背景
在当今的云计算和微服务架构中,Kubernetes 已经成为了容器编排和管理的事实标准。它不仅提供了高效的容器管理能力,还支持自动扩缩容、服务发现、负载均衡等高级功能,极大地简化了云原生应用的部署和运维工作。然而,随着应用的复杂性增加,确保系统的高可用性和稳定性变得尤为重要。故障模拟(Chaos Engineering)作为一种通过主动引入故障来测试系统稳定性的实践方法,对于提高 Kubernetes 集群的鲁棒性至关重要。
本文档旨在介绍如何在腾讯云标准集群环境中,针对 CPU、内存、磁盘资源进行故障模拟,以帮助开发和运维团队更好地理解和准备应对可能的系统故障。
演练实施
步骤一:演练准备
准备一个TKE容器实例,部署一个测试Pod。
进入探针管理页面为TKE容器安装探针,具体安装方式请参考 探针管理 进行操作。
说明:
由于 Serverless 集群与标准集群故障注入过程和故障表现一致,参考本文的标准集群故障实践即可。
步骤二:演练编排
1. 登录 云顾问 > 混沌演练控制台,进入演练管理页面,单击新建演练,点击跳过,新建空白演练。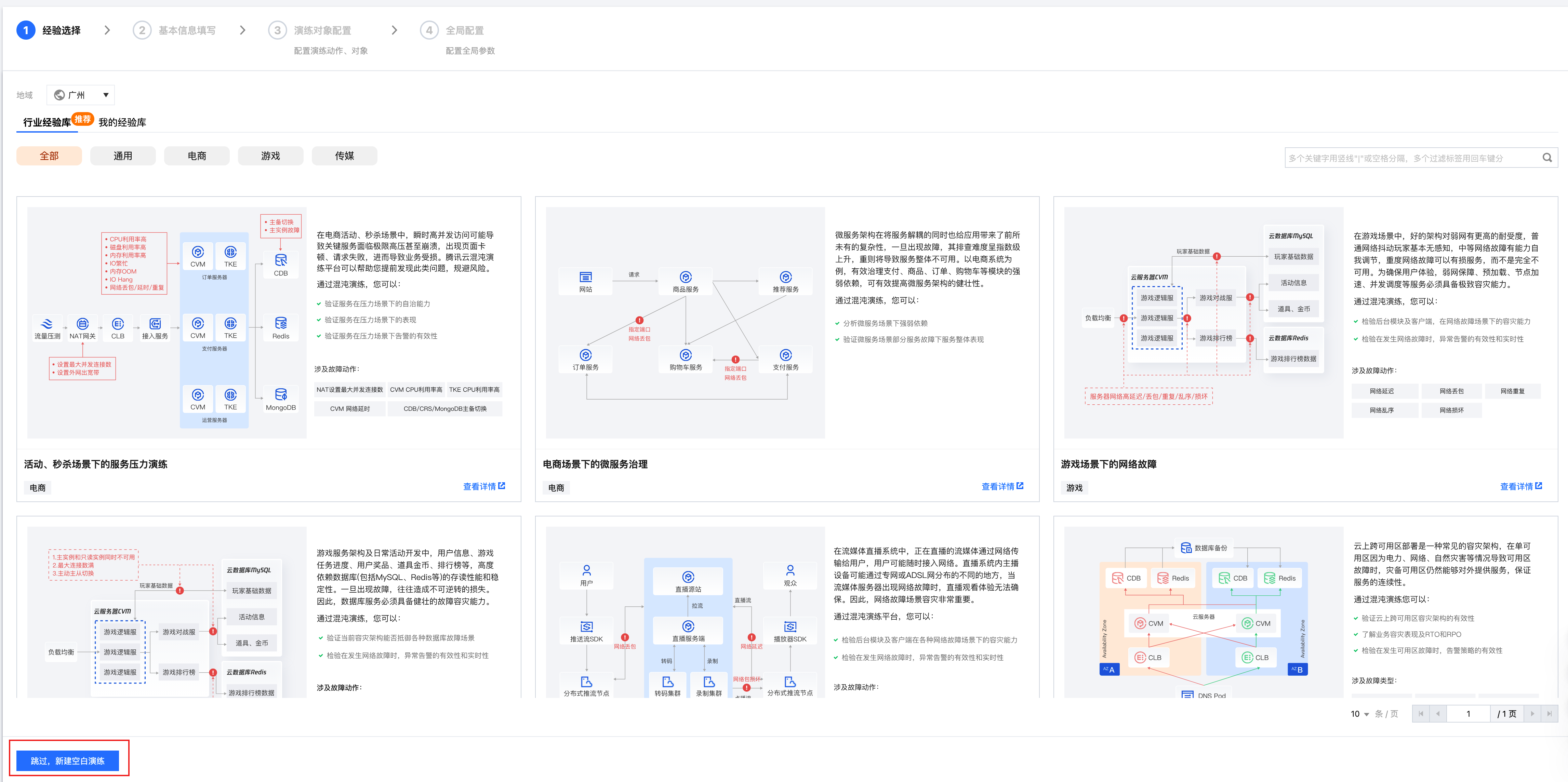
