背景
TKE Serverless 集群和普通集群提供 超级节点 能力,以提高资源动态扩缩容效率并降低资源使用成本。集群以 Pod 形式交付计算资源,无需用户管理 Pod 背后运行的实际节点,使用超级节点类似于使用一台超大规格的 CVM,便于资源管理和资源扩缩容。
超级节点本身只是逻辑概念,在超级节点上运行 Pod 时,集群会动态创建一个临时的虚拟节点,该虚拟节点为 Pod 独占,并随 Pod 的删除销毁。当检测到虚拟节点故障时,Pod 会进行容灾漂移,重新构建虚拟节点并重建 Pod。您可以将超级节点部署在不同可用区实现资源分散,规避可用区故障带来的灾难风险。云顾问 - 混沌演练提供 Serverless Pod 虚拟节点关机故障场景,可以帮助您验证虚拟节点出现故障后,Pod 容灾漂移对您的服务造成的影响,更进一步,还可以模拟单可用区故障后对调度到超级节点上 Pod 的影响,以验证您容灾设计的有效性。
注意:
对未调度到超级节点的 Pod 进行该场景故障注入会失败。
k8s 集群具备一定的故障自愈能力,但当发生大规模故障时,如突发超过 50% 的 node 或 50% Serverless 容器异常时,该自愈能力会退避甚至熔断,避免突发大规模的驱逐、摘流动作导致更大的故障风险,例如引发整个集群雪崩。建议您单次故障演练不要超过集群总 Serverless Pod 总数的一半。
故障判定时长受虚拟机内 Agent 上报超时配置影响(默认5min),如果需要及时摘除异常 Pod 流量,请参照 自动重建自愈 进行配置。
故障参数说明
