介绍
大模型的自回归解码的特性导致其不能充分利用 GPU 的并行计算进行加速。基于此,学术界提出了投机采样,其可以利用更高效的 Draft Model 快速生成多个 Token,然后一次性地交给 Target Model 进行验证。在接受率高的情况下,可以显著减少推理时间。
传统的投机采样使用 GPU 作为 Draft Model 的计算资源,而 GPU 的成本高昂。针对这个痛点,TACO 与 Intel 团队合作,基于 AMX 指令集对 CPU 上的矩阵乘法做了优化,借助 Intel 推出的 IPEX 加速库及其他技术对 CPU 上的推理进行加速,使得 CPU 作为 Draft Model 成为可能,从而在进行推理加速的同时,显著降低了推理成本。
注意:
当前该功能支持的机型:搭载 Intel EMR 8576C 或 Intel SPR 8476C 的 GPU 云服务器,其中:
SPR:搭载内置加速器的第四代英特尔® 至强® 可扩展处理器。
EMR:搭载内置加速器的第五代英特尔® 至强® 可扩展处理器。
基于 TACO-LLM 使用 CPU 单独进行推理
注意:
该 feature 会导致 GPU 推理的功能失效,因此若想使用 GPU 推理,需要重新安装对应的包。
1. 额外依赖安装
sudo apt-get updatesudo apt-get install -y libdnnl-devpip install intel-extension-for-pytorch==2.4.0pip install torch --index-url https://download.pytorch.org/whl/cpu