2. 填写演练基本信息。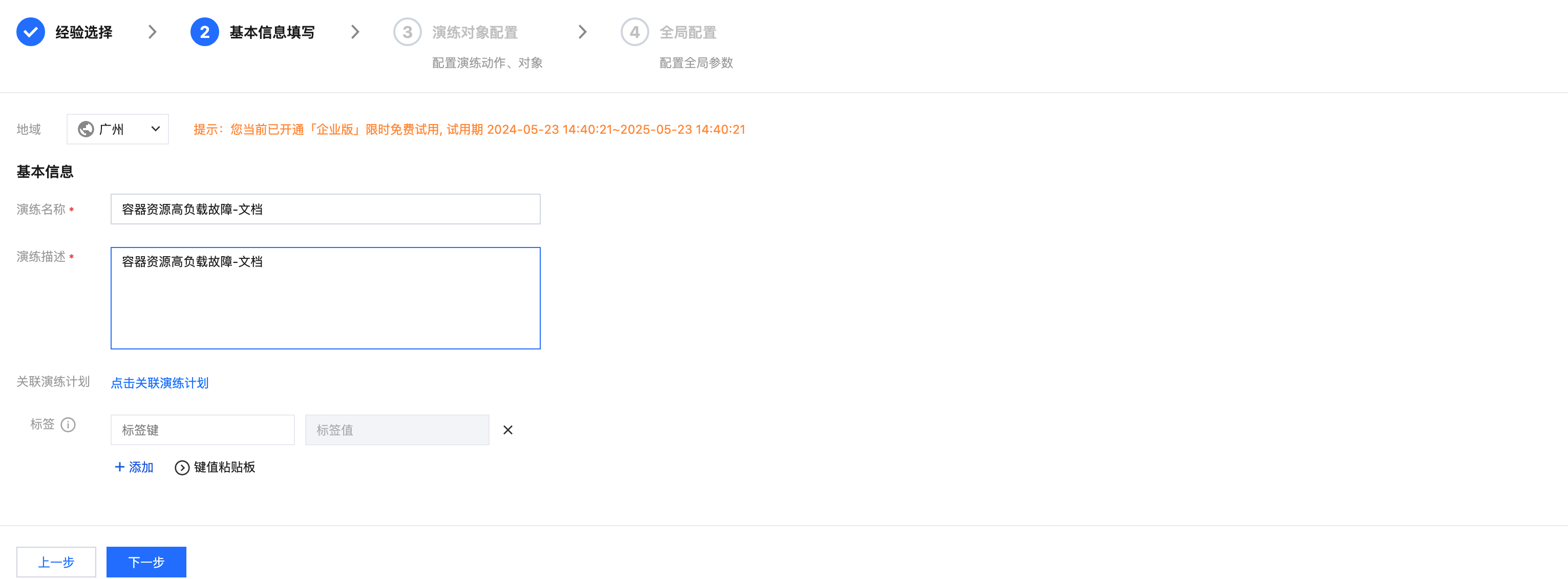
3. 资源类型选择容器,资源对象选择标准集群 Pod,然后添加实例。
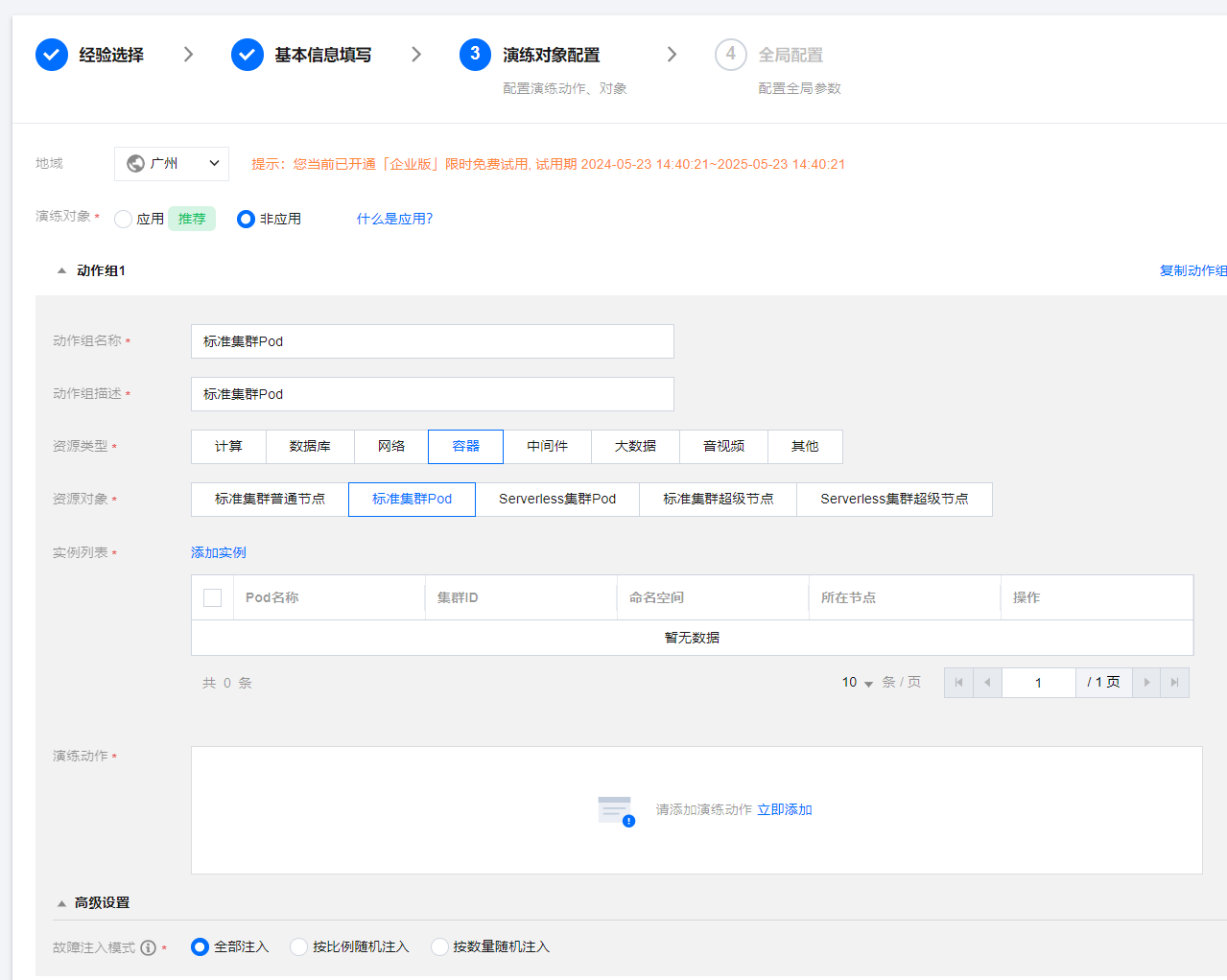
4. 添加演练动作,点击立即添加,并配置故障动作参数。
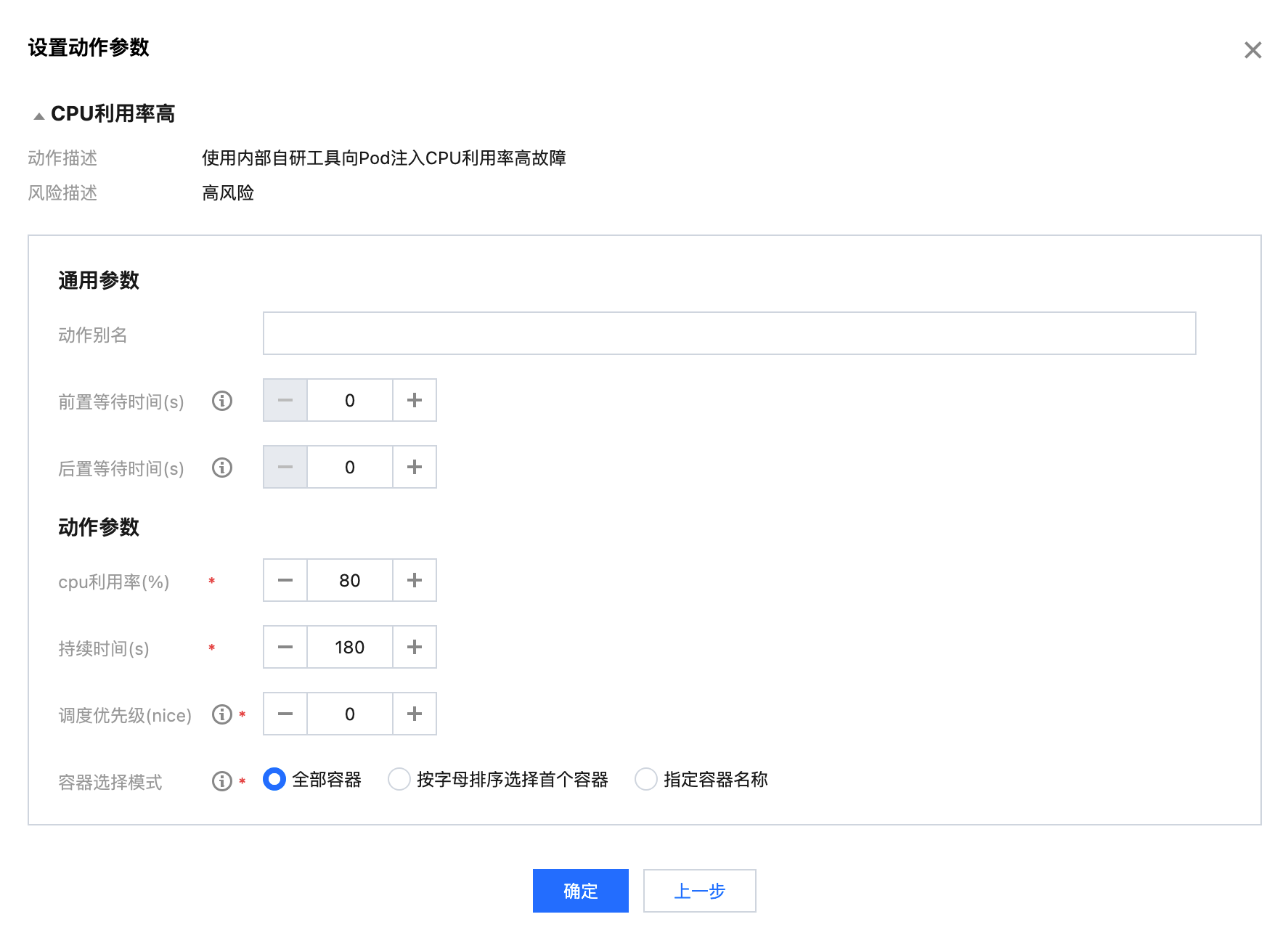
