目前,TencentOS Server 4 已实现对 NVIDIA Driver 和 CUDA 的原生支持,为您使用 NVIDIA GPU 提供了完整的 RPM 二进制软件包,包括内核级驱动、系统管理工具、计算库及AI框架适配组件。
本文档将指导如何在 TencentOS Server 4 上快速完成 NVIDIA Driver 和 CUDA 的安装部署,并无缝运行上层 AI 模型与应用。
基础环境要求及说明
支持 TencentOS 内核版本:6.6内核(含其间各小版本)。如您使用的是TencentOS 2 或 3系列(5.4内核),建议您升级至 TencentOS 4版本(6.6 内核)。
支持的 GPU 驱动和对应 CUDA 版本 :
驱动版本 | 对应CUDA版本 |
525.147.05 | 12.0.1 |
530.41.03 | 12.1.1 |
535.274.02 | 12.2.2 |
545.29.06 | 12.3.2 |
550.163.01 | 12.4.1 |
555.58.02 | 12.5.1 |
560.35.03 | 12.6.3 |
570.195.03 | 12.8.1 |
575.64.05 | 12.9.1 |
580.95.05 | 13.0.1 |
支持的 CUDA 版本:11.8.0、 12.0.1、 12.1.1、 12.2.2、 12.3.2、 12.4.1、 12.5.1、 12.6.3、 12.8.1、 12.9.1、 13.0.1。
安装 NVIDIA Driver
安装 TencentOS EPOL源
dnfinstallepol-release
安装 NVIDIA Driver 驱动包
此处以 Nvidia-Driver-570 为例,若需安装其他版本,请更新以下命令中软件包名的版本号,将570替换为目标版本号即可。
# 安装开源模块dnf install -y kmod-nvidia-570-dkms-open nvidia-570 nvidia-driver-570-open# 安装闭源模块dnf install -y kmod-nvidia-570-dkms nvidia-570 nvidia-driver-570
说明:
NVIDIA Driver 分为开源和闭源版本,所以部署流程分为开源模块安装和闭源模块安装两部分。
闭源版本驱动由 NVIDIA 公司官方提供,内核模块来自 NVIDIA 官方 .run安装包中的闭源代码,通常拥有最新的功能和最优化的性能,包括对 NVIDIA 最新显卡架构的支持,以及对 DirectX、OpenGL 等图形接口的完整支持。缺点是它们不开放源代码,这可能会限制它们与 Linux 内核的兼容性,并且在社区支持方面不如开源驱动。