持续时间(s):故障允许的最大时间,默认值为30min,故障注入成功开始经过配置的持续时间后,故障会自动恢复(即使未手动执行恢复动作)。
是否自动重建 Pod:是否开启 Pod 的自动重建功能,默认开启。用于模拟无法自愈的持续故障,详情请参照 自动重建自愈。
恢复后等待 Pod 重建时间(s):故障自愈后,会在该时间内持续检测 Pod 健康状态,以判断故障是否恢复,默认值为8min。请确保该时长大于 Pod 的最大重建时间。
演练实施
步骤一:演练准备
运行在超级节点的 Pod 实例,例如 Serverless 集群和标准集群超级节点。
进入 探针管理 页面对 Pod 所在集群安装故障注入探针。
步骤二:创建演练
1. 登录 云顾问 > 混沌演练控制台,进入演练管理页面,单击新建演练。
2. 单击跳过,新建空白演练,并填写演练信息。
步骤三:添加演练实例和动作
1. 在演练对象配置环节中,选择对象类型容器为标准集群 Pod 或 Serverless 集群 Pod。
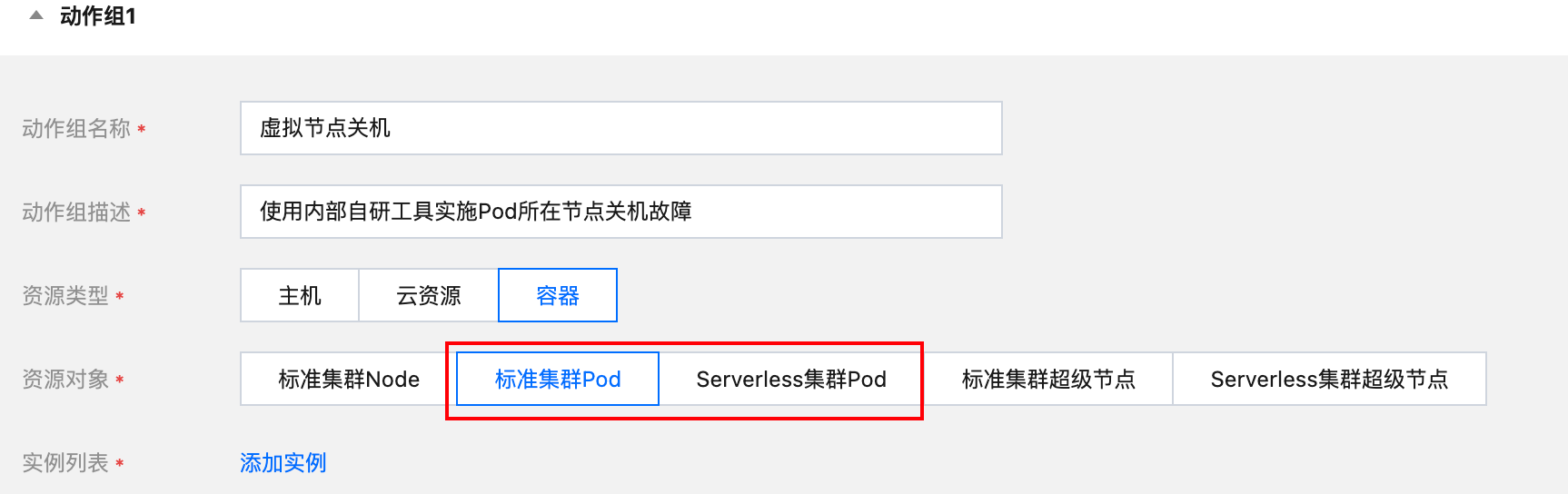
2. 添加实例选择对应的 Pod 名称。选择需要注入的集群 ID 和命名空间,将会自动获取集群下该命名空间的 Pod。
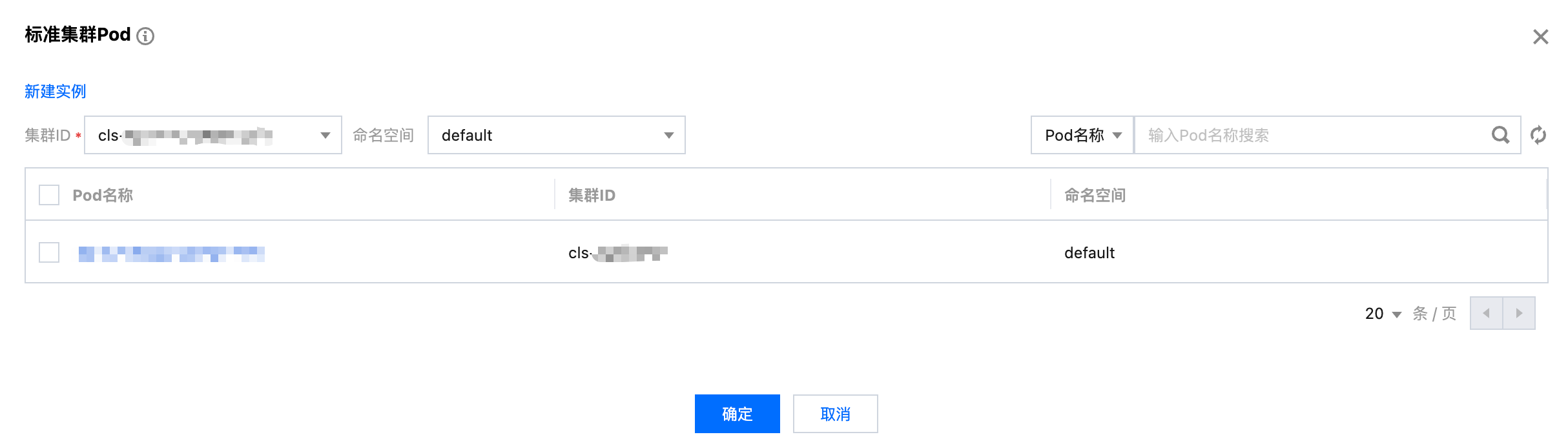
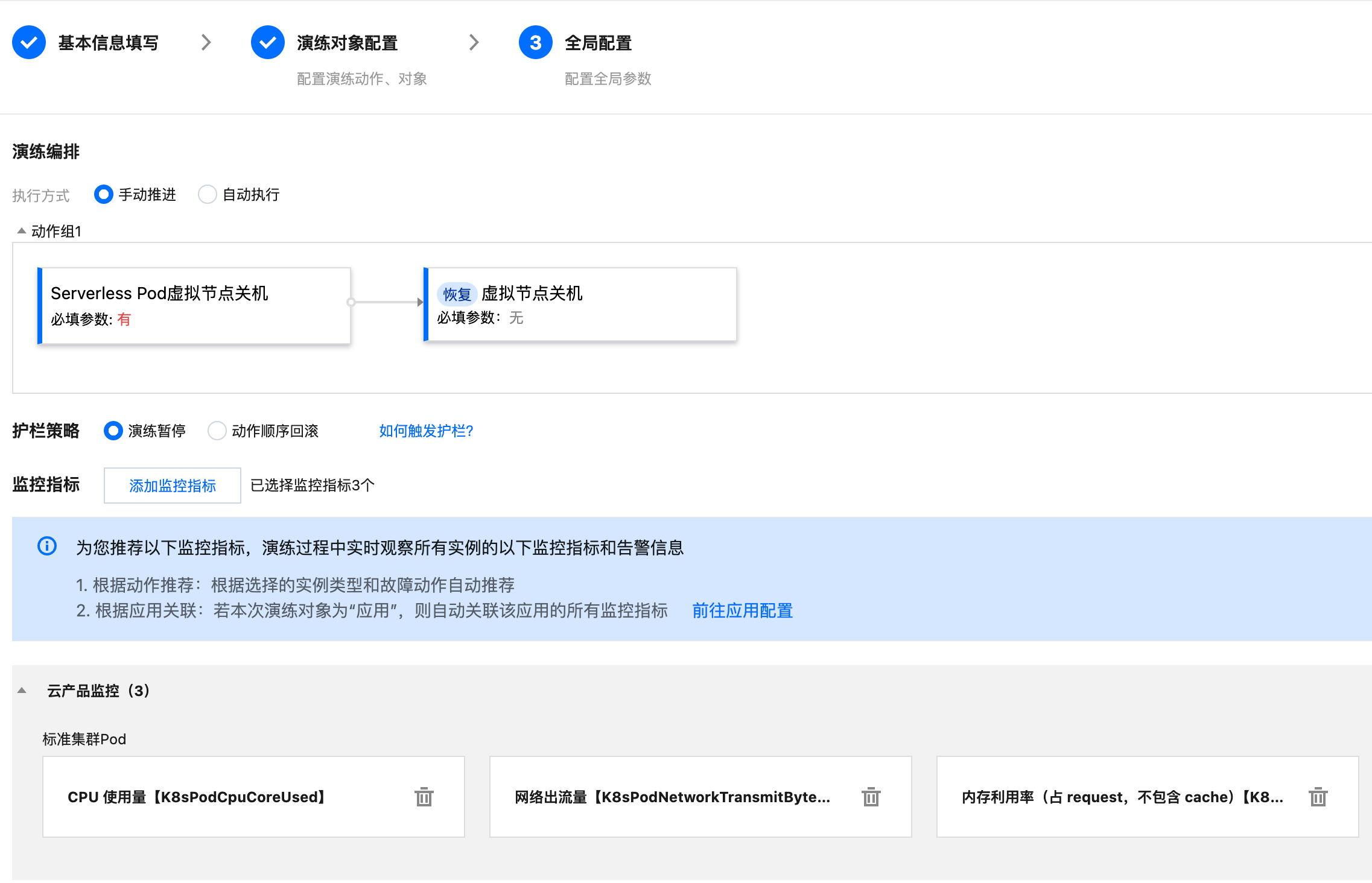
3. 添加演练动作。选择 Pod 操作分类下的 Serverless Pod 虚拟节点关机故障。
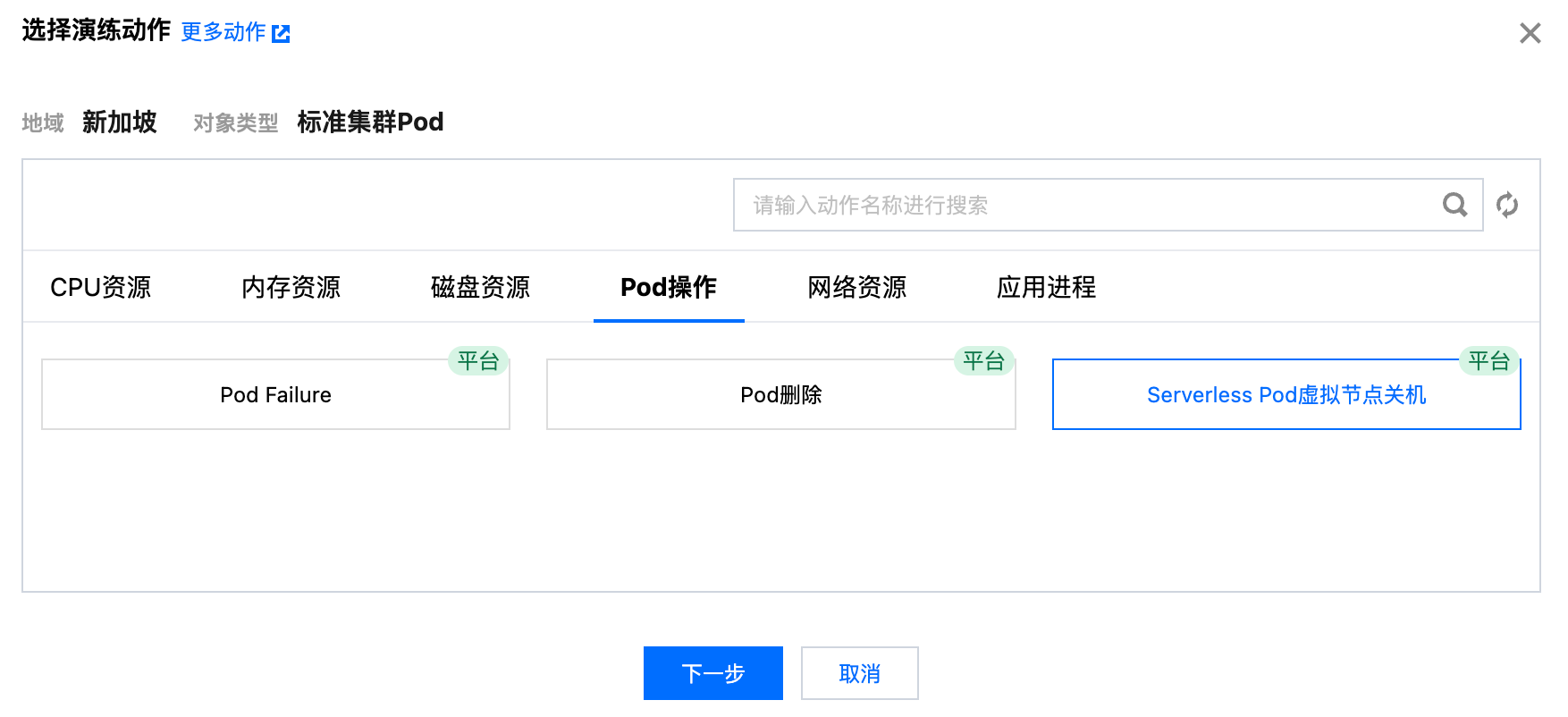
4. 配置动作参数,请参照故障参数说明一节。