配置 CPU 利用率高动作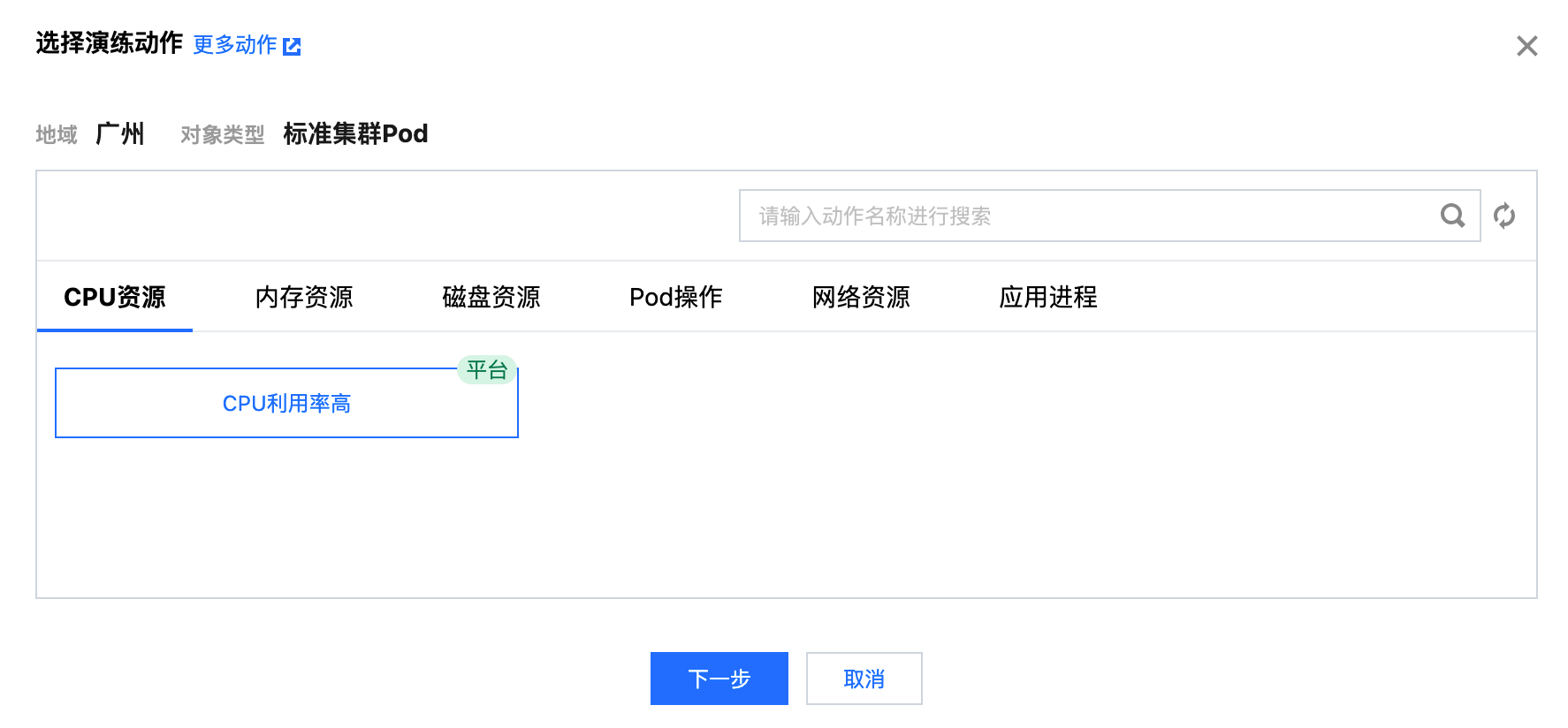
说明:
cpu 利用率:指定 CPU 负载百分比,取值在0 - 100之间。
持续时间:故障动作持续时间,达到该时间探针会自动将故障恢复。
调度优先级:影响进程在 CPU 调度中的优先级。较低的 nice 值使进程更有可能获得 CPU 时间片,从而提高其执行优先级。仅当利用率为100%时生效。
容器选择模式:选择故障范围,对Pod下的部分或者全部容器注入故障。
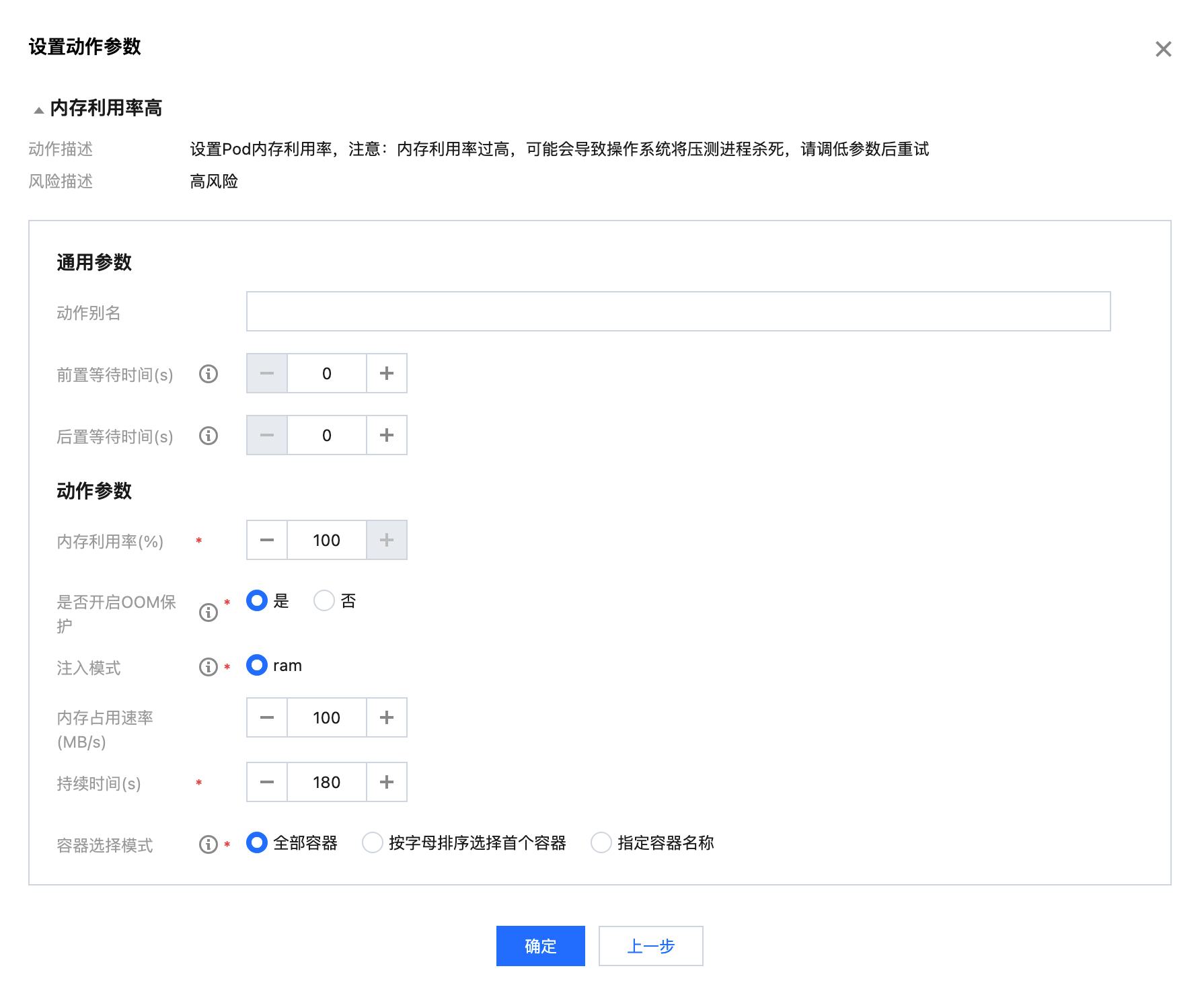