开源版本驱动(如 nouveau)是由社区维护的,内核模块来自 open-gpu-kernel-modules 仓库的开源代码,可以更好地与 Linux 内核集成。尽管它们可能在功能/性能上不如闭源驱动全面,但在某些方面,如内核兼容性,它们表现得更为出色。
安装验证
# 重启机器sudo reboot# 查看已安装的驱动软件包dnf list installed | grep nvidia# 查看驱动信息nvidia-smi
注意:
实例重启会导致正在运行的应用和服务被强制终止,或文件和内存数据会丢失。请先在重启前做好数据保存等操作。
卸载驱动安装包(可选)
如需要切换驱动版本,请参见以下步骤卸载已安装的驱动安装包。
# 卸载开源模块dnf remove -y kmod-nvidia-570-dkms-open nvidia-570 nvidia-driver-570-open# 卸载闭源模块dnf remove -y kmod-nvidia-570-dkms nvidia-570 nvidia-driver-570
安装 CUDA
针对使用场景的不同,TencentOS 团队采用了全新的打包方案。新方案通过将 CUDA 拆分为 runtime 和 devel 两类子包,实现了组件精细化分层管理,既满足了轻量级生产部署的需求,又支持了代码编译和模型训练的完整开发环境。
优化方向 | 传统方案 | 新方案 |
包结构 | 细分子包 | 拆分为 runtime /devel 两类子包 |
组件分层 | 静态库/工具与运行时捆绑 | 划分可执行文件、.so 动态库、头文件、.a 静态库 |
其中,runtime / devel,对应组件范围如下:
类型 | 组件范围 | 适用场景 |
Runtime | 可执行文件、 .so 动态库 | 轻量级生产部署 |
Devel | runtime 、头文件、 .a 静态库 | 代码编译/模型训练 |
安装 CUDA 组件
此处以 cuda-12-8 为例,如需安装其他版本,请更新以下命令中软件包名的版本号,将12-8替换为目标版本号即可。
Runtime 包安装:
dnfinstall-y cuda-runtime-12-8
Devel 包安装:
dnfinstall-y cuda-devel-12-8
安装验证
# 查看已安装的 cuda 软件包dnf list installed | grep cuda# 查看 cuda 版本nvcc --version
多版本共存支持(可选)
新版打包方案解决了 CUDA 多版本共存的问题,可下载多个版本的 CUDA,并利用