2. 环境检查(如果出现问题)
需要确保:
1. torch 和 ipex 的版本号匹配
2. torch 是 cpu 版本
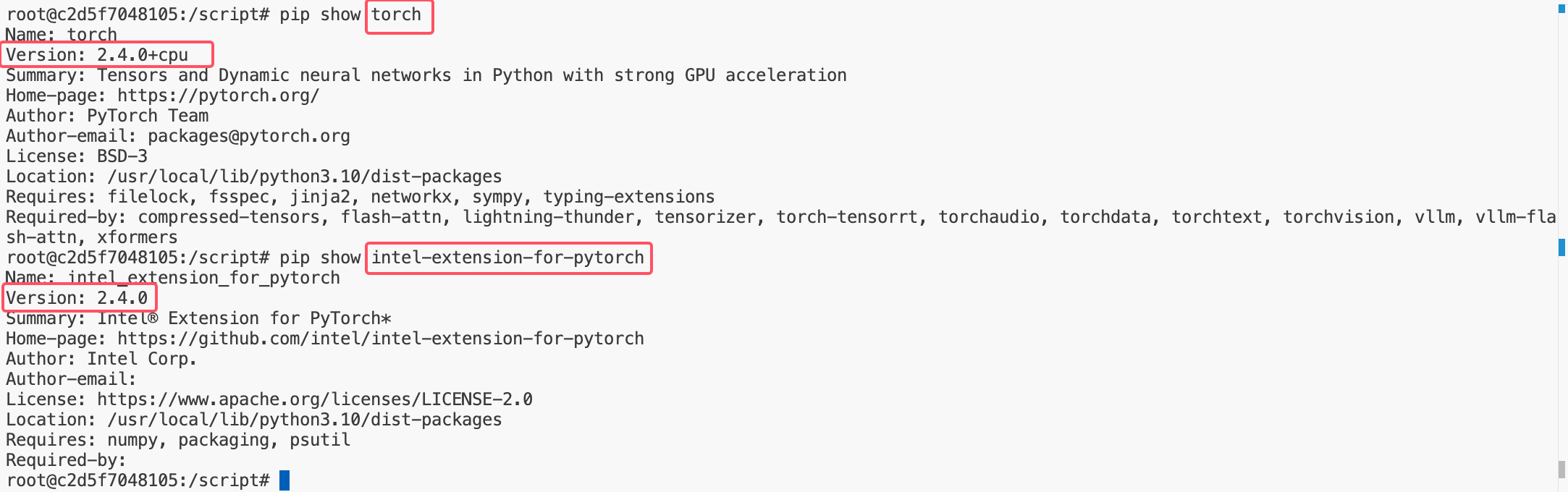
3. 使用
以离线模式为例,其使用方法和在 GPU 上推理完全一致。
llm = LLM(model="facebook/opt-125m")
基于 TACO-LLM 使用 CPU 辅助投机采样
1. 额外依赖安装
sudo apt-get updatesudo apt-get install -y libdnnl-devpip install intel-extension-for-pytorch==2.4.0pip install torch==2.4.0
2. 环境检查(如果出现问题)
需要确保:
1. torch 和 ipex 的版本号匹配
2. torch 是不带 cpu 的版本
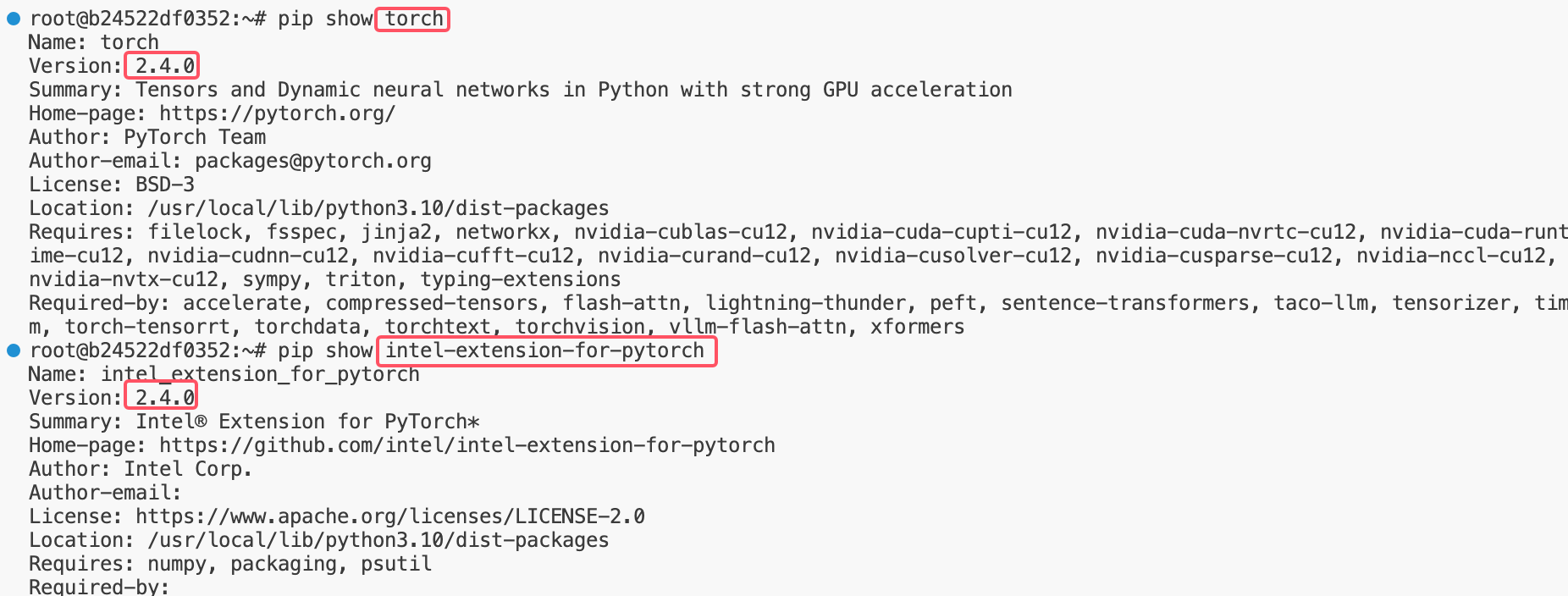
3. 使用
以离线模式为例,其使用方法在投机采样原始配置上额外新增一个 cpu_draft_worker 即可。
llm = LLM(model = "meta-llama/Llama-2-7b-chat-hf",speculative_model = "Felladrin/Llama-68M-Chat-v1",num_speculative_tokens = 2,use_v2_block_manager = True,cpu_draft_worker = True, # <<== 新增参数)
附录
AMX 介绍
什么是 AMX?