配置内存利用率高动作
说明:
内存使用率:指定内存负载百分比,取值在0 - 100之间。
持续时间:故障动作持续时间,达到该时间探针会自动将故障恢复。
是否开启 OOM 保护:开启后会降低故障进程被 OOM-KILL 的可能性,优先 Kill 业务进程。
内存占用速率:每秒增加的内存使用量。
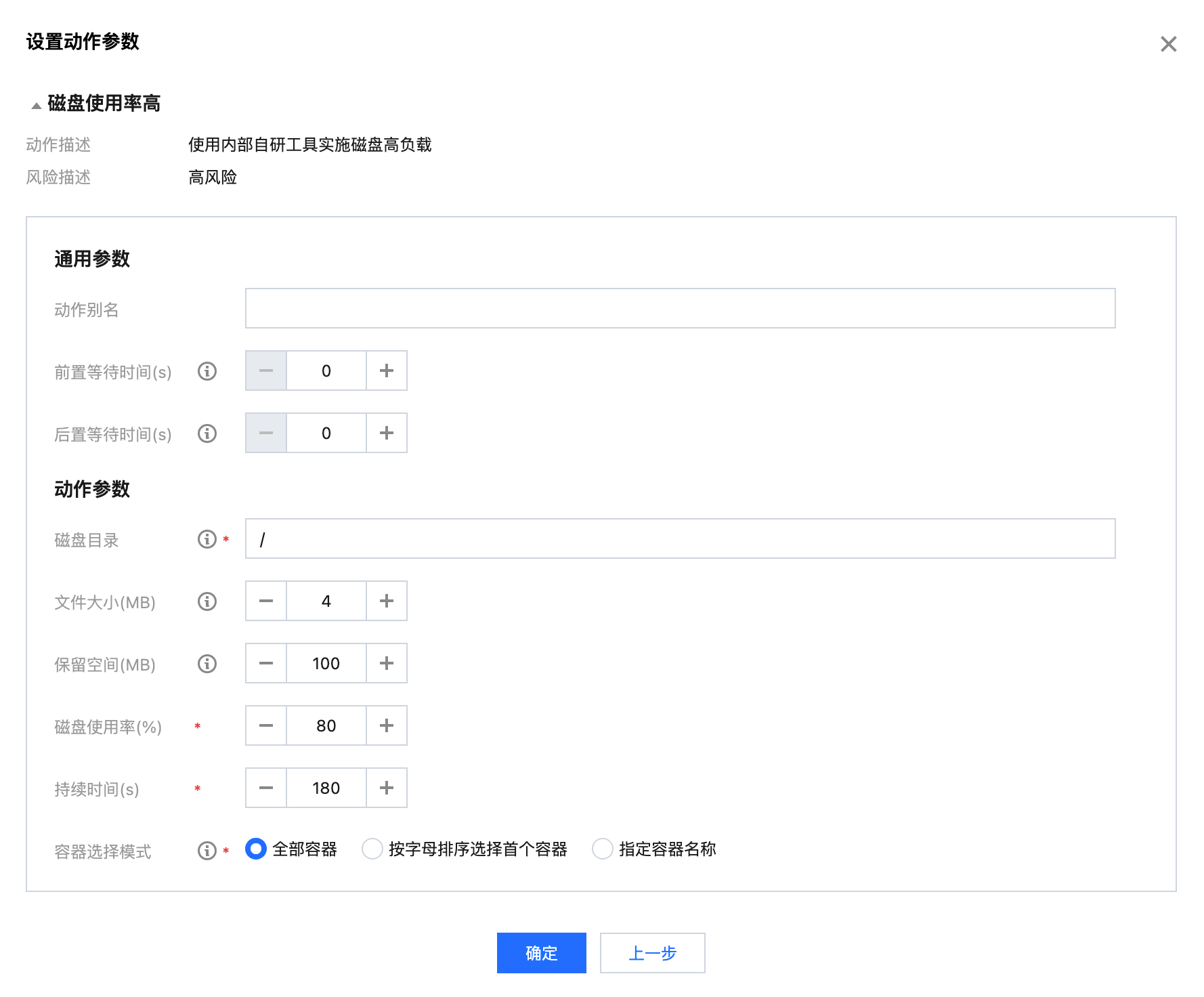
配置磁盘使用率高动作
说明:
磁盘目录:需要进行填充的磁盘目录,即文件写入目录。