update-alternatives 进行版本切换。如需兼容 CUDA 多版本共存,请参见 安装 CUDA,依次安装所需版本。例如,当同时安装 CUDA 12.2 与 12.9 版本,可参见以下方式切换版本: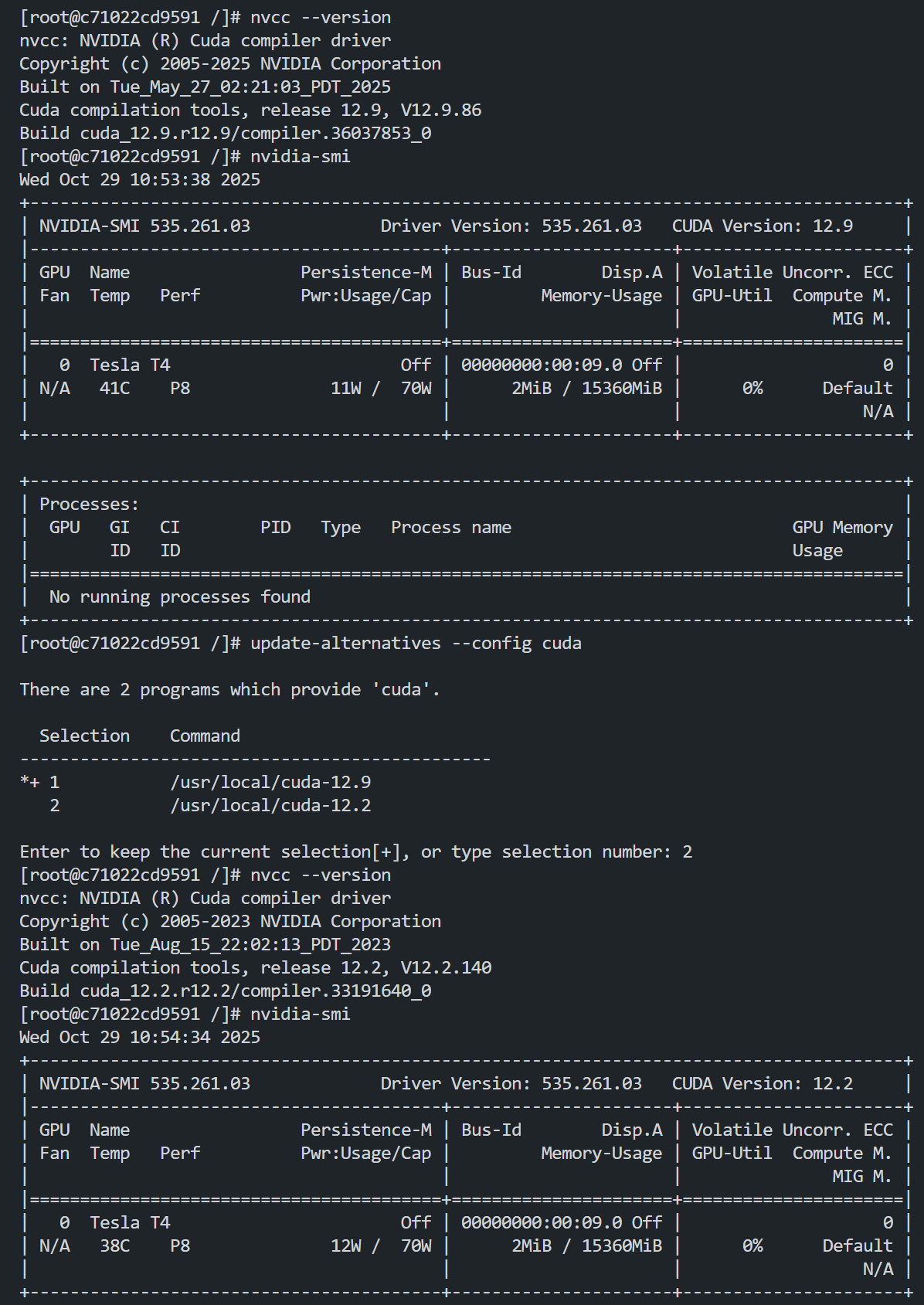
卸载 CUDA 组件(可选)
如需切换 CUDA 版本,请参见以下步骤卸载已安装的 CUDA 安装包。
Runtime 包:
dnf remove -y cuda-runtime-12-8 cuda-toolkit-12-8-config-common
Devel 包:
dnf remove -y cuda-runtime-12-8 cuda-toolkit-12-8-config-common cuda-12-8 cuda-devel-12-8 cuda-toolkit-12-8
AI 应用安装与验证
运行大模型(以 vLLM 框架和 Qwen 示例)
安装 uv
# 下载 uvdnf install pippip install uv# 推荐使用 uv 安装,智能处理依赖冲突uv pip install vllm==0.10.0 --system
服务启动
# 启动 vllm 服务,拉取大模型(此处以 Qwen 为例)vllm serve "Qwen/Qwen3-0.6B"# 若机器配置较低,可尝试如下命令启动服务vllm serve "Qwen/Qwen3-0.6B" --gpu-memory-utilization 0.7 --max-model-len 1024 --max-num-seqs 4 --dtype float16 --block-size 16
结果展示:
示例:命令行测试
# 另起终端curl -X POST "http://localhost:8000/v1/chat/completions" -H "Content-Type: application/json" --data '{"model": "Qwen/Qwen3-0.6B","messages": [{"role": "user","content": "What is the capital of France?"}]}'
示例:Python 代码部署和推理
创建python程序,内容如下:from vllm import LLM, SamplingParamsfrom transformers import AutoTokenizer# 初始化模型参数model_path = "Qwen/Qwen3-0.6B" # 替换为实际模型路径llm = LLM(model=model_path,dtype="half", # 启用半精度推理(FP16)trust_remote_code=True, # 