英特尔推出的第四代英特尔® 至强® 可扩展处理器及其内置的英特尔® 高级矩阵扩展(Intel® Advanced Matrix Extensions,英特尔® AMX)可进一步提高 AI 功能,实现较上一代产品 3 至 10 倍的推理和训练性能提升。
开发人员可以编写非 AI 功能代码来利用处理器的指令集架构 (ISA),也可编写 AI 功能代码,以充分发挥英特尔® AMX 指令集的优势。英特尔已将其 oneAPI DL 引擎——英特尔® oneAPI 深度神经网络库(Intel® oneAPI Deep Neural Network Library,英特尔® oneDNN)集成至包括 TensorFlow、PyTorch、PaddlePaddle 和 ONNX 在内的多个主流 AI 应用开源工具当中。
AMX 架构
英特尔® AMX 架构由两部分组件构成:
第一部分为 TILE,由 8 个 1 KB 大小的 2D 寄存器组成,可存储大数据块。
第二部分为平铺矩阵乘法 (TMUL),它是与 TILE 连接的加速引擎,可执行用于 AI 的矩阵乘法计算。

AMX 支持的数据类型
英特尔® AMX 支持两种数据类型:INT8 和 BF16,两者均可用于 AI 工作负载所需的矩阵乘法运算。
当推理无需 FP32 的精度时可使用 INT8 这种数据类型。由于该数据类型的精度较低,因此单位计算周期内运算次数就更多。
BF16 这种数据类型实现的准确度足以达到大多数训练的要求,必要时它也能让 AI 推理实现更高的准确度。
AMX 的性能
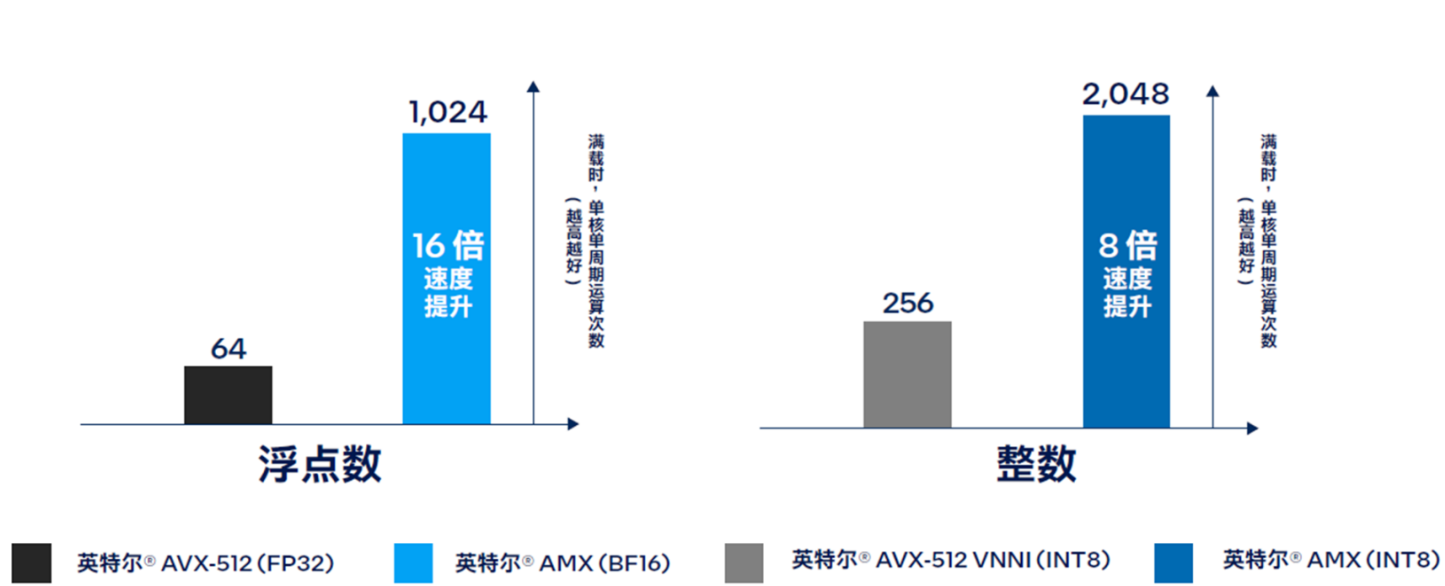
凭借这种新的平铺架构,英特尔® AMX 实现了大幅代际性能提升。与运行英特尔® 高级矢量扩展 512 神经网络指令(Intel® Advanced Vector Extensions 512 Neural Network Instructions,英特尔® AVX-512 VNNI)的第三代英特尔® 至强® 可扩展处理器相比,运行英特尔® AMX 的第四代英特尔® 至强® 可扩展处理器将单位计算周期内执行 INT8 运算的次数从 256 次提高至 2048 次。