文件大小:填充的文件大小。
磁盘使用率:通过staf命令获取磁盘使用情况,计算出达到指定使用率所需的文件大小。
保留空间:剩余空间保留大小。
持续时间:故障动作持续时间,达到该时间探针会自动将故障恢复。
如果文件大小、磁盘使用率、保留空间参数都存在,优先级计算逻辑为: 磁盘使用率 > 保留空间 > 文件大小。
配置磁盘 IO 负载高动作
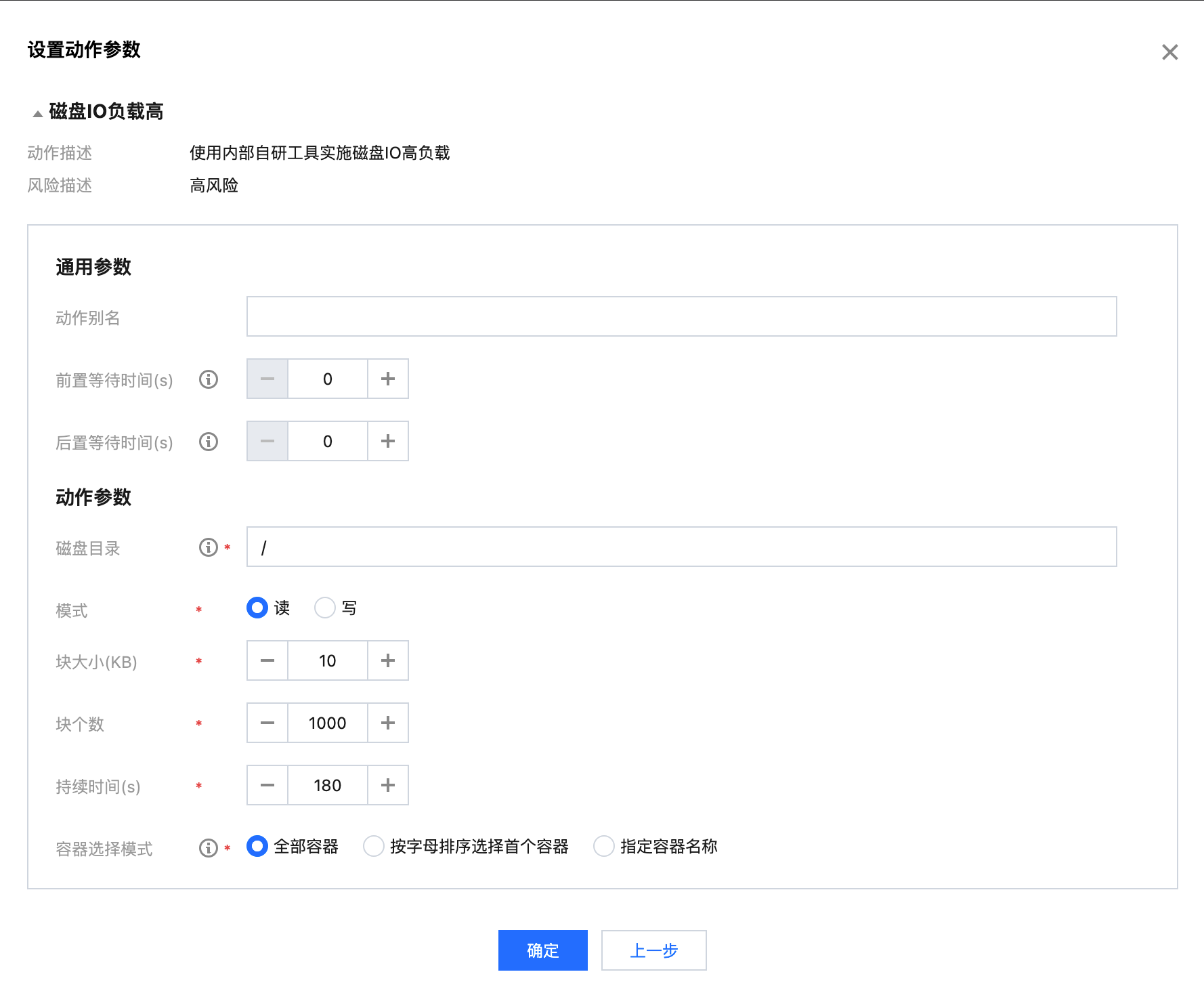
说明:
磁盘目录:指定提升磁盘 IO 的目录,会作用于其所在的磁盘上。