对Hugging Face模型必须开启tensor_parallel_size=1, # 单GPU运行gpu_memory_utilization=0.8 # 显存利用率控制)# 配置生成参数sampling_params = SamplingParams(temperature=0.7,top_p=0.95,max_tokens=256,repetition_penalty=1.1)# 构建对话模板messages = [{"role": "system", "content": "你是一个诗人"},{"role": "user", "content": "写一首关于春天的七言绝句"}]tokenizer = AutoTokenizer.from_pretrained(model_path)prompt = tokenizer.apply_chat_template(conversation=messages,tokenize=False,add_generation_prompt=True)# 执行推理outputs = llm.generate(prompts=[prompt],sampling_params=sampling_params)# 输出结果for output in outputs:generated_text = output.outputs[0].textprint(f"生成结果:\\n{generated_text}")
运行大模型(以 Ollama + Qwen 示例)
安装
# 安装依赖dnf install -y gawk# 下载安装脚本并安装curl -fsSL https://ollama.com/install.sh | sh
服务启动
# 服务启动ollama serve
运行 Qwen 模型
# 拉取大模型(此处以 Qwen 为例)ollama run qwen3:0.6b
常见问题
nvidia-smi 显示的 CUDA Version 与实际 CUDA Toolkit 版本不一致
nvidia-smi 显示的 CUDA Version 与实际 CUDA Toolkit 版本不一致是正常现象,原因在于两者代表不同层面的版本信息。nvidia-smi 命令返回结果中,Driver Version 是当前安装的驱动版本,CUDA Version 代表驱动所支持的最高 CUDA Runtime API 版本,并非当前安装的 CUDA Toolkit 版本。如需查看 CUDA Toolkit 版本,请执行
nvcc --version 命令。cuda-compat 问题(Driver 与 CUDA 版本兼容)