步骤四:全局配置
可在全局配置阶段配置推进方式、监控指标,护栏等策略。
故障结果观测
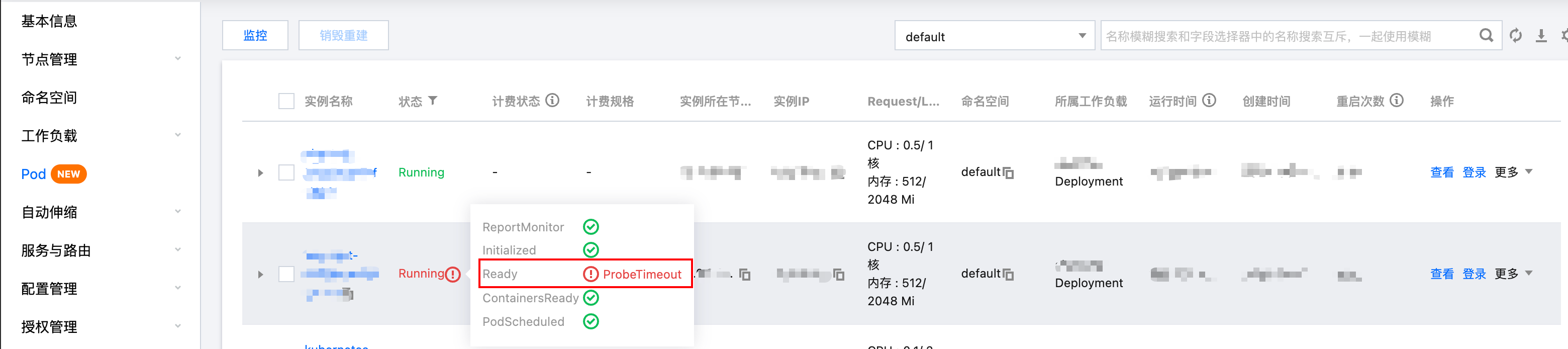
点击执行等待故障注入成功,在 TKE 控制台 > 集群 中观察 Pod 状态。进入集群基本信息页面,点击 Pod,当 Pod 的 Ready 状态为 ProbeTimeout,代表底层虚拟节点已经关机成功,引发相应的 Agent 上报超时(此时异常 Pod 的流量已被摘除)。
如果在故障参数中指定自动重建失败 Pod,那么在故障后,会自动触发 Pod 重建,Pod 会在一定时间内进行重建自愈,可以观察相应 Pod 重建事件。
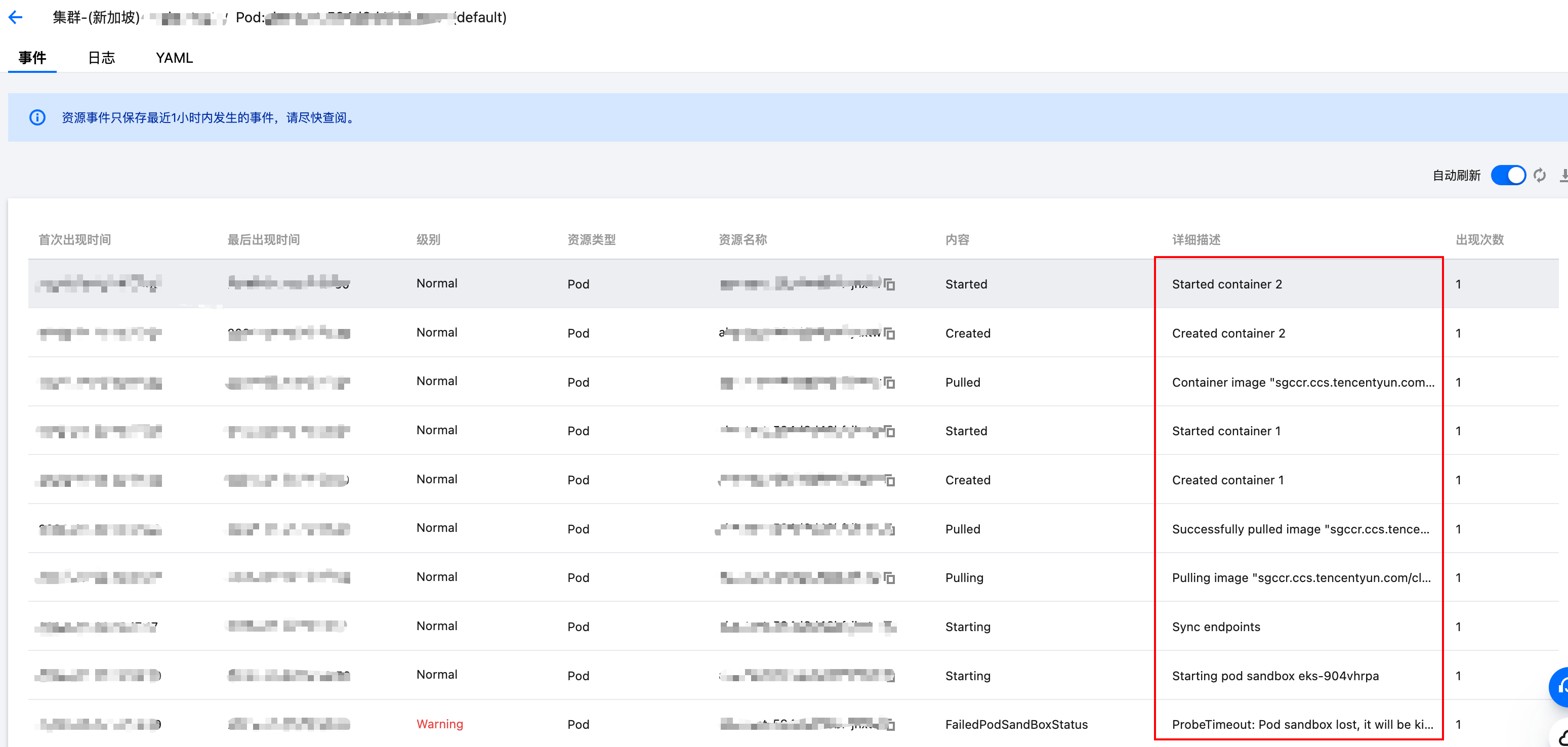