此外,如图 6 所示,第四代英特尔® 至强® 可扩展处理器可在单位计算周期内执行 1024 次 BF16 运算,而第三代英特尔® 至强® 可扩展处理器执行 FP32 运算的次数仅为 64 次。
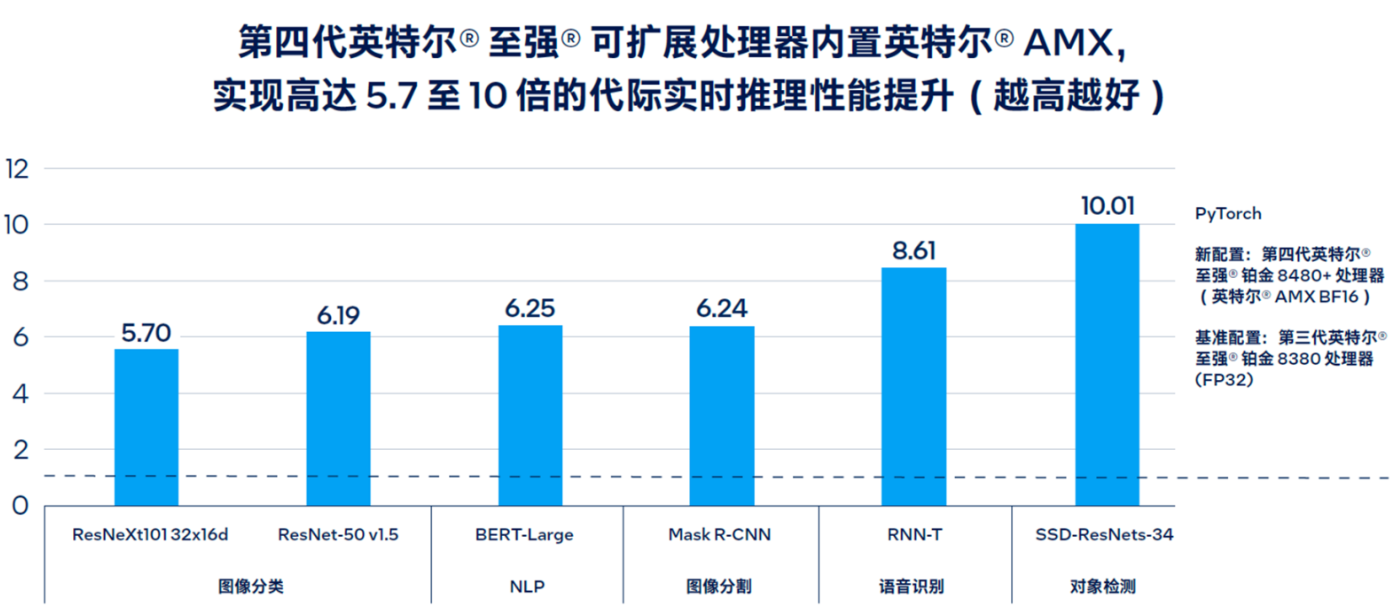
下图所示为英特尔® AMX 在代际间实现高达 5.7 至 10 倍的 PyTorch 实时推理性能提升的情况。
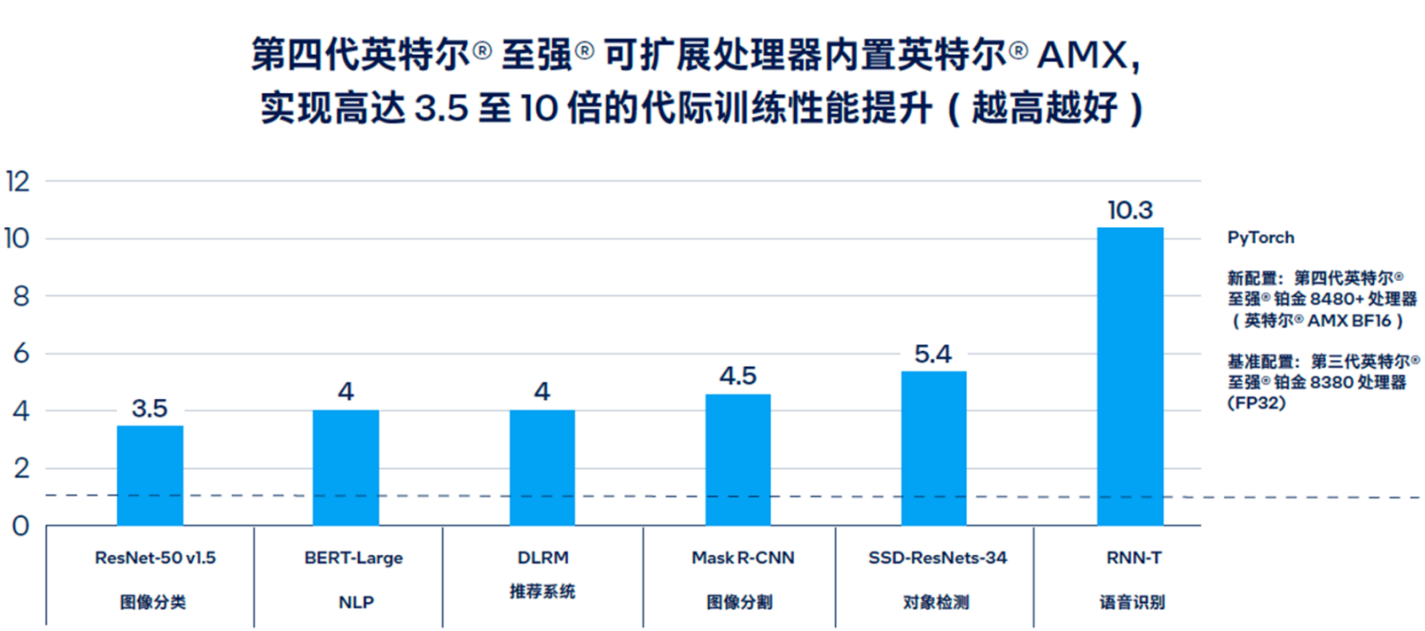
下图所示为英特尔® AMX 在代际间实现高达 3.5 至 10 倍的 PyTorch 训练性能提升的情况。
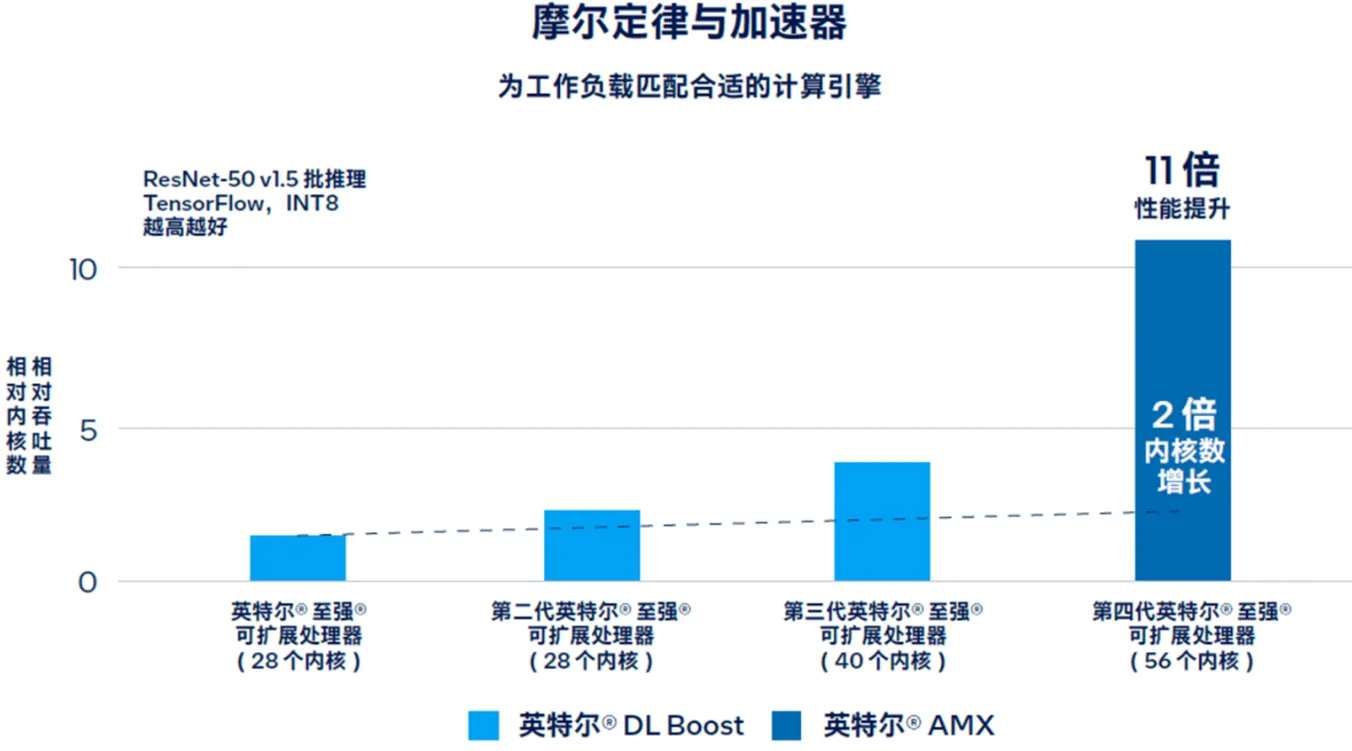
通过下图可以看出英特尔® AMX 带来的性能提升远大于每一代产品(从第一代英特尔® 至强® 可扩展处理器开始)通过增加内核所实现的性能提升。
IPEX 介绍
Intel® Extension for PyTorch* (IPEX) 是由英特尔发起的一个开源扩展项目,旨在通过模块级的全面优化及更为简洁的API接口,在基于原生PyTorch框架运行时,显著提升深度学习任务在英特尔硬件(包括但不限于CPU和GPU)上的推理与训练性能。IPEX兼容PyTorch生态系统中超过90%的主流模型,并对其中50多个深度模型进行了特别优化。用户只需添加少量代码以启用BF16混合精度支持,即可轻松享受到性能上的显著改进,整个过程无需复杂的配置调整,从而提供了近乎即插即用的便捷体验。
此外,Intel® Extension for PyTorch* 通过对Intel硬件特性的深入挖掘,如利用Intel® Advanced Vector Extensions 512 (AVX-512) 中的向量神经网络指令(VNNI)、Intel® Advanced Matrix Extensions (AMX) 以及Intel独立显卡上配备的Intel Xe Matrix Extensions (XMX) AI加速引擎等技术,进一步增强了PyTorch在Intel平台上的执行效率。