在 CUDA 生态中,不同 CUDA 版本均有与之最为适配的驱动程序版本。实际上,每个 CUDA 工具包都配套提供了 NVIDIA 显示驱动程序包,此驱动程序能够全面支持该版本 CUDA 工具包所引入的各项功能,是在该 CUDA 版本开发阶段就紧密匹配、功能兼容性最优的版本对应关系。
关于 CUDA 版本与驱动版本的对应关系,请参见 官方版本发布说明。但是,在实际应用场景里,如果需要突破这种既定对应关系,例如在旧版本的驱动上运行高版本的 CUDA,或者是在较新的驱动上运行旧版本的 CUDA,将不可避免地引发兼容性问题。
为满足高版本 CUDA 在老旧硬件设备上的运行需求,官方专门推出了 cuda-compat 包以实现兼容适配。其实际效果是,当使用该包时,高版本 CUDA 仅能调用当前驱动所支持的最高版本 CUDA 所具备的功能,而无法使用因 CUDA 升级而新增的功能,从功能体验层面来看,类似对 CUDA 版本进行“降级”处理。
具体结论如下:
驱动版本高于或等于 CUDA 版本,CUDA 不安装 cuda-compat,运行正常;安装 cuda-compat,可能发生异常。
驱动版本低于 CUDA 版本, CUDA 必须安装 cuda-compat。
低版本 CUDA 上运行 AI 框架(vLLM)时库文件缺失问题
vLLM 核心架构是自研高性能 C++/CUDA 内核,深度集成 PyTorch,编译时链接特定版本的 CUDA 运行时,与 PyTorch 的 CUDA 版本强相关。而高版本的 vLLM 都是根据较新的 PyTorch 来进行构建,因此在较低版本的系统 CUDA 环境中编译 vLLM 时会出现关键 symbol 缺失问题,具体报错信息可参考如下截图:
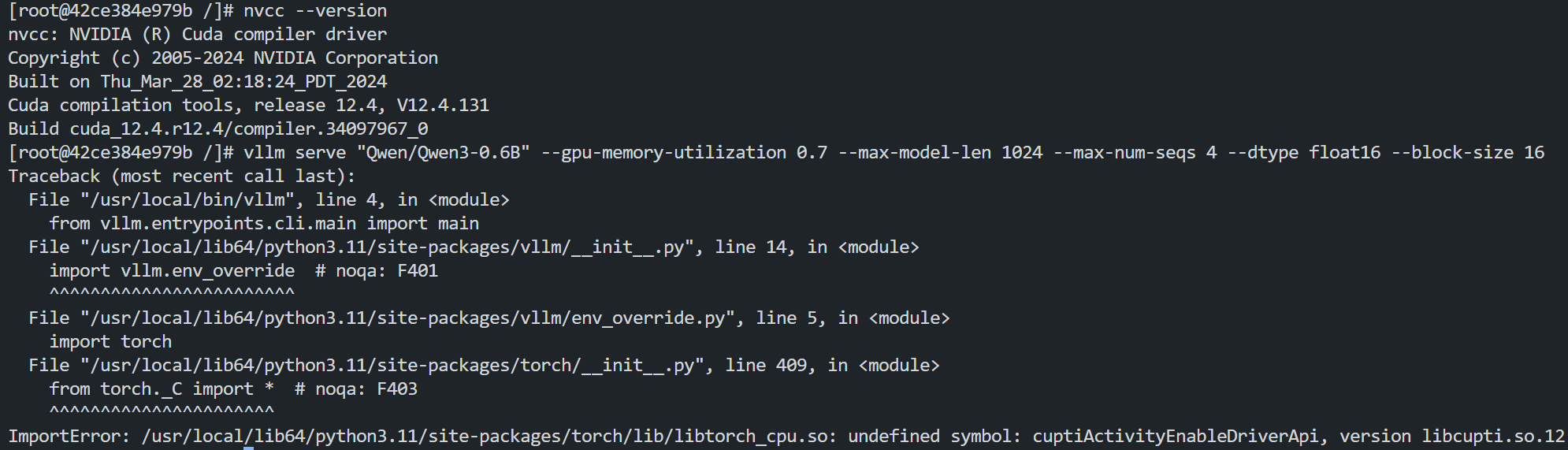
例如,在 CUDA 12.2 中编译 vLLM 时出现 CUPTI 相关 symbol 缺失问题,经分析发现,PyTorch/Triton 自带的 CUPTI 库包含所需符号,但 CUDA 12.2 包含的 CUPTI 库缺少所需符号:

切换到高版本的 CUDA 12.9 环境时,测试结果包含目标 symbol 且可以成功运行:

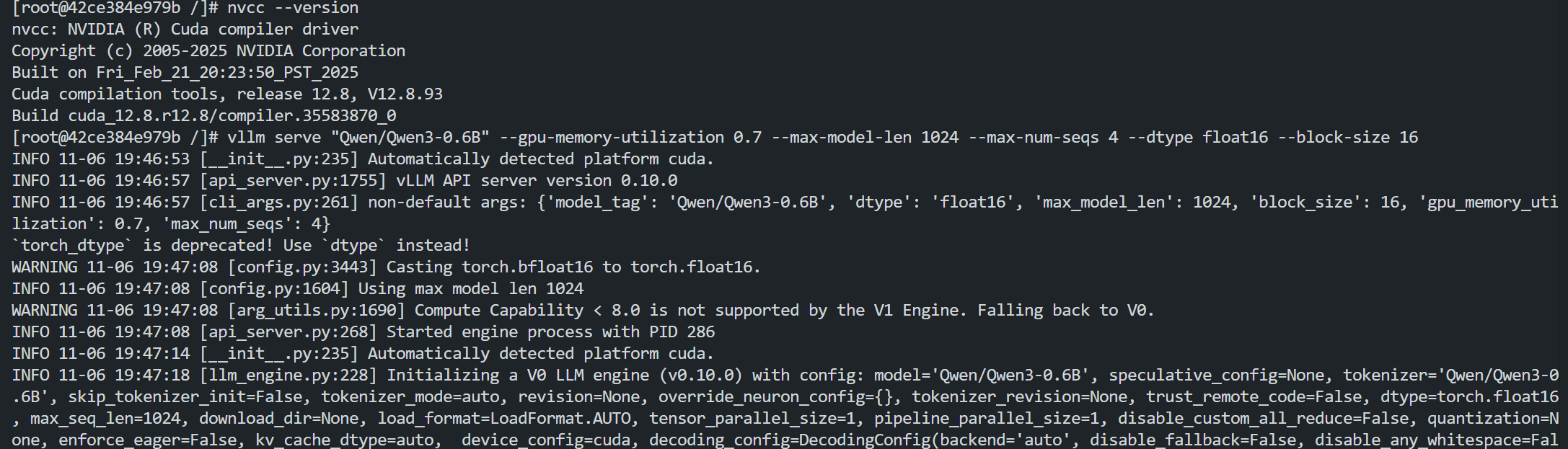
以上情况,您可通过设置环境变量,指定动态链接器搜索共享库(.so文件)的路径。当运行需要特定版本 CUDA 库的程序时,系统会优先在这个路径中查找库文件。具体命令如下:
export LD_LIBRARY_PATH=/usr/local/lib/python3.11/site-packages/nvidia/cuda_cupti/lib:$LD_LIBRARY_PATH



