腾讯云数据仓库 TCHouse-D 作为一个分析性数据库,适合几乎所有的分析性数据的场景,其中最主要的四种场景列出如下:

这四种场景都是实际业务中用户对分析性数据库期望最多的场景,但是这些场景在大数据量下,对系统的要求也是非常高的。腾讯云数据仓库 TCHouse-D 通过以下技术来满足这些场景对系统功能和性能的苛刻要求。
OLAP 多维分析和报表——高维表上的高速随意探查能力
在关系数据库中,多维分析定义的对数据立方体(CUBE)上进行的钻取、上卷、切片、切块、旋转等操作是通过维度建模实现的。
维度建模最常见的模型是星型模型和雪花模型。
维度建模中,一个表中的列可以分为维度列和指标列,腾讯云数据仓库 TCHouse-D 支持在建表的时候定义出维度列和指标列,如下图所示。

实时数仓和数据分析——PB 级数据量上的实时增、删、改、查能力
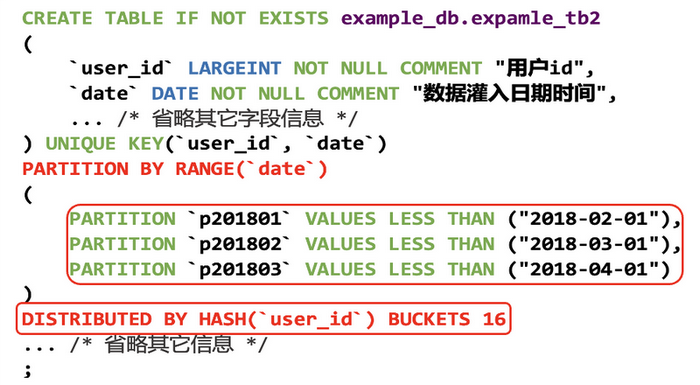
下图展示的是一个腾讯云 TCHouse-D 的建表语句,从这个语句中可以看出,数据可以分区(Partition),也可以分桶 (DISTRIBUTED BY),通过分区和分桶,可以将一个表 (Table) 的数据拆分成多个 Tablet。
物理上,Tablet 会按照一定大小(256M)拆分为多个 Segment 文件,Segment 是列存的 LSM-Tree,全称是Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构。这种结构的理论基础是磁盘批量的顺序写要远比随机写性能高。
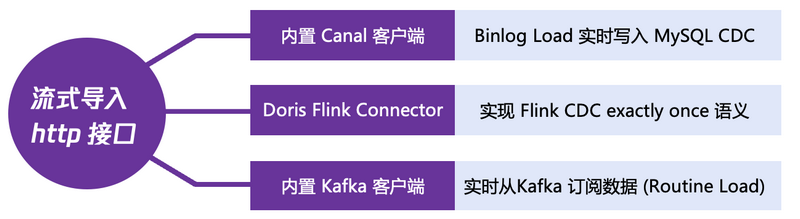
另外,数据的实时写入是非常关键的一个环节,为了实现数据的实时写入,腾讯云数据仓库 TCHouse-D 支持多种写入方式:
