背景
在 LLM 大模型推理中,长序列场景应用越来越广泛,目前业界对长序列的优化主要是 kv cache 量化、稀疏化等方法,这些都对模型精度有一定的影响。TACO LLM 自研长序列并行方案,可以在长序列场景进行精度无损的加速。长序列推理场景首字延迟会比较慢,针对该问题,序列并行在 prefill 阶段采用了 Ring Attention 类的方案,可以通过扩展机器,降低首字延迟。而对于推理阶段,TACO LLM 可以使用 Lookahead 等投机采样技术加速。
使用方式
启动 TACO LLM 服务时添加参数 --sequence-parallel-size 2 即可开启序列并行,目前只支持 serve 方式,不支持 LLM 的离线方式(0.6.4版本开始支持)。
最佳实践
序列并行可以和张量并行一起使用,同时也可以和 FP8一起使用。序列并行适合符合如下几个特点的场景:
由于序列并行具备通信计算重叠的优点,故适合在 PNV5b、4090PCIe 系列卡上。
适合输入较长,输出较短的场景。
建议与 FP8 一起使用,加速效果更好。
适合 GQA 类的模型,由于 kv cache 更小,通信更小,相对于 TP 来说加速更快。
性能数据
MHA 场景
当前测试模型大小为 Llama2 7B,序列长度为6000, SP 为2,在 PNV6/HCCPNV6 和 A800上,相对于 TP 无性能提升。
在 PNV5b 上 FP16:SP = 2的场景相对于 TP = 2场景,端到端性能有5%到15%的提升,prefill 性能提升15%-20%。
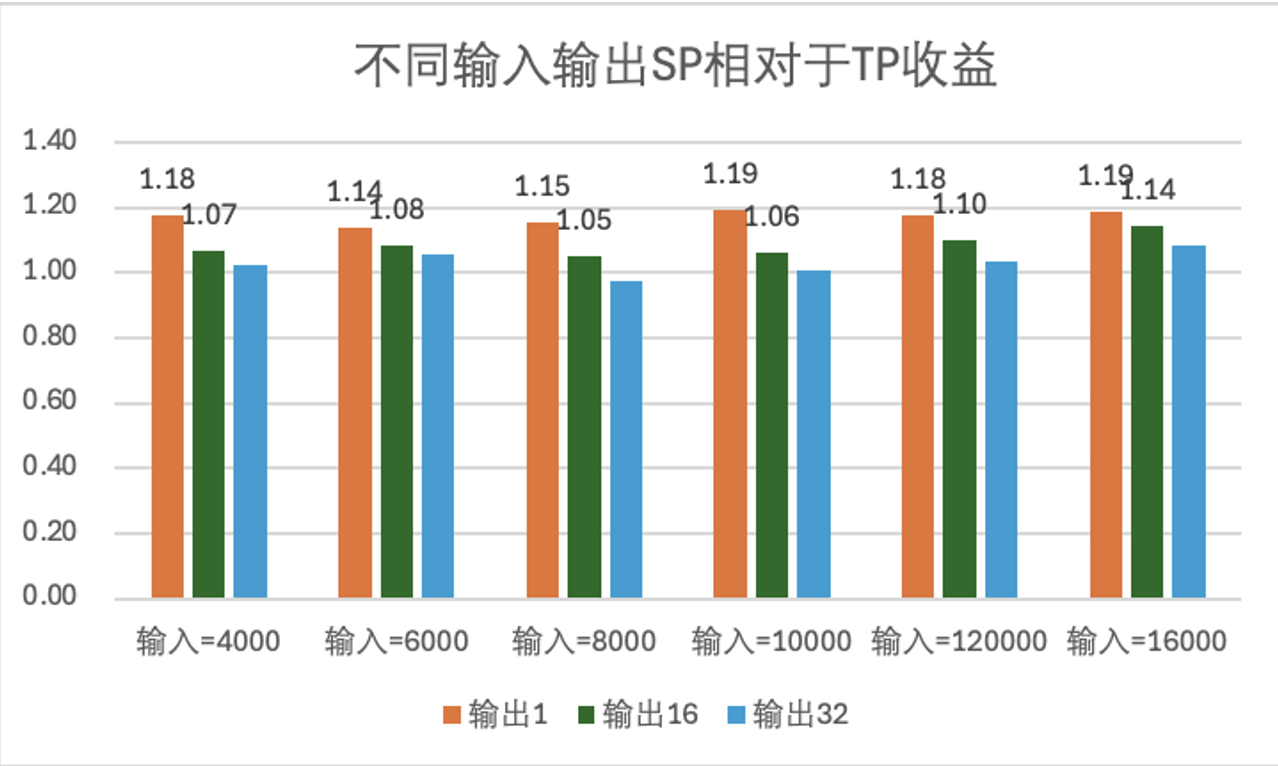
