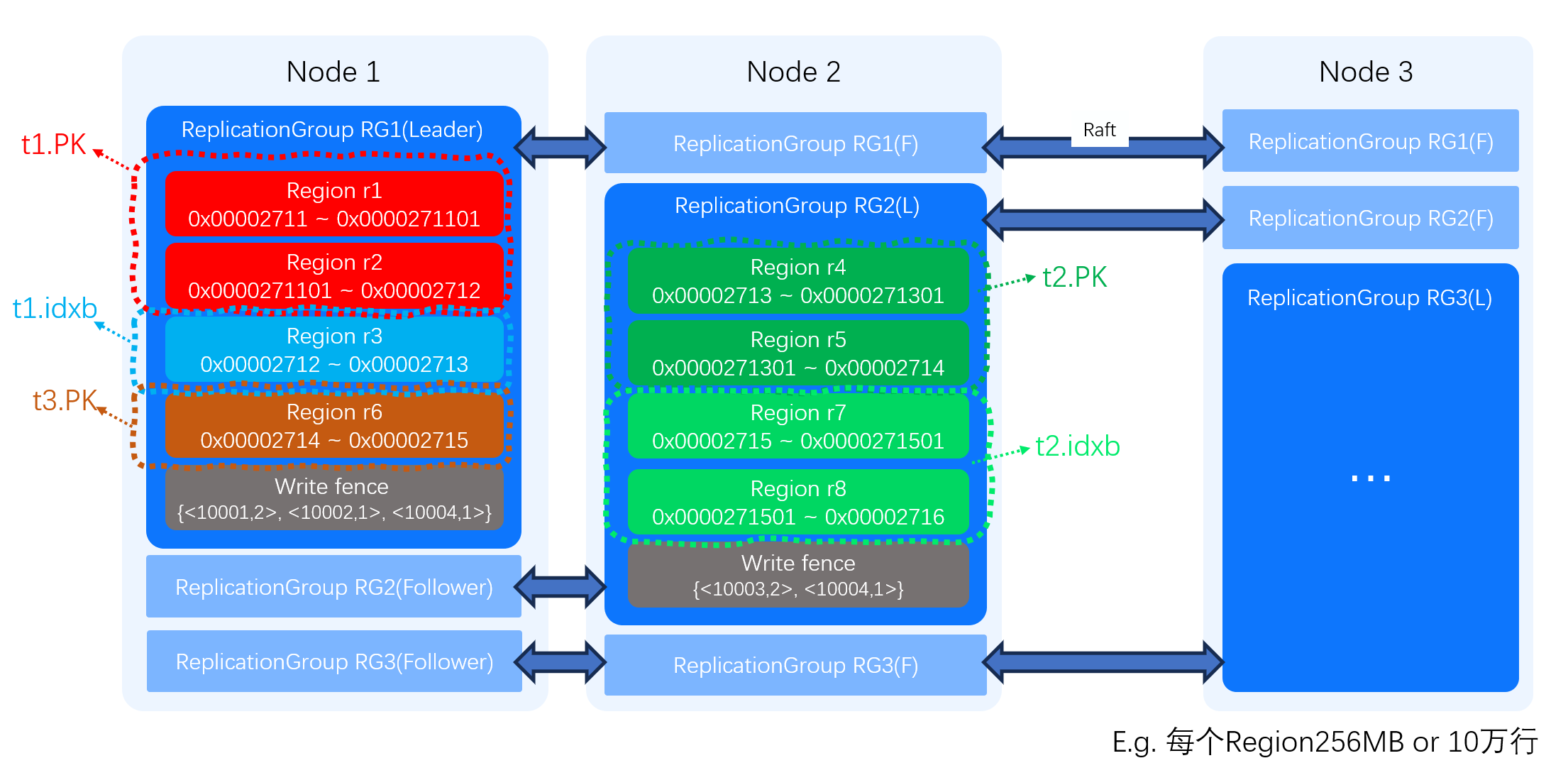
数据分片和复制组
在逻辑数据空间中,每个 Key 对应一个离散的点,但物理上每个 Key-Value 都需要存储空间。当数据量增大时,单个节点无法承载所有数据,因此数据被分割成多个分片,称为 Region。每个 Region 的容量标准为256MB或10万行数据。由于不同索引的数据量不同,Region 的数量会有所差异。
如下所示,表 t1 行数不足10万行,但 Value 字段较多,主键记录占空间更大,因此主键需要2个 Region,二级索引只需1个 Region。
表 t2 行数很多(如20万行),每一行的数据 Key-Value 很短,其主键和二级索引各自需要2个 Region,分别容纳10万行。
为了优化数据调度,在 Region 之上引入了 Replication Group(复制组)。例如,t1.pk 和 t1.idxb 属于不同 Region,但通过复制组可以将这些 Region 调度到相同节点上,从而在 INSERT 操作时避免 2PC 分布式事务,并在查询时避免跨节点回表。一个复制组可包含多个 Region,且复制组的 Leader 节点即为组内所有 Region 的 Leader 节点。