模式:提供读、写两种方式实施高负载。
块大小:指定每次读取或写入的块大小。
块个数:指定复制的块个数。
持续时间:故障动作持续时间,达到该时间探针会自动将故障恢复。
5. 动作参数配置完成之后,单击下一步。然后根据实际情况配置护栏策略和监控指标,完成所有配置之后,点击提交,完成演练创建。
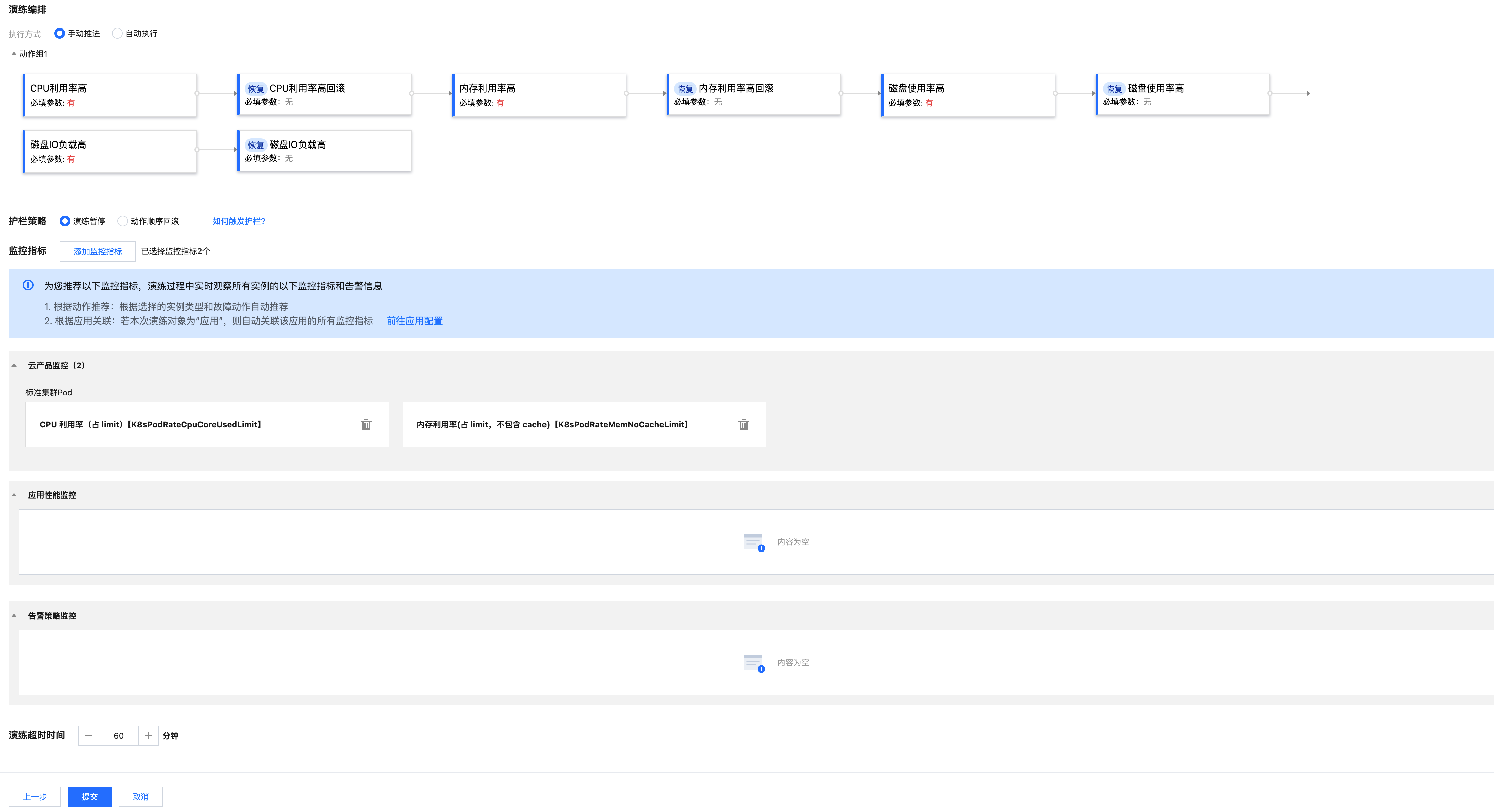
步骤三:执行演练
1. 点击执行 CPU 利用率高动作开始执行演练,观察监控指标。