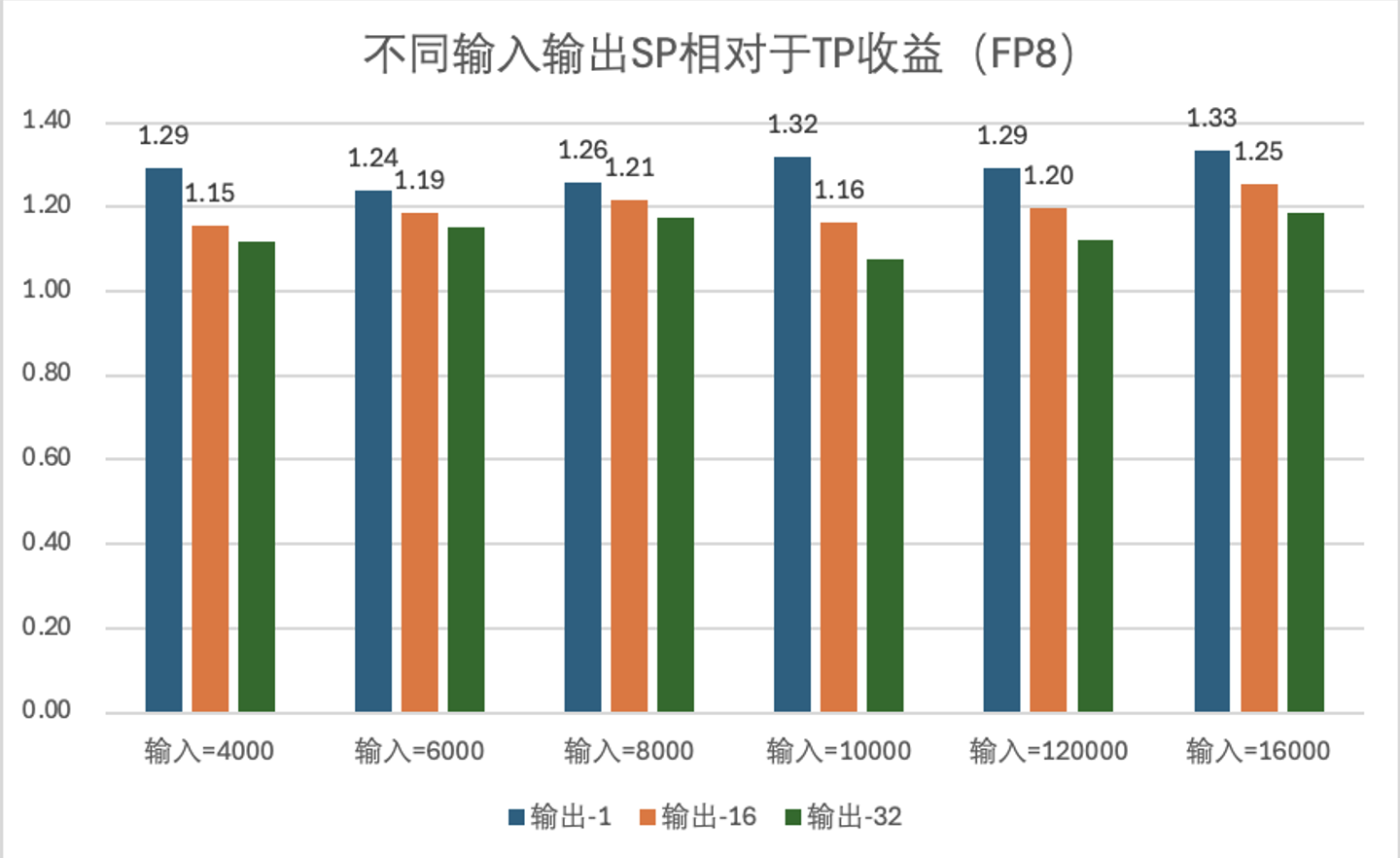
在 PNV5b 上 FP8:SP = 2的场景相对于 TP = 2场景,性能有15%到25%的提升。
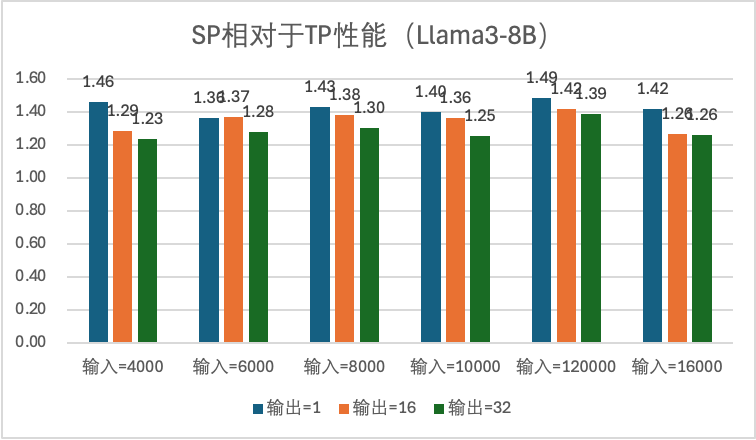
GQA 场景
当前测试模型大小为 Llama3-8B。
在 PNV5b 上 FP16:SP = 2的场景相对于 TP = 2场景,端到端性能有10%到20%的提升,prefill 性能提升20%-30%。
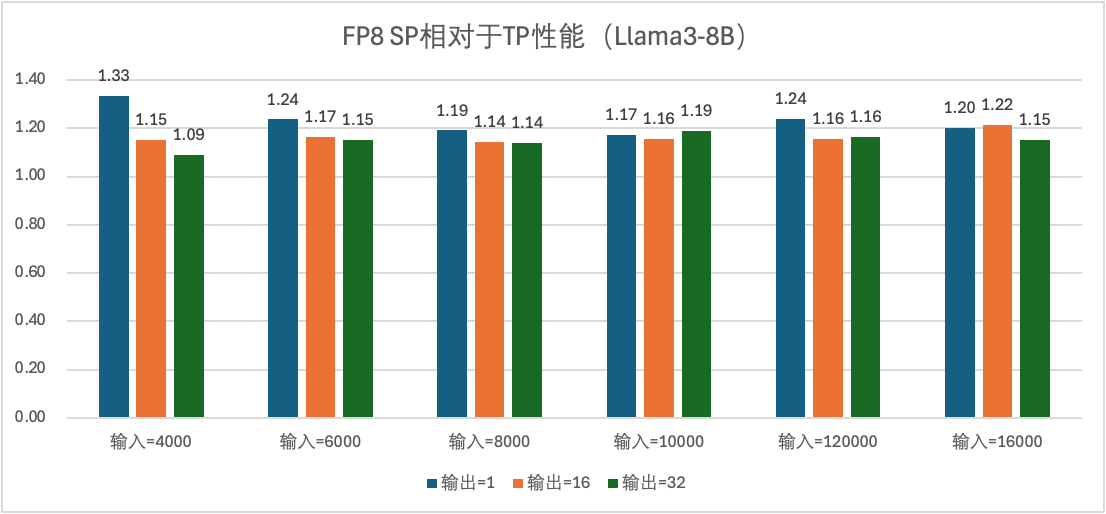
在 PNV5b 上 FP8:SP = 2的场景相对于 TP = 2场景,端到端性能有20%到40%的提升,prefill 性能有40%-50%。