如果在故障参数中指定不自动重建失败 Pod,那么故障会持续,直到手动执行回滚动作,或到达故障持续时间自动恢复故障。故障恢复的过程同样是重新分配底层虚拟节点并重建Pod。
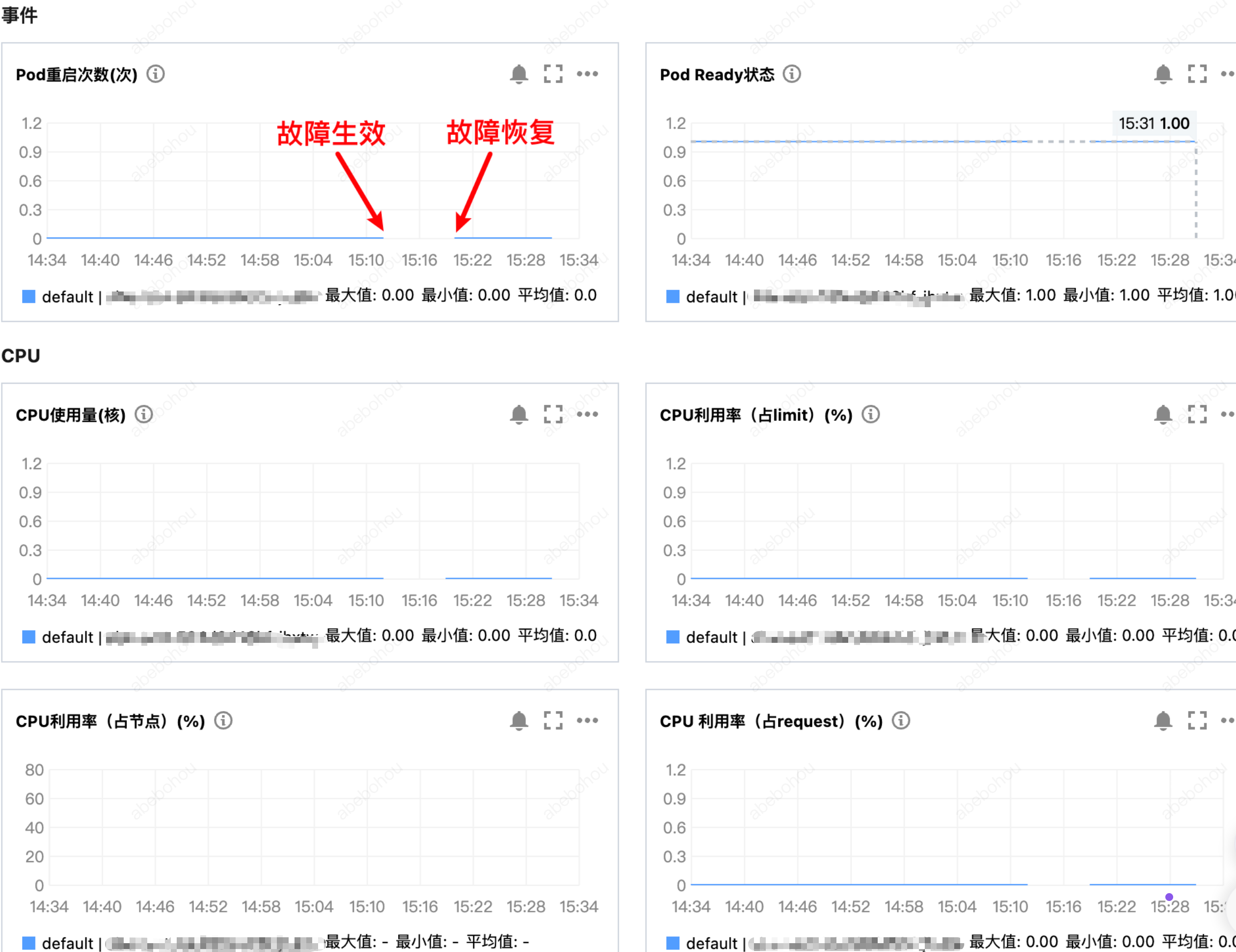
此外,通过观察 Pod 监控指标,也可以观察到故障过程,如下图,Pod 的各项指标在故障后出现断点并在故障恢复后恢复(注意:因为 Pod 整体发生重新调度,所以 Pod 重启次数不会增加)。
FAQ
如何模拟超级节点单可用区故障?
如果您在购买超级节点时进行过多可用区配置,可以先将待故障可用区的超级节点 封锁,然后对调度到该超级节点的所有 Pod 执行虚拟节点关机故障,模拟因为单可用区故障后,超级节点整体不可用,Pod 迁移到其它可用区的场景。