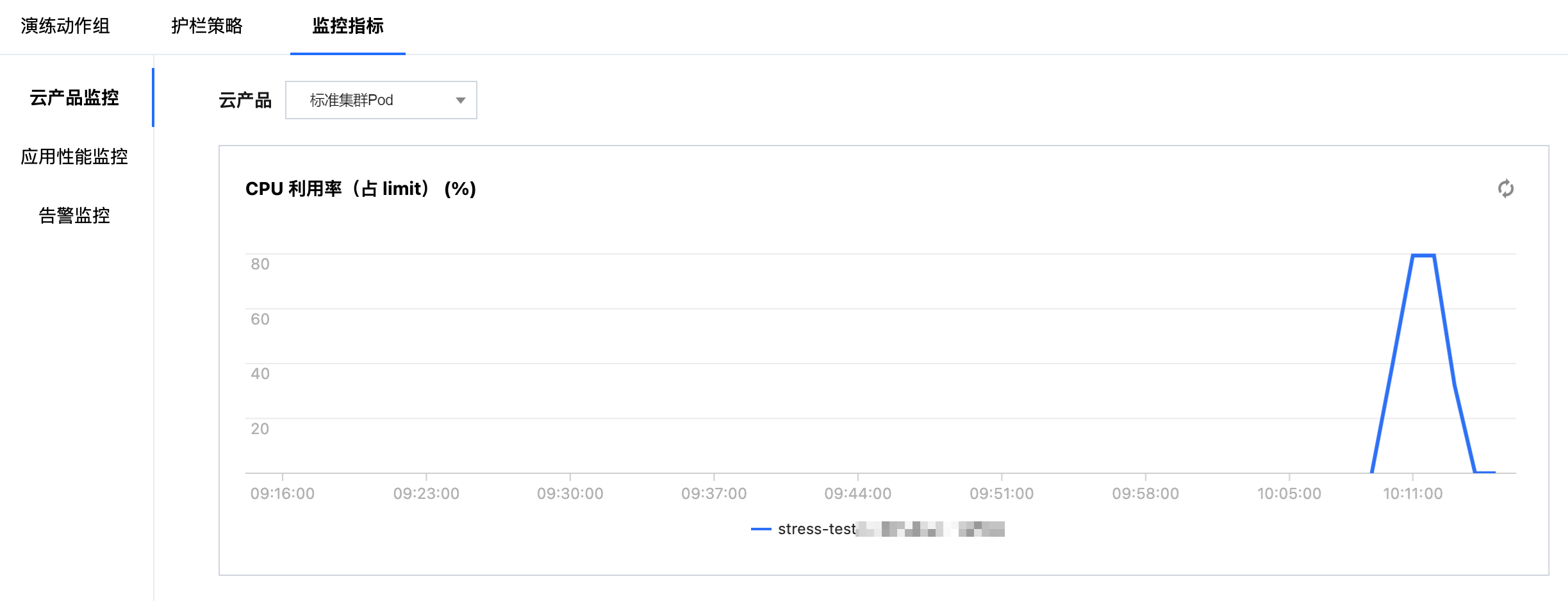
2. 执行内存利用率搞动作,观察监控指标。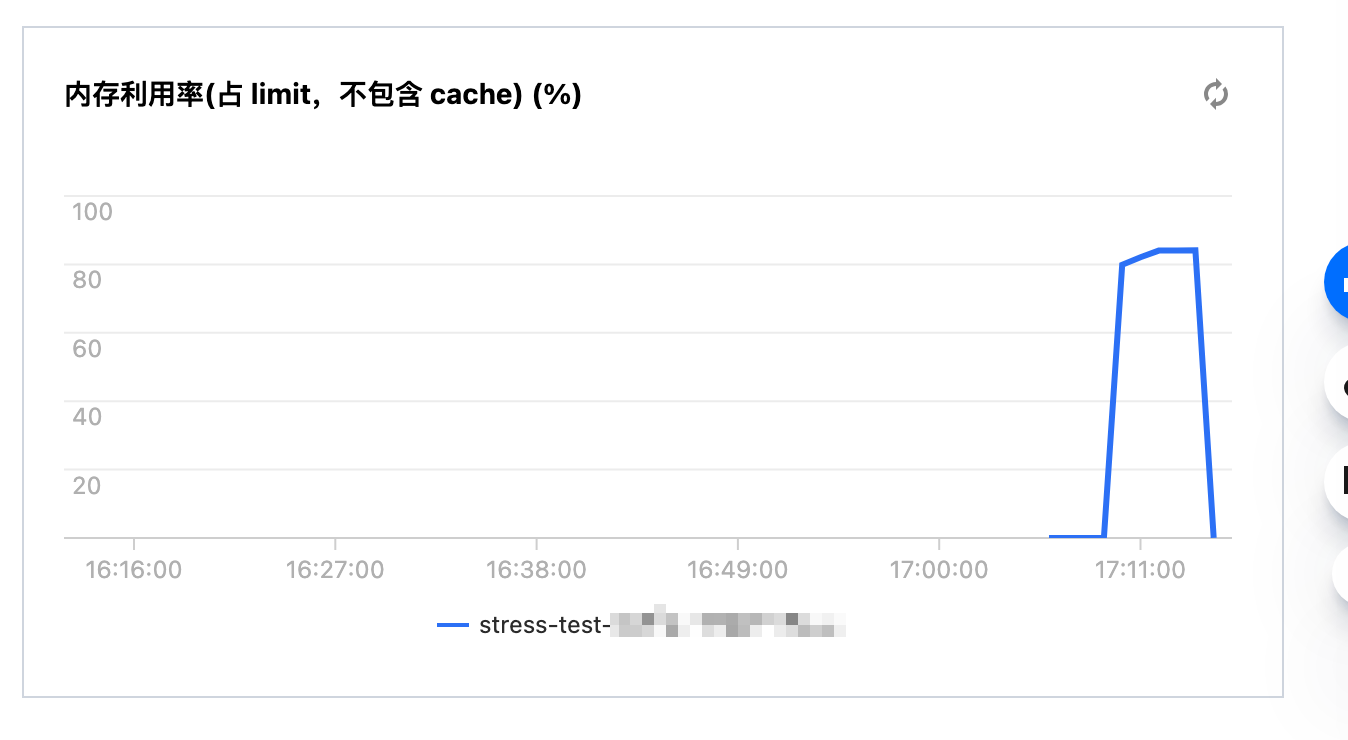
3. 执行磁盘使用率高动作,登入容器后使用 df 命令观察磁盘负载逐步提高达到指定使用率,执行回滚动作后恢复至常态。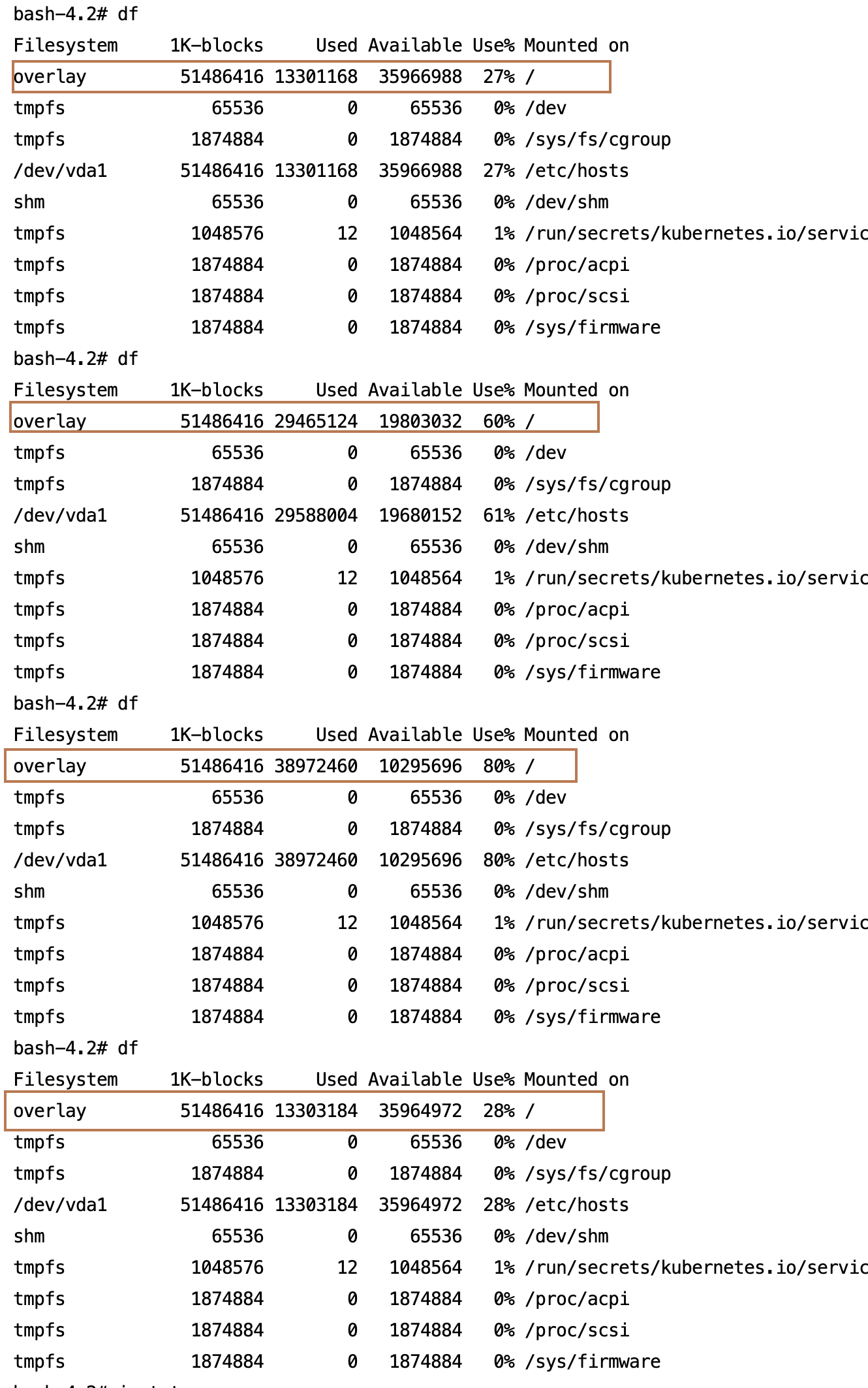
4. 执行磁盘 IO 高负载动作,登入容器后使用 iostat 命令观察。
故障中
回滚后