通过 Stream Load 实现数据的实时写入能力;
通过内置的 Canal 客户端实时获取 MySQL 的 binlog;
通过 Doris Flink Connector 对接 Flink 的 CDC 能力实现数据的精确导入;
通过内置的 Kafka 客户端订阅 Kafka 的 Topic, 从而实现数据的实时更新。
高并发场景——高并发下低延迟查询能力
腾讯云数据仓库 TCHouse-D 是现代的MPP查询引擎,这个引擎完整实现了 Exchange 节点。有了 Exchange 节点,查询就能被分解到各个节点进行并行数据处理。
同时由于 FE 和 BE 能很容易横向扩展,理论上就能应对并发增加的情况,从而满足高并发场景。
另外,腾讯云数据仓库 TCHouse-D 提供了丰富的索引结构来帮助加速数据的读取和过滤,索引的类型大体可以分为智能索引和二级索引两种。
智能索引是在数据写入时自动生成的,无需用户干预,智能索引包括前缀稀疏索引和MinMax索引两种。
二级索引是用户可以选择性的在某些列上添加的辅助索引。
另外,腾讯云数据仓库 TCHouse-D 也支持动态分区裁剪和谓词下推技术,这些技术都能有效的降低最终从磁盘 scan 的数据量,从而加快查询的执行。
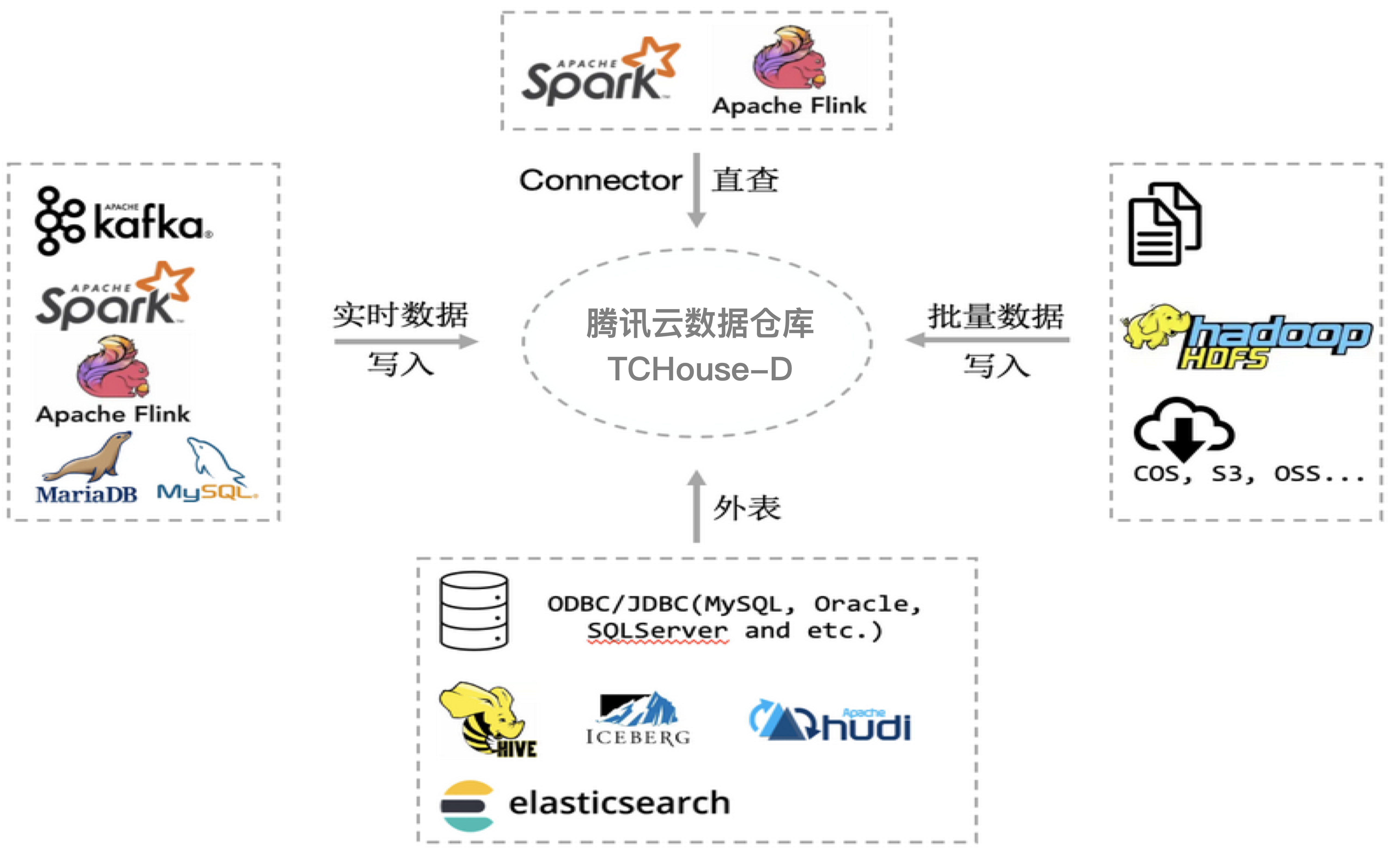
大数据和数据库统一分析——Hadoop 生态兼容和外表高性能查询能力
腾讯云数据仓库 TCHouse-D 不依赖 Hadoop 组件,但本身对 Hadoop 生态进行了全面的支持。除了可以通过 Flink、Spark 写入外,还可以导入 HDFS 的数据,或通过建立 Hive 外表,直接查询 Hive 数据。
下图是腾讯云数据仓库 TCHouse-D 对 Hadoop 生态支持的一个